こちらの記事がすごく勉強になりました。
LLaVAを触ったことはありましたが、モデルサービングエンドポイントにデプロイするにはどうしたらいいのか?と思っていたら、そのままズバリの記事でした。
説明されているノートブックを翻訳しながらウォークスルーしていきます。ありがとうございます。
DatabricksとLLaVAを用いたマルチモーダルAI
導入
人工知能(AI)は、近い将来、遠い将来の生活はどうなるのかと不思議に思うくらいに我々の探究心を刺激し、我々の想像力を掻き立てています。少なくともAIは私にはこのような効果をもたらしています。我々の脳にチップを埋め込むことになるのか?汎用人工知能(AGI)を発明することになるのか?AIの領域における全ての進化によって、逆説的ではありますがAGIは間も無くと感じつつも、現時点のものではないのでしょう。一つ確実に言えることは、ギャップを埋め続けることで、我々のAIシステムは、異なるモダリティを含む複数の外部刺激を同時に感知、処理すべきであるということです。
この記事では、特にマルチモーダルAIシステムの最近の生成AIの進化を活用することにフォーカスします。マルチモーダルAIモデルは、多くの場合、単一のモダリティで優れている二つのモデルを組み合わせます。マルチモーダルモデルの一例としてLLaVAにフォーカスします。このモデルがどのようにデザインされ、モデルがどのように動作するのか、このモデルで遊ぶためにどのようにDatabricksプラットフォームを活用できるのかを学びます。最初にLLaVAモデル自身を議論しましょう。
AIスペースの一般的なトピックに興味があるのであれば、AIのフォーカスしている他の記事をご覧ください: Object Detection with YOLOv8 on Databricks、Getting Started with OpenAI、Hands-on with Edge AI、Getting Started with Databricks。
LLaVAに関して
LLaVAはHuggingFaceにおいて、先月に300万ダウンロードされ、人気が爆発しています。このハイプは、OpenAIのGPT-4と同様のマルチモーダルの機能を導入するモデルファミリーとして保証されています。
LLaVAは、“Large Language and Vision Assistant”の略語であり、上で学んだように生成AIのマルチモーダルの能力を導入しました。しかし、これは何を意味するのでしょうか?この場合、LLaVAはタスクを実行するために二つのモデルを組み合わせています。視覚/画像データを解釈するビジョンエンコーダーと、テキストのパーシングや理解を行う大規模言語モデル(LLM)です。概念的には、LLaVAはここのモデルとは反対のフレームワークやアーキテクチャと考えることができます。実際、さまざまなモデル、パラメーター(7b、13b、34bなど)で置き換える無数の派生系が存在しています。
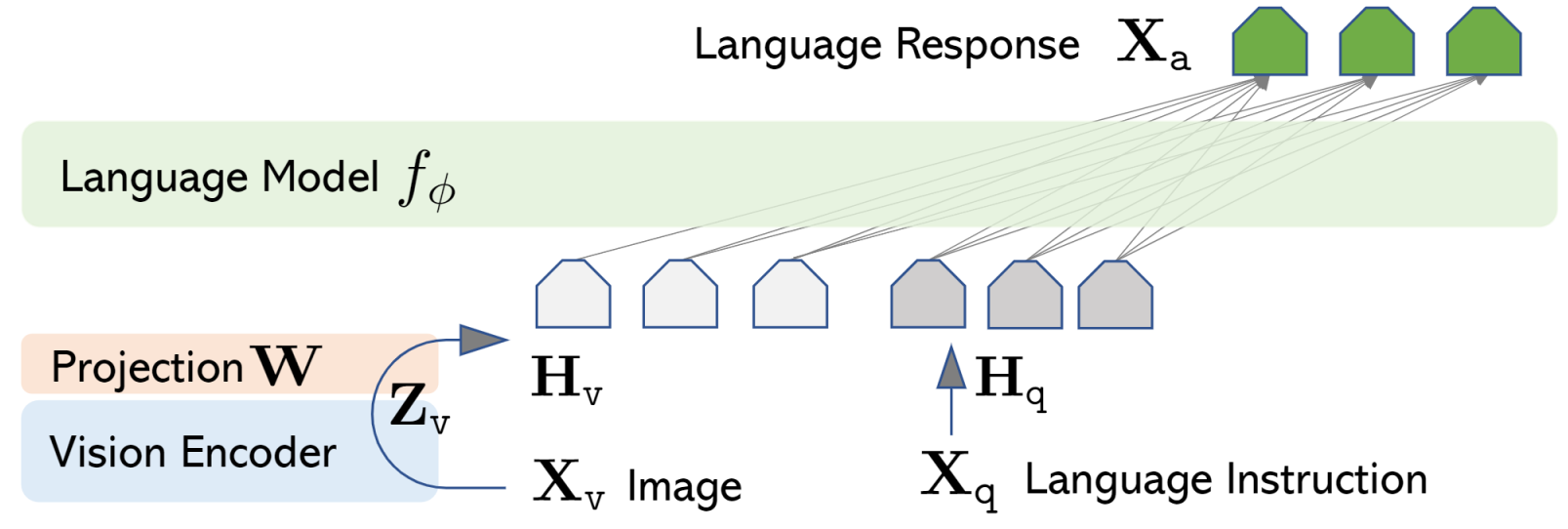
言語モデルとビジョンエンコーダーを示すLLaVAネットワークアーキテクチャ
もちろん、このネットワークアーキテクチャの汎化は、背後の複雑性を過小評価していますが、それはこの記事のスコープ外です。興味があるのであれば、arXivやHaotian Liu’s Github repoをご覧ください。
LLaVAウェブサイトでは、モデルとインタラクションするためのウェブアプリを提供しています。モデルに画像とテキストプロンプトをどのように与えているのかを見るためにスクリーンショットを見てみましょう。このモデルは、あなたが友達をつついて「いったいあそこで何が起きているんだ?」と言ったときのようなレスポンスを返してくれます。

