以前、エクスプレスセットアップについて記事を書きました。
こちらのセットアップでは、お客様の方でAWSアカウントを作成することなしに、クイックにDatabricksを使い始めることができます。
こちらからセットアップをスタートできます。
クイックセットアップを選択します。
そして、今日になってワークスペースのトップページにチュートリアルが追加されていることに気づきました。
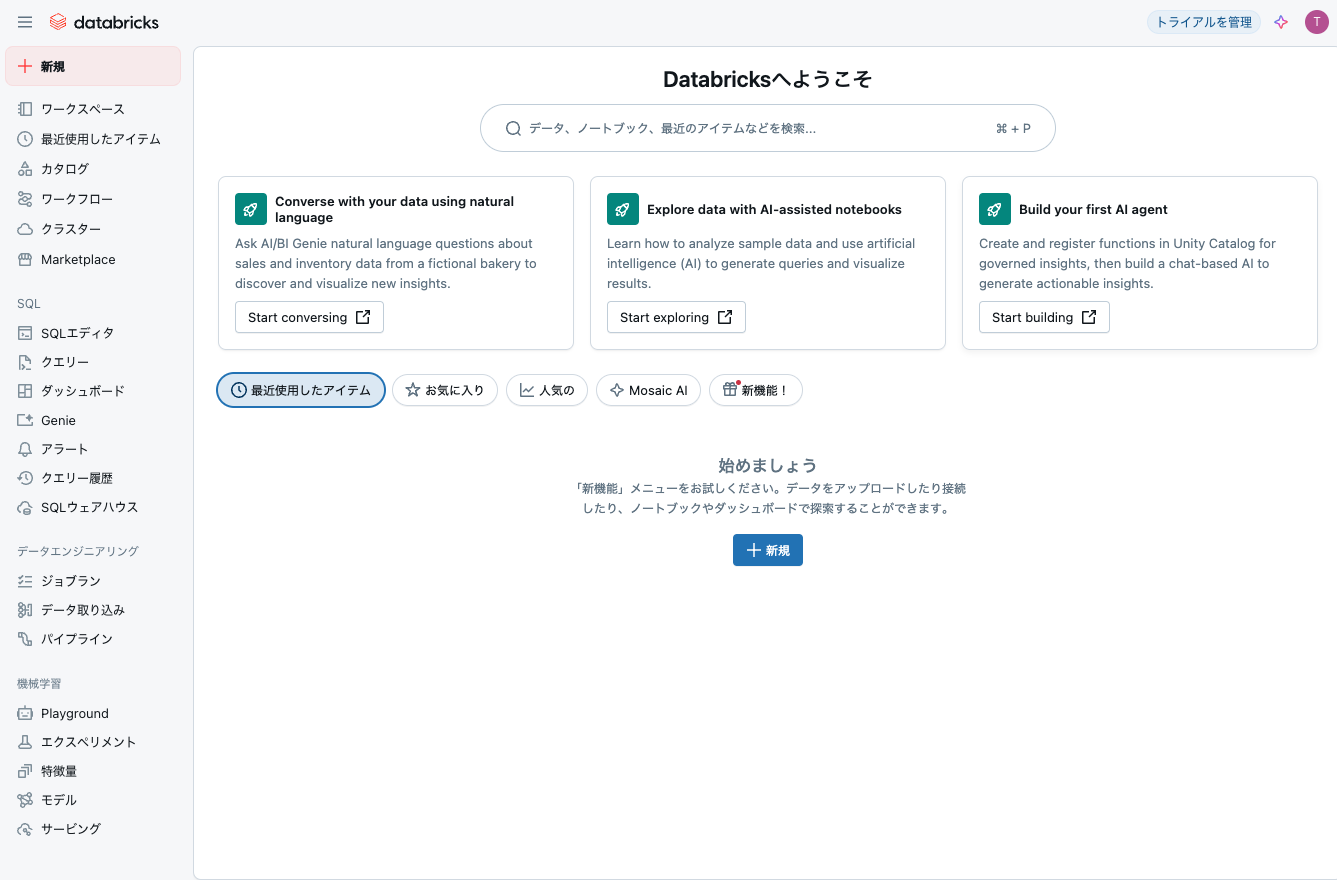
以下の3つです。
- 自然言語を用いてデータと会話する 新たな洞察を発見、可視化するために、架空のパン屋からの売上、在庫データに関して自然言語でAI/BI Genieに質問します。
- AIアシストノートブックでデータを探索 クエリーを生成し、結果を可視化するために、サンプルデータの分析方法と人工知能(AI)の使い方を学びます。
- 初めてのAIエージェントの構築 ガバナンスの効いた洞察のためにUnity Catalogで関数を作成、登録し、アクション可能な洞察を生成するためにチャットベースのAIを構築します。
それぞれ試していきます。
自然言語を用いてデータと会話する
Genieにアクセスすると、サンプルのGenieスペースBakehouse Sales Starter Spaceが作成されています。
ウェアハウスを開始して、問い合わせしてみます。
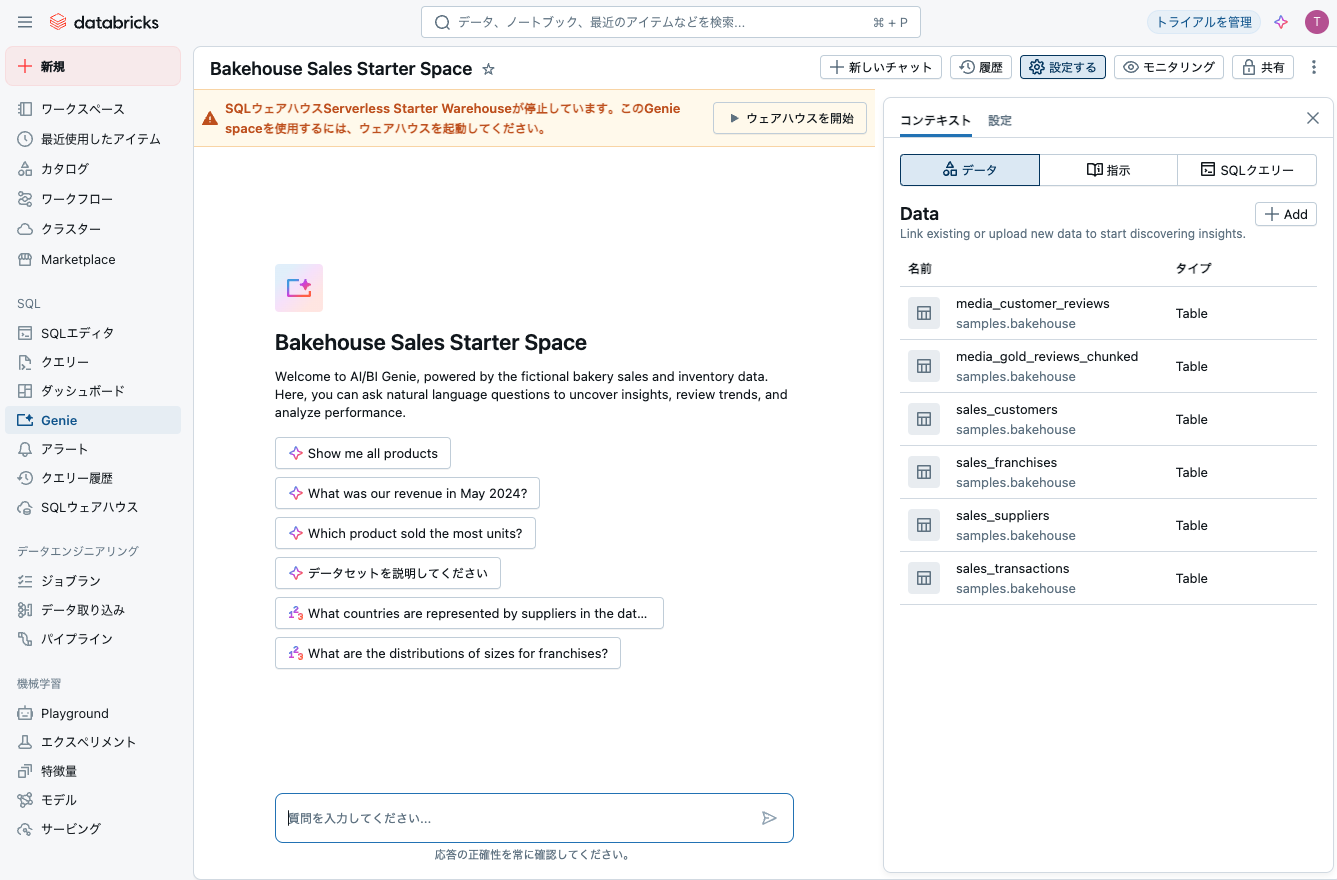
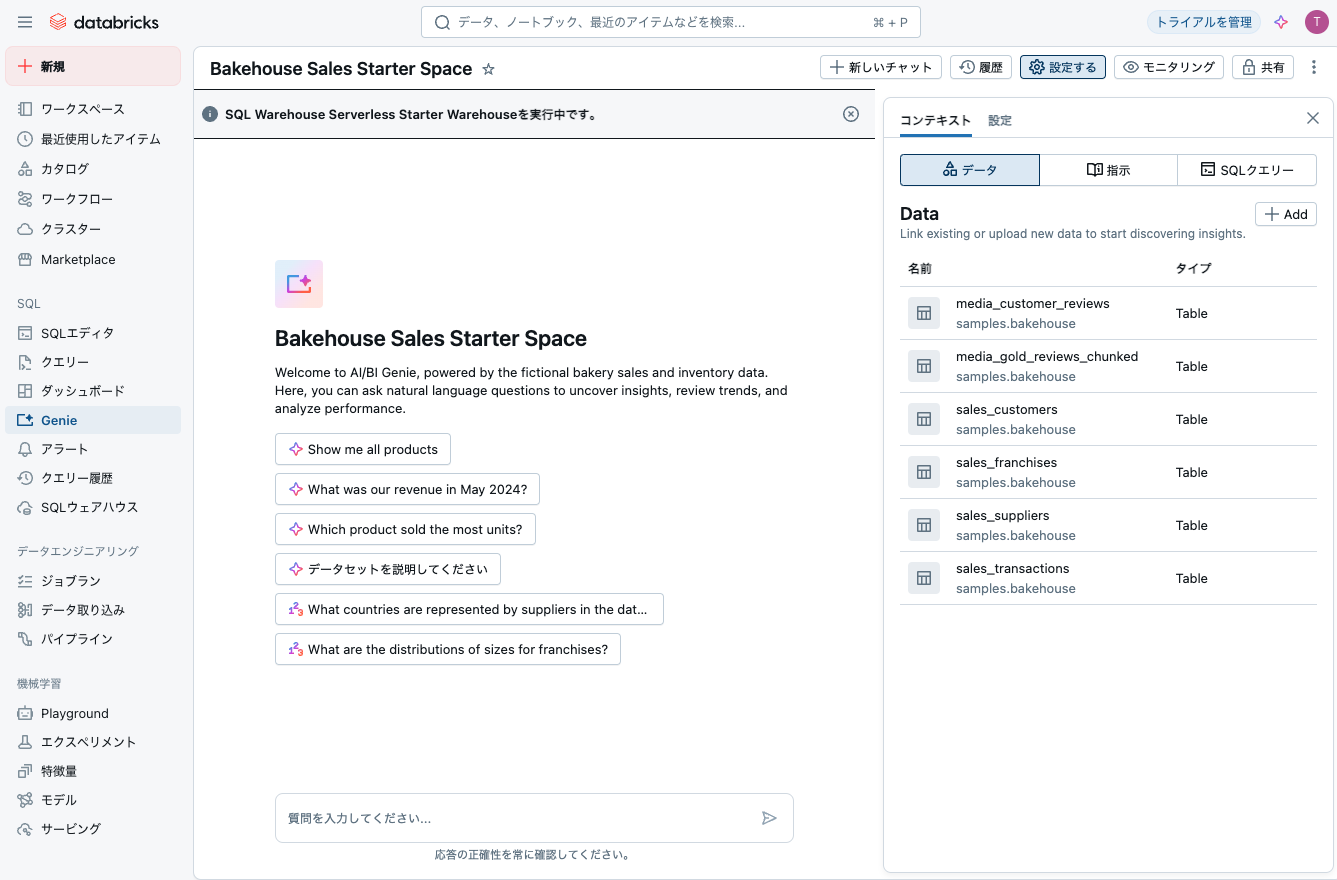
