本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
Delta Lake 1.1はマージオペレーションの性能を改善し、ジェネレーテッドカラムのサポートを追加し、ネストされたフィールドの解決を改善します。
オープンソースコミュニティの多大なる貢献により、Delta Lakeコミュニティは最近Apache Spark™ 3.2におけるDelta Lake 1.1.0のリリースを発表しました。Apache Sparkと同様に、Delta LakeコミュニティはScala 2.12とScala 2.13向けのMavenアーティファクトとPyPI (delta_spark)をリリースしました。
このリリースには、MERGEオペレーション、ネストされたフィールドの解決周りの特筆すべき改善とPython型ノーテーション、replaceWhereにおける任意表現などが含まれています。Delta LakeがApache Sparkのインベーションに対して最新の状態を保つことが非常に重要です。これは、Spark Release 3.2.0で利用できる機能を用いて、Delta Lakeで更なるパフォーマンスのメリットを享受できることを意味します。
本記事においては、新たな1.1.0リリースにおいて特筆すべき機能と主要な変更をカバーします。詳細はproject’s Github repositoryをチェックしてください。
すぐにDelta Lakeを試したいですか?Delta Lakeが何であるかを学び、Delta Lakeを用いてレイクハウスを構築するにはこちらのガイドを活用してください。
Delta Lake 1.1の主要機能
- MERGEオペレーションにおける性能改善: パーティション化されたテーブルにおいて、MERGEオペレーションはファイルを書き出す前に自動で出力データの再パーティションを行います。これにより、MERGEオペレーションと後続の読み取りオペレーションにおけるアウトオブボックスの優れたパフォーマンスを提供します。
- DataFrameReader/WriterオプションによるHadoop設定のサポート: DataFrameReader/WriterのオプションとしてHadoop FileSystemの設定(アクセス認証情報など)を行うことができます。これまでは、このような設定を指定するには、全ての読み書きに適用されるSparkセッション設定に引き渡すしか選択肢がありませんでした。これにより、今では読み取り、書き込みそれぞれに異なる値を設定することができます。詳細はドキュメントを参照ください。
- DataFrameWriterオプションのreplaceWhereにおける任意表現のサポート: パーティションカラムのみに対する表現の代わりに、DataFrameWriterオプションのreplaceWhereで任意の表現を用いることができます。これは、データフレームの書き込みで直接テーブルのデータを好きなように置き換えることができることを意味します。
- ネストされたフィールド解決の改善、struct配列に対するMERGEオペレーションにおけるスキーマ進化: ネストされたstructの配列として型が定義されたカラムを持つターゲットテーブルに対してMERGEオペレーションを適用する際、ソース、ターゲットデータ間のネストされたカラムは、struct内の位置ではなく名前によって解決されます。これにより、配列ないのstructは、配列外のstructと一貫性のある挙動をします。MERGEに対して自動スキーマ進化が有効化されると、structのネストされたカラムは、配列外のstrcutのカラムとして同じ進化ルールに従います(例:テーブルに同じ名前のカラムが存在しない場合に追加)。詳細はドキュメントを参照ください。
- MERGEオペレーションにおけるジェネレーテッドカラムのサポート: ジェネレーテッドカラムを持つテーブルに対してMERGEオペレーションを適用することができます。
- GCSにおける稀に起きるデータ破壊の修正: Delta Lake 1.0の実験的GCSサポートにおいては、部分的に書き込まれたトランザクションログによりDeltaテーブルが読み込めなくなると言う稀なバグが存在していました。この問題が修正されました(1、2)。
- Python DeltaTable.convertToDelta()で不適切な型のオブジェクトを返却するバグの修正: 不適切な型のオブジェクトを返却し利用できなかったAPIが、適切なdelta.tables.DeltaTable型のPythonオブジェクトを返却するようになりました。
- Python型アノテーション: 型ヒントをサポートするエディタにおけるオートコンプリートの性能を改善するPython型アノテーションを追加しました。オプションとして、mypyやビルトインツール(Pycharmツールなど)における静的なチェックを有効化することができます。
Delta 1.1.0における他の特筆すべき機能は以下の通りとなります。
- パーティションカラム名に特殊文字を含むテーブルの読み込みサポートを削除。詳細はmigration guideをご覧ください。
- 他のAPIとの一貫性のために、DeltaTable.forName()の"delta.
