こちらの機能がGAになりました!
File arrival triggers in Databricks Workflows is GA
ファイル到着トリガーがすべてのクラウドプロバイダーでGAになりました。このリリースで、既存のUnity Catalog外部ロケーションのサポートに加えて、Unity Catalogのボリュームに新規ファイルが到着した際にDatabricksジョブを実行するためにファイル到着トリガーを活用できるようになります。新しいファイルが到着したときにジョブをトリガーするをご覧ください。
早速試します。
ボリュームの作成
/Volumes/takaakiyayoi_catalog/default/landing_zone/というボリュームを作成します。
ノートブックの作成
このノートブックは、あとでジョブから呼び出します。Auto Loaderを用いて、新規到着ファイルのみを処理するようにします。checkpoint_pathやloadの引数のパスも適宜ボリュームを指定しています。テーブルtakaakiyayoi_catalog.default.ingestedに書き込んでいます。
checkpoint_path = "/Volumes/takaakiyayoi_catalog/default/checkpoint"
(spark.readStream
.format("cloudFiles") # Auto Loader
.option("cloudFiles.format", "csv") # ファイルフォーマット
.option("header", "true")
.option("delimiter", ",")
.option("cloudFiles.schemaLocation", checkpoint_path) # スキーマ格納場所
.load("/Volumes/takaakiyayoi_catalog/default/landing_zone") # 読み込みボリュームパス
.writeStream
.option("checkpointLocation", checkpoint_path) # チェックポイント格納場所
.trigger(availableNow=True) # 増分バッチ処理
.toTable("takaakiyayoi_catalog.default.ingested")) # 書き込み先テーブル
ジョブの作成
タスクを作成し、上のノートブックを指定します。トリガータイプをファイル到着にし、上記ボリュームのパスを指定します。
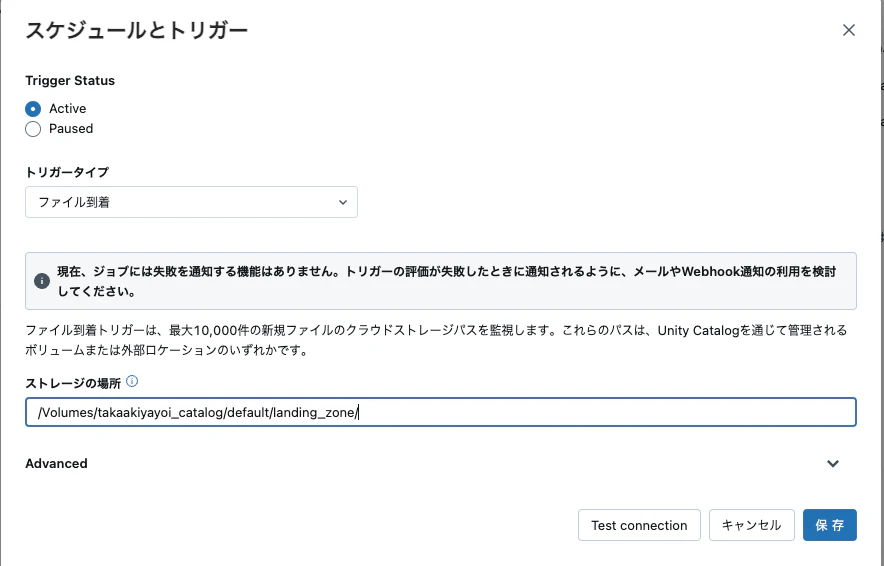
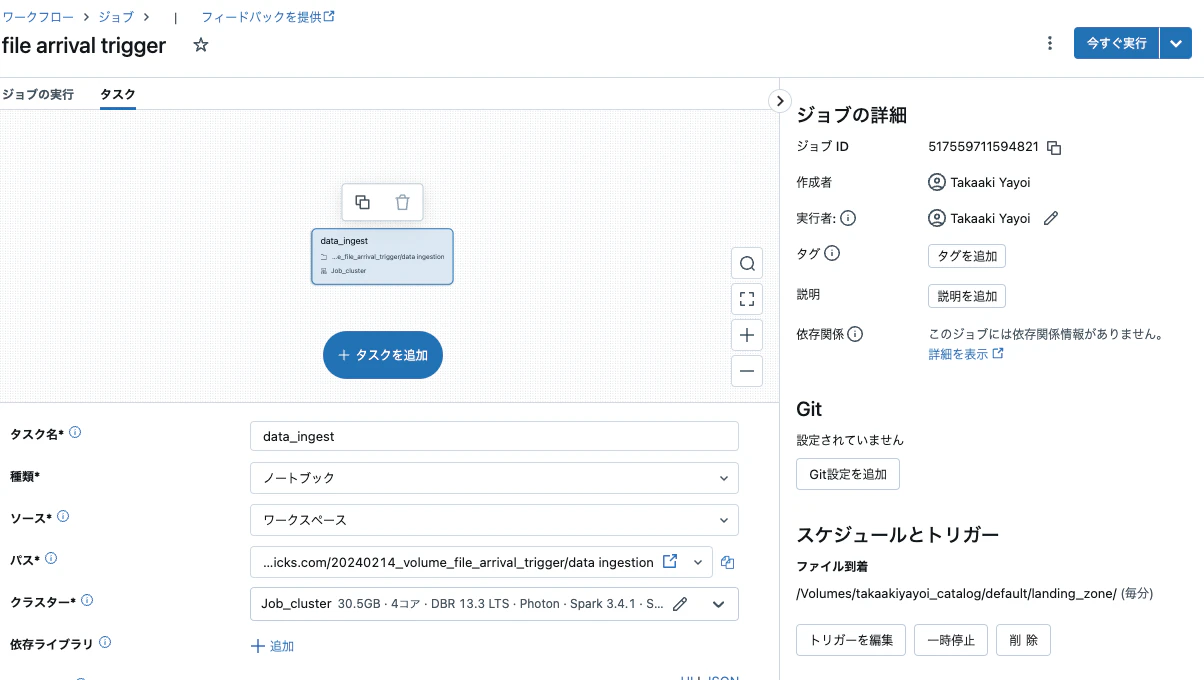
これでファイル到着によって起動するジョブの準備ができました。
ファイルのアップロード
以下のようなCSVファイルを準備します。
id,first,last
1, taka, yayoi
2, ume, yayoi
id,first,last
3, yuki, yayoi
4, chi, yayoi
ボリュームに001.csvをアップロードします。
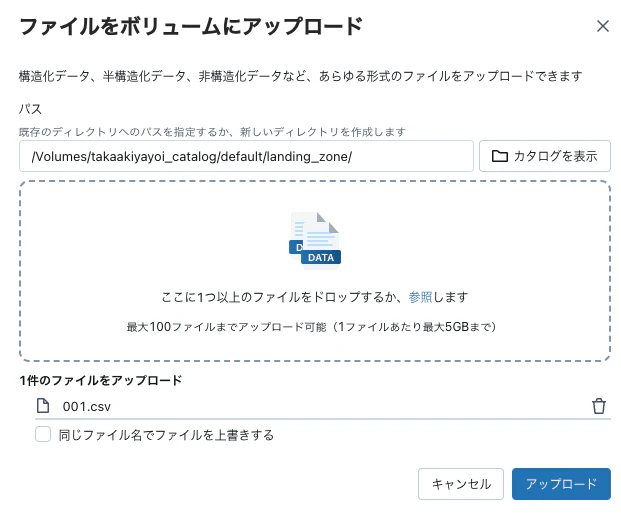
少しするとジョブが起動します。

ジョブが完了するとテーブルが作成されます。
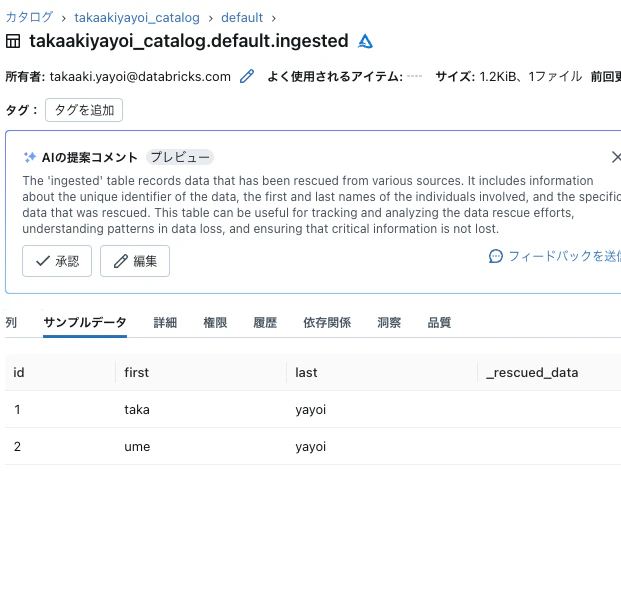
次いで、002.csvをアップロードします。すると、再びジョブが起動します。
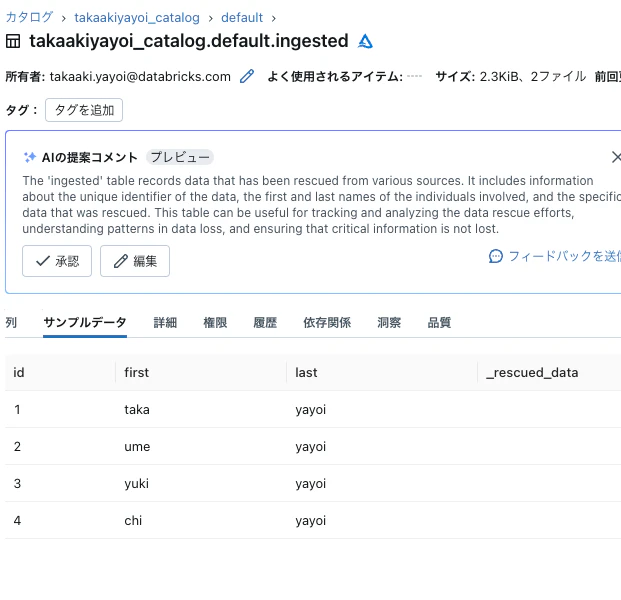
テーブルを確認すると、002.csvの内容が追記されていることがわかります。
お手軽にファイル処理のパイプラインを起動できるファイル到着トリガー、ご活用ください!