ある意味こちらの記事の続きです。
上の記事ではエージェントにどのように文脈を与えて、それと企業の知識をどのように組み合わせてエージェントしてどうさせるべきかの思考実験を行いました。
こちらでは、人間とエージェントのインタフェースについて思考実験とプロトタイピングを行なってみます。
モチベーション
- 生成AIのユースケースの一つが要約です。こちらのチュートリアルを体験してみるとわかりますが、非常に高い精度でWebページから要約を作成してくれます。
- ただ、ノートブックでしか要約を見れないのはもどかしいです。Webページの要約を見たいのは、Webページを見ている時です。
- なので、Webページを見ているときに生成AIによる要約を見れるようにしてみました。
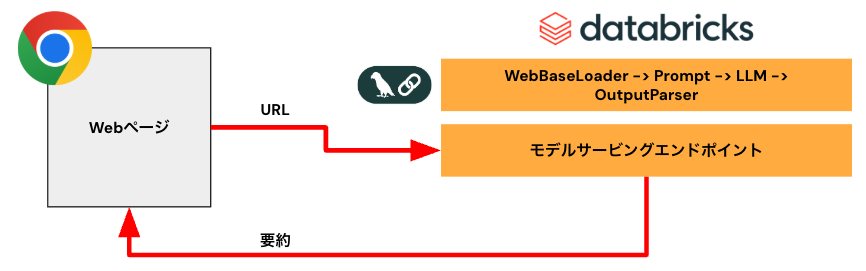
アーキテクチャ
- Langchainで要約チェーンを構築
- LLMはgpt-4o-mini
- Databricksモデルサービングエンドポイントにチェーンをデプロイ。REST APIで要約を取得できるように
- フロントエンドとしてChrome拡張を作成
実装
この仕組みはスクレイピングを伴うので、使用する際には用法にご注意ください。ここでは、Databricksマニュアルサイト限定で動作するものを構築します。
バックエンド
Databricksで以下のノートブックを実行していきます。DBR 16.1MLを使っています。
%pip install --upgrade --quiet tiktoken langchain langgraph beautifulsoup4 langchain-community
%pip install -qU langchain-openai
%restart_python
OpenAIのAPIキーはシークレットに格納しておきます。モデルサービングエンドポイントの設定でもシークレットを使います。
import os
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai_api_key")
最初にWebBaseLoaderの挙動を確認します。
loader = WebBaseLoader("https://docs.databricks.com/ja/generative-ai/retrieval-augmented-generation.html")
docs = loader.load()
docs[0].page_content
Webページのテキストが取得できています。
'\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nDatabricksのRAG (検索拡張生成) | Databricks on AWS\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nヘルプセンター\n\nドキュメント\n\nナレッジベース\n\n\n\n\n\n\n\nコミュニティ\nサポート\nフィードバック\nDatabricks を試す\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nEnglish\n\n\nEnglish\n\n\n日本語\n\n\nPortuguês\n\n\n\n\nAmazon\n Web Services\n\n\nMicrosoft Azure\n\n\nGoogle Cloud Platform\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nDatabricks on