きっかけはこちらのブログ記事です。
こちらでは、Delta Live Tables(DLT)でデータの前処理を通じて特徴量を作成し、AutoMLで時系列予測を行うという流れが説明されています。その際にはDLTにおけるリネージは追跡されるのですが、AutoMLになったところでリネージが途切れてしまいます。なお、サーバレスの時系列予測AutoMLは特徴量ストア連携をサポートしていません。
そこで、以下のような機械学習モデルのライフサイクルを通じてどのようにリネージを追跡できるのかを調べてみました。

参考にしたマニュアルはこちらです。
- Unity Catalogを使用したデータリネージのキャプチャと表示 | Databricks Documentation
- Unity Catalogで特徴量テーブルを使用する | Databricks Documentation
- Unity Catalogでモデルのライフサイクルを管理する | Databricks Documentation
- 特徴量のガバナンスのリネージ | Databricks Documentation
こちらのサンプルノートブックをベースとして、上のリネージを実現してみます。
DLTにおけるリネージ
DLTでパイプラインを構成すれば、パイプラインに含まれるビューやテーブルのリネージは自動で追跡されます。
特徴量テーブルの準備
wine_idだけでワインの品質を予測するエンドポイントを構築する必要があるとします。これには、エンドポイントがwine_idでワインの特徴を検索できるように、Feature Storeに保存された特徴量テーブルが必要です。このデモの目的のために、まずこの特徴量テーブルを自分で準備する必要があります。手順は次のとおりです:
- 生データを読み込み、クリーンアップする。
- 特徴量とラベルを分離する。
- 特徴量を特徴量テーブルに保存する。
生データの読み込み
生データには11の特徴量とquality列を含む12列があります。quality列は3から8の範囲の整数です。目標はquality値を予測するモデルを構築することです。
注意
- 以下では列名にスペースを含むデータを取り扱う必要があるため、
table_propertiesやdelta.minReaderVersionを指定することでカラムマッピングを有効化してエラーを回避しています。 - DLTではデータソースとしてボリュームからファイルを読み込んでいても、現時点ではボリュームとのリネージは追跡されません。
# モジュールのインポート
import dlt
from pyspark.sql.functions import *
# 変数にパイプラインパラメータを割り当て
my_catalog = spark.conf.get("my_catalog")
my_schema = spark.conf.get("my_schema")
my_volume = spark.conf.get("my_volume")
# ソースデータへのパスを定義
volume_path = f"/Volumes/{my_catalog}/{my_schema}/{my_volume}/"
# ボリュームからデータを取り込むストリーミングテーブルを定義
@dlt.table(
comment="生のワイン品質データ",
table_properties={
"delta.columnMapping.mode": "name",
'delta.minReaderVersion': '3',
'delta.minWriterVersion': '7'
}
)
def wine_quality_raw():
df = (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("inferSchema", True)