画像とプロンプトをLLaVAに渡し、画像にある複雑性の理解をデモンストレーションするレスポンスを受け取っています(ソース: https://llava-vl.github.io/)
このモデルは、画像に含まれるシーンとアクションを解釈し、そしてプロンプトを理解します。これは複合モダリティの学習をデモンストレーションする興奮すべき機会です。しかし、現時点ではスタートするのに十分無情報を入手しました。これで、LLaVAが何を提供するのかを理解したので、このエクササイズでなぜDatabricksがプラットフォームと計算資源のプロバイダーとしての役割を担うのかをみていきましょう。
Databricksに関して
![]()
以前の記事で議論したように、Databricksはレイクハウスのアーキテクチャ/コンセプトの発明者であり、MIT Reviewによると、企業の74%が導入しているとのことです。また、Spark、Delta Lake、MLflowを含む、モダンデータアーキテクチャに含まれるテクノロジーのクリエーターでもあります。
Databricksを活用することで、構造化、半構造化、画像を含む非構造化データセットを取り扱うためのデータパイプラインを容易に構築することができます。データパイプラインや大規模なデータボリュームはこの生地の本題ではありませんが、このソリューションをスケールさせるための能力は、プロダクションのデータデプロイメントにおける重要な検討事項となります。さらに、Databricksを活用することで、データエンジニアリングのフォーカスと機械学習のフォーカスの間でシームレスにプロジェクトを移行することができます。新たに到着するデータに対応する必要がある場合には、このような機能が有用となります。Databricksでは、データエンジニアリング、データアナリティクス、データサイエンス、機械学習、人工知能プロジェクトのための長大な機能のリストがありますが、このLLaVAサンプルで特に使う機能は以下を含む数個となります:
-
GPU有効化クラスター(
transformersやtorchのように容易に外部からインポートできるライブラリを含む) - モデルトラッキング、評価、サービングのためのMLflow
- データとAIの統合ガバナンスのためのUntiy Catalog(我々のAIモデルの権限/アクセス管理を保証)
- Databricksボリューム(モデルチェックポイントのようなバイナリー/非テーブルデータの格納)
概要
このエクササイズでは、以下を探索します:
- LLaVAモデルとその能力
- Databricksプラットフォームのモデルを登録、サービングする能力
以前の記事では、比較的小さいチューニング用データセットに対するYOLOv8モデルのチューニングを見ました。この記事では、トレーニングやチューニングの要素を強調するのではなく、代わりに、AIモデルを活用するため実験トラッキング、モデル登録、モデルサービングのステップを見ていきます。これらのステップでは、MLflowを活用します。
より具体的には、以下のステップを完了することでAIモデルのエクササイズを達成します:
- HuggingFaceからLLaVAモデルを取得し、毎回のセッションで再ダウンロードを避けるために15GB程度のモデルをDatabricksのボリュームにキャッシュ
- モデルシグネチャと作成し、
mlflow.pyfuncモデルを記録するためにMLflowを活用し、DatabricksのUnity Catalogモデルレジストリに登録 - リアルタイムやバッチAI推論のためのモデルエンドポイントを作成するためにDatabricksを活用
それではダイブしましょう!