どのようなデータかを聞きます。
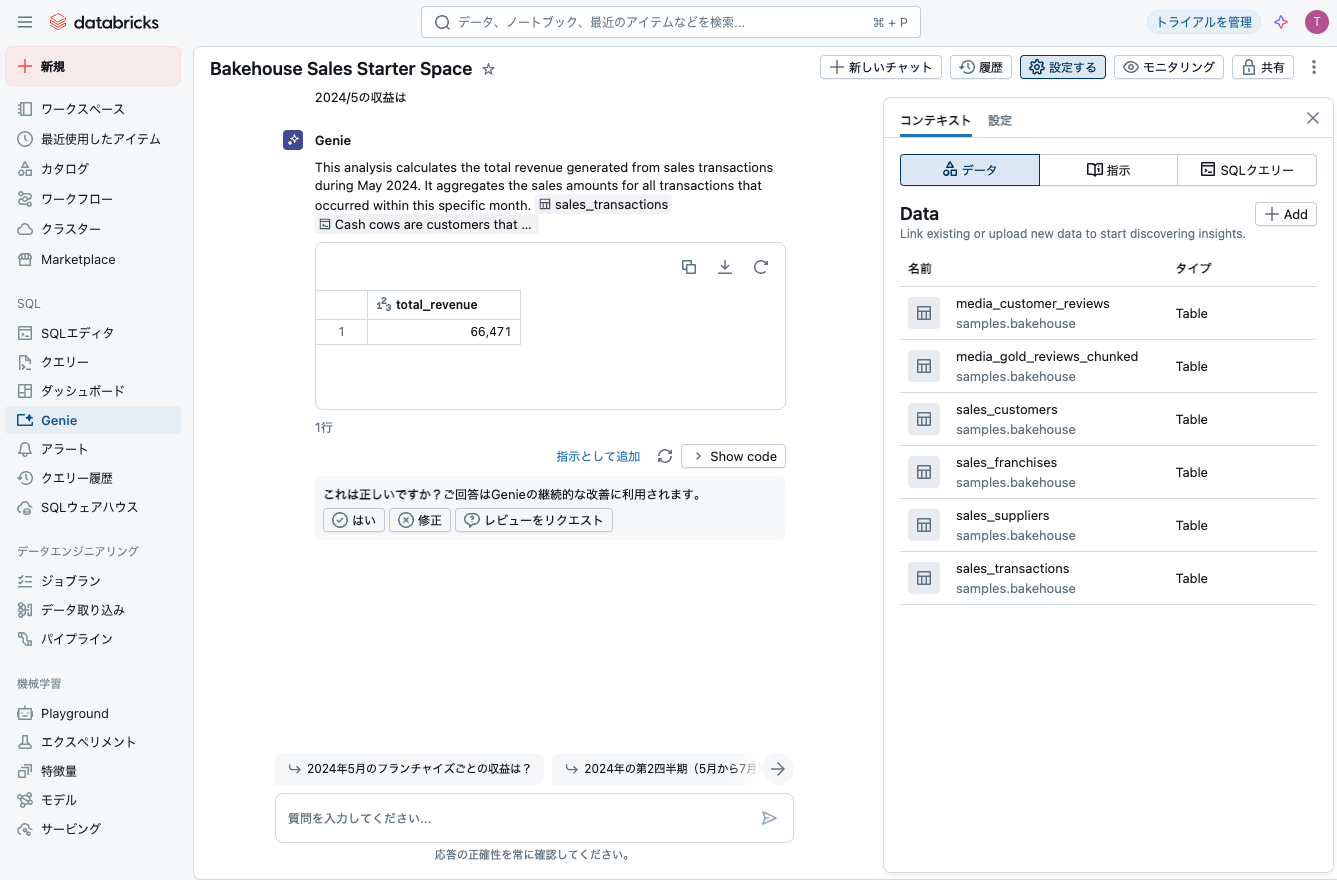
2024/5の収益を聞いてみます。
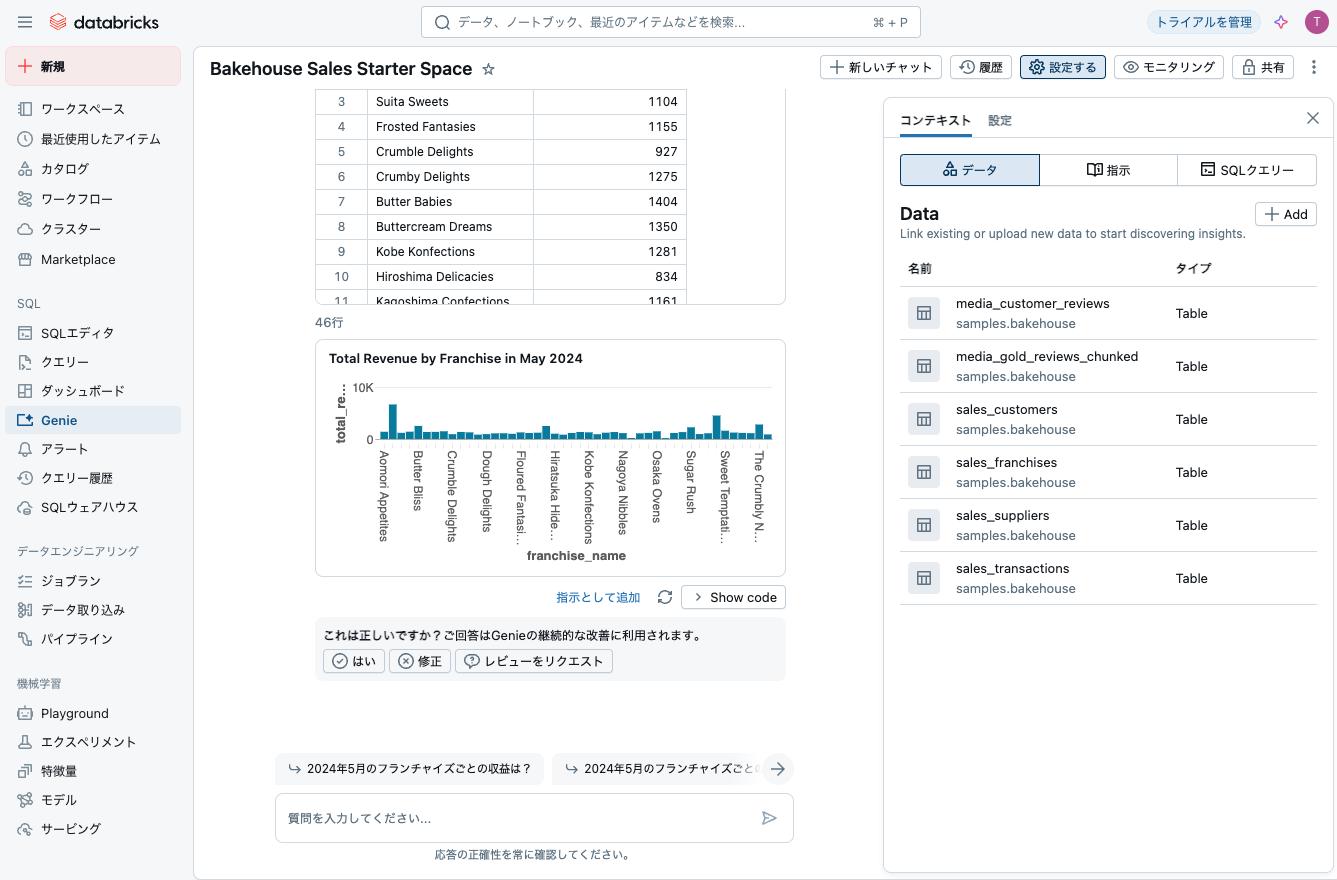
フランチャイズごとの収益を聞いてみます。
セットアップしてからここまでで約4分です。
AIアシストノートブックでデータを探索
ノートブックが開きます。英語ですが、 ボタンをクリックしてアシスタントを呼び出します。翻訳と指示すれば日本語になります。
ボタンをクリックしてアシスタントを呼び出します。翻訳と指示すれば日本語になります。
Databricksノートブックへようこそ
ノートブックは、Databricksの主要なコード作成ツールです。これを使って、シンプルな探索的データ分析からMLモデルのトレーニング、複数段階のデータパイプラインの構築まで、何でも行うことができます。
ベイクハウスのデータを調査して、売上を分析してみましょう!
ステップ1: 始めましょう
ノートブックセルでコードを実行するには、コードを入力して、セルの左上にある実行ボタンをクリックするか、Cmd + Enterを使用します。
提供されたステートメントを実行してみてください: print("Let's execute some Python code!")
print("Let's execute some Python code!")
Let's execute some Python code!