.option("separator", ";")
.option("header", True)
.load(volume_path)
)
return df
クリーンアップ
生データにはいくつかの問題があります:
- 列名にスペース(' ')が含まれており、これはFeature Storeと互換性がありません。
- 後でFeature Storeで検索できるように、生データにIDを追加する必要があります。
次のセルでは、これらの問題に対処します。
from pyspark.sql.types import DoubleType
# ID列を追加する関数
def addIdColumn(dataframe, id_column_name):
columns = dataframe.columns
new_df = dataframe.withColumn(id_column_name, monotonically_increasing_id())
return new_df[[id_column_name] + columns]
# 列名を変更する関数
def renameColumns(df):
renamed_df = df
for column in df.columns:
renamed_df = renamed_df.withColumn(column, df[column].cast(DoubleType()))
for column in df.columns:
renamed_df = renamed_df.withColumnRenamed(column, column.replace(' ', '_'))
return renamed_df
# データを検証するマテリアライズドビューを定義
@dlt.table(
comment="分析のためにクリーンアップされたワインデータ"
)
@dlt.expect("valid_quality", "quality IS NOT NULL")
def wine_quality_prepared():
raw_data_frame = spark.table("wine_quality_raw")
# 列名をFeature Storeに対応するように変更
renamed_df = renameColumns(raw_data_frame)
# ID列を追加
id_and_data = addIdColumn(renamed_df, 'wine_id')
return id_and_data
特徴量テーブルの作成
ワインが開封された後、アルコール度数は時間とともに変化する変数であると仮定します。この値はオンライン推論のためにリアルタイム入力として提供されます。
次に、データを2つの部分に分割し、静的特徴を含む部分のみを特徴量テーブルとして保存します。
注意
- こちらに記載があるように、DLTのマテリアライズドビューは主キーを設定することで特徴量テーブルとして取り扱うことができます。
# トレーニングと推論で使用するマテリアライズドビューを定義
@dlt.table(
comment="静的な特徴量テーブル",
schema="""
wine_id bigint NOT NULL PRIMARY KEY,
fixed_acidity double,
volatile_acidity double,
citric_acid double,
residual_sugar double,
chlorides double,
free_sulfur_dioxide double,
total_sulfur_dioxide double,
density double,
pH double,
sulphates double
