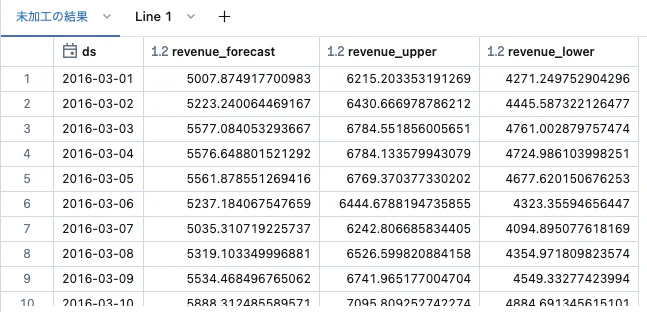
こちらのai_forecast関数を実際に動かして見ます。
重要!
この機能はパブリックプレビューです。プレビューに参加するにはDatabricksアカウントチームに連絡してください。
基本的な使い方
WITH
aggregated AS (
SELECT
DATE(tpep_pickup_datetime) AS ds, -- 日付に変換
SUM(fare_amount) AS revenue -- 収益の合計
FROM
samples.nyctaxi.trips
GROUP BY
1
)
SELECT * FROM AI_FORECAST(
TABLE(aggregated),
horizon => '2016-03-31', -- 予測のhorizon
time_col => 'ds', -- 時間列
value_col => 'revenue' -- 値列
)
これだけで予測を行うことができます。
可視化します。
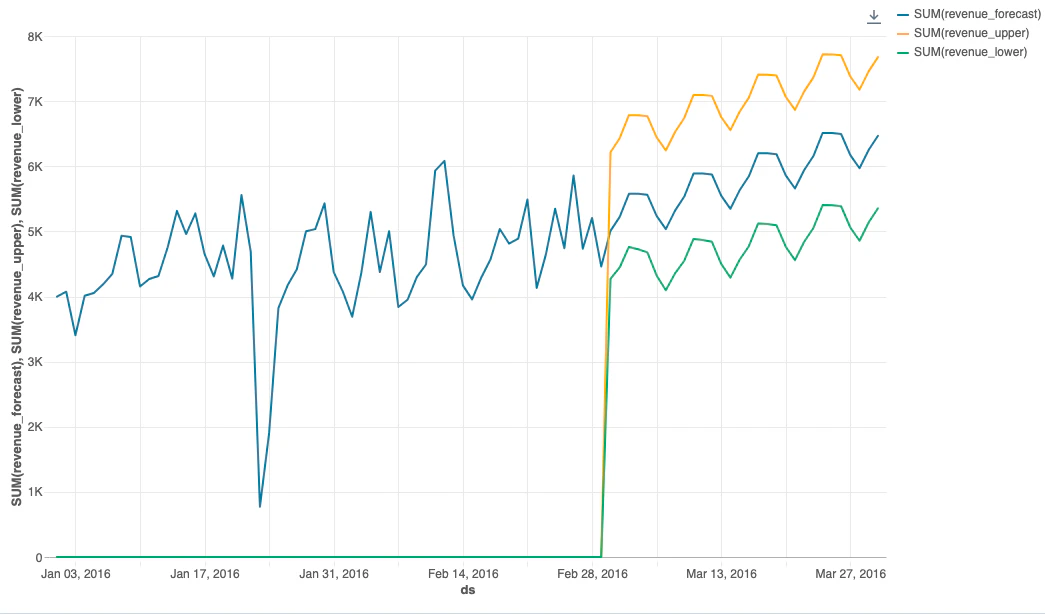
より挙動をわかりやすくするために、過去のデータ(トレーニングデータ)を追加します。
WITH aggregated AS (
SELECT
DATE(tpep_pickup_datetime) AS ds,
-- 日付に変換
SUM(fare_amount) AS revenue -- 収益の合計
FROM
samples.nyctaxi.trips
GROUP BY
1
)
SELECT
*
FROM
AI_FORECAST(
TABLE(aggregated),