環境の設定
再現性と一般的な安定性のために、一貫性のあるパッケージバーションで環境を設定します。この記事の投稿時点で重要なパッケージのバージョンはtransformers==4.39.0, mlflow==2.11.3, tensorflow==2.16.1です。環境にバージョンの変更が反映されるようにpythonを再起動します。
%pip install --upgrade transformers==4.39.0 mlflow>=2.11.3 tensorflow==2.16.1 accelerate
dbutils.library.restartPython()
Hugging Faceへの認証
from huggingface_hub import notebook_login
# モデルにアクセスするために Huggingfaceに ログイン
notebook_login()
キャッシュロケーションの設定
大規模なモデルを取り扱うので、GPUのメモリーにモデルをロード、再ロードする必要がある場合に、不必要なダウンロードを回避し、モデルのチェックポイントに比較的クイックにアクセスできるようにしたいと考えます。環境変数を適切に設定するようにしましょう。この場合、Databricksのボリュームをキャッシュに指定します。
import os
os.environ["HF_HOME"] = "/Volumes/users/takaaki_yayoi/llava_test"
MLflowとモデル管理
これで、モデルとmlflowとtransformersの活用にフォーカスする第二セクションに到達しました。
モデル名とシグネチャ
MLflowの今後のリリースでは必須となるモデルのシグネチャを作成する必要があります。幸運なことに、mlflow.modelsは、サンプルのモデルの入出力やスキーマからシグネチャを推定することで、これをシンプルにしてくれます。ここでは後者を採用します。入力として2つの文字列を送信します。一つは画像のURLで、もう一つはプロンプトです。出力として一つの文字列を受け取ります。我々のサンプルには配列に含まれる二つの例があることに注意してください。
model_id = "llava-hf/llava-v1.6-mistral-7b-hf"
import numpy as np
from mlflow.models import infer_signature
# シグネチャ
signature = infer_signature(
model_input=np.array(
[
["<Some URL 1>", "<Some instruction 1>"],
["<Some URL 2>", "<Some instruction 2>"],
]
),
model_output=np.array(
[
["<Sample output 1>"],
["<Sample output 2>"]
]
),
)
モデルのロギング
次のタスクは少々複雑です。まず、LLaVAモデルの活用をスムーズにするtransformersライブラリを取り扱うところからスタートします。さらに、トラッキングの目的でモデルを記録するためにmlflowを活用します。以下に、このステップにおける幾つかの重要事項を示します:
-
.from_pretrained()の呼び出しでは、キャッシュからモデルをロードするようにcache_dirを指定しています。これを適切に設定しないと、モデルのダウンロードが開始されます(約15GB!)。 -
mlflow.pyfunc.PythonModelを継承するModelというクラスを定義します。 - 我々のクラスの
.predict()メソッドは、入力を受け取り手順に従って結果を処理します。これは、さらに最適化することもできます。 - モデルを記録するために
mlflow.start_run()とmlflow.pyfunc.log_model()を呼び出し、このプロセスで依存関係が失われないようにするために特定のpip_requirements=[…]を指定しています。
import mlflow
import pandas as pd
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
from PIL import Image
import requests
class Model(mlflow.pyfunc.PythonModel):
def __init__(self):
self.processor = LlavaNextProcessor.from_pretrained(model_id)
self.model = LlavaNextForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
cache_dir="/Volumes/users/takaaki_yayoi/llava_test")
self.model.to("cuda:0")
def predict(self, context, model_input):
processor = self.processor
model = self.model
results = []
for mi in model_input:
img_url = mi[0]
prompt = mi[1]
image = Image.open(requests.get(img_url, stream=True).raw)
# Prepare inputs
inputs = processor(prompt, image, return_tensors='pt').to(0, torch.float16)
# Generate and store response
output = model.generate(**inputs, max_new_tokens=150, do_sample=False)
result = (processor.decode(output[0], skip_special_tokens=True))
results.append(result)
return results
# 関数をモデルとして保存
with mlflow.start_run():
mlflow.pyfunc.log_model(
"model",
python_model=Model(),
pip_requirements=['transformers==4.39.0', 'mlflow==2.11.3', 'tensorflow', 'torch', 'Image', 'requests'],
signature=signature
)
run_id = mlflow.active_run().info.run_id
この時点で、LLaVAモデルがHuggingFaceから取得され、Databricksボリュームにキャッシュされ、依存関係とともにMLflowに記録されるので、エンドポイントの設定と推論に進む準備ができたことになります!
