こちらの前段となります。
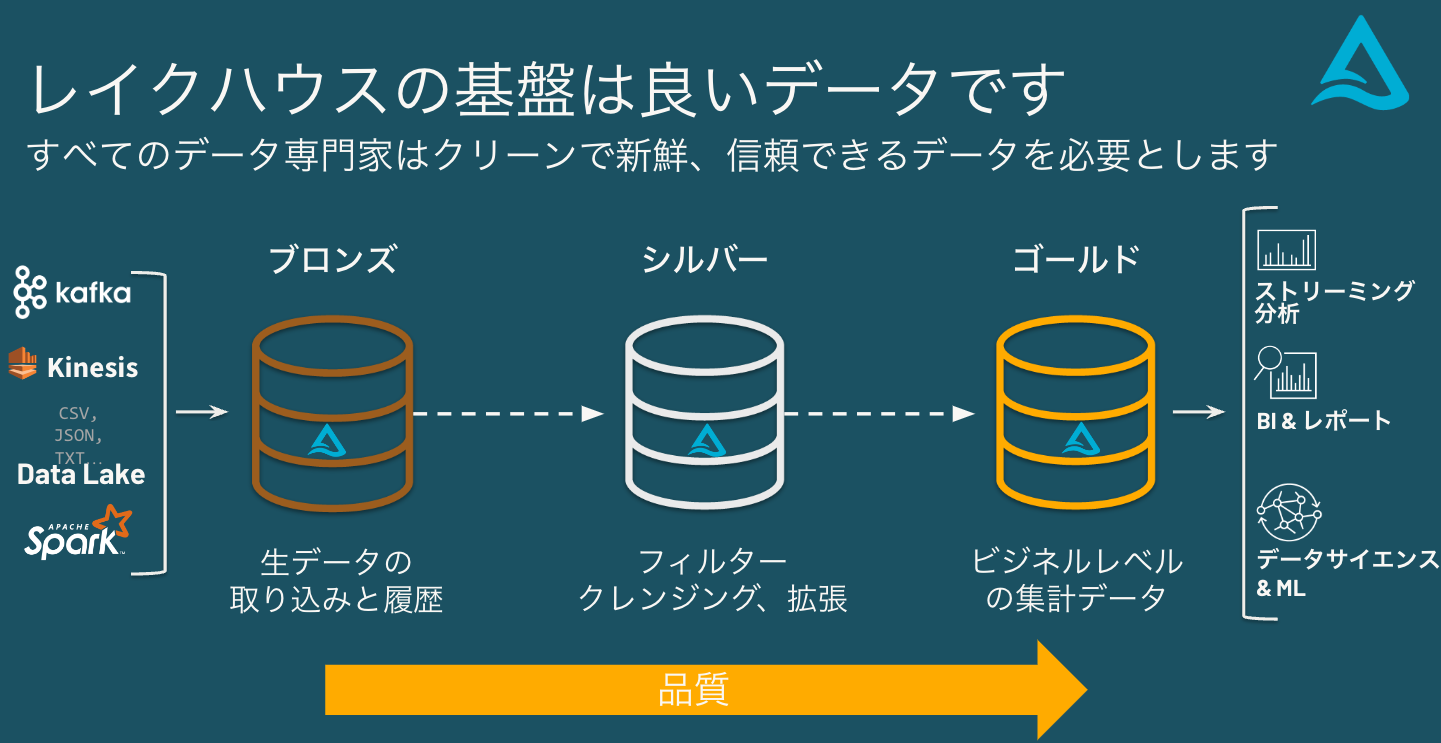
レイクハウスの基盤は良いデータです
すべてのデータ専門家はクリーンで新鮮、信頼できるデータを必要とします。
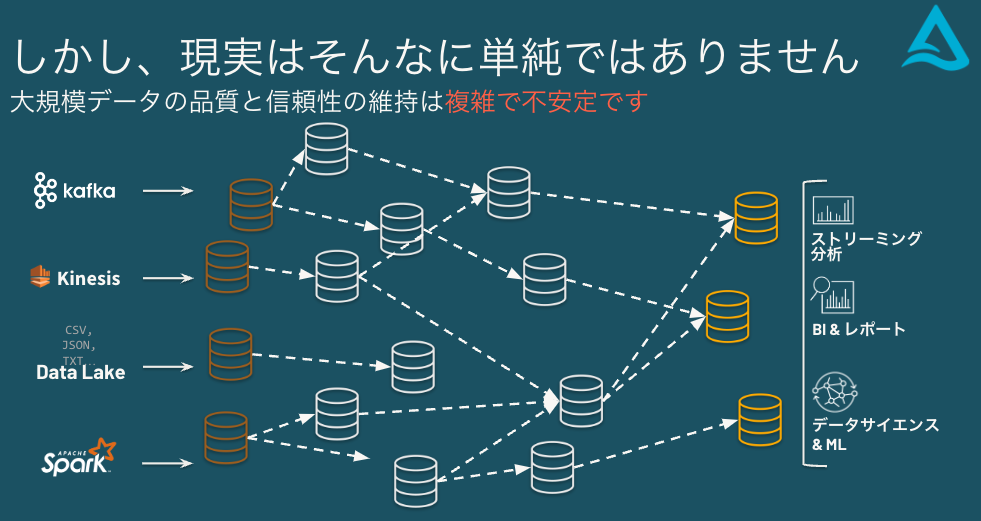
しかし、現実はそんなに単純ではありません
大規模データの品質と信頼性の維持は複雑で不安定です。
データ専門家としての人生…
CEOから無茶振りされることもあります。

