Spark Structured Streaming - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
注意
2016年の記事です。
Apache Spark 2.0で、継続的アプリケーションを構築するための新たな高レベルAPIである構造化ストリーミングの最初のバージョンを追加しました。主なゴールは、一貫性があり耐障害性のある方法でストレージ、サービングシステム、バッチジョブと連携するエンドツーエンドのストリーミングアプリケーションの構築を右容易にするということです。この記事では、現行の分散ストリーミングエンジンではなぜこれが難しいのかを説明し、構造化ストリーミングをご紹介します。
なぜストリーミングは難しいのか
ざっと見ると、分散ストリーミングエンジンの構築は、一連のサーバーを起動し、それらの間でデータをプッシュするのと同じようにシンプルなものに見えるかもしれません。残念ですが、分散ストリーミング処理はバッチジョブのようなシンプルな計算処理には影響しない、さまざまな複雑性に直面することになります。
まず初めに、シンプルなアプリケーションを考えてみます:モバイルアプリからイベント(phone_id, time, action)を受け取り、時間あたりそれぞれのタイプのアクションがあったのかをカウントし、MySQLに結果を保存したいものとします。このアプリケーションをバッチジョブとして実行しており、すべての入力イベントを保有するテーブルが存在するとした場合、以下のSQLクエリーで表現することができます。
SELECT action, WINDOW(time, "1 hour"), COUNT(*)
FROM events
GROUP BY action, WINDOW(time, "1 hour")
分散ストリーミングエンジンにおいて、以下に示すように「map-reduce」パターンに従ってデータを処理するノードをセットアップすることができます。最初のレイヤーのそれぞれのノードは、入力データ(すなわち、一連のスマートフォンからのストリーム)のパーティションを読み込み、グループごとのカウントをトラックし、MySQLを定期的に更新するreducerノードに送信するために、イベントを(action, hour)でハッシュします。
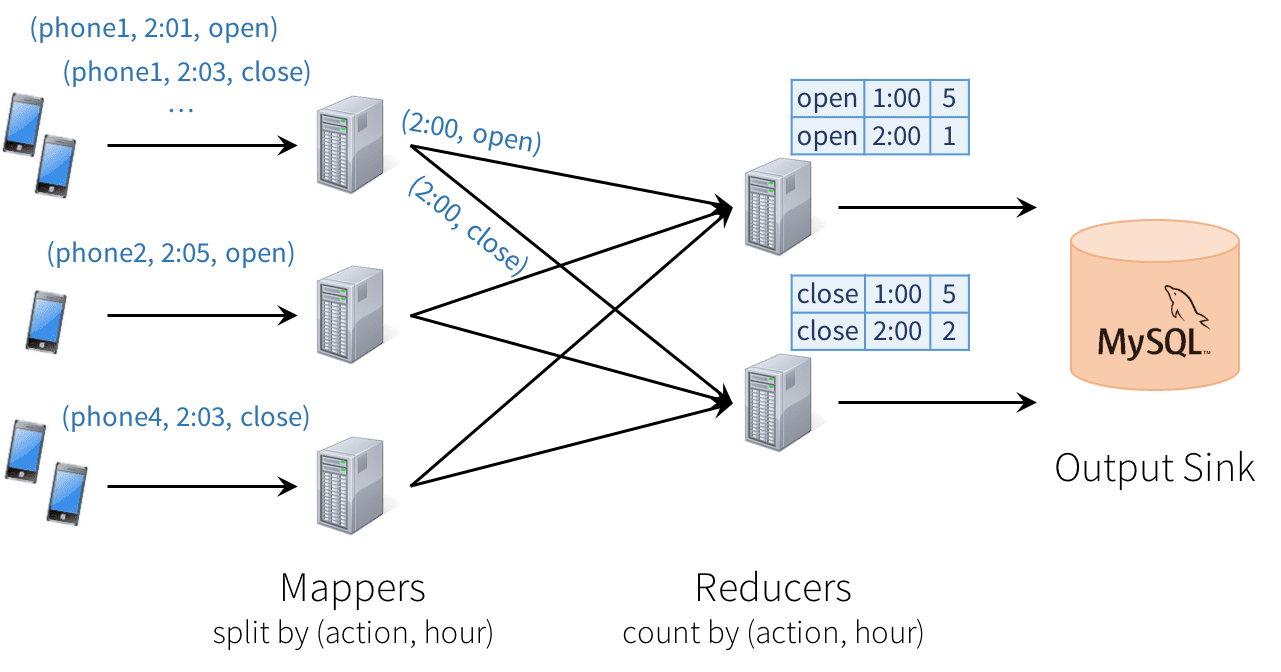
残念ですが、この種のデザインは多くの課題をもたらします。
- 一貫性: この分散のデザインにおいては、レコードは別の部分で処理される前にシステムの一部で処理されることになり、ナンセンスな結果を引き起こします。例えば、ユーザーがアプリを開いた際に「オープン」イベントを送信し、閉じた際に「クローズ」イベントを送信します。「オープン」を取り扱うReducerノードが、「クローズ」を取り扱うReducerノードよりも遅い場合、MySQLで「オープン」よりも「クローズ」の合計カウントが高くなる様子を確認することになり、ナンセンスな結果となります。上の図ではこのような例を示しています。
- 耐障害性: Mapper、Reducerの一つが障害を起こした場合に何が起きるのでしょうか?ReducerはMySQLにアクションを2回含めるべきではありませんが、Mapperが出現した際にどのように古いデータをリクエストするのかを知る必要があります。ストリーミングエンジンは少なくともエンジン内で強力なセマンティックスを提供するために、膨大なトラブルを体験しています。しかし、多くのエンジンにおいては、外部ストレージで結果の一貫性を保つことはユーザーに任されています。