エンドポイントと推論
この時点で、モデルを推論することができます。しかし、思い出してください、我々のゴールは単に推論することではなく、これ以降も推論できるようにするための再利用可能なインフラストラクチャをセットアップし、モデルの重みの変更のためのアップデート、ドリフトを検知するために結果をモニタリングできるようにすることなどを可能にすることです。
このことを念頭に置き、モデルサービングエンドポイント(縮めてエンドポイント)をセットアップします。Databricksモデルサービングを用いることで、比較的簡単にこれを行うことができます。
モデルの登録
最初にモデルを登録します。モデルに後でシームレスに権限を適用できるようにするために、Unity Catalogのモデルレジストリを活用します。カタログ名、スキーマ名、モデル名を指定する必要があります。また、mlflow.set_registry_uri()に“databricks-uc”を指定することで、DatabricksのUCレジストリを使うということを指定します。モデルを登録すると、あとでバージョン番号を特定する際に使うモデルオブジェクトを受け取ります。
import mlflow
catalog_name = "users"
schema_name = "takaaki_yayoi"
model_name = "llava_1-6"
mlflow.set_registry_uri("databricks-uc")
model_version_obj = mlflow.register_model(
model_uri=f"runs:/{run_id}/model",
name=f"{catalog_name}.{schema_name}.{model_name}"
)
モデルエンドポイントの作成
次に、現在MLflowに登録されているモデルをサービングするためのエンドポイントを作成する必要があります。create_endpoint()にモデルの詳細を指定し、workload_typeをGPU_MEDIUMとして含めた設定を提供します。この設定によって、モデルエンドポイントがGPU機能(A10)を持つようになります。
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="llava-model-endpoint",
config={
"served_entities": [
{
"name": "llava-model-endpoint",
"entity_name": f"{catalog_name}.{schema_name}.{model_name}",
"entity_version": f"{model_version_obj.version}",
"workload_type": "GPU_MEDIUM",
"workload_size": "Small",
"scale_to_zero_enabled": False
}
]
}
)
このプロセスは数分を要し、GPUやtensorflowやtorchのような重量級のライブラリを必要とするモデルでは、モデルエンドポイントのデプロイに最大1時間を要することがあります。Databricksを用いることで、モデルエンドポイントのデプロイメントのステータスをチェックするために、UI上のログやAPIを活用することができます。
モデルの準備ができたら、推論ができます!モデルエンドポイントに対するシンプルなRESTコールでこれを行うことができます。ここでは、セキュリティ上の理由からURLは表示していませんが、このエンドポイントはRESTコールを受け取り、結果を含むレスポンスを返却します。ユーザーがマルチモーダルモデルを活用できるようにするために、これと、StreamlitやGradio、その他のアプリと組み合わせることができます!
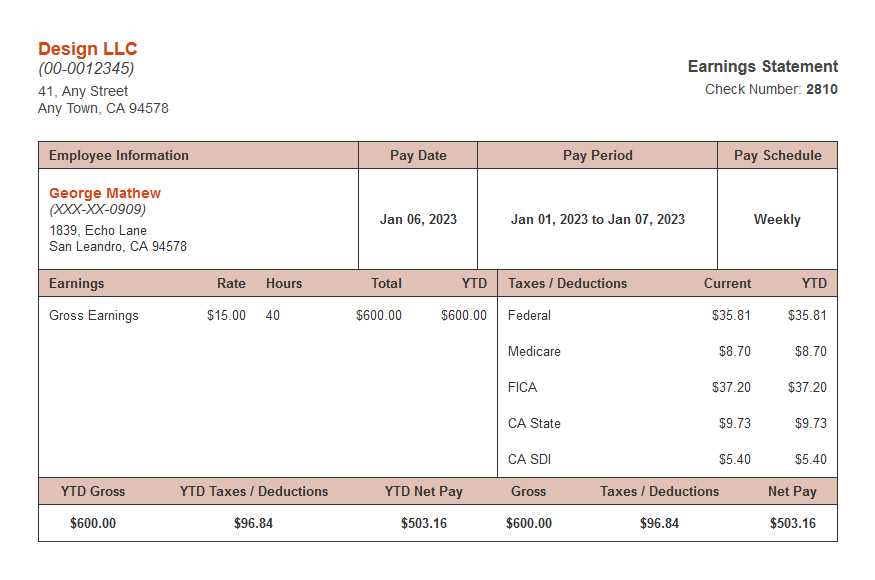
テキストのプロンプトと画像の入力を持つことで有益となるユースケースは多数存在します。試しに一つピックアップしてみます。我々のモデルがサンプルの小切手から情報を抽出できるかどうかをみてみましょう。これは、ドキュメント重視のワークロードの自動化やOCRパフォーマンスの改善で有益です。
import mlflow
catalog_name = "users"
schema_name = "takaaki_yayoi"
model_name = "llava_1-6"
from mlflow.deployments import get_deploy_client
client = get_deploy_client("databricks")
endpoint = client.create_endpoint(
name="llava-model-endpoint",
config={
"served_entities": [
{
"name": "llava-model-endpoint",
"entity_name": f"{catalog_name}.{schema_name}.{model_name}",
"entity_version": 1,
"workload_type": "GPU_MEDIUM",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]
}
)
しばらくすると、モデルサービングエンドポイントが起動します。

import requests
import json
img_url = "https://www.securepaystubs.com/assets/images/templates/classic/meadow-paystub.png"
prompt = '[INST] <image>\nPlease extract the employee name, employee address, and check number in the following JSON format: {"emp_name": <Employee Name>, "emp_address": <Employee Address>, "check_no": <Check Number>}. Please fill in the fields delimited by <>[/INST]'
