背景
GoogleのNotebookLMのような、ドキュメントをアップロードして質問に答えてくれるRAGアプリケーションをDatabricks上で構築しました。
Databricksには以下のような機能が揃っており、RAGアプリケーションを構築するのに適しています:
- Databricks Apps: Streamlitアプリをマネージドでホスティング
- Unity Catalog Volumes: ファイルストレージ
- ai_parse_document: ドキュメントパース(OCR対応)
- Vector Search: ベクトル検索インデックス
- Model Serving: LLMエンドポイント
本記事では、これらを組み合わせてNotebookLM風アプリケーションを構築する方法と、実装上のハマりポイントを紹介します。
完成イメージ
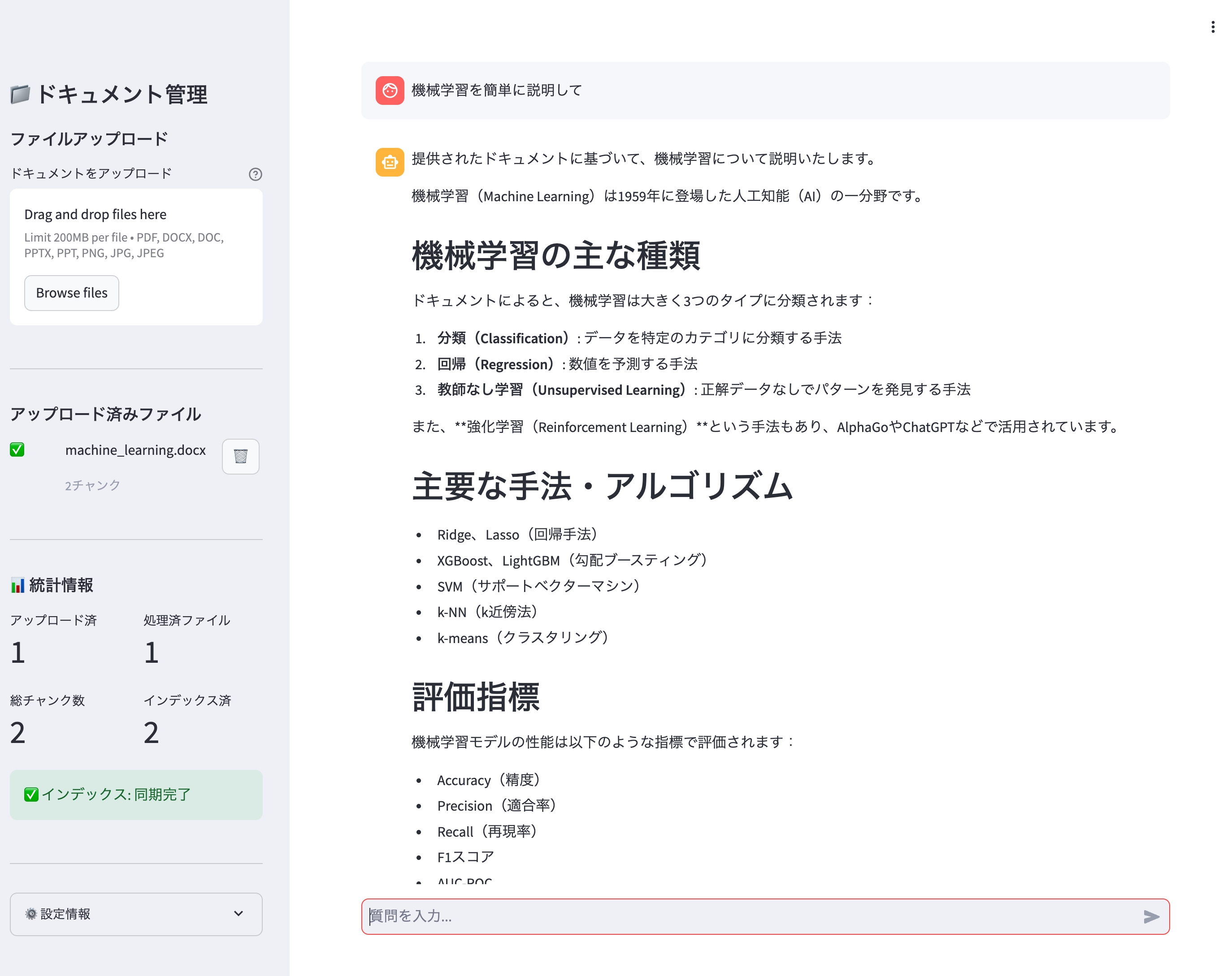
ソースコードなどはこちらに。
全体構成
┌─────────────────────────────────────────────────────────────────┐
│ Databricks Apps │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Streamlit アプリ (app.py) │ │
│ │ - ファイルアップロード/削除 │ │
│ │ - 統計情報表示 │ │
│ │ - Q&A チャット │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│ │ │
│ ファイル操作 │ ジョブ起動 │ 検索・LLM
▼ ▼ ▼
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ Unity Catalog │ │ Serverless Job │ │ Vector Search │
│ Volumes │ │ │ │ Index │
│ (documents) │ │ - ai_parse_doc │ │ │
└──────────────────┘ │ - chunking │ └──────────────────┘
│ - table insert │ │
│ - index sync │ │
└──────────────────┘ │
│ │
▼ │
┌──────────────────┐ │
│ Delta Table │ ◄─────────┘
│ (document_chunks)│ Delta Sync
└──────────────────┘
コンポーネント
| コンポーネント | 役割 |
|---|---|
| Databricks Apps | Streamlitアプリのホスティング、認証管理 |
| Unity Catalog Volumes | アップロードファイルの保存 |
| Serverless Job | ドキュメント処理(パース、チャンキング、インデックス同期) |
| Delta Table | チャンクデータの保存 |
| Vector Search Index | Delta Sync Indexによるベクトル検索 |
| Model Serving | Claude Sonnet 4による回答生成 |
| SQL Warehouse | 統計情報取得のためのSQLクエリ実行 |
