こちらをDatabricksでウォークスルーします。
翻訳版のノートブックはこちらです。
Responses APIでのファイル検索ツールの使用
RAGは圧倒されることがありますが、PDFファイルの検索は複雑であるべきではありません。現在最も採用されているオプションの一つは、PDFを解析し、チャンク戦略を定義し、それらのチャンクをストレージプロバイダーにアップロードし、それらのテキストチャンクに埋め込みを実行し、それらの埋め込みをベクターデータベースに保存することです。そして、それはセットアップの一部に過ぎません。LLMワークフローでコンテンツを取得するには、複数のステップが必要です。
ここで、Responses APIで使用できるホスト型ツールであるファイル検索が登場します。これにより、ナレッジベースを検索し、取得したコンテンツに基づいて回答を生成することができます。このクックブックでは、これらのPDFをOpenAIのベクターストアにアップロードし、ファイル検索を使用して最初のステップで生成した質問に答えるための追加のコンテキストをこのベクターストアから取得します。次に、OpenAIのブログ(openai.com/news)から抽出したPDFに基づいて、最初に少数の質問セットを作成します。
ファイル検索は以前はアシスタントAPIで利用可能でした。現在は新しいResponses APIで利用可能で、メタデータフィルタリングなどの新機能を備えたステートフルまたはステートレスなAPIです
セットアップ
PyPDF2 error "PyCryptodome is required for AES algorithm"というエラーに遭遇したので、こちらを参考にpycryptodomeをインストールしています。
%pip install PyPDF2 pandas tqdm openai -qU
%pip install pycryptodome==3.15.0
%restart_python
from openai import OpenAI
from concurrent.futures import ThreadPoolExecutor
from tqdm import tqdm
import concurrent
import PyPDF2
import os
import pandas as pd
import base64
os.environ['OPENAI_API_KEY'] = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai_api_key")
client = OpenAI(api_key=os.getenv('OPENAI_API_KEY'))
dir_pdfs = 'PDF' # これらのPDFはここにローカルで保存されています
pdf_files = [os.path.join(dir_pdfs, f) for f in os.listdir(dir_pdfs)]
PDFは自前で準備しています。

PDFを使用したベクターストアの作成
OpenAI APIでベクターストアを作成し、PDFをベクターストアにアップロードします。OpenAIはこれらのPDFを読み取り、コンテンツを複数のテキストチャンクに分割し、それらに埋め込みを実行し、その埋め込みとテキストをベクターストアに保存します。これにより、クエリに基づいて関連するコンテンツを返すためにこのベクターストアをクエリすることができます。
def upload_single_pdf(file_path: str, vector_store_id: str):
file_name = os.path.basename(file_path)
try:
file_response = client.files.create(file=open(file_path, 'rb'), purpose="assistants")
attach_response = client.vector_stores.files.create(
vector_store_id=vector_store_id,
file_id=file_response.id
)
return {"ファイル": file_name, "ステータス": "成功"}
except Exception as e:
print(f"{file_name}でエラーが発生しました: {str(e)}")
return {"ファイル": file_name, "ステータス": "失敗", "エラー": str(e)}
def upload_pdf_files_to_vector_store(vector_store_id: str):
pdf_files = [os.path.join(dir_pdfs, f) for f in os.listdir(dir_pdfs)]
stats = {"総ファイル数": len(pdf_files), "成功したアップロード": 0, "失敗したアップロード": 0, "エラー": []}
print(f"{len(pdf_files)} PDFファイルを処理します。並行してアップロード中...")
