こちらのチュートリアルの最初の01-llm-rag-fine-tuningノートブックをウォークスルーします。
注意
このチュートリアルで使用しているFoundation Model Training APIはプレビュー中であり、利用できるリージョンに制限があります。詳細はDatabricksアカウントチームにお問い合わせください。
DatabricksであなたのLLMをファインチューニング
LLMのファインチューニングは、既存のモデルをあなたの要件に特化するアクションです。技術的には、(DBRXやLLAMAのような)既存の基盤モデルの重みからスタートし、ご自身のデータセットに基づく別のトレーニングラウンドを追加することになります。
なぜファインチューニング?
Databricksでは、既存の基盤モデルを特化させるための簡単な手段を提供しており、優れたパフォーマンスを獲得し、コストを削減し、厳密なセキュリティとプライバシーを保ちつつも、ご自身のモデルを所有、コントロールできる様にします。
典型的なファインチューニングのユースケースには以下の様なものがあります:
- 固有の内部知識に対してモデルをトレーニング
- モデル挙動のカスタマイズ 例: 特殊なエンティティの抽出
- 回答の品質を改善しつつもモデルサイズと推論コストを削減
継続事前トレーニング(CPT) vs 指示ファインチューニング(IFT)
DatabricksのFine Tuning APIによって、いくつかの方法でご自身のモデルを適応させることができます:
-
教師ありファインチューニング: 構造化されたプロンプト-レスポンスデータでモデルをトレーニング。新たなタスクへのモデルの適応、レスポンスのスタイルの変更、NERのような指示追従能力の追加をする際にこちらを使用します(
instruction-fine-tuning/01-llm-instruction-drug-extraction-fine-tuningをご覧ください)。 - 継続事前トレーニング: 追加のラベルなしテキストデータでモデルをトレーニング。モデルに新たな知識を追加する、特定のドメインにモデルをフォーカスさせる場合にこちらを使用します。適切なものにするには数百万のトークンが必要となります。
- チャットコンプリーション: ユーザーとAIアシスタントとのチャットログでモデルをトレーニングします。このフォーマットは、実際のチャットログや質疑応答や会話テキストの標準フォーマットの両方に使用することができます。テキストは、特定のモデル向けに適切なチャットフォーマットに自動で整形され、このデモではこちらにフォーカスします。
ファインチューニングかRAGか?
RAGと指示ファインチューニングは一緒に動作します!適切なRAGのユースケースをお持ちの場合、基盤モデルを用いたRAGからスタートし、ご自身のコーパスがビジネス固有のもの(例: 基盤モデルトレーニングに含まれていないもの)である場合や特定の挙動が必要な場合(例: エンティティ抽出のような特定のタスクへの回答)には、モデルを特化させます。
基盤モデルに対するRAGからスタートし、モデルがどの様に動作しているのか、どこを改善できるのかを評価し、ファインチューンのためのデータセットを構築します!
Databricksドキュメントに対するチャットbotのファインチューニング
このデモでは、お客様のDatabricksに関連する質問に回答するRAGチャットbotのために、Databricksドキュメントを用いてMistral(あるいはllama)をファインチューニングします。

Databricksでは、モデルをファインチューニングし、パフォーマンスを評価するシンプルでビルトインのAPIを提供しています。始めましょう!
Databricksにおけるファインチューニングのドキュメント:
- 概要: 基盤モデル トレーニング | Databricks on AWS
- SDKガイド: 基盤モデル トレーニングAPIを使用してトレーニング 実行を作成します | Databricks on AWS
# 我々の製品のインストールからスタートしましょう
%pip install databricks-genai==1.0.2
%pip install databricks-sdk==0.27.1
%pip install "mlflow==2.12.2"
dbutils.library.restartPython()
%run ./_resources/00-setup
ファインチューニングのデータセット

高品質のファインチューニングデータセットの構築は、あなたのモデルのパフォーマンスの改善の鍵となります。
トレーニングデータセットは、最終的なモデルに送信することになるデータとマッチさせる必要があります。
RAGアプリケーションがある場合には、あなたのモデルがあなたが望む方法でコンテキストと回答から適切な情報を抽出する方法を学習できる様に、完全なRAG指示パイプラインを用いてファインチューンする必要があります。
このデモでは、以下を含むファインチューニングデータセットをロードしました:
- Databricksユーザーの質問 (例: どのようにウェアハウスを起動する?)
