先日のイベントでLangfuseというサービスのことを伺いました。
LLMアプリケーションをデバッグ、改善するためのトレース、評価、プロンプト管理、メトリクスを提供しているオープンソースのLLMエンジニアリングプラットフォームとのこと。MLflowやLangSmithと同じようなモチベーションを持つプラットフォームですね。
調べてみたら、Databricksとも連携しているので試してみます。こちらのノートブックを動かします。
翻訳版はこちらです。
Langfuseを使用したDatabricksモデルの可観測性
Databricksは、大規模な言語モデルをホスティングおよび提供するための強力なプラットフォームを提供します。Databricksの提供エンドポイントとLangfuseを組み合わせることで、開発および本番環境でAIワークロードをトレース、監視、および分析できます。
このノートブックでは、Langfuseを使用してDatabricksモデルを使用する3つの異なる方法を示します:
- OpenAI SDK: OpenAI SDKを介してDatabricksモデルエンドポイントを使用します。
- LangChain: LangChainパイプラインでDatabricks LLMインターフェースと統合します。
- LlamaIndex: LlamaIndex内でDatabricksエンドポイントを使用します。
Databricks Model Servingとは?
Databricks Model Servingは、大規模なモデルを本番環境で提供するための自動スケーリングと堅牢なインフラストラクチャを備えています。また、プライベートデータでLLMを微調整することも可能で、データプライバシーを維持しながら独自の情報を活用できます。
Langfuseとは?
Langfuseは、LLMの可観測性と監視のためのオープンソースプラットフォームです。メタデータ、プロンプトの詳細、トークン使用量、レイテンシーなどをキャプチャすることで、AIアプリケーションをトレースおよび監視するのに役立ちます。
1. 依存関係のインストール
始める前に、Python環境に必要なパッケージをインストールします:
- openai: OpenAI SDKを介してDatabricksエンドポイントを呼び出すために必要です。
- databricks-langchain: "OpenAIのような"インターフェースを介してDatabricksエンドポイントを呼び出すために必要です。
- llama-index および llama-index-llms-databricks: LlamaIndex内でDatabricksエンドポイントを使用するために必要です。
- langfuse: Langfuseプラットフォームにトレースデータを送信するために必要です。