処理フロー
- ユーザーがアプリからファイルをアップロード
- ファイルがUnity Catalog Volumeに保存される
- アプリがサーバレスジョブを起動
- ジョブが以下を実行:
-
ai_parse_documentでドキュメントをパース - テキストをチャンクに分割
- Delta Tableに挿入
- Vector Search Indexを同期
-
- ユーザーが質問を入力
- Vector Searchで関連チャンクを検索
- LLMが検索結果を基に回答を生成
リソース設定
事前準備:Unity Catalogリソースの作成
アプリで使用するUnity Catalogリソースを事前に作成します。
-- ボリューム(ファイル保存用)
CREATE VOLUME IF NOT EXISTS catalog.schema.documents;
-- テーブル(チャンクデータ保存用)
CREATE TABLE IF NOT EXISTS catalog.schema.document_chunks (
chunk_id STRING NOT NULL COMMENT 'チャンク識別子',
document_id STRING NOT NULL COMMENT 'ドキュメントID',
file_name STRING NOT NULL COMMENT 'ファイル名',
chunk_index INT NOT NULL COMMENT 'チャンク番号',
content STRING NOT NULL COMMENT 'チャンクテキスト',
page_number INT COMMENT 'ページ番号',
element_type STRING COMMENT '要素タイプ',
created_at TIMESTAMP COMMENT '作成日時',
CONSTRAINT pk_document_chunks PRIMARY KEY (chunk_id)
);
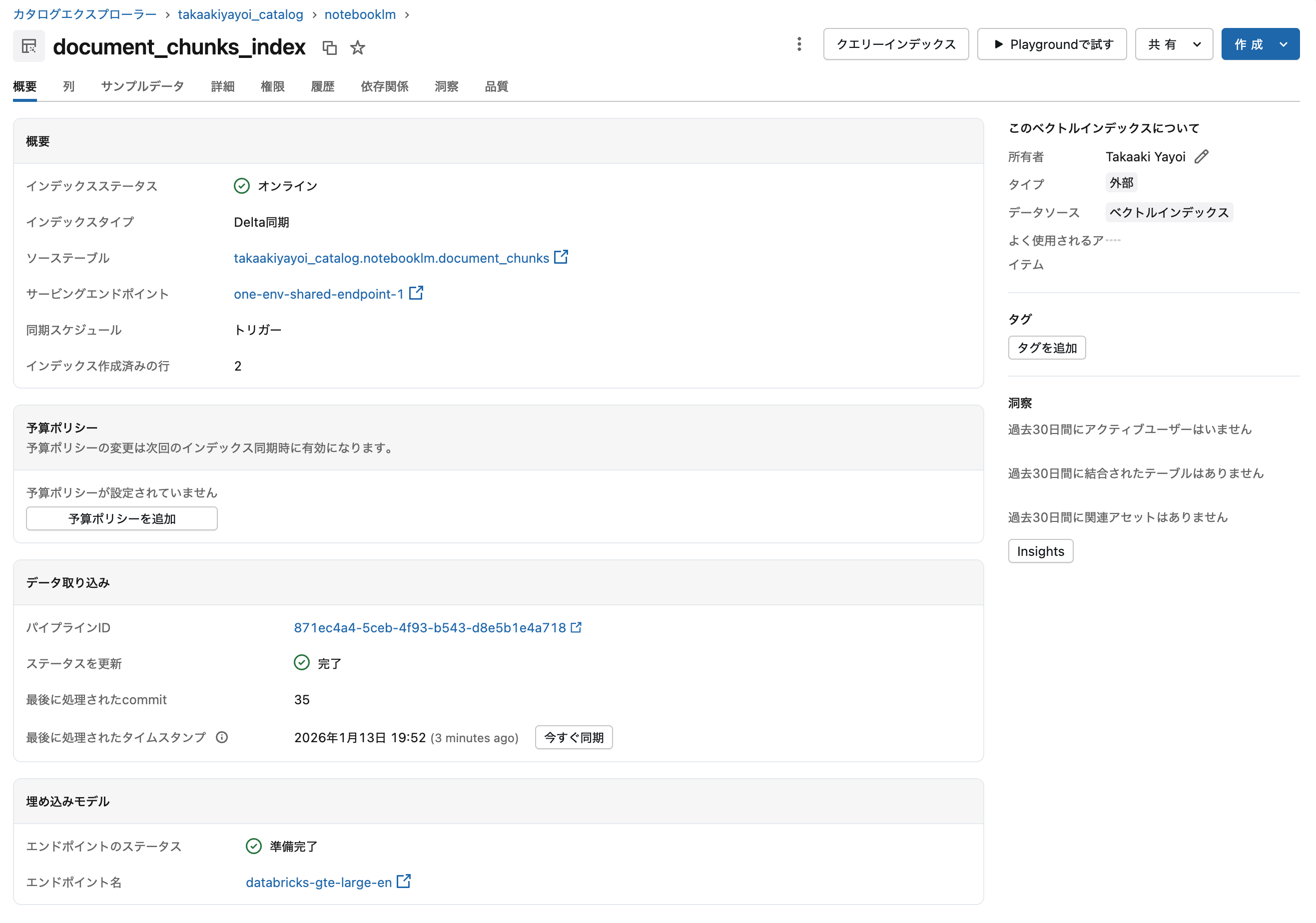
Vector Search Indexの作成
Delta Sync Indexを作成します。TRIGGEREDモードでは手動で同期が必要ですが、コスト効率が良いです。
databricks vector-search-indexes create-index --json '{
"name": "catalog.schema.document_chunks_index",
"endpoint_name": "your-vs-endpoint",
"primary_key": "chunk_id",
"index_type": "DELTA_SYNC",
"delta_sync_index_spec": {
"source_table": "catalog.schema.document_chunks",
"pipeline_type": "TRIGGERED",
"embedding_source_columns": [
{
"name": "content",
"embedding_model_endpoint_name": "databricks-gte-large-en"
}
]
}
}'
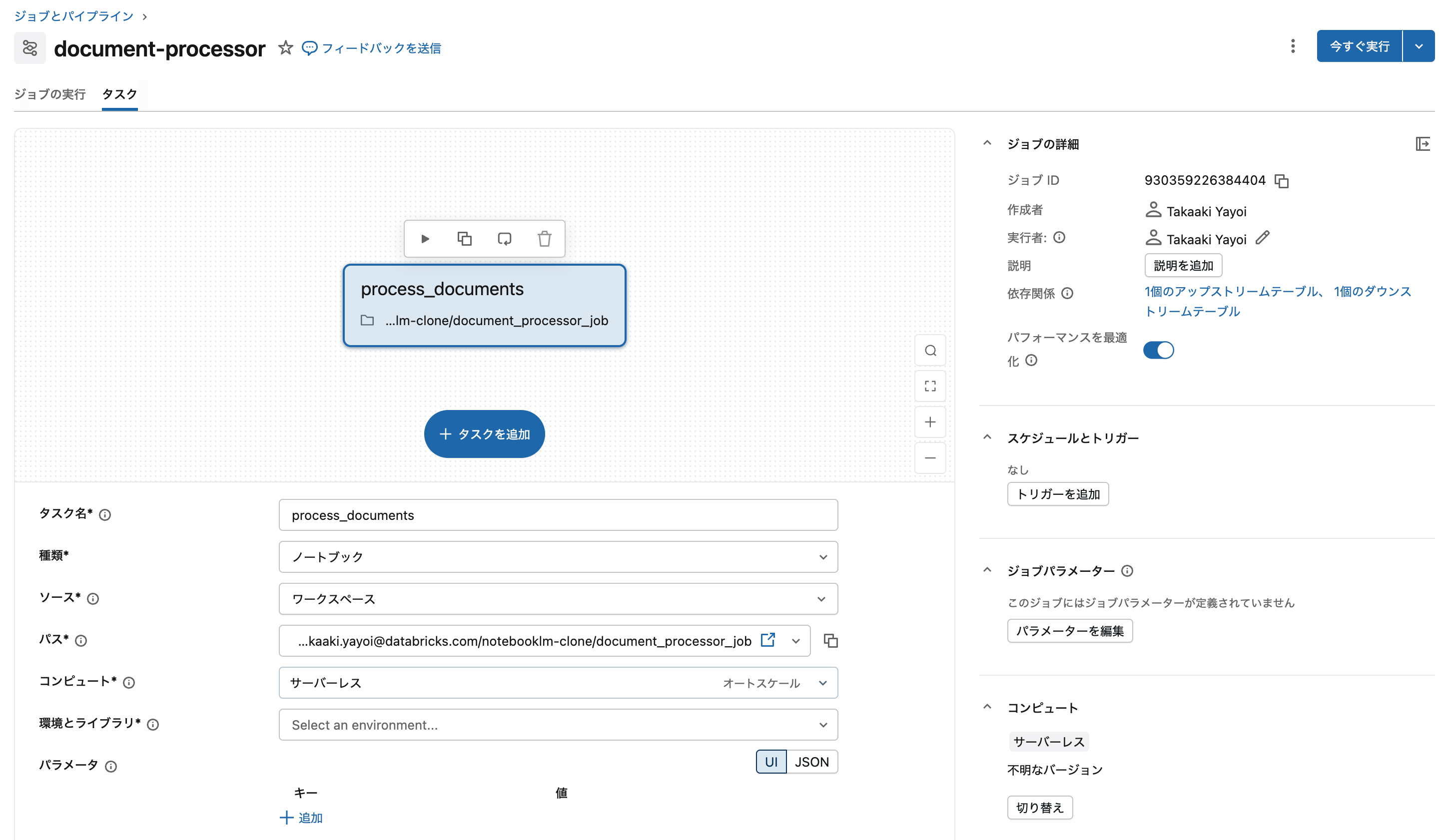
ドキュメント処理ジョブの作成
サーバレスジョブを作成します。
