An Introduction to Time Series Forecasting with Generative AI | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
生成AIによる時系列予測のご紹介
時系列予測は、この数十年間において、企業のリソース計画の礎となってきました。将来的な需要の予測は、在庫のユニット数、雇用すべき労働者の数、プロダクションや補充のインフラストラクチャに対する資本投資、商品やサービスの値付けのような重要な意思決定をガイドします。これらや数多くの他のビジネス上の意思決定においては、正確な需要予測は重要なものとなります。
しかし、予測が完璧であったことは稀です。2010年代半ばには、計算能力の制限や高度な予測能力へのアクセスが減的であったことに対応していた多くの企業は、予測の精度はたった50-60%であったと報告しています。しかし、クラウドが幅広く導入され、よりアクセス可能な技術が導入され、気候やイベントデータのような外部データソースへのアクセスが改善されたことで、企業では改善し始めています。
生成AIの時代に突入することで、企業にさらなる改善をもたらす能力がある時系列トランスフォーマーと呼ばれる新たなモデルのクラスが出現しています。文章の次の単語の予測に長けている(ChatGPTのような)大規模言語モデルと同様に、時系列トランスフォーマーは、数値のシーケンスの次の値を予測します。時系列の膨大なボリュームのデータが公開されることで、これらのモデルはこれらの系列における値間の関係性の些細なパターンをピックアップする専門家となり、様々な領域での成功を示しています。
この記事では、マネージャ、アナリスト、データサイエンティストが動作原理を理解する基礎を持てる助けになるように、このクラスの予測モデルのハイレベルな紹介を行います。そして、Databricksでデータを保持している企業で、自身の予測要件に合わせてこれらの最も人気なモデルのいくつかを容易に活用できるのかをデモンストレーションするために、公開データをベースに構築した一連のノートブックへのアクセスを提供します。これによって、企業でより優れた予測精度を導き出すために、生成AIのポテンシャルを活用できるようになればと考えています。
時系列トランスフォーマーの理解
生成AIモデルは、膨大な数の入力が予測値に到達するまでに様々な方法で組み合わされる複雑な機械学習モデルである、ディープニューラルネットワークの一形態です。入力を組み合わせて正確な予測に到達するために、モデルが学習を行う機構は、モデルのアーキテクチャと呼ばれます。
生成AIの勃興につながったディープニューラルネットワークのブレークスルーは、トランスフォーマーと呼ばれる特化されたモデルアーキテクチャのデザインです。他のディープニューラルネットワークアーキテクチャとトランスフォーマーがどのように違うのかの正確な詳細は非常に複雑ですが、簡単に言うと、トランスフォーマーは長いシーケンスにおけるあたいの間の複雑な関係性をピックアップすることに非常に長けていると言えます。
時系列トランスフォーマーをトレーニングするには、適切にアーキテクトされたディープニューラルネットワークは、大規模な時系列に晒されることになります。数十億の時系列の値が利用できない場合、数百万の時系列データでトレーニングする機会があった場合には、これらのデータセットにある関係性の複雑なパターンを学習します。未知の時系列が与えられた際、当該の時系列に類似の関係性のパターンがあるのかを特定したり、シーケンスの新たな値を予測するために、この基本知識を活用することができます。
このような大規模データからの関係性の学習プロセスは、事前トレーニングと呼ばれます。事前トレーニングでモデルによって獲得された知識は高度に汎化できるので、基盤モデルと呼ばれる事前学習済みモデルは、追加トレーニングなしに未知の時系列に対して活用することができます。とはいえ、
ファインチューニングと呼ばれるプロセスで、企業固有のデータを用いて追加のトレーニングを行うことで、いくつかのケースでは企業でさらに優れた予測精度を達成する助けとなります。どちらの方法においても、モデルが満足できる状態になったとみなしたら、企業はシンプルに時系列とともに提供することになり、次に来るのは何か? と尋ねることになります。
一般的な時系列の課題への対応
時系列トランスフォーマーに対するハイレベルの理解は納得いくものかもしれませんが、多くの予測実践者は即座に3つの質問をすることになるかと思います。はじめに、2つの時系列が類似のパターンに従っている場合でも、それらは全く異なるスケールでオペレーションされているかもしれません。トランスフォーマーはこの問題をどのように克服するのでしょうか?2つ目に、多くの時系列モデルでは、検討すべき日次、週次、年次の季節性パターンがあります。モデルはこれらのパターンを検知することをどのように理解するのでしょうか?3つ目に、多くの時系列データは、外部要因の影響を受けます。予測生成プロセスにこのようなデータをどのように組み込むことができるのでしょうか?