%pip install openai langfuse databricks-langchain llama-index llama-index-llms-databricks
%restart_python
2. 環境変数の設定
LangfuseのクレデンシャルとDatabricksのクレデンシャルを環境変数として設定します。以下のダミーキーをそれぞれのアカウントから取得した実際のキーに置き換えてください。
-
LANGFUSE_PUBLIC_KEY/LANGFUSE_SECRET_KEY: Langfuseプロジェクト設定から取得します。 -
LANGFUSE_HOST:https://cloud.langfuse.com(EUリージョン)またはhttps://us.cloud.langfuse.com(USリージョン)。 -
DATABRICKS_TOKEN: Databricksのパーソナルアクセストークン。 -
DATABRICKS_HOST: DatabricksワークスペースのURL(例:https://dbc-xxxxxxx.cloud.databricks.com)。
Langfuseにサインアップして、Organization、Projectを作成することでAPIキーを取得することができます。Secret KeyとPublic Keyをコピーしておきます。
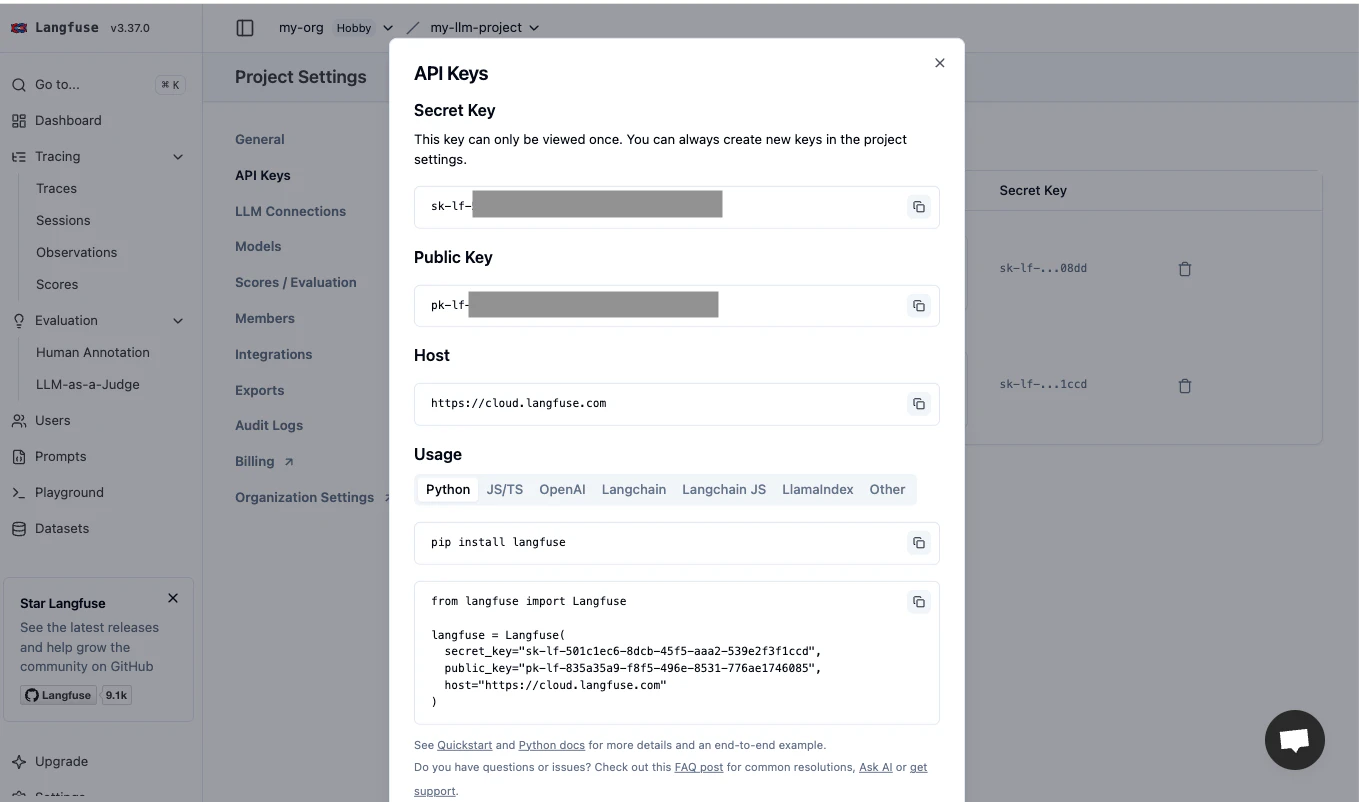
import os
# 環境変数の例(実際のキー/トークンに置き換えてください)
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-..." # あなたのパブリックキー
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-..." # あなたのシークレットキー
os.environ["LANGFUSE_HOST"] = "https://cloud.langfuse.com" # または https://us.cloud.langfuse.com
os.environ["DATABRICKS_TOKEN"] = "dapi..." # Databricks パーソナルアクセストークン
os.environ["DATABRICKS_HOST"] = "https://.....cloud.databricks.com/"
アプローチ1: OpenAI SDKを介したDatabricksモデルの使用
Databricksエンドポイントは、OpenAI APIの代替として機能できます。これにより、openaiライブラリに依存する既存のコードと簡単に統合できます。内部では、langfuse.openai.OpenAIがリクエストを自動的にLangfuseにトレースします。
手順
-
langfuse.openaiからOpenAIクライアントをインポートします。 - クライアントを作成し、
