Introducing Materialized Views and Streaming Tables for Databricks SQL | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
データアナリストがすべてをSQLでデータの取り込み、変換、デリバリーできるように支援
AWSとAzureのDatabricks SQLでマテリアライズドビューとストリーミングテーブルが利用できるようになることを発表できて嬉しく思っています。ストリーミングテーブルは、クラウドストレージやメッセージキューからのインクリメンタルな取り込みを提供します。マテリアライズドビューは、新規データの到着に合わせて自動かつインクリメンタルに更新されます。これらの2つの機能を組み合わせることで、ビジネスに新鮮なデータをセットアップし、提供することをシンプルにするインフラストラクチャ不要のデータパイプラインを実現します。この記事では、データウェアハウスでアナリストや分析エンジニアたちがデータや分析アプリケーションをより効果的にデリバリーするために、これらの新機能がどのような助けになるのかを探索します。
背景
すべてのデータドリブンの企業において、データウェアハウスやデータエンジニアリングは重要なものとなっています。データウェアハウスは、分析やレポートの主要な場所として動作し、データエンジニアリングにはデータの取り込みや変換を行うデータパイプラインの作成が含まれます。
しかし、従来型のデータウェアハウスは、ストリーミングの取り込みや変換処理のためには設計されていません。従来のデータウェアハウスで大規模のデータを低レーテンシーで取り込むのは、レガシーデータウェアハウスはバッチ処理向けに設計されているので、効果で複雑なものとなります。このため、チームはウェアハウスの外での設計を必要とする不器用なソリューションを実装し、中間ステージングロケーションとしてクラウドストレージを使わなくてはなりませんでした。これらのシステムの管理は高コストで、エラーに対して脆弱で、維持が複雑なものです。
Databricksレイクハウスプラットフォームは、統合されたソリューションを提供することで、この従来型のパラダイムを打破します。Delta Live Tables (DLT)はデータエンジニアリングやストリーミングを行うためのベストな場所であり、Databricks SQLは既存のデータレイクにおける分析ワークロードで、最大12倍のコストパフォーマンスを提供します。
さらに、dbtのようなパートナーは、この発表でより詳細を説明するこれらのネイティブ機能を用いてインテグレーションできるようになりました。
データウェアハウスユーザーが直面する共通課題
データウェアハウスは、ビジネスインテリジェンス(BI)アプリケーションを通じた内部レポートための分析やデータデリバリーのためのベストな場所として動作します。企業は、データウェアハウスの導入において幾つかの課題に直面します:
- セルフサービス: SQLアナリストは、多くの場合においてデータの問題を修正するために他のリソースやツールに依存するという課題に直面し、ビジネスが対応すべきペースをスローダウンしてしまいます。
- 遅いBIダッシュボード: 大規模データをベースに作成したBIダッシュボードは、結果の返却が遅い傾向があり、さまざまな質問に回答する際のインタラクティブ性や使いやすさの妨げとなっています。
- 古いデータ: 多くの場合、ETLジョブが深夜にのみ実行されることで、BIダッシュボードは昨日のデータなど古いデータを表示します。
3rdパーティなしにデータを取り込み、変換するためにSQLを活用
ストリーミングテーブルとマテリアライズドビューは、データエンジニアリングのベストプラクティスを用いて、SQLアナリストの能力を高めます。S3のロケーションに新規に到着するファイルを継続的に取り込み、シンプルなレポート用テーブルを準備するという例を考えてみます。Databricks SQLを用いることで、以下の例のように数行のコードのみを用いることで、数分でS3のファイルをクイックに発見し、プレビューし、シンプルなETLパイプラインをセットアップすることができます。
1 - S3のデータの発見とプレビュー
/* Discover your data in an External Location */
LIST "s3://mybucket/analysis"
/* Preview your data */
SELECT * FROM read_files("s3://mybucket/analysis")
2 - ストリーミングでデータを取り込み
/* Continuous streaming ingest at scale */
CREATE STREAMING TABLE my_bronze_table
SCHEDULE CRON ‘0 0 * ? * * *’
AS
SELECT id,event_id FROM STREAM read_files('s3://mybucket/analysis')
3 - マテリアライズドビューを用いてインクリメンタルにデータを集計
/* Create a Silver aggregate table */
CREATE MATERIALIZED VIEW my_silver_table
SCHEDULE CRON ‘0 0 * ? * * *’
AS
SELECT count(distinct event_id) as event_count from my_bronze_table;
マテリアライズドビューとは?