これらの課題の1つ目は、スケーリングと呼ばれる一連のテクニックを用いることで、すべての時系列データを数学的に標準化することで対応できます。このメカニズムはそれぞれのアーキテクチャの内部的なものですが、基本的には入力される時系列の値は標準スケールに変換され、モデルは基本的な知識に基づいてデータのパターンを認識することができます。予測が行われ、これらの予測結果はオリジナルデータのオリジナルのスケールに戻されます。
季節性パターンに関しては、トランスフォーマーアーキテクチャのコアにあるのはself-attentionと呼ばれるプロセスがあります。このプロセスは非常に複雑ですが、基本的にこの機構によって、モデルはどの特定の事前の値が特定の未来の値に影響を与えるのかの度合いを学習することができます。
季節性に対するソリューションのように聞こえるかもしれませんが、時系列データの入力をどのように分割するのかに基づいて、季節性の低レベルのパターンのピックアップする能力に違いがあることを理解することが重要です。トークナイゼーションと呼ばれるプロセスを通じて、時系列データの値はトークンと呼ばれる単位に分割されます。トークンは単一の時系列の値であったり、(パッチと呼ばれる)値の短いシーケンスである場合があります。
トークンのサイズは、季節性パターンが検知される最低レベルの粒度を決定します。(また、トークナイゼーションでは欠損地への対応ロジックも定義します。)特定のモデルを探索する際には、あなたのデータにモデルが適しているかどうかを理解するために、時にはトークナイゼーションに関する技術情報を参照することが重要となります。
最後に、外部変数に関しては、時系列トランスフォーマーでは、さまざまなアプローチを活用しています。いくつかのモデルでは、時系列データと関連する外部変数を用いてトレーニングされています。他のモデルにおいては、単一の時系列は複数、並列、関連するシーケンスから構成される場合があることを理解するアーキテクチャになあっています。活用される正確なテクニックに関係なく、これらのモデルのいくつかでは外部変数のサポートが限定的なものがあります。