api_keyにDatabricksトークンを、base_urlにDatabricksワークスペースエンドポイントを設定します。 - クライアントの
chat.completions.create()メソッドを使用してプロンプトを送信します。 - Langfuseダッシュボードでトレースを確認します。
注: Langfuseを使用したOpenAIのトレースに関する詳細な例については、OpenAI統合ドキュメントを参照してください。
# Langfuse OpenAI クライアント
from langfuse.openai import OpenAI
# 環境変数を取得
databricks_token = os.environ.get("DATABRICKS_TOKEN")
databricks_host = os.environ.get("DATABRICKS_HOST")
# Databricks を指す OpenAI ライクなクライアントを作成
client = OpenAI(
api_key=databricks_token, # Databricks パーソナルアクセストークン
base_url=f"{databricks_host}/serving-endpoints", # あなたの Databricks ワークスペース
)
response = client.chat.completions.create(
messages=[
{"role": "system", "content": "あなたはAIアシスタントです。"},
{"role": "user", "content": "Databricksとは何ですか?"}
],
model="databricks-meta-llama-3-3-70b-instruct", # Databricksモデルサービングエンドポイント名に基づいて調整
max_tokens=256
)
# モデルからの応答を表示
display(response.choices[0].message.content)
'Databricks は、Apache Spark をベースにした、データエンジニアリング、データサイエンス、データ分析のためのクラウドベースのプラットフォームです。Databricks は、データの統合、処理、分析を容易にし、データ駆動型の意思決定を促進することを目的としています。\n\nDatabricks の主な機能には、以下のものがあります。\n\n1. Apache Spark: Databricks は Apache Spark を基盤としており、Spark のすべての機能を利用できます。\n2. クラウドネイティブ: Databricks はクラウドベースのプラットフォームであり、AWS、Azure、Google Cloud Platform などの主要なクラウドプロバイダーで利用できます。\n3. データレイク: Databricks では、データレイクを使用して構造化されたデータと非構造化されたデータを統合できます。\n4. ノートブック: Databricks では、Python、R、SQL などの言語を使用したノートブックを使用してコードを書き、データを分析できます。\n5. コラボレーション: Databricks'
