Accelerating Your Deep Learning with PyTorch Lightning on Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
PyTorch Lightningは、お手元のPyTorchコードをシンプルにし、ディぷラーニングのワークロードをブートスラップするための優れた手段となります。しかし、皆様のレイクハウスにあるすべてのデータを用いてタイムリーな結果を生み出すためにワークロードをスケールさせようとすると、PyTorch Lightningが持っている課題に直面することになります。本書では、Horovodを用いて、どのようにこれを達成するのか、コードをどのように効率的にスケールさせるのかを説明します。
イントロダクション
企業は自分達の高度な機械学習アプリケーションを加速させるために、徐々にディープラーニングに移行しています。例えば、現在ではコンピュータービジョン技術が、製造業における不良品検知を改善するために活用されています。チャットボットを用いてビジネルプロセスを拡張するために自然言語処理が用いられ、顧客に対する成果を改善するためにニューラルネットワークベースのレコメンデーションシステムが用いられています。
しかし、適切に最適化されたコードであっても、ディープラーニングモデルのトレーニングは遅いプロセスとなり、データサイエンスチームがクイックな実験の繰り返しを通じて、成果を提供する能力を制限してしまっています。このため、これをスケールアップさせるために、どのように計算能力を組み合わせるのがベストであるのかを知ることが重要となります。
本書では、最初にコードの再利用を最大化するためにお使いのコードベースをどのように構造化するのかを説明し、小規模な単一ノードインスタンスから、どのようにして完全なGPUクラスターにスケールさせるのかを説明します。また、完全なる実験トラッキングとモデルロギングを提供するために、すべてをMLflowとインテグレーションします。
Part 1 - データのロードおよびPyTorch Lightningの導入
ターゲットとなるアーキテクチャからスタートしましょう。
クラスターのセットアップ
ディープラーニングをスケールさせる際、高価なGPUリソースを効率的に活用できるように、実験を小規模なものからスタートし、徐々にスケールアップすることが重要です。コードの複雑性を削減するために、複数のノードにスケールさせる前に、単一ノードの複数のGPUで実行されるようにコードをスケールアップします。
Databricksでは、この有用なパターンをサポートするためのシングルノードクラスターをサポートしています。Azure Single Node Clusters、AWS Single Node Clusters、GCP Single Node Clustersをご覧ください。インスタンスの選択に関しては、Nvidia T4 GPUがスタートするのに最適なコスト効率の高いインスタンスタイプを提供しています。AWSではG4インスタンスを利用することもできます。AzureではNCasT4_v3インスタンス、GCPではA2インスタンスを利用することができます。
ノートブックで説明している手順を進めるには、少なくとも64GBのRAMが非有用となります。モデリングのプロセスではメモリーを大量に必要とし、小規模なインスタンスでは以下のようなRAM不足のエラーになる場合があります。
Fatal error: The Python kernel is unresponsive.