data = {
"inputs": [(img_url, prompt)]
}
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().getOrElse(None)
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(
url="https://xxxx.databricks.com/serving-endpoints/llava-model-endpoint/invocations", json=data, headers=headers
)
print(json.dumps(response.json()))
HTTPリクエストを構築し、ペイロードの一部として小切手の画像とプロンプトを指定すると、レスポンスを受け取ります。こちらが、DatabricksモデルサービングによってサービングされるLLaVAモデルからのレスポンスです。
{"predictions": ["[INST] \nPlease extract the employee name, employee address, and check number in the following JSON format: {\"emp_name\": <Employee Name>, \"emp_address\": <Employee Address>, \"check_no\": <Check Number>}. Please fill in the fields delimited by <>[/INST] {\"emp_name\": \"George Matthew\", \"emp_address\": \"1839 Echo Lane, San Leandro, CA 94578\", \"check_no\": \"2810\"} "]}
訳者註
日本語でも動作します。
import requests
import json
img_url = "https://www.ibarakiguide.jp/data/photo_library/01-004-01Z.jpg"
prompt = '[INST] <image>\n画像にある場所を初めて訪れたものとして、感想を述べてください。[/INST]'
data = {
"inputs": [(img_url, prompt)]
}
API_TOKEN = dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().getOrElse(None)
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
response = requests.post(
url="https://xxxx.databricks.com/serving-endpoints/llava-model-endpoint/invocations", json=data, headers=headers
)
print(json.dumps(response.json(), ensure_ascii=False))

{"predictions": ["[INST] \n画像にある場所を初めて訪れたものとして、感想を述べてください。[/INST] この画像は、私が初めて訪れた場所です。\n\nこの画像は、日本の春の景色を表しています。樹の花が咲いていることから、春の季節です。樹の花は、紅色であり、広く開いています。その中に、日の光が洗り、水面に反映されています。\n\nこの場所は、湖の岸にあり、湖の中には、船が泊"]}
レスポンスのみの抜粋。
この画像は、私が初めて訪れた場所です。この画像は、日本の春の景色を表しています。樹の花が咲いていることから、春の季節です。樹の花は、紅色であり、広く開いています。その中に、日の光が洗り、水面に反映されています。この場所は、湖の岸にあり、湖の中には、船が泊
やりました!追加のトレーニングやファインチューニングをしていないLLaVAモデルは、モックの小切手から氏名、住所、小切手番号を抽出することができています。さらに、このモデルは適切なJSONを返却していることに注意してください。もちろん、より細かくみていけば、このモデルはこのタスク以上のことを実行することができるのです!
まとめと次のステップ
依然として勢いを見せ続けている生成AIのブームを目撃することは、十年以上技術業界にいる人であっても驚きを感じることです。マルチモーダルAIの進化の最近の波は、AIのルセっサンスが継続するという楽観主義を生み出しています。疑うことないことですが、両方のモダリティを犠牲にすることなく複数のモダリティをサポートするモデルを開発することは、人工汎用知能(AGI)に向けてデータとAIの領域を前進させることになります。
この記事でカバーしたことを振り返りましょう。多くのことを行いました。マルチモーダルAIであるLLaVAモデルアーキテクチャや、Databricksのデータインテリジェンスプラットフォームを学び、DatabricksとMLflowを通じてLLaVAをデプロイしました。Databricksモデルサービングエンドポイント経由でデプロイされた我々のLLaVAモデルは、テキストと画像のプロンプトを与えられると、高い精度とスピードで結果を返却しました。これまでに参照していない画像から比較的簡単にテキストを抽出しました。このプロセスの美しいところは、モデルは抽象化されているので、技術が進歩したら、モデルを切り替えたり、キャッシュ、登録などを行えるということです。あるいは、ユースケースが変化した際には、プロンプトやモデルシグネチャを変更・適応させることができます。