- この質問に適したDatabricksドキュメントのページあるいはチャンク
- 人間によってレビューされた期待される回答
training_dataset = spark.sql("""
SELECT q.id as question_id, q.question, a.answer, d.url, d.content FROM training_dataset_question q
INNER JOIN databricks_documentation d on q.doc_id = d.id
INNER JOIN training_dataset_answer a on a.question_id = q.id
WHERE answer IS NOT NULL""")
display(training_dataset)

チャットコンプリーションのためのデータセットの準備

チャットbotをファインチューニングするので、チャットコンプリーションのデータセットを準備する必要があります。
チャットコンプリーションには、OpenAIの標準に従い、ロールとプロンプトのリストが必要となります。この標準によって、我々のLLMインストラクションパターンに従うプロンプトに入力を変換するメリットが得られます。
それぞれの基盤モデルでは、異なるインストラクションタイプでトレーニングされている場合がありますので、ファインチューニングには同じタイプを使用することをお勧めします。
可能な限りチャットコンプリーションを用いることをお勧めします。
[
{"role": "system", "content": "[system prompt]"},
{"role": "user", "content": "Here is a documentation page:[RAG context]. Based on this, answer the following question: [user question]"},
{"role": "assistant", "content": "[answer]"}
]
ファインチューニングデータセットはあなたのRAGアプリケーションで使用するのと同じフォーマットである必要があることを覚えておいてください。
トレーニングデータのタイプ
Databricksでは様々な種類のデータセットフォーマット(ボリュームのファイル、Deltaテーブル、公開されている.jsonlフォーマットのHugging Faceデータセット)をサポートしていますが、プロダクションの品質を確実にするために、適切なデータパイプラインの一部として、Unity Catalog内のDeltaテーブルとしてデータセットを準備することをお勧めします。
覚えておいてください、このステップは重要なものであり、ご自身のトレーニングデータセットが高品質であることを確実にする必要があります。
