こちらの記事で紹介されているソリューションアクセラレータをウォークスルーします。
ソリューションアクセラレータはこちらです。
注意
私は最初はgitフォルダにクローンして実行していましたが、MLflowによるノートブックエクスペリメントへのモデル保存がうまく動かなかったので、ワークスペースにノートブックや依存しているファイルをクローンして実行しました。
01_introduction
生成AIによるブランドにアラインした画像の生成
様々な業界のデザインのプロは、彼らの次の製品デザインのインスピレーションとして役に立つ画像を生成するために、diffusionモデルを活用しています。このソリューションアクセラレータでは、パーソナライズされた画像生成アプリケーションのエンドツーエンドの開発を促進するツールをDatabricksユーザーに提供します。アセットには、トレーニング画像の前処理、text-to-imageのdiffusionモデルのファインチューン、ファインチューンモデルの管理、後段のアプリケーションで利用できるようにするためにエンドポイントへのモデルのデプロイの方法を説明する一連のノートブックが含まれています。このソリューションはカスタマイズ可能(ご自身の画像を利用)であり、Databricksのパワフルな分散計算処理を活用することでスケールすることができます。
クラスター設定
このソリューションアクセラレータを実行するためには以下の仕様のクラスターを使うことを推奨します:
- Unity Catalog有効化クラスター
- Databricks Runtime 14.3LTS ML 以降
- シングルノードのマルチGPUクラスター: 例
g5.48xlargeon AWS やStandard_NC48ads_A100_v4on Azure Databricks.
%run ./99_utils
すぐに利用できるStable Diffusion XL Baseモデルの活用
Stable Diffusion XL Baseは(2024/3/1時点)商用利用可能な最もパワフルでオープンソースのtext-to-imageモデルの一つとなっています。このモデルはStability AIによって開発され、その重みはHugging Faceでアクセスすることができ、Databricksでネイティブサポートしているものとなります。Hugging Faceからこのモデルをダウンロードし、画像を生成するには、以下のセルを実行します。
import torch
from diffusers import DiffusionPipeline
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
pipe.to(device)
prompt = "A photo of a brown leather chair in a living room."
image = pipe(prompt=prompt).images[0]
show_image(image) # この関数は 99_utils ノートブックで定義されています

以降のノートブックを実行できるようにメモリーを解放します
import gc
# パイプラインを削除し、メモリーを解放します
del pipe
gc.collect()
torch.cuda.empty_cache()
02_data_prep
%run ./99_utils
ファインチューニングのための画像の準備
生成モデルの出力の調整は、成功するアプリケーションの構築で重要となります。これは、画像生成モデルが支援するユースケースにも適用されます。家具のデザイナーがアイデア出しの目的で画像を生成しようとしており、過去の画像を生成画像に反映させたいというシナリオをイメージしてみてください。それだけではなく、素材や色のような観点でいくつかのバリエーションも見たいものとします。このような事例では、モデルは彼らの過去の製品を知り、それらに新たなスタイルを適用できるようにすることが不可欠です。このようなケースではカスタマイゼーションが必要となります。我々の画像に対して事前学習モデルをファインチューニングすることで、これを実現することができます。
Unity Catalogのボリュームで画像を管理
このソリューションアクセラレータでは、モデルをファインチューニングするために/images/chair/のサブフォルダに格納されている25のトレーニング画像を使用します。GitHubからこのアクセラレータをインポートすると、すでに画像が含まれています。シンプルにノートブックをダウンロードした場合、修正なしに以下のセルを実行するためには、ワークスペースでフォルダー構造を作成し、 https://github.com/databricks-industry-solutions/personalized_image_gen から画像をインポートする必要があります。
theme = "chair"
catalog = "takaakiyayoi_catalog" # アセットを管理するために使用するカタログ名 (例: 画像、重み、データセット)
volumes_dir = f"/Volumes/{catalog}/{theme}" # UCボリュームのディレクトリへのパス
# カタログとスキーマが存在することを確認
_ = spark.sql(f"CREATE CATALOG IF NOT EXISTS {catalog}")
_ = spark.sql(f"CREATE SCHEMA IF NOT EXISTS {catalog}.{theme}")
import os
import subprocess
# スキーマの下にボリュームを作成し、トレーニング画像をコピー
for volume in os.listdir("./images/chair"):
volume_name = f"{catalog}.{theme}.{volume}"
spark.sql(f"CREATE VOLUME IF NOT EXISTS {volume_name}")