コマンドパレットを試してみましょう
[Cmd + Shift + P] キーボードショートカットを使用して、コマンドパレットを開き、新しいセルの挿入、結果の並列表示などの主要なノートブックアクションを実行します。
これを使ってセルを挿入してみましょう。

ノートブックはマルチランゲージのオーサリング体験です
DatabricksではPythonだけでなく、SQLやMarkdownを使用してノートブックにコードを書いて実行することができます。
右上のドロップダウンを使用して言語を変更してみましょう。
- コマンドパレットを使用して現在のセルの下に新しいセルを挿入します。
- 言語スイッチャーを使用してその言語をSQLに変更します。セルの上部に
%sqlが表示されることに注目してください。これはマジックコマンドと呼ばれます。 -
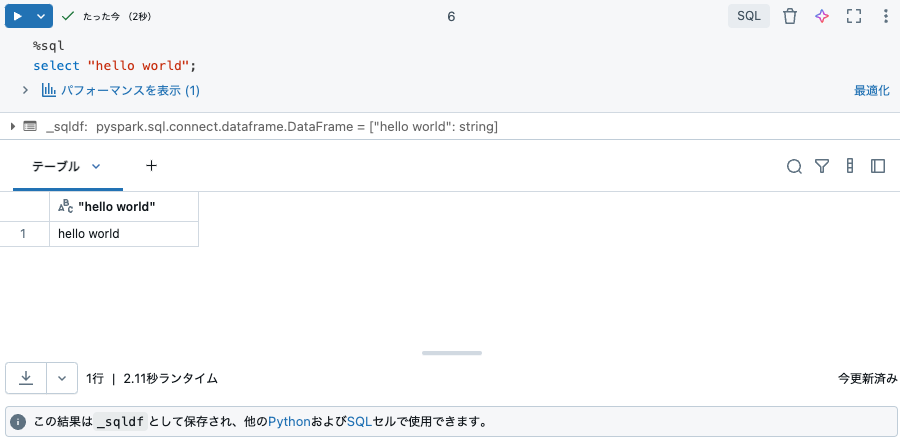
select "hello world";と入力して実行ボタンを押します。
%sql
select "hello world";
ステップ 3: データの探索と分析
私たちのベーカリーは複数の国でフランチャイズを展開しており、さまざまな製品を提供しています。
まず、Pythonを使用してサンプルデータをクエリし、最も人気のある製品を特定します。
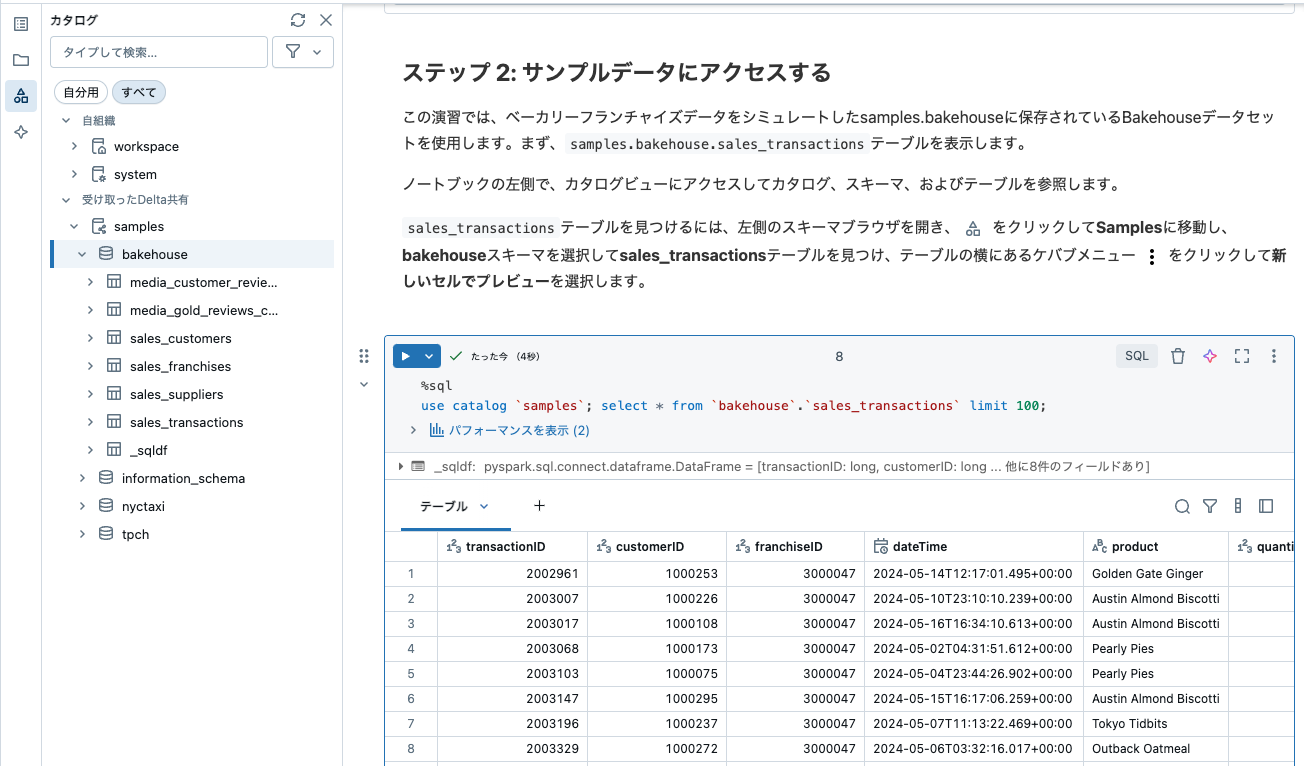
ステップ 2: サンプルデータにアクセスする
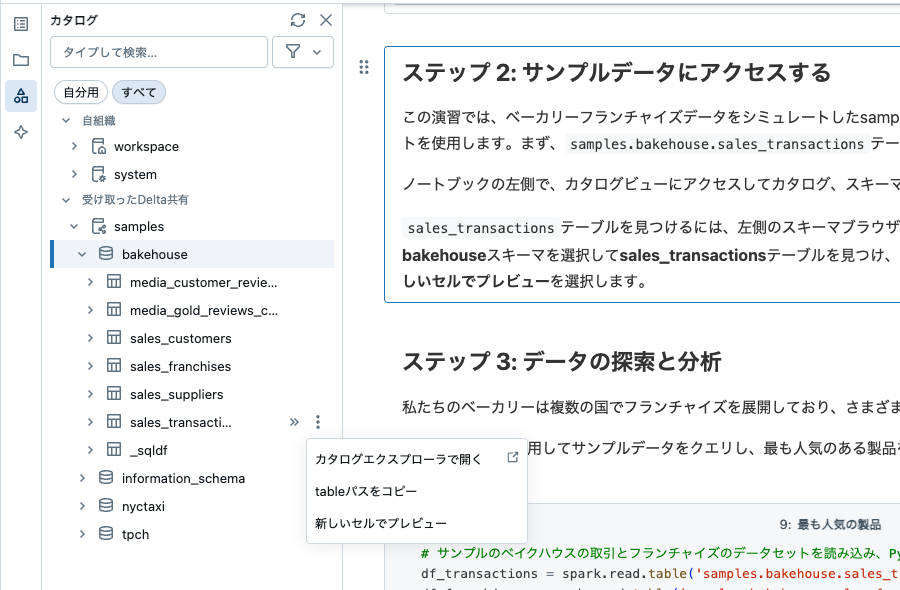
この演習では、ベーカリーフランチャイズデータをシミュレートしたsamples.bakehouseに保存されているBakehouseデータセットを使用します。まず、samples.bakehouse.sales_transactionsテーブルを表示します。
ノートブックの左側で、カタログビューにアクセスしてカタログ、スキーマ、およびテーブルを参照します。
sales_transactionsテーブルを見つけるには、左側のスキーマブラウザを開き、![]() をクリックしてSamplesに移動し、bakehouseスキーマを選択してsales_transactionsテーブルを見つけ、テーブルの横にあるケバブメニュー
をクリックしてSamplesに移動し、bakehouseスキーマを選択してsales_transactionsテーブルを見つけ、テーブルの横にあるケバブメニュー  をクリックして新しいセルでプレビューを選択します。
をクリックして新しいセルでプレビューを選択します。
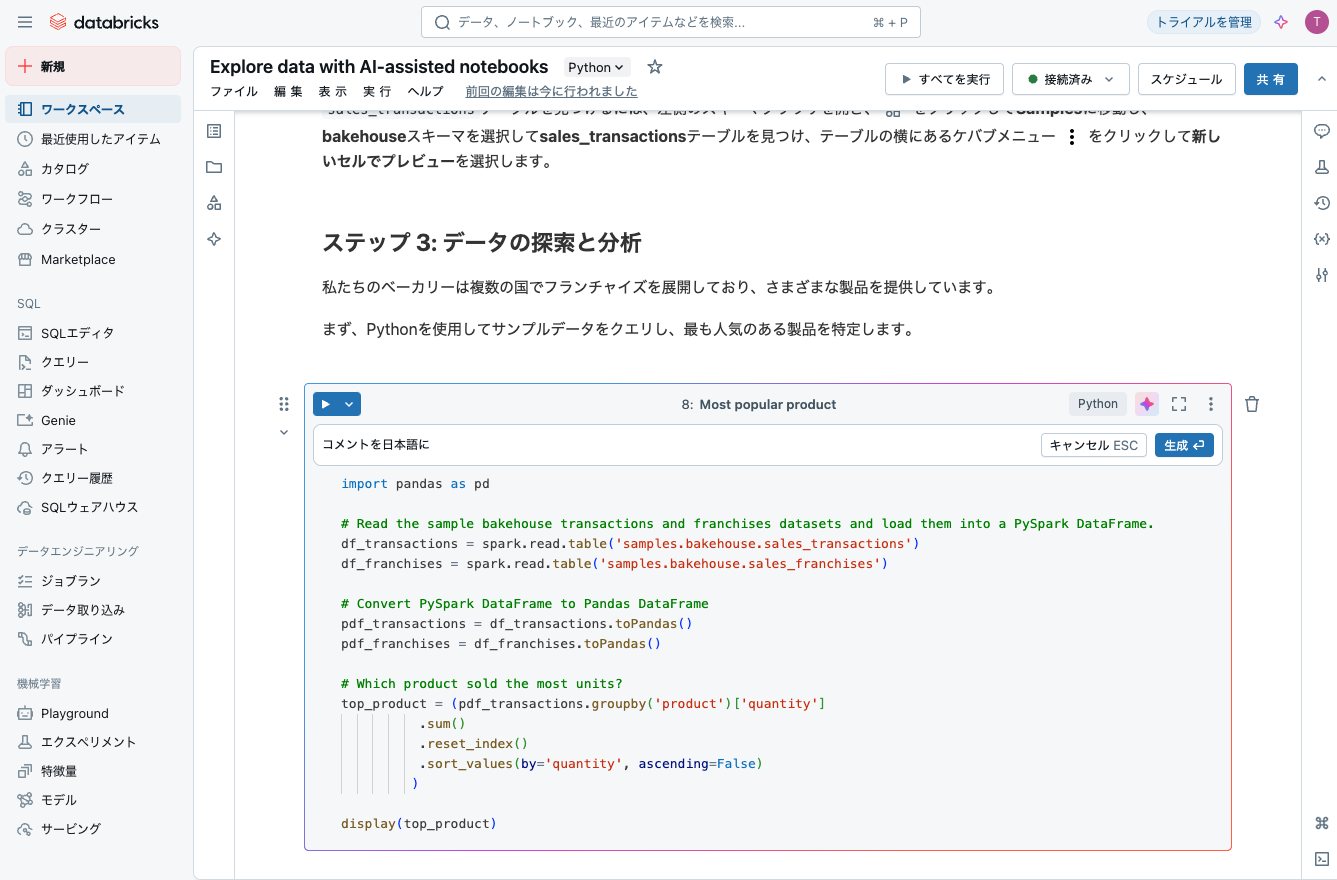
ステップ 3: データの探索と分析
私たちのベーカリーは複数の国でフランチャイズを展開しており、さまざまな製品を提供しています。
まず、Pythonを使用してサンプルデータをクエリし、最も人気のある製品を特定します。
最も人気の製品
コメントを日本語にでコメントも翻訳してもらいます。
# サンプルのベイクハウスの取引とフランチャイズのデータセットを読み込み、PySpark DataFrameにロードする。
df_transactions = spark.read.table('samples.bakehouse.sales_transactions')
df_franchises = spark.read.table('samples.bakehouse.sales_franchises')
# PySpark DataFrameをPandas DataFrameに変換する
pdf_transactions = df_transactions.toPandas()
pdf_franchises = df_franchises.toPandas()