- 順番を守らないデータ: 現実世界においては、異なるデータソースからのデータは順序を守らずに到着します。例えば、通信できないモバイルデバイスにおいては、データのアップロードの時間が遅れることがあります。時間フィールドの順序でデータが到着することを想定するReducerオペレータを記述しても、これは動作しません。順序を守らないデータの到着に備える必要があり、それに応じてMySQLで結果をアップデートしなくてはなりません。
現在の多くのストリーミングシステムでは、これらの一部あるいは全ての懸念はユーザーに任されています。残念ながら、アプリケーションが外の世界とどのようにやり取りをするのかというこれらの問題は、理由づけを行い適切な状態にするのが非常に困難であることによります。特に、上述したSQLクエリーのようにシンプルなセマンティクスを得る簡単な方法が存在しません。
構造化ストリーミングモデル
構造化ストリーミングにおいて、我々はシステムに対して、いつでもデータのプレフィクスにおいてバッチジョブの実行結果とアプリケーションの出力が同じようになるように強力な保証を行うことで、セマンティクスの問題に正面から取り組んでいます。例えば、このモニタリングアプリケーションにおいて、MySQLの結果テーブルはそれぞれの電話の更新ストリーム(ここまででシステムに為されたデータ更新)のプレフィクスの取得、上に示したようなSQLクエリーの実行と常に等しくなります。「クローズ」イベントよりも先にカウントされる「オープン」イベントや、障がいにおける更新の重複などは存在しません。構造化ストリーミングはエンジン内で自動で一貫性と信頼性の両方をハンドリングし、外部システム(MySQLをトランザクション更新するなど)と連携します。
このプレフィックス一貫性は、ここまでで特定した3つの課題に対する理由づけを容易にします。特に、
- 出力テーブルはデータプレフィックスの全てのレコードと常に一貫性があります。例えば、それぞれの電話が連続ストリーム(Apache Kafkaと同じパーティションなど)としてデータをアップロードする限り、常に順序通りイベントを処理、カウントすることになります。
- 構造化ストリーミングによって、出力シンクとのやり取りを含め、包括的に耐障害性がハンドリングされます。これは、継続的アプリケーションのサポートにおける主要なゴールとなっています。
- 順序を守らないデータ(out-of-order) の影響は明らかです。我々はジョブが、ストリームのプレフィクスに対するアクションと時間でグルーピングされたカウントを出力することを知っています。後でより多くのデータを受信した場合、過去1時間の時間フィールドを見ることとなり、MySQLのそれぞれの行をシンプルにアップデートします。また、構造化ストリーミングは、ユーザーが必要であればあまりに古いデータを除外するAPIもサポートしています。しかし、基本的に順序を守らないデータは「特別なケース」ではありません。時間フィールドでグルーピングするためにクエリーを実行することで、古い時間をみることは、繰り返しのアクションを見ることと違いはありません。
