こちらで存在を知りました。
もともとSpark PDFデータソースというものが存在していたそうなのですが、こちらのデータソースがDatabricksでも動くようになったとのこと。ありがとうございます。
リポジトリはこちら。
Databricksで動かしてみます。
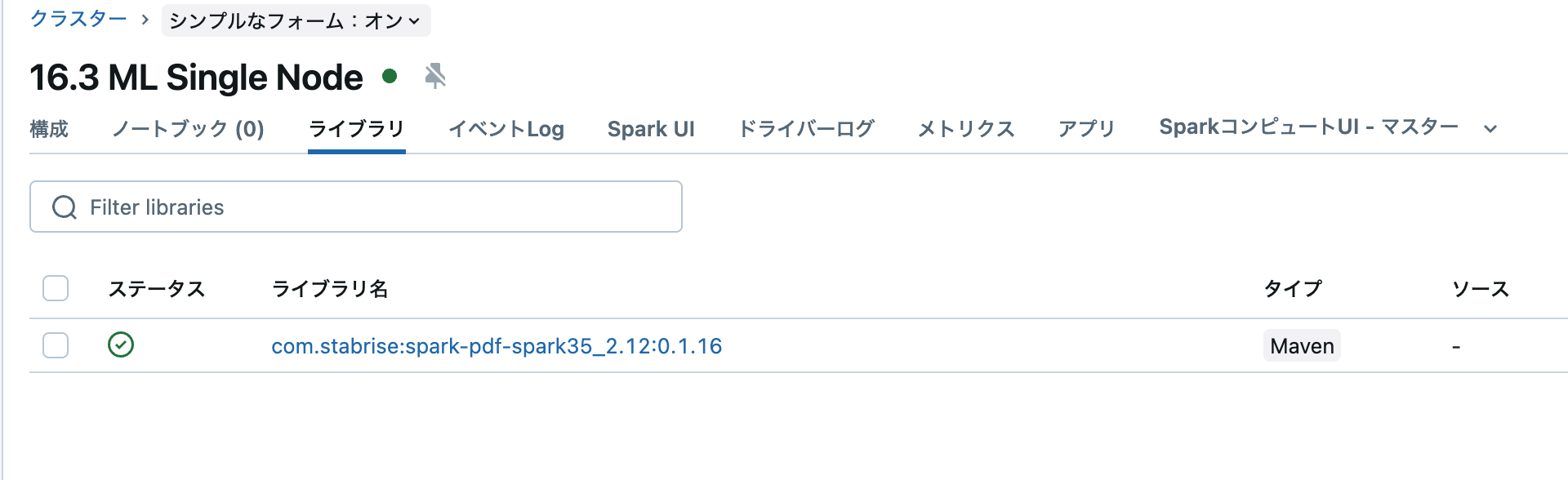
使用するには、クラスターでMavenからライブラリをインストールする必要があります。

