Manufacturing Insights: Calculating Streaming Integrals on Low-Latency Sensor Data | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
データエンジニアは、複雑かつノイジーなデータから洞察を導き足すために数学や統計学を頼りにしています。最も重要な領域は、エリアアンダーカーブの計算としてよく説明される積分を提供する微積分学です。これは、大量のデータが有用な計測結果を提供するための割合を積分から導き出すことができるエンジニアにとって有用です。例えば:
- ある時刻でのセンサーの値を積分することで時間重み付きの平均を計算することができます。
- 自動車の速度の積分は移動距離を計算するために使用できます。
- ネットワーク転送速度の積分から転送データボリューム結果を得ることができます。
もちろん、学生はあるタイミングで積分の計算方法を学び、静的データのバッチに対する計算自身はシンプルなものです。しかし、機器のパフォーマンスの閾値に基づくアラートの設定や、物流ユースケースにおける異常検知のように、ビジネス価値を実現するために積分を低レーテンシーかつインクリメンタルに計算する必要がある一般的なエンジニアリングパターンが存在します。
| ポイントインタイムの測定 | 積分によって得られる値 | 低レーテンシーのビジネスユースケースと価値 |
|---|---|---|
| 風速 | 時間重み付きの平均 | コスト回避のためにオペレーションの閾値を超えたセンシティブな機材をシャットダウン |
| 速度 | 距離 | 顧客にアラートするための物流の遅延を予測 |
| 転送速度 | 合計転送ボリューム | ネットワーク帯域問題や不正な活動を検知 |
積分の計算は、現実世界のセンサーデータを取り扱っているモダンなデータエンジニアのツールセットにおいて重要なツールとなっています。ここでの例は部分的なもので、以下で説明するテクニックは多くのデータエンジニアリングパイプラインに組み込むことができますが、この記事の残りでは時間重み付き平均を計算するために現実世界のセンサーデータに対するストリーミング積分の計算にフォーカスします。
大量のセンサー
センサーデータを取り扱う際の一般的なパターンは、実際には膨大な量のデータになるというものです:60ヘルツで送信される風力タービンの温度センサーは一日あたり50億以上のデータポイントを生成します。タービンに設置された100個センサーで掛け算すると、単体の装置は一日あたり数GBのデータを生成することになります。多くの物理的なプロセスにおいては、それぞれの読み取り値は以前の読み取り値とほとんど変わらないということも考慮します。
これを格納すること自体は安価ですが、転送はそうとは限らず、現在の多くのIoTプロダクションシステムはこの膨大なデータを蒸留する手段を提供しています。多くのセンサーやそれらの中間システムは、あるバイナリ値が別の値に変化したり、以前の値より5%変動したりして何か「興味深い」ことが起きた際にのみ読み取り値を送信するように設定されています。