以前こちらの記事を書きましたが、前提としてサーバレスモデルサービングエンドポイントが必要です。Azure日本リージョンにはまだ来ていないので使えません。すみません。
ということで、ai_queryの代替がないかと探していたらこちらの記事に辿り着きました。
SparkとOpenAI APIの組み合わせということで、まさにドンピシャ。翻訳はこちらです。
若干手を加えながら実行していきます。使うデータは私のQiita記事です。
%sql
SELECT * FROM takaakiyayoi_catalog.vector_seach.qiita_partial limit 10
環境の準備
APIキーはシークレットに格納しておきます。
import os
import openai
import requests
import json
# ライブラリのインポート
import pyspark.sql.functions as F
from pyspark.sql.types import *
from pyspark.sql import Row
import aiohttp
import asyncio
import nest_asyncio
import ssl
from concurrent.futures import ThreadPoolExecutor, as_completed
from threading import Lock
# シークレットからAPIキーを取得
api_key = dbutils.secrets.get("demo-token-takaaki.yayoi", "openai")
# OpenAI REST APIのアドレス
api_url = "https://api.openai.com/v1/chat/completions"
手法1: Spark UDFを用いた同期API呼び出し
まずは、最もシンプルな実装を試します。
アプローチ
この手法では、Sparkデータフレームのそれぞれの行に対する同期API呼び出しを行うために、requestsライブラリを用いたユーザー定義関数(UDF)を使用しています。
コンセプト
- ユーザー定義関数: Sparkにおけるユーザー定義関数、UDFによって、それぞれの行に対してカスタムのPythonコードを実行することができます。
- 同期I/O: 同期呼び出しは、次に進む前にレスポンスを待ちますので、APIリクエストのようなI/Oバウンドのタスクでは遅くなることがあります。
比較
- 実装、理解するのにシンプルです。
- 小規模データセットや、レスポンス時間が問題にならない場合には適しています。
- 同期の性質を保つため、大規模データセットでは効率的ではありません。Sparkジョブ全体は完了するまでそれぞれのAPI呼び出しを待たなくてはならないので、実行時間が長くなります。
## `requests`パッケージを使用してOpenAI APIにクエリを送信する汎用関数
def query_gpt4(prompt):
# APIリクエストのヘッダー
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
messages=[{"role": "system", "content": "あなたは有能なアシスタントです"}, {"role": "user", "content": prompt}]
data = {
"model": "gpt-4o-mini",
"messages": messages
}
# APIリクエストを送信
response = requests.post(api_url, headers=headers, json=data)
# レスポンスが成功したか確認
if response.status_code == 200:
# レスポンスを解析
response_json = response.json()
return response_json['choices'][0]['message']['content']
else:
print("レスポンスの取得に失敗しました: ", response.status_code, response.text)
raise Exception
# UDFの登録
udf_query_gpt4 = udf(query_gpt4, StringType())
# プロンプトを含むデータフレームを読み込む
sql_statement = "SELECT * FROM takaakiyayoi_catalog.vector_seach.qiita_partial limit 10"