4つの人気の時系列トランスフォーマーの概要
時系列トランスフォーマーに対するハイレベルの理解をしたので、4つの人気の時系列トランスフォーマーモデルを見ていきましょう:
Chronos
Chronosは、Amazonによるオープンソースの事前学習済み時系列予測モデルです。これらのモデルは、トークン間の独自の関係性パターンを持つ特殊言語として時系列を解釈することで、予測を行う比較的ナイーブなアプローチをとっています。欠損値のサポートを含みますが、外部変数をサポートしない比較的シンプルなアプローチにも関わらず、Chronosモデルファミリーは、汎用予測ソリューションとして印象的な結果を示しています(図1)。
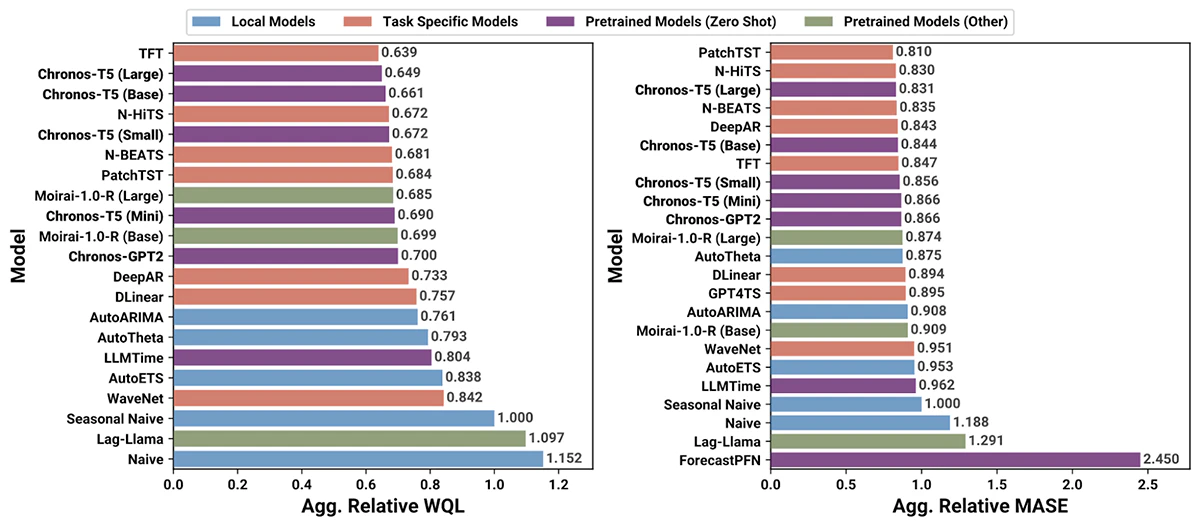
図1. 27のベンチマークデータセットに対するChronosと他の予測モデルの評価メトリクス(出典: https://github.com/amazon-science/chronos-forecasting)
TimesFM
TimesFMは、1000億の現実世界の時系列ポイントで事前トレーニングされた、Google Researchによるオープンソースの基盤モデルです。Chronosと異なりTimesFMには、ユーザーが入出力がどのように構成されているのかに関する、きめ細かいコントロールを用いることができる時系列固有のメカニズムがアーキテクチャに組み込まれています。季節性パターンをどのように検知するのかにインパクトを与えることができますが、モデルに関係する計算時間にもインパクトを与えることができます。TimesFMは、非常にパワフルで柔軟な時系列予測ツールでることを立証しています(図2)。
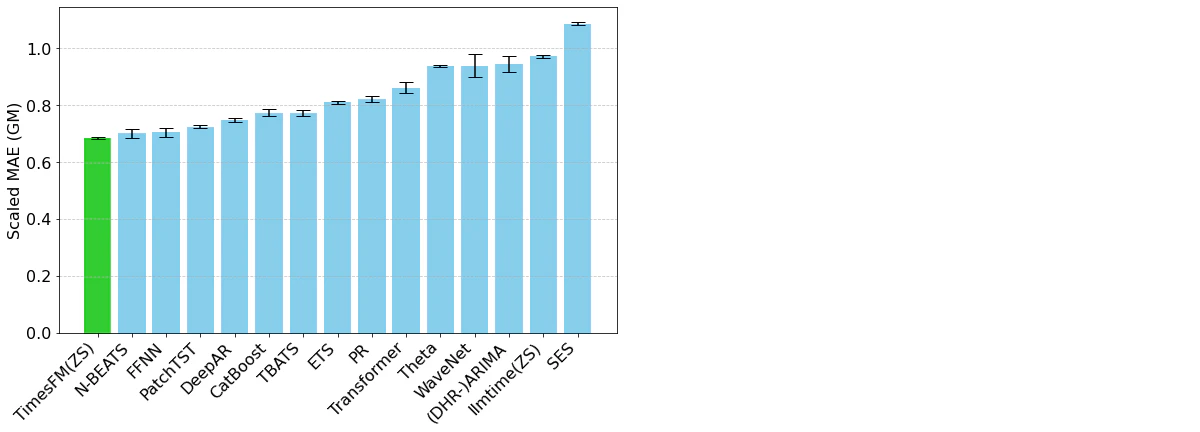
図2. Monash Forecasting Archiveデータセットに対するTimesFMと他のモデルの評価メトリクス(出典: https://research.google/blog/a-decoder-only-foundation-model-for-time-series-forecasting/)
