本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
初心者によるよくあるDatabricksの間違いトップ11を学びましょう。あなたのスキルをクイックに発展させるために、効果的なデータ管理、Delta Lakeテーブル、最適なパーティショニング、コーディングの習慣を学びましょう。

現実のプロジェクト経験に基づき、これらの一般的な間違いは、チーム環境に重大な問題を引き起こすことがありますので、これらを明確に取り扱うことがベストと言えます。また、第二弾の14 Critical Databricks Mistakes Advanced Developers Make: Security, Workflows, Environment(翻訳)もお勧めします。
1. テーブルの所有者を変更しない
間違い: デフォルトでは、Databricksでテーブルを作成した際、あなたのクラウド管理者のみがアクセスできます。しかし、あなたはチームとして働いているので、チーム全体がテーブルにアクセスできるようにすべきです。
修正方法: ノートブック全体の始めに、テーブルの編集、削除のアクセス権を持つチームのtable_owner_groupのグループ名を設定します。
table_owner_group = "your_group_name"
そして、テーブル作成の行で、ALTER TABLEコマンドを追加する必要があります:
spark.sql(f"ALTER TABLE catalog.schema.table_name SET OWNER TO `{table_owner_group}`")
また、すでに多くのスクリプトが手元にあり、所有者はそれぞれの作成者であり、コードすべてを修正するのが困難な場合には、自動化することができます。これに関する記事をすでに書いています:Set Owners for Databricks Tables in UNITY Catalog SchemasとSet Owners for Databricks Tables in HIVE Catalog Schemasです。
2. ノートブックの構成をモジュール化せずにすべてのコードに一つのセルを使う
間違い: 単一のノートブックセルにすべてのコードを書いてしまい、テスト、可読性、メンテナンス、デバッグを困難にします。
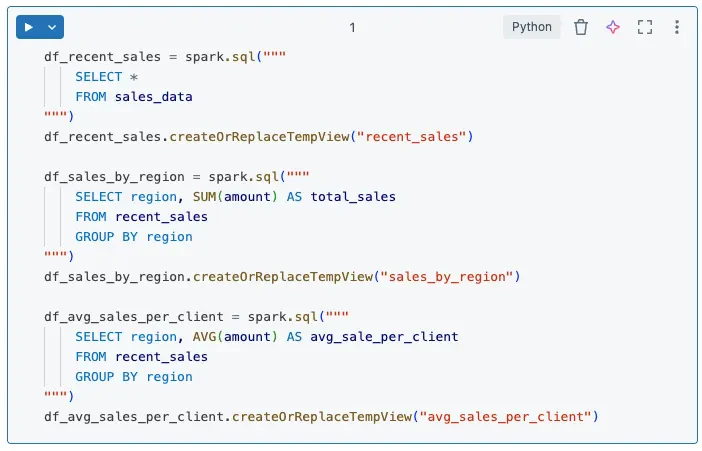
修正方法: コードを論理的、独立したセルやブロックに分割することで、ノートブックの構成をモジュール化します。それぞれのブロックは、個別の機能ステップやオペレーションを表現すべきであり、独立して実行、テスト、デバッグできるようになります。ノートブックをこのように整理することで、あなたのワークフローはより明確になり、トラブルシュートをより迅速にし、コラボレーションを容易にします。
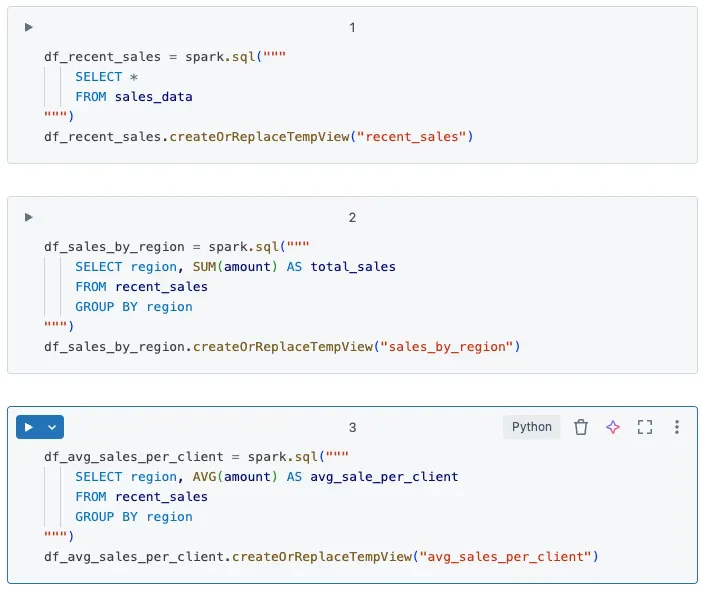
3. ステージングテーブルは永続化したテーブルではなく、一時ビューあるいはSparkデータフレームにすべきである