ここで使用するコードは、Databricks機械学習ランタイム10.4LTSと11.1MLで構築され、テストされました。DBR 10.4 ML LTSではpytorch-lightning 1.6.5までがサポートされています。DBR 11.1 MLではpytorch-lightning 1.7.2でテストしました。我々はライブラリをワークスペースレベルライブラリとしてインストールしました。ドライバーノード上のアクティブなノートブックにのみライブラリをインストールする%pipと異なり、ワークスペースライブラリは後で行う分散トレーニングで必要となるすべてのノードにライブラリをインストールします。
DBR 10.4 LTS MLの設定
DBR 11.1 MLの設定

図1. ライブラリの設定
ターゲットアーキテクチャ

図2. キーとなるコンポーネント
本書のゴールは、上のように構造化されたコードベースを構築することです。オープンソースのLinux FoundationプロジェクトであるDelta Lakeを用いてデータを格納します。Delta Lakeは内部で生のデータをParquetフォーマットで格納します。Petastormがデータロードの役割を担い、レイクハウスとディープラーニングモデルの間のインタフェースとなります。MLflowは、エクスペリメントトラッキングツールを提供し、モデルレジストリにモデルを保存できるようになります。
このセットアップによって、不要なデータ複製によるコストや、トレーニングするモデルの管理のコストを回避することができます。
Part 2 - サンプルユースケースおよびライブラリの概要
サンプルユースケース
このサンプルユースケースでは、tensorflow flowersデータセットを使用します。このデータセットは、花はどのクラスなのかを識別しようとする分類タイプの問題で使用されます。

図3. Flowersデータセット
Petastormを用いてデータレイクをディープラーニングに活用する
歴史的に、レイクハウスやデータウェアハウスのようなデータ管理システムは、機械学習フレームワークとインテグレーションするというよりは、並列に開発されてきました。このため、PyTorchデータローダーモジュールでは、簡単にParquetをサポートすることができません。また、これらはhiveメタストアのようなレイクハウスのメタデータ構造とインテグレーションされていません。
Petastormプロジェクトは、レイクハウスのテーブルとPyTorchの間のインタフェースを提供します。トレーニングノード間のデータのシャーディングをハンドリングし、キャッシングレイヤーを提供します。PetastormはDatabricks機械学習ランタイムにプレパッケージされています。
最初にデータセットやどのように操作するのかに慣れ親しんでみましょう。
peta_conv_df = make_spark_converter(preprocessed_df)
spark_converterオブジェクトを作成することで、以下のようにPyTorch Dataloaderに変換することができます。
with peta_conv_df.make_torch_dataloader(transform_spec=transform_func) as converted_dataset