サンプルノートブックの実行
Databricks用のサンプルノートブックが提供されているので、こちらを使わせていただきます。

このノートブックは、Databricksプラットフォーム上でApache Sparkを使用して複数ページのPDFファイルを読み込む方法を示しています。
ソースコード: https://github.com/StabRise/spark-pdf
関連ブログ投稿:
- https://stabrise.com/blog/spark-pdf-on-databricks/
- https://stabrise.com/blog/spark-pdf-databricks-unity-catalog/
⭐ GitHubでスターを付けてください — 私たちの大きな励みになります!
主な機能:
- PDFドキュメントをSpark DataFrameに読み込む
- ページごとにPDFファイルを遅延読み込み
- 最大10,000ページの大きなファイルをサポート
- スキャンされたPDFファイルをサポート(OCRを呼び出す)
- Tesseract OCRをインストールする必要はありません。パッケージに含まれています
必要条件
- Databricksランタイムv15.04以上(Spark v3.5.x)
- Spark PDF v0.1.16以上(maven: com.stabrise:spark-pdf-spark35_2.12:0.1.16)
import io
import os
from PIL import Image
SparkにPDFドキュメントを読み込む
# サンプルのPDFファイルをダウンロード
import urllib.request
filenames = ["example1.pdf", "example2.pdf", "example3.pdf"]
url = f"https://raw.githubusercontent.com/StabRise/spark-pdf/refs/heads/main/examples/"
for f in filenames:
urllib.request.urlretrieve(url + f, f)
df = spark.read.format("pdf") \
.option("imageType", "BINARY") \
.option("resolution", "300") \
.option("pagePerPartition", "8") \
.option("reader", "pdfBox") \
.load([f"file:{os.getcwd()}/{f}" for f in filenames])
データソースの利用可能なオプション:
-
imageType: 出力画像タイプ。次の値が使用可能: "BINARY", "GREY", "RGB"。デフォルト: "RGB"。 -
resolution: PDFページを画像にレンダリングする際の解像度。デフォルト: "300" dpi。 -
pagePerPartition: Spark DataFrameにおけるパーティションごとのページ数。デフォルト: "5"。 -
reader: サポートされるリーダー:pdfBox- PdfBox Javaライブラリに基づく,gs- GhostScriptに基づく(システムにGhostScriptのインストールが必要)
すべてのドキュメントの総ページ数をカウントする
Spark PDFは遅延評価アプローチを採用しており、PDFファイル全体をメモリにロードすることなくメタデータを抽出します。
この例では、2つのPDFドキュメントを読み込みました:
- 最初のドキュメントは1ページです。
- 2番目のドキュメントは認識されないテキストを含む1ページです。
- 最後のドキュメントは30ページです。
df.count()
32
パーティション数の確認
設定でオプション pagePerPartition = 8 を指定しました。これにより、6つのパーティションが作成されます:
- 最初のファイルに1つのパーティション。
- 2番目のファイルに1つのパーティション。
- 30ページを含む最後のファイルに4つのパーティション。
df.rdd.getNumPartitions()
6
データフレームの表示
データフレームには次の列が含まれています:
-
path: ファイルへのパス -
page_number: ドキュメントのページ番号 -
text: PDFページのテキストレイヤーから抽出されたテキスト -
image: ページの画像表現 -
document: レンダリングされた画像からOCRで抽出されたテキスト(Tesseract OCRを使用) -
partition_number: パーティション番号
df.select("filename", "page_number", "partition_number", "text") \
.orderBy("filename", "page_number") \
.show()
+------------+-----------+----------------+--------------------+
| filename|page_number|partition_number| text|
+------------+-----------+----------------+--------------------+
|example1.pdf| 0| 4|RECIPE\nStrawberr...|
|example2.pdf| 0| 5| \n|
|example3.pdf| 0| 0|Lorem ipsum \nLor...|
|example3.pdf| 1| 0|In non mauris jus...|
|example3.pdf| 2| 0|Lorem ipsum dolor...|
|example3.pdf| 3| 0|Maecenas mauris l...|
|example3.pdf| 4| 0|Etiam vehicula lu...|
|example3.pdf| 5| 0|Lorem ipsum \nLor...|
|example3.pdf| 6| 0|In non mauris jus...|
|example3.pdf| 7| 0|Lorem ipsum dolor...|
|example3.pdf| 8| 1|Maecenas mauris l...|
|example3.pdf| 9| 1|Etiam vehicula lu...|
|example3.pdf| 10| 1|Lorem ipsum \nLor...|
|example3.pdf| 11| 1|In non mauris jus...|
|example3.pdf| 12| 1|Lorem ipsum dolor...|
|example3.pdf| 13| 1|Maecenas mauris l...|
|example3.pdf| 14| 1|Etiam vehicula lu...|
|example3.pdf| 15| 1|Lorem ipsum \nLor...|
|example3.pdf| 16| 2|In non mauris jus...|
|example3.pdf| 17| 2|Lorem ipsum dolor...|
+------------+-----------+----------------+--------------------+
only showing top 20 rows
displayでも表示可能です。
df.select("filename", "page_number", "partition_number", "text") \
.orderBy("filename", "page_number").display()

df.printSchema()
root
|-- path: string (nullable = true)
|-- filename: string (nullable = true)
|-- page_number: integer (nullable = true)
|-- partition_number: integer (nullable = true)
|-- text: string (nullable = true)
|-- image: struct (nullable = true)
| |-- path: string (nullable = true)
| |-- resolution: integer (nullable = true)
| |-- data: binary (nullable = true)
| |-- imageType: string (nullable = true)
| |-- exception: string (nullable = true)
| |-- height: integer (nullable = true)
| |-- width: integer (nullable = true)
|-- document: struct (nullable = true)
| |-- path: string (nullable = true)
| |-- text: string (nullable = true)
| |-- outputType: string (nullable = true)
| |-- bBoxes: array (nullable = true)
| | |-- element: struct (containsNull = true)
| | | |-- text: string (nullable = true)
| | | |-- score: float (nullable = true)
| | | |-- x: integer (nullable = true)
| | | |-- y: integer (nullable = true)
| | | |-- width: integer (nullable = true)
| | | |-- height: integer (nullable = true)
| |-- exception: string (nullable = true)
テキストレイヤーを含むPDFドキュメントページ(デジタル/検索可能なPDF)
# あるドキュメントの最初のページを読み込む
row = spark.read.format("pdf") \
.option("imageType", "BINARY") \
.option("resolution", "300") \
.option("pagePerPartition", "8") \
.option("reader", "pdfBox") \
.load(f"file:{os.getcwd()}/example1.pdf") \
.select("page_number", "text", "image.data", "path") \
.limit(1) \
.collect()[0]
# ページの画像表現
display(Image.open(io.BytesIO(row.data)).resize((600, 800)))