Langfuseのダッシュボードを確認するとトレースを確認できます。プロンプト、応答、レイテンシ、トークン使用量などの詳細が表示されます。
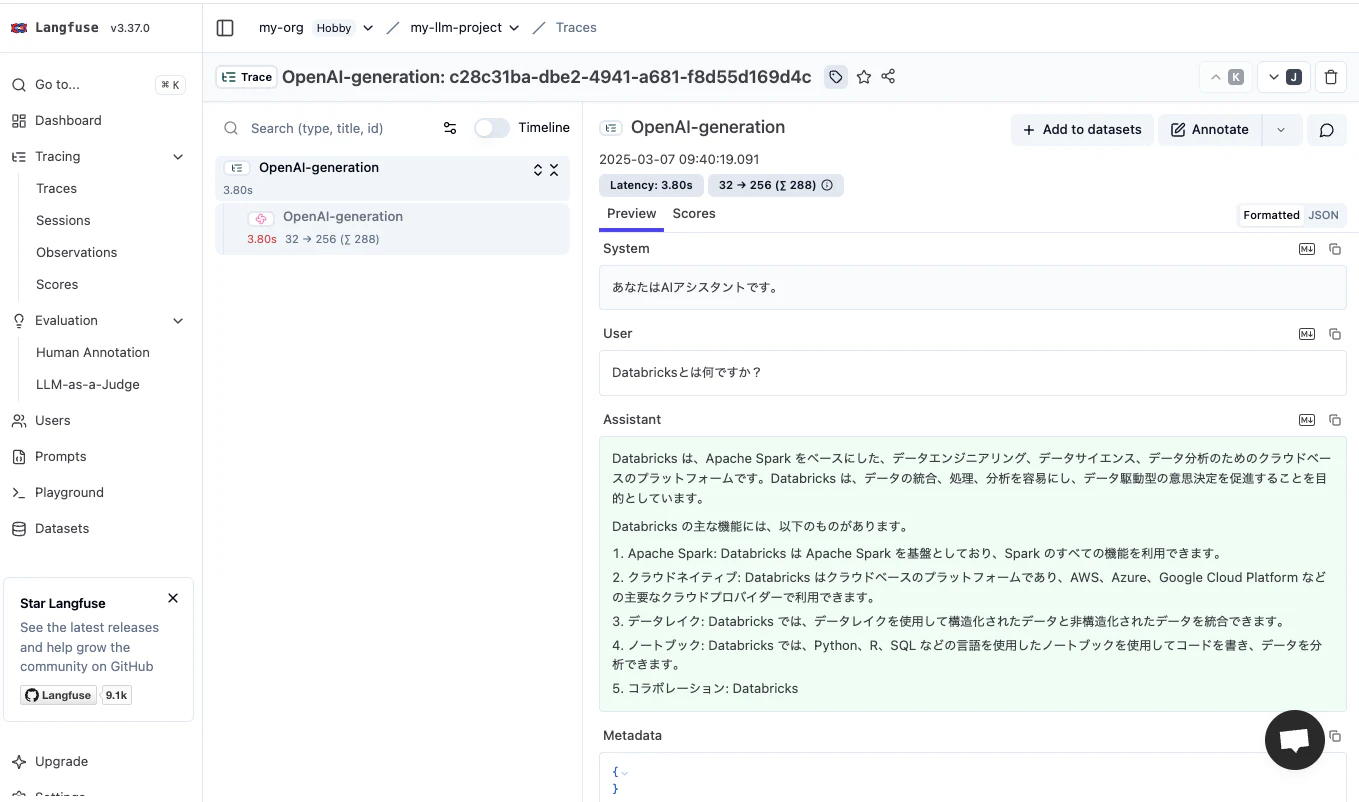
アプローチ2: LangChainの使用
DatabricksモデルはLangChainを介しても使用できます。ChatDatabricksクラスは、Databricksのモデルサービングエンドポイントをラップします。
手順
- 環境変数として
DATABRICKS_HOSTを設定します。 - トレースデータを自動的に収集するLangfuseの
CallbackHandlerを初期化します。 - エンドポイント名、温度、その他のパラメータを使用して
ChatDatabricksを使用します。 - メッセージでモデルを呼び出し、Langfuseのコールバックハンドラーを渡します。
- Langfuseダッシュボードでトレースを確認します。
注: Langfuseを使用したLangChainのトレースに関する詳細な例については、LangChain統合ドキュメントを参照してください。
from langfuse.callback import CallbackHandler
# Langfuseコールバックハンドラーを初期化
langfuse_handler = CallbackHandler(
secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),
public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),
host=os.environ.get("LANGFUSE_HOST")
)
from databricks_langchain import ChatDatabricks
chat_model = ChatDatabricks(
endpoint="databricks-meta-llama-3-3-70b-instruct", # Databricksモデルサービングエンドポイント名
temperature=0.1,
max_tokens=256,
# 他のパラメータをここに追加できます
)
# プロンプトをシステム/ユーザーメッセージのリストとして構築
messages = [
("system", "あなたはDatabricksに関する質問に答えることができるチャットボットです。"),
("user", "Databricks Model Servingとは何ですか?")