AWS\nはじめに\n\nはじめに\nDatabricks とは\nDatabricksIQ\nリリースノート\n\nデータの読み込みと管理\n\nデータベースオブジェクトの操作\nデータソースへの接続\nコンピュートへの接続\nデータの発見\nデータのクエリー\nデータの取り込み\nファイルの操作\nデータの変換\nワークフローのスケジュールとオーケストレーション\nデータとAI資産を監視する\n外部システムでの読み取り\nデータの安全な共有\n\nデータの取り扱い\n\nデータエンジニアリング\nAIと機械学習\nチュートリアル\nAI playground\nSQLのAI関数\nAIゲートウェイ\nモデルのデプロイ\nモデルのトレーニング\nAIのためのデータ提供\nAIの評価\n生成AIアプリの構築\nAI エージェントの作成\nエージェントツール\nトレースエージェント\nエージェントの記録と登録\nエージェントのデプロイ\nエージェントスキーマの定義\n複合AIシステムとAIエージェント\nDatabricks 上の RAG\n\n\nMLOps と MLflow\n生成AIモデルのメンテナンスポリシー\n統合\nグラフとネットワーク解析\nリファレンスソリューション\n\n\n生成AI チュートリアル\nビジネスインテリジェンス\nデータウェアハウジング\nノートブック\nDelta Lake\n開発者\n技術パートナー\n\n管理\n\nアカウントとワークスペースの管理\nセキュリティとコンプライアンス\nデータガバナンス(Unity Catalog)\nレイクハウスアーキテクチャ\n\n参考資料とリソース\n\n参考資料\nリソース\n今後の予定\nドキュメントアーカイブ\n\n\n\n更新しました 2025/01/08\n\n\nフィードバックの送信\n\n\n\n\n\n\n\n\n\n\nドキュメント \nDatabricksにおけるAIと機械学習 \nDatabricksの生成AIアプリ構築入門 \nDatabricksのRAG (検索拡張生成) \n\n\n\n\n\n\n\nDatabricksのRAG (検索拡張生成) \n\nプレビュー\nこの機能はパブリックプレビュー段階です。\n\nAgent Framework は、開発者がDatabricks Retrieval Augmented Generation (RAG) アプリケーションなどの本番運用品質のAI エージェント を構築、デプロイ、評価できるように設計された 上の一連のツールで構成されています。\nこの記事では、RAG とは何かについて、また Databricks で RAG アプリケーションを開発する利点について説明します。\n\n\n\nエージェントフレームワークには、エンドツーエンドのLLMOpsワークフローを使用して、RAG開発のすべてを迅速に反復させられるという利点があります。\n\n要件\n\nパートナーが提供するAI支援機能は、ワークスペースで有効にする必要があります。\nエージェントアプリケーションのすべてのコンポーネントは、1つのワークスペース内に存在する必要があります。たとえばRAGアプリケーションの場合、サービングモデルとベクトル検索インスタンスは同じワークスペースに存在する必要があります。\n\n\n\nRAG とは\nRAG は大規模言語モデル(LLM)を外部の知識で強化する生成 AI の設計手法です。この手法では、以下の方法でLLMを改善します:\n\n独自の知識:特定分野の質問に答えるため、LLM の初期学習に使用されていない独自の情報(メモ、メール、文書など)を RAG に含めることができます。