path"をサポート - Delta 1.0.0で導入されたDeltaTableBuilder APIの改善
- 一時ビューにおけるMERGE/UPDATE/DELETEサポートの改善
- テーブル作成、置換時のコミット情報でユーザーメタデータをサポート
- 自動隙間エボリューションが有効化され、複数のINSERT、UPDATE句を伴うMERGEを行う際の不適切な分析例外の修正
- MERGE/UPDATE/DELETEオペレーションにおけるパス(スペースなど)の特殊文字の不適切な取り扱いの修正
- Apache Spark 3.2でデフォルトで有効化されたAdaptive Query Executionによって影響を受けるVacuum並列モードの修正
- 最新の適切なタイムトラベルバージョンに関する修正
- チェックポイントを書き込む際にHadoop設定が使用されないバグの修正
- Delta制約に対する複数の修正(1、2、3)
次のセクションでは、本リリースで最も特筆すべき機能にディープダイブしていきましょう。
MERGEオペレーションに対するアウトボックスの優れたパフォーマンス
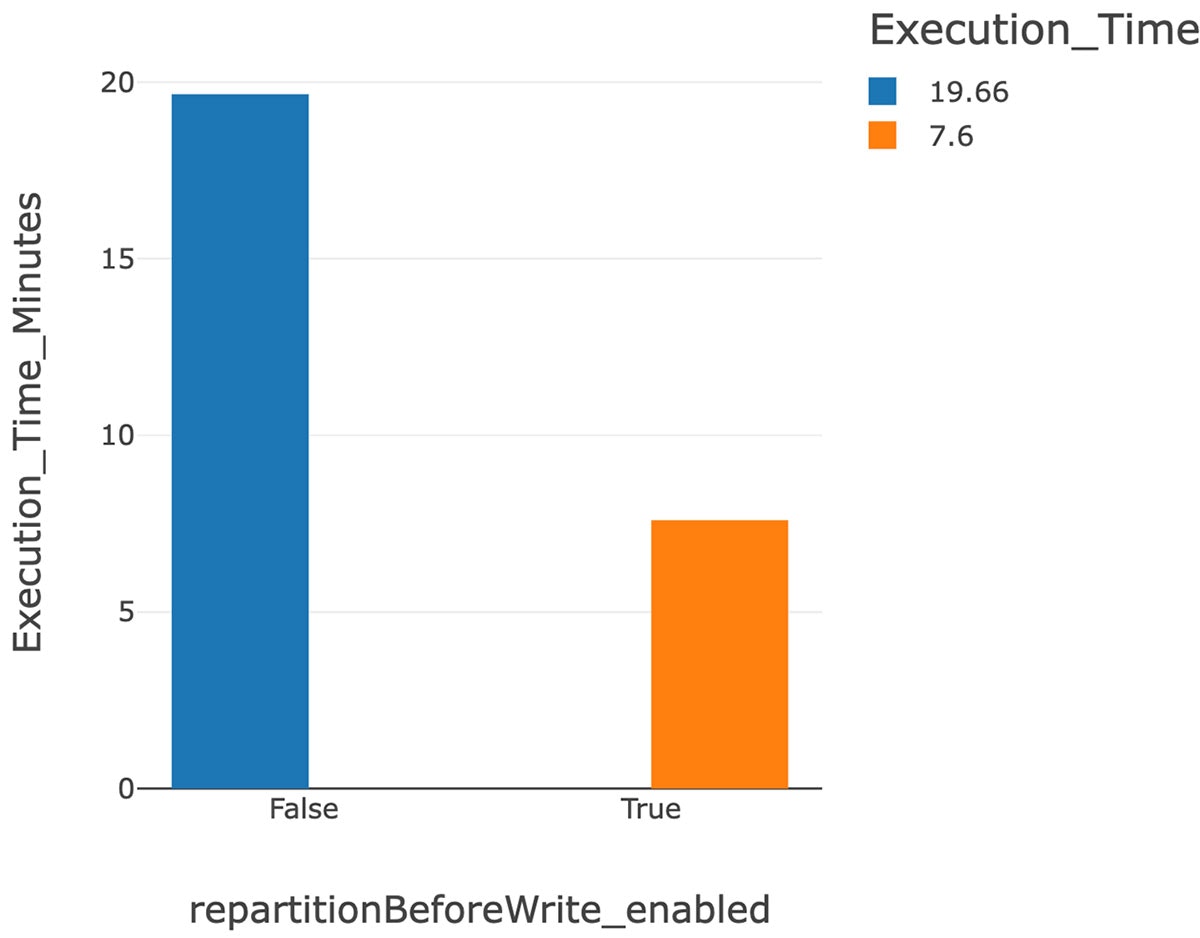
- 上のグラフは機能フラグを有効化することで、19.66分(有効化前)から7.6分(有効化後)に、実行時間を劇的に削減したことを示しています。
- 以下に示すクエリー前後のDAGビジュアライゼーションのステージの違いに注意して下さい。SortMergeJoinの後にAQE ShuffleReadステージが追加されています。
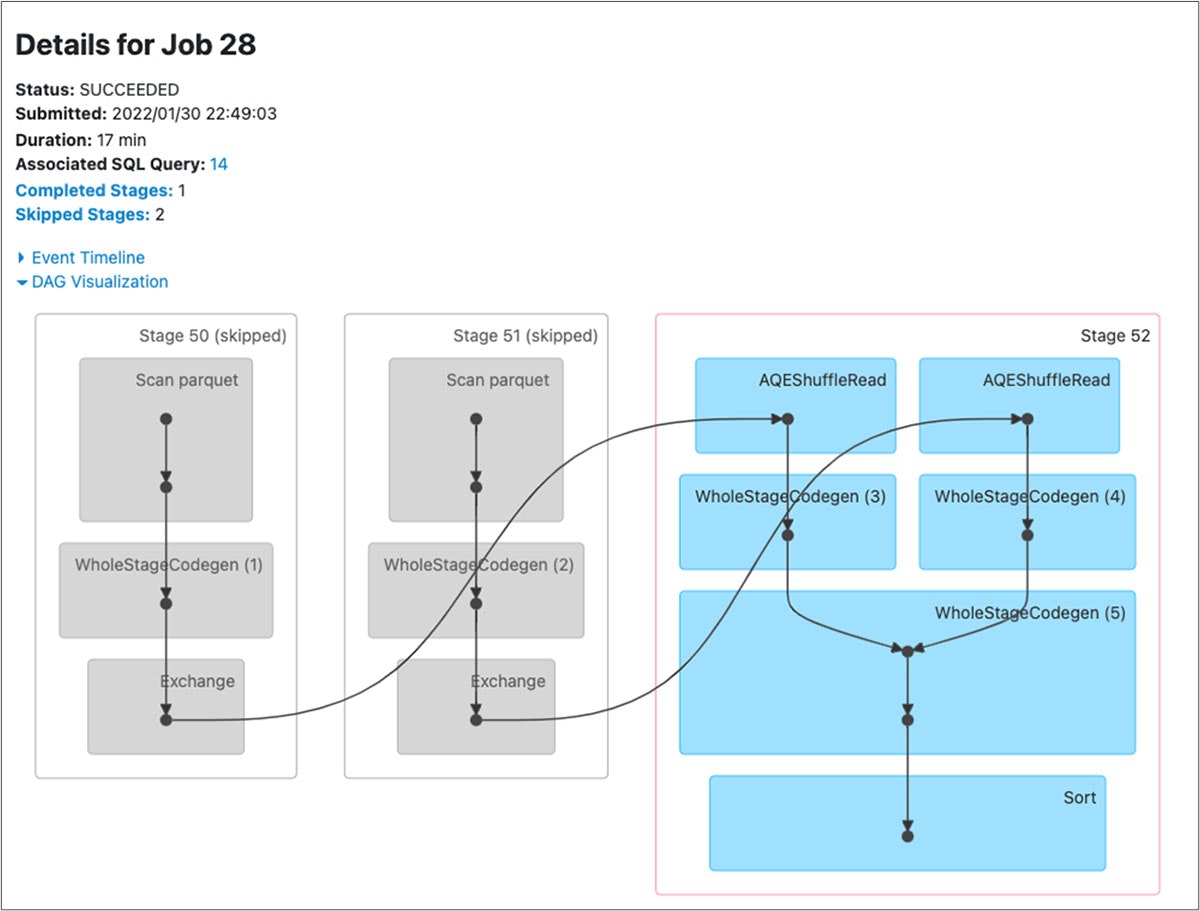
図: repartitionBeforeWriteが無効化された状態でのdelta mergeのクエリーに対するDAG
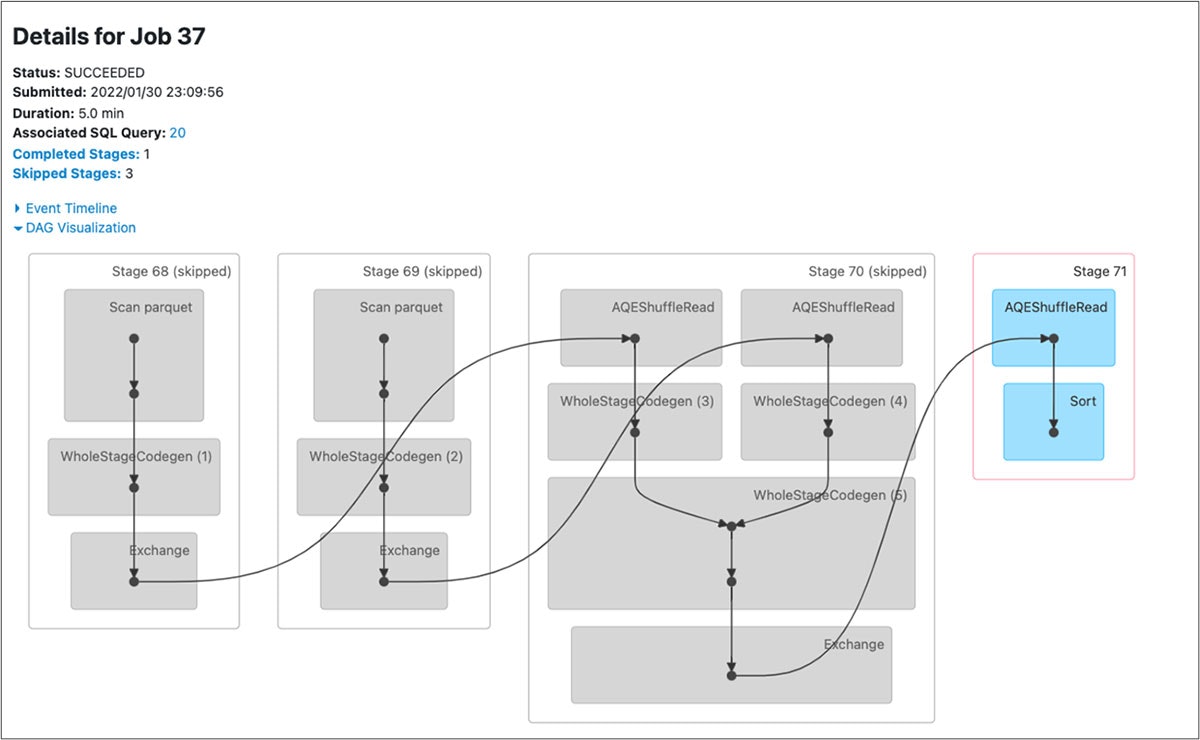
図: repartitionBeforeWrite](https://databricks.com/blog/2022/01/31/make-your-data-lakehouse-run-faster-with-delta-lake-1-1.html)が有効化された状態でのdelta mergeのクエリーに対するDAG
このサンプルを見ていきましょう。