databricks jobs create --json '{
"name": "document-processor",
"tasks": [
{
"task_key": "process_documents",
"notebook_task": {
"notebook_path": "/Workspace/Users/user@example.com/app/document_processor_job",
"source": "WORKSPACE"
}
}
]
}'
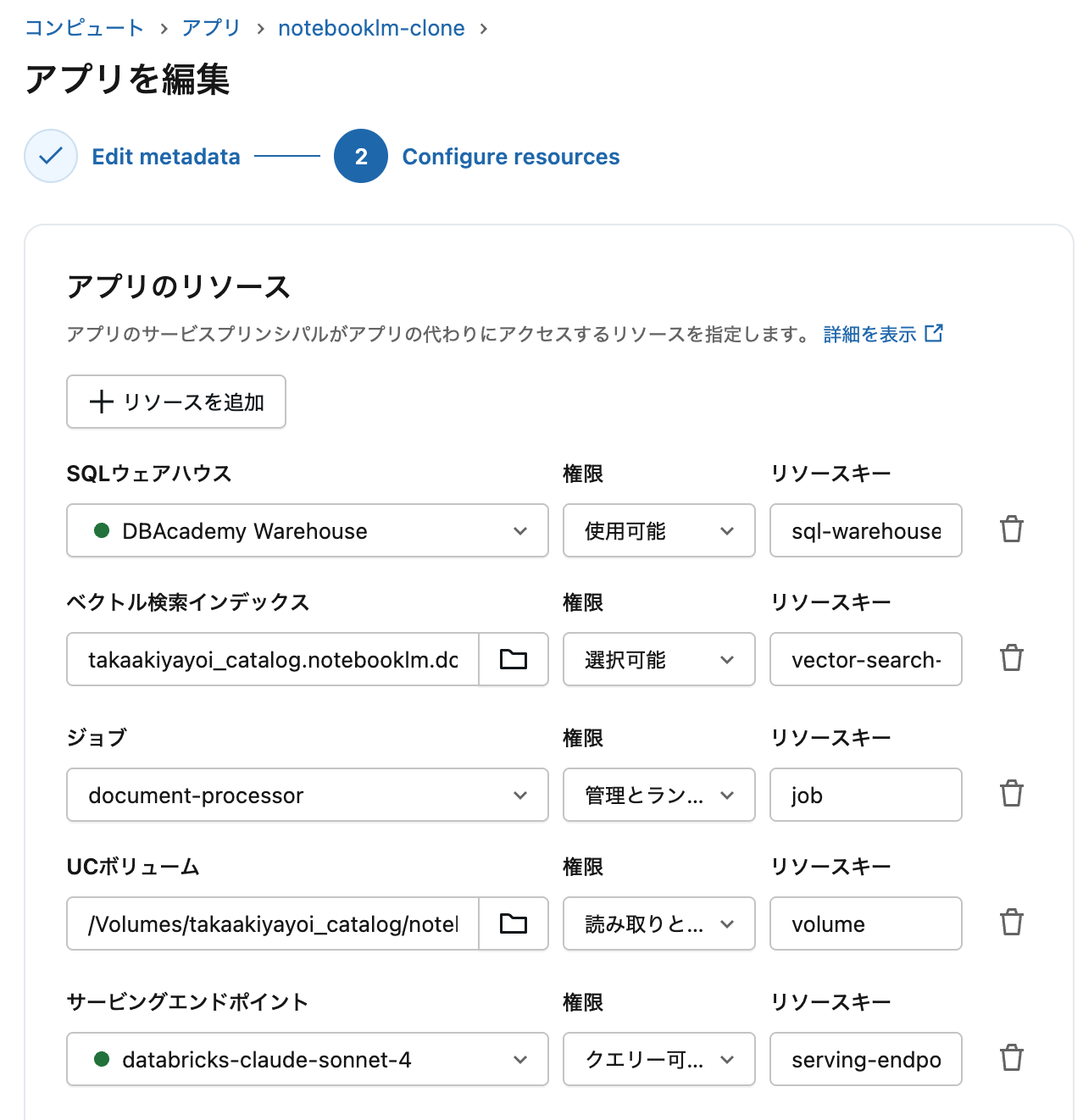
Databricks Appsのリソース設定
Databricks Apps UIからリソースを追加します。app.yamlの定義だけでは権限は付与されません。
- Databricks Apps UIを開く
- アプリの「リソース」タブを選択
- 「リソースの追加」をクリック
- 各リソースを追加
追加するリソース一覧
| リソースタイプ | リソース名 | 権限 |
|---|---|---|
| Unity Catalog Volume | catalog.schema.documents |
読み取りと書き込み |
| SQL Warehouse | warehouse_id |
使用可能 |
| Vector Search Index | catalog.schema.document_chunks_index |
選択可能 |
| Serving Endpoint | databricks-claude-sonnet-4 |
クエリ可能 |
| Lakeflow Job | document-processor |
実行を管理可能 |
注意: Vector Search Indexは「選択可能」(クエリのみ)しか選択できません。インデックス同期はジョブで行います。
また、テーブルcatalog.schema.document_chunksに対して、アプリのサービスプリンシパルのSELECT権限を付与します。
ジョブへの権限付与
アプリのサービスプリンシパルにジョブの実行権限を付与します。
# アプリのサービスプリンシパルIDを確認
databricks apps get app-name | jq '.service_principal_client_id'
# ジョブに権限を付与
databricks api patch /api/2.0/permissions/jobs/JOB_ID --json '{
"access_control_list": [
{
"service_principal_name": "SERVICE_PRINCIPAL_ID",
"permission_level": "CAN_MANAGE_RUN"
}
]
}'
権限設定の詳細
アプリのサービスプリンシパル
Databricks Appsは専用のサービスプリンシパルで実行されます。このサービスプリンシパルに必要な権限を付与する必要があります。
# サービスプリンシパル情報の確認
databricks apps get app-name
出力例:
{
"service_principal_client_id": "48b6f77d-xxxx-xxxx-xxxx-xxxxxxxxxxxx",
"service_principal_id": 70660267727427,
