Taking Apache Spark’s Structured Streaming to Production - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
注意
2017年の記事です。
これは、Apache Sparkを用いた複雑なストリーミング分析をどのように実行するのかに関するシリーズの5番目の記事です。
Databricksにおいては、過去数ヶ月を通じてプロダクションパイプラインを構造化ストリーミングに移行してきており、お客さまがDatabricks上でプロダクションパイプラインを迅速に構築できるように、すぐに利用できるデプロイメントモデルをy交遊したいと考えています。
プロダクションのアプリケーションでは、モニタリング、アラート、障害復旧に対する自動化(クラウドネイティブ)アプローチが必要となります。本書では、これらの課題に取り組むために利用できるAPIをウォークスルーするだけではなく、Databricksがどのようにプロダクションにおける構造化ストリーミングの実行をシンプルにしているのかを説明します。
メトリクスとモニタリング
Apache Sparkにおける構造化ストリーミングでは、現在実行中のストリームに関する情報を取得するためにシンプルなプログラムのAPIを提供しています。実行中のクエリーに関する適切な情報を取得するために、現在アクティブなストリームに対して実行できる2つの主要なコマンドが存在します。現在のステータスを得るためのコマンドと、クエリーの最新の進捗を得るためのコマンドです。
ステータス
おそらく最初の質問は「私のストリームは今どのような処理を実行しているのか?」でしょう。ステータスは、ストリームの現在の状態に関する情報を維持し、クエリーを開始した際に返却されるオブジェクトを通じてアクセスすることができます。例えば、以下のクエリーによって定義されるIOTデバイスのカウントを提供するシンプルなカウントストリームがあるとします。
query = streamingCountsDF \
.writeStream \
.format("memory") \
.queryName("counts") \
.outputMode("complete") \
.start()
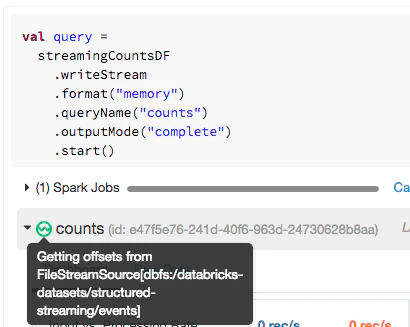
query.statusを実行することで、ストリームの現在の状態を取得することができます。これによって、ストリームで現在何が起きているのかに関して詳細な情報を取得することができます。
{
"message" : "Getting offsets from FileStreamSource[dbfs:/databricks-datasets/structured-streaming/events]",
"isDataAvailable" : true,
"isTriggerActive" : true
}
Databricksノートブックでは、いかなるストリーミングクエリーのステータスを参照するシンプルな方法を提供しています。シンプルにストリーミングクエリーの![]() アイコンの上にマウスカーソルを持っていきます。同じ情報を取得できるので、ストリームの状態をクイックに確認することが簡単にできます。
アイコンの上にマウスカーソルを持っていきます。同じ情報を取得できるので、ストリームの状態をクイックに確認することが簡単にできます。
最新の進捗
クエリーのステータスは間違いなく重要ですが、クエリーのこれまでの進捗を参照できることも同様に重要です。進捗のメタデータを用いることで、「どのくらいのスピードでタプルを処理しているのか?」や「ソースからどのくらいのスピードでタプルが到着しているのか?」といった疑問に答えることができるようになります。
stream.recentProgressを実行することで、処理速度やバッチ期間のような時間ベースの情報にアクセスできるようになります。しかし、千のJSONよりも一つの絵ですので、Databricksにおいては、ストリームの最新の進捗のクイックな分析を可能にするためにビジュアライゼーションを作成します。