構造化ストリーミングの最後のメリットは、そのAPIの使いやすさです。これは単にSparkのデータフレーム、データセットAPIです。ユーザーは単に実行したクエリーと入力と出力の場所、そして、オプションの追加情報を記述します。システムはこのクエリーをインクリメンタルに処理し、障害からの復旧に十分な状態を保持し、外部巣tーレージにおける一貫性を保持し続けます。例えば、ストリーミングモニタリングアプリケーションをどのように記述するのかを以下に示します。
// Read data continuously from an S3 location
val inputDF = spark.readStream.json("s3://logs")
// Do operations using the standard DataFrame API and write to MySQL
inputDF.groupBy($"action", window($"time", "1 hour")).count()
.writeStream.format("jdbc")
.start("jdbc:mysql//…")
このコードは以下のバッチバージョンとほとんど同じです。readとwriteが変わっているだけです。
// Read data once from an S3 location
val inputDF = spark.read.json("s3://logs")
// Do operations using the standard DataFrame API and write to MySQL
inputDF.groupBy($"action", window($"time", "1 hour")).count()
.writeStream.format("jdbc")
.save("jdbc:mysql//…")
次のセクションでは、このモデルの詳細とAPIを説明します。
モデルの詳細
コンセプト的には、構造化ストリーミングは到着するすべてのデータを制限のない入力テーブルとして取り扱います。行のようなストリーミング内のそれぞれの新規アイテムは入力テーブルに追加されます。実際には、入力の全てを保持しませんが、結果は全てをバッチ実行したものと等しくなります。

次に、開発者は出力シンクに書き込まれる最終的な結果テーブルを計算するために、静的なテーブルに行うのと同じように、入力テーブルに対するクエリーを定義します。Sparkは自動でこのバッチのようなクエリーを、ストリーミング実行計画に変換します。これは、インクリメンタル化(incrementalization) と呼ばれ、Sparkはレコードが到着するたびに結果を更新するために、何の状態を保持すべきかを特定します。最後に、結果をいつ更新するのかをコントロールするためにトリガーを指定します。トリガーが起動されるたびに、Sparkは新規データ(入力テーブルの新規行)をチェックし、結果をインクリメンタルに更新します。
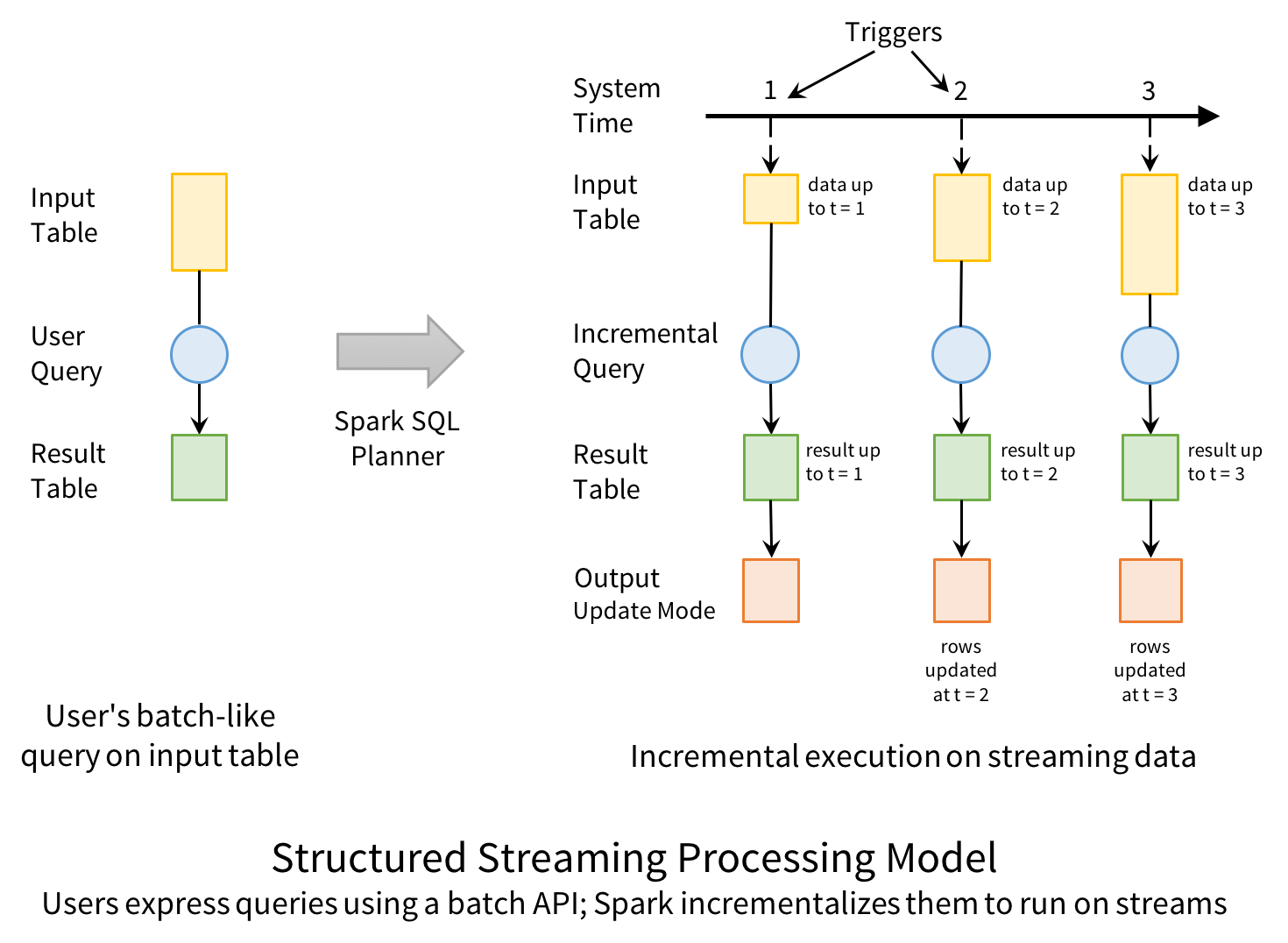
モデルの最後の部分は出力モードです。結果テーブルが更新されるたびに、開発者はS3、HDFS、データベースのような外部システムに変更を書き込みたいと考えます。通常は出力をインクリメンタルに書き込みたいと考えます。このため、構造化ストリーミングでは以下の3つの出力モードをサポートしています。