\n最新情報:RAG アプリケーションは、更新されたデータソースから LLM に情報を提供することができます。\n情報源の引用:RAG を利用すると、LLM は特定の情報源を引用することができ、ユーザーが回答の正確さを確認できます。\nデータセキュリティとアクセス制御リスト(ACL):ユーザー認証情報に基づいて個人情報や専有情報が選択的に取得されるように検索ステップを設計できます。\n\n\n複合 AI システム \nRAG アプリケーションは複合 AI システムの一例です。LLM の言語能力を他のツールや手順と組み合わせて拡張することができます。\n最も単純な形式では、RAG アプリケーションは以下のことを実行します:\n\n検索:ユーザーのリクエストを使用して、ベクトルストア、テキストキーワード検索、SQLデータベースなどの外部データストアに対してクエリーを実行します。LLM の回答を裏付けるデータを取得することが目標です。\n拡張:多くの場合、追加の書式設定と指示を含むテンプレートを使用し、取得したデータとユーザーのリクエストを組み合わせてプロンプトを作成します。\n生成:プロンプトが LLM に渡され、クエリーに対する回答が生成されます。\n\n\n\n\n非構造化 RAG データと構造化 RAG データ \nRAG アーキテクチャでは、非構造化サポートデータと構造化サポートデータのいずれかを使用できます。RAG で使用するデータはユースケースによって異なります。\n非構造化データ:特定の構造や組織を持たないデータ。テキスト、画像、音声、動画などのマルチメディアコンテンツを含むドキュメント。\n\nPDF\nGoogle/Office ドキュメント\nWiki\n画像\n動画\n\n構造化データ:データベースのテーブルなど、特定のスキーマに従って行と列に配置された表形式のデータ。\n\nBI またはデータウェアハウスシステムの顧客レコード\nSQL データベースのトランザクションデータ\nアプリケーション API(SAP、Salesforce など)から取得したデータ\n\n以下のセクションでは、非構造化データのRAGアプリケーションについて説明します。\n\n\nRAG データパイプライン\nRAG データパイプラインは、迅速かつ正確な検索のため、ドキュメントを前処理してインデックス化します。\n以下の図は、セマンティック検索アルゴリズムを使用した非構造化データセットのサンプルデータパイプラインを示しています。Databricks ジョブは各ステップをオーケストレーションします。\n\n\n\n\nデータ取り込み - 独自のデータソースからデータを取り込みます。このデータを Delta テーブルまたは Unity Catalog ボリュームに保存します。\nドキュメント処理:これらのタスクは、Databricks ジョブ、Databricks ノートブック、および Delta Live Tables を使用して実行できます。\n\n生ドキュメントの解析:生データを使用可能な形式に変換します。例えば、PDF のコレクションからテキスト、表、画像を抽出したり、光学文字認識技術を使用して画像からテキストを抽出したりします。\nメタデータの抽出:検索ステップのクエリをより正確にするために、ドキュメントのタイトル、ページ番号、URLなどのドキュメントメタデータを抽出します。\nドキュメントのチャンク分割:データを LLM のコンテキストウィンドウに収まるチャンクに分割します。文書全体ではなく、これらの焦点を絞ったチャンクを取得することで、回答の生成に役立つ、より的を絞ったコンテンツを LLM に提供します。\n\n\nチャンクのエンべディング - エンべディングモデルは、チャンクを使用してベクトルエンべディングと呼ばれる情報の数値表現を作成します。