"service_principal_name": "app-xxxxx app-name"
}
Unity Catalog権限
UIで設定できない場合や、より詳細な制御が必要な場合はGRANT文で直接付与します。
-- サービスプリンシパルIDを使用
GRANT READ_VOLUME, WRITE_VOLUME
ON VOLUME catalog.schema.documents
TO `48b6f77d-xxxx-xxxx-xxxx-xxxxxxxxxxxx`;
GRANT SELECT
ON TABLE catalog.schema.document_chunks
TO `48b6f77d-xxxx-xxxx-xxxx-xxxxxxxxxxxx`;
権限の確認
設定した権限を確認します。
-- ボリュームの権限確認
SHOW GRANTS ON VOLUME takaakiyayoi_catalog.notebooklm.documents;
| Principal | ActionType | ObjectType | ObjectKey |
|---|---|---|---|
| 48b6f77d-6579-4aff-b023-36a45caead6d | READ VOLUME | VOLUME | takaakiyayoi_catalog.notebooklm.documents |
| 48b6f77d-6579-4aff-b023-36a45caead6d | WRITE VOLUME | VOLUME | takaakiyayoi_catalog.notebooklm.documents |
-- テーブルの権限確認
SHOW GRANTS ON TABLE takaakiyayoi_catalog.notebooklm.document_chunks;
| Principal | ActionType | ObjectType | ObjectKey |
|---|---|---|---|
| 48b6f77d-6579-4aff-b023-36a45caead6d | SELECT | TABLE | takaakiyayoi_catalog.notebooklm.document_chunks |
Databricks Appsのベストプラクティス
本アプリケーションはDatabricks Appsのベストプラクティスに沿って設計しています。
アプリ設計:処理のオフロード
App コンピュートは UI レンダリング用に最適化されています
Databricks Appsのコンピュートはフロントエンド処理に最適化されているため、重い処理は専用サービスにオフロードすることが推奨されています。
| 処理タイプ | オフロード先 |
|---|---|
| 複雑なデータ処理 | Databricks SQL |
| バッチ処理 | Lakeflow Jobs(サーバレスジョブ) |
| AI推論 | Model Serving |
本アプリケーションでは:
- ドキュメント処理(パース、チャンキング、インデックス同期)→ サーバレスジョブ
- ベクトル検索 → Vector Search
- 回答生成 → Model Serving(Claude Sonnet 4)
アプリ自体は軽量なUI操作とジョブ起動のみを担当しています。
起動時間の短縮
初期化ロジックは軽量に保ち、スタートアップ中に大きな依存関係やAPI呼び出しをブロックしないことが重要です。