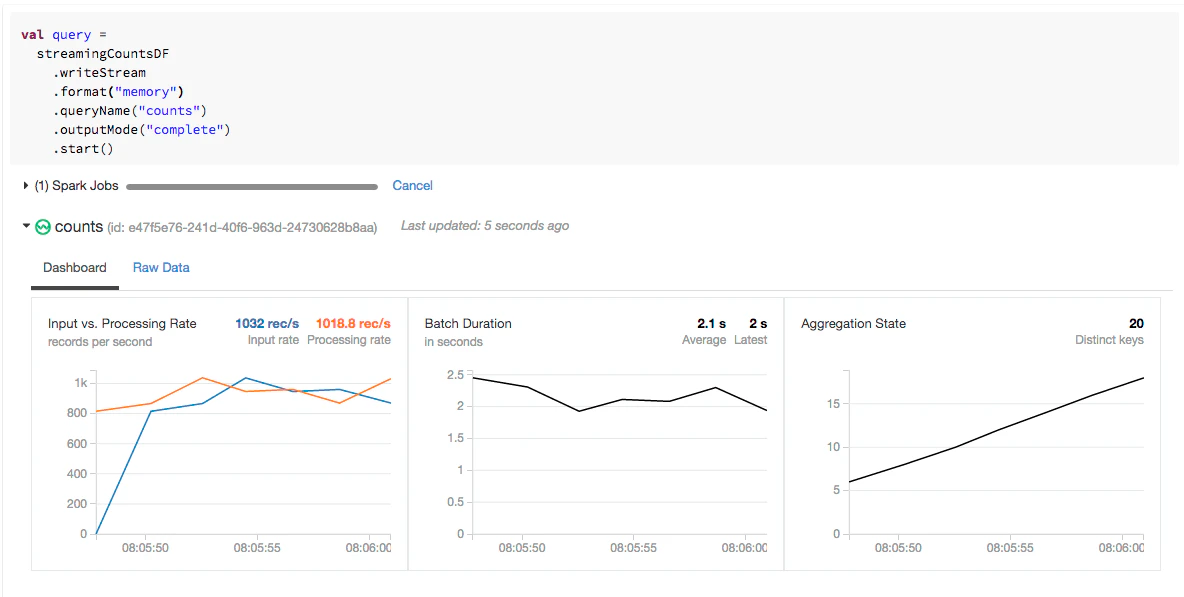
なぜこれらのメトリクスを選択したのか、なぜこれらを理解することが重要なのかを探索していきましょう。
入力レートと処理レート
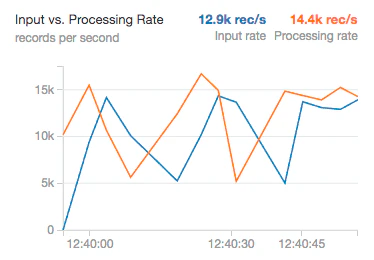
入力レートは、KafkaやKinesisのようなシステムから、構造化ストリーミングにどれだけのデータが流れ込んでいるのかを示します。処理レートはそのデータをどれだけクイックに分析できるのかを示します。理想的なケースにおいては、これらは共に一貫性を持って変化すべきです。しかし、これは処理がスタートした際にどれだけの入力データが存在するのかに応じて変化するでしょう。処理レートをはるかに上回る勢いで入力データが存在すると、ストリームは遅延することになり、より大きな負荷を取り扱えるようにクラスターのサイズをスケールアップしなくてはならないかもしれません。
バッチ期間
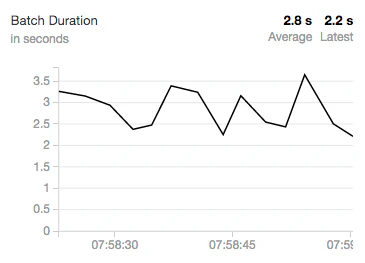
説得性のあるスループットでオペレーションを行うために、ほぼすべてのストリーミングシステムではバッチ化を活用しています(一部では、低いスループットと引き換えに高いレーテンシーのオプションを提供しています)。構造化ストリーミングは両方を達成します。データに対してオペレーションを行う際、構造化ストリーミングは時間経過と共に変動する数のイベントを処理するので、この振動を目撃することになるでしょう。コミュニティエディションのシングルコアのクラスターにおいて、バッチ期間が3秒周辺で定常的に振動している様子を観測しました。より大規模なクラスターでは通常より高速な処理レートとより短いバッチ期間を持つことになります。
ストリーミングジョブにおけるプロダクションのアラート
メトリクスやモニタリングは良いものではありますが、一日中ストリーミングジョブのお守りをすることなしに、発生するいかなる問題にクイックに対応できるようにするためには、堅牢なアラートの仕組みを必要とすることでしょう。Databricksでは、プロダクションパイプラインとして構造化ストリーミングを実行できるようにすることで、アラートを容易なものにしています。
例えば、以下の設定でDatabricksジョブを定義してみましょう。
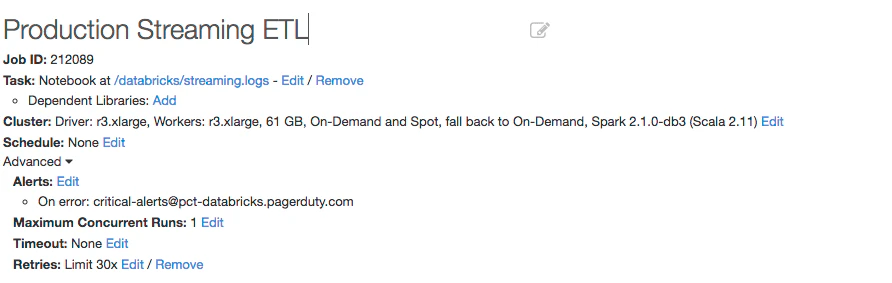
PagerDutyのアラートを起動するためのメールアドレスを指定していることに注意してください。これはジョブが失敗した際に、プロダクトのアラート(あるいは指定したレベルのアラート)を起動します。
自動化障害復旧
アラートは便利ですが、ベストなケースでも人間が障害に対応しなくてはなりませんし、最悪の場合、対応自体が不可能です。構造化ストリーミングを真にプロダクションに移行するためには、データの一貫性を保持し、データの損失がない状態で、可能な限りクイックに障害から自動で復旧できるようにしたいと考えるでしょう。Databricksではこれをシームレスに行います。復旧不可能な障害の前のリトライ回数をシンプルに設定すると、Databricksはあなたのために自動でストリーミングジョブを復旧しようとします。失敗ごとに、プロダクションの障害として通知を起動することもできます。
両方の世界の最良のものを手に入れることができます。システムは自己復旧を試みつつも、ステータスを従業員、開発者に連絡し続けます。
アプリケーションをアップデートする
お使いのストリーミングアプリケーションをアップデートしなくてはならない十分な理由が生じる2つの状況があります。(出力スキーマなど)重要なビジネスロジックを変更しない多くのケースでは、同じチェックポイントディレクトリを指定してストリーミングジョブをシンプルに再起動することができます。アップデートされた新たなストリーミングアプリケーションは前回の地点から再開し、稼働を続けます。