間違い: SASのようなレガシー分析プラットフォームから移行する際、ユーザーは多くの場合において、彼らのスクリプト記述プロセスのそれぞれのステップにおいて、永続化されるストレージテーブルを作成するというプラクティスを継続してしまいます。これは、初めはデバッグやインクリメンタルな検証が便利のように見えますが、インメモリ処理の効率性やクイックな繰り返し開発を含む、Sparkが提供する重要な利点を損なっています。
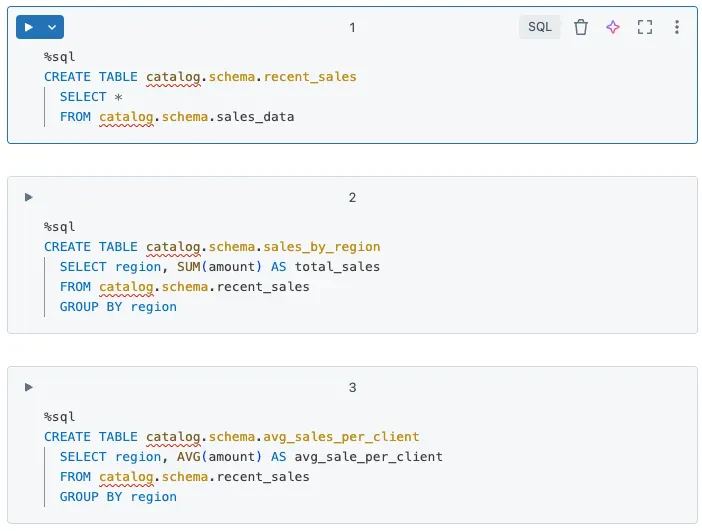
修正方法: 中間状態に対しては一時ビューやSparkデータフレームを使う方法に移行し、永続化テーブルを用いずにデータを操作しましょう。Sparkは連続的なディスクの読み書きによる不必要な入力/出力を削減することで、パフォーマンスを劇的に改善するインメモリ計算に最適化されています。
4. 適切なデバッグ手法ではなく、printやdisplay文を過度に使う
間違い: 過度にprintやdisplay文や一時ビューに対する%sql SELECTを使っています。
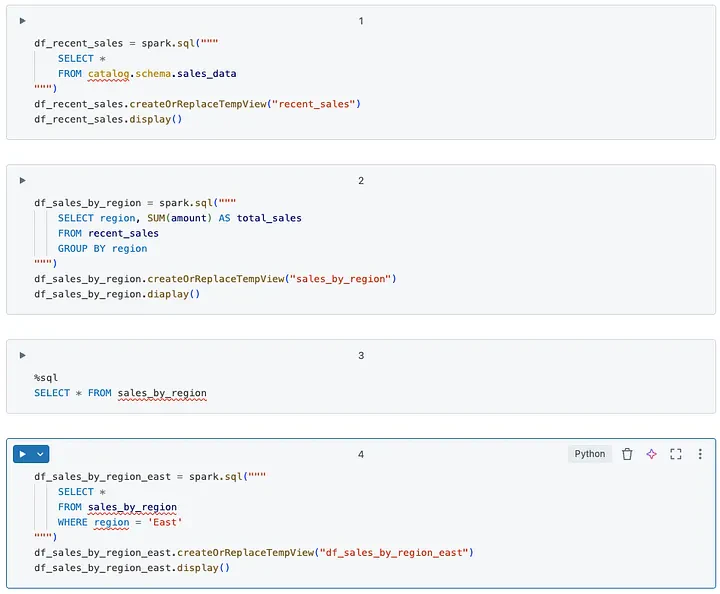
修正方法: 変数に対するprintは一般的に無害ですが、データフレームのチェーンや一次ビューにクエリーを行うdisplayや%sql SELECT文の使用は、最終化された本番運用用のノートブックに残された場合、可読性とパフォーマンスにネガティブな影響を与えることがあります。これらのコマンドは、中間データ出力をクイックに検証するため開発やデバッグでは有用ですが、プロダクションに過度にこれらを残してしまうと、出力を雑然とさせ、特に長いクエリーチェーンや複雑なデータフレームの変換処理においては、非効率的な処理実行につながります。
私はパフォーマンスを削減する行をコメントアウトしました。不要であれば、削除することもできます:
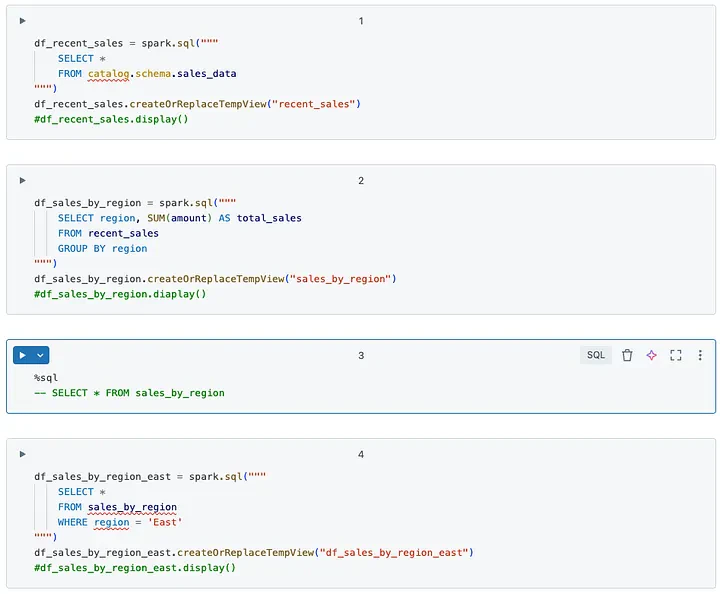
逆に、初めに変数を宣言してそれらをprintするのであれば、どのような場合においてもパフォーマンスに影響は与えません。
5. SparkデータフレームではなくPandasを過度に使用し、パフォーマンス劣化を引き起こす
間違い: データ操作においてPandasは有用で便利ですが、Sparkノートブックでそれらを使いすぎると、スクリプトの動作を遅くさせることがあります。Pandasはシングルマシンでしか動作しないので、特に大きなデータの場合には頻繁にSparkデータフレームからPandasデータフレームに変換(toPandas())することで、ノートブックの動作が遅くなり、時にはメモリー不足になることもあります。
修正方法: 例えば、データの入力/出力や最終的なレポートのように、必要な時にスクリプトの最初や最後でのみPandasを使いましょう。中間ステップでの不必要なSpark、Pandasデータフレーム間の変換は避けましょう。実際には、スクリプトにおいて実際に必要はないのにSparkデータフレームとPandasデータフレーム間の変換は頻繁に発生しています - これらの冗長な変換処理を削除することで、スクリプトの性能を劇的に改善します。