command = f"cp ./images/chair/{volume}/*.jpg /Volumes/{catalog}/{theme}/{volume}/"
process = subprocess.Popen(command, stdout=subprocess.PIPE, shell=True)
output, error = process.communicate()
if error:
print('Output: ', output)
print('Error: ', error)
import glob
# ボリュームにある画像を表示
img_paths = f"{volumes_dir}/*/*.jpg"
imgs = [PIL.Image.open(path) for path in glob.glob(img_paths)]
num_imgs_to_preview = 25
show_image_grid(imgs[:num_imgs_to_preview], 5, 5) # utilノートブックで定義されているカスタム関数

ユニークなトークンを用いた画像への注釈
ファインチューニングには、それぞれのトレーニング画像に対するキャプションを追加する必要があります。上の25個の画像は、5つの異なるスタイルの椅子から構成されています。それぞれのスタイルに対するユニークなトークンを割り当てます: 例えば、「BCNCHR椅子の画像」、ここでは、BCNCHRは一番上の行の黒い皮の椅子に割り当てられるユニークなトークンです(上のセルのアウトプットをご覧ください)。トークンのユニーク性によって、ベースの事前トレーニング済みモデルがもたらすシンタックス、セマンティックの知識を保持する助けになります。ファインチューニングの考え方は、モデルがすでに知っていることを台無しにすることではなく、新たなトークンの対象の間の関連性を学習します。これに関する詳細はこちらをご覧ください。
以下のセルでは、キャプションのプレフィクスを用いてそれぞれのキャプションにトークン(BCNCHRなど)を付与します。この例では、"a photo of a BCNCHR chair,"というフォーマットをload知いますが、"a photo of a chair in the style of BCNCHR"のようなフォーマットでも構いません。
BLIPによるカスタムキャプション生成の自動化
トレーニング画像の数が多い場合、BLIPのようなモデルを用いたキャプション生成の自動化が選択肢となります。
import pandas as pd
import PIL
import torch
from transformers import AutoProcessor, BlipForConditionalGeneration
# プロセッサとキャプション付けモデルのロード
device = "cuda" if torch.cuda.is_available() else "cpu"
blip_processor = AutoProcessor.from_pretrained("Salesforce/blip-image-captioning-large")
blip_model = BlipForConditionalGeneration.from_pretrained(
"Salesforce/blip-image-captioning-large", torch_dtype=torch.float16
).to(device)
# (Pil.Image, path) ペアのリストの作成
imgs_and_paths = [
(path, PIL.Image.open(path).rotate(-90))
for path in glob.glob(f"{volumes_dir}/*/*.jpg")
]
import json
captions = []
for img in imgs_and_paths:
instance_class = img[0].split("/")[4].replace("_", " ")
caption_prefix = f"a photo of a {instance_class} {theme}: "
caption = (
caption_prefix
+ caption_images(img[1], blip_processor, blip_model, device).split("\n")[0] # caption_images関数はutilsノートブックで定義されています
)
captions.append(caption)
# BLIPによって生成されたキャプションの表示
display(pd.DataFrame(captions).rename(columns={0: "caption"}))
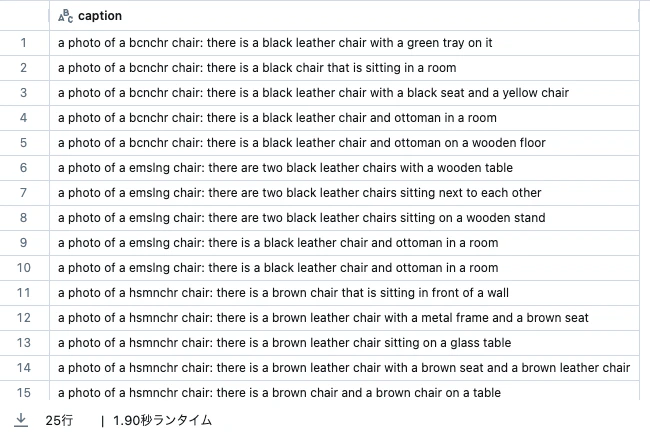
UCボリュームでのデータセットの管理
Hugging Face Datasetオブジェクトを作成し、Unity Catalogボリュームに格納します。
from datasets import Dataset, Image
d = {
"image": [imgs[0] for imgs in imgs_and_paths],
"caption": [caption for caption in captions],
}
dataset = Dataset.from_dict(d).cast_column("image", Image())
spark.sql(f"CREATE VOLUME IF NOT EXISTS {catalog}.{theme}.dataset")
dataset.save_to_disk(f"/Volumes/{catalog}/{theme}/dataset")
ここでもメモリーを解放しましょう。
import gc
del blip_processor, blip_model
gc.collect()