responseDF = spark.sql(sql_statement)
# for debug
#responseDF = spark.createDataFrame(data=[Row(body="Databricks は、エンタープライズレベルのデータ分析と AI ソリューションを大規模に構築、デプロイ、共有、保守するための、統合されたオープンな分析プラットフォームです。 Databricksデータインテリジェンスプラットフォームは、クラウド アカウントのクラウド ストレージおよびセキュリティと統合し、ユーザーに代わってクラウド インフラストラクチャを管理およびデプロイします。")])
display(responseDF)
本文を要約してもらいます。それに応じてプロンプトを編集します。以下のコードでは、本文の先頭に右の文字列を要約してください:を追加してから推論してもらっています。
responseDF = responseDF.withColumn(
"summary", udf_query_gpt4(F.concat(F.lit("右の文字列を要約してください:"), F.col("body")))
)
display(responseDF)
いい感じで動いています。ただ、上で書いたように、こちらの手法は同期的に動くので各行を逐次実行しており、Sparkの旨みがありません。10行の処理で約46秒を要しています。

パーティションを作成すれば、コア数の並列度を実現することは可能です。
# 再パーティショニング
# コア数でrepartitionしてコア数の並列度を実現することで、若干パフォーマンスを改善することができます
responseDF = responseDF.repartition(spark.sparkContext.defaultParallelism)
responseDF = responseDF.withColumn(
"summary", udf_query_gpt4(F.concat(F.lit("右の文字列を要約してください:"), F.col("body")))
)
display(responseDF)
ここでは、4コアで動かしているので若干速くなって約21秒でした。ただ、数百行、数千行に対するバッチ処理となるとスケールしなさそうです。ということで、二つ目の手法に。
手法2: asyncioを用いたPandasに対する非同期バッチ
アプローチ
- 非同期プログラミングのために
asyncio、非ブロッキングのHTTPリクエストのためにaiohttpを活用します。 - 非同期タスクを用いてデータフレームにあるプロンプトを処理します。
- API呼び出しをバッチにグルーピングし、それぞれのバッチを非同期で実行します。
- Jupyter環境で非同期タスクを実行するために
asyncio.get_event_loop()を使います。
キーコンセプト
- 非同期I/O: シングルスレッドで同時に複数のI/Oオペレーションを取り扱うことができるので、I/Oバウンドのタスクにおける効率性を改善します。
- バッチ処理: 頻繁なコンテキストスイッチのオーバーヘッドを削減し、ネットワーク利用を最適化することができます。
比較
- 非ブロッキングの性質のため、I/Oバウンドのタスクにおいては同期の手法よりも高速になる可能性があります。
- それぞれのプロンプトの個々の呼び出しを行うのではなく、バッチでリクエストを送信することで、APIサーバーの負荷を削減します。
- 非同期プログラミングなので実装が複雑になります。
# Jupyterで実行中の場合、既存のイベントループを利用するために必要なパッチを適用
nest_asyncio.apply()
# Azure OpenAI APIへの非同期呼び出しを行う関数
async def async_query_gpt4(session, api_key, prompt):
url = api_url # 必要に応じて調整
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "gpt-4o-mini", # 必要に応じてモデルを調整
"messages": [
{"role": "system", "content": "あなたは有能なアシスタントです"},
{"role": "user", "content": prompt}
]
}