6. 過度にネストされたクエリーを用いて、可読性の問題を引き起こし、パフォーマンスを低下させる
間違い: 複雑で深くネストされたSQLクエリーを頻繁に作成することはよくある間違いです。ネストされたクエリー(サブクエリーの中に繰り返されるサブクエリー)は重大な問題を引き起こします: 読んだりデバッグすることが困難となり、あなたのSQLロジックを複雑にし、クエリーの最適化にネガティブなインパクトを与え、パフォーマンスを劣化させます。
修正方法: 可読性、メンテナンス性、効率性を改善するには:
- 一時ビューやSparkデータフレームを作成する: 中間結果を格納し参照する。
- クエリーを平坦化する: 可能であればネストの深さを削減してロジックをシンプルにする。
- デバッグを容易にするために、ステップバイステップの変換処理を明確に実行する。
7. パラメータ化やノートブックへの入力をシンプルにするためにウィジェットを使わない
間違い: ノートブックユーザーで良くある間違い - 特に比較的ノートブックを使い始めた人において - は、コードに直接入力パラメーターをハードコードすることです。これによって、ノートブックの柔軟性は低下し、毎回コードの編集が必要となります。この慣習は、柔軟性を低下させ、エラーのリスクを高め、ワークフローの生産性を損ないます。

修正方法: コードのインタラクションとパラメータ化をシンプルにするために、ノートブックでウィジェットを使いましょう。ウィジェットによって、ユーザーは背後のコードを変更せずに、動的に入力値を調整することができ、明確でユーザーフレンドリーなインタフェースを提供できます。
以下は、デフォルト値を持つウィジェットのインストール例です。起動後に、ノートブックの上部にウィジェットが表示され、スクリプトコードを変更することなしに値を変更できます。
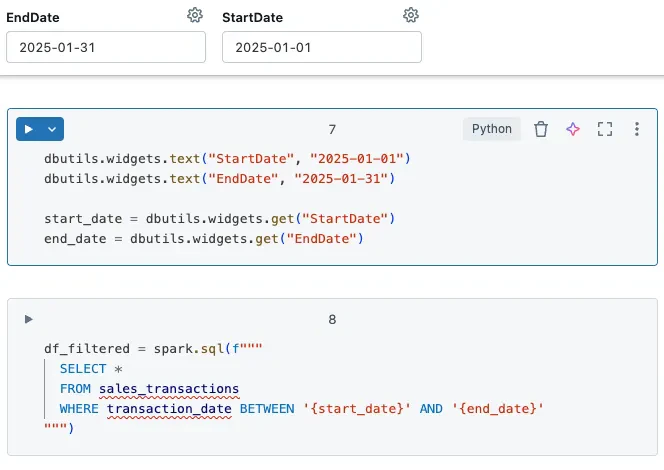
また、ウィジェットの変数はノートブック間で引き渡すことができます。詳細は私の記事All about Parameters in Databricks Workflowsをご覧ください。
8. フォーマットされたマークダウンセル(%md)ではなく、コードのコメントを書いてしまう
間違い: ノートブックを使い始めたユーザーは特に、スクリプトの文書化においてインラインのコードコメント(#)に過度に依存してしまうことはよくあることです。インラインのコメントはコードのステップを簡単に説明する助けとなりますが、インラインのコードコメントで過度の文書化や説明を行うと、ノートブックを雑然とさせ、可読性を低下させることがあります。

修正方法: 代わりに、ノートブックのフォーマットされたマークダウンセル(%md)を使いましょう。マークダウンによって、明確なフォーマット、構造化、情報の階層化を可能にし、可読性を劇的に改善します。