ベクトルは表面的なキーワードだけでなく、テキストの意味的な情報を表現します。このシナリオでは、エンべディングを計算し、モデルサービングを使用してエンべディングモデルを提供します。\nエンべディングの保存 - ベクトルエンべディングとチャンクのテキストを、ベクトル検索と同期されている Delta テーブルに保存します。\nベクトルデータベース - RAG エージェントが簡単にクエリーできるように、エンべディングとメタデータは、ベクトル検索の一貫としてインデックス化され、ベクトルデータベースに保存されます。ユーザーがクエリーを実行すると、そのリクエストはベクトルにエンベディングされます。その後、データベースはベクトルインデックスを使用して最も類似したチャンクを検索して返します。\n\n各ステップには、RAG アプリケーションの品質に影響を与えるエンジニアリング上の決定が含まれます。たとえば、ステップ3では、適切なチャンクサイズを選択することでLLMがコンテキスト情報を含んだ具体的な情報を受け取れるようになり、ステップ4では、適切なエンベディングモデルを選択することで検索時に返されるチャンクの正確性が決まります。\n\nDatabricks ベクトル検索 \n類似性の計算は、多くの場合計算コストが高くなりますが、Databricks ベクトル検索のようなベクトルインデックスは、エンベディングを効率的に整理することでこれを最適化します。ベクトル検索では、各エンベディングをユーザーのクエリーと個別に比較することなく、最も関連性の高い結果を迅速にランク付けします。\nベクトル検索は、Delta テーブルに追加された新しいエンベディングを自動的に同期し、ベクトル検索インデックスを更新します。\n\n\n\nRAG エージェントとは \n検索拡張生成(RAG)エージェントは、外部データ検索を統合することで大規模言語モデル(LLM)の能力を強化する RAG アプリケーションの重要な部分です。RAG エージェントはユーザーのクエリーを処理して、ベクトルデータベースから関連データを取得し、そのデータを LLM に渡して回答を生成します。\nLangChain や Pyfunc などのツールは、入力と出力を接続することでこれらのステップを結びつけます。\n以下の図は、チャットボット用の RAG エージェントと、各エージェントを構築するために使用される Databricks の機能を示しています。\n\n\n\n\nクエリーの前処理 - ユーザーがクエリーを送信すると、ベクトルデータベースに対するクエリーとして適した形に前処理されます。これには、リクエストをテンプレートに当てはめたり、キーワードを抽出したりすることが含まれる場合があります。\nクエリーのベクトル化 - モデルサービングを使用して、データパイプラインでチャンクのエンベディングに使用したものと同じエンベディングモデルを使用してリクエストをエンベディングします。これらのエンベディングにより、リクエストと前処理されたチャンク間の意味的類似性の比較が可能になります。\n検索フェーズ - リトリーバー(関連情報の取得を担当するアプリケーション)は、ベクトル化されたクエリーを受け取り、ベクトル検索を使用してベクトル類似性検索を実行します。最も関連性の高いデータチャンクがクエリーとの類似性に基づいてランク付けされ、取得されます。\nプロンプト拡張 - リトリーバーは、取得されたデータチャンクを元のクエリーと組み合わせて、LLM に追加のコンテキストを提供します。プロンプトは、LLM がクエリーのコンテキストを理解できるように入念に構造化されます。