# 最も多くのユニットが売れた製品はどれか?
top_product = (pdf_transactions.groupby('product')['quantity']
.sum()
.reset_index()
.sort_values(by='quantity', ascending=False)
)
display(top_product)
| product | quantity |
|---|---|
| Golden Gate Ginger | 3865 |
| Outback Oatmeal | 3733 |
| Austin Almond Biscotti | 3716 |
| Tokyo Tidbits | 3662 |
| Pearly Pies | 3595 |
| Orchard Oasis | 3586 |
ゴールデンゲートジンジャーは当店のベストセラークッキーです!
その販売で最も業績の良い都市を特定するために、transactionsテーブルとfranchisesテーブルを結合します。これにより、どの都市がゴールデンゲートジンジャーの販売数が最も多いかを分析できます。
franchisesとtransactionsテーブルの結合
## ゴールデンゲートジンジャーのユニットを最も多く販売した都市
top_city = (pdf_franchises.merge(pdf_transactions[pdf_transactions['product'] == 'Golden Gate Ginger'],
on='franchiseID',
how='right')
.groupby('city')['quantity']
.sum()
.reset_index()
.sort_values(by='quantity', ascending=False)
.rename(columns={'quantity': 'units'})
)
display(top_city)
| city | units |
|---|---|
| Rome | 474 |
| Stockholm | 316 |
| Sydney | 184 |
| San Francisco | 116 |
| Kanazawa | 93 |
| Kyoto | 92 |
| Osaka | 92 |
| Chicago | 90 |
| Washington D.C. | 83 |
| Nashville | 83 |
| Boston | 81 |
| Los Angeles | 81 |
| Chiba | 80 |
| Nagoya | 79 |
| Aomori | 79 |
| Las Vegas | 78 |
| Okayama | 78 |
| Seattle | 77 |
| Gold Coast | 75 |
| Berlin | 75 |
| Kobe | 74 |
| Austin | 74 |
| Paris | 73 |
| Philadelphia | 72 |
| Adelaide | 70 |
| Niigata | 68 |
| Vancouver | 64 |
| Portland | 64 |
| Matsuyama | 64 |
| Melbourne | 63 |
| Kagoshima | 63 |
| Honolulu | 62 |
| Miami | 62 |
| Amsterdam | 61 |
| Suita | 60 |
| Denver | 59 |
| Hiratsuka | 51 |
| Brisbane | 50 |
| New Orleans | 49 |
| Kumamoto | 46 |
| Fukuoka | 45 |
| Sendai | 40 |
| Tokyo | 40 |
| Perth | 37 |
| Hiroshima | 29 |
| Naha | 10 |
| Sapporo | 9 |
ステップ 4: 結果テーブルの検索とフィルタリング
結果の並べ替え:
上の結果テーブルで列名にカーソルを合わせ、表示される矢印アイコンをクリックしてその列の値で並べ替えます。
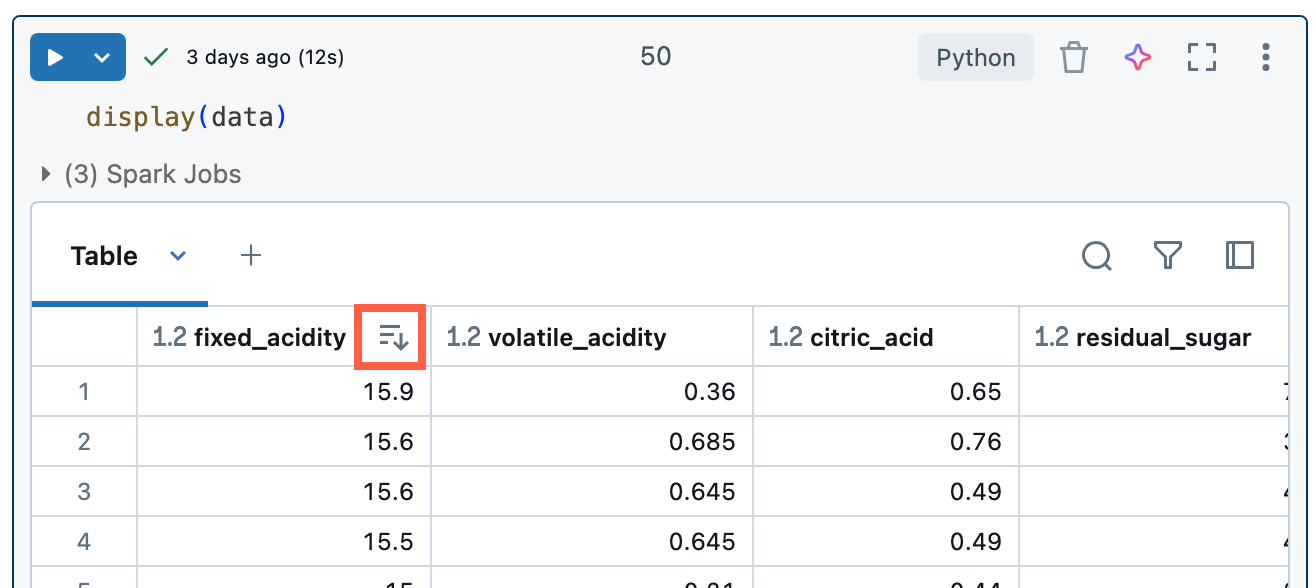
- 上の結果テーブルを昇順に並べ替えて、ゴールデンゲートジンジャークッキーの販売数が最も少ない都市を見つけてみてください。
結果のフィルタリング:
フィルタを作成するには、セル結果の右上にある ![]() をクリックします。表示されるダイアログで、フィルタリングする列と適用するフィルタルールおよび値を選択します。
をクリックします。表示されるダイアログで、フィルタリングする列と適用するフィルタルールおよび値を選択します。
-
units > 100と入力して、ゴールデンゲートジンジャーを100単位以上販売しているすべての都市をフィルタリングしてみてください。
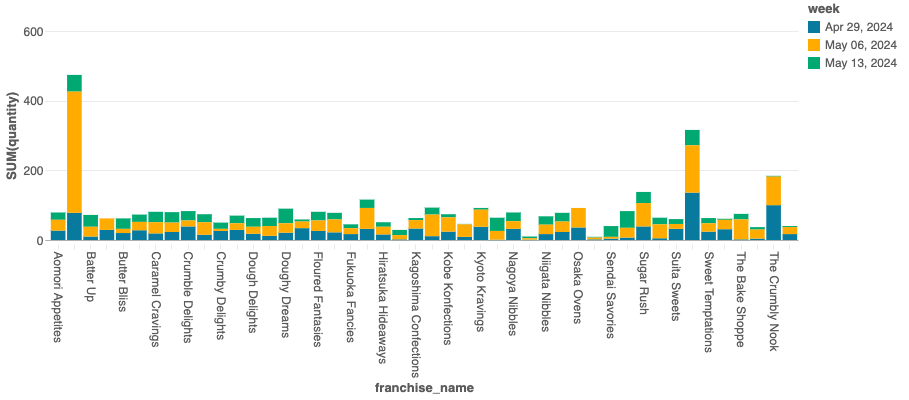
ステップ 5: データの可視化
全店舗におけるゴールデンゲートジンジャーの週間販売を可視化しましょう。
- 下のセルを実行してゴールデンゲートジンジャーの販売データを表示します。
- 可視化を作成するには、結果の上部にある + ボタンをクリックし、可視化ビルダーの手順に従います。
- 好みのチャートタイプを選択し、チャートの値を設定して可視化を完成させます。

- 下の結果セクションでゴールデンゲートジンジャーの販売テーブルをクリックして、サンプルの可視化を表示します。
%sql
-- すべての場所で毎週どれだけのGolden Gate Gingerが販売されているか?