このため、データエンジニアにとっては、新たな読み取り値が到達しないこと自体が重要である場合(システムでの変化がない)もあり、現地のネットワーク障害によってデータ到着が遅延している場合もあります。
装置の障害を分析、回避することに責任を持つサービスエンジニアのチームにとっては、タイムリーな洞察を導き出す能力は、大量のセンサーデータを利用可能な分析テーブルに変換するデータエンジニアに依存することになります。ここでは、列数が少なく追加のみのセンサー読み取り値のストリームを、それぞれの場所/センサーのペアに対する10分間隔の値の時間重み付き平均に変換することにフォーカスします。
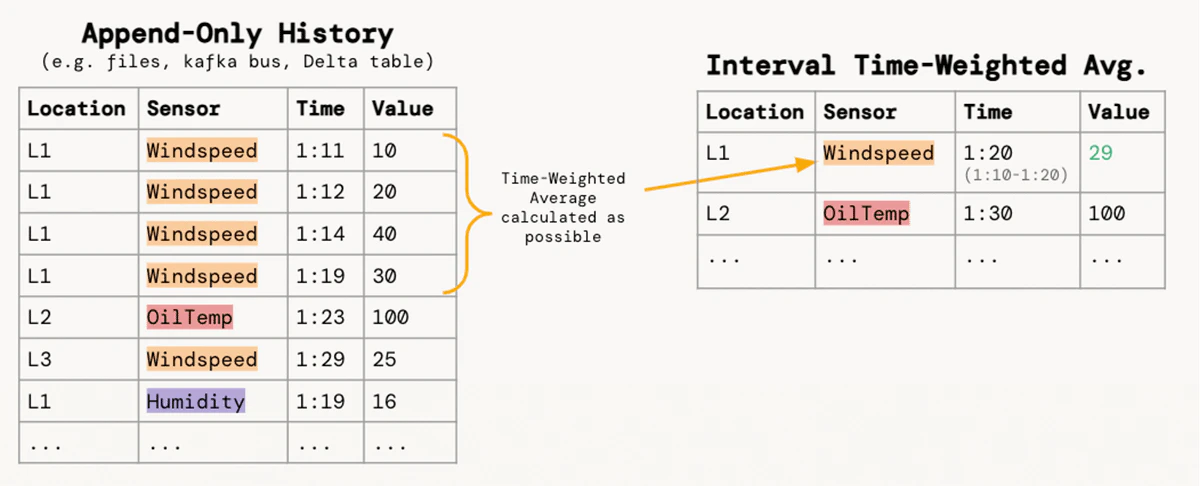
余談:積分のリフレッシャー
簡単に言えば、積分は曲線の下の領域です。いかなる曲線の積分に対する数式を近似し、記号的に積分を計算するための堅牢な数学的テクニックが存在していますが、リアルタイムのストリーミングデータの目的においては、時間経過とともにデータが到着するたびに効率的に計算を行うRiemann sumsを用いた数値的近似手法を活用します。
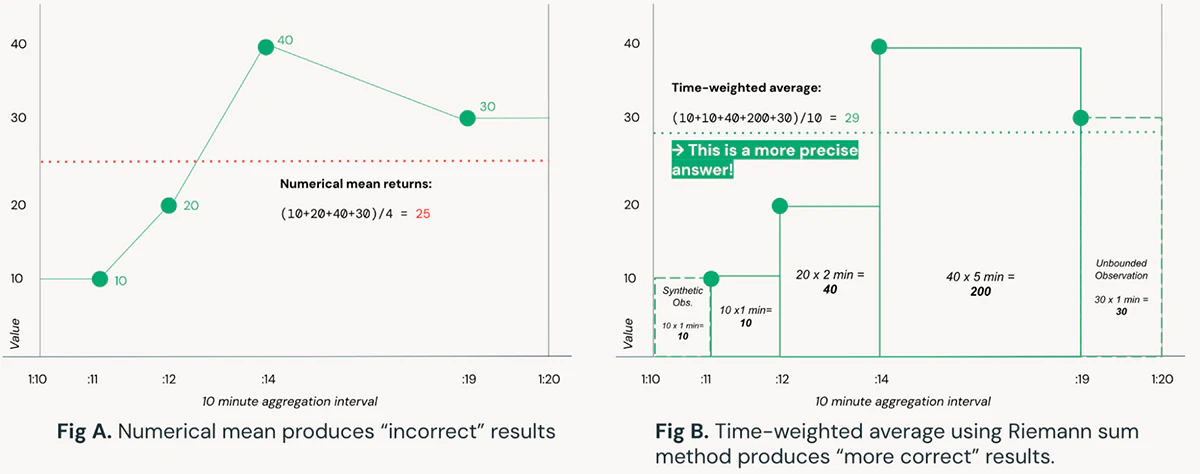