"""
)
def wine_quality_static_feature():
id_and_data = spark.table("wine_quality_prepared")
# wine_idと静的特徴量
id_static_features = id_and_data.drop('alcohol', 'quality', '_rescued_data')
return id_static_features
# トレーニングと推論で使用するマテリアライズドビューを定義
@dlt.table(
comment="動的な特徴量と目的変数を保持するテーブル"
)
def wine_quality_id_rt_feature():
id_and_data = spark.table("wine_quality_prepared")
# wine_id、リアルタイム特徴量(alcohol)、ラベル(quality)
id_rt_feature_labels = id_and_data.select('wine_id', 'alcohol', 'quality')
return id_rt_feature_labels
このパイプラインを実行することで、以下のようなパイプラインのリネージが追跡されます。
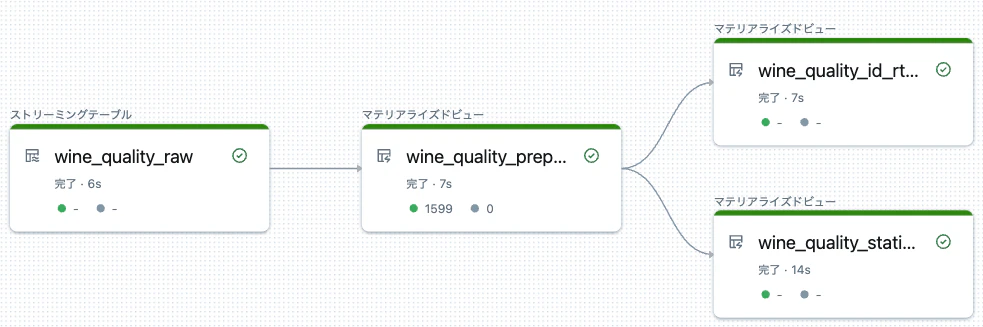
特徴量と機械学習モデルのリネージ
%pip install databricks-sdk==0.41.0
%pip install databricks-feature-engineering==0.8.0
%pip install mlflow>=2.9.0
dbutils.library.restartPython()
# カタログに対する `CREATE CATALOG` 権限が必要です。
# 必要に応じて、ここでカタログとスキーマ名を変更してください。
username = spark.sql("SELECT current_user()").first()["current_user()"]
username = username.split(".")[0]
# 既存のカタログを使います
catalog_name = "users"
# スキーマ名として使用するユーザー名を取得します。
schema_name = "takaaki_yayoi"
#spark.sql(f"CREATE CATALOG IF NOT EXISTS {catalog_name}")
spark.sql(f"USE CATALOG {catalog_name}")
#spark.sql(f"CREATE DATABASE IF NOT EXISTS {catalog_name}.{schema_name}")
spark.sql(f"USE SCHEMA {schema_name}")
Databricksオンラインテーブルの設定
このままでも、DLTのマテリアライズドビューを特徴量テーブルとして用いることで機械学習モデルとのリネージを追跡することができます。しかし、最後のモデルサービングエンドポイントでオンラインの特徴量ルックアップを行えるようにするには、オンラインテーブルにする必要があります。
カタログエクスプローラーUI、Databricks SDK、またはRest APIからオンラインテーブルを作成できます。以下に、Databricks Python SDKを使用する手順を説明します。詳細については、Databricksのドキュメントを参照してください(AWS | Azure)。必要な権限については、権限に関する情報を参照してください(AWS | Azure)。
wine_table = f"{catalog_name}.{schema_name}.wine_quality_static_feature"