この例で使われたデータセットでは、customers1とcustomers2は顧客と売り上げに関する200,000行と11列のデータを保持しています。必要最小限のデータに対してMERGEオペレーションを実行する際にフラグを有効化することによる違いを示すために、Macbook Pro 2019ラップトップ上のSparkのジョブを1GBのメモリーと1コアに限定しました。使用するRAMとコアを調整することで、これらの数値はさらに削減される可能性があります。MERGEテーブルにおいては、事前のテーブルにMERGEオペレーションを実行するために、45,000行のcustomers_mergeが使用されます。このサンプルの完全なスクリプトと結果はこちらから参照できます。
機能が無効化されていることを確認してから、以下のコマンドを実行してください。
sql(”SET spark.databricks.delta.merge.repartitionBeforeWrite.enabled = false”)
コードは以下の通りとなります。
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/temp/data/customers1")
mergeDF = spark.read.format("delta").load("/temp/data/customers_merge")
deltaTable.alias("customers1").merge(mergeDF.alias("c_merge"),"customers1.customer_sk = c_merge.customer_sk").whenNotMatchedInsertAll().execute()
結果
注意
機能フラグを無効にするとオペレーション全体は19.66分かかります。 クエリーの詳細に関しては、こちらの完全な結果を参照することができます。
![]()
パーティション化されたテーブルに対しては、MERGEはシャッフルパーティションの数より多い数の小さいファイルを生成する場合があります。これは、それぞれのシャッフルタスクが複数のパーティションに複数のファイルを書き込むことによるものであり、パフォーマンス上のボトルネックとなり得ます。パーティション化されたテーブルに対するMERGEオペレーションを高速化するには、以下のコードスニペットを使用する前にrepartitionBeforeWriteを有効化しましょう。