torch.cuda.empty_cache()
03_fine_tuning
%run ./99_utils
DreamBoothとLoRAによるStable Diffusion XLのファインチューニング
ファインチューニングでは、少数の画像を用いて事前学習済みtext-to-imageモデルの重みをアップデートするテクニックであるDreamBoothを活用します。このソリューションアクセラレータでは、DreamBoothのDiffusers実装を活用します。
TensorBoardのセットアップ
TensorBoardは、モデルトレーニングのためのオープンソースのモニタリングソリューションです。ダッシュボード上でニアリアルタイムでイベントログを読み込み、トレーニングメトリクスを表示し、トレーニングが完了するまで待つことなしに、ファインチューニングのステータスを計測する助けとなります。
イベントログをDBFSに書き込む際、トレーニングが完了し、ファイルの書き込みがクローズされるまでは表示されないことに注意してください。これはリアルタイムモニタリングには適していません。このため、ドライバーノードにイベントログを書き出し、そこからTensorBoardを実行することをお勧めします(どのように行うのかは以下のセルをご覧ください)。ドライバーノードに格納されたファイルは、クラスターを停止、再起動した際に削除されてしまいます。しかし、Databricksノートブックでトレーニングを実行した際、MLflowは自動でTensorboardアーティファクトを自動で記録し、あとでリカバリすることができます。この例を以下で見ることになります。
import os
from tensorboard import notebook
logdir = "/databricks/driver/logdir/sdxl/" # ドライバーノードにイベントログを書き出し
notebook.start("--logdir {} --reload_multifile True".format(logdir))
いくつかの変数を指定しましょう。
theme = "chair"
catalog = "takaakiyayoi_catalog"
volumes_dir = "/Volumes/takaakiyayoi_catalog"
os.environ["DATASET_NAME"] = f"{volumes_dir}/{theme}/dataset"
os.environ["OUTPUT_DIR"] = f"{volumes_dir}/{theme}/adaptor"
os.environ["LOGDIR"] = logdir
# ボリュームが存在することを確認
_ = spark.sql(f"CREATE VOLUME IF NOT EXISTS {catalog}.{theme}.adaptor")
パラメーターの設定
Stable Diffusion XLのようなヘビーなパイプラインでDreamBoothとLoRAを利用できるようにするために、以下のハイパーパラメータを使用します:
- Gradient checkpointing (
--gradient_accumulation_steps) - 8-bit Adam (
--use_8bit_adam) - Mixed-precision training (
--mixed-precision="fp16") - その他のパラメーターは
yamls/zero2.yamlで定義
その他のパラメーター:
- LoRAモデルのリポジトリ名を指定するために
--output_dirを使用 - お使いのデータセットのキャプション列を指定するために
--caption_columnを使用 -
yamls/zero2.yamlのパラメーターnum_processesに適切なGPU数を指定してください: 例えば、g5.48xlargeではnum_processesは8となります。
デフォルトのトレーニング画像では、8xA10GPUインスタンスのシングルノードクラスターでは、以下のセルの実行に約15分を要します。
%sh accelerate launch --config_file yamls/zero2.yaml personalized_image_generation/train_dreambooth_lora_sdxl.py \
--pretrained_model_name_or_path="stabilityai/stable-diffusion-xl-base-1.0" \
--pretrained_vae_model_name_or_path="madebyollin/sdxl-vae-fp16-fix" \
--dataset_name=$DATASET_NAME \
--caption_column="caption" \
--instance_prompt="" \
--output_dir=$OUTPUT_DIR \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=3 \
--gradient_checkpointing \
--learning_rate=1e-4 \
--snr_gamma=5.0 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--use_8bit_adam \
--max_train_steps=500 \
--checkpointing_steps=717 \
--seed="0" \
--report_to="tensorboard" \
--logging_dir=$LOGDIR
%sh ls -ltr $OUTPUT_DIR
total 22843
-rwxrwxrwx 1 nobody nogroup 23390424 Apr 18 06:36 pytorch_lora_weights.safetensors
推論のテスト
ファインチューニングしたモデルを用いていくつかの画像を生成してみましょう!