Figure Aでは時間間隔に対するセンサーデータの値の平均を計算するためにシンプルな数値平均を使用しています。逆にFigure Bではより正確な値をもたらす 時間重み付き平均(time-weighted averages) を計算するためにRiemann sumアプローチを使用しています。長方形ではなく台形を用いて(Trapezoidal rule)拡張することもできます。Figure Aの素朴な手法によって得られた結果はFigure Bの手法よりも10%以上異なることを考慮すると、風力タービンのような複雑なシステムにおいては、安定状態のオペレーションと装置の障害の違いになってしまうかもしれません。
ソリューションの概要
アメリカの大規模ユーティリティ企業においては、予兆保全や他のプロプライエタリユースケースのために大ボリュームのタービンデータをアクション可能な洞察に変換するためのエンドツーエンドのソリューションの一部としてこのパターンが実装されました。以下の図では、数百のマシンから取り込まれるの生のタービンデータ、クラウドストレージ経由の取り込み、Delta Live Tablesによってオーケストレートされた高パフォーマンスストリーミングパイプラインからユーザーが利用するテーブルからビューに至る変換処理を説明しています。
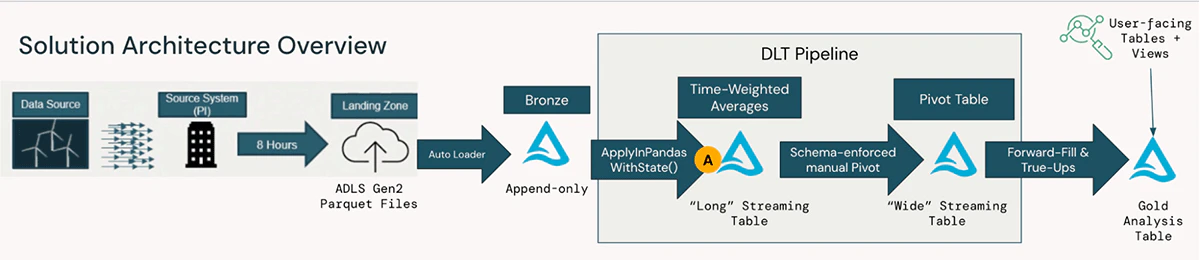
コードサンプル(delta-live-tables-notebooks githubをご覧ください)では、上でstep Aとラベルが付いている変換処理、特に時間重み付き平均のステートフルな計算処理のためのApplyInPandasWithState()にフォーカスしています。