最終的なチャットコンプリーションデータセットの作成をサポートする小さなpandas UDFを作成しましょう。
from pyspark.sql.functions import pandas_udf
import pandas as pd
#base_model_name = "meta-llama/Llama-2-7b-hf"
base_model_name = "mistralai/Mistral-7B-Instruct-v0.2"
system_prompt = """You are a highly knowledgeable and professional Databricks Support Agent. Your goal is to assist users with their questions and issues related to Databricks. Answer questions as precisely and accurately as possible, providing clear and concise information. If you do not know the answer, respond with "I don't know." Be polite and professional in your responses. Provide accurate and detailed information related to Databricks. If the question is unclear, ask for clarification.\n"""
@pandas_udf("array<struct<role:string, content:string>>")
def create_conversation(content: pd.Series, question: pd.Series, answer: pd.Series) -> pd.Series:
def build_message(c,q,a):
user_input = f"Here is a documentation page that could be relevant: {c}. Based on this, answer the following question: {q}"
if "mistral" in base_model_name:
# Mistralはsystemプロンプトをサポートしていません
return [
{"role": "user", "content": f"{system_prompt} \n{user_input}"},
{"role": "assistant", "content": a}]
else:
return [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_input},
{"role": "assistant", "content": a}]
return pd.Series([build_message(c,q,a) for c, q, a in zip(content, question, answer)])
training_data, eval_data = training_dataset.randomSplit([0.9, 0.1], seed=42)
training_data.select(create_conversation("content", "question", "answer").alias('messages')).write.mode('overwrite').saveAsTable("chat_completion_training_dataset")
eval_data.write.mode('overwrite').saveAsTable("chat_completion_evaluation_dataset")
display(spark.table('chat_completion_training_dataset'))

ファインチューニングランのスタート

トレーニングが完了すると、あなたのモデルは自動でUnity Catalog内に保存され、サービングできる様になります!
1.1) ベースラインモデルに対する指示ファインチューン

このデモでは、我々のLLMをプログラムからファインチューニングするために、先ほど作成したテーブルにAPIを使用します。
しかし、UIから新たなファインチューニングのエクスペリメントを作成することもできます!
from databricks.model_training import foundation_model as fm
# データセットを読み取り、ファインチューニングクラスターに送信するために使う現行のクラスターのIDを返却。https://docs.databricks.com/en/large-language-models/foundation-model-training/create-fine-tune-run.html#cluster-id をご覧ください
def get_current_cluster_id():
import json
return json.loads(dbutils.notebook.entry_point.getDbutils().notebook().getContext().safeToJson())['attributes']['clusterId']
# モデル名をきれいにしましょう
registered_model_name = f"{catalog}.{db}." + re.sub(r'[^a-zA-Z0-9]', '_', base_model_name)
run = fm.create(