しかし、ステートフルなオペレーション(集計や出力スキーマ)を変更する場合、より多くの更新作業が必要となります。新規のチェックポイントディレクトリを指定して完全に新しいストリームを起動しなくてはなりません。幸運なことに、Databricksにおいては、新規のストリームへの移行を行っているのと並行に2つのストリームを実行できるように、簡単に別のストリームを起動することができます。
高度なアラートとモニタリング
他にもDatabricksがサポートする行動なモニタリングテクニックが存在します。例えば、Datadog、Apache Kafka、Coda Hale Metricsのようなシステムを用いて通知を出力することができます。これらの高度なテクニックは、外部モニタリング、アラートシステムの実装に使用することができます。
以下の例では、Kafkaにすべてのクエリーの進捗情報を転送するStreamingQueryListenerを作成します。
class KafkaMetrics(servers: String) extends StreamingQueryListener {
val kafkaProperties = new Properties()
kafkaProperties.put("bootstrap.servers", servers)
kafkaProperties.put("key.serializer", "kafkashaded.org.apache.kafka.common.serialization.StringSerializer")
kafkaProperties.put("value.serializer", "kafkashaded.org.apache.kafka.common.serialization.StringSerializer")
val producer = new KafkaProducer[String, String](kafkaProperties)
def onQueryProgress(event: org.apache.spark.sql.streaming.StreamingQueryListener.QueryProgressEvent): Unit = {
producer.send(new ProducerRecord("streaming-metrics", event.progress.json))
}
def onQueryStarted(event: org.apache.spark.sql.streaming.StreamingQueryListener.QueryStartedEvent): Unit = {}
def onQueryTerminated(event: org.apache.spark.sql.streaming.StreamingQueryListener.QueryTerminatedEvent): Unit = {}
}
訳者注
PySparkでもストリーミングクエリーのリスナーがサポートされました。
まとめ
この記事では、Databricksを用いることで、構造化ストリーミングのプロトタイプからプロダクションまでの移行がどれだけシンプルになるのかを説明しました。構造化ストリーミングの他の側面に関して学びたいのであれば、ブログシリーをご覧ください。
- Sparkの構造化ストリーミング
- Real-time Streaming ETL with Structured Streaming in Apache Spark 2.1
- Working with Complex Data Formats with Structured Streaming in Apache Spark 2.1
- Processing Data in Apache Kafka with Structured Streaming in Apache Spark 2.2
- Event-time Aggregation and Watermarking in Apache Spark’s Structured Streaming
Databricksのドキュメントでストリーミングの使用方法を学ぶか、フリートライアルにサインアップすることもできます。