# 重いリソースは必要な時点でロード
@st.cache_resource
def get_workspace_client():
"""WorkspaceClientのシングルトン取得"""
return WorkspaceClient()
キャッシング戦略
頻繁に使用されるデータをキャッシュして、レイテンシを減らし冗長な処理を回避します。
# Streamlitのキャッシュデコレータを活用
@st.cache_resource
def get_workspace_client():
return WorkspaceClient()
# または functools.lru_cache
from functools import lru_cache
@lru_cache(maxsize=100)
def get_cached_data(key):
# 重い処理
pass
非同期パターンの採用
タイムアウトしやすい同期リクエストを避け、ジョブを起動して状態を定期的に確認する非同期パターンを採用しています。
def run_processor_job(w: WorkspaceClient) -> bool:
"""ジョブを起動(非同期)"""
try:
run = w.jobs.run_now(job_id=int(PROCESSOR_JOB_ID))
st.info(f"処理ジョブを開始しました (Run ID: {run.run_id})")
return True
except Exception as e:
st.warning(f"ジョブ起動エラー: {e}")
return False
ジョブの完了を待たずに即座にレスポンスを返し、ユーザーは統計情報で処理状態を確認できます。
セキュリティ:最小特権の原則
各リソースに必要最小限の権限のみを付与しています。
| リソース | 権限 | 理由 |
|---|---|---|
| Volume | READ_VOLUME, WRITE_VOLUME | ファイルアップロード/削除 |
| Table | SELECT | 統計情報の読み取りのみ |
| Serving Endpoint | CAN_QUERY | 推論リクエストのみ |
| SQL Warehouse | CAN_USE | クエリ実行のみ |
| Job | CAN_MANAGE_RUN | 実行のみ(設定変更不可) |
CAN_MANAGE(フルコントロール)は使用せず、必要な操作に限定した権限を付与しています。
依存関係の固定
requirements.txtで正確なバージョン番号を使用し、ビルド間で環境の一貫性を確保します。
databricks-sdk>=0.30.0
databricks-sql-connector>=3.0.0
streamlit>=1.35.0
pandas>=2.0.0
tenacity>=8.0.0
requests>=2.31.0
ログ出力
stdout/stderrにログを記録することで、Databricks UIでログを確認できます。
# ジョブ内でのログ出力
print(f"処理中: {file_name}")
print(f" パース結果: {len(content)} 文字")
print(f" チャンク数: {len(chunks)}")
ローカルファイルへのログ出力は避け、標準出力を使用します。
実装上の注意点