print(row.text) # ページのテキスト表現
RECIPE
Strawberry
Vanilla
Pancakes
Ready in 20minutes
Serves 8 people
280 calories
Ingredients
● Lorem ipsum dolor sit amet
● Consectetuer adipiscing elit
● Suspendisse scelerisque
● Libero interdum auctor
Preparation
1. Lorem ipsum dolor sit amet
consectetuer adipiscing elit sed do
tempor incididunt ut labore et dolore
magna aliqua.
2. Ut enim adminim veniam, quis nostrud
exercitation ullamco laboris nisi ut aliquip
ex ea commodo consequat.
3. Suspendisse scelerisquemi ami. Lorem
ipsum dolor sit amet, consectetur
adipiscing elit, sed dolore eiusmod
tempor.
4. Vestibulum ante ipsum primis
elementum, libero interdum auctor
cursus, sapien enim dictum quam.
5. Phasellus vehicula nonummy nunc.
Lorem ipsum dolor sit amet, consectetur
adipiscing elit. Ut enim adminim veniam,
quis nostrud exercitation.
6. Ullamco laboris nisi ut aliquip ex ea
commodo consequat.
Tips
Lorem ipsum dolor sit amet consectetuer
adipiscing elit sed do tempor incididunt ut
labore et doloremagna aliqua.
画像データを含むPDFドキュメントページ(スキャンまたは画像ベースのPDF)
# テキストデータが認識されていないドキュメントの最初のページを読み込む
row = spark.read.format("pdf") \
.option("imageType", "BINARY") \
.option("resolution", "300") \
.option("pagePerPartition", "8") \
.option("reader", "pdfBox") \
.load(f"file:{os.getcwd()}/example2.pdf") \
.select("page_number", "text", "document", "image.data", "path") \
.limit(1) \
.collect()[0]
display(Image.open(io.BytesIO(row.data)).resize((600, 800)))

print(row.text) # このページにはテキストレイヤーが含まれていないため、空です
# OCRで認識されたテキストを表示
print(row.document.text)
YOUR COMPANY
123 YOUR STREET
YOUR CITY, ST 12345
(123) 456-7890
NO_REPLY@EXAMPLE.COM
September 04, 20XX
Dear Ms. Reader,
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy
nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat. Ut wisi
enim ad minim veniam, quis nostrud exerci tation ullamcorper suscipit lobortis
nisl ut aliquip ex ea commodo consequat.
Duis autem vel eum iriure dolor in hendrerit in vulputate velit esse molestie
consequat, vel illum dolore eu feugiat nulla facilisis at vero eros et
accumsan.
Nam liber tempor cum soluta nobis eleifend option congue nihil imperdiet
doming id quod mazim placerat facer possim assum. Typi non habent claritatem
insitam; est usus legentis in iis qui facit eorum claritatem. Investigationes
demonstraverunt lectores legere me lius quod ii legunt saepius.
Sincerely,
日本語のPDFも読み込みめました。ただ、OCRは英語前提のようです。こちらにチケットが上がっているので、対応されることを期待してます。
# 日本語のPDFの最初のページを読み込む
row = spark.read.format("pdf") \
.option("imageType", "BINARY") \
.option("resolution", "300") \
.option("pagePerPartition", "8") \
.option("reader", "pdfBox") \
.load(f"file:{os.getcwd()}/御社環境におけるDatabricksクラスター設定手順_V1.pdf") \
.select("page_number", "text", "document", "image.data", "path") \
.limit(1) \
.collect()[0]
display(Image.open(io.BytesIO(row.data)).resize((600, 800)))
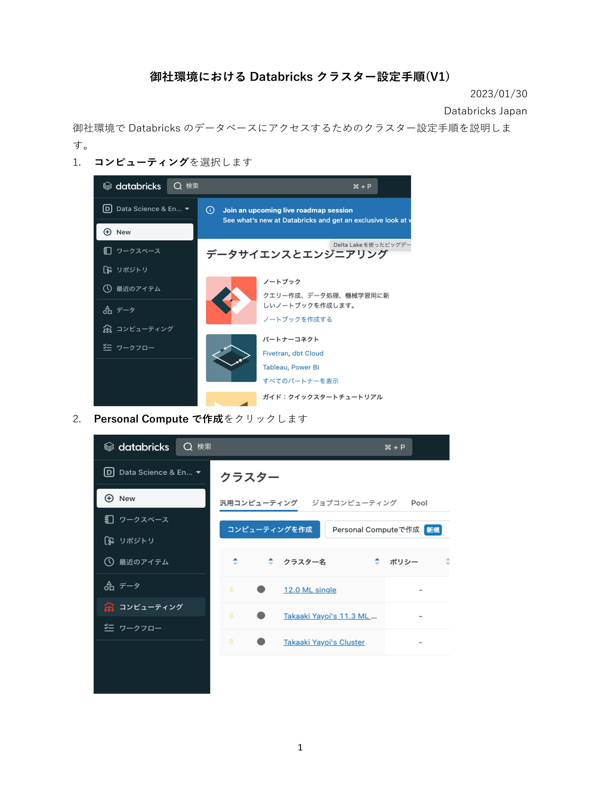
print(row.text)
1
御社環境における Databricks クラスター設定手順(V1)
2023/01/30
Databricks Japan
御社環境で Databricks のデータベースにアクセスするためのクラスター設定手順を説明しま
す。
1. コンピューティングを選択します
2. Personal Compute で作成をクリックします