これによって、通常pytorchコードで使うのと同じように使用できるconverted_datasetのDataLoaderを提供します。
Exploring the flowers datasetというノートブックを開いて試してみましょう。標準的なMLランタイムのクラスターで十分であり、GPUクラスターで実行する必要はありません。
モデルをシンプルにし構造化する - PyTorch Lightningにようこそ
デフォルトでは、PyTorchコードは膨大なものとなる場合があります。モデルの定義、トレーニングループ、データローダーのセットアップが含まれます。デフォルトでは、このコードはすべて結び付けられており、迅速な実験においてはキーとなるデータセットやモデルを入れ替えることが困難となります。
PyTorch Lightningは、実験モデルやメインのトレーニングループのセットアップに必要な定型コードを大幅に削減することでシンプルにします。可読性とメンテナンス性を高めるための、PyTorchコードを構造化するためのアプローチとなります。
我々のプロジェクトにおいては、コードを以下のモジュールにブレークダウンします。
- PyTorchモデル
- データローダーとトランスフォーメーション
- メインのトレーニングループ
これによって、コードがよりポータブルになり、整理することができるようになります。これらのすべてのクラスとファンクションは、トレーニングのハイパーパラメーターが定義され、実際にコードを実行するメイン処理実行用のノートブックから%run経由で呼び出されることになります。

図4. コードのレイアウト
モデル定義
このモジュールには、モデルクラスであるLightningModuleの中にモデルのアーキテクチャのコードが含まれています。ここにモデルのアーキテクチャが存在します。リファレンスとして、これがtimmやHuggingFaceのような人気のあるモデルフレームワークを活用するためにアップデートを必要とするモジュールとなります。また、このモジュールにはオプティマイザの定義も含まれます。この場合、SGDを使用しますが、他のタイプのオプティマイザをテストするためにパラメーター化を行うことができます。
DataLoaderクラス
データローダーのコードとモデルのコードが結びつき合っているネイティブのPyTorchと異なり、PyTorch Lightningを用いることで、別のLightningDataModuleクラスに分割することができます。これによって、データセットの管理を容易にし、データセットに対して異なる操作をクイックにテストできるようになります。
Petastormデータローダーを用いたLightningDataModuleを構築する際には、生のSparkデータフレームではなくspark_converterオブジェクトにデータを投入します。Sparkデータフレームは内部のSparkクラスターで管理され最初から分散されておりますが、PyTorchデータローダーにおいては別の手段を用いて後ほど分散します。
メインのトレーニングループ