SELECT
f.name as franchise_name,
date_trunc('week',datetime) as week,
sum(quantity) as quantity
FROM samples.bakehouse.sales_transactions t join samples.bakehouse.sales_franchises f on t.franchiseID = f.franchiseID
WHERE product = 'Golden Gate Ginger'
GROUP BY 1,2
-- 結果セクションのGolden Gate Ginger Salesタブをクリック
ステップ 6: コード提案のためのDatabricks Assistantの使用
ノートブックには、コンテキストに応じたDatabricks Assistantが装備されており、自然言語を使用してコードの生成、説明、および修正を支援します。
アシスタントを使用するには、新しいセルを作成し、CMD+Iをクリックするか、新しいセルの右上にある![]() をクリックします。
をクリックします。
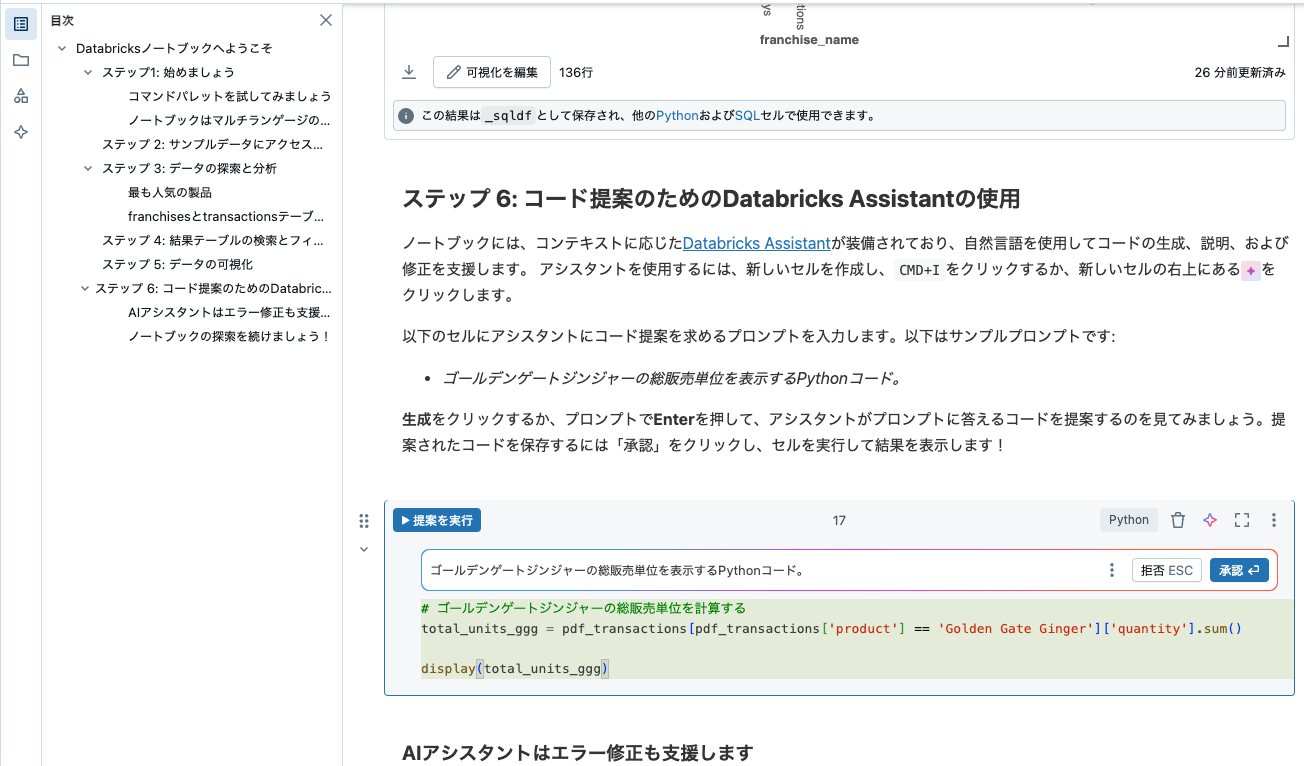
以下のセルにアシスタントにコード提案を求めるプロンプトを入力します。以下はサンプルプロンプトです:
- ゴールデンゲートジンジャーの総販売単位を表示するPythonコード。
生成をクリックするか、プロンプトでEnterを押して、アシスタントがプロンプトに答えるコードを提案するのを見てみましょう。提案されたコードを保存するには「承認」をクリックし、セルを実行して結果を表示します!
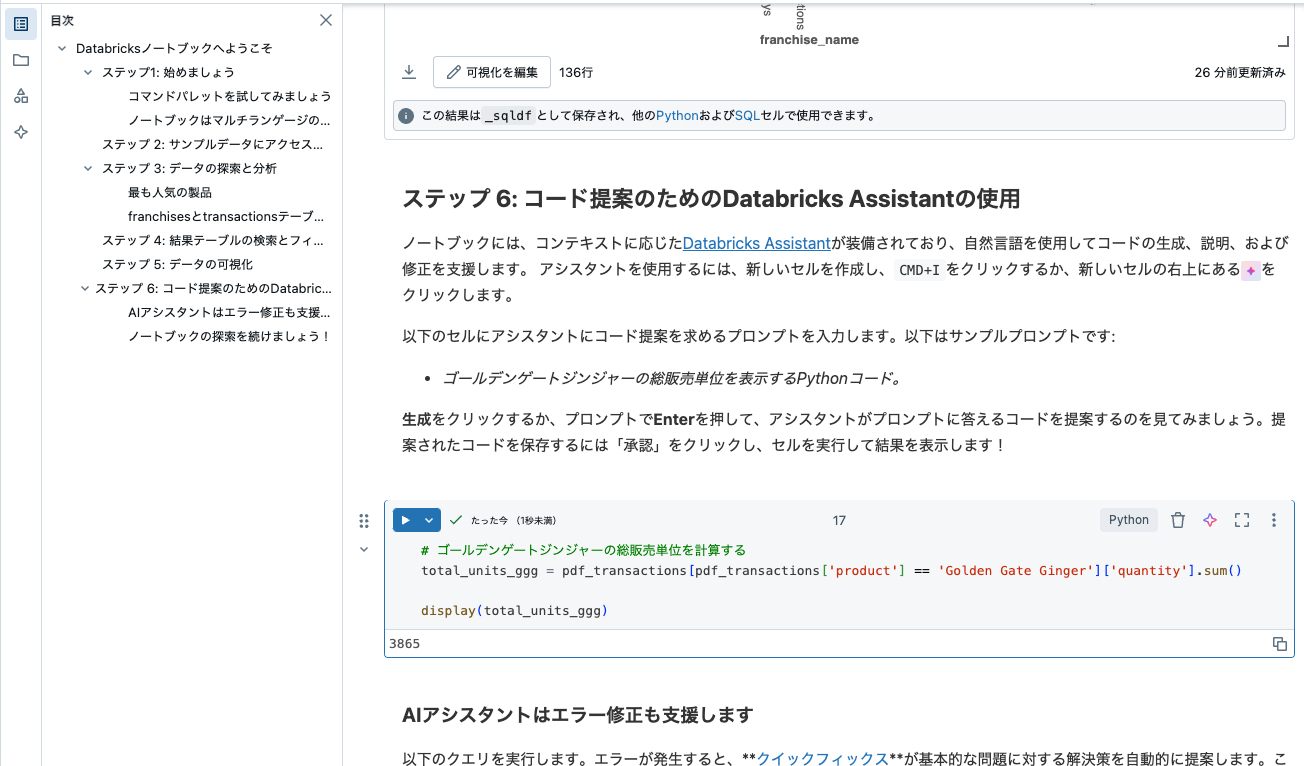
AIアシスタントはエラー修正も支援します
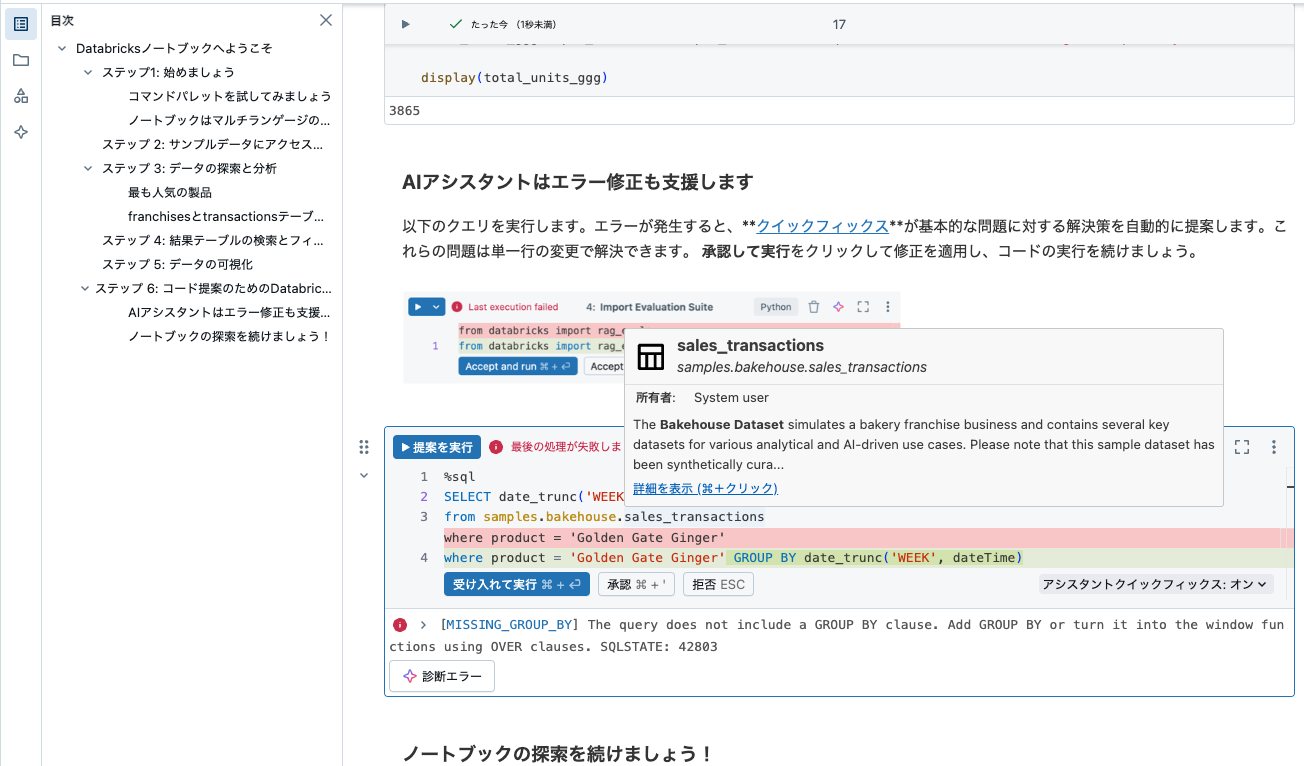
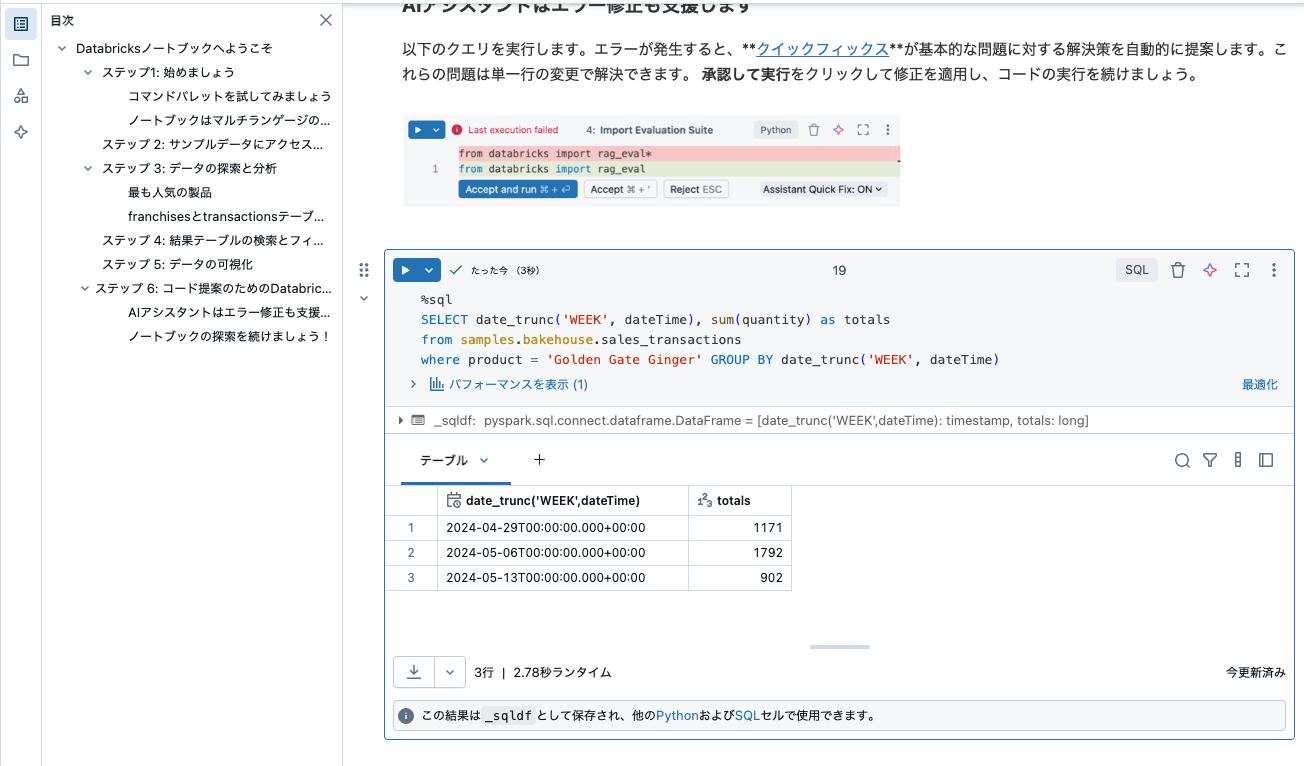
以下のクエリを実行します。エラーが発生すると、クイックフィックス が基本的な問題に対する解決策を自動的に提案します。これらの問題は単一行の変更で解決できます。
承認して実行をクリックして修正を適用し、コードの実行を続けましょう。

セットアップしてからここまでで約9分です。途中で翻訳もしています。
初めてのAIエージェントの構築
AI駆動のデータインテリジェンスでスマートなクッキーフランチャイズを実現
このデモへようこそ。ここでは、クッキーフランチャイズビジネス向けに強力なAIエージェントを構築します。このエージェントは、フランチャイズオーナーが顧客データを分析し、ターゲットを絞ったマーケティングキャンペーンを作成し、データ駆動の販売戦略を開発して運営を改善するための支援を目的としています。
データインテリジェンスを使用することで、フランチャイズはトップセラー商品を理解し、実際の販売データに基づいたキャンペーンを作成することができます。
このノートブックでは、Unity Catalogでシンプルな関数を作成および登録し、インサイトへのガバナンスされたアクセスを提供する方法を案内します。その後、これらの関数を使用してチャットベースのAIを構築し、フランチャイズがよりスマートでデータ駆動のキャンペーンを開発できるようにします。
以下の内容をカバーします:
- Unity CatalogでのSQL関数の作成と登録
- Langchainを使用してこれらの関数をツールとして統合
- これらのツールを実行し、複雑な質問に取り組むAIエージェントの構築
%pip install -q langchain-community==0.2.16 langchain-openai==0.1.19 mlflow==2.15.1 databricks-agents==0.5.0 langchain==0.2.16
%restart_python
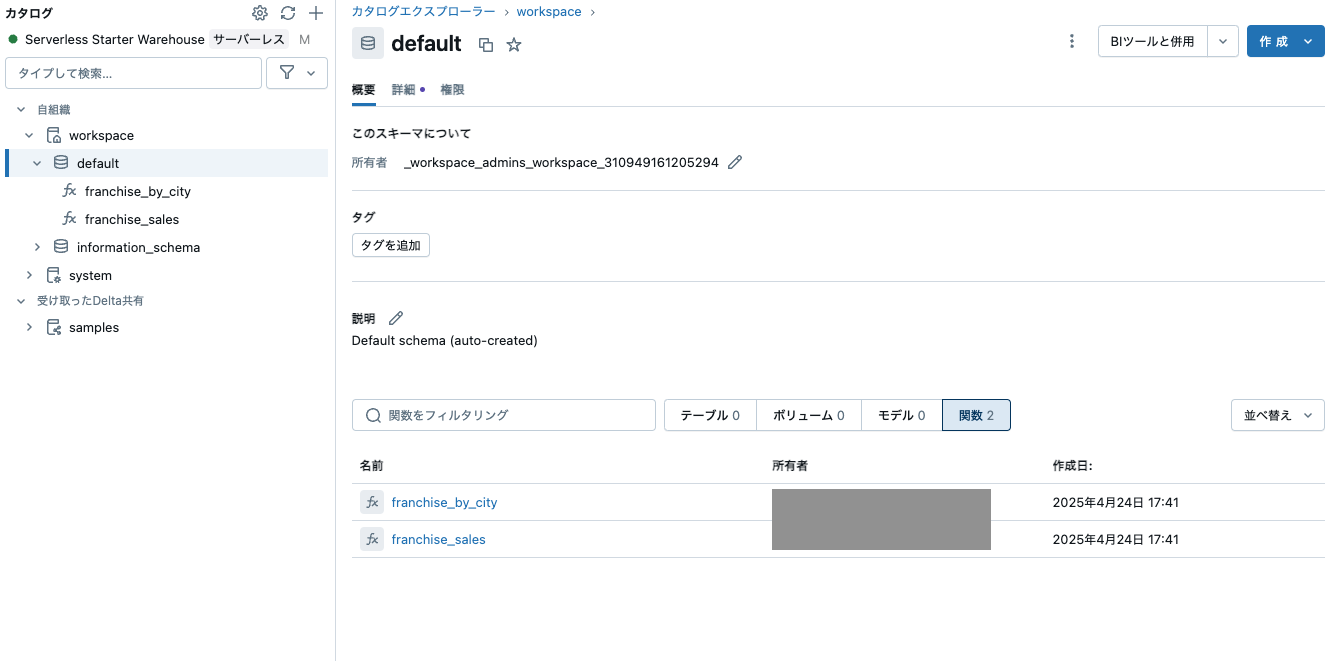
ステップ1: Unity Catalogでの関数/ツールの作成
次の2つの関数を作成します:
- 都市名に基づいてIDを取得するシンプルなクエリ
- 指定されたIDの売上データを返す集計クエリ
Franchise by City関数の作成
%sql
-- まず、既に存在しないことを確認します
DROP FUNCTION IF EXISTS workspace.default.franchise_by_city;
-- 最初の関数を作成します。これは都市名を入力として受け取り、その都市にあるフランチャイズのテーブルを返します。
-- 後でエージェントをガイドするために、入力パラメータにコメントを追加しました。
CREATE OR REPLACE FUNCTION
workspace.default.franchise_by_city(
city_name STRING COMMENT '検索する都市'