- Append: 前回のトリガーが外部ストレージに書き込んだ以降の新規行のみが結果テーブルに追加されます。これは、結果テーブルに存在する行が変更できない場合(入力ストリームに対するmapなど)にのみ適用できます。
- Complete: 外部ストレージに更新された結果テーブル全体が書き込まれます。
- Update: 前回のトリガー以降の結果テーブルで更新された行のみが、外部ストレージで変更されます。このモードは、MySQLテーブルのようにその場で更新される出力シンクで動作します。
このモデルで我々のモバイルモニタリングアプリケーションをどのように実行するのかを見ていきましょう。バッチクエリーは、(action, hour)でグルーピングされたアクションの数を計算するためのものでした。インクリメンタルにこのクエリーを実行するために、Sparkはその時点のペアごとのカウントといくつかの状態を保持し、新規レコードが到着するたびに更新を行います。変更されたそれぞれのレコードに対して、出力モードに応じてデータを出力します。以下の図では、Update出力モードを用いた処理を表しています。
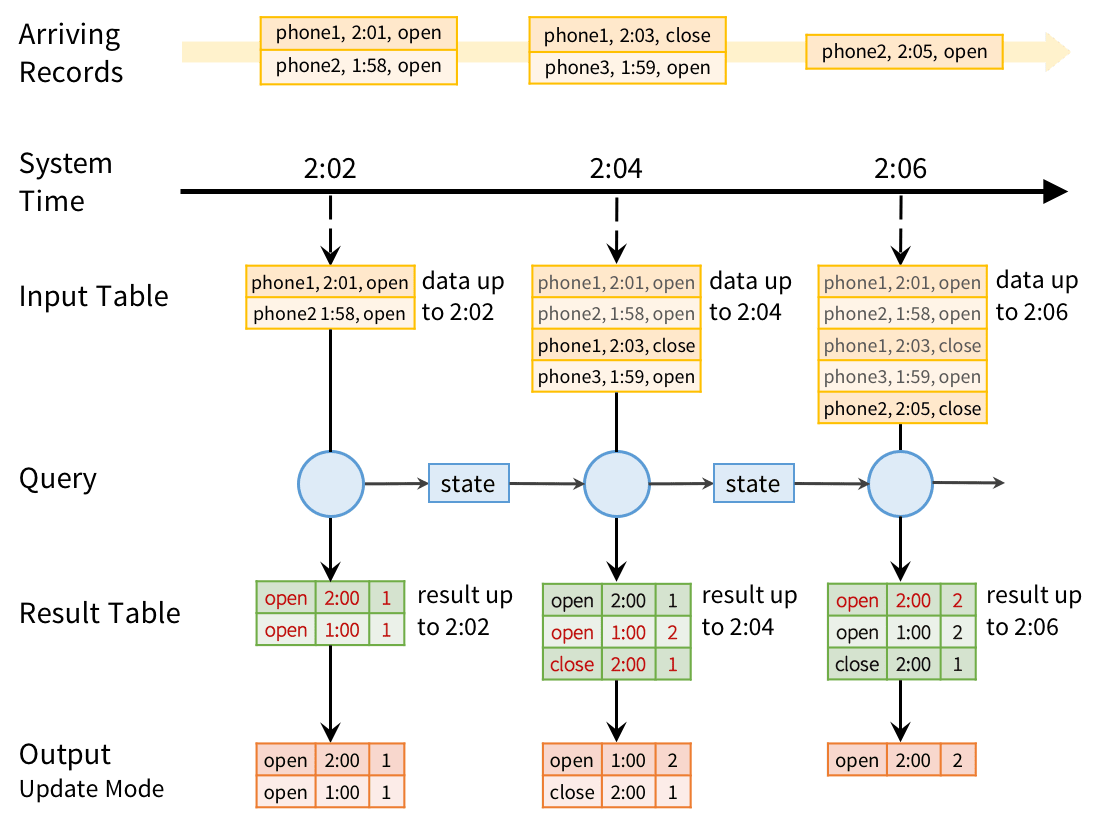
それぞれのトリガーポイントにおいて、前回グルーピングされたカウントを取得し、新たな結果テーブルを得るために前回のトリガー以降に到着した新規データを用いてアップデートを行います。シンクに対する出力モードで必要な変更のみが送信されます。ここでは、MySQL(図における赤色)における当該トリガーの間で変化した(action, hour)ペアのレコードをアップデートします。
また、システムは遅延データも自動でハンドリングすることに注意してください。上の図では、携帯上で1:58に発生したphone3の「オープン」イベントは2:02にシステムに到着します。しかし、これは2:00に属しますが、MySQLにおいては1:00のレコードを更新します。しかし、構造化ストリーミングにおけるプレフィクスの一貫性保証は、それぞれのソースからレコードを到着順で処理することを保証します。例えば、phone1の「クローズ」イベントは「オープン」イベントの後に到着するので、常に「クローズ」カウントの更新の前に「オープン」イベントを更新します。
障害復旧及びストレージシステムの要件
構造化ストリーミングは、マシンに障害が起きても結果を適切な状態に保ちます。このために、入力ソースと出力シンクに2つの要件を求めます。
- 入力ソースは、ジョブがクラッシュした際に最新データを再読み込みできるように、再実行可能でなくてはなりません。例えば、Amazon KinesisやApache Kafkaのようなメッセージバスは、ファイルシステム入力ソースと同じように再実行可能です。数分データのみを保持する必要があります。構造化ストリーミングはその後の内部状態を維持します。
- 出力シンクでは、システムが一連のレコードを原子的に取り扱えるようにトランザクション更新をサポートする必要があります。現在の構造化ストリーミングではファイルシンクに対する実装をしており、将来的には一般的なデータベースやキーバリューストアに対する実装を追加する予定です。
我々は、ユーザー自身がジョブの信頼性を高めるためにすでに多くのSparkアプリケーションにおいて、これらの特性を持つシンクとソースを使用していることを知りました。
