こちらで紹介されている新機能、Identity列を試してみました。
Databricks SQLでテーブルを作成して、データをインサートしていきます。
Databricks SQLにアクセス
Databricksワークスペースにログインし、サイドメニューのペルソナスイッチャーでSQLを選択します。
テーブルの作成
-
サイドメニューからクエリを選択します。
-
画面右上のクエリーを作成をクリックします。
-
クエリーエディタが表示されます。
-
以下のクエリーを入力します。
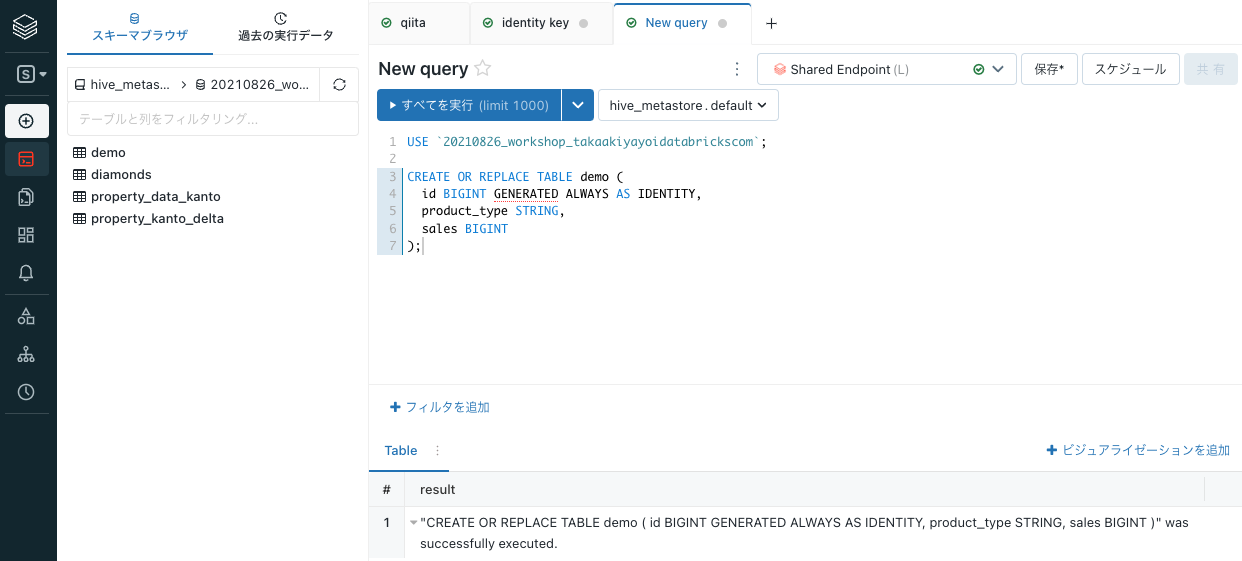
USEで指定するデータベースは適宜変更してください。SQLUSE `20210826_workshop_takaakiyayoidatabrickscom`; CREATE OR REPLACE TABLE demo ( id BIGINT GENERATED ALWAYS AS IDENTITY, product_type STRING, sales BIGINT ); -
すべてを実行をクリックしてテーブルを作成します。クエリーが成功すると
demoテーブルが作成されます。
-
この時点ではテーブルは空です。
行のインサート
-
ダミーの行をインサートします。
SQLUSE `20210826_workshop_takaakiyayoidatabrickscom`; INSERT INTO demo (product_type, sales) VALUES ("Batteries", 150000); INSERT INTO demo (product_type, sales) VALUES ("Chargers", 200000); -