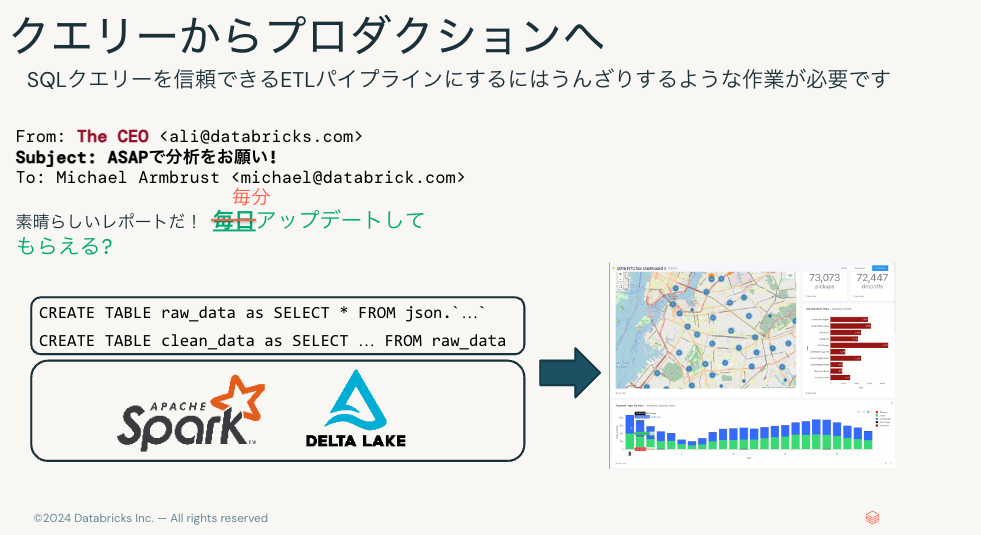
クエリーからプロダクションへ
SQLクエリーを本番システムに持っていくには多くの苦労が伴います。
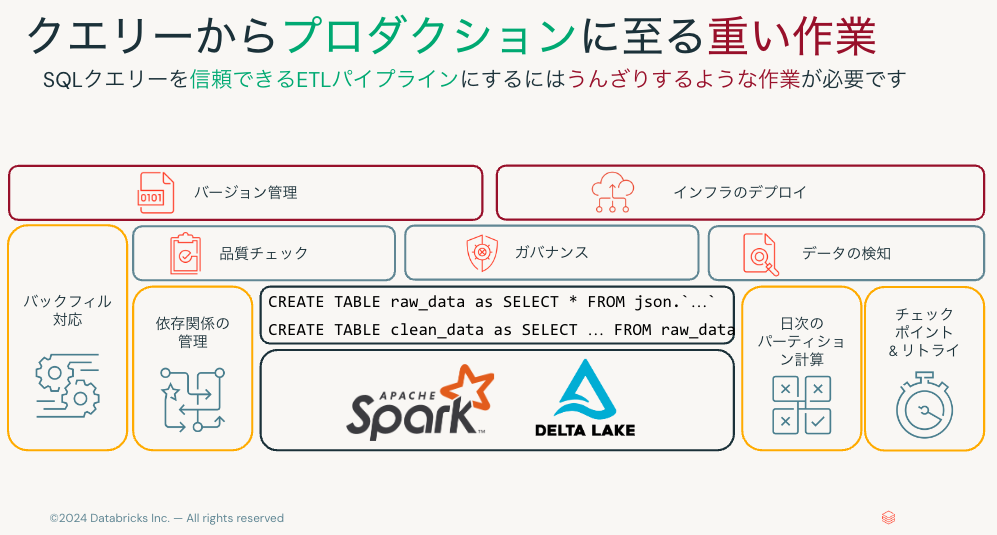
SQLクエリー以外にも、以下のようなことを検討、実装しなくてはなりません。
- バージョン管理
- インフラのデプロイ
- 品質チェック
- ガバナンス
- データの検知
- バックフィル対応
- 依存関係の管理
- 日次のパーティション計算
- チェックポイント & リトライ
データエンジニアは、変換処理ではなくツールの準備に時間が費やされます。

