DSPy on Databricks | Databricksの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
大規模言語モデル(LLM)は、プロンプティング技術の最適化を通じた効果的な人間とAIのインタラクションに対する興味を生み出しました。「プロンプトエンジニアリング」はモデルの出力をカスタマイズするための手法として成長しており、Retrieval Augmented Generation (RAG)のような高度なテクニックは、適切な情報を取得してレスポンスすることで、LLMの生成能力を強化しています。
スタンフォードのNLPグループによって開発されたDSPyは、「基盤モデルのプロンプティングではなく、プログラミング」を通じて複合AIシステムを構築するためのフレームワークとして誕生しました。DSPyはDatabricksのモデルサービングやVector Searchとの連携をサポートしています。
複合AIのエンジニアリング
これらのプロンプティングのテクニックは、AI開発者が複合AIシステム(翻訳)開発の過程で、LLM、リトリーバルモデル(RM)、そのほかのコンポーネントを組み合わせた複雑な「プロンプティングパイプライン」へのシフトの兆候を示しています。
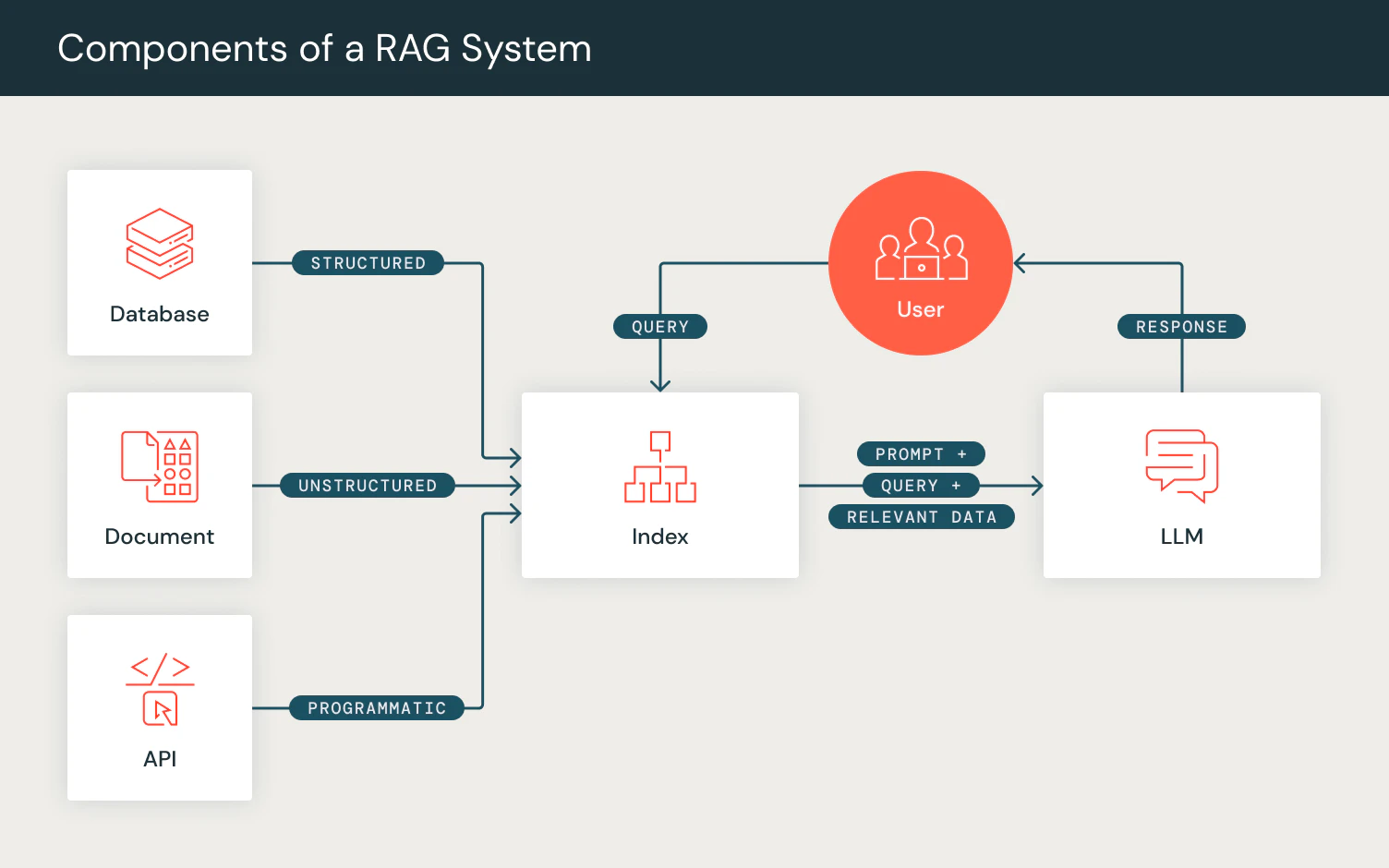
プロンプティングではなくプログラミング: DSPy
DSPyは、後段のタスクメトリクスに対し、LLMの呼び出しと他の計算ツールを構成することで、AI駆動システムのパフォーマンスを最適化します。従来の「プロンプトエンジニアリング」とは異なり、DSPyはユーザー定義の自然言語シグネチャを完全な指示とfew-shotの例に変換することで、プロンプトのチューニングを自動化します。PyTorchにおけるエンドツーエンドのパイプラインの最適化を真似ることで、ユーザーはDSPyによって望む目標に対して最適化しつつも、AIシステムをレイヤーごとに定義、構成することが可能となります。
class RAG(dspy.Module):
def __init__(self, num_passages=3):
super().__init__()
# declare three modules: the retriever, a query generator, and an answer generator
self.retrieve = retriever_model
self.generate_answer = dspy.Predict("context, query -> answer")
def forward(self, query):
retrieved_context = self.retrieve(query)
context, context_ids = retrieved_context.docs, retrieved_context.doc_ids
prediction = self.generate_answer(context=context, query=query)
return dspy.Prediction(answer=prediction.answer)
DSPyのプログラムでは、2つの主要なメソッドがあります:
- 初期化: ユーザーは、DSPyレイヤーとして自分のプロンプティングパイプラインのコンポーネントを定義することができます。例えば、RAGに関連するステップを考慮するために、retrievalレイヤーとgenerationレイヤーを定義します。
- 入力された検索クエリーに対して適切な文や文書のセットを収集するためにユーザーが設定したRMを用いるretrievalレイヤー
dspy.Retrieveを定義します。 - そして、生成のためのプロンプトを内部で準備する
dspy.Predictモジュールを用いるgenerationレイヤーを初期化します。このgenerationレイヤーを設定するには、入力フィールド("context", "query")と期待する出力フィールド("answer")によって指定される、自然言語のシグネチャフォーマットでRAGタスクを定義します。すると、このモジュールは定義されたフォーマットに合致するプロンプトを内部で整形し、ユーザーが設定したLMからの生成結果を返却します。