これがメインのトレーニング関数となります。Trainerクラスにデータを投入する前に、モデルを定義するLightningDataModuleとLightningModuleを受け取ります。ここで、PyTorch Lightningのトレーナーのインスタンスを作成し、必要なすべてのコールバックを定義します。
後ほどこのトレーニングプロセスをスケールアップさせるので、すべての処理ノードでMLflowのロギングのような幾つかのプロセスを実行する必要はありません。このため、ここでは、最初のGPUでのみ実行するように処理を制限します。
if device_id == 0:
# we only need this on node 0
mlflow.pytorch.autolog()
トレーニングの過程でモデルのチェックポイントを作成することは進捗を保存する観点で重要ですが、PyTorch Lightningではデフォルトでチェックポイントの作成を行うのでコードに追加する必要はありません。
ノートブックBuilding the PyTorch Lightning Modulesを試してください。
Part 3 - トレーニングジョブをスケールさせる
単体のGPUによるトレーニングはCPUによるトレーニングよりもはるかに高速ですが、多くの場合十分ではありません。適切なプロダクションのモデルは大規模なものとなり得ますし、これらを適切にトレーニングするために必要となるデータセットも大規模なものとなり得ます。このため、複数のGPUでトレーニングを行えるようにスケールアップする方法を探す必要があります。
ディープラーニングモデルを分散させる主なアプローチは、それぞれのGPUにモデルのコピーを送信し、それぞれの異なるデータのシャードを与えるというデータ並列性を通じて行うというものです。これによって、こちらの記事で議論されているように、トレーニング時間を改善するために、バッチサイズを増やし、高い学習率を活用できるようになります。
GPUに対するトレーニングジョブの分散を支援するために、Horovodを活用することができます。Horovodは別のLinux Foundationプロジェクトであり、複数ノードに対してpytorchのプロセスをマニュアルで起動することに対する代替策を提供します。Databricks MLランタイムにはデフォルトでHorovodRunnerクラスが含まれており、シングルノード、マルチノードのトレーニング両方でスケールさせることができるようになります。
Horovodを活用するためには、新たな「スーパー」トレーニングループを作成する必要があります。
def train_hvd():
hvd.init()
# MLflow setup for the worker processes
mlflow.set_tracking_uri("databricks")
os.environ['DATABRICKS_HOST'] = db_host
os.environ['DATABRICKS_TOKEN'] = db_token
hvd_model = LitClassificationModel(class_count=5, learning_rate=1e-5*hvd.size(), device_id=hvd.rank(), device_count=hvd.size())