)
returns table(franchiseID BIGINT, name STRING, size STRING)
return
(SELECT franchiseID, name, size from samples.bakehouse.sales_franchises where city=city_name
order by size desc)
Franchise by City関数のテスト
%sql
-- 先ほど作成した関数をテストします
SELECT * from workspace.default.franchise_by_city('Seattle')
| franchiseID | name | size |
|---|---|---|
| 3000038 | Dough Delights | XXL |
| 3000014 | Sweet Temptations | L |
Sales関数の作成
%sql
-- 再度存在するか確認します
DROP FUNCTION IF EXISTS workspace.default.franchise_sales;
-- この関数はIDを入力として受け取り、今回は集計を行い、そのfranchise_idの売上を返します。
CREATE OR REPLACE FUNCTION
workspace.default.franchise_sales (
franchise_id BIGINT COMMENT '検索するフランチャイズのID'
)
returns table(total_sales BIGINT, total_quantity BIGINT, product STRING)
return
(SELECT SUM(totalPrice) AS total_sales, SUM(quantity) AS total_quantity, product
FROM samples.bakehouse.sales_transactions
WHERE franchiseID = franchise_id GROUP BY product)
Sales関数のテスト
%sql
-- sales関数が機能するか確認します - 前のクエリからfranchise_idを使用します
SELECT * FROM workspace.default.franchise_sales(3000038)
| total_sales | total_quantity | product |
|---|---|---|
| 138 | 46 | Pearly Pies |
| 348 | 116 | Outback Oatmeal |
| 108 | 36 | Austin Almond Biscotti |
| 108 | 36 | Orchard Oasis |
| 51 | 17 | Tokyo Tidbits |
| 189 | 63 | Golden Gate Ginger |
これらの関数は、画面右のカタログからアクセスできるカタログエクスプローラで確認できます。
import mlflow
import langchain
# エージェントの実行中に何が起こるかを理解するためにこれを有効にします
mlflow.langchain.autolog(disable=False)
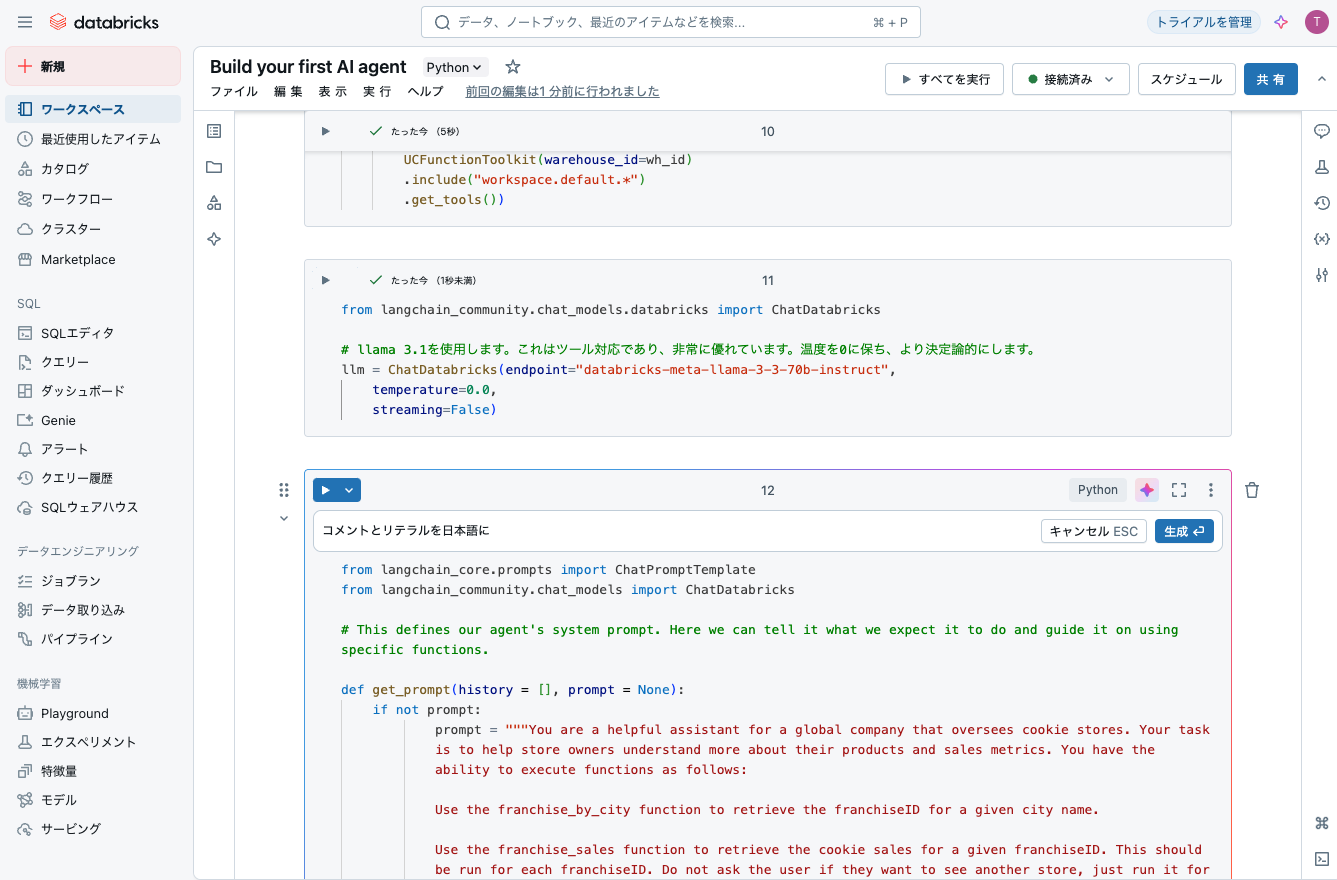
ステップ2: エージェントの作成
このステップでは、エージェントの3つの重要な部分を定義します:
- エージェントが使用するツール
- エージェントの「頭脳」として機能するLLM
- エージェントのタスクのガイドラインを定義するシステムプロンプト
from langchain_community.tools.databricks import UCFunctionToolkit
from databricks.sdk import WorkspaceClient
import pandas as pd
import time
w = WorkspaceClient()
def get_shared_warehouse():
w = WorkspaceClient()
warehouses = w.warehouses.list()
for wh in warehouses:
if wh.name == "Serverless Starter Warehouse":
if wh.num_clusters == 0:
w.warehouses.start(wh.id)
time.sleep(5)
return wh
else:
return wh
raise Exception("Couldn't find any Warehouse to use. Please start the serverless SQL Warehouse for this code to run.")