多くの場合、LLM には回答をフォーマットするためのテンプレートがあります。プロンプトを調整するこのプロセスは、プロンプトエンジニアリングとして知られています。\nLLM 生成フェーズ - LLM は、検索結果によって強化された拡張クエリーを使用して回答を生成します。LLM はカスタムモデルの場合も基盤モデルの場合もあります。\n後処理 - 追加のビジネスロジックを適用したり、引用を追加したり、あるいは事前に定義されたルールや制約に基づいて生成テキストを改良したりするため、LLM の回答が処理される場合があります。\n\nこのプロセス全体を通じて、企業ポリシーへの準拠を確保するためにさまざまなガードレールが適用される場合があります。これには、適切なリクエストのフィルタリング、データソースにアクセスする前のユーザー権限の確認、生成された回答のコンテンツモデレーションなどが含まれる可能性があります。\n\n\n本番運用レベルのRAGエージェント開発 \n以下の特性を活用することで、エージェント開発を迅速に反復させることができます。\n任意のライブラリと MLflow を使用してエージェントを作成し、ログに記録します。エージェントをエクスペリメントにパラメータ化し、エージェント開発を迅速に反復します。\nトークン ストリーミングとリクエスト/レスポンス ロギングのネイティブ サポートに加えて、エージェントに対するユーザー フィードバックを得るための組み込みレビュー アプリを使用して、エージェントを本番運用にデプロイします。\nエージェントトレースを使用すると、エージェントコード全体のトレースの記録、分析、比較が可能になるため、エージェントがリクエストにどのように対応しているかをデバッグして理解できます。\n\n\n評価とモニタリング\n評価とモニタリングは、RAG アプリケーションが品質、コスト、レイテンシーの要件を満たしているかどうかを判断するのに役立ちます。評価は開発中に行われ、モニタリングはアプリケーションが本番環境にデプロイされた後に行われます。\n非構造化データを使用した RAG には、品質に影響を与える多くの要素があります。たとえば、データフォーマットの変更は、取得されるチャンクや、LLM が関連する回答を生成する能力に影響を与える可能性があります。そのため、アプリケーション全体に加えて個々の要素を評価することが重要です。\n\n詳細については、「Mosaic AI エージェント評価とは」を参照してください。\n\n利用可能なリージョン \nエージェントフレームワークの利用可能なリージョンについては、「利用可能なリージョンが限定されている機能」を参照してください\n\n\n\n\n\n\n\n\n\n\n\n\n\n © Databricks 2025 です。 全著作権所有。 Apache、Apache Spark、Spark、および Spark のロゴは、 Apache Software Foundation の商標です。\n \n\nフィードバックをお送りください | プライバシーに関する通知 | 利用規約 | 現代奴隷制に関する声明 | カリフォルニア州のプライバシー | お客様のプライバシーに関する選択 \n\n\n\n\n\n\n\n\n\n'
チェーンを構築します。LangChain Expression Language(LCEL)を使ってます。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.runnables import RunnableLambda