hvd_datamodule = FlowersDataModule(train_converter, val_converter, device_id=hvd.rank(), device_count=hvd.size())
# `gpus` parameter here should be 1 because the parallelism is controlled by Horovod
return train(hvd_model, hvd_datamodule, gpus=1, strategy="horovod", device_id=hvd.rank(), device_count=hvd.size())
この関数は、horovodのhvd.init()を起動させ、我々のDataModuleとtrain関数が、適切なノード番号であるhvd.rank()、デバイスの総数であるhvd.size()を用いて起動されることを保証します。horovod の記事で議論されているように、GPUの数を用いて学習率をスケールアップします。
hvd_model = LitClassificationModel(class_count=5, learning_rate=1e-5*hvd.size(), device_id=hvd.rank(), device_count=hvd.size())
そして、Horovodが並列性をハンドリングするので、GPUのカウントが1に設定された通常のトレーニングループを返却します。
Main Execution notebookを試していく中で、単一のGPUから複数のGPUに移行する方法を見ていきます。
Step 1 - 1ノードでスケールさせる
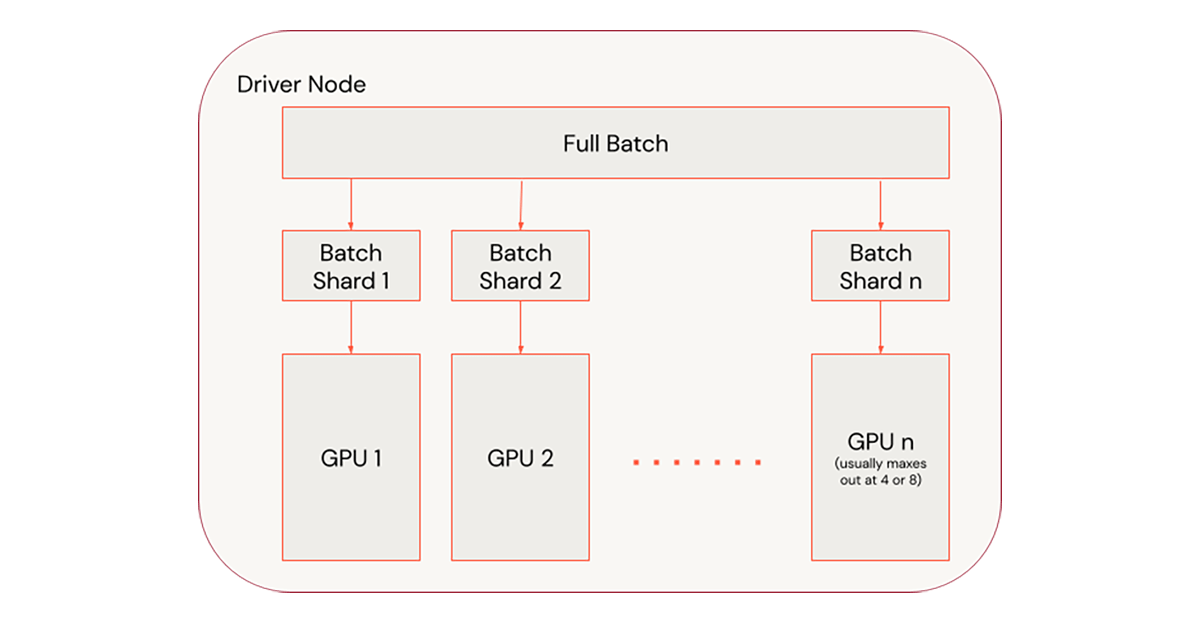
図5. シングルノードにおけるスケーリング
1ノードをスケールさせることが一番簡単な方法となります。また、複数ノードのトレーニングでは必要となるネットワークトラフィックを避けることができるので、非常の高速です。SparkネイティブのMLライブラリと異なり、多くのディープラーニングのトレーニングプロセスは、ノード障害から自動で復旧しません。しかし、PyTorch Lightningはトレーニングのエポックを復旧できるように自動でチェックポイントを作成します。
我々のコードでは、train関数の中でパラメーターdefault_dirをdbfsに指定しています。ここにPyTorch Lightningがチェックポイントを保存します。ckpt_restoreのパスをチェックポイントを指すようにすると、train関数はそこにあるチェックポイントからトレーニングを再開します。
def train(model, dataloader, gpus:int=0,
strategy:str=None, device_id:int=0,
device_count:int=1, logging_level=logging.INFO,
default_dir:str='/dbfs/tmp/trainer_logs',
ckpt_restore:str=None,
mlflow_experiment_id:str=None):