]
# LangChainの.invoke()メソッドを使用してモデルを呼び出す
chat_model.invoke(messages, config={"callbacks": [langfuse_handler]})
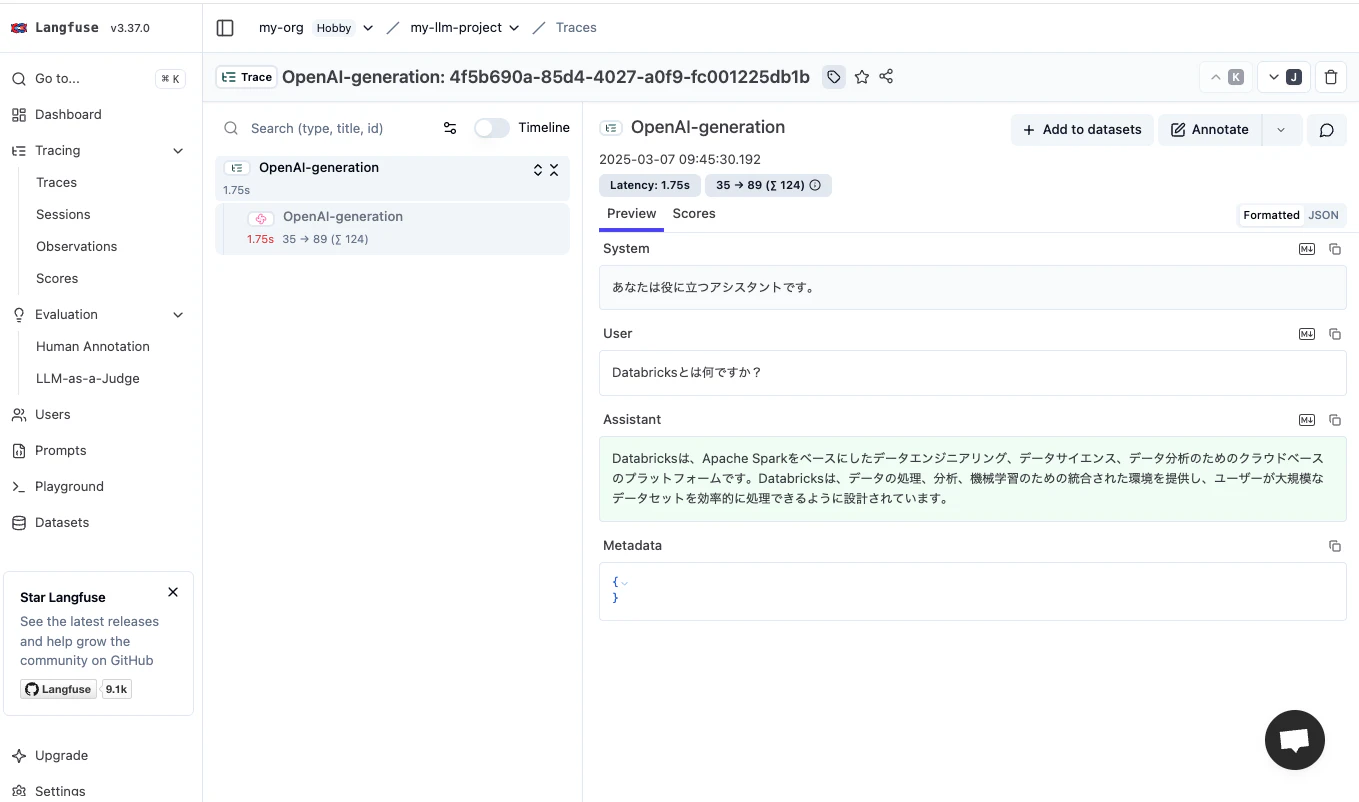
AIMessage(content='Databricks Model Servingは、機械学習モデルを簡単にデプロイして管理できるようにする、Databricksのクラウドベースのサービスです。データ サイエンティストとエンジニアは、Databricks Model Serving を使用して、トレーニング済みのモデルを簡単にデプロイして、リアルタイムの予測とバッチ予測のために REST エンドポイントとして公開できます。モデルは、Databricks のマネージド サービスとして自動的にホストされ、スケーリングされ、セキュリティが保護されます。Databricks Model Serving を使用すると、モデルを迅速にデプロイして、ビジネス上の意思決定を支援する予測を生成できます。', additional_kwargs={}, response_metadata={'prompt_tokens': 44, 'completion_tokens': 170, 'total_tokens': 214}, id='run-f62a4015-0dd5-44ae-a627-be83abd34baf-0')
コードを実行した後、Langfuseダッシュボードを開いて記録された会話を確認します。

アプローチ3: LlamaIndexの使用
データの取り込み、インデックス作成、またはRAGにLlamaIndexを使用する場合、デフォルトのLLMをDatabricksエンドポイントに置き換えることができます。
手順
-
llama_index.llms.databricksからDatabricksをインポートします。 - エンドポイント名とDatabricksの認証情報を使用して
DatabricksLLMを初期化します。 -