フォーカスしなくてはいけないのは、データから価値を得ることです。

Delta Live Tablesのご紹介
LIVEを追加するだけでクエリーからプロダクションパイプラインへ。

Delta Live Tablesの基本コンセプト
宣言型プログラミングのご紹介
宣言型プログラムはどのようにするのかではなく何をすべきかを記述します。

命令型プログラム
numbers = […]
sum = 0
for n in numbers:
sum += n
print(n)
宣言型プログラム
SELECT sum(n) FROM numbers

ワークフローかDLTか?
大抵両方です: DLTを含むすべてをワークフローはオーケストレートできます。
-
すべてのタスクの実行にワークフローを使用
- スケジュールで実行
- 他のタスクが完了したら実行
- ファイルが到着したら実行
- 他のテーブルが更新された実行
-
データフローの管理にDLTを使用
- Deltaテーブルの作成/更新
- 構造化ストリーミングの実行
なぜ宣言型プログラミング?
あなたの目的を理解することでDLTはつまらないことの面倒を見てくれます。
- 定型文の排除
- 耐障害性
- 状態管理
- オブジェクトのライフサイクル
- スケジュール、依存関係、並列度
- 一般的なデータの問題 (CDC、スキーマ進化)
- 最適化
- 動的実行や複数クエリーに対するベストな戦略を選択
- オペレーション
- HMR(Hot Module Replacement) – システムの退行やクラウド問題を自動で検知、対策
DLTのコアの抽象化
データセットを定義すると、DLTは自動でそれらを最新の状態に維持します。

ストリーミングテーブル
(複数の)ストリームが書き込まれるDeltaテーブル
用途:
- データの取り込み
- 低レーテンシーの変換処理
- 大規模データ
マテリアライズドビュー
Deltaテーブルに格納されるクエリーの結果
用途:
- データの変換
- 集計テーブルの構築
- BIのクエリーとレポートの高速化
ストリーミングテーブルとは?
構造化ストリーミングが書き込みを行うDeltaテーブルです。