# WebBaseLoaderをRunnable Lambdaでラッピングしてチェーンに組み込めるようにする
# https://github.com/langchain-ai/langserve/discussions/457
def get_text_to_analyze(url: str) -> str:
loader = WebBaseLoader(url)
documents = loader.load()
as_text = documents[0].page_content
return as_text
# LLM
llm = ChatOpenAI(model="gpt-4o-mini")
# 出力パーサー
output_parser = StrOutputParser()
# プロンプトの定義
prompt = ChatPromptTemplate.from_messages(
[("system", "以下の簡潔な要約を記述してください:\\n\\n{context}")]
)
# チェーンのインスタンスを作成
chain = RunnableLambda(get_text_to_analyze) | prompt | llm | output_parser
チェーンの動作確認をします。引数はURLとなります。
# チェーンの呼び出し
result = chain.invoke("https://docs.databricks.com/ja/generative-ai/retrieval-augmented-generation.html")
print(result)
要約が帰ってきました。
DatabricksのRAG(Retrieval Augmented Generation)は、開発者が本番運用品質のAIエージェントを構築、デプロイ、評価するためのツール群です。この手法は、大規模言語モデル(LLM)を外部の知識で強化し、独自の情報や最新のデータソースを活用することで、回答の精度を向上させます。RAGアプリケーションは、ユーザーのリクエストを処理し、関連データを検索し、それを基にLLMが回答を生成する仕組みで構成されています。また、非構造化データと構造化データを利用し、データの前処理やインデックス化を行い、高速かつ正確な検索を実現します。エージェントは、評価とモニタリングを通じて品質を確保し、ユーザーのフィードバックを取り入れながら改善されます。
MLflowのトレースでチェーンの挙動を確認できます。
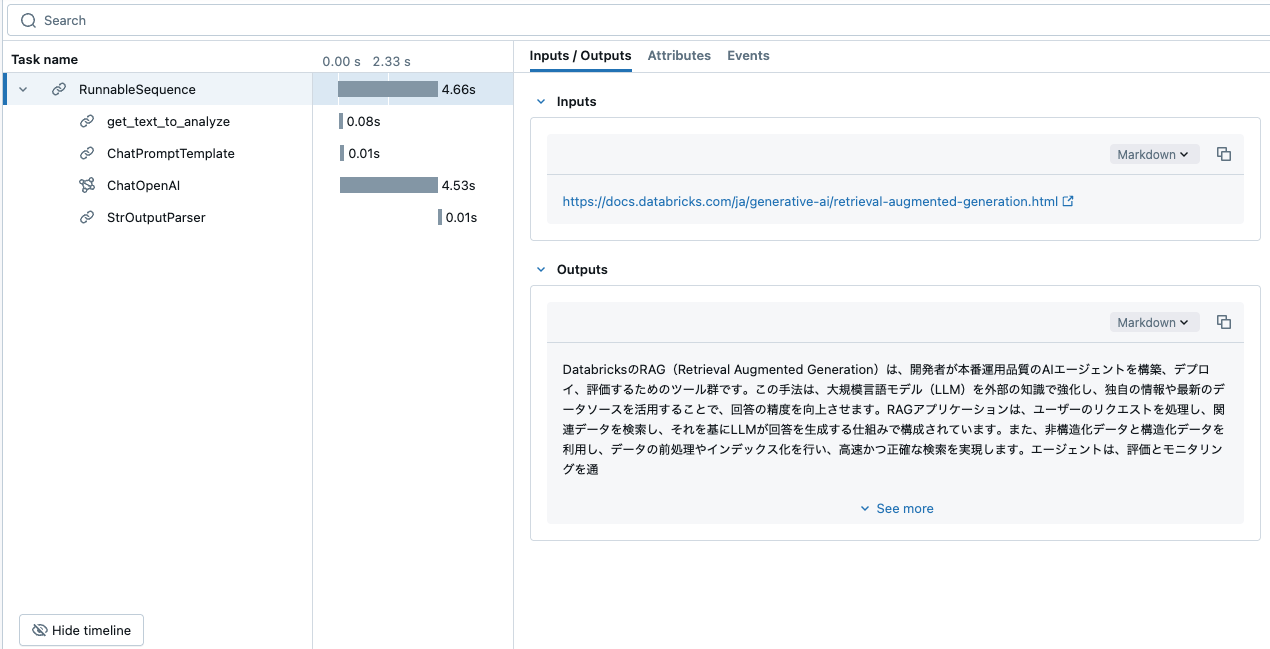
モデルサービングエンドポイントにデプロイするために、チェーンをモデルとしてUnity Catalogに登録します。
import mlflow
from mlflow.models import infer_signature
# UCにモデルを登録
mlflow.set_registry_uri("databricks-uc")
signature = infer_signature(
model_input={
"url": "https://docs.databricks.com/ja/generative-ai/retrieval-augmented-generation.html"
},
model_output="ここに要約結果を出力します",
)
signature
inputs:
['url': string (required)]
outputs:
[string (required)]
params:
None
# 要約チェーンの記録
with mlflow.start_run() as mlflow_run:
logged_model = mlflow.langchain.log_model(
chain,
"doc_summarization",