我々のtrain関数を1ノード上の複数のGPUにスケールさせるには、HorovodRunnerを使用します。
from sparkdl import HorovodRunner
hr = HorovodRunner(np=-4, driver_log_verbosity='all')
hvd_model = hr.run(train_hvd)
npを負の値に設定するとシングルノードで動作します。この例では、ドライバーノードの4CPUで実行されます。npを正の値にすると、ワーカーノードにまたがって実行されます。
Step 2 - ノードにまたがってスケールさせる
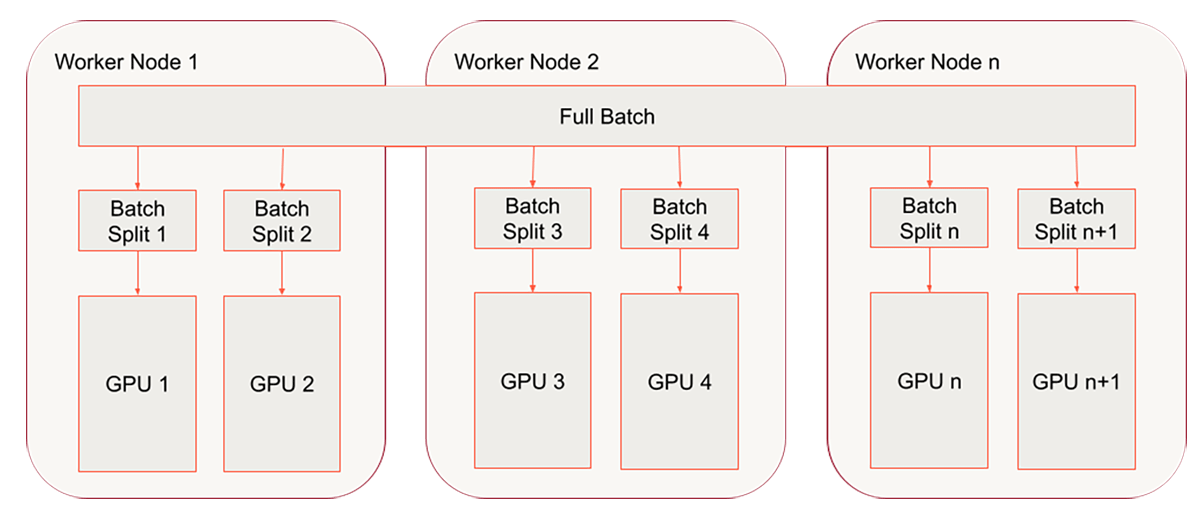
図5. 複数ノードでのスケーリング
我々は既にトレーニング関数をhorovodラッパーでラップしており、シングルノードにおける複数GPUでHorovodRunnerを活用しました。最後のステップは、マルチノード、マルチGPU環境に移行することとなります。ここまででシングルノードクラスターを使っていたのであれば、ここでマルチノードクラスターに切り替えることになります。以降のコードでは、以下の設定のクラスターを使用します。

図6. マルチノードクラスターのセットアップ
Databricksで分散トレーニングを実行する際、現時点ではオートスケーリングがサポートされていないので、事前に固定数のワーカーを設定しておきます。
hr = HorovodRunner(np=8, driver_log_verbosity='all')
hvd_model = hr.run(train_hvd)
分散ディープラーニングのジョブをスケールアップする際に生じる一般的な問題は、すべてのGPUがバッチのスプリットを取得できるようにPetastormのテーブルが適切にパーティショニングされていないということです。複数のGPUを持っているので、少なくとも多くのデータパーティションが作成されるようにする必要があります。
我々のコードでは、num_devices変数とprepare_data関数を用いてGPUの数を設定することでこの問題に対応しています。
flowers_df, train_converter, val_converter = prepare_data(data_dir=Data_Directory, num_devices=NUM_DEVICES)
datamodule = FlowersDataModule(train_converter=train_converter,
val_converter=val_converter)
これは、シンプルに標準的なSparkの再パーティションコマンドを呼び出します。我々はパーティションの数をGPUの数であるnum_devicesの倍数になるように設定しており、データセットがトレーニングプロセスに割り当てたすべてのGPUに対して十分なパーティションを持つようにしています。不十分なパーティションはアイドル状態のGPUの一般的な原因となります。
flowers_dataset = flowers_dataset.repartition(num_devices*2)
分析