マテリアライズドビュー(MV)は、遅いクエリーや頻繁に使用される計算処理を事前計算することで、コストを削減し、クエリーのレーテンシーを改善します。データエンジニアリングの文脈では、これはデータの変換に活用されます。しかし、これらは以下の理由からデータウェアハウスを活用しているアナリストチームでも有益です。
- エンドユーザーのクエリーとBIダッシュボードをスピードアップします。
- セキュアにデータを共有できます。
Delta Live Tablesの上に構築されており、遅いクエリーや頻繁に使用される計算処理を事前計算することで、MVはクエリーのレーテンシーを削減します。
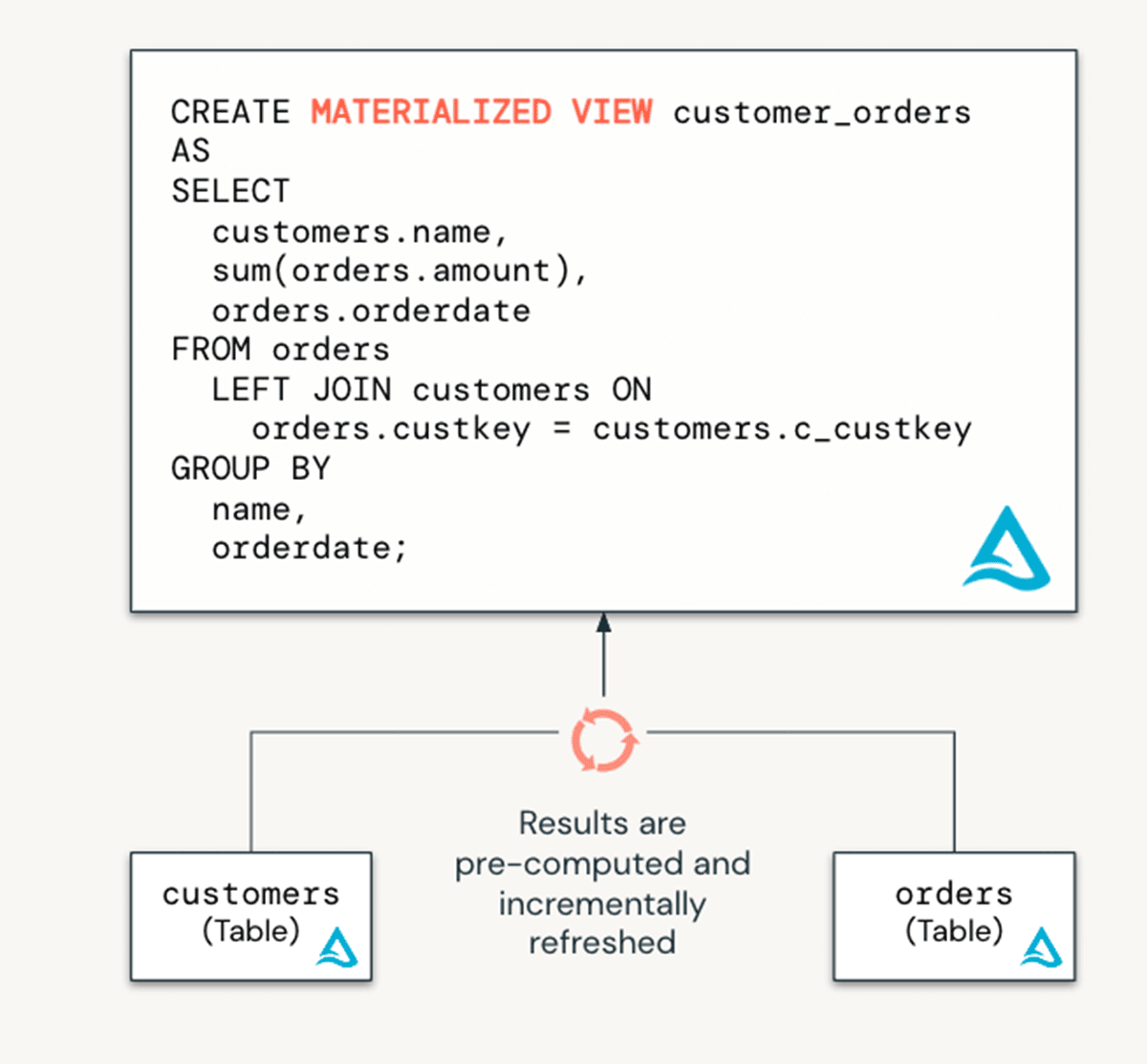
マテリアライズドビューのメリットは以下の通りです:
- BIダッシュボードの高速化。MVはデータを事前計算するので、エンドユーザーはベーステーブルを直接クエリーしてデータを再処理する必要がないので、エンドユーザーのクエリーは非常に高速になります。
- データ処理コストの削減。新規データが到着した際に、ビューを完全に再構築する必要性を回避するために、MVの結果はインクリメンタルにリフレッシュされます。
- セキュアな共有のためのデータアクセスコントロールの改善。ベーステーブルに対するアクセスをコントロールすることで、利用者が参照できるデータをよりタイトに制御します。
ストリーミングテーブルとは?
DBSQLにおけるデータ取り込みは、ストリーミングテーブル(ST)で実現されます。STは「ブロンズ」テーブルへのデータの取り込みに理想的なものと考えてください。STによって、クラウドストレージやメッセージバス(EventHubやApache Kafka)などを含むすべてのデータソースからの連続的、スケーラブルなデータ取り込みが可能となります。
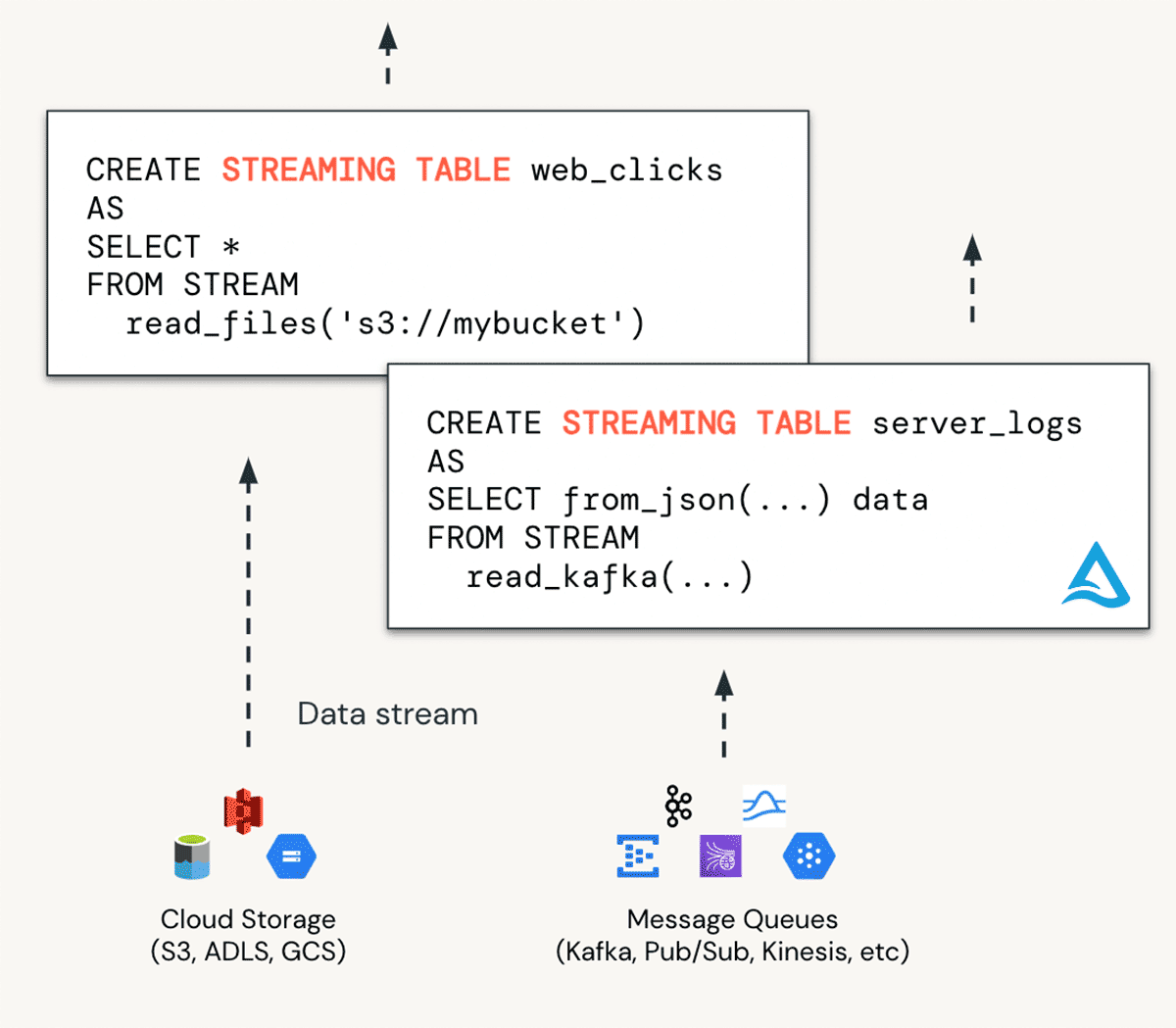
ストリーミングテーブルのメリットは以下の通りです:
- リアルタイムユースケースを解放します。ストリーミングデータを伴うリアルタイム分析/BI、機械学習、オペレーションのユースケースをサポートできるようになります。
- 優れたスケーラビリティ。大規模バッチではなく、インクリメンタルな処理を通じて膨大なデータをより効率的に取り扱えるようになります。
- より多くの人が活用可能に。シンプルなSQL構文によって、すべてのデータエンジニアやアナリストがデータストリーミングにアクセスできるようになります。
カスタマーストーリー: AdobeやDanske Spilはマテリアライズドビューを用いてどのようにダッシュボードクエリーを加速したのか
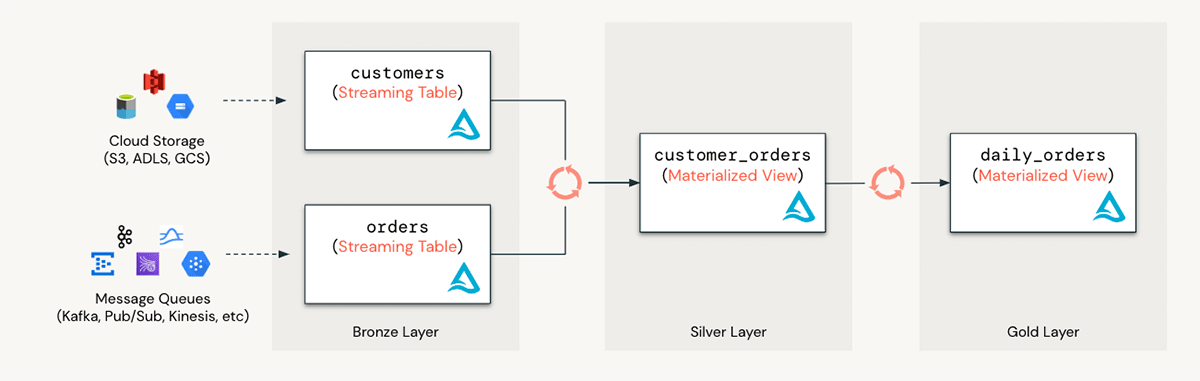
Databricks SQLは、データアナリストがサードパーティツールに頼ることなしに、ビジネス要件に応えるために容易にデータの取り込み、クレンジング、補強できるように能力を強化し舞うs。すべてをSQLで行うことができるので、ワークフローを円滑にします。
マテリアライズドビューとストリーミングテーブルを活用することで、以下のことが可能となります:
- アナリストの能力強化: あなたのビジネスの要件にクイックに応えるために、SQLアナリストやデータアナリストは容易にデータを取り込み、クレンジングし、補強することができます。すべてはSQLで行えるので、サードパーティツールは不要です。
- BIダッシュボードのスピードアップ: 事前に結果を計算しておくことで、SQL分析やBIレポートを加速するMVを作成します。
- リアルタイム分析への移行: リアルタイムユースケースのためのインクリメンタルなデータパイプラインを作成するために、MVとストリーミングテーブルを組み合わせます。Databricks SQLウェアハウスで直接取り込みや変換を行うストリーミングデータパイプラインをセットアップすることができます。