online_table_name = f"{catalog_name}.{schema_name}.wine_quality_static_features_online"
オンラインテーブルの作成
from pprint import pprint
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.catalog import OnlineTable, OnlineTableSpec, OnlineTableSpecTriggeredSchedulingPolicy
workspace = WorkspaceClient()
# オンラインテーブルを作成
spec = OnlineTableSpec(
primary_key_columns = ["wine_id"],
source_table_full_name = wine_table,
run_triggered=OnlineTableSpecTriggeredSchedulingPolicy.from_dict({'triggered': 'true'}),
perform_full_copy=True)
online_table = OnlineTable(name=online_table_name, spec=spec)
try:
workspace.online_tables.create_and_wait(table=online_table)
except Exception as e:
if "already exists" in str(e):
print(f"オンラインテーブル {online_table_name} は既に存在します。再作成しません。")
else:
raise e
pprint(workspace.online_tables.get(online_table_name))
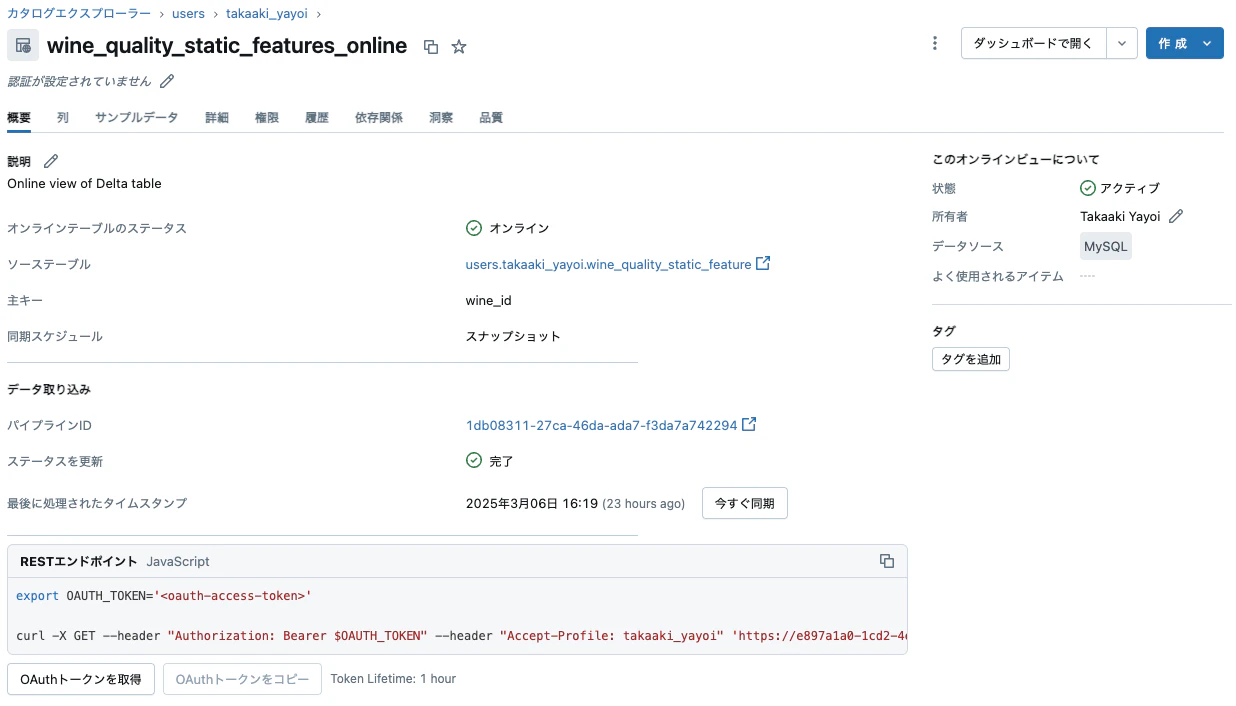
モデルのトレーニングとデプロイ
次に、特徴量を使用して分類器をトレーニングします。主キーを指定するだけで必要な特徴量を取得します。
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import logging
import mlflow.sklearn
from databricks.feature_engineering import FeatureLookup
まず、TrainingSetを定義します。トレーニングセットはfeature_lookupsリストを受け取り、各アイテムはFeature Store内の特徴量テーブルからの特徴量を表します。この例では、wine_idをルックアップキーとして使用し、テーブルonline_feature_store_example.wine_featuresからすべての特徴量を取得します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
id_rt_feature_labels = spark.table(f"{catalog_name}.{schema_name}.wine_quality_id_rt_feature")
ワイン品質トレーニングデータローダー
# トレーニングセットを作成
training_set = fe.create_training_set(
df=id_rt_feature_labels,
label='quality',
feature_lookups=[
FeatureLookup(
table_name=f"{catalog_name}.{schema_name}.wine_quality_static_feature",