Moirai
Salesforce AI Researchによって開発されたMoiraiは、時系列予測に対する別のオープンソース基盤モデルです。「9つの異なるドメインにまたがる270億の観測値」でトレーニングされたことで、Moiraiは欠損値と外部変数の両方をサポートできる普遍的な予測器として出現しました。変更可能なパッチサイズによって、企業では自身のデータセットの季節性パターンにモデルをチューニングすることができ、適切に適用することで、他のモデルよりも非常に優れたパフォーマンスを示しています(図3)。
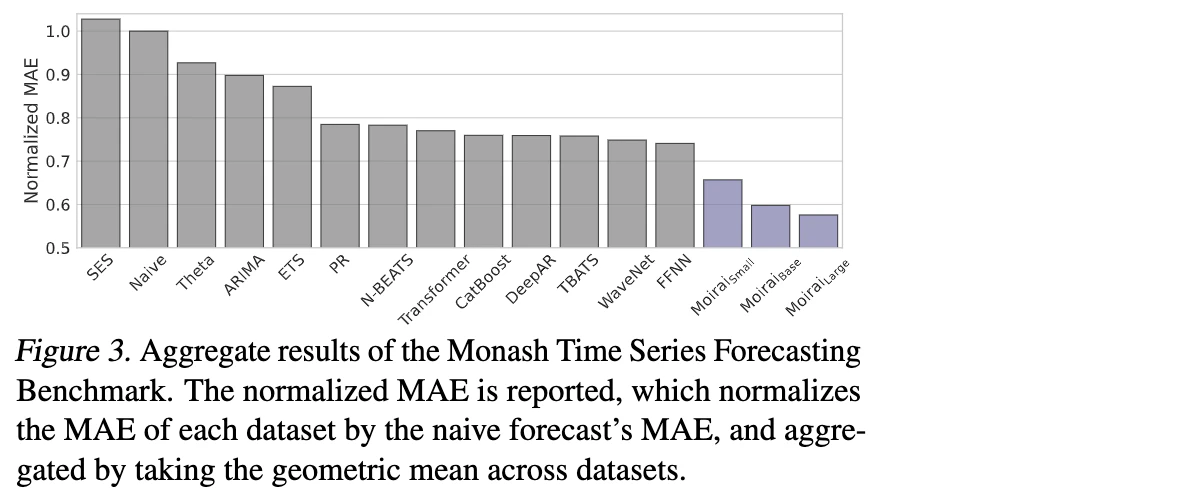
図3. Monash Time Series Forecastingベンチマークに対するMoiraiと他のさまざまなモデルにおける評価メトリクス(出典: https://blog.salesforceairesearch.com/moirai/)
TimeGPT
TimeGPTは、外部変数をサポートしますが、欠損値をサポートしないプロプライエタリなモデルです。使いやすさにフォーカスしており、企業が1行のコードだけで予測を生成できるように、パブリックAPIを通じてホスティングされています。時間的な粒度のレベルが異なる300,000のユニークな時系列に対するモデルのベンチマークにおいては、このモデルは非常に少ない予測レーテンシーでいくつかの印象的な結果をもたらしています(図4)。
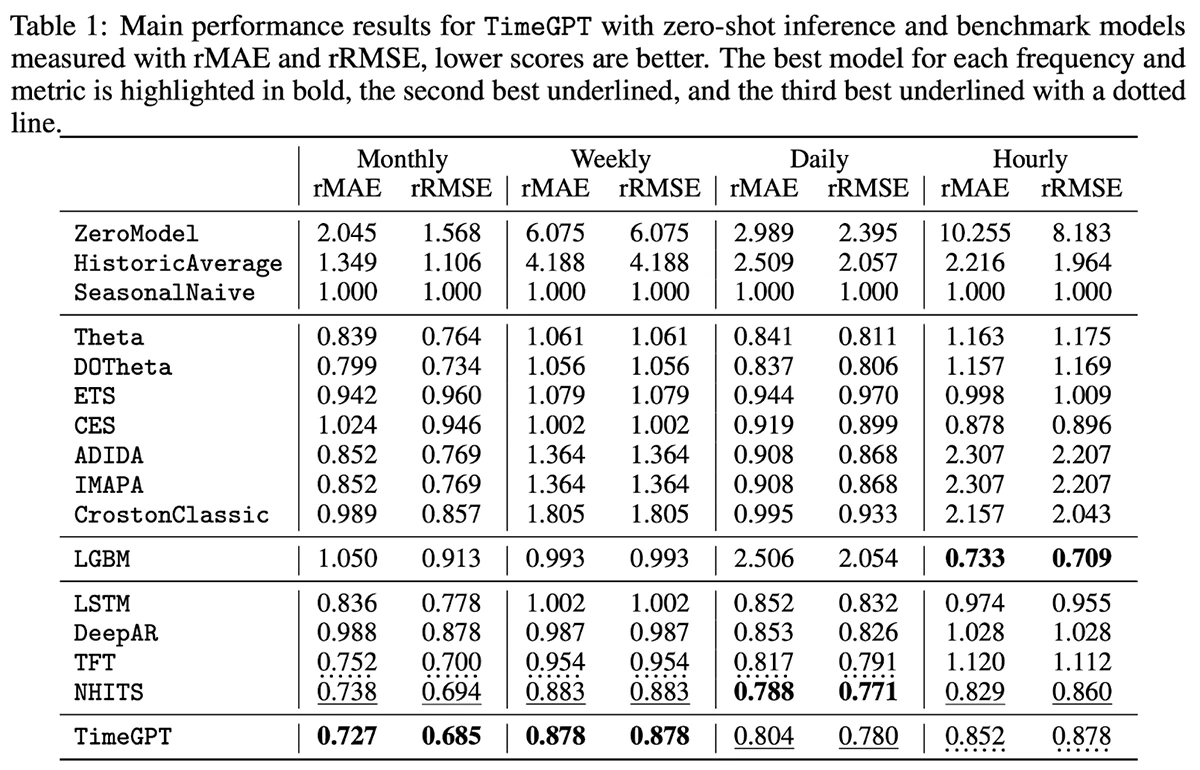
図4. 300,000のユニークな時系列に対するTimeGPTと他のモデルの評価メトリクス(出典: https://arxiv.org/pdf/2310.03589)
Databricksでトランスフォーマーによる予測を始める