langfuse.llama_indexからLlamaIndexInstrumentorを使用して自動トレースを有効にします。 - チャットリクエストでLLMを呼び出します。
- Langfuseダッシュボードでトレースを確認します。
注: Langfuseを使用したLlamaIndexのトレースに関する詳細な例については、LlamaIndex統合ドキュメントを参照してください。
from llama_index.llms.databricks import Databricks
# Databricks LLMインスタンスを作成
llm = Databricks(
model="databricks-meta-llama-3-3-70b-instruct", # Databricksモデルサービングエンドポイント名
api_key=os.environ.get("DATABRICKS_TOKEN"),
api_base=f"{os.environ.get('DATABRICKS_HOST')}/serving-endpoints/"
)
from langfuse.llama_index import LlamaIndexInstrumentor
from llama_index.core.llms import ChatMessage
# LlamaIndexの操作をトレースするためにLlamaIndexInstrumentorを初期化
instrumentor = LlamaIndexInstrumentor(
secret_key=os.environ.get("LANGFUSE_SECRET_KEY"),
public_key=os.environ.get("LANGFUSE_PUBLIC_KEY"),
host=os.environ.get("LANGFUSE_HOST")
)
# 自動トレースを開始
instrumentor.start()
messages = [
ChatMessage(role="system", content="あなたは役に立つアシスタントです。"),