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
futures = {executor.submit(upload_single_pdf, file_path, vector_store_id): file_path for file_path in pdf_files}
for future in tqdm(concurrent.futures.as_completed(futures), total=len(pdf_files)):
result = future.result()
if result["ステータス"] == "成功":
stats["成功したアップロード"] += 1
else:
stats["失敗したアップロード"] += 1
stats["エラー"].append(result)
return stats
def create_vector_store(store_name: str) -> dict:
try:
vector_store = client.vector_stores.create(name=store_name)
details = {
"id": vector_store.id,
"name": vector_store.name,
"created_at": vector_store.created_at,
"file_count": vector_store.file_counts.completed
}
print("ベクトルストアが作成されました:", details)
return details
except Exception as e:
print(f"ベクトルストアの作成中にエラーが発生しました: {e}")
return {}
store_name = "databricks_ebook_store"
vector_store_details = create_vector_store(store_name)
upload_pdf_files_to_vector_store(vector_store_details["id"])
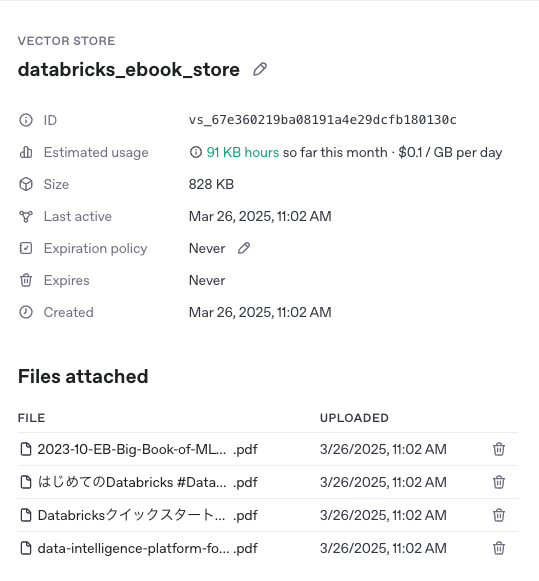
ベクトルストアが作成されました: {'id': 'vs_67e360219ba08191a4e29dcfb180130c', 'name': 'databricks_ebook_store', 'created_at': 1742954529, 'file_count': 0}
4 PDFファイルを処理します。並行してアップロード中...
100%|██████████| 4/4 [00:02<00:00, 1.79it/s]
ベクトルストアが作成されます。
スタンドアロンのベクター検索
ベクターストアが準備できたので、特定のクエリに対してベクターストアを直接クエリし、関連するコンテンツを取得することができます。新しいベクター検索APIを使用することで、LLMクエリに統合することなく、ナレッジベースから関連する項目を見つけることができます。
query = "Databricksとは何ですか?"
search_results = client.vector_stores.search(
vector_store_id=vector_store_details['id'],
query=query
)
for result in search_results.data:
display(f"{len(result.content[0].text)} 文字のコンテンツが {result.filename} から取得され、関連スコアは {result.score} です。")
'847 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.9036443169878364 です。'
'837 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.8656873844087783 です。'
'828 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.8504137278924903 です。'
'854 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.8045002502709124 です。'
'741 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.8006740095031514 です。'
'941 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.786620195848578 です。'
'789 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.7602417440530186 です。'
'912 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.7429814459720738 です。'
'658 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.7412312997571795 です。'
'782 文字のコンテンツが data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf から取得され、関連スコアは 0.7402049767365444 です。'
検索クエリから異なるサイズ(および内部的には異なるテキスト)が返されていることがわかります。それらはすべて、ハイブリッド検索を使用するランカーによって計算された異なる関連性スコアを持っています。
検索結果をLLMと統合して単一のAPI呼び出しを行う
しかし、ベクターストアをクエリしてからそのデータをResponsesまたはChat Completion API呼び出しに渡すのではなく、この検索結果をLLMクエリで使用するさらに便利な方法は、OpenAI Responses APIの一部としてfile_searchツールを使用することです。
query = "Databricksとは何ですか?"
response = client.responses.create(
input=query,
model="gpt-4o-mini",
tools=[{
"type": "file_search",
"vector_store_ids": [vector_store_details['id']],
}]
)
# 応答から注釈を抽出
annotations = response.output[1].content[0].annotations
# 上位k件の取得されたファイル名を取得
retrieved_files = set([result.filename for result in annotations])
display(f'使用されたファイル: {retrieved_files}')
display('応答:')
display(response.output[1].content[0].text) # 0はファイル検索呼び出し
"使用されたファイル: {'data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf', 'はじめてのDatabricks #Databricks - Qiita.pdf'}"
'応答:'
'Databricksは、データインテリジェンスプラットフォームを提供するツールです。このプラットフォームは、レイクハウスアーキテクチャに基づいており、組織全体でのデータとAIの活用を促進します。主な機能には、データの抽出・変換・ロード(ETL)、データウェアハウジング、生成AIの活用が含まれます。具体的には、DatabricksIQというデータインテリジェンスエンジンが組織特有のデータ環境に応じて自然言語によるアクセスを実現し、全ての従業員がデータを簡単に検索、理解、照会できるようにしています。\n\nDatabricksは、サーバーレスデータウェアハウスやデータエンジニアリングワークフローを効率的に支援する機能も備えており、特にJupyter NotebookやGoogle Colaboratoryとの違いは、クラウド環境でのスケーラビリティやパフォーマンスの最適化にあります。'