lookup_key="wine_id"
)
],
exclude_columns=['wine_id'],
)
# Feature Storeからトレーニングデータをロード
training_df = training_set.load_df()
display(training_df)
| alcohol | fixed_acidity | volatile_acidity | citric_acid | residual_sugar | chlorides | free_sulfur_dioxide | total_sulfur_dioxide | density | pH | sulphates | quality |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 10.1 | 11.5 | 0.18 | 0.51 | 4 | 0.104 | 4 | 23 | 0.9996 | 3.28 | 0.97 | 6 |
| 10.6 | 9.1 | 0.28 | 0.48 | 1.8 | 0.067 | 26 | 46 | 0.9967 | 3.32 | 1.04 | 6 |
| 10 | 7.6 | 0.42 | 0.08 | 2.7 | 0.084 | 15 | 48 | 0.9968 | 3.21 | 0.59 | 5 |
| 10.4 | 6.4 | 0.79 | 0.04 | 2.2 | 0.061 | 11 | 17 | 0.99588 | 3.53 | 0.65 | 6 |
| 11.9 | 6.2 | 0.7 | 0.15 | 5.1 | 0.076 | 13 | 27 | 0.99622 | 3.54 | 0.6 | 6 |
次のセルでは、RandomForestClassifierモデルをトレーニングします。
# トレーニングデータの特徴量とラベルを準備
X_train = training_df.drop('quality').toPandas()
y_train = training_df.select('quality').toPandas()
# モデルをトレーニング
model = RandomForestClassifier()
model.fit(X_train, y_train.values.ravel())
トレーニング済みモデルをlog_modelを使用して保存します。log_modelは、モデルと特徴量(training_setを通じて)の間の系統情報も保存します。そのため、サービング中にモデルはルックアップキーだけで特徴量をどこから取得するかを自動的に認識します。
MLflowによるモデル登録
import mlflow
mlflow.set_registry_uri("databricks-uc")
registered_model_name = f"{catalog_name}.{schema_name}.wine_classifier"
fe.log_model(
model=model,
artifact_path="model",
flavor=mlflow.sklearn,
training_set=training_set,
registered_model_name=registered_model_name
)
# 最新のモデルバージョンを取得
client = mlflow.tracking.MlflowClient()
versions = client.search_model_versions(f"name='{registered_model_name}'")
registered_model_version = max(int(v.version) for v in versions)