これらの要件に加え、構造化ストリーミングは我々の例におけるランニングカウント のようなデータを保存するために、S3、HDFSのような高信頼ストレージシステムで内部状態を管理します。これらの特性によって、構造化ストリーミングはエンドツーエンドのプレフィクス一貫性を強制します。
構造化ストリーミングAPI
構造化ストリーミングはSparkのデータセット、データフレームAPIに組み込まれています。多くの場合、ストリーミング処理を実行するために幾つかのメソッド呼び出しを追加する必要があるだけです。また、ウィンドウ集計のための新たなオペレーターと、実行モデルのためのパラメーター設定(出力モードなど)が追加されています。Apache Spark 2.0においては、コアAPIとシステムのアルファバージョンを開発しました。シリアライズ化などの他のオペレーターは将来的に追加される見込みです。
APIの基本
構造化ストリーミングのストリームはisStreamingプロパティがtrueに設定されたデータフレーム、データセットとして表現されます。さまざまなソースに対して特殊なreadメソッドを用いてこれらを作成することができます。例えば、我々のモニタリングソリューションにおいては、Amazon S3にアップロードされるJSONファイルからデータを読み込むものとします。以下のコードではScalaでどのように実装するのかを示しています。
val inputDF = spark.readStream.json("s3://logs")
結果として得られるデータフレーム、inputDFが入力テーブルとなり、ディレクトリに新規ファイルが追加されるたびに、新規レコードで継続的に拡張されることになります。このテーブルには2つのカラムtimeとactionがあります。これで、データを変換するために通常のデータフレーム、データセットのオペレーションを使用することができます。我々の例では、時間ごとのアクションのタイプのカウントを行います。このためには、アクションと1時間の時間ウィンドウを用いてグルーピングを行います。
val countsDF = inputDF.groupBy($"action", window($"time", "1 hour"))
.count()
新たなデータフレームcountsDFが結果テーブルとなり、action、window、countのカラムを持ち、クエリーが開始すると継続的にアップデートされます。inputDFが静的なテーブルだったとしても、この変換処理は1時間ごとのカウントを提供することに注意してください。これによって、開発者は静的なデータセットに対して自身のビジネスロジックをテストすることができ、ロジックを変更することなしにシームレスにストリーミングデータに適用することができます。
最後に、このテーブルをシンクに書き込み、ストリーミング処理をスタートするようにエンジンに指示します。
val query = countsDF.writeStream.format("jdbc").start("jdbc://...")
返却されるクエリーは、アクティブなストリーミング実行のハンドルであり、処理実行の管理、モニタリングに使用されるStreamingQueryとなります。
これらの基本に加え、構造化ストリーミングで可能な数多くのオペレーションが存在します。
マッピング、フィルタリング、集計の実行