1. Databricks Appsのコードデプロイ
問題: databricks apps deployを実行してもコードが反映されない
原因: databricks apps deployはワークスペース上のコードをデプロイするだけで、ローカルファイルを同期しない
解決策: デプロイ前にdatabricks syncでローカルファイルを同期する
# ローカルファイルをワークスペースに同期
databricks sync /path/to/local /Workspace/Users/user@example.com/app
# アプリをデプロイ
databricks apps deploy app-name --source-code-path /Workspace/Users/user@example.com/app
2. Databricks Appsの認証
問題: アプリからREST APIを呼び出す際に401エラーが発生
原因: 環境変数からトークンを取得しようとしても、Databricks Appsでは利用できない
解決策: WorkspaceClientのauthenticate()メソッドを使用する
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# 認証ヘッダーを取得
auth_headers = w.config.authenticate()
# REST API呼び出し
headers = {"Content-Type": "application/json"}
headers.update(auth_headers)
response = requests.post(url, headers=headers, json=payload)
3. Databricks Appsのリソース権限
問題: app.yamlにリソースを定義しても権限が付与されない
原因: app.yamlのリソース定義は参照用であり、実際の権限付与はUIまたはAPIで行う必要がある
解決策:
- Databricks Apps UIの「リソース」タブからリソースを追加
- または、Unity Catalog権限をGRANT文で直接付与
-- ボリューム権限
GRANT READ_VOLUME, WRITE_VOLUME ON VOLUME catalog.schema.volume TO `service-principal-id`;
-- テーブル権限
GRANT SELECT ON TABLE catalog.schema.table TO `service-principal-id`;
4. Vector Search Indexの権限制限
問題: アプリからsync_index()を呼び出すと権限エラー
原因: Databricks AppsではVector Search Indexに対して「クエリ可能」権限しか付与できない(「管理可能」は不可)
解決策: インデックス同期はジョブで実行し、ジョブはユーザー権限で実行される
# ジョブ内で実行(ユーザー権限)
w.vector_search_indexes.sync_index(index_name=VS_INDEX_NAME)
5. ai_parse_documentの制限
問題: 日本語PDFやスキャンPDFでテキストが正しく抽出されない
原因: ai_parse_documentは非ラテン文字のOCRに最適化されていない