log_modelを呼び出した後、新しいバージョンのモデルが保存されます。ここまでで、このようにリネージが追跡されています。
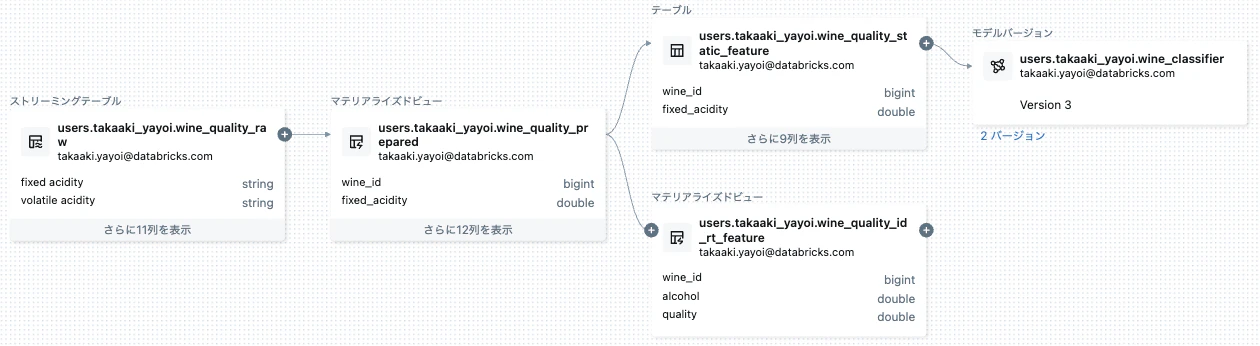
機械学習モデルとモデルサービングエンドポイントのリネージ
モデルをモデルサービングエンドポイントにデプロイすることでリネージが追跡されます。
自動特徴量ルックアップを使用したリアルタイムクエリの提供
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
# エンドポイントを作成
endpoint_name = f"{username}_wine_classifier_endpoint"
try:
status = workspace.serving_endpoints.create_and_wait(
name=endpoint_name,
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name=registered_model_name,
entity_version=registered_model_version,
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
print(status)
except Exception as e:
if "already exists" in str(e):
print(f"エンドポイント {endpoint_name} は既に存在するため、作成しません。")
else:
raise e

クエリを送信する
さて、ワインのボトルを開けて、ボトルから現在のABVを測定するセンサーがあるとします。モデルと自動特徴量ルックアップを使用したリアルタイムサービングを使用して、測定されたABV値をリアルタイム入力「alcohol」としてワインの品質を予測できます。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint=endpoint_name,
inputs={
"dataframe_records": [
{"wine_id": 25, "alcohol": 7.9},
{"wine_id": 25, "alcohol": 11.0},
{"wine_id": 25, "alcohol": 27.9},
{"wine_id": 79, "alcohol": 1.9},
{"wine_id": 79, "alcohol": 101.0},
{"wine_id": 37, "alcohol": 27.9},
]
},
)
pprint(response)
{'predictions': [5.0, 5.0, 5.0, 4.0, 5.0, 6.0]}
これで、エンドポイントとのリネージも追跡されます。
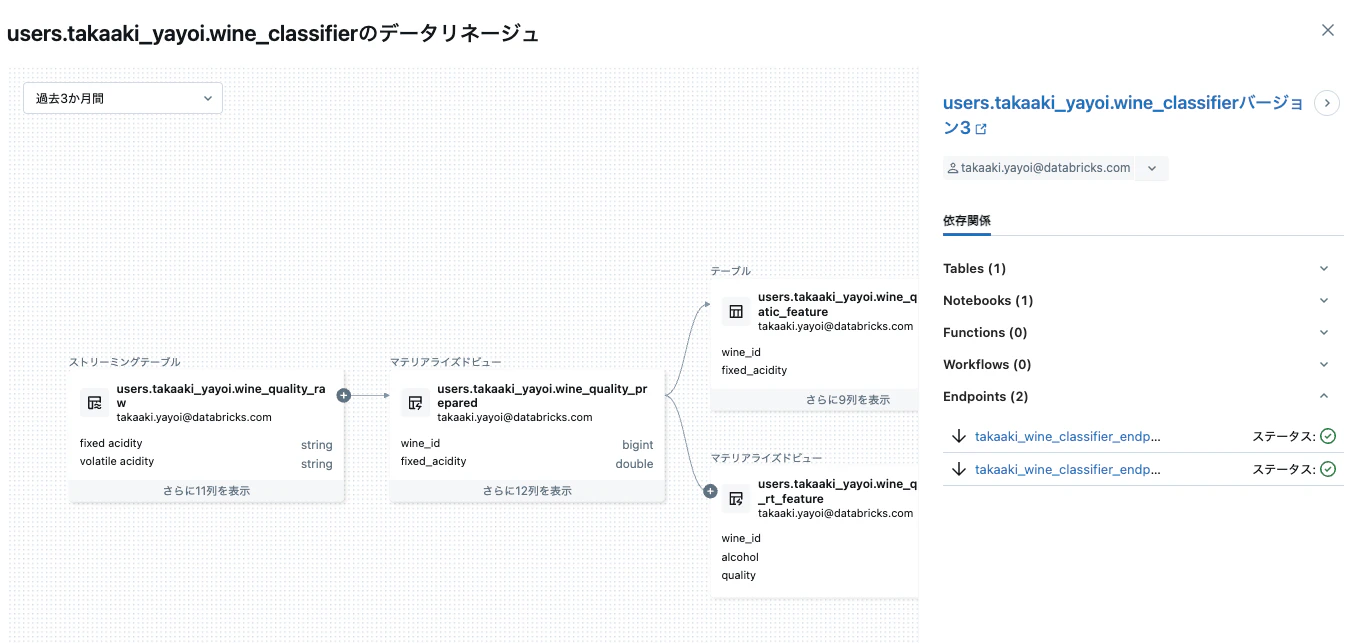
まとめ
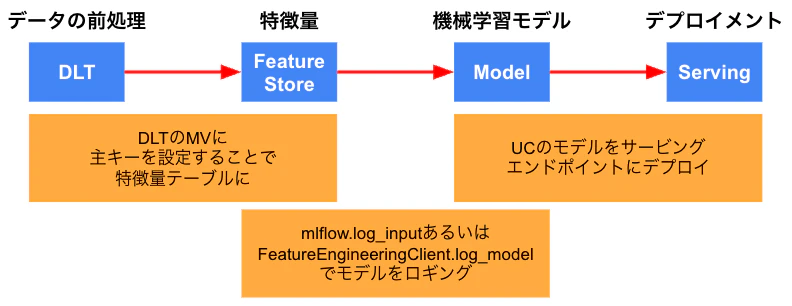
- DLTのリネージ: パイプラインによって生成されるテーブルやビューのリネージは追跡される。ボリュームとのリネージは未対応。主キーを設定することで特徴量テーブルとして使用できる。
-
特徴量テーブルと機械学習モデルのリネージ:
mlflow.log_inputあるいはFeatureEngineeringClient.log_modelでモデルをロギングすることでリネージが追跡される。 - 機械学習モデルとサービングエンドポイントとのリネージ: 特徴量ルックアップを行う場合にはオンラインテーブルを作成する必要がある。モデルをサービングエンドポイントにデプロイすればリネージが追跡される