CREATE STREAMING TABLE report
AS SELECT *
FROM read_files("/mydata/", "json")
- ストリーミングテーブルはKafka、Kinesis、Auto Loader(クラウドストレージ上のファイル)のような追加オンリーのデータソースから読み込みを行います
- ストリーミングテーブルは、それぞれの入力レコードを一度だけ読み込むことで、コストとレーテンシーを削減します
- ストリーミングテーブルはアドホックなデータ操作(GDPR等)のためのDML(UPDATE, DELETE, MERGE)をサポートします
マテリアライズドビューとは?
事前に計算され、Deltaに格納されるクエリーの結果です。
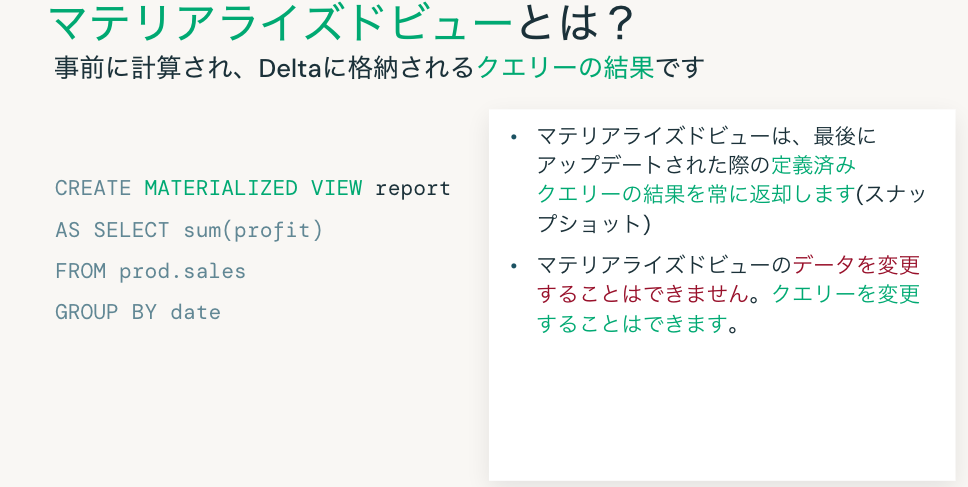
CREATE MATERIALIZED VIEW report
AS SELECT sum(profit)
FROM prod.sales
GROUP BY date
- マテリアライズドビューは、最後にアップデートされた際の定義済みクエリーの結果を常に返却します(スナップショット)
- マテリアライズドビューのデータを変更することはできません。クエリーを変更することはできます。
Pythonの活用
高度なデータフレームのコードとUDFの記述が可能です。

import dlt
@dlt.table
def report():
df = spark.table("LIVE.events")
return df.select(…)
spark.udf.register(
"complex_function",
lambda x: …)
- データフレームを返却する任意の関数に
@dlt.tableを追加します。 - 単一のパイプラインでSQL/Pythonのノートブックを混成、マッチさせます。
- しかし、単一のノートブックではすべてPythonかすべてSQLである必要があります(ノートブックレベルで混成、マッチはできません)
- PySpark、Koalas、SQL文字列を用いてデータフレームを構成できます。
クイックノート: 用語の進化
- STREAMING LIVE TABLE ➡ STREAMING TABLE
- LIVE TABLE ➡ MATERIALIZED VIEW
セマンティクスは同じで、古い文法との互換性をサポートします。我々のゴールは、文法をシンプルにして他のシステムとマッチさせることです。
エクスペクテーションによる適正性の保証
エクスペクテーションはプロダクションのデータ品質を保証するテストです。
CONSTRAINT valid_timestamp
EXPECT (timestamp > '2012-01-01’)
ON VIOLATION DROP
@dlt.expect_or_drop(
"valid_timestamp",
col("timestamp") > '2012-01-01')
エクスペクテーションは処理の過程でそれぞれの行の検証に用いられるtrue/falseのエクスプレッションです。
DLTはエクスペクテーションの違反レコードに対する柔軟なポリシーを提供します:
- 不正レコード数の追跡
- 不正レコードの削除
- 一つの不正レコードで処理を中止
- 検疫 (提供予定、あるいはクックブックのレシピをお使いください)
パイプラインの作成
DatabricksのUIによるパイプラインの作成方法。