構造化ストリーミングプログラムでは、データの変換にmap、filter、selectなどを含む既存のデータフレーム、データセットのメソッドを使用することができます。さらに、開始時刻からのcountのようなランニング(無限の)集計も既存APIを通じて利用することができます。上述のモニタリングアプリケーションで使用したのがこれです。
イベント時間に対するウィンドウ集計
多くの場合、ストリーミングのアプリケーションでは、互いにオーバーラップ(5分間隔で進む1時間のウィンドウなど)するスライディングウィンドウや、互いにオーバラップしない(例:単に時間単位)タンブリングウィンドウを含むさまざまなタイプのウィンドウに基づいてデータを計算する必要があります。構造化ストリーミングにおいて、ウィンドウはシンプルにgroup byで表現されます。それぞれの入力イベントは1つ以上のウィンドウにマッピングされ、シンプルに1行以上の結果テーブルの行を更新することになります。
ウィンドウはデータフレームのwindow関数を用いて指定することができます。例えば、以下のようにスライディングウィンドウを用いてアクションをカウントするように、モニタリングジョブを変更することができます。
inputDF.groupBy($"action", window($"time", "1 hour", "5 minutes"))
.count()
以前のアプリケーションでは(hour, action, count)の形式で結果を出力していましたが、この新しいアプリケーションでは、(“1:10-2:10”, “open”, 17)のように(window, action, count)の形式になります。遅延したレコードが到着すると、MySQLで対応するすべてのウィンドウを更新します。他の数多くのシステムと異なり、ウィンドウ処理はストリーミング処理における特別なオペレータというだけではありません。同じようにバッチジョブをグルーピングするために、同じコードを実行することができます。
ウィンドウ集計は、我々が構造化ストリーミングで拡張し続けようとしている領域の一つです。特に、Spark 2.1では、十分な時間が経過した後にあまりに古いデータを削除する機能であるウォーターマークを追加しようとしています。この種の機能なしには、システムは古いウィンドウすべてを追跡しなくてはならないかも知れず、アプリケーションの処理がスケールしません。さらに、あるソースからのイベントをビジネスロジックに応じて可変長のセッションにグルーピングするセッションベースのウィンドウをサポートする予定です。
訳者注
セッションウィンドウはSpark 3.2時点でサポート済みです。
静的データとストリームのJoin
構造化ストリーミングはシンプルにデータフレームAPIを使用しているので、Apahce Hiveテーブルのような静的なデータフレームに対してストリームをjoinするのは簡単です。
// Bring in data about each customer from a static "customers" table,
// then join it with a streaming DataFrame
val customersDF = spark.table("customers")
inputDF.join(customersDF, "customer_id")
.groupBy($"customer_name", hour($"time"))