Pi HistoriansのようなIoTデータを取り扱うその他のソフトウェアツールを含むソリューションの残りの部分は、オープンソースの標準やDatabricksデータインテリジェンスプラットフォームの柔軟性によってシンプルに実装することができます。
積分のステートフル処理
これで、上述の積分のリフレッシャーセクションのFigure Bのシンプルなサンプルを実行することができます:タービンセンサーからクイックにデータを処理するために、このソリューションはストリームの一部としてデータが到着するものと考えなくてはなりません。この例では、それぞれのタービン+センサーの組み合わせに対して10分のウィンドウで集計したいものとします。データは連続的に到着し、パイプラインはデータが利用可能になったらマイクロバッチとして処理を行うので、時間間隔が終了したとみなせる時点まで、それぞれの集計ウィンドウの状態を追跡しなくてはなりません(構造化ストリーミングのウォーターマークで制御されます)。
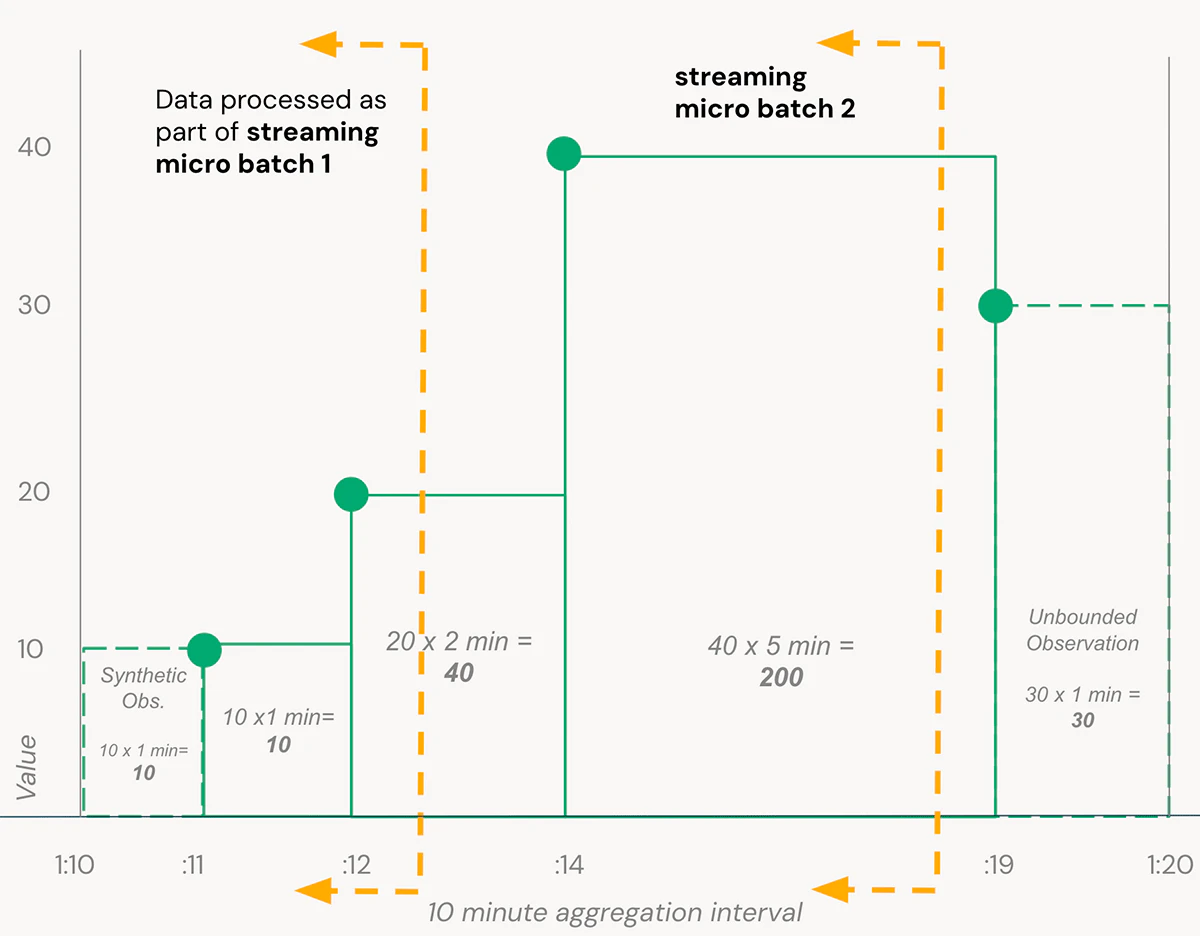
これをDatabricksの宣言型ETLフレームワークであるDelta Live Tables(DLT)で実装することで、ストリームのチェックポイントや計算の最適化のようなオペレーションの問題ではなく変換ロジックにフォーカスできるようになります。完全なコードサンプルについてはexample repoをご覧いただきたいのですが、ここではDLTパイプラインでステートフルな時間重み付き平均を効率的に計算するための、SparkのApplyInPandasWithState()関数の使い方を説明します:
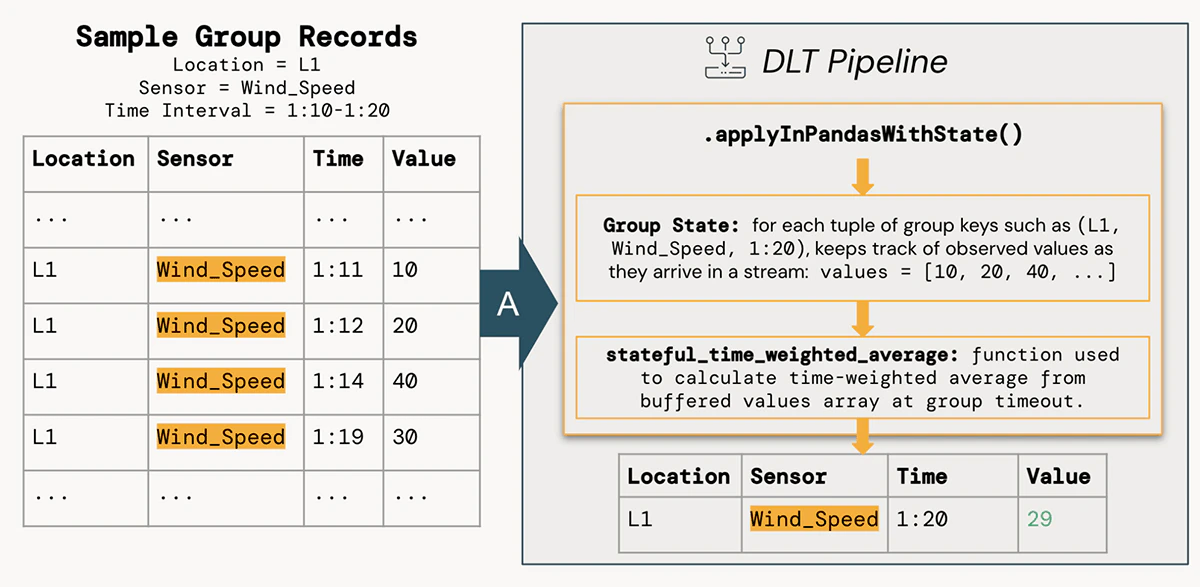
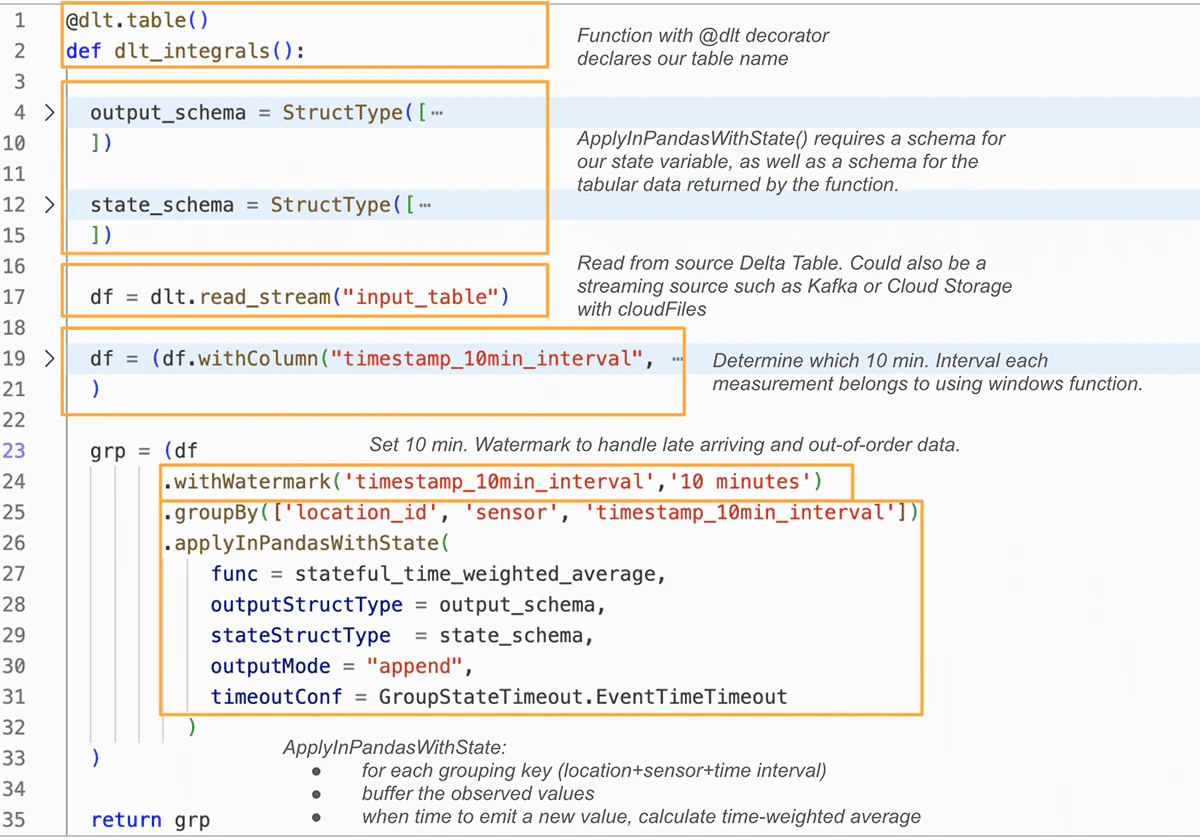
上でgroupBy().applyInPandasWithState()とパイプランを作成する際、時間重み付き平均を計算するためにstateful_time_weighted_averageというシンプルなPandasの関数を使用しています。この関数は、当該ストリームが十分に最新のタイムスタンプ値(ウォーターマークで期間を制御します)を観測するようになりグループが「クローズされる」まで、それぞれの状態グループの観測値を効率的に「バッファ」します。これらのバッファされた値は、Rieman sumを計算するためのシンプルなPython関数に引き渡されます。
このアプローチのメリットは、単体のPandasデータフレームに対して操作を行う堅牢かつテスト可能な関数を記述できるだけでなく、数千の状態グループを同時にSparkクラスターのすべてのワーカーで並列に計算することができる能力です。状態を追跡し、それぞれの場所+センサー+時間間隔のグループの行をいつ排出するのかを決定する能力は、設定timeoutConfと、関数内のstate.hasTimedOutメソッド使用によってハンドリングされます。
結果およびアプリケーション