gpt-4o-mini が、Databricksに関する最新かつ専門的な知識を必要とするクエリに回答できたことがわかります。最も関連性の高いテキストのチャンクを含む data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf ファイルの内容を使用しました。検索エンジンによって返された異なるテキストをさらに分析したい場合は、クエリに include=["output[*].file_search_call.search_results"] を追加することで、検索結果を分析することもできます。
パフォーマンスの評価
情報検索システムにとって重要なのは、回答に対して取得されたファイルの関連性と品質を測定することです。このクックブックの次のステップでは、評価データセットを生成し、この生成されたデータセットに対してさまざまな指標を計算します。これは不完全なアプローチであり、常に独自のユースケースに対して人間が検証した評価データセットを持つことをお勧めしますが、評価方法を示します。不完全である理由は、生成された質問の一部が一般的なものである可能性があるためです(例:「この文書の主要な利害関係者が述べていることは何ですか」)。そのため、検索テストはその質問がどの文書のために生成されたかを特定するのが難しい場合があります。
質問の生成
ローカルにあるPDFを読み取り、この文書でしか回答できない質問を生成する関数を作成します。これにより、後で使用できる評価データセットが作成されます。
def extract_text_from_pdf(pdf_path):
text = ""
try:
with open(pdf_path, "rb") as f:
reader = PyPDF2.PdfReader(f)
for page in reader.pages:
page_text = page.extract_text()
if page_text:
text += page_text
except Exception as e:
print(f"{pdf_path} の読み取りエラー: {e}")
return text
def generate_questions(pdf_path):
text = extract_text_from_pdf(pdf_path)
prompt = (
"このドキュメントからのみ回答できる質問を生成できますか?:\n"
f"{text}\n\n"
)
response = client.responses.create(
input=prompt,
model="gpt-4o",
)
question = response.output[0].content[0].text
return question
最初のPDFファイルに対して関数generate_questionを実行すると、生成される質問の種類がわかります。
generate_questions(pdf_files[0])
'Sure, here are some questions based solely on the document provided:\n\n1. What is the primary focus of the 2nd edition of "The Big Book of MLOps"?\n2. Can you describe what LLMOps is and how it differs from traditional MLOps?\n3. What are the key components introduced in Unity Catalog?\n4. How does Databricks Model Serving simplify the deployment of real-time ML models?\n5. What are the main benefits of using Lakehouse Monitoring in Databricks?\n6. How does the reference architecture manage data and models across different environments?\n7. What is Retrieval Augmented Generation (RAG) and what is a typical workflow for it?\n8. How does prompt engineering play a role in LLM-powered applications?\n9. What are the considerations for choosing between third-party APIs and self-hosting models?\n10. What strategies are recommended for reducing the costs of inference with large language models?'
ローカルに保存されているすべてのPDFに対して質問を生成できます。
# 各PDFの質問を生成し、辞書に保存
questions_dict = {}
for pdf_path in pdf_files:
questions = generate_questions(pdf_path)
questions_dict[os.path.basename(pdf_path)] = questions
questions_dict
{'2023-10-EB-Big-Book-of-MLOps-2nd-Edition.pdf': 'Certainly! Here are some questions based specifically on the provided document:\n\n1. **What new section is included in the second edition of the Big Book of MLOps?**\n - A section on LLMOps.\n\n2. **What are the key benefits of using Unity Catalog as outlined in the document?**\n - Benefits include centralized access control, auditing, lineage, and data discovery capabilities across Databricks workspaces.\n\n3. **What is the purpose of the Lakehouse Monitoring solution?**\n - To ensure that both data and AI assets are of high quality, accurate, and reliable by implementing data and model monitoring.\n\n4. **What are the stages of the MLOps development process described in the document?**\n - Development, staging, and production.\n\n5. **What is one recommended architectural approach for ML model deployment?**\n - A "deploy code" approach, which separates the lifecycles of code and models, allowing for robust testing.\n\n6. **What are some methods mentioned for reducing LLM inference costs?**\n - Using smaller models, model distillation, quantization, and reducing computation through techniques like shortening queries.\n\n7. **What are the benefits of employing Retrieval Augmented Generation (RAG)?