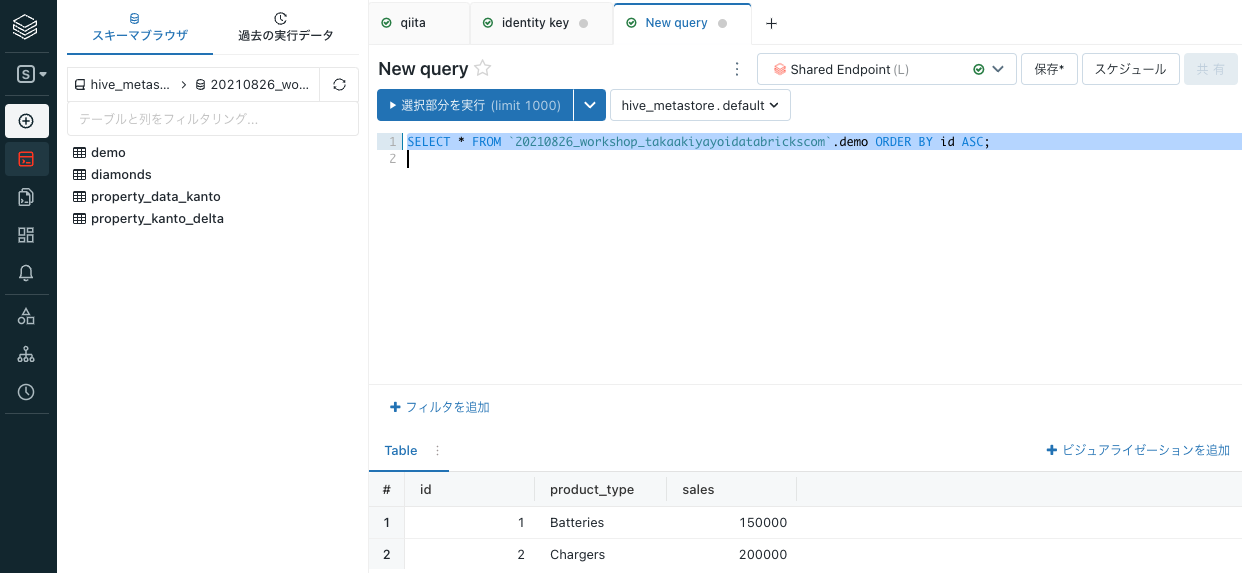
テーブルを確認します。
SQLSELECT * FROM `20210826_workshop_takaakiyayoidatabrickscom`.demo ORDER BY id ASC;id列にインサートされた順の連番が振られていることがわかります。
-
さらにダミーの行をインサートします。
SQLUSE `20210826_workshop_takaakiyayoidatabrickscom`; INSERT INTO demo (product_type, sales) VALUES ("Papers", 50000); INSERT INTO demo (product_type, sales) VALUES ("Repair", 1200000); -
テーブルを確認します。
SQLSELECT * FROM `20210826_workshop_takaakiyayoidatabrickscom`.demo ORDER BY id ASC;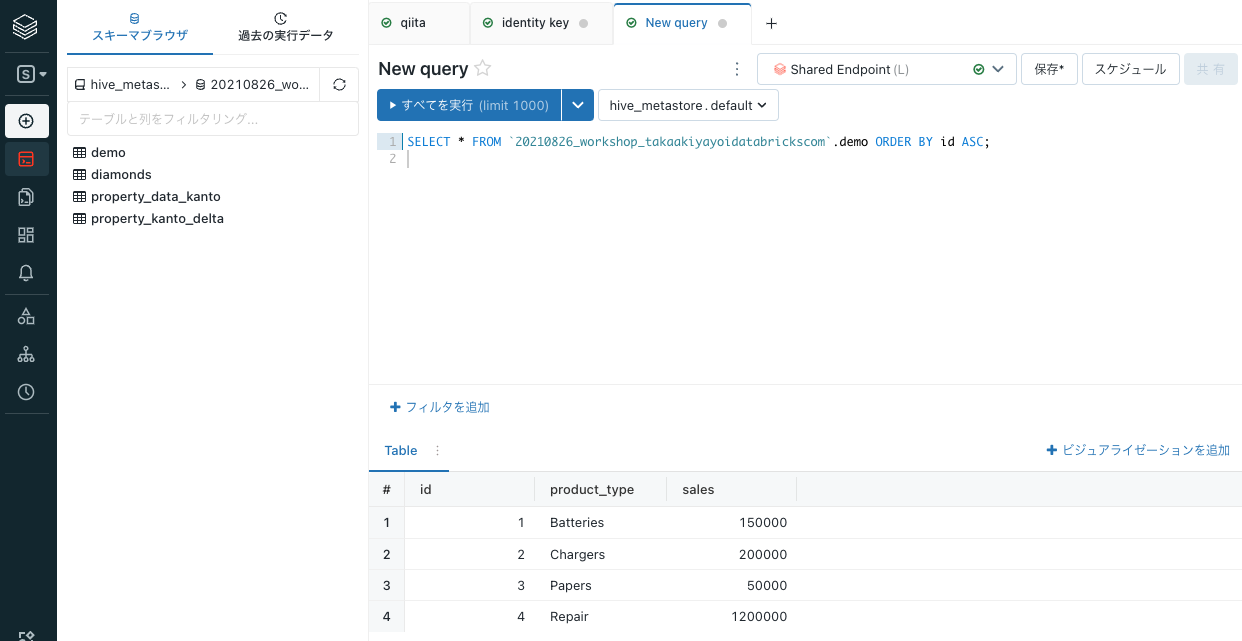
クリーンアップするにはテーブルをドロップしてください。
SQL
DROP TABLE `20210826_workshop_takaakiyayoidatabrickscom`.demo
このようにIdentity列を使うことで、データベースでは当たり前の主キー・外部キーによるテーブル結合がデータレイク上のデータでも容易に行えるようになります。