"may not perform optimally when handling images using text of non-Latin alphabets"
対策:
- テキストベースのPDF(テキスト選択可能)を使用する
- 英語ドキュメントを優先する
- 日本語の場合は事前にOCR処理済みのPDFを使用する
6. ファイル到着トリガーの制限
問題: 同名ファイルの上書きが検知されない
原因: ファイル到着トリガーは新規ファイルのみを検知し、既存ファイルの上書きは検知しない
解決策: ファイル到着トリガーを使わず、アプリからオンデマンドでジョブを起動する
def run_processor_job(w: WorkspaceClient) -> bool:
"""ドキュメント処理ジョブを実行"""
try:
run = w.jobs.run_now(job_id=int(PROCESSOR_JOB_ID))
return True
except Exception as e:
st.warning(f"ジョブ起動エラー: {e}")
return False
# アップロード後にジョブを起動
if upload_file(w, uploaded_file):
run_processor_job(w)
ファイル構成
databricks-notebooklm/
├── app.py # Streamlitアプリ
├── app.yaml # Databricks Apps設定
├── document_processor_job.py # ドキュメント処理ジョブ(ノートブック形式)
├── requirements.txt # 依存パッケージ
└── setup.sql # Unity Catalogリソース作成SQL
デプロイ手順
1. ローカルファイルの同期
# --watchオプションで継続的に同期(開発時に便利)
databricks sync --watch /path/to/local /Workspace/Users/user@example.com/app
2. アプリのデプロイ
databricks apps deploy app-name --source-code-path /Workspace/Users/user@example.com/app
3. 動作確認
デプロイ後、アプリのURLにアクセスして動作を確認します。
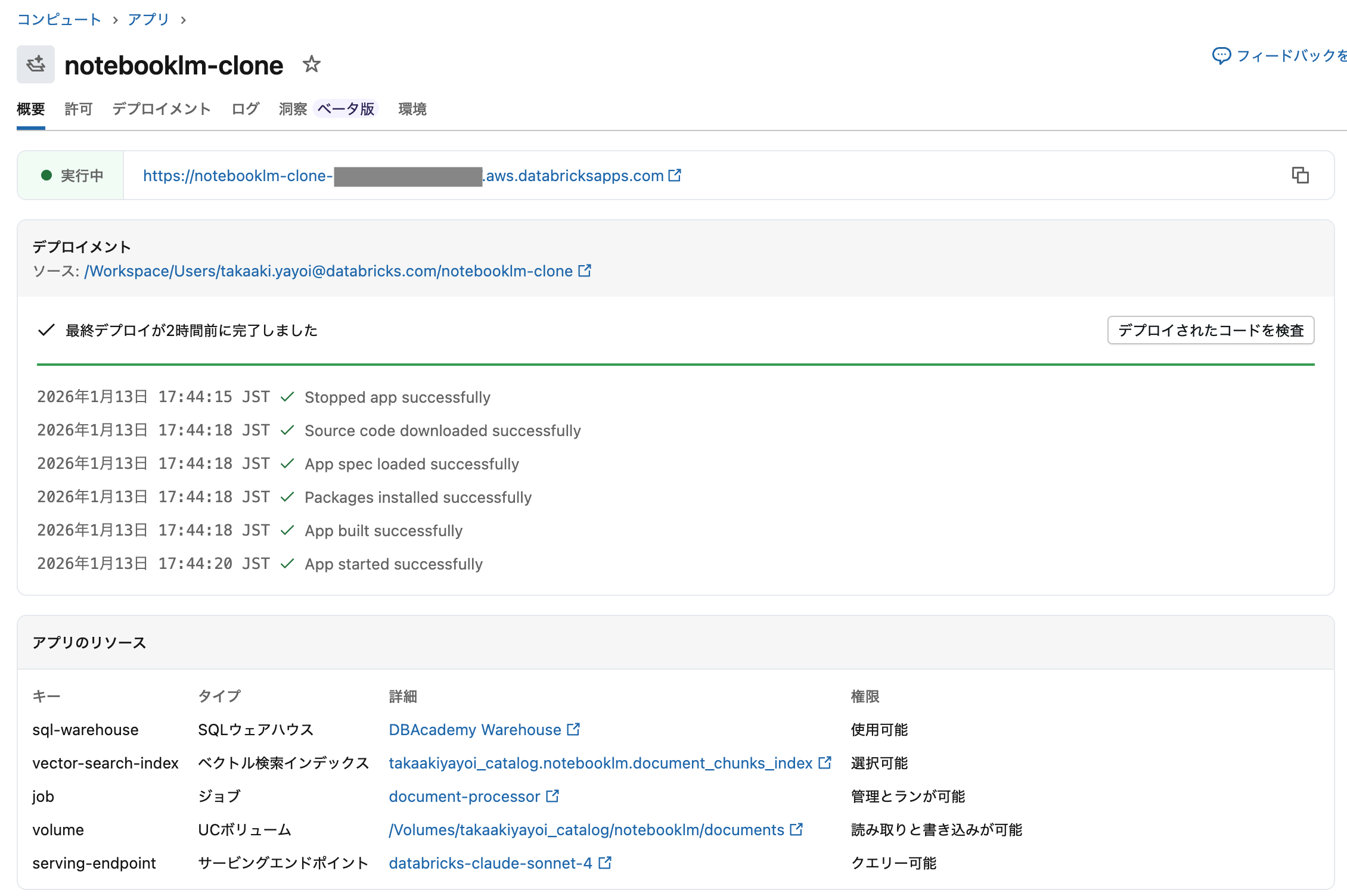
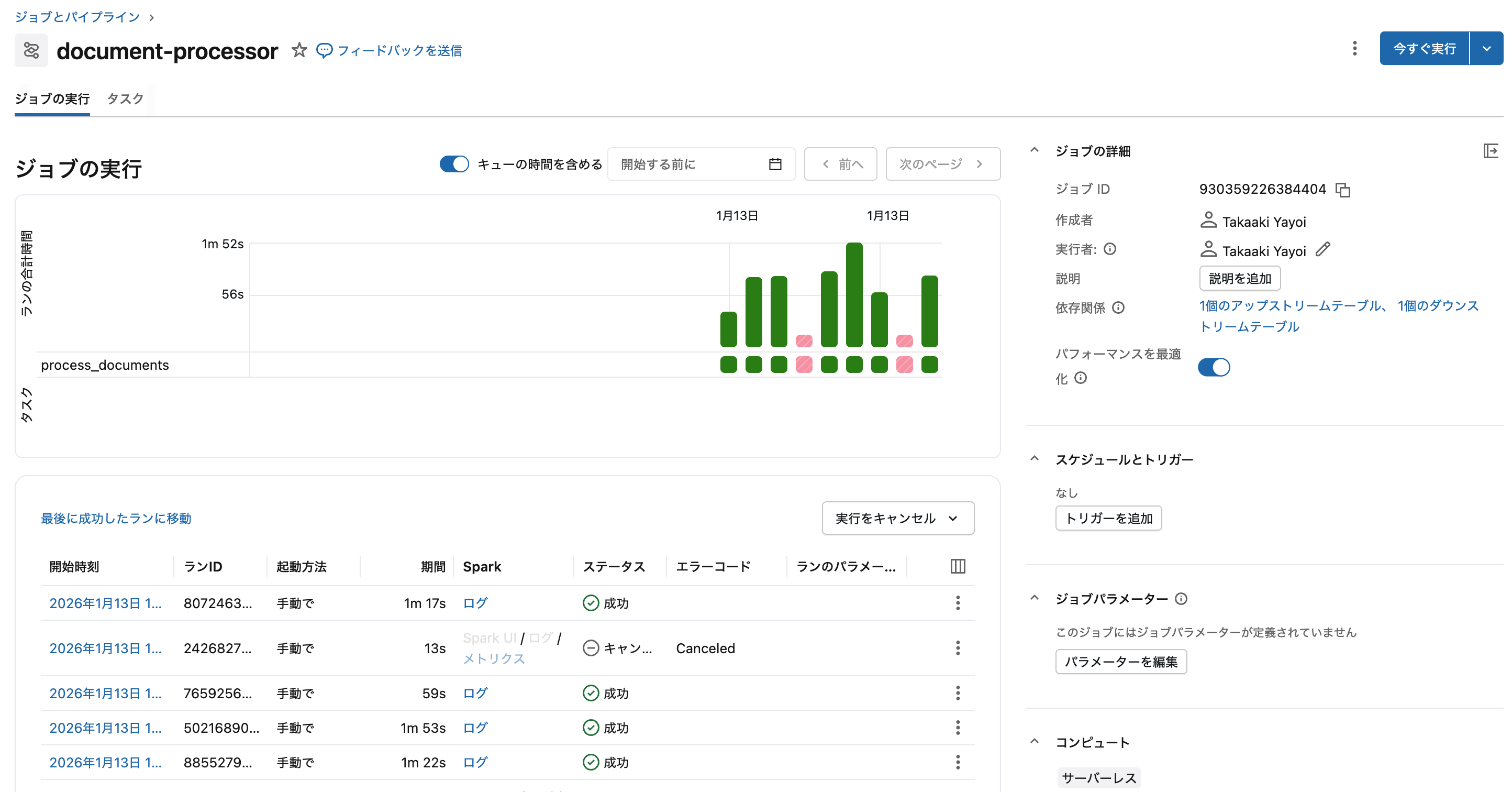
4. ジョブの動作確認
ファイルをアップロードしてジョブが正常に実行されることを確認します。
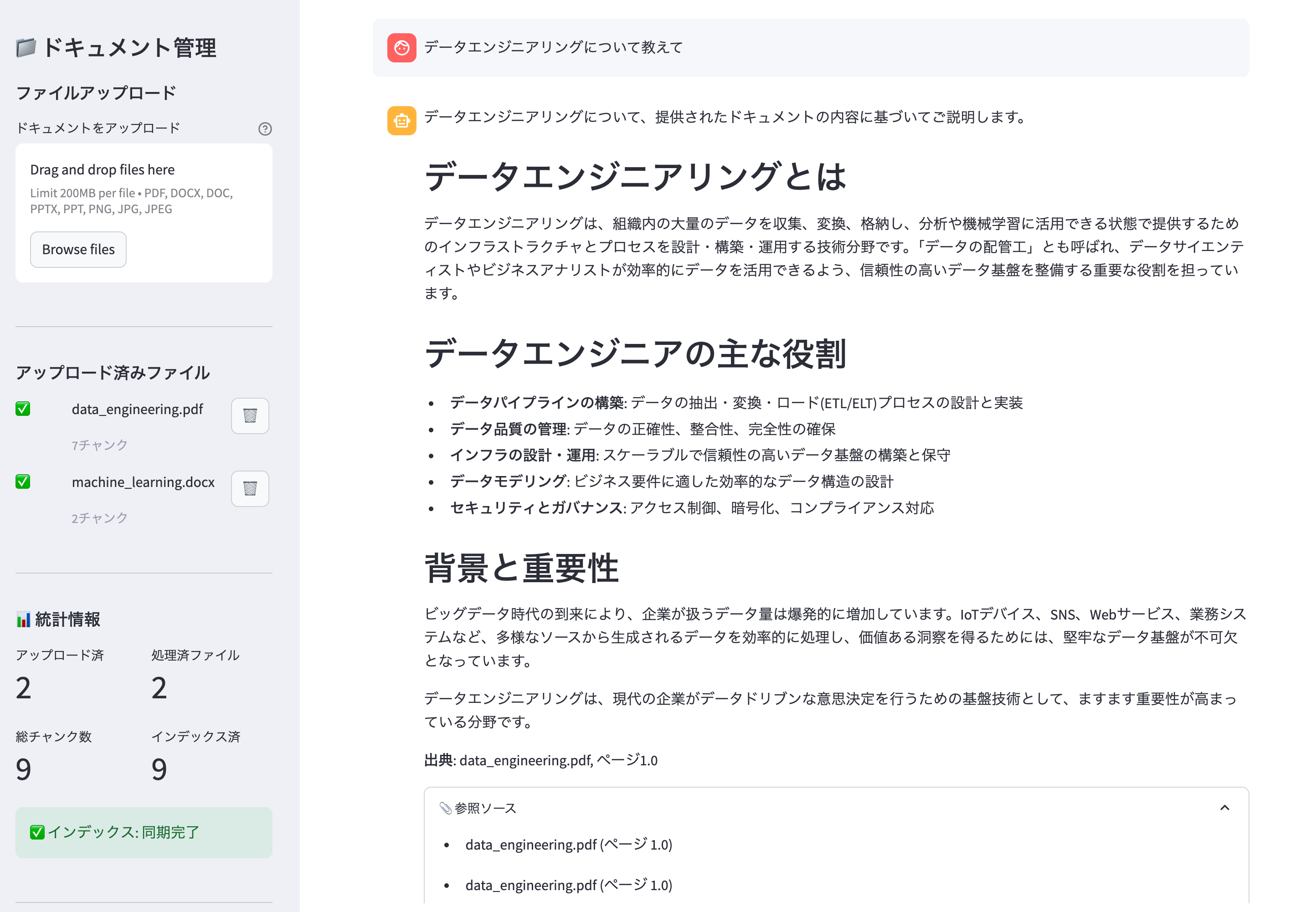
5. Q&A機能の確認
ドキュメントに関する質問をして、RAGが正常に動作することを確認します。
app.yamlの設定例
name: notebooklm-clone
description: ドキュメントベースのRAG Q&Aアプリケーション
resources:
- name: documents_volume
type: volume
volume: catalog.schema.documents
grants:
- permission: READ_VOLUME
- permission: WRITE_VOLUME