signature=signature,
input_example=["https://docs.databricks.com/ja/generative-ai/retrieval-augmented-generation.html"],
registered_model_name="users.takaaki_yayoi.summarizer"
)
カタログエクスプローラからもモデル(チェーン)を確認できます。
REST API経由でこのモデルにアクセスできるように、モデルサービングエンドポイントにデプロイします。
サービングエンドポイントの名称、デプロイするモデル、エンドポイントのスペックを指定します。
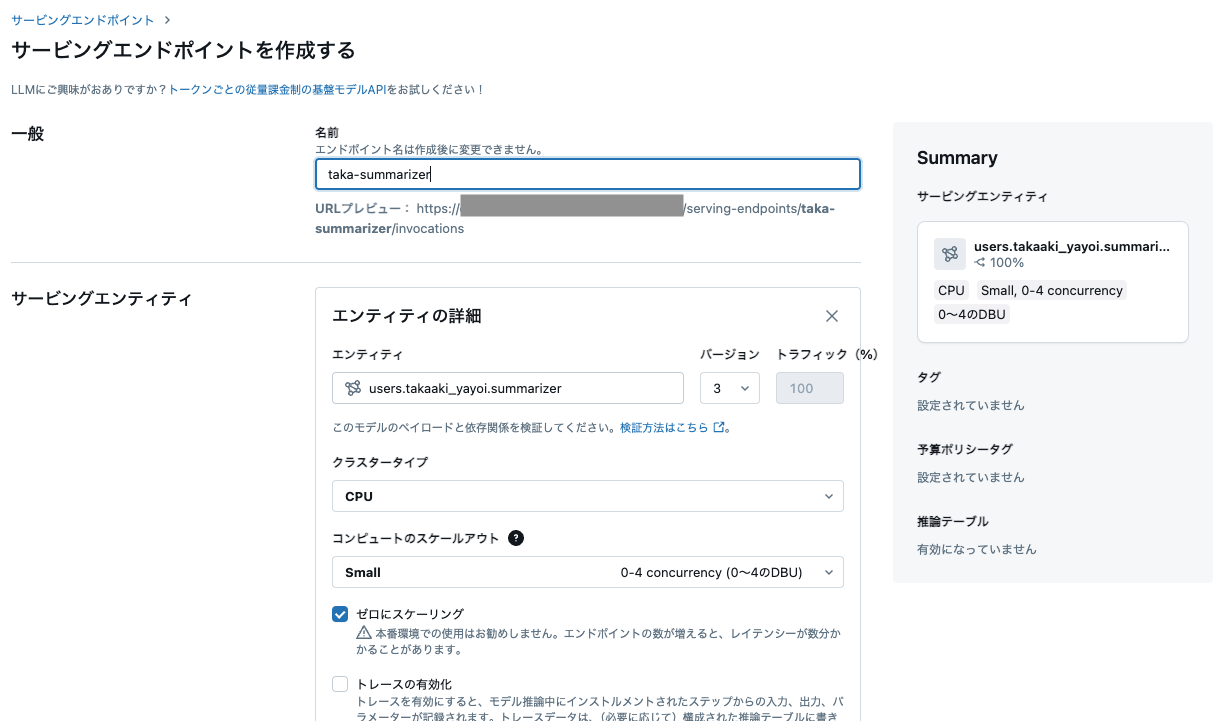
ここで重要なのは、詳細設定の環境変数です。ここにOpenAIのAPIキーを指定しないと、デプロイされたチェーンが動作しません。OPENAI_API_KEYとして上述のシークレットを参照するように{{secrets/demo-token-takaaki.yayoi/openai_api_key}}を指定します。
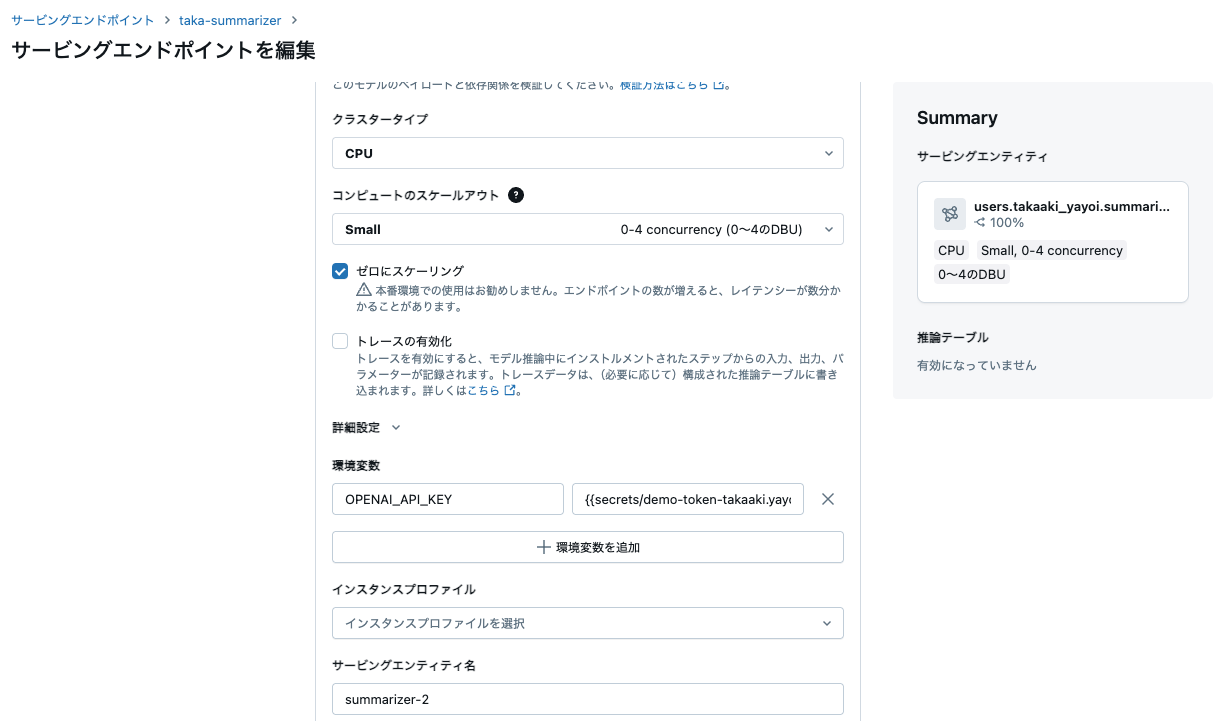
十数分待つと、モデルサービングエンドポイントが準備完了になるはずです。
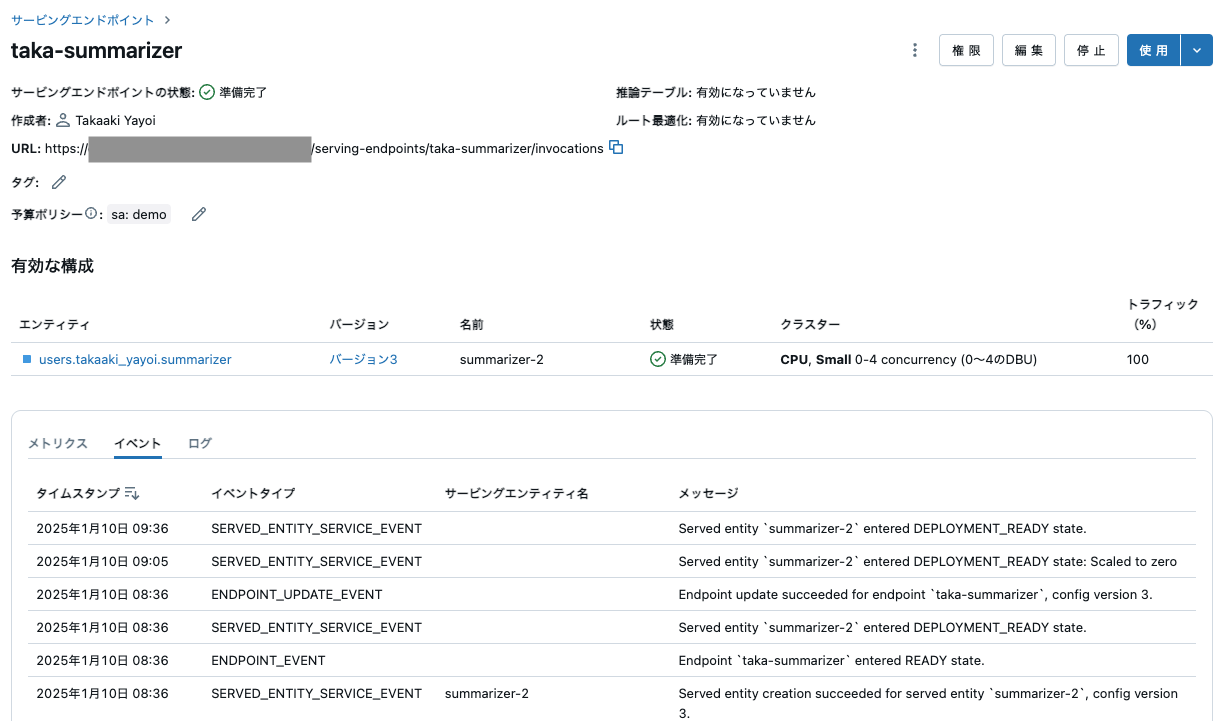
ここで表示されているURLがエンドポイントとなります。エンドポイントにアクセスする際には認証が必要となります。ここでは、開発目的のためパーソナルアクセストークンを使用します。認証の詳細については、カスタムモデルのサービングエンドポイントをクエリするをご覧ください。
この画面でもモデルサービングエンドポイントの動作確認が可能です。画面右上の使用ボタンをクリックすると、エンドポイントに問い合わせできるダイアログが表示されます。
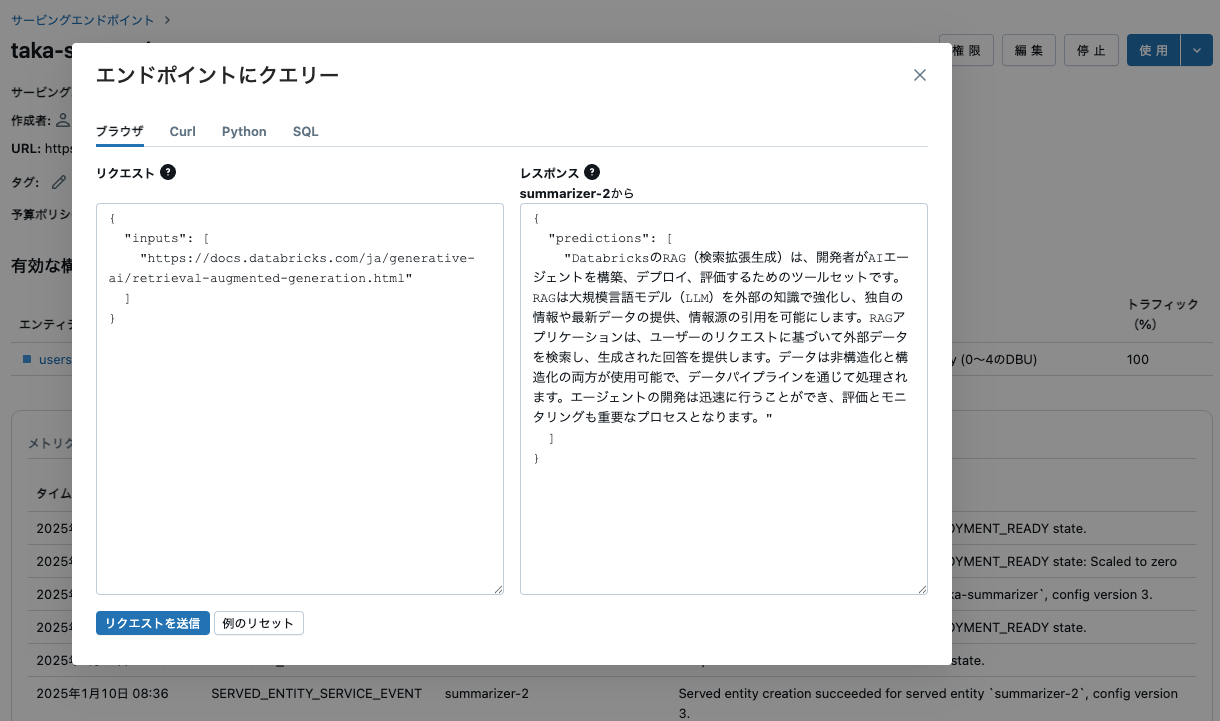
これでバックエンドの準備ができました。
フロントエンド
ここからは、ローカルマシンでの作業です。主にこちらの記事を参考にさせていただきながら開発しました。
{
"name": "Web Page Summarizer Extensions",
"description": "Base Level Extension",
"version": "1.0",
"manifest_version": 3,
"permissions": ["tabs","activeTab"],
"host_permissions": [
"https://*.databricks.com/"
],
"action": {
"default_popup": "hello.html",
"default_icon": "hello_extensions.png"
}
}
<!DOCTYPE html>
<html>
<head>
<title>Web Page Summarizer Extensions</title>
<script src="popup.js"></script>
<style type="text/css">
body {
min-width:300px;
font-size: 16px;
}
</style>
</head>
<body>
<p id="summaryText">Summarizing...</p>
</body>
</html>
document.addEventListener("DOMContentLoaded", async function () {
try {