- 入力された検索クエリーに対して適切な文や文書のセットを収集するためにユーザーが設定したRMを用いるretrievalレイヤー
- フォワード: PyTorchのフォワードパスと同じように、DSPyプログラムのフォワード関数によって、ユーザーはプロンプトパイプラインのロジックを構成することができます。初期化したレイヤーを用いて、指定されたクエリーに対する一連の文を収集し、回答を生成するために、それらの文とクエリーをコンテキストを活用し、DSPyのディクショナリーオブジェクトで期待されるアウトプットを行うRAGの計算フローをセットアップします。
DSPyプログラムとDBRXを用いたRAGの実践を見ていきましょう。
この例では、適切な回答を引き出すために複数のステップを必要とする質問を含むHotPotQAのサンプル質問を使用します。
query = "The Wings entered a new era, following the retirement of which Canadian retired professional ice hockey player and current general manager of the Tampa Bay Lightning of the National Hockey League (NHL)?"
answer = "Steve Yzerman"
はじめに、DSPyでLMとRMを設定しましょう。DSPyは様々な言語モデル、リトリーバルモデルのインテグレーションを提供しており、ユーザーはこれらのパラメータを設定し、すべてのDSPy定義のプログラムが確実にそれらの設定を通じて動作させることができます。
dspy.settings.configure(lm=lm, rm=retriever_model)
定義したDSPyのRAGプログラムを宣言して、入力として質問を与えましょう。
rag = RAG()
rag(query=query)
リトリーバルステップでは、内部的には以下のようにフォーマットされるトップ3の適切な文を出力するself.retrieveレイヤーにクエリーが渡されます:
[1] «Steve Yzerman | Stephen Gregory "Steve" Yzerman ( ; born May 9, 1965) is a Canadian retired professional ice hockey player and current general manager of the Tampa Bay Lightning of the National Hockey League (NHL). He is ...»
[2] «2006–07 Detroit Red Wings season | The 2006–07 Detroit Red Wings season was the ...»
[3] «List of Tampa Bay Lightning general managers | The Tampa Bay Lightning are ...»
これらの取得された文とクエリーを自然言語シグネチャの入力フィールド"context, query"に合致するdspy.Predictモジュールのself.generate_answerに引き渡します。これは内部的には、いくつかの基本的なフォーマット処理とフレージング処理を適用するので、LMに対するプロンプトエンジニアリングを行うことなしに、正確なタスクの説明によってモデルに指示することができます。
フォーマット処理を宣言すると、入力フィールドの"context"と"query"に値が代入され、最終的なプロンプトがDBRXに送信されます:
Given the fields `context`, `query`, produce the fields `answer`.