- name: document_chunks_table
type: table
table: catalog.schema.document_chunks
grants:
- permission: SELECT
- name: serving_endpoint
type: serving_endpoint
serving_endpoint: databricks-claude-sonnet-4
grants:
- permission: CAN_QUERY
- name: sql_warehouse
type: sql_warehouse
sql_warehouse: warehouse_id
grants:
- permission: CAN_USE
- name: vector_search_index
type: vector_search_index
vector_search_index: catalog.schema.document_chunks_index
grants:
- permission: CAN_QUERY_AND_MANAGE
- name: document_processor_job
type: job
job: "job_id"
grants:
- permission: CAN_MANAGE_RUN
env:
- name: CATALOG
value: catalog
- name: SCHEMA
value: schema
# ... その他の環境変数
command:
- streamlit
- run
- app.py
まとめ
Databricks Appsを使ってNotebookLM風のRAGアプリケーションを構築しました。
ベストプラクティスの適用
| ベストプラクティス | 本アプリでの適用 |
|---|---|
| 処理のオフロード | パース・チャンキング・インデックス同期をサーバレスジョブに分離 |
| 起動時間の短縮 |
@st.cache_resourceで重いリソースを遅延ロード |
| 非同期パターン | ジョブを起動して即座にレスポンス、統計情報で状態確認 |
| 最小特権の原則 | 各リソースに必要最小限の権限のみ付与 |
| 依存関係の固定 |
requirements.txtでバージョン指定 |
主な学び
- アーキテクチャ: Databricks AppsはUIレンダリング用に最適化されているため、重い処理は専用サービス(Jobs、SQL、Model Serving)にオフロードする
-
認証:
WorkspaceClient.config.authenticate()を使用してSDK経由で認証ヘッダーを取得 - 権限: app.yamlの定義だけでは不十分、UIまたはAPIで明示的に付与が必要
-
デプロイ:
databricks syncでローカルファイルを同期してからデプロイ - 制限の理解: Vector Search Indexの権限制限、ai_parse_documentのOCR制限など、サービスの制限を理解して設計に反映
今後の改善点
- チャンク統計のキャッシュによるSQL Warehouse依存の削減
- 処理状態のリアルタイム表示(ジョブ実行状況のポーリング)
- 日本語ドキュメント対応の強化
Databricksのマネージドサービスを活用することで、インフラ管理なしでエンタープライズ向けRAGアプリケーションを構築できます。