Databricksではクラスターにノートブックをアタッチして処理を実行します。
再現性確保の観点では、ノートブックをどのような仕様のクラスターで実行したのかを記録しておくことが重要と言えます。
アタッチされているクラスターが存在しているのであれば、保存されている情報から追跡できなくはないですが、途中で設定が変更されてしまったり、クラスターが削除されてしまったりすると追跡は困難です。
ということで、ここではノートブックにクラスターの情報を埋め込むアプローチをご紹介します。Databricks SDK for Pythonを使って、アタッチしているクラスターの情報にアクセスします。
SDKのインストール
%pip install databricks-sdk --upgrade
dbutils.library.restartPython()
アタッチしているクラスターのID取得
SDKで使用するアタッチしているクラスターのIDを取得します。spark.conf経由で取得できます。
current_cluster_id = spark.conf.get("spark.databricks.clusterUsageTags.clusterId")
current_cluster_id
'0830-044559-343hcl1h'
クラスターの仕様へのアクセス
from databricks.sdk import WorkspaceClient
from pprint import pprint
# WorkspaceClient のインスタンスを作成
w = WorkspaceClient()
# 現在のクラスターの情報を取得
current_cluster = w.clusters.get(current_cluster_id)
# クラスターの情報を表示
pprint(vars(current_cluster))
ランタイムのバージョンspark_version、クラスター名cluster_name、アクセスモードdata_security_mode、ワーカーノード数num_workers(シングルノードはワーカー数0です)、インスタンスタイプnode_type_id、initスクリプトinit_scriptsなど、高度な設定含めたクラスターの情報を取得することができます。また、クラスター作成時にGUIから指定した内容にフォーカスするのであれば、'spec'にアクセスします。
{'autoscale': None,
'autotermination_minutes': 4320,
'aws_attributes': None,
'azure_attributes': AzureAttributes(availability=<AzureAvailability.ON_DEMAND_AZURE: 'ON_DEMAND_AZURE'>,
first_on_demand=1,
log_analytics_info=None,
spot_bid_max_price=-1.0),
'cluster_cores': 4.0,
'cluster_id': '0830-044559-343hcl1h',
'cluster_log_conf': None,
'cluster_log_status': None,
'cluster_memory_mb': 14336,
'cluster_name': "Takaaki Yayoi's Personal Compute Cluster",
'cluster_source': <ClusterSource.UI: 'UI'>,
'creator_user_name': 'takaaki.yayoi@databricks.com',
'custom_tags': {'ResourceClass': 'SingleNode'},
'data_security_mode': <DataSecurityMode.SINGLE_USER: 'SINGLE_USER'>,
'default_tags': {'ClusterId': '0830-044559-343hcl1h',
'ClusterName': "Takaaki Yayoi's Personal Compute Cluster",
'Creator': 'takaaki.yayoi@databricks.com',
'Vendor': 'Databricks',
'owner': 'xxxxx@databricks.com'},
'docker_image': None,
'driver': SparkNode(host_private_ip='xxx.xxx.xxx.xxx',
instance_id='7ec1d4d58fc04c12854282f329ba82e0',
node_aws_attributes=None,
node_id='6315c366f0704725b8a9fd0fedf6d8af',
private_ip='xxx.xxx.xxx.xxx',
public_dns='xxx.xxx.xxx.xxx',
start_timestamp=1724993301783),
'driver_instance_pool_id': None,
'driver_node_type_id': 'Standard_DS3_v2',
'enable_elastic_disk': True,
'enable_local_disk_encryption': False,
'executors': [],
'gcp_attributes': None,
'init_scripts': [],
'instance_pool_id': None,
'jdbc_port': 10000,
'last_restarted_time': 1724993497711,
'last_state_loss_time': 0,
'node_type_id': 'Standard_DS3_v2',
'num_workers': 0,
'policy_id': 'D96308F1BF0003A7',
'runtime_engine': <RuntimeEngine.STANDARD: 'STANDARD'>,
'single_user_name': 'takaaki.yayoi@databricks.com',
'spark_conf': {'spark.databricks.cluster.profile': 'singleNode',
'spark.master': 'local[*, 4]'},
'spark_context_id': 4577072528423978100,
'spark_env_vars': None,
'spark_version': '15.4.x-cpu-ml-scala2.12',
'spec': CreateCluster(spark_version='15.4.x-cpu-ml-scala2.12',
apply_policy_default_values=True,
autoscale=None,
autotermination_minutes=4320,
aws_attributes=None,
azure_attributes=None,
cluster_log_conf=None,
cluster_name="Takaaki Yayoi's Personal Compute Cluster",
cluster_source=None,
custom_tags=None,
data_security_mode=<DataSecurityMode.SINGLE_USER: 'SINGLE_USER'>,
docker_image=None,
driver_instance_pool_id=None,
driver_node_type_id=None,
enable_elastic_disk=None,
enable_local_disk_encryption=None,
gcp_attributes=None,
init_scripts=[],
instance_pool_id=None,
node_type_id='Standard_DS3_v2',
num_workers=0,
policy_id='D96308F1BF0003A7',
runtime_engine=<RuntimeEngine.STANDARD: 'STANDARD'>,
single_user_name=None,
spark_conf=None,
spark_env_vars=None,
ssh_public_keys=None,
workload_type=None),
'ssh_public_keys': None,
'start_time': 1724993160168,
'state': <State.RUNNING: 'RUNNING'>,
'state_message': '',
'terminated_time': None,
'termination_reason': None,
'workload_type': None}
取得できる情報に関しては、databricks.sdk.service.compute.ClusterDetailsをご覧ください。
クラスターライブラリ
以下のようにクラスターライブラリとしてインストールされたライブラリの情報にもアクセスできます。
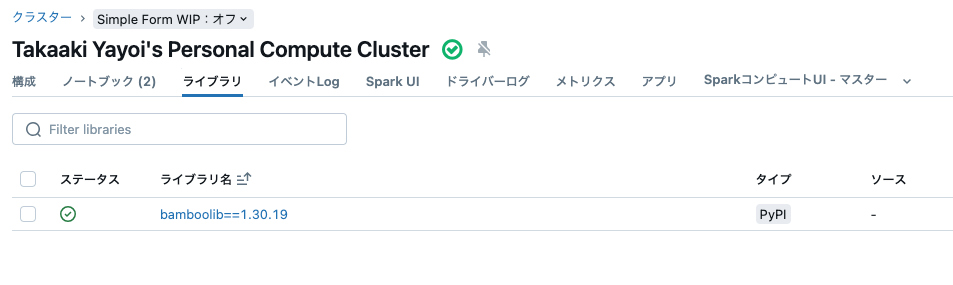
詳細はw.libraries: Managed Librariesをご覧ください。
installed_libraries = w.libraries.cluster_status(current_cluster_id)
for library in installed_libraries:
pprint(vars(library))
{'is_library_for_all_clusters': False,
'library': Library(cran=None,
egg=None,
jar=None,
maven=None,
pypi=PythonPyPiLibrary(package='bamboolib==1.30.19',
repo=None),
whl=None),
'messages': None,
'status': <LibraryFullStatusStatus.INSTALLED: 'INSTALLED'>}
出力はノートブックに埋め込まれる形になりますので、ノートブックを参照すれば確実なクラスターの情報にアクセスできることになります。ご活用ください!