wh_id = get_shared_warehouse().id
def get_tools():
return (
UCFunctionToolkit(warehouse_id=wh_id)
.include("workspace.default.*")
.get_tools())
from langchain_community.chat_models.databricks import ChatDatabricks
# llama 3.1を使用します。これはツール対応であり、非常に優れています。温度を0に保ち、より決定論的にします。
llm = ChatDatabricks(endpoint="databricks-meta-llama-3-3-70b-instruct",
temperature=0.0,
streaming=False)
コメントとリテラルを日本語にで、コメントに加えて文字列定数も翻訳します。
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatDatabricks
# これはエージェントのシステムプロンプトを定義します。ここで、期待することを伝え、特定の関数を使用するように指示できます。
def get_prompt(history = [], prompt = None):
if not prompt:
prompt = """あなたはクッキーストアを監督するグローバル企業の役に立つアシスタントです。あなたの任務は、店舗オーナーが製品と販売指標について理解するのを助けることです。次のように関数を実行する能力があります:
franchise_by_city関数を使用して、指定された都市名のfranchiseIDを取得します。
franchise_sales関数を使用して、指定されたfranchiseIDのクッキー販売を取得します。これは各franchiseIDに対して実行する必要があります。ユーザーに他の店舗を見たいかどうかを尋ねず、すべてのfranchiseIDに対して実行してください。
各ステップで関数を呼び出し、結果が取得されたことを確認してから次のステップに進むようにしてください。ツールについてユーザーに言及しないでください。ユーザーが尋ねていることだけに答えてください。"""
return ChatPromptTemplate.from_messages([
("system", prompt),
("human", "{messages}"),
("placeholder", "{agent_scratchpad}"),
])
from langchain.agents import AgentExecutor, create_openai_tools_agent, Tool, load_tools
prompt = get_prompt()
tools = get_tools()
agent = create_openai_tools_agent(llm, tools, prompt)
# ここで定義された要素を収集し、それらを組み合わせてエージェントを作成します
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
from operator import itemgetter
from langchain.schema.runnable import RunnableLambda
from langchain_core.output_parsers import StrOutputParser
# 入力(messages)をエージェントに渡し、出力(output)を文字列として収集する非常に基本的なチェーン
agent_str = ({ "messages": itemgetter("messages")} | agent_executor | itemgetter("output") | StrOutputParser() )
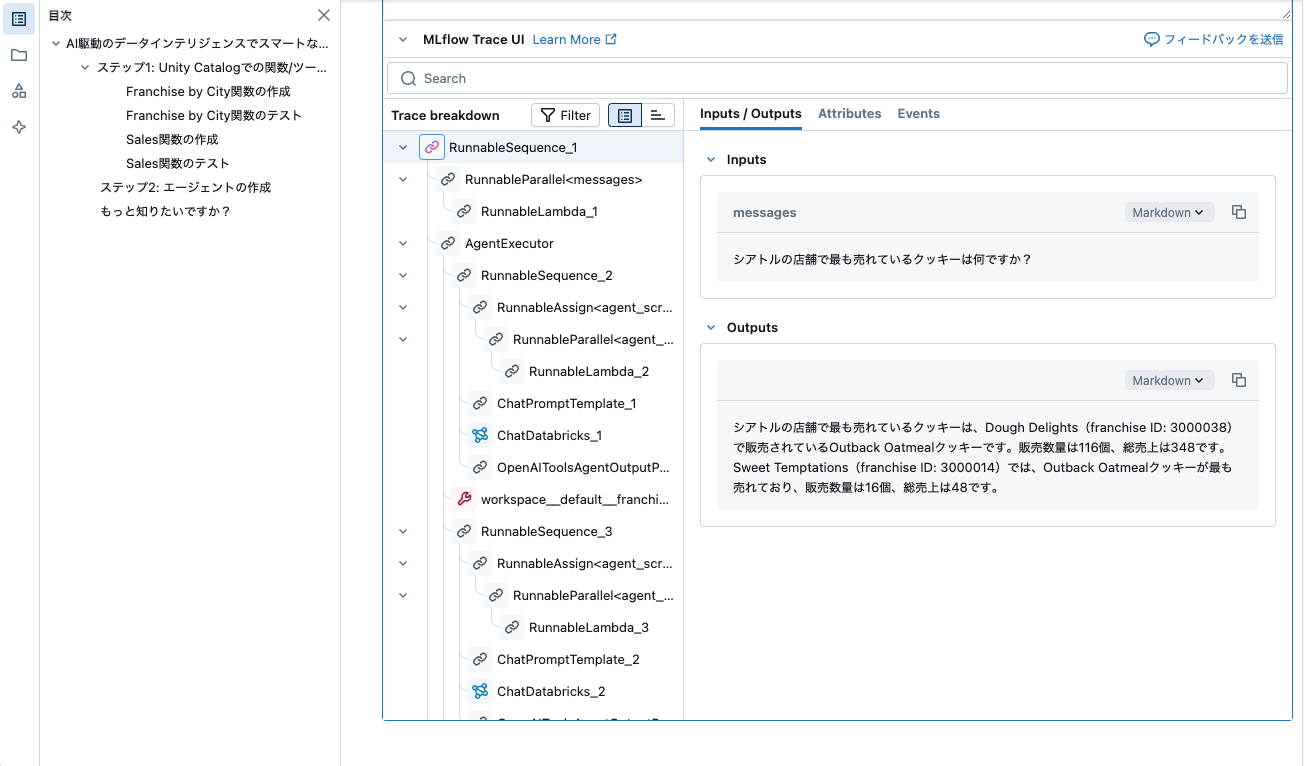
# 複合AIエージェントにInstagramの投稿を生成させましょう。これには以下が必要です:
# 1. シアトルにある店舗を調べる
# 2. 売上データを使用してその店舗で最も売れているクッキーを調べる
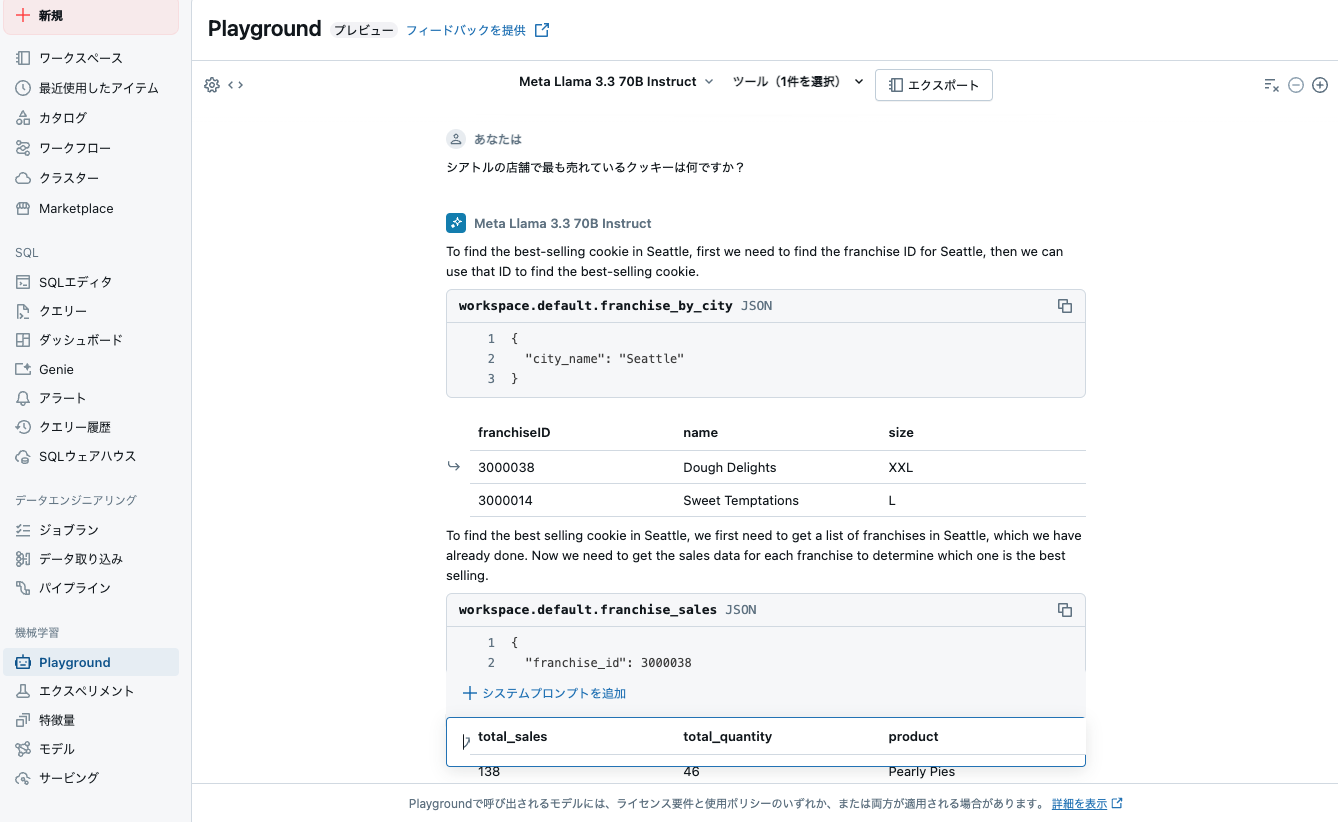
answer=agent_str.invoke({"messages": "シアトルの店舗で最も売れているクッキーは何ですか?"})
> Entering new AgentExecutor chain...