ディープニューラルネットワークをトレーニングする際、ネットワークを下学習させないことが重要となります。これに対処する標準的な方法は、Early Stoppingを用いるというものです。このプロセスは、それぞれのエポックにおいてモニタリングするように設定したメトリックに依然として改善が認められるのかをチェックします。この場合はval_lossとなります。
我々の実験においては、min_deltaを0.01に設定しているので、それぞれのエポックで少なくともval_lossに0.01の改善が認められることを期待します。patienceを10に設定しているので、トレーニングを停止する前に、改善が認められないエポックが10発生するまでトレーニングを継続します。我々は最後のパフォーマンスの改善まで持たせるまでこの設定を行なっています。実験を短時間で終わらせられるように、stopping_thresholdを0.55に設定しており、val_lossがこのレベルを下回った場合には、すぐにトレーニングプロセスを停止します。
これらのパラメーターを念頭において、以下でスケーリングの実験結果を見ていきましょう。
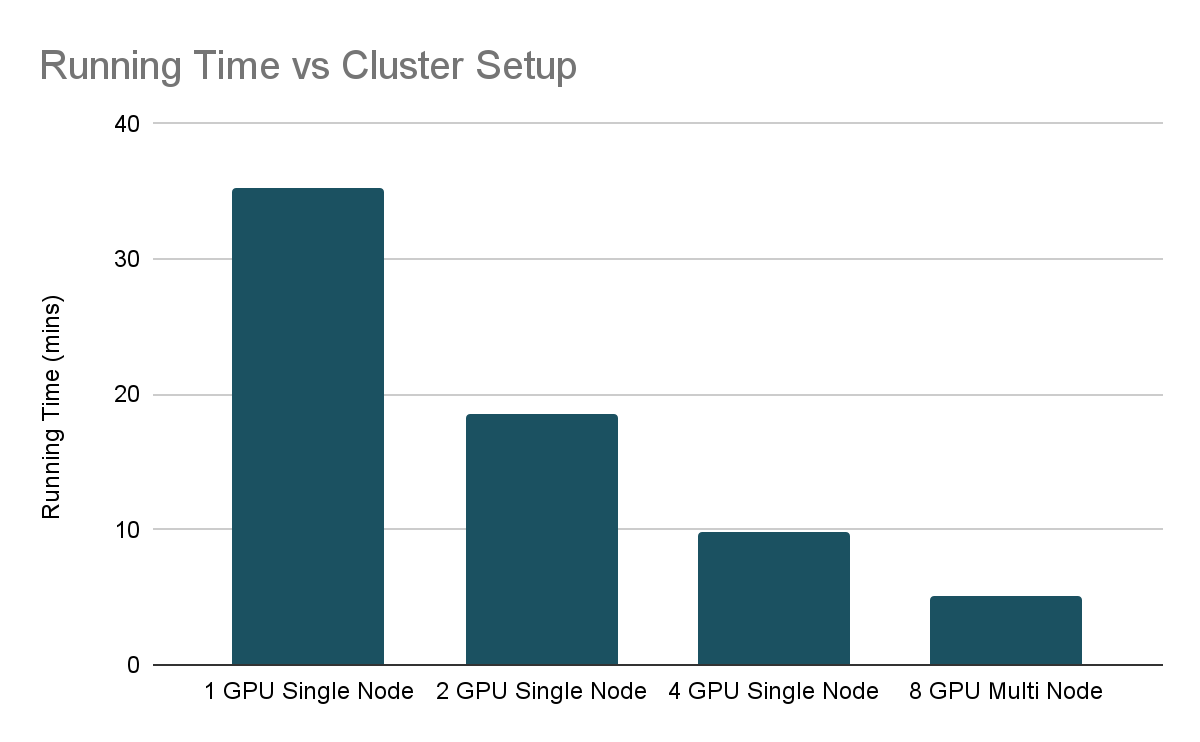
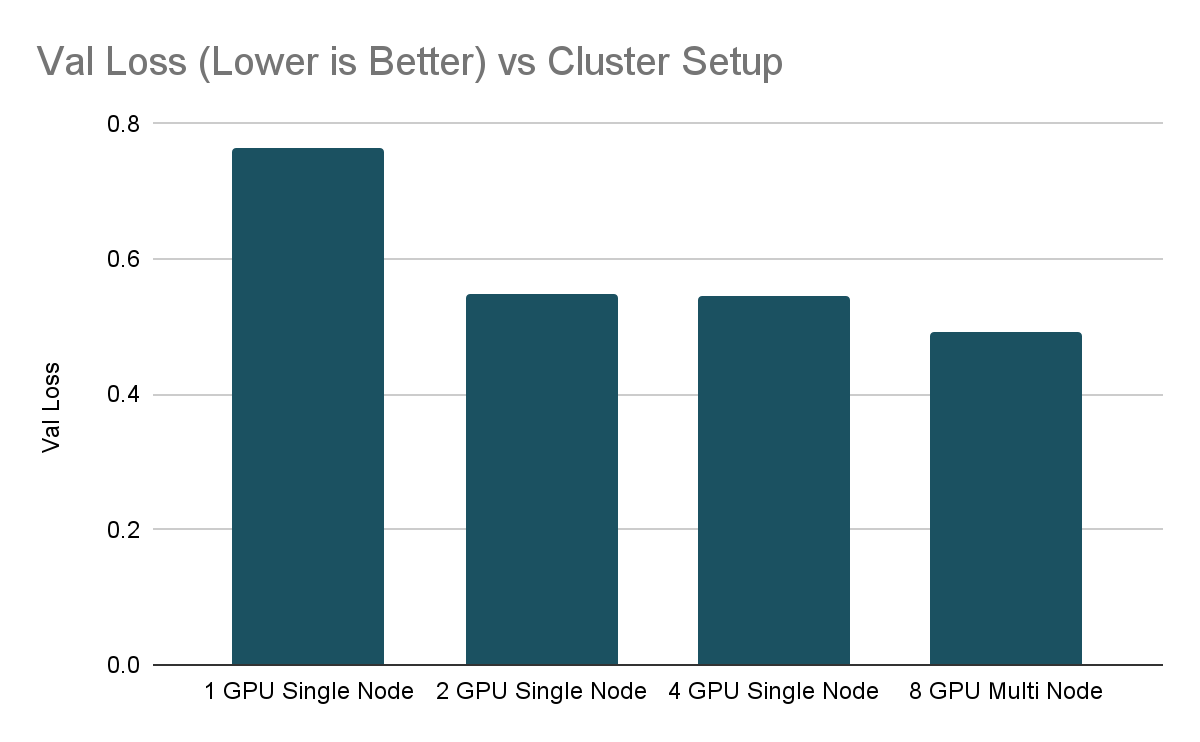
Running Time vs Cluster Setupのグラフから分かるように、システムのリソースを増加させることで、トレーニング時間をほぼ半分にしています。異なるGPU間でのトレーニングプロセスの調整によるオーバーヘッドのため、線形にはスケーリングしていません。ディープラーニングをスケールさせる際、結果が減少しているかどうかを見ることは一般的であり、GPUを追加する前にトレーニングループが効率的になっていることを確認することが重要です。
これは全体像ではありませんが、以前のブログ記事ディープラーニングを容易にスケールさせる(させない)6つのステップでアドバイスしているベストプラクティスに基づいて、さまざまなトレーニングの実行によって達成される最終的なvalidation lossをチェックすることが重要なのでEarlyStoppingを活用しました。この場合、stopping_thresholdを0.55に設定しました。面白いことに、単一のGPU環境では、複数GPUの環境よりも悪いvalidation lossで停止しています。単一のGPUでのトレーニングでは、val_lossに改善が認められなくなるまで処理が実行されました。
使い始める
ここまでで、DatabricksでどのようにPyTorch Lightningを活用できるのか、複数ノードにスケールさせるためにHorovodRunnerでどのようにラッピングするのかを説明し、EarlyStoppingをどのように活用するのかに関してのガイドを説明しました。次はあなたがトライしてみる番です。
ノートブック
参考文献
- HorovodRunner
- Petastormを用いたデータロード
- Databricksにおけるディープラーニングのベストプラクティス
- ディープラーニングを容易にスケールさせる(させない)6つのステップ
- Leveling the Playing Field: HorovodRunner for Distributed Deep Learning Training