本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
イントロダクション
このブログ記事では、Hugging Face Diffusers、Databricksモデルサービング、Databricks Appsを用いたインペインティングアプリケーション作成をウォークスルーします。インペインティングは、文脈情報を活用することで、画像の特定の部分を編集したり、欠損したりダメージを受けている領域を再構成するために生成AIを活用する魅力的なアプリケーションです。我々はDatabricksを用いて、シームレスなデプロイのための、スケーラブルなMLインフラ、マネージドのモデルサービング、アプリのパワーを活用します。Databricksモデルサービングは、AIや機械学習モデルをデプロイ、管理、クエリーするための統合されたインタフェースを提供し、REST APIを通じたスケーラブルでリアルタイムの推論を可能にします。Databricks Appsによって、開発者はDatabricksプラットフォーム内で直接、Dash、Streamlit、Gradioのような人気のフレームワークを用いて、セキュアなデータとAIのアプリケーションを迅速に構築、デプロイできるようになります。
このステップバイステップのガイドでは、以下の方法をデモンストレーションします:
- 必要な環境とツールのセットアップ
- インペインティングパイプラインによる実験
- カスタムMLflowモデルの作成
- MLflowへのモデルの記録、Unity Catalogへの登録
- Databricksモデルサービンを用いたモデルのサービング
- Databricksアプリの作成
この取り組みのコードとスクリプトは、こちらのGithubリポジトリで提供されています。
ステップ 1: 環境のセットアップ
-
Databricksクラスターを作成します。
- ML Databricks Runtime 15.4 LTSを使います。
- 最低でも60GBのRAMとGPU(最低でも16GBのVRAM)を持つシングルノードクラスターを選択します。
-
依存関係のインストール:
%pip installを用いて以下のライブラリをインストールします:%pip install mlflow==2.17.2 diffusers==0.31.0 dbutils.library.restartPython()進める前に、以下を実行することでCUDAが利用できることを確認できます。
import torch print(torch.cuda.is_available()) -
Hugging Face認証情報のセットアップ: Databricksマネージドのシークレットを用いて、セキュアにHugging Faceにログインします:
すでにセットアップされているすコーオプとシークレットが必要となります。手順に関しては、Databricksのシークレット管理のドキュメントをご覧ください。
from huggingface_hub import login login(token=dbutils.secrets.get('your_scope_name', 'HF_API_TOKEN'))
ステップ 2: インペインペインティングパイプラインを用いた実験
すべてのMLプロジェクトは開発や実験からスタートします。このステップでは、モデルを記録、登録する前に、実験フェーズを実施します。このステップは、Hugging Faceのインペイントのページに強く影響を受けています。
-
インペインティングモデルのロード
Stable Diffusion XL 1.0インペインティングパイプラインをロードします。Hugging Faceのモデルハブには他にもインペインティングパイプラインがあることに注意してください。from diffusers import AutoPipelineForInpainting pipe = AutoPipelineForInpainting.from_pretrained( "diffusers/stable-diffusion-xl-1.0-inpainting-0.1", torch_dtype=torch.float16, variant="fp16" ).to("cuda:0")効率的な処理のために、パイプラインをGPU(
cuda:0)に移動します。我々が使っているGPUには、このモデルを取り扱うのに十分なVRAMがあるので、パイプライン全体をGPUに移動する事ができます。小規模なGPUでは、複数のGPUにワークロードを分散させるオプションがありますが、この記事のスコープ外になります。 -
入力の準備: 入力の画像とマスク(マスクはインペインティングの領域を定義します)をロードします:
from PIL import Image image = Image.open("./input_image.jpg").convert("RGB") mask = Image.open("./input_mask.png").convert("L").convert("RGB")互換性のために、画像とマスクの次元は8で割れるようにしてください。
-
インペインティングの実行: プロンプトを用いて出力画像を生成します:
prompt = "some prompt ..." negative_prompt = "some prompt ..." output_image = pipe( prompt=prompt, negative_prompt=negative_prompt, image=image, mask_image=mask, num_inference_steps=40, guidance_scale=9, strength=0.81 ).images[0] output_image.save("./output_image.png")ここでのゴールは、全てが期待した通りに動作することを確認し、インペインティングパイプラインとその設定に慣れ親しむことであることに注意してください。
ステップ 3: モデルの登録とサービング
-
MLflowモデルの作成: インペインティングパイプラインと連携するカスタムの
InPainterモデルを実装します。import mlflow mlflow.set_registry_uri('databricks-uc') from diffusers import AutoPipelineForInpainting class InPainter(mlflow.pyfunc.PythonModel): def load_context(self, context): ... def base64_to_image(self, img_base64_str): ... def base64_to_image(self, img_base64_str): ... def predict(self, context, model_input, params=None): ...MLflowレジストリURIとして、Databricks Unity Catalogを設定していることを確認してください。こちらはモデルのサービングで重要となります。コードの詳細に関しては、GitHubのリポジトリをご覧ください。
-
MLflowによるモデルの登録: モデルのシグネチャ(入出力のスキーマとパラメーター)を定義します。
from mlflow.models.signature import ModelSignature from mlflow.types import Schema, ColSpec, DataType input_schema = ... output_schema = ... parameters = ... signature = ModelSignature(inputs=input_schema, outputs=output_schema, params=parameters)モデルシグネチャもまたモデルのサービングでは重要なものとなります。
次に、モデルをMLflowトラッキングサーバーに記録し、Unity Catalogに登録します。これによって、モデルをサービングできるようになるだけではなく、Unity Catalogの統合ガバナンスの監視下に置く事ができます。
with mlflow.start_run(): mlflow.pyfunc.log_model( artifact_path="sdxl_inpaint_model", python_model=InPainter(), artifacts={"snapshot": snapshot_location}, registered_model_name=f"{catalog}.{schema}.sdxl_inpaint", signature=signature )
ステップ 4: モデルのデプロイとサービング
Databricksモデルサービングを用いて、エンドポイントとしてモデルをデプロイします。これは、UIあるいはAPIを用いて行う事ができます。(ミディアムあるいはラージの)GPUワークロードタイプを選択するようにしてください。モデルサービングのさまざまな設定に関しては、Databricksモデルサービングのドキュメントをご覧ください。
import mlflow
from mlflow.deployments import get_deploy_client
ENDPOINT_NAME = 'eo-sdxl-inpainter'
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name=f"{ENDPOINT_NAME}",
config={
"served_entities": [
{
"entity_name": f"{catalog}.{schema}.sdxl_inpaint",
"entity_version": "1",
"workload_type": "GPU_MEDIUM",
"workload_size": "Medium",
"scale_to_zero_enabled": False
}
],
"traffic_config": {
"routes": [
{
"served_model_name": "sdxl_inpaint-1",
"traffic_percentage": 100
}
]
}
},
route_optimized=True,
)
ステップ 5: アプリケーションのテスト
エンドポイントがライブになったら、入力を送信し、インペイントされた画像を取得するためにAPIを使えるようになります。テスト用のノートブックはGitHubリポジトリで提供されています。
ステップ 6: Databricksアプリの構築
Databricks Appsを用いる事で、ユーザーが画像とマスクをアップロードし、パラメーターを選択し、結果を参照できる直感的なUIを構築する事ができます。Databricks Appsによって、Databricksが提供する企業レベルのスケーラビリティ、ガバナンス、セキュリティ機能とフロントエンドアプリの柔軟性を組み合わせる事ができるようにナリアmす。図1では、数ステップでDatabricksアプリを作成、デプロイできることを示しています。詳細に関しては、Databricks Appsのドキュメントをご覧ください。
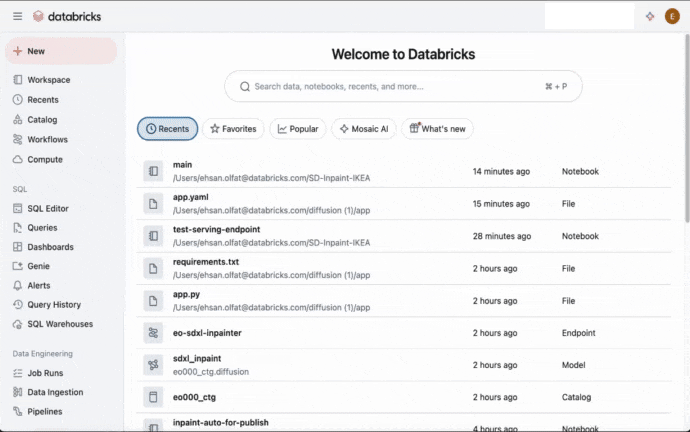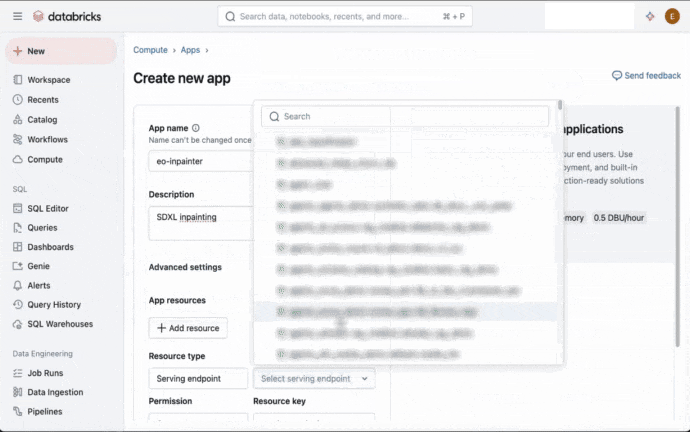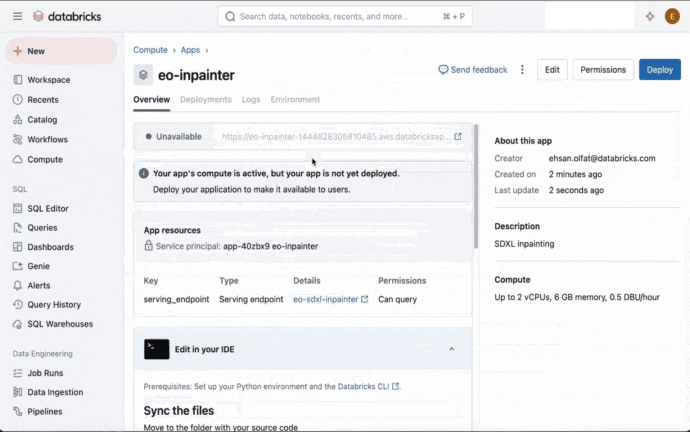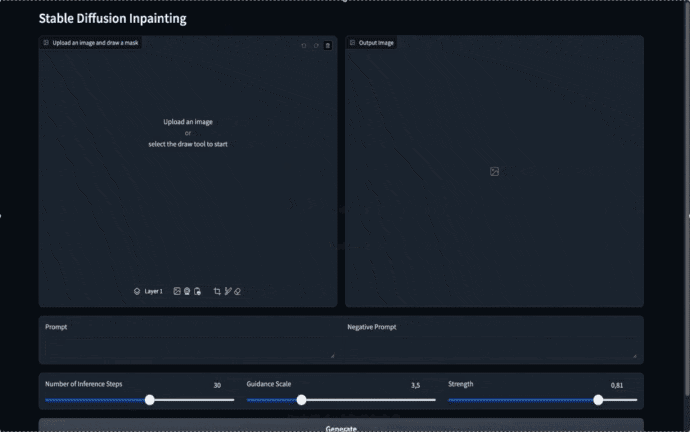
図1. UIを通じたDatabricksアプリの作成とデプロイ
Databricks Appsは一般的なアプリのフレームワークをサポートしています。この記事ではGradioを使っています。図2では、最終的な成果を示しており、インペインティングアプリがどのように動作するのかをデモンストレーションしています。
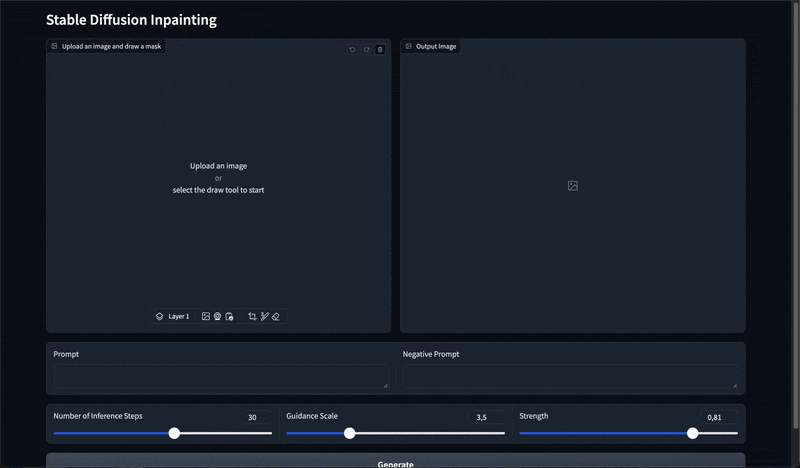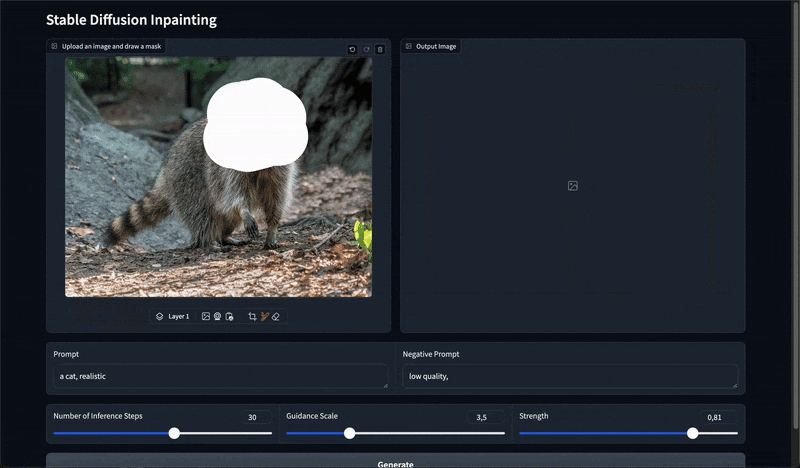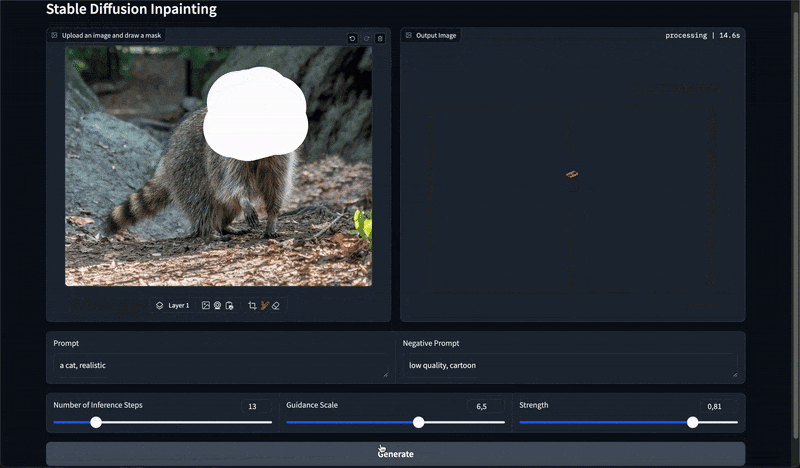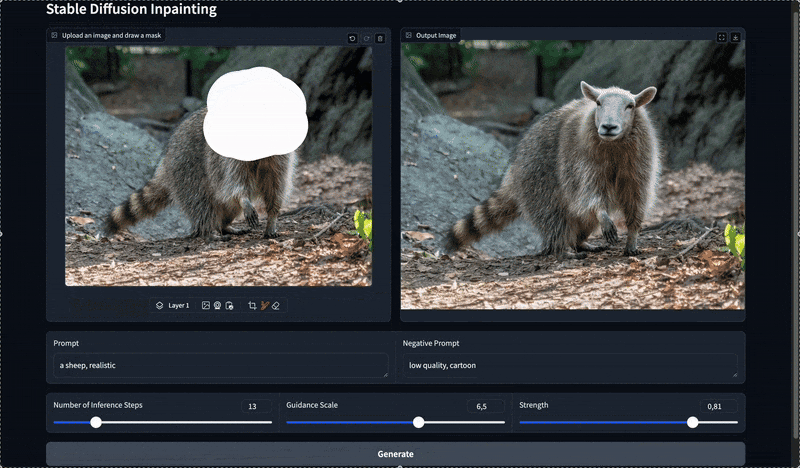
図2. 最終的なインペインティングアプリ
まとめ
このガイドでは、Hugging Face Diffuser、MLflow、Databricksモデルサービング、Databricks Appsをインテグレーションすることで、インペインティングアプリを構築しました。Databricksのモジュール性によって、シームレスなスケーリングやデプロイメントが可能となり、AIドリブンのアプリケーションの優れたプラットフォームとなっています。画像を改善したり、古い写真を修復するにしても、このパイプラインはあなたのインペインティングプロジェクトの堅牢な基盤となります。