フラグを有効にして再度MERGEを実行
sql(”SET spark.databricks.delta.merge.repartitionBeforeWrite.enabled = true”)
これにより、MERGEオペレーションがファイルを書き込む前にパーティション化されたテーブルの出力データを自動で再パーティショニングします。これは多くの場合、書き込みを行う前にテーブルのパーティションカラムによる出力データの再パーティションの役に立ちます。これによって、MERGEオペレーションと後続の読み取りオペレーションの両方に対してアウトボックスの優れたパフォーマンスを提供します。それではcustomer_t0テーブルにMERGEオペレーションを実行してみましょう。
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/temp/data/customers2")
mergeDF = spark.read.format("delta").load("/temp/data/customers_merge")
deltaTable.alias("customers2").merge(mergeDF.alias("c_merge"),"customers2.customer_sk = c_merge.customer_sk").whenNotMatchedInsertAll().execute()
注意
「repartitionBeforeWrite」機能を有効化した後は、MERGEクエリーの処理時間は7.68分となります。クエリーの詳細はこちらから参照できます。
ティップ
GDPRやCCPAのユースケースに関わっている企業においては、お使いのデータレイクの再構成を行うことなしにコスト効率が高い方法で特定の場所の高速アップデート、高速削除が可能になるので、この機能が非常に役立ちます。
DataFrameWriterオプションのreplaceWhereにおける任意の表現のサポート
原子的にテーブルの全てのデータを置換するには上書きモードを使用します。
INSERT OVERWRITE TABLE default.customer_t10 SELECT * FROM customer_t1