マークダウンセル(%md)を活用する利点は以下の通りです:
- 可読性の改善: コードから分離された明確なドキュメント。
- 階層の構造化: コンテンツを論理的に整理、構造化するためにヘッダー(
#、##、###)を使いましょう。 - メンテナンス性の強化: メンテナンスとレビューが容易になります。
ユーザーフレンドリーなドキュメントのために一貫してマークダウンセルを使い、簡単あるいは技術的な説明に最低限のインラインコメント(#)を用いることで、コラボレーションのためのワークフローやノートブックの明確性を劇的に強化することができます。
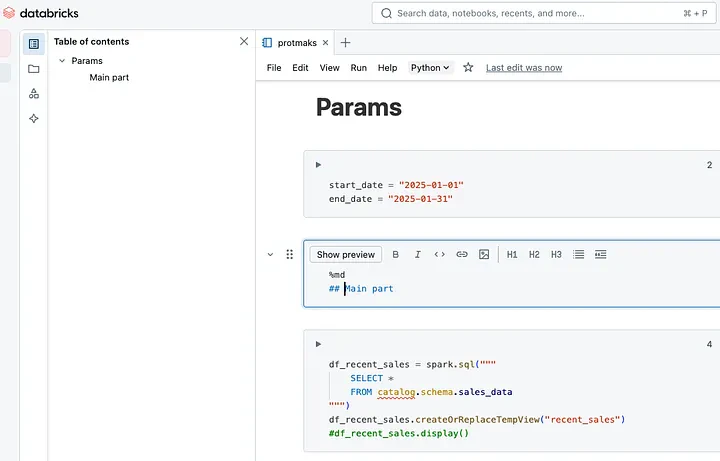
さらに、Databricksノートブックでは、ビルトインのセルタイトルを提供しており、ユーザーはノートブックのキーとなるステップや論理的なパーティションをラベリング、ハイライトすることができ、さらに構造化とナビゲーションを改善することができます。
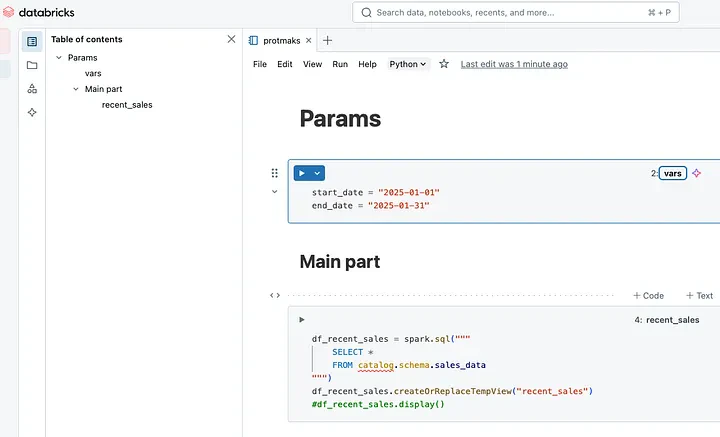
9. Databricksワークフロー経由で自動化せずに、手動でスクリプトを実行する
間違い: すべてのユーザーがスクリプトにスケジュールを設定できることを知っているわけではなく、手動で実行し続けています。
修正方法: Databricksにはワークフロータブがあります。そこでは、スクリプトを日次、月次、ある周期での繰り返しでスケジュールすることができます。また、スクリプト間の依存関係を設定することができます。エラーの通知を設定し、より安価なクラスターを起動しましょう。セットアップにおいては多くのニュアンスが存在しますが、それらは次の記事で取り扱います。
10. テーブルを作成する際にDeltaフォーマットを使わない
間違い: Databricksでテーブルを作成する際、2つの主要な方法が存在します:
%sql
CREATE TABLE catalog.schema.table_name AS
SELECT * FROM some_table;
df_name.write.mode("overwrite").saveAsTable("catalog.schema.table_name")
デフォルトでは、この挙動はあなたの設定に依存します:
- Unity Catalog: デフォルトでDeltaフォーマットが使われます。
- Hiveメタストア: フォーマットはクラスター設定に依存します。(DeltaあるいはParquet)
修正方法:
明確性と予測可能性のために、常に明示的にフォーマットを指定することをお勧めします:
%sql
CREATE TABLE catalog.schema.table_name
USING DELTA
AS SELECT * FROM some_table;
df_name.write.format("delta").mode("overwrite").option("overwriteSchema", "true").saveAsTable(f"catalog.schema.table_name")