**\n - Dynamic context, reduced hallucinations, domain-specific contextualization, and cost-effectiveness for domain-specific knowledge adaptation.\n\n8. **What design principle remains central to Databricks’ MLOps offerings according to the document?**\n - A data-centric approach to machine learning.\n\n9. **How does the document suggest handling model deployment testing?**\n - Through pre-deployment testing like deployment readiness checks and load testing to ensure performance under varying demands.\n\n10. **What does the document highlight as a significant recent change in the machine learning landscape?**\n - The rapid advancement of generative AI, especially large language models (LLMs).',
'はじめてのDatabricks #Databricks - Qiita.pdf': '以下のドキュメントに基づいて質問を作成します。\n\n1. DatabricksとJupyter Notebookの主な違いは何ですか?\n2. Databricksでデータを保存する際の推奨方法は何ですか?\n3. Databricksのクラスターを効率的に使用するためのヒントは何ですか?\n4. Databricksでのデータ処理のステップはどのようになっていますか?\n5. Databricks内でユーザーが使用できるノートブックの特徴は何ですか?\n6. Databricksでのデータアクセス時に考慮すべき注意点は何ですか?\n7. Databricksクラスターの作成において、パーソナルコンピュートとは何ですか?\n8. データの可視化において、Databricksのノートブックはどのように役立ちますか?\n9. 書き込み処理を行う際の注意点は何でしょうか?\n10. DatabricksでSQLとPythonをどのように使い分けますか?\n\nこれらの質問は、提供されている情報を元に回答できる内容です。',
'Databricksクイックスタートガイド #AWS - Qiita.pdf': '以下のドキュメントに基づいた質問です:\n\n1. Databricksとは何ですか?\n2. Databricksレイクハウスの目的は何ですか?\n3. DatabricksのセットアップはAWSでの利用を想定していますか?\n4. Unity Catalogとは何ですか?\n5. Databricksでのデータサイエンスコラボレーションの方法は?\n6. Databricksのクラスター設定のベストプラクティスについて教えてください。\n7. Databricksノートブックとは何ですか?\n8. MLflowをDatabricksでどのように使用しますか?\n9. Databricks SQLの主な利点は何ですか?\n10. Databricksにおけるセキュリティ管理の機能は何ですか?\n\nこれらは、ドキュメントからの情報を基にした質問です。',
'data-intelligence-platform-for-dummies-databricks-special-edition-jp.pdf': 'はい、このドキュメントに基づいて質問を生成できます。例えば:\n\n1. Databricksのデータ・インテリジェンス・プラットフォームは何を提供しますか?\n2. データインテリジェンスとは具体的に何を指しますか?\n3. レイクハウスアーキテクチャの利点は何ですか?\n4. DatabricksIQの機能について教えてください。\n5. 生成AIと従来型AIの違いは何ですか?\n6. Databricks Workflowsの目的は何ですか?\n7. データインテリジェンス・プラットフォームの主要なセキュリティ機能は何ですか?\n8. データドリブンなインサイトとは何ですか?\n9. Mosaic AIとは何で、どのように活用されますか?\n10. 統合型データプラットフォームが必要とされる理由は何ですか?'}
私たちは現在、filename:questionの辞書を持っており、ドキュメントを提供せずにgpt-4o(-mini)に質問することができます。gpt-4oはベクトルストア内の関連ドキュメントを見つけることができるはずです。
辞書をデータフレームに変換し、gpt-4o-miniを使用して処理します。期待されるファイルを探します。
rows = []
for filename, query in questions_dict.items():
rows.append({"query": query, "_id": filename.replace(".pdf", "")})
# メトリクス評価パラメータ
k = 5
total_queries = len(rows)
correct_retrievals_at_k = 0
reciprocal_ranks = []
average_precisions = []
def process_query(row):
query = row['query']
expected_filename = row['_id'] + '.pdf'
# Responses APIを介してfile_searchを呼び出す
response = client.responses.create(
input=query,
model="gpt-4o-mini",
tools=[{
"type": "file_search",
"vector_store_ids": [vector_store_details['id']],
"max_num_results": k,
}],
tool_choice="required" # file_searchを強制するため、必須に設定
)
# レスポンスからアノテーションを抽出
annotations = None
if hasattr(response.output[1], 'content') and response.output[1].content:
annotations = response.output[1].content[0].annotations
elif hasattr(response.output[1], 'annotations'):
annotations = response.output[1].annotations
if annotations is None:
print(f"クエリに対するアノテーションがありません: {query}")
return False, 0, 0
# 上位k件の取得ファイル名を取得
retrieved_files = [result.filename for result in annotations[:k]]
if expected_filename in retrieved_files:
rank = retrieved_files.index(expected_filename) + 1
rr = 1 / rank
correct = True
else:
rr = 0
correct = False
# 平均適合率を計算
precisions = []
num_relevant = 0
for i, fname in enumerate(retrieved_files):
if fname == expected_filename:
num_relevant += 1
precisions.append(num_relevant / (i + 1))
avg_precision = sum(precisions) / len(precisions) if precisions else 0
if expected_filename not in retrieved_files:
print("期待されるファイルが取得ファイルに見つかりませんでした!")