Delta Lake 1.1.0以降では、データフレームを用いて任意の表現とマッチするデータのみを選択的に上書きすることができます。以下のコマンドは、c_birth_yearでパーティショニングされ、customer_t1にデータを持つターゲットテーブルの生年が1924であるレコードのみを原子的に置き換えます。
input = spark.read.table("delta.`/usr/local/delta/customer_t1`")
input.write.format("delta") \
.mode("overwrite") \
.option("overwriteSchema", "true") \
.partitionBy("c_birth_year") \
.option("replaceWhere", "c_birth_year >= '1924' AND c_birth_year <= '1925'") \
.saveAsTable("customer_t10")
このクエリーの実行は成功し、以下のアウトプットが得られます。

しかし、1.1.0より前の過去のDelta Lakeリリースでは、同じクエリーは以下のエラーとなります。

replaceWhereフラグを無効化することでこれを試すことができます。
Python型アノテーション
Python型アノテーションは、型ヒントをサポートするエディタにおけるオートコンプリートの性能を改善します。オプションとして、mypyやビルトインツール(Pycharmツールなど)を通じた静的チェックを有効化することができます。PRのオリジナルオーサーであるMaciej Szymkiewiczによる動画では、Delta Lake 1.1におけるPythonの挙動の変化を説明しています。
この記事を通じてクールなDelta Lakemの機能を見ていただけたと思います。皆様がこれらの機能を活用している様子を見ることができたら非常に嬉しいですし、もしフィードバックや、成果物のサンプルなどがありましたらコミュニティでシェアしてください。
まとめ
レイクハウスはデータプラットフォーム、データアーキテクチャを構築したいと考えている組織における新たな標準となりました。そして、これは全て、5000以上の企業がデータとAIアプリケーションに対するプロダクションレイクハウスプラットフォームの構築を現実のものとしたDelta Lakeによるものです。データの指数関数的増加により、大量のデータを高速化つ高信頼に処理することが重要となっています。Delta Lake、そしてバージョン1.1の機能を用いることで、開発者は自身のレイクハウスをより高速に実行できるようになり、イノベーションのペースを維持することができます。