horizon => '2016-03-31',
-- 予測の地平線
time_col => 'ds',
-- 時間列
value_col => 'revenue' -- 値列
)
UNION
SELECT
DATE(tpep_pickup_datetime) AS ds,
-- 日付に変換
SUM(fare_amount) AS revenue_forecast,
-- 収益の合計
NULL as revenue_lower,
NULL as revenue_upper
FROM
samples.nyctaxi.trips
GROUP BY
1
より複雑な例
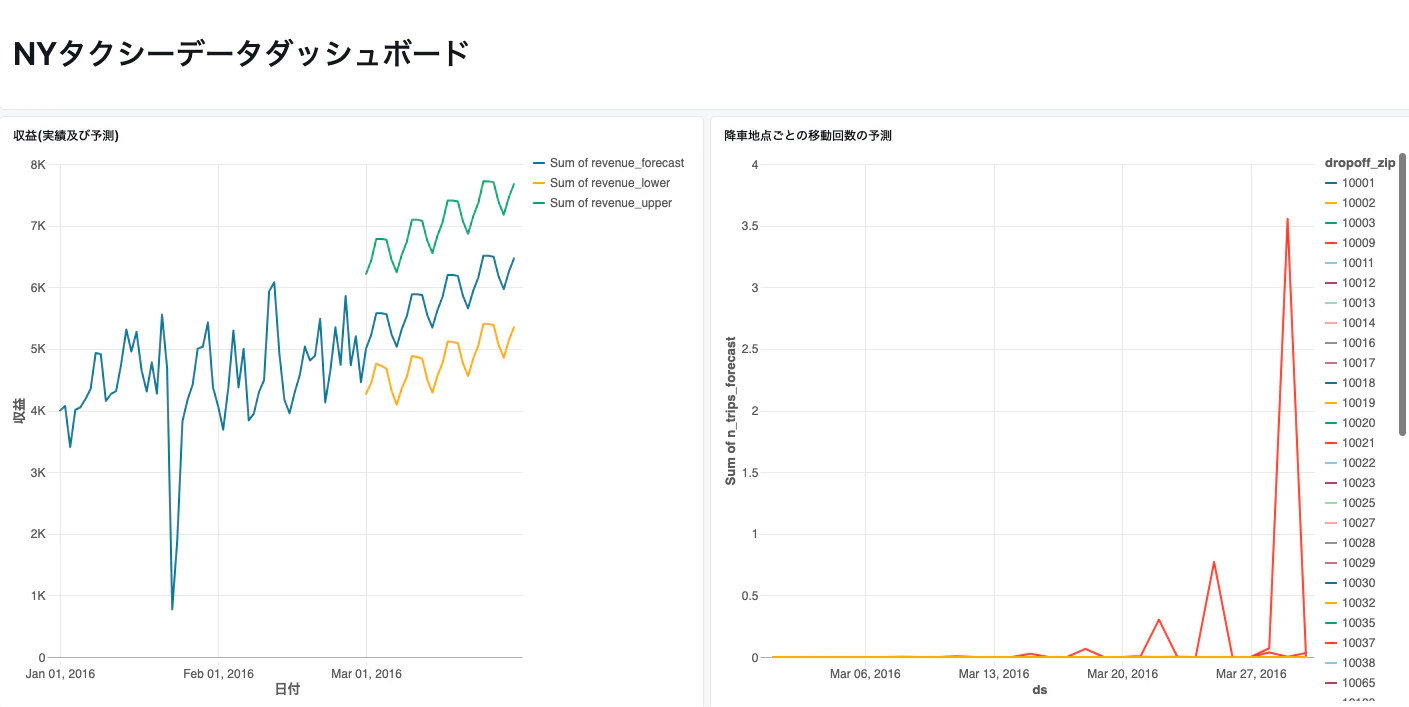
降車地点の郵便番号dropoff_zipでグルーピングし、revenueとn_tripsを予測しています。
WITH
aggregated AS (
SELECT
DATE(tpep_pickup_datetime) AS ds, -- 日付に変換
dropoff_zip, -- 配送先の郵便番号
SUM(fare_amount) AS revenue, -- 収益の合計
COUNT(*) AS n_trips -- トリップ数
FROM
samples.nyctaxi.trips
GROUP BY
1, 2
),
spine AS (
SELECT all_dates.ds, all_zipcodes.dropoff_zip
FROM (SELECT DISTINCT ds FROM aggregated) all_dates -- すべての日付
