Simplifying Geospatial Data Analysis With Python Using Databricks - The Databricks Blogの翻訳です。
Databricks向けのオープンソースユーティリティプロジェクト
この記事は、以前IntelematicsにいたシニアエンジニアのStephanie Makによる寄稿です。
この記事では、私がIntelematicsにいたときにスタートしたBricklayerのオープンソースコミュニティに貢献した体験をお話しします。BricklayerはDatabricksのレイクハウスプラットフォームを用いて構築された、ジョブの実行、位置空間データを用いて地図レイヤーや他の構造化データを構築するデータエンジニア向けのユーティリティです。Bricklayerを用いることで、位置空間データの操作、可視化、そして、プログラムによるバッチジョブの並列化が容易になります。このオープンソースプロジェクトを通じて、位置空間情報データを取り扱っているチームは、共通的な関数のコーディングに費やす時間を削減でき、生産性を向上することができるようになりました。
背景
2001年にメルボルンで創業したIntelematicsは、インテリジェント交通の領域と、お客様に対するそのインパクトに対する深い洞察を得るために20年を費やしました。数年間を通じて、スマートセンサー、商用、個人用の自動車のプローブ、様々なIoTセンサーから集められるトラフィックインテリジェンスのデータポイントは約2兆となりました。この大量のデータから意味を導き出すために、INSIGHTトラッフィクインテリジェンスプラットフォームが構築され、これにより、全体的かつ信頼性の高いトラフィックデータと洞察を必要とするプロジェクトの計画、管理、評価のための、車両GPSのトラッキング、管理、アクセスが容易となりました。
Databricksを活用することで、INSIGHTトラフィックインテリジェンスプラットフォームは、120億の道路のトラフィックデータポイントを30秒で処理することができました。また、複雑な道路、交通問題を解決し、新たな機会を見出すために、オーストラリアにおける道路、移動ネットワークに関する詳細な全体像を提供しました。
当初、INSIGHTチームが、内部の生産性をモニタリングし、位置空間情報を分析、複数処理を行う際に体験したペインポイントのいくつかを解決するために、我々のオープンソースプロジェクトBricklayerをスタートしました。我々は、オンラインのデータ取得ツール(Databricks)とオフラインの位置空間情報可視化ツール(QGIS)の間の切り替えや、パイプラインにおける任意の並列度の処理のシンプル化のようなワークフローにおける非効率性を解決することができました。そして、我々はビッグデータ処理エコシステムの基盤を形作ることを支援するために、オープンソースコミュニティに参加することを決めました。
GISデータ変換
Databricksワークスペースにおける空間分析の必要性
空間分析や位置情報の取り扱いは、従来はローカルあるいはサーバーで動作するデスクトップアプリケーションであるQGISで行われており、これは複数のベクトルオーバーレイ、位置空間クエリーに対する即時のビジュアライズ、結果の位置情報処理をサポートしています。
我々のデータ変換パイプラインの開発は、Databricksワークスペースで行われました。分析、設計、実装、検証、そして、後段の処理によって進められるデータアセットの高速なイテレーションをサポートするためには、ローカル環境での開発は非効率的であり、我々の持つ大量データを取り扱うことは不可能でした。
Databricksノートブックで表示するマップレイヤーの構築
OpenStreetMapのようなマップタイルセット上にジオメトリーをレンダリングし、Databricksノートブック上に表示するために、folium mapsを使用することを決めました。
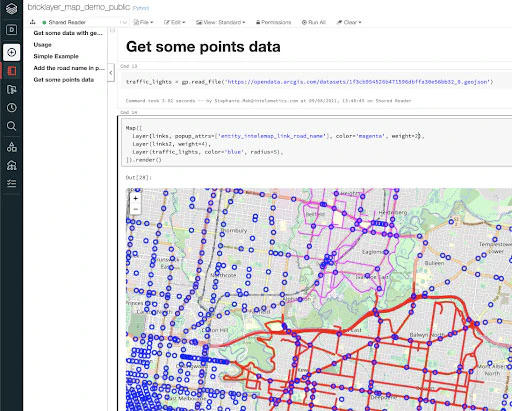
どのようなものかサンプルを見たいのであれば、公開されているマップのデモノートブックが使い方の参考になるかもしれません。
バッチ処理のスケーリング、並列化
並列バッチ処理の必要性
位置空間情報データの変換には、大量の計算リソースを必要となります。我々のデータ量(数十万の道路セグメントにおいて数年間にわたる、1日あたり96タイムスロット)では、Databricksにおける最大サイズのインスタンスであっても、メモリーに全てのデータをロードすることは不可能でした。「分割統治」のアプローチに基づき、時間の次元に基づいてデータを分割し、均等に分散されたバッチとして、並列で処理を行うことができます。このワークロードはPythonで実行されていたので、スレッドでの並列化は不可能であり、Apache Spark™の並列化処理を使うのは簡単ではありませんでした。
Jobs APIによるジョブの実行
Databricksでは、dbutils.notebook.runコマンドを用いて、ジョブを実行することができます。しかし、コマンド実行はブロックコールであるため、ジョブを同時に実行することはできません。Databricks REST API 2.0を活用することで、Bricklayerは並列化問題に対応するために、複数のジョブを同時に起動することができます。我々は、新規ジョブクラスターによる新規ジョブの作成、ジョブのステータス監視、バッチの停止などジョブを取り扱う際に共通するユースケースをラッピングしました。
複数のジョブを起動するには以下のようにします。
from bricklayer.api import DBSApi
for x in range(3):
job = DBSApi().create_job('./dummy_job')
特定のジョブを取得して停止するには以下のようにします。
from bricklayer.api import DBSApi
for job in DBSApi().list_jobs(job_name='dummy_job'):
print(job.job_id)
job.stop()
次のステップ
Databricksは、データサイエンス、データエジニアリング、ビジネスにおけるワークフローを一つのプラットフォームで統合することで、イノベーションを加速します。Bricklayerによって、エンジニアの営みをより簡単なものにするために、よりシームレスなインテグレーションを生み出すことがIntelematicsのミッションになりました。
我々は、エラーメッセージをより有用かつわかりやすいものにし、Avro、Swagger/OpenAPIで指定されるスキーマに基づいて複数のフォーマットのテーブルを自動生成する機能、スキーマに基づくカタログの検証などをサポートすることを計画しています。より詳細に関しては、ロードマップを参照ください。
Intelematicsについて
2001年にメルボルンで創業したIntelematicsは、インテリジェント交通の領域と、お客様に対するそのインパクトに対する深い洞察を得るために20年を費やしましています。我々は、増加し続けるデータと、接続性に対する要望は我々の生き方、向こう数十年の生活のあり方を変化させると信じています。我々は、技術のパワーとデータを結びつけ、よりスマートな意思決定とお客様の利益のためのイノベーションを生み出すために、お客様と協働しています。