Invoking: `workspace__default__franchise_by_city` with `{'city_name': 'Seattle'}`
{"format": "CSV", "value": "franchiseID,name,size\n3000038,Dough Delights,XXL\n3000014,Sweet Temptations,L\n", "truncated": false}
Invoking: `workspace__default__franchise_sales` with `{'franchise_id': 3000038}`
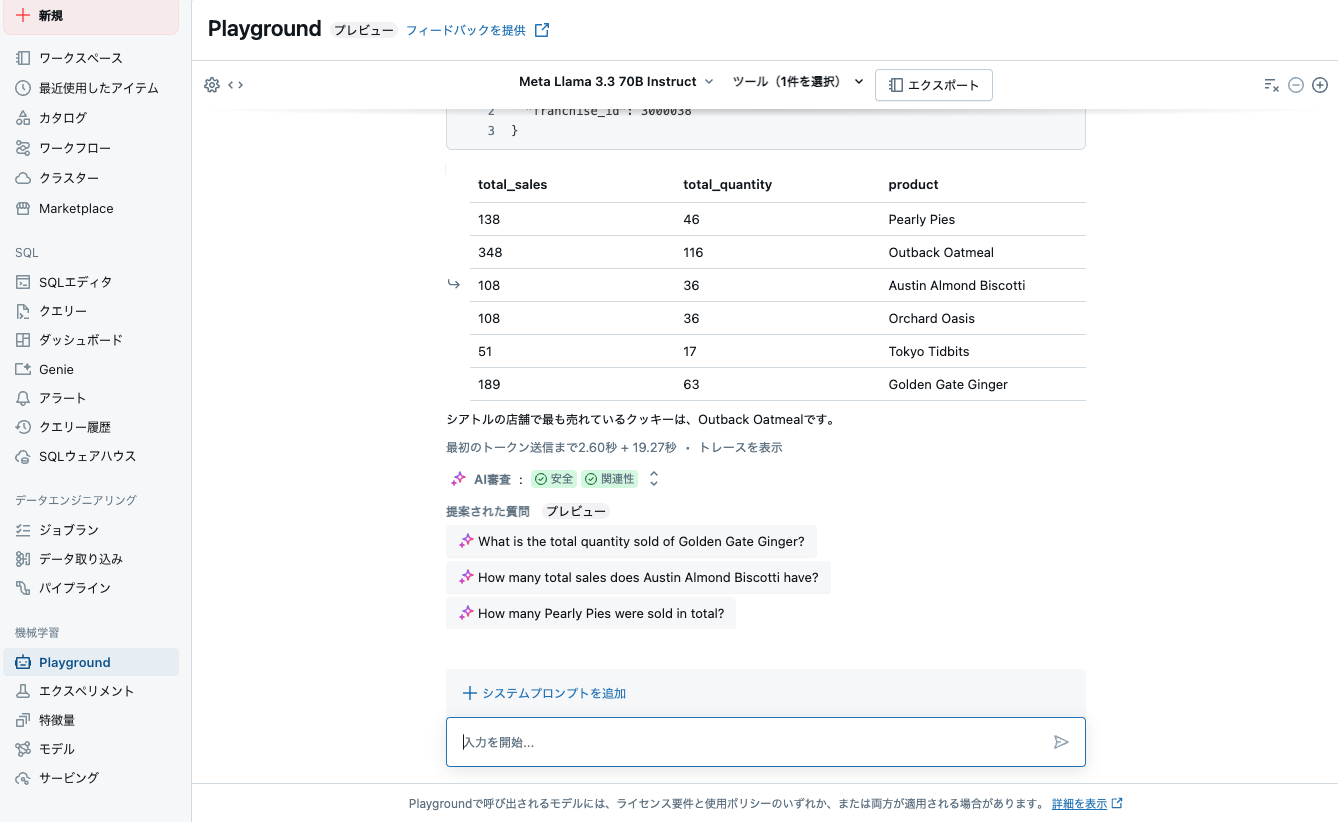
{"format": "CSV", "value": "total_sales,total_quantity,product\n108,36,Austin Almond Biscotti\n138,46,Pearly Pies\n189,63,Golden Gate Ginger\n348,116,Outback Oatmeal\n51,17,Tokyo Tidbits\n108,36,Orchard Oasis\n", "truncated": false}
Invoking: `workspace__default__franchise_sales` with `{'franchise_id': 3000014}`
{"format": "CSV", "value": "total_sales,total_quantity,product\n27,9,Austin Almond Biscotti\n42,14,Pearly Pies\n42,14,Golden Gate Ginger\n48,16,Outback Oatmeal\n36,12,Tokyo Tidbits\n30,10,Orchard Oasis\n", "truncated": false}シアトルの店舗で最も売れているクッキーは、Dough Delights(franchise ID: 3000038)で販売されているOutback Oatmealクッキーです。販売数量は116個、総売上は348です。Sweet Temptations(franchise ID: 3000014)では、Outback Oatmealクッキーが最も売れており、販売数量は16個、総売上は48です。
> Finished chain.
"シアトルの店舗で最も売れているクッキーは、Dough Delights(franchise ID: 3000038)で販売されているOutback Oatmealクッキーです。販売数量は116個、総売上は348です。Sweet Temptations(franchise ID: 3000014)では、Outback Oatmealクッキーが最も売れており、販売数量は16個、総売上は48です。"
もっと知りたいですか?
- アクション中の完全なデモをこちらでご覧ください。
- 次のステップに進んで、コンテキストの深みを加えたRAGベースのチャットボットを構築しましょう!
セットアップしてからここまでで約16分です。途中で翻訳もしています。
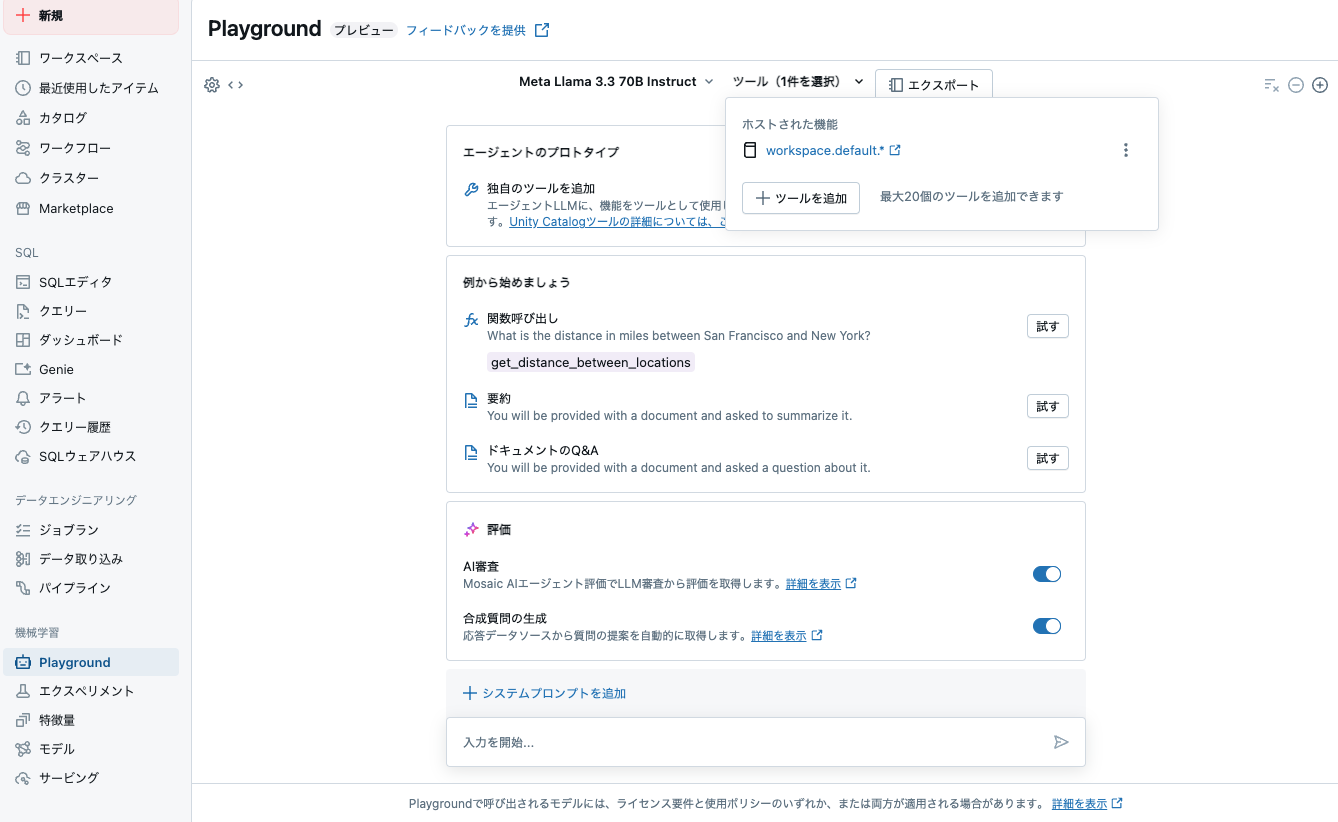
なお、ここで定義したツールは、AI Playgroundでも動作確認することができます。
まとめ
ここまでで費用は一円もかかっていません。Genie、ノートブック、AIエージェントを是非お試しください!