ChatMessage(role="user", content="Databricksとは何ですか?")
]
response = llm.chat(messages)
display(response)
# Flush any pending events to Langfuse
instrumentor.flush()
ChatResponse(message=ChatMessage(role=<MessageRole.ASSISTANT: 'assistant'>, additional_kwargs={}, blocks=[TextBlock(block_type='text', text='Databricksは、Apache Sparkをベースにしたデータエンジニアリング、データサイエンス、データ分析のためのクラウドベースのプラットフォームです。Databricksは、データレイクハウス、データウェアハウス、リアルタイムデータ処理、機械学習などの機能を提供し、ビッグデータの処理と分析を効率化することを目的としています。')]), raw=ChatCompletion(id='chatcmpl_c5974af8-6da9-4787-83d8-31a2b0219a07', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Databricksは、Apache Sparkをベースにしたデータエンジニアリング、データサイエンス、データ分析のためのクラウドベースのプラットフォームです。Databricksは、データレイクハウス、データウェアハウス、リアルタイムデータ処理、機械学習などの機能を提供し、ビッグデータの処理と分析を効率化することを目的としています。', refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1741304951, model='meta-llama-3.3-70b-instruct-121024', object='chat.completion', service_tier=None, system_fingerprint=None, usage=CompletionUsage(completion_tokens=93, prompt_tokens=35, total_tokens=128, completion_tokens_details=None, prompt_tokens_details=None)), delta=None, logprobs=None, additional_kwargs={'prompt_tokens': 35, 'completion_tokens': 93, 'total_tokens': 128})
LlamaIndexの呼び出しを確認するためにLangfuseにログインし、プロンプト、トークン使用量、完了データなどの詳細を確認できます。
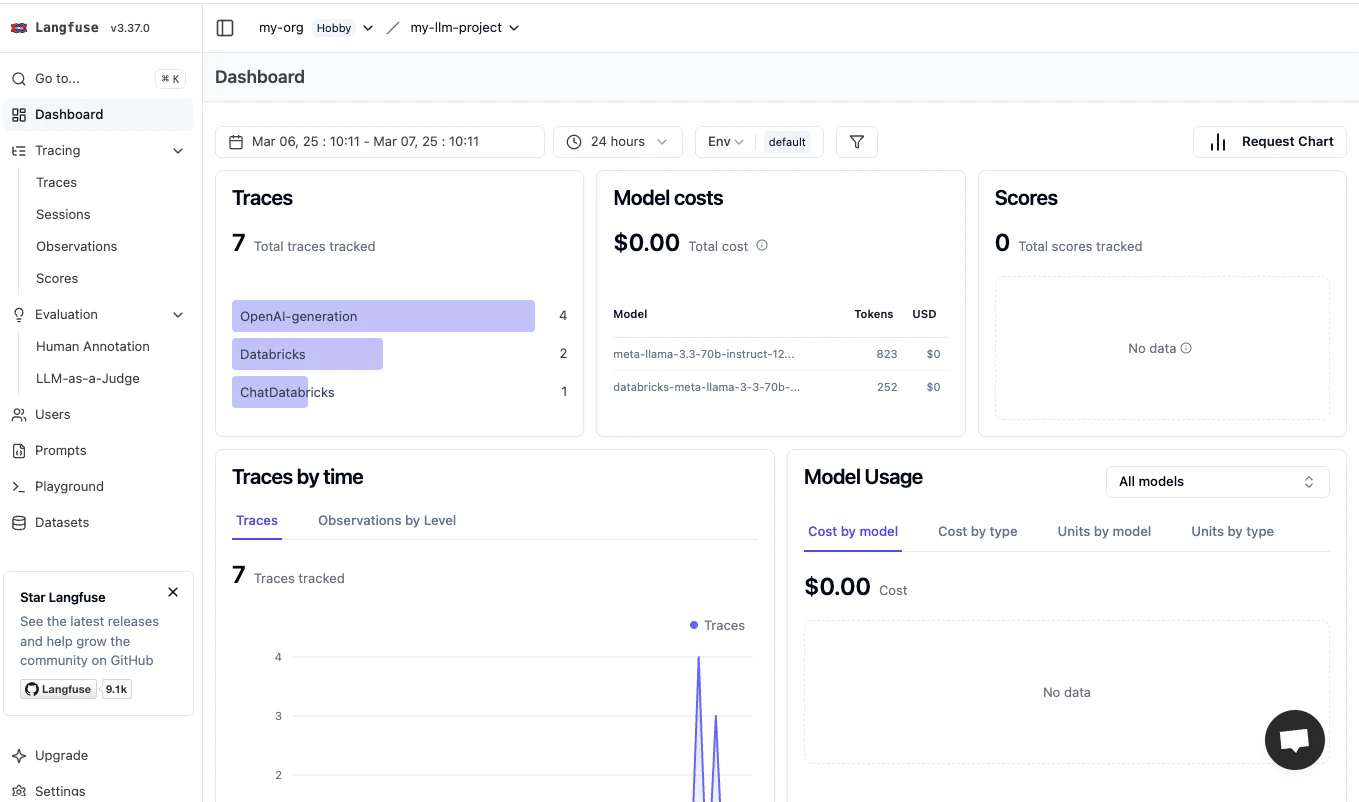
そして、Langfuseのダッシュボードでは様々なメトリクスを概観することができます。これは便利。
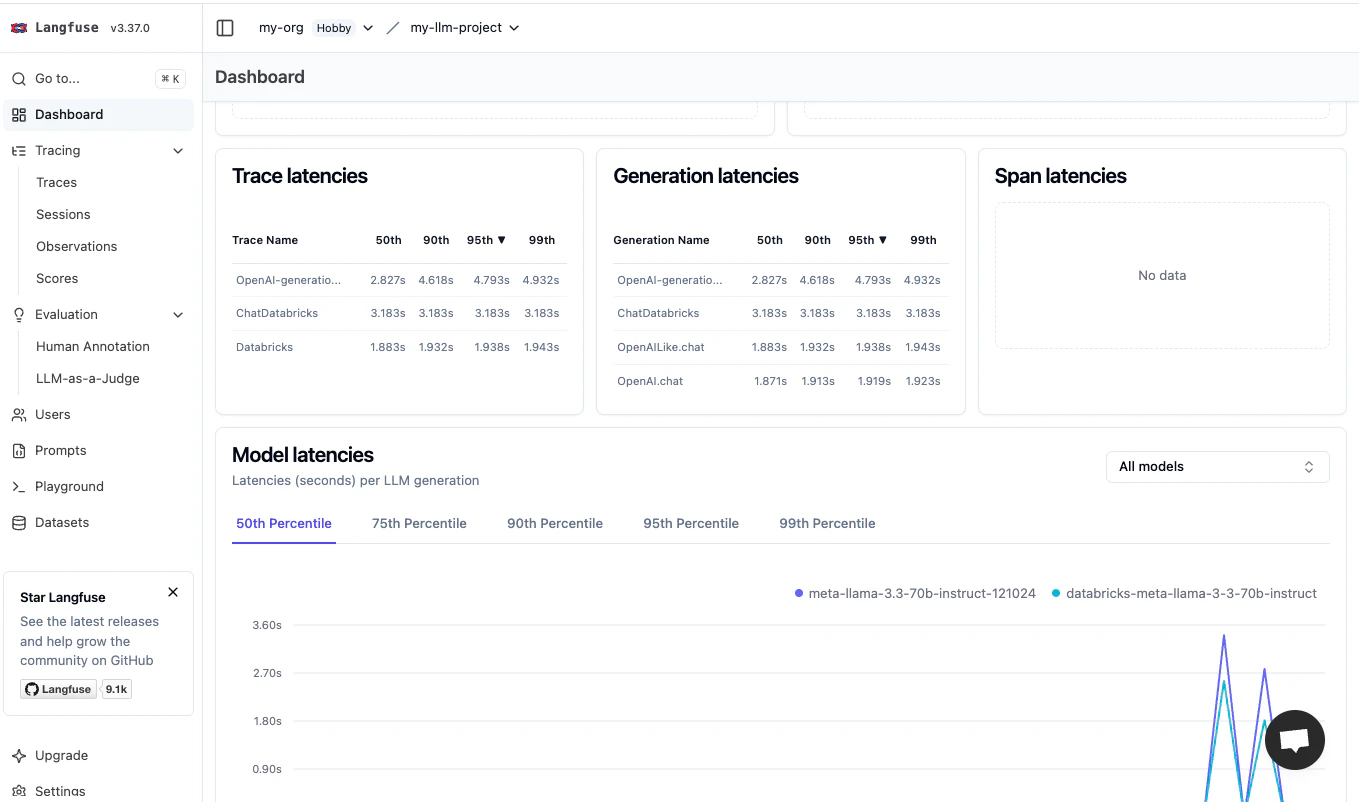
トレースの強化 (オプション)
Langfuseは、より豊富なトレースデータのための追加機能をサポートしています:
- トレースにメタデータ、タグ、ログレベル、およびユーザーIDを追加
- トレースをセッションでグループ化
- 追加のアプリケーションロジックをトレースするための
@observe()デコレータ - Langfuseプロンプト管理を使用し、プロンプトをトレースにリンク
- トレースにスコアを追加
詳細については、Langfuseのドキュメントを参照してください。
次のステップ
- Langfuse PlaygroundでDatabricksモデルを使用する方法やLLM-as-a-Judge評価についてはこちらをご覧ください。
- 高度なモデルサービング構成についてはDatabricksのドキュメントを参照してください。
- アプリケーション全体のフローを追跡するためのLangfuseトレース機能について学びましょう。
- Langfuseのプロンプト管理を試すか、LLM-as-a-Judge評価を設定してみましょう。