Adobeは、人間の創意工夫を増幅する副操縦士として、人工知能を用いて世界をよりクリエイティブ、生産的、パーソナライズされたものにするというミッションのもと、AIに対する高度なアプローチを採用しています。Databricks SQLのマテリアライズドビューの早期プレビューユーザーとして、このミッションを実現する役に立つさまざまな技術的、ビジネス的なメリットを目撃しています。
「マテリアライズドビューに変換することで、クエリー実行時間を8分から3秒に削減することで、クエリー性能に劇的な改善が認められました。これによって、我々のチームはデータから得られる洞察に基づいて、より効率的、クイックに意思決定できるようになりました。さらに、コスト削減は本当に助かりました。」— Karthik Venkatesan, Security Software Engineering Sr. Manager, Adobe

1948年に創業したDanske Spilは、デンマークの国営くじであり、DB SQLのマテリアライズドビューの早期プレビューユーザーでした。Data Engineering Team LeadであるSøren Kleinは、組織にとってマテリアライズドビューが非常に価値のあるものとなったことに関して、彼の視点を共有しています。
「Danske Spilにおいて、我々はウェブサイトのトラッキングデータのパフォーマンスをスピードアップするためにマテリアライズドビューを活用しています。この機能によって、不要なテーブルの作成や複雑性の追加を避けることができつつも、エンドユーザーのレポーティングソリューションを加速する永続化ビューのスピードを手に入れました。」— Søren Klein, Data Engineering Team Lead, Danske Spil
dbtによる簡単なストリーミングの取り込みと変換