数多くのモデルの選択肢があり、今後も提供されることになりますが、多くの企業における重要な疑問は、自分たちのプロプライエタリなデータを用いてこれらのモデルの評価をどのようにスタートしたらいいのか? と言うことでしょう。他の予測アプローチ同様、時系列予測モデルを活用している企業では、予測結果を生成するにはモデルに自分たちの履歴データを与えなくてはならず、それらの予測結果を注意深く評価し、最終的にはアクションを起こせるように、後段のシステムにデプロイする必要があります。
Databricksのスケーラビリティのクラウドリソースの効率的な活用によって、多くの企業においては、予測の取り組み基盤としてDatabricksを活用しており、自分たちのビジネスオペレーションを実行するために、日次で数千万以上の予測値を生成しています。予測モデルの新たなクラスの導入で、この取り組みの本質が変わるわけではなく、シンプルに企業に自分の環境で予測を行うための更なる選択肢を提供しているにすぎません。
だからと言って、これらのモデルに伴う新たなテクニックがないと言うわけではありません。ディープニューラルネットワークアーキテクチャをベースとしているので、これらのモデルの多くはGPUでベストなパフォーマンスを示し、TimeGPTの場合、予測生成プロセスの一部として外部インフラに対するAPI呼び出しが必要となります。しかし、根本的には、企業の過去の時系列データの格納、モデルへのデータ提供、テーブルでクエリーできるようにアウトプットをキャプチャするパターンは不変です。
企業がDatabricks環境でこれらのモデルをどのように活用できるのかの理解を助けるために、上述の4つのモデルで予測をどのように生成できるのかをデモンストレーションする一連のノートブックを準備しました。実践者は活用に慣れるために、これらのノートブックを自由にダウンロードし、Databricks環境で活用することができます。Databricksを活用している企業に自分たちのリソース計画プロセスにおける生成AIの活用の更なる選択肢と予測の取り組みの基盤を提供することで、他の類似のモデルに合わせて含まれているコードをカスタマイズすることができます。
ノートブックシリーズを用いて予測モデリングのためにDatabricksを始めましょう。