- CREATE ST/MVの記述
- ノートブックでテーブル定義を記述します。
- Databricks Reposによってテーブル定義のバージョン管理が可能になります。
- パイプラインの作成
- 一つのパイプラインでは、一つ以上のノートブックと必要な設定を組み合わせます。
- スタートをクリック
- DLTはパイプラインのすべてのテーブルを作成、更新します。
DLTパイプラインへのデータの取り込み
- すべてのビルトインのSparkデータソース
- ファイル - バッチとストリーミングの両方、しかし、ファイル一覧のみ、スキーマ進化は未対応
- JDBC - DBRバンドルのデータベースドライバーのみ、バッチのみ
- Databricks Auto Loader
- ストリーミングテーブルのみ
- ファイル通知や最適化ファイル一覧モード
- スキーマ進化!(DLTではデフォルト)
- Python & SQL APIの両方
- ストリーミングシステム (多くの場合Python):
- Kafka (read_kafka関数でSQLでもサポート)
- Kinesis
- EventHubs (Kafkaコネクター経由)
- より多くのソースを提供予定…
データロードの例
SQLを用いたバッチモードでJSONファイルを読み込み
CREATE MATERIALIZED VIEW taxi_raw
AS SELECT * FROM json.`/.../json/`
Pythonを用いたストリーミングモードでParquetファイルを読み込み
@dlt.table
def raw_parquet():
return spark.readStream.format("parquet").load(raw_path)
Kafkaコネクターを用いたAzure Event Hubsからの読み込み
@dlt.table(table_properties = {"pipelines.reset.allowed": "false"})
def bronze():
eh_sasl = f'kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="$ConnectionString" password="{readConnectionString}";'
kafka_options = { "kafka.bootstrap.servers": f"{eh_namespace}.servicebus.windows.net:9093",
"kafka.sasl.mechanism": "PLAIN", "kafka.security.protocol": "SASL_SSL",
"startingOffsets": "earliest", "failOnDataLoss": False,
"kafka.sasl.jaas.config": eh_sasl, "subscribe": eh_topic, }
df = spark.readStream\
.format("kafka")\
.options(**kafka_options)\
.load()\
.withColumn("value", F.col("value").cast("string"))
Databricks Auto LoaderとDLTの活用
SQLのread_files関数を使用(以前はcloud_files)
CREATE STREAMING TABLE raw
AS SELECT *
FROM read_files('/path/…/*.csv', 'csv',
map('header', 'true',
'cloudFiles.inferColumnTypes', 'true')
);
パラメーター:
- ファイルパス (必須)
- ファイルフォーマット (必須)
- 設定 (
map<string, string>, オプション)
Pythonを使用
@dlt.table
def raw():
return (
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("cloudFiles.inferColumnTypes", "true")
.load("/path/…/*.csv")
ベストプラクティス
- 可能であればファイル一覧ではなくファイル通知モードを使いましょう - ファイル一覧の優れたパフォーマンス、少ないオーバーヘッド。
- スキーマ推定を使いましょう。DLTでAuto Loaderを使う際にはデフォルトでスキーマ進化が有効化されます!
- モニタリングに関しては、プロダクションのベストプラクティスに従いましょう。
無制限の保管のためにDeltaを活用(リファレンスアーキテクチャ)
Deltaは一時的なソースに対して、安価で柔軟、管理可能なストレージを提供します。
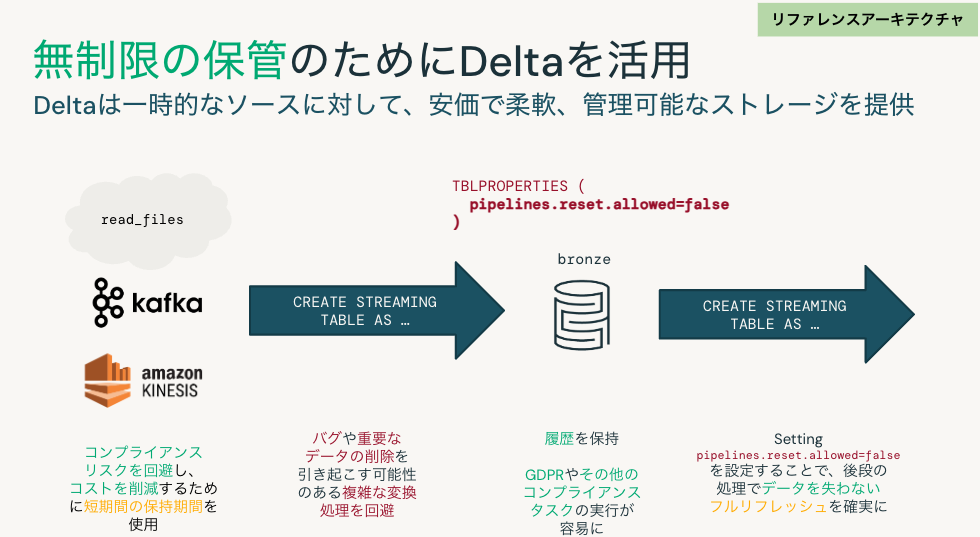
- ストリーミングソースでは、コンプライアンスリスクを回避し、コストを削減するために短期間の保持期間を使用します。
- ブロンズテーブルではバグや重要なデータの削除を引き起こす可能性のある複雑な変換処理を回避します。
- ブロンズテーブルでは、履歴を保持することで、GDPRやその他のコンプライアンスタスクの実行が容易になります。
-
pipelines.reset.allowed=falseを設定することで、後段の処理でデータを失わないフルリフレッシュを確実にします。
Delta Live Tables開発のベストプラクティスやDelta Live Tablesの本格運用に続きます。