Databricksとdbt Labsは、レイクハウスアーキテクチャにおけるリアルタイム分析エンジニアリングをシンプルにするためにコラボレーションしています。dbtの非常に人気の分析エンジニアリングフレームワークとDatabricksレイクハウスプラットフォームの組み合わせによって、パワフルな機能を提供します:
- dbt + ストリーミングテーブル: すべてのソースからのストリーミング取り込み処理はdbtプロジェクトにビルトインされます。SQLを用いることで、SQLエンジニア、分析エンジニアは自身のdbtパイプラインで直接クラウド/ストリーミングデータの定義や取り込みを行うことができます。
- dbt + マテリアライズドビュー: Databricksのパワフルなインクリメンタルリフレッシュ機能を活用して、dbtでの効率的なパイプライン構築がより簡単になります。ユーザーは、MVをベースとしたパイプラインを構築、実行するためにdbtを用い、効率的でインクリメンタルな計算処理によってインフラストラクチャのコストを削減します。
テイクアウェイ
データウェアハウスとデータエンジニアリングは、すべてのデータドリブンな企業で重要なものとなっています。しかし、それぞれの視点における別個の粗リューションの管理は、高コストで、エラーに対して脆弱で、維持が困難です。Databricksレイクハウスプラットフォームは、Databricks SQLにベストなデータエンジニアリング機能をネイティブに取り込み、統合されたソリューションでSQLユーザーの能力を高めます。さらに、dbtのようなパートナーとのインテグレーションによって、我々共通のお客様は、より迅速な洞察、リアルタイム分析、整理されたデータエンジニアリングワークフローを実現するために、これらのユニークな機能を活用することができます。
こちらのリンクからDatabricks SQLのマテリアライズドビューとストリーミングテーブルにアクセスしてください。また、DatabricksやDatabricks SQLを使い始めることもできますし、マテリアライズドビューやストリーミングテーブルのドキュメントを確認することもできます。