from diffusers import DiffusionPipeline, AutoencoderKL
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16
)
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
pipe.load_lora_weights(f"{volumes_dir}/{theme}/adaptor/pytorch_lora_weights.safetensors")
pipe = pipe.to(device)
import os
import glob
types = os.listdir("./images/chair")
num_imgs_to_preview = len(types)
imgs = []
for type in types:
imgs.append(
pipe(
prompt=f"A photo of a red {type} chair in a living room",
num_inference_steps=25,
).images[0]
)
show_image_grid(imgs[:num_imgs_to_preview], 1, num_imgs_to_preview)

MLflowにモデルを記録
import mlflow
import torch
class sdxl_fine_tuned(mlflow.pyfunc.PythonModel):
def __init__(self, vae_name, model_name):
self.vae_name = vae_name
self.model_name = model_name
def load_context(self, context):
"""
このメソッドは指定されたモデルリポジトリを用いて、vaeとモデルを初期化します。
"""
# トークナイザーと言語モデルの初期化
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.vae = diffusers.AutoencoderKL.from_pretrained(
self.vae_name, torch_dtype=torch.float16
)
self.pipe = diffusers.DiffusionPipeline.from_pretrained(
self.model_name,
vae=self.vae,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
)
self.pipe.load_lora_weights(context.artifacts["repository"])
self.pipe = self.pipe.to(self.device)
def predict(self, context, model_input):
"""
This method generates output for the given input.
"""
prompt = model_input["prompt"][0]
num_inference_steps = model_input.get("num_inference_steps", [25])[0]
# 画像の生成
image = self.pipe(
prompt=prompt, num_inference_steps=num_inference_steps
).images[0]
# 予測結果として返却す売るために画像をnumpy配列に変換
image_np = np.array(image)
return image_np
vae_name = "madebyollin/sdxl-vae-fp16-fix"
model_name = "stabilityai/stable-diffusion-xl-base-1.0"
output = f"{volumes_dir}/{theme}/adaptor/pytorch_lora_weights.safetensors"
import numpy as np
import pandas as pd
import mlflow
from mlflow.models.signature import ModelSignature
from mlflow.types import DataType, Schema, ColSpec, TensorSpec
import transformers, bitsandbytes, accelerate, deepspeed, diffusers
mlflow.set_registry_uri("databricks-uc")
# 入力と出力のスキーマの定義
input_schema = Schema(
[ColSpec(DataType.string, "prompt"), ColSpec(DataType.long, "num_inference_steps")]
)
output_schema = Schema([TensorSpec(np.dtype(np.uint8), (-1, 768, 3))])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# 入力のサンプルを定義
input_example = pd.DataFrame(
{"prompt": [f"A photo of a {theme} in a living room"], "num_inference_steps": [25]}
)
# アーティファクト、pipの要件、入力のサンプルのような詳細とともにモデルを記録
with mlflow.start_run() as run:
mlflow.pyfunc.log_model(
"model",
python_model=sdxl_fine_tuned(vae_name, model_name),
artifacts={"repository": output},
pip_requirements=[
"transformers==" + transformers.__version__,
"bitsandbytes==" + bitsandbytes.__version__,
"accelerate==" + accelerate.__version__,
"deepspeed==" + deepspeed.__version__,
"diffusers==" + diffusers.__version__,
],
input_example=input_example,
signature=signature,
)
mlflow.set_tag("dataset", f"{volumes_dir}/{theme}/dataset")
モデルが記録されます。
Unity Catalogにモデルを登録
# モデルを格納するスキーマが存在することを確認
_ = spark.sql(f"CREATE SCHEMA IF NOT EXISTS {catalog}.model")
# モデルの登録
registered_name = f"{catalog}.model.sdxl-fine-tuned-{theme}"
result = mlflow.register_model(
"runs:/" + run.info.run_id + "/model",
registered_name
)
推論を行うために登録モデルを再度ロード
アウトオブメモリーの問題に遭遇した場合には、トレーニングで占有されたGPUメモリーを解放するためにPythonカーネルを再起動して下さい。このためには、以下のセルのコメントを解除して実行し、theme、catalog、volume_dirのような変数を再定義してください。
#dbutils.library.restartPython()
def get_latest_model_version(mlflow_client, registered_name):
latest_version = 1
for mv in mlflow_client.search_model_versions(f"name='{registered_name}'"):
version_int = int(mv.version)
if version_int > latest_version:
latest_version = version_int