const tabs = await chrome.tabs.query({ active: true, currentWindow: true });
if (tabs.length === 0 || !tabs[0].url) {
alert("No active tab or URL is undefined.");
return;
}
const url = tabs[0].url;
if (!url.includes("databricks")) {
alert("Not a Databricks page.");
return;
}
let pageId;
try {
pageId = url.split("/").pop().split("-").pop();
} catch (error) {
alert("Error: " + error.message);
throw error;
}
const response = await fetch("<モデルサービングエンドポイントのURL>", {
method: "POST",
headers: {
"Content-Type": "application/json",
"Authorization": "Bearer <Databricksパーソナルアクセストークン>",
},
body: JSON.stringify({ "inputs": [ url ] }),
});
if (!response.ok) {
throw new Error("Network response was not ok");
}
const json = await response.json();
summary = json["predictions"][0]
document.getElementById("summaryText").innerHTML = summary;
} catch (error) {
console.log(error);
if (error.message.includes("Failed to fetch")) {
alert("Error: Connection refused. Please ensure the server is running.");
} else if (error instanceof TypeError) {
alert("Error: TypeError: Failed to fetch");
} else {
alert("Error: " + error.message);
}
}
});
他に以下の記事も参考にさせていただきました。十数年ぶりにjavascript触りました。
- javascript - How to modify the content of popup page in chrome extension? - Stack Overflow
- Chrome 拡張機能の CORS エラーを回避(Manifest V3) #JavaScript - Qiita
動作確認
拡張をChromeにインストールします。
このように動作します。

今後の展望
私はLLMバッチ推論も好きですが、今回体験してみて改めて感じましたが、アプリケーションと連携させることでも色々な価値を見出せそうです。
- Webブラウジングという文脈から離脱することなしに生成AIを活用すると、得られる情報の有益性が高まると思います。今回はシンプルな要約のチェーンですが、ここからさらに高度なチェーンにすることは可能だと思います。関連ドキュメントをベクトルDBから引っ張ってくるとか、翻訳のプロンプトを組み込むとか。
- あとは、フロントエンド側のユーザビリティを高める方向性もあると思います。