if retrieved_files and retrieved_files[0] != expected_filename:
print(f"クエリ: {query}")
print(f"期待されるファイル: {expected_filename}")
print(f"最初に取得されたファイル: {retrieved_files[0]}")
print(f"取得されたファイル: {retrieved_files}")
print("-" * 50)
return correct, rr, avg_precision
process_query(rows[0])
(True, 1.0, 1.0)
この例では、リコールと精度は1であり、ファイルが最初にランク付けされたため、MRRとMAPも1です。
これで、質問のセットに対してこの処理を実行できます。
with ThreadPoolExecutor() as executor:
results = list(tqdm(executor.map(process_query, rows), total=total_queries))
correct_retrievals_at_k = 0
reciprocal_ranks = []
average_precisions = []
for correct, rr, avg_precision in results:
if correct:
correct_retrievals_at_k += 1
reciprocal_ranks.append(rr)
average_precisions.append(avg_precision)
# kにおけるリコールを計算
recall_at_k = correct_retrievals_at_k / total_queries
# この文脈では、リコールと同じ
precision_at_k = recall_at_k
# 平均逆順位を計算
mrr = sum(reciprocal_ranks) / total_queries
# 平均適合率を計算
map_score = sum(average_precisions) / total_queries
100%|██████████| 4/4 [00:15<00:00, 3.87s/it]期待されるファイルが取得ファイルに見つかりませんでした!
クエリ: 以下のドキュメントに基づいた質問です:
1. Databricksとは何ですか?
2. Databricksレイクハウスの目的は何ですか?
3. DatabricksのセットアップはAWSでの利用を想定していますか?
4. Unity Catalogとは何ですか?
5. Databricksでのデータサイエンスコラボレーションの方法は?
6. Databricksのクラスター設定のベストプラクティスについて教えてください。
7. Databricksノートブックとは何ですか?
8. MLflowをDatabricksでどのように使用しますか?
9. Databricks SQLの主な利点は何ですか?
10. Databricksにおけるセキュリティ管理の機能は何ですか?
これらは、ドキュメントからの情報を基にした質問です。
期待されるファイル: Databricksクイックスタートガイド #AWS - Qiita.pdf
最初に取得されたファイル: 2023-10-EB-Big-Book-of-MLOps-2nd-Edition.pdf
取得されたファイル: ['2023-10-EB-Big-Book-of-MLOps-2nd-Edition.pdf', '2023-10-EB-Big-Book-of-MLOps-2nd-Edition.pdf', '2023-10-EB-Big-Book-of-MLOps-2nd-Edition.pdf', '2023-10-EB-Big-Book-of-MLOps-2nd-Edition.pdf']
--------------------------------------------------
上記の出力は、評価データセットがファイルを最初にランク付けすることを期待していた場合に、ファイルが最初にランク付けされなかったか、まったく見つからなかったことを示しています。私たちの不完全な評価データセットからわかるように、いくつかの質問は一般的であり、別の文書を期待していましたが、私たちの検索システムはこの質問に対して特定の文書を検索しませんでした。
# kにおけるメトリクスを表示
print(f"k={k}におけるメトリクス:")
print(f"リコール@{k}: {recall_at_k:.4f}")
print(f"適合率@{k}: {precision_at_k:.4f}")
print(f"平均逆順位 (MRR): {mrr:.4f}")
print(f"平均適合率 (MAP): {map_score:.4f}")
k=5におけるメトリクス:
リコール@5: 0.7500
適合率@5: 0.7500
平均逆順位 (MRR): 0.7500
平均適合率 (MAP): 0.7167
このクックブックでは、次の方法を確認しました:
- PDFコンテキスト詰め込み(4oのビジョンモダリティを活用)と従来のPDFリーダーを使用して評価のデータセットを生成する
- ベクターストアを作成し、PDFでそれを埋める
- OpenAIのResponse APIの
file_searchツールコールを使用して、RAGシステムを活用してクエリに対するLLMの回答を得る - テキストのチャンクがどのように取得され、ランク付けされ、Response APIの一部として使用されるかを理解する
- 以前に生成された評価のデータセットで精度、リコール、MRR、MAPを測定する
Responsesを使用したファイル検索を使用することで、RAGアーキテクチャを簡素化し、新しいResponses APIを使用して単一のAPIコールでこれを活用できます。ファイルストレージ、埋め込み、取得がすべて1つのツールに統合されています!