async with session.post(url, json=data, headers=headers) as response:
return await response.json()
# バッチで非同期タスクを実行する関数
async def async_task(api_key, prompts, api_call_batch_size=128):
async with aiohttp.ClientSession() as session:
tasks = []
responses = [] # レスポンスを格納
for prompt in prompts:
task = asyncio.create_task(async_query_gpt4(session, api_key, prompt))
tasks.append(task)
if len(tasks) >= api_call_batch_size:
responses.extend(await asyncio.gather(*tasks))
tasks = []
responses.extend(await asyncio.gather(*tasks)) # 最後のバッチを処理
return responses
def process_prompts(DF, prompt_col, response_col='response', api_call_batch_size=128):
# プロンプトインデックスを作成し、プロンプトをリストに抽出
DF = DF.withColumn("prompt_idx", F.monotonically_increasing_id())
df = DF[['prompt_idx', prompt_col]].toPandas()
prompts_idx = df['prompt_idx'].to_list()
prompts = df[prompt_col].to_list()
# 非同期タスクを実行し、結果を取得
loop = asyncio.get_event_loop()
prompt_responses = loop.run_until_complete(async_task(api_key, prompts, api_call_batch_size))
# APIレスポンスから内容を抽出
responses = [response['choices'][0]['message']['content'] for response in prompt_responses]
# 結果をリストに変換
results = list(zip(prompts_idx, responses))
results_DF = spark.createDataFrame(results, ["prompt_idx", response_col])
# インデックスを使用して元のDataFrameと結合
DF = DF.join(results_DF, on=['prompt_idx']).drop('prompt_idx')
return DF
今度は100行でやってみます。
# プロンプトを含むデータフレームを読み込む
sql_statement = "SELECT * FROM takaakiyayoi_catalog.vector_seach.qiita_partial"
responseDF = spark.sql(sql_statement)
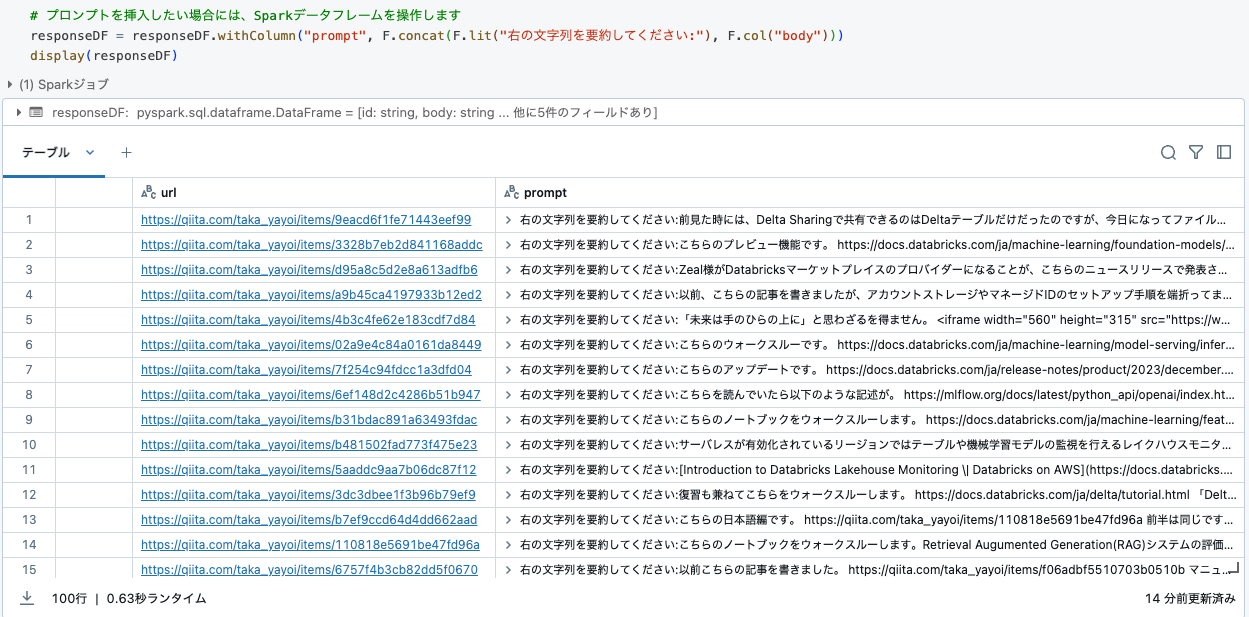
# プロンプトを挿入したい場合には、Sparkデータフレームを操作します
responseDF = responseDF.withColumn("prompt", F.concat(F.lit("右の文字列を要約してください:"), F.col("body")))
display(responseDF)
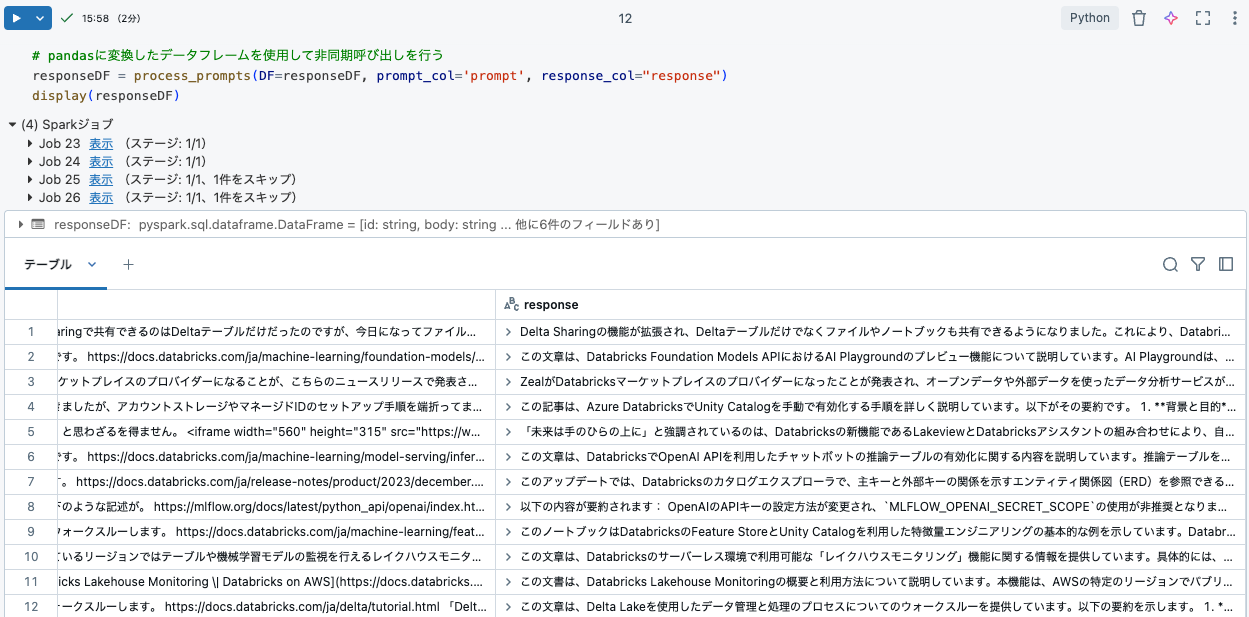
# pandasに変換したデータフレームを使用して非同期呼び出しを行う
responseDF = process_prompts(DF=responseDF, prompt_col='prompt', response_col="response")
display(responseDF)
100行が2分程度で完了しました。
LLMバッチ推論の実装としては有用だと思いました。元の記事ではこれ以外にもレート制限への対応やマルチスレッドの実装も紹介されていますので、そちらもご覧ください。