CROSS JOIN (SELECT DISTINCT dropoff_zip FROM aggregated) all_zipcodes -- すべての郵便番号
)
SELECT * FROM AI_FORECAST(
TABLE(
SELECT
spine.*,
COALESCE(aggregated.revenue, 0) AS revenue, -- 収益がnullの場合は0を使用
COALESCE(aggregated.n_trips, 0) AS n_trips -- トリップ数がnullの場合は0を使用
FROM spine LEFT JOIN aggregated USING (ds, dropoff_zip)
),
horizon => '2016-03-31', -- 予測の地平線
time_col => 'ds', -- 時間列
value_col => ARRAY('revenue', 'n_trips'), -- 値列
group_col => 'dropoff_zip', -- グループ化列
prediction_interval_width => 0.9, -- 予測区間の幅
parameters => '{"global_floor": 0}' -- パラメータ
)
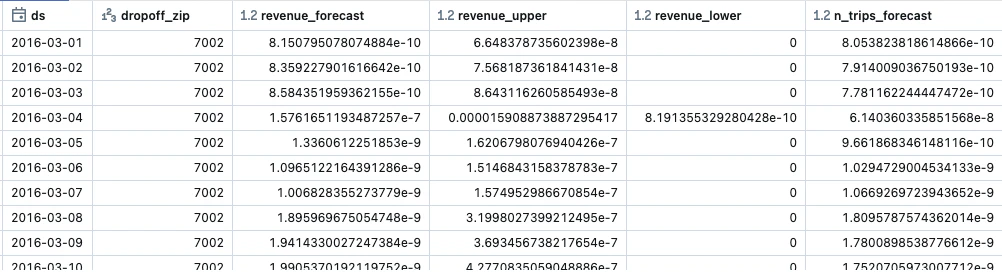
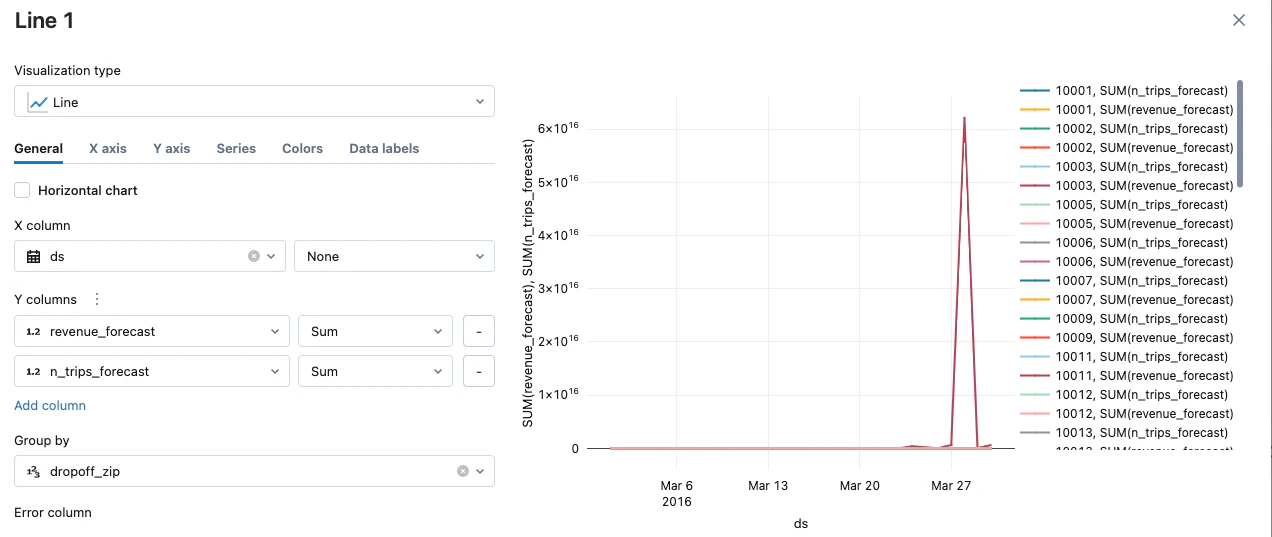
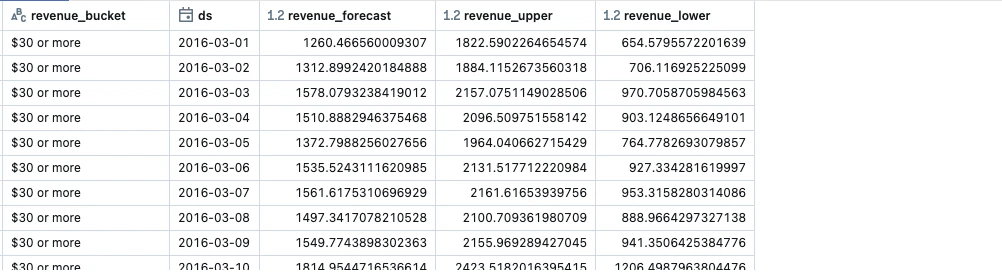
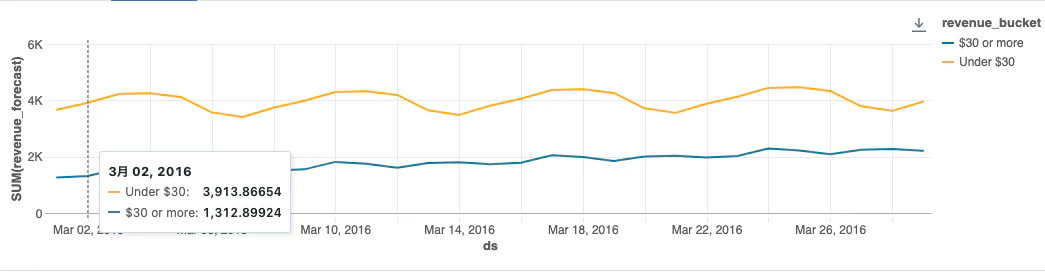
グループごとに異なるパラメーターを適用
WITH past AS (
SELECT
CASE
WHEN fare_amount < 30 THEN 'Under $30'
ELSE '$30 or more'
END AS revenue_bucket, -- 収入バケットを割り当てる
CASE
WHEN fare_amount < 30 THEN '{"daily_order": 0}' -- 日付の順序を0に設定
ELSE '{"daily_order": "auto"}' -- 日付の順序を自動に設定
END AS parameters,
DATE(tpep_pickup_datetime) AS ds, -- 日付列を設定
SUM(fare_amount) AS revenue -- 収入の合計を計算
FROM samples.nyctaxi.trips
GROUP BY 1, 2, 3
)
SELECT * FROM AI_FORECAST(
TABLE(past),
horizon => (SELECT MAX(ds) + INTERVAL 30 DAYS FROM past), -- 予測の地平線を設定
time_col => 'ds', -- 時間列を指定
value_col => 'revenue', -- 値列を指定
group_col => ARRAY('revenue_bucket'), -- グループ列を指定
parameters => 'parameters' -- パラメータを指定
)
動的にparametersというカラムを作成してその中にパラメーターを埋め込んでいます。
ダッシュボードへの組み込み
ロジックをSQLで完結できるので、簡単にダッシュボードに組み込むことができます。プレビュー申請の上、ご活用ください!