return latest_version
import mlflow
from mlflow import MlflowClient
import pandas as pd
mlflow.set_registry_uri("databricks-uc")
mlflow_client = MlflowClient()
registered_name = f"{catalog}.model.sdxl-fine-tuned-{theme}"
model_version = get_latest_model_version(mlflow_client, registered_name)
logged_model = f"models:/{registered_name}/{model_version}"
# PyFuncModelとしてモデルをロード
loaded_model = mlflow.pyfunc.load_model(logged_model)
このモデルを活用することで、デザインチームは自身の製品の新たなバリエーションを探索し、自身のポートフォリオの過去の生産アイテムのデザインを反映した新規アイテムを生成することすらも可能となります。
# パーソナライズされた画像を生成するために以下のトークンのいずれかを使ってください: 'bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr'
input_example = pd.DataFrame(
{
"prompt": ["A photo of a long brown sofa in the style of the bcnchr chair"],
"num_inference_steps": [25],
}
)
image = loaded_model.predict(input_example)
show_image(image)

# モデルにエイリアスを割り当てます
mlflow_client.set_registered_model_alias(registered_name, "champion", model_version)
カタログエクスプローラでモデルが登録されていることを確認できます。
04_deploy_model
Pythonによるモデルサービングエンドポイントの作成
Unity Catalogにファインチューニングしたモデルを登録したので、最後のステップはモデルサービングエンドポイントにこのモデルをデプロイすることとなります。このノートブックでは、Pythonモデルサービンワークフローにおける、モデルサービングエンドポイントの作成のためのREST APIのラッピング、モデルバージョンに基づくエンドポイント設定の更新、エンドポイントの削除をカバーします。
import mlflow
mlflow.set_registry_uri("databricks-uc")
client = mlflow.tracking.MlflowClient()
いくつかの変数を指定します。
theme = "chair"
catalog = "takaakiyayoi_catalog"
log_schema = "log" # 推論のログを格納するカタログ内のスキーマ
model_name = f"{catalog}.model.sdxl-fine-tuned-{theme}" # モデルレジストリに既存モデルがある場合には複数のバージョンが存在します
model_serving_endpoint_name = f"sdxl-fine-tuned-{theme}"
トークンとモデルバージョンの取得
以下のセクションでは、ノートブックから取得できるAPIのトークンの指定方法と、サービングとデプロイを行おうとする最新のモデルバージョンの取得方法を説明します。
token = (
dbutils.notebook.entry_point.getDbutils()
.notebook()
.getContext()
.apiToken()
.getOrElse(None)
)
# このトークンを用いて、以降のAPI呼び出しの認証ヘッダーを作成することができます
headers = {"Authorization": f"Bearer {token}", "Content-Type": "application/json"}
# 次に、リクエストを処理するエンドポイントが必要となり、エンドポイント名はノートブックのタグコレクションから取得できます
java_tags = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags()
# このオブジェクトはJavaのCMから取得され、Java MapオブジェクトをPythonのディクショナリーに変換します
tags = sc._jvm.scala.collection.JavaConversions.mapAsJavaMap(java_tags)
# 最後にディクショナリーからDatabricksインスタンス(ドメイン名)を抽出します
instance = tags["browserHostName"]
champion_version = client.get_model_version_by_alias(model_name, "champion")
model_version = champion_version.version
設定のセットアップ
ご自身のユースケースにおけるレーテーンシーとスループット要件に応じて、適切なworkload_typeとworkload_sizeを選択したいと思うことでしょう。
Azure Databricksを使っている場合には、workload_typeではGPU_LARGEを使うように注意してください。auto_capture_configブロックは推論ログをどこに書き込むかを指定します: 例えば、エンドポイントにおけるリクエストとレスポンスをタイムスタンプとともに記録します。
import requests
my_json = {
"name": model_serving_endpoint_name,
"config": {
"served_models": [
{
"model_name": model_name,
"model_version": model_version,
"workload_type": "GPU_MEDIUM",
"workload_size": "Small",
"scale_to_zero_enabled": "false",
}
],
"auto_capture_config": {
"catalog_name": catalog,
"schema_name": log_schema,
"table_name_prefix": model_serving_endpoint_name,
},
},
}
# 推論テーブルのスキーマが存在することを確認
_ = spark.sql(
f"CREATE SCHEMA IF NOT EXISTS {catalog}.{log_schema}"
)
# テーブルが存在する場合には削除
_ = spark.sql(
f"DROP TABLE IF EXISTS {catalog}.{log_schema}.`{model_serving_endpoint_name}_payload`"
)
注意
私の環境では上の設定だとエラーになったので、推論テーブルのauto_capture_configはオフにしました。
以下では次を行うPython関数を定義します:
- モデルサービングエンドポイントの作成
- 最新のモデルバージョンを用いてモデルサービングエンドポイントの設定を更新
- モデルサービングエンドポイントの削除
def func_create_endpoint(model_serving_endpoint_name):
# エンドポイントのステータスを取得
endpoint_url = f"https://{instance}/api/2.0/serving-endpoints"
url = f"{endpoint_url}/{model_serving_endpoint_name}"
r = requests.get(url, headers=headers)
if "RESOURCE_DOES_NOT_EXIST" in r.text:
print(
"Creating this new endpoint: ",
f"https://{instance