---
Follow the following format.
Context: ${context}
Query: ${query}
Reasoning: Let's think step by step in order to ${produce the answer}. We ...
Answer: ${answer}
---
Context:
[1] «Steve Yzerman | Stephen Gregory "Steve" Yzerman ( ; born May 9, 1965) is a Canadian retired professional ice hockey player and current general manager of the Tampa Bay Lightning of the National Hockey League (NHL). He is ...»
[2] «2006–07 Detroit Red Wings season | The 2006–07 Detroit Red Wings season was the ...»
[3] «List of Tampa Bay Lightning general managers | The Tampa Bay Lightning are ...»
Query: The Wings entered a new era, following the retirement of which Canadian retired professional ice hockey player and current general manager of the Tampa Bay Lightning of the National Hockey League (NHL)?
Answer:
DBRXはAnswer:フィールドに値を埋め込み、以下を呼び出すことでこのプロンプト生成を確認することができます:
lm.inspect_history(n=1)
これは、LMからの最後のプロンプト生成で“Steve Yzerman”という回答を生成しており、正しい回答となっています!
Given the fields `context`, `query`, produce the fields `answer`.
---
Follow the following format.
Context: ${context}
Query: ${query}
Reasoning: Let's think step by step in order to ${produce the answer}. We ...
Answer: ${answer}
---
Context:
[1] «Steve Yzerman | Stephen Gregory "Steve" Yzerman ( ; born May 9, 1965) is a Canadian retired professional ice hockey player and current general manager of the Tampa Bay Lightning of the National Hockey League (NHL). He is ...»
[2] «2006–07 Detroit Red Wings season | The 2006–07 Detroit Red Wings season was the ...»
[3] «List of Tampa Bay Lightning general managers | The Tampa Bay Lightning are ...»
Query: The Wings entered a new era, following the retirement of which Canadian retired professional ice hockey player and current general manager of the Tampa Bay Lightning of the National Hockey League (NHL)?
Answer: Steve Yzerman.
DSPyは、ファインチューニング、コンテキスト内学習、情報抽出、自己洗練など様々な言語モデルタスクで活用されています。この自動化アプローチは、人間が記述した標準的なfewショットのプロンプトを上回っており、マルチホップのRAGのような自然言語タスクやGSM8Kのような数学ベンチマークでは、GPT-3.5では最大46%、Llama2-13b-chatでは65%という結果を示しています。
DatabricksにおけるDSPy
DSPyはモデルサービングやVector SearchのDatabricks開発者のエンドポイントとのインテグレーションをサポートしました。ユーザーは、dspy.Databricksを通じてOpenAI SDKによるDatabricksがホストする基盤モデルAPIを設定することができます。これによって、ユーザーはDatabricksでホストされるモデルに対する自分達のエンドツーエンドのDSPyパイプラインを評価することができます。現時点でモデルサービングエンドポイントでサポートされるモデルは: チャット(DBRX Instruct, Mixtral-8x7B Instruct, Llama 2 70B Chat)、コンプリーション(MPT 7B Instruct)そしてエンベディング(BGE Large (En))モデルです。
チャットモデル
lm = dspy.Databricks(model='databricks-dbrx-instruct', model_type='chat', api_key = {Databricks API key}, api_base = {Databricks Model Endpoint url})
lm(prompt)
コンプリーションモデル
lm = dspy.Databricks(model="databricks-mpt-7b-instruct", ...)
lm(prompt)
エンベディングモデル
lm = dspy.Databricks(model="databricks-bge-large-en", model_type='embeddings', ...)
lm(prompt)
リトリーバモデル/Vector Search
さらに、ユーザーはDatabricks Vector Searchを通じてリトリーバモデルを設定することができます。Vector Searchのインデックスとエンドポイントの作成の後で、ユーザーはdspy.DatabricksRMを通じて対応するRMのパラメータを指定することができます:
retriever_model = DatabricksRM(databricks_index_name = index_name, databricks_endpoint = workspace_base_url, databricks_token = databricks_api_token, columns= ["id", "text", "metadata", "text_vector"], k=3, ...)
ユーザーは、対応するDatabricksエンドポイントに対してLMとRMを設定し、DSPyプログラムを実行することでグローバルに設定することができます。
dspy.settings.configure(lm=llm, rm=retriever_model)
このインテグレーションによって、ユーザーはDatabricksのエンドポイントを用いてRAGのようなエンドツーエンドのDSPyアプリケーションを構築、評価することができます!
生成AIタスクをどのようにして、Databricksを用いた多芸なDSPyのパイプラインに変換するのかを学ぶには、公式のDSPy GitHubリポジトリ、ドキュメント、Discordをチェックしてみてください!