この記事の関連コードでは、サンプルデータを用いたDelta Live Tablesパイプラインでこのロジックのセットアップをウォークスルーしており、いかなるDatabricksワークスペースで実行可能です。
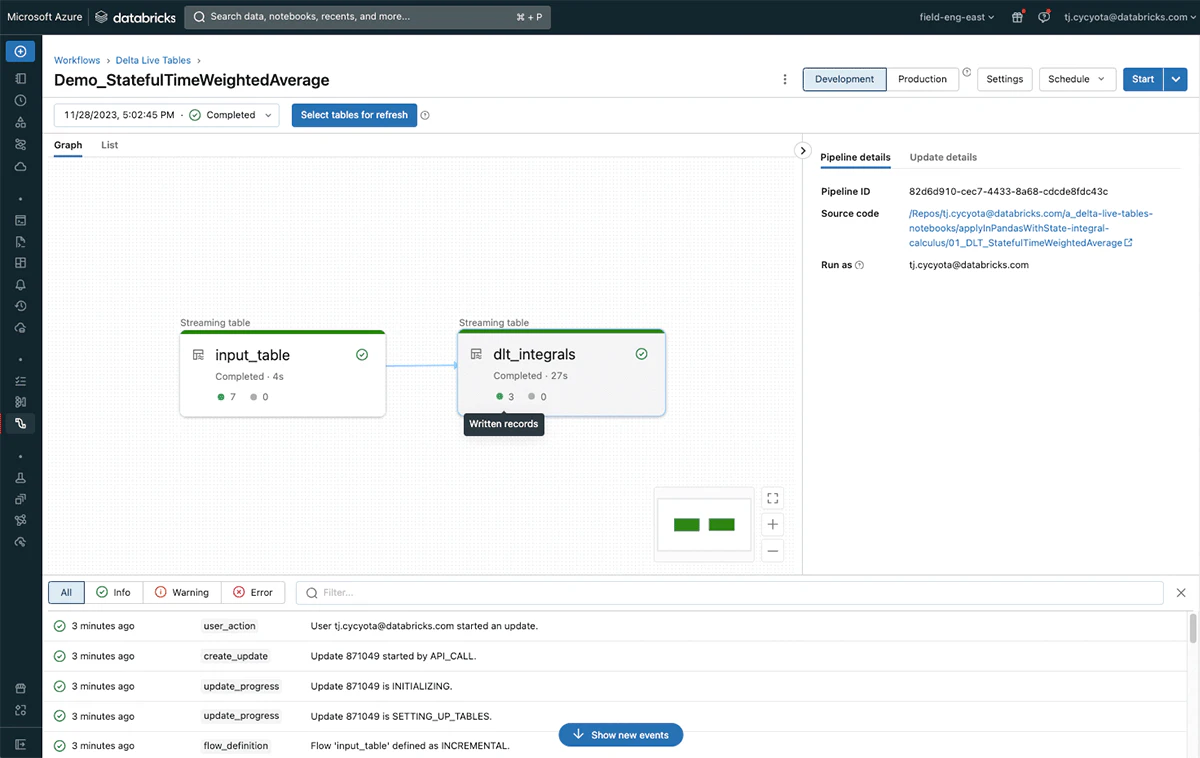
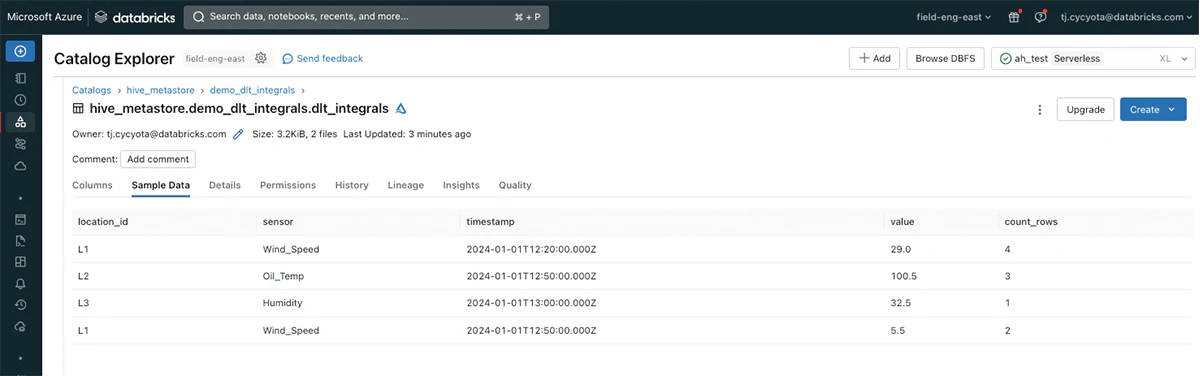
この結果は、数多くのIoTユースケースにおける膨大な量のストリーミングデータに対する時間重み付き平均ののような積分ベースのメトリクスを効率的かつインクリメンタルに計算できることを示しています。
このソリューションを実装したアメリカのユーティリティ企業でのインパクトは計り知れないものでした。数千の風力タービンに対して統一された集約アプローチによって、メンテナンス、パフォーマンス、その他のエンジニアリング部門のデータ活用者は、装置の信頼性を維持するために複雑なトレンドを分析し、プロアクティブなアクションをとることができるようになりました。また、この統合されたデータは、障害予測に関する将来的な機械学習ユースケースの基盤として機能し、さらなるニアリアルタイム分析のための大ボリュームの振動データと組み合わせることができます。
積分のようなステートフルストリーミング集計は、モダンなデータエンジニアのツールセットの単なる一例にすぎず、Databricksを用いることで、ストリーミングデータを必要とするビジネスクリティカルアプリケーションにこれらを適用することはシンプルなものとなっています。