オープンソースのDelta Lakeに興味がありますか?
Delta Lake online hubを訪れてみてください。SlackやGoogle Group経由でコミュにぃに参加できます。今後のリリースや計画されている機能をGitHub milestonesで追跡することができますし、Databricksのフリーアカウントを用いてマネージドのDelta Lakeをトライすることもできます。
クレジット
以下の方々のDelta Lake 1.1.0への貢献に感謝の意を評します:Abhishek Somani, Adam Binford, Alex Jing, Alexandre Lopes, Allison Portis, Bogdan Raducanu, Bart Samwel, Burak Yavuz, David Lewis, Eunjin Song, ericfchang, Feng Zhu, Flavio Cruz, Florian Valeye, Fred Liu, gurunath, Guy Khazma, Jacek Laskowski, Jackie Zhang, Jarred Parrett, JassAbidi, Jose Torres, Junlin Zeng, Junyong Lee, KamCheung Ting, Karen Feng, Lars Kroll, Li Zhang, Linhong Liu, Liwen Sun, Maciej, Max Gekk, Meng Tong, Prakhar Jain, Pranav Anand, Rahul Mahadev, Ryan Johnson, Sabir Akhadov, Scott Sandre, Shixiong Zhu, Shuting Zhang, Tathagata Das, Terry Kim, Tom Lynch, Vijayan Prabhakaran, Vítor Mussa, Wenchen Fan, Yaohua Zhao, Yijia Cui, YuXuan Tay, Yuchen Huo, Yuhong Chen, Yuming Wang, Yuyuan Tang, Zach Schuermann.