.count()
さらに、静的なデータフレームをSparkクエリーを用いて研鑽することができるので、バッチとストリーミングの処理を混在させることができます。
インタラクティブなクエリー
構造化ストリーミングは、SparkのJDBCサーバーを通じてインタラクティブクエリーに直接結果を公開することができます。Spark 2.0においては、これを行うために、大規模データボリュームには向かない初歩的な「memory」出力シンクを使用していました。しかし、将来的なリリースでは、インメモリのSpark SQLテーブルにクエリーの結果を描き出せるようになり、それに対して直接クエリーを実行できるようになります。
// Save our previous counts query to an in-memory table
countsDF.writeStream.format("memory")
.queryName("counts")
.outputMode("complete")
.start()
// Then any thread can query the table using SQL
sql("select sum(count) from counts where action=’login’")
訳者注
Spark 3.2時点では、toTableを用いることでテーブルを出力シンクに指定できるようになっています。
他のエンジンとの比較
構造化ストリーミングの何がユニークなのかを示すために、以下の表では他のいくつかのシステムとの比較を行なっています。議論したように、構造化ストリーミングのプレフィクス一貫性の強力な保証によって、バッチジョブと等価なものとなり、大規模アプリケーションとのインテグレーションが容易になっています。さらに、Spark上で開発することで、バッチとインタラクティブクエリーとのインテグレーションを実現します。

まとめ
構造化ストリーミングは、Sparkストリーミングで最も最適に動作する機能を用いて開発されており、エンドツーエンドのリアルタイムアプリケーションの構築に対して非常にシンプルなモデルになることを約束します。Apache Spark 2.0で構造化ストリーミングはアルファバージョンですが、ぜひ試していただければと考えています。
長期的にはデータフレームAPIのように、より厳密かつより高レベルなインタフェースを提供することで構造化ストリーミングがSparkストリーミングを補完することになると考えています。今時点でSparkストリーミングを実行しているのであれば心配しないでください、サポートは継続されます。しかし、より多くのユーザーに対して構造化ストリーミングがリアルタイム処理への扉を開くことを信じています。
また、構造化ストリーミングは無料のDatabricksコミュニティエディションを含み、Databricksで完全にサポートされています。
追加の資料
さらに、以下のリソースで構造化ストリーミングをカバーしています。
- Structuring Spark: DataFrames, Datasets and Streaming
- Structured Streaming Programming Guide
- Spark 2.0 and Structured Streaming
- A Deep Dive Into Structured Streaming