Parquetに対するDeltaの利点は以下の通りです:
- トランザクションオペレーションのサポート(UPDATE、DELETE、MERGE)
- データ変更履歴(タイムトラベル)
- スキーマ進化
- 原子的な読み書きオペレーション
- データを並列処理する能力
すでにUnity Catalogを使っている、あるいはデフォルトフォーマットがDeltaを使うようにHiveクラスターが設定されているのであれば、明示的にフォーマットを指定しないでテーブルを作成した際には、Deltaフォーマットでテーブルが自動で作成されます。しかし、明示的なコントロールや互換性のため、テーブルを作成する際には常にフォーマットを選択することをお勧めします。
11. 特にSAS(や他のレガシーシステム)から移行する際に不適切にテーブルのパーティショニングを行う
間違い: SASや他のレガシーシステムから移行する際に、Databricksの適切なパーティショニングではなく、それぞれの期間ごとに個別のテーブル(NAME_2023_01、NAME_2023_02、NAME_2023_03など)を作成します。この時代遅れの慣習は、多数のテーブルをメンテナンスする際の複雑性や非効率的なクエリーにつながります。
修正方法: Databricksにおいては、単一のDeltaテーブルでデータを効率的に整理するためにパーティショニングを使いましょう。パーティショニングは、数百の個別のファイルを作成するのではなく、あなたのファイルをコンピューターのフォルダーやサブフォルダーに整理するようなものです。
例えば、以下のように個別のテーブルファイルを作成するのではなく:
NAME_2022_01
NAME_2022_02
…
NAME_2023_01
NAME_2023_02
以下のようにデータを整理する年と月によるパーティションを持つ一つのNAMEテーブルを作成することができます:
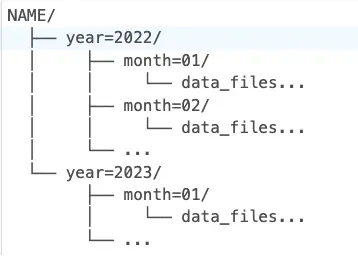
パーティションの粒度を決定する際には:
- 月毎のデータボリュームが小さい(100MB以下)場合には、(年ごとのように)大きなパーティションを選びましょう。
- 数百MBから数GBの間のパーティションサイズを狙いましょう。
- データを通常どのようにクエリーするのかを考えましょう - 月毎にフィルタリングするのが稀であれば、年のパーティションで十分かもしれません。
このアプローチは、データ管理をシンプルにし、クエリーを高速にし、Databricksの最適化機能ともうまく連携します。
あなたのDatabricksスキルをさらにレベルアップしたいですか?
次の記事では、14 Critical Databricks Mistakes Advanced Developers Make: Security, Workflows, Environment(翻訳)を明らかにします。
Mediumにおける私のブログ記事をサブスクライブして、これらの高等な洞察や最先端のプラクティスを見逃さないでください!