data_prep_cluster_id=get_current_cluster_id(), # トレーニングデータソースとしてDeltaテーブルを使っている際には必要。これは、データ準備ジョブで使用するクラスターのIDとなります。
model=base_model_name, # ベースラインとしてどのモデルを使うのかを定義
train_data_path=f"{catalog}.{db}.chat_completion_training_dataset",
task_type="CHAT_COMPLETION", # コンプリーションためにファインチューニングAPIを使う際には task_type="INSTRUCTION_FINETUNE" に変更
register_to=registered_model_name,
training_duration="5ep", # デモを加速するために5エポックのみ。この数を増やすかどうかを確認するにはMLflowエクスペリメントのメトリクスをチェックしてください
learning_rate="5e-7",
)
print(run)
ちなみにUIはこんな感じです。
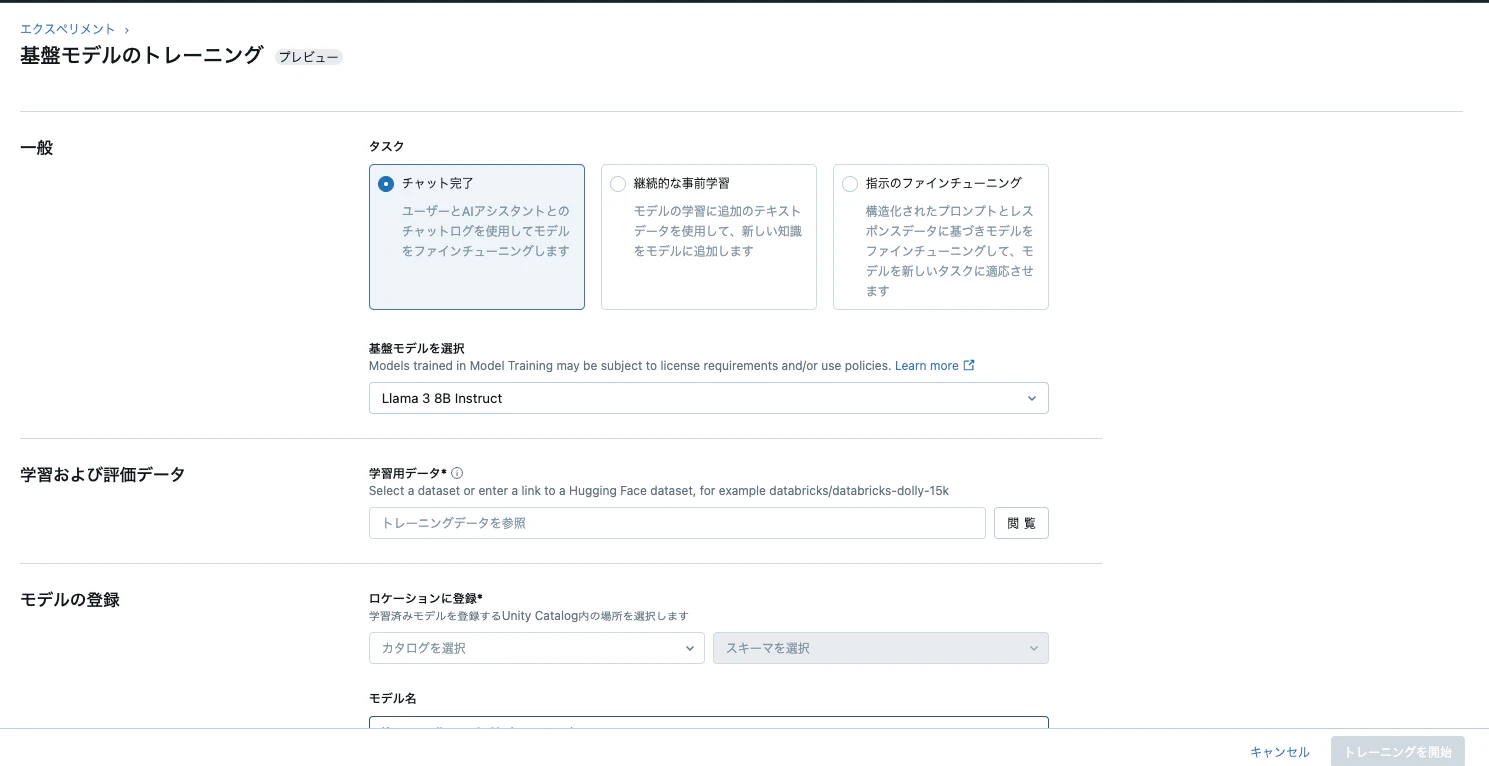
1.2) MLFlowエクスペリメント経由でファインチューニングのランを追跡
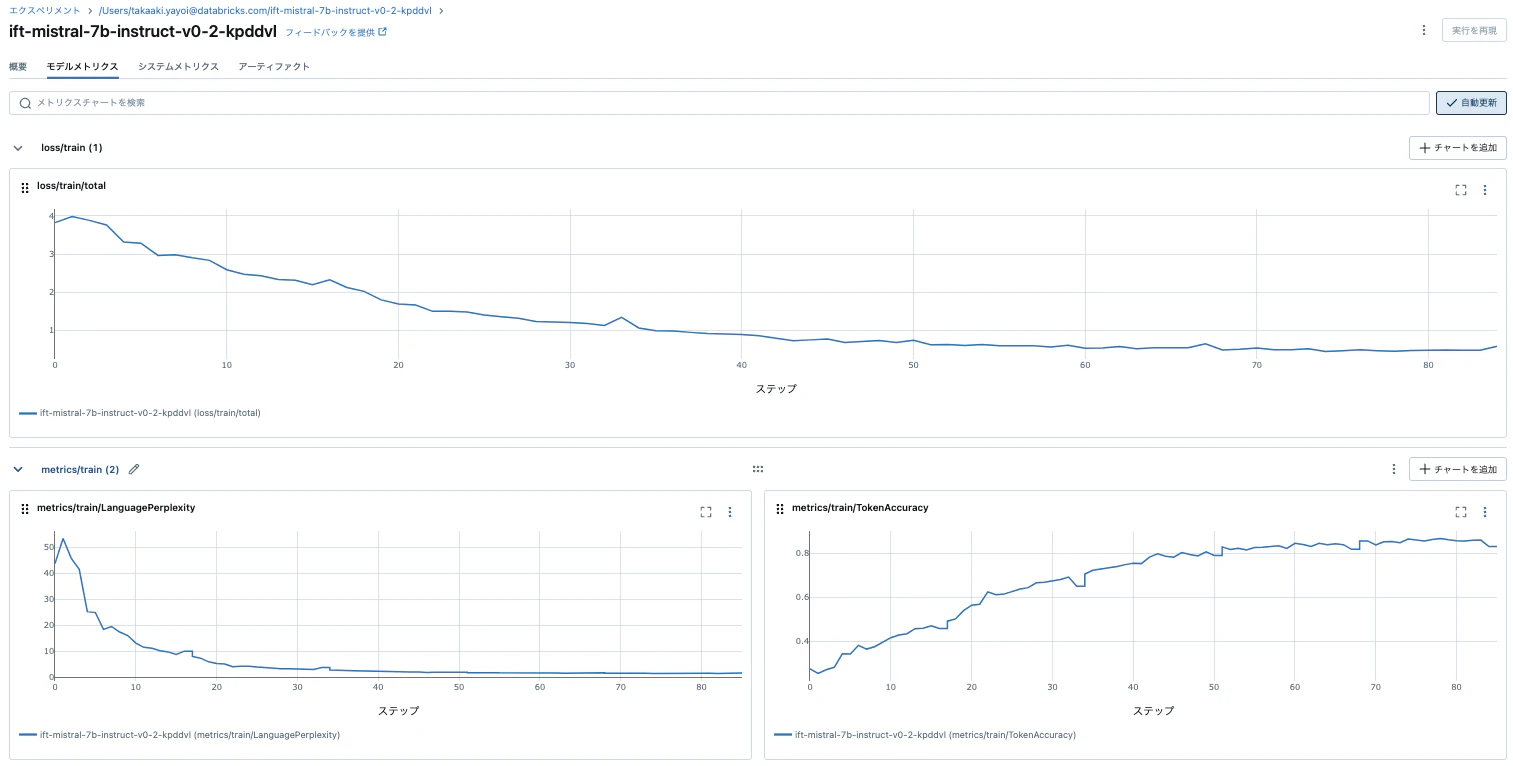
実行中、過去のファインチューニングのランの進捗を監視するには、MLflowエクスペリメントからランを開くことができます。ここでは、より良い結果を今後得るためにどの様な調整を行うべきなのかに関する有益な情報にアクセスすることがd系ます。例えば:
- ランの最後であなたのモデルに改善の余地がある場合にはエポックを追加
- ロスが減少しているが非常に遅い場合には学習率を増加
- ロスが大きく変動している場合には学習率を削減

displayHTML(f'Open the <a href="/ml/experiments/{run.experiment_id}/runs/{run.run_id}/model-metrics">training run on MLFlow</a> to track the metrics')
# ランの詳細を追跡
display(run.get_events())
# ランが終了するまで待つヘルパー関数 - 詳細は _resource フォルダーをご覧ください
wait_for_run_to_finish(run)
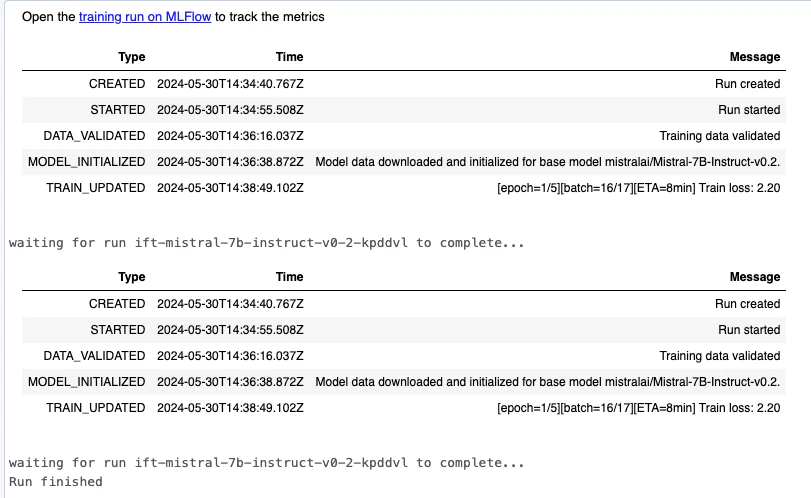
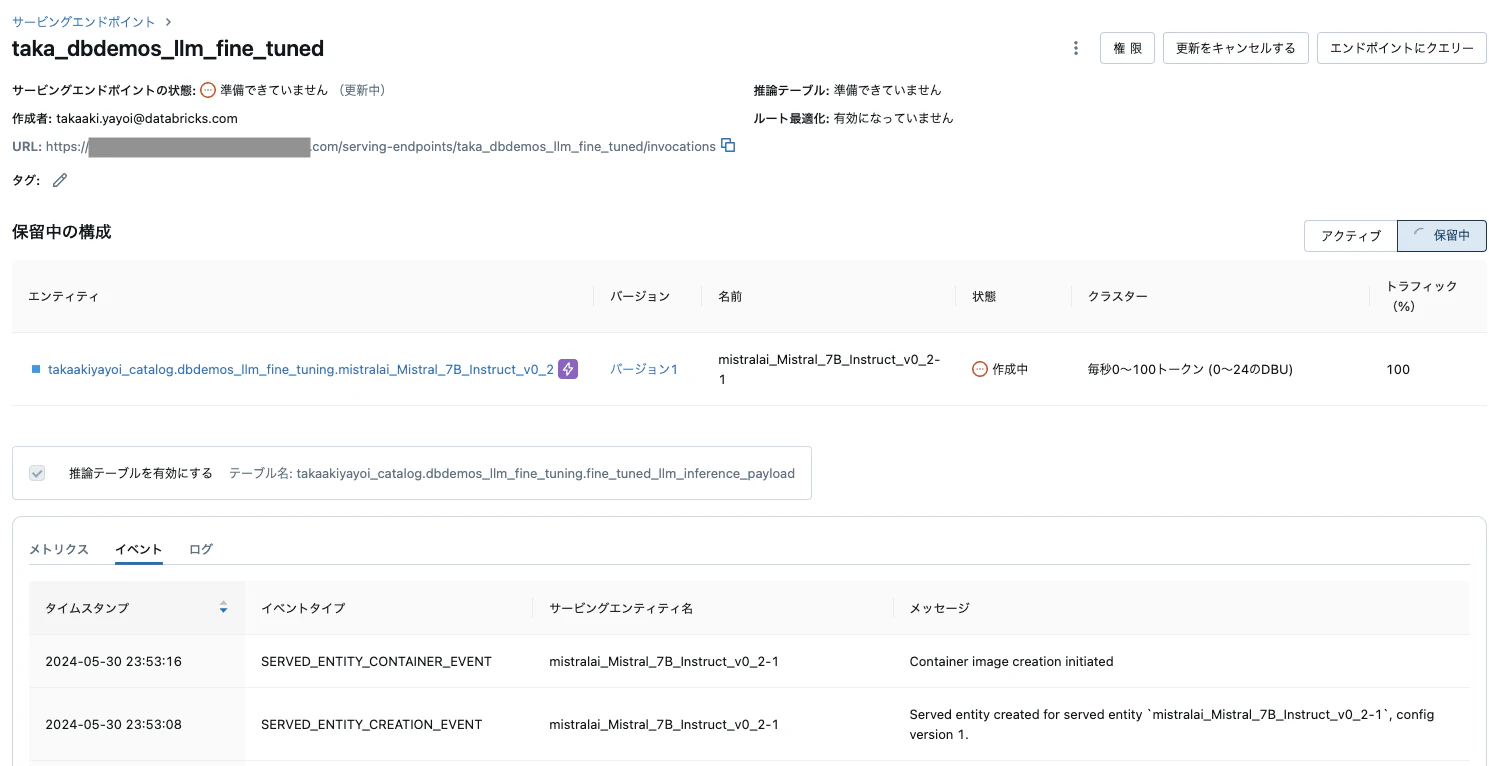
ランが完了すると、Unity Catalogに表示されます。
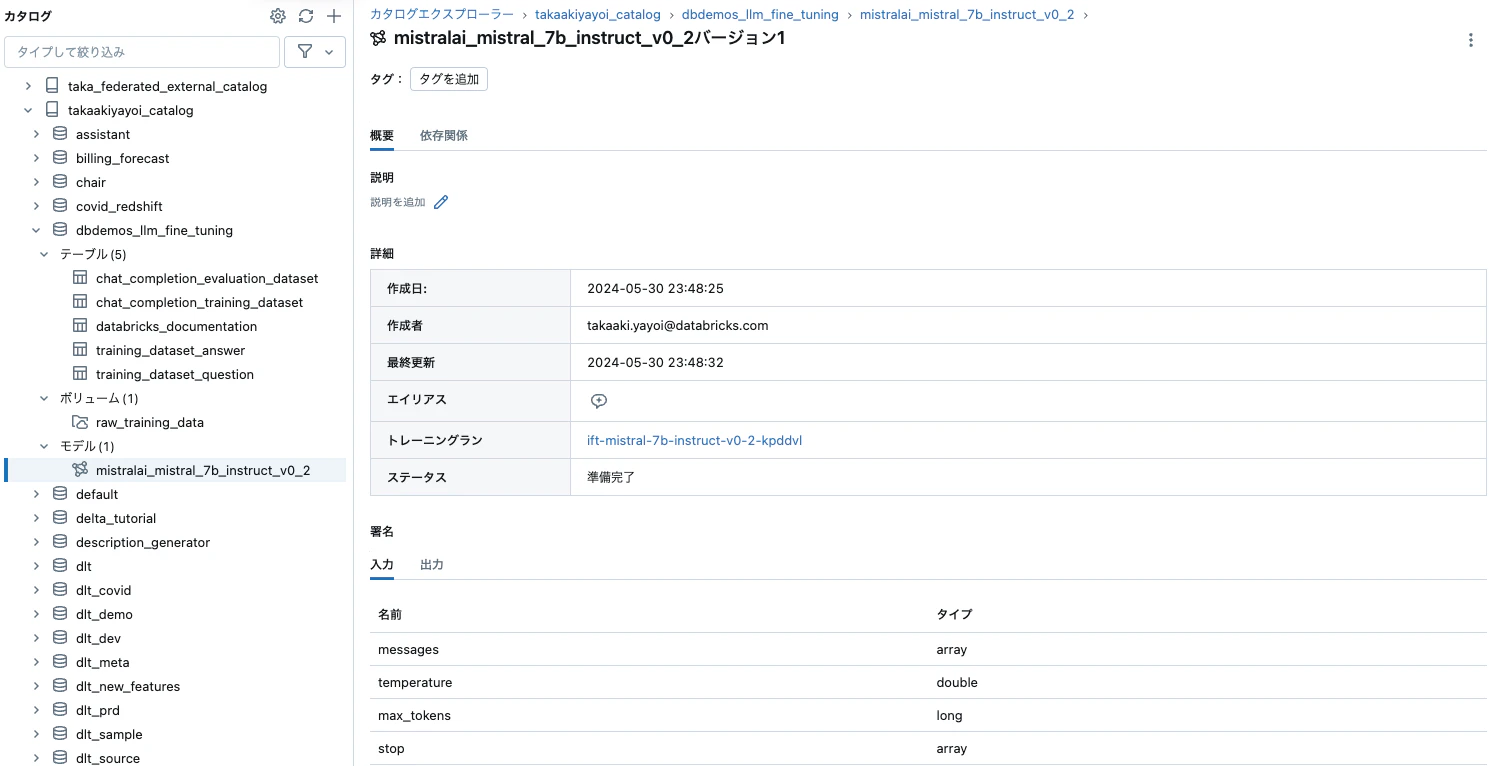
ここで使用しているアセットもUnity Catalogで管理されるのでテーブル間のリネージも確認できます。
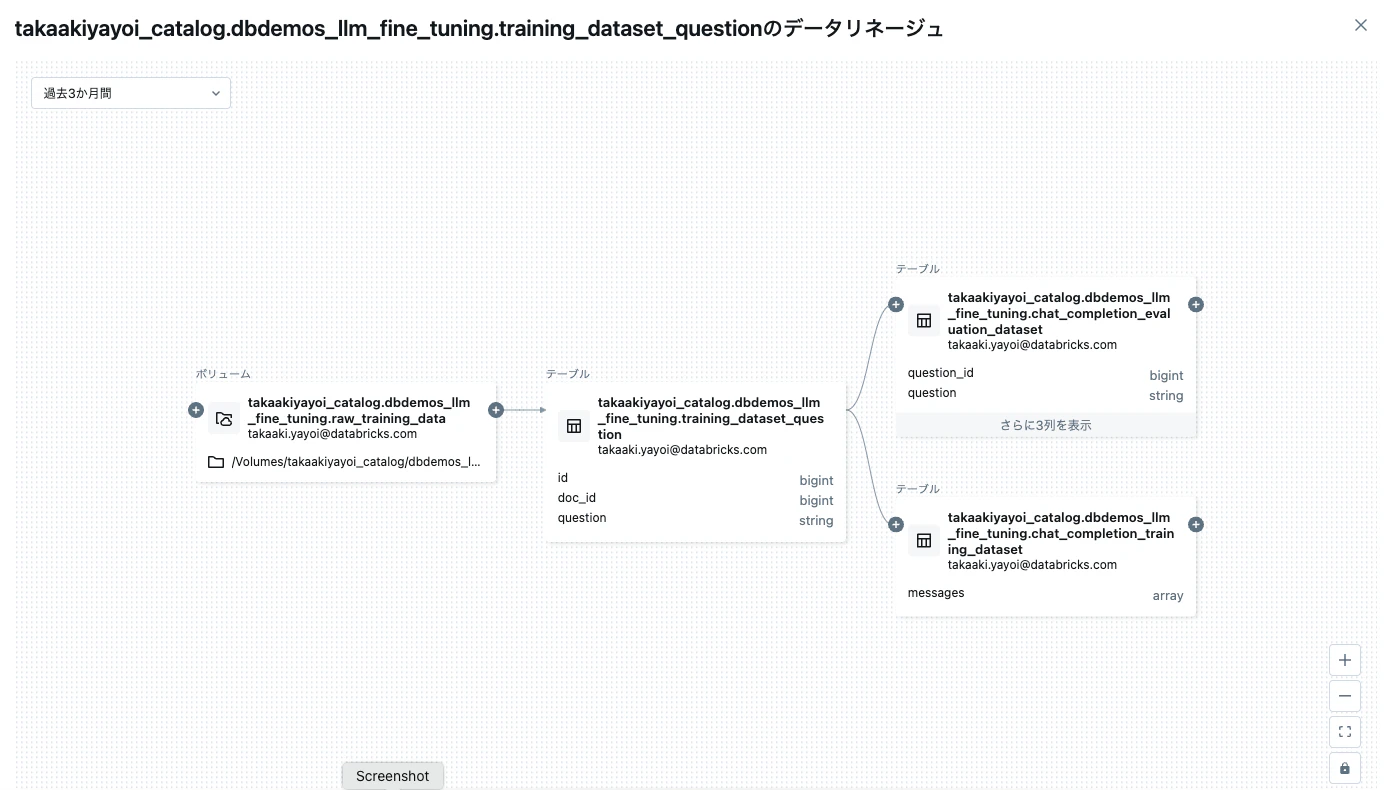
そして、エクスペリメントからはメトリクスを確認できます。
1.3) サービングエンドポイントにファインチューンしたモデルをデプロイ

準備ができると、Unity Catalogからモデルにアクセスできる様になります。
ここからは、モデルのデプロイにUIを使うか、APIを使うことができます。再現性のために下ではAPIを使っています:
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, AutoCaptureConfigInput
serving_endpoint_name = "taka_dbdemos_llm_fine_tuned" # エンドポイント名
w = WorkspaceClient()
endpoint_config = EndpointCoreConfigInput(
name=serving_endpoint_name,
served_entities=[
ServedEntityInput(
entity_name=registered_model_name,
entity_version=get_latest_model_version(registered_model_name),
min_provisioned_throughput=0, # エンドポイントがスケールダウンする最小秒間トークン数
max_provisioned_throughput=100,# エンドポイントがスケールアップする最大秒間トークン数
scale_to_zero_enabled=True
)
],
auto_capture_config = AutoCaptureConfigInput(catalog_name=catalog, schema_name=db, enabled=True, table_name_prefix="fine_tuned_llm_inference" )
)
force_update = False # 新規バージョンをリリースする際にはこれを True に設定(このデモではデフォルトで新規モデルバージョンにエンドポイントを更新しません)
existing_endpoint = next(
(e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None
)
if existing_endpoint == None:
print(f"Creating the endpoint {serving_endpoint_name}, this will take a few minutes to package and deploy the endpoint...")
w.serving_endpoints.create_and_wait(name=serving_endpoint_name, config=endpoint_config)
else:
print(f"endpoint {serving_endpoint_name} already exist...")
if force_update:
w.serving_endpoints.update_config_and_wait(served_entities=endpoint_config.served_entities, name=serving_endpoint_name)
エンドポイントがセットアップされます。デプロイが完了するまで待ちましょう。
1.4) モデルエンドポイントのテスト

これで全てです!ファインチューニングしたモデルをサービングし、質問できる準備が整いました!
我々のRAGチャットbotはDatabricksのドキュメントに特化し、整形されたアウトプットによって、レスポンスが改善されました!
import mlflow
from mlflow import deployments
# system + userロールのみを取得する様に回答を削除
test_dataset = spark.table('chat_completion_training_dataset').selectExpr("slice(messages, 1, size(messages)-1) as messages").limit(1)
# 最初のメッセージの取得
messages = test_dataset.toPandas().iloc[0].to_dict()['messages'].tolist()
client = mlflow.deployments.get_deploy_client("databricks")
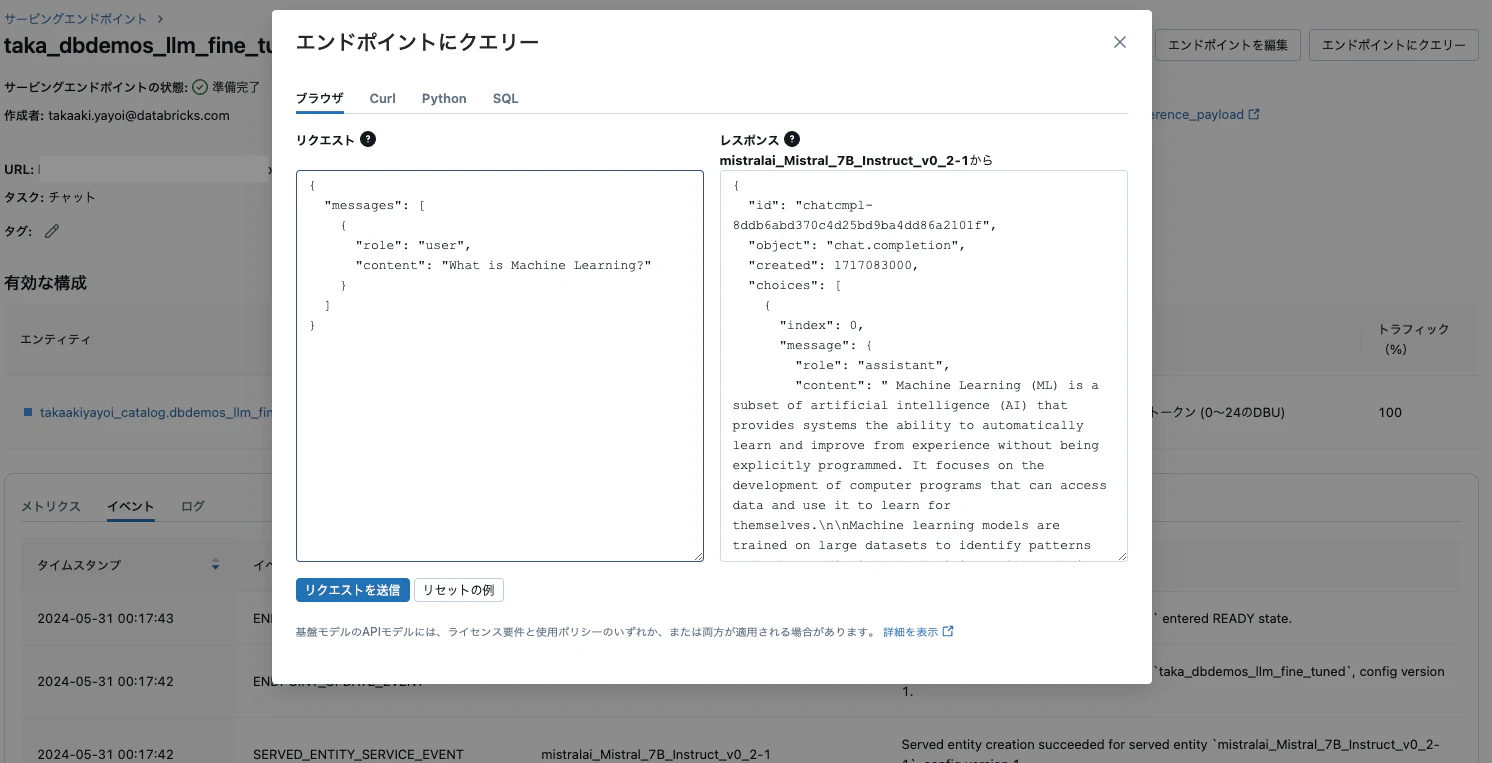
client.predict(endpoint=serving_endpoint_name, inputs={"messages": messages, "max_tokens": 100})
なお、上のmessagesはこちらとなっています。
[{'role': 'user',
'content': 'You are a highly knowledgeable and professional Databricks Support Agent. Your goal is to assist users with their questions and issues related to Databricks. Answer questions as precisely and accurately as possible, providing clear and concise information. If you do not know the answer, respond with "I don't know." Be polite and professional in your responses. Provide accurate and detailed information related to Databricks. If the question is unclear, ask for clarification.\n \nHere is a documentation page that could be relevant: stack table-valued generator function \nApplies to: Databricks SQL Databricks Runtime \nSeparates expr1, …, exprN into numRows rows. \nSyntax\nSyntax\nstack(numRows, expr1 [, ...] )\n\nArguments\nArguments\nnumRows: An INTEGER literal greater than 0 specifying the number of rows produced. \nexprN: An expression of any type. The type of any exprN must match the type of expr(N+numRows).\n\nReturns\nReturns\nA set of numRows rows which includes max(1, (N/numRows)) columns produced by this function. An incomplete row is padded with NULLs. \nBy default, the produced columns are named col0, … col(n-1). \nstack is equivalent to theVALUESclause. \nApplies to: Databricks Runtime 12.1 and earlier: \nstack can only be placed in the SELECT list as the root of an expression or following a LATERAL VIEW. When placing the function in the SELECT list there must be no other generator function in the same SELECT list or UNSUPPORTED_GENERATOR.MULTI_GENERATOR is raised. \nApplies to: Databricks SQL Databricks Runtime 12.2 LTS and above: \nInvocation from the LATERAL VIEW clause or the SELECT list is deprecated. Instead, invoke stack as a table_reference.\n\nExamples\nExamples\nApplies to: Databricks Runtime 12.1 and earlier: \n> SELECT 'hello', stack(2, 1, 2, 3) AS (first, second), 'world'; hello 1 2 world hello 3 NULL world > SELECT 'hello', stack(2, 1, 2, 3) AS (first, second), stack(2, 'a', 'b') AS (third) 'world'; Error: UNSUPPORTED_GENERATOR.MULTI_GENERATOR -- Equivalent usage of VALUES > SELECT 'hello', s1., s2., 'world' FROM VALUES(1, 2), (3, NULL) AS s1(first, second), VALUES('a'), ('b') AS s2(third); hello 1 2 a world hello 3 NULL a world hello 1 2 b world hello 3 NULL b world \nApplies to: Databricks SQL Databricks Runtime 12.2 LTS and above: \n> SELECT 'hello', s., 'world' FROM stack(2, 1, 2, 3) AS s(first, second); hello 1 2 world hello 3 NULL world > SELECT 'hello', s1., s2.*, 'world' FROM stack(2, 1, 2, 3) AS s1(first, second), stack(2, 'a', 'b') AS s2(third); hello 1 2 a world hello 3 NULL a world hello 1 2 b world hello 3 NULL b world\n\nRelated functions\nRelated functions\nexplode table-valued generator function \nexplode_outer table-valued generator function \ninline table-valued generator function \ninline_outer table-valued generator function \nposexplode_outer table-valued generator function \nposexplode table-valued generator function. Based on this, answer the following question: "How can I use thestackfunction to generate a set of rows with specified values in Databricks SQL Databricks Runtime?"'}]
質問自体は最後のHow can I use the stack function to generate a set of rows with specified values in Databricks SQL Databricks Runtime?です。
{'id': 'chatcmpl-cb4bc22462794cb9a16af12f98b7d76c',
'object': 'chat.completion',
'created': 1717083015,
'choices': [{'index': 0,
'message': {'role': 'assistant',
'content': ' You can use the `stack` function in Databricks SQL Databricks Runtime to generate a set of rows with specified values by providing the desired number of rows as an argument `numRows` and a list of expressions as arguments `exprN`. The function will return a set of `numRows` rows which includes max(1, (N/numRows)) columns produced by this function, with any incomplete row padded with NULLs. Here is an example:\n'},
'finish_reason': 'length',
'logprobs': None}],
'usage': {'prompt_tokens': 944,
'completion_tokens': 100,
'total_tokens': 1044}}
動いた!
サービングエンドポイントの画面でも動作確認できます。
次のステップ: ファインチューニングしたモデルの評価
いい感じです!シンプルなAPI呼び出しだけで我々のモデルをファインチューンしました。しかし、ベースラインモデルと比較してどれだけ改善しているのかをどの様に計測できるのでしょうか?
Databricksはこれも簡単にしてくれます!次のセクションでは、我々のチューニングランがどれだけ上手くいったのかを確認するために、ベースラインの基盤モデルに対してファインチューニングしたモデルを比較するMLflow Evaluateの機能を活用します。
新たなカスタムLLMをベンチマークするために02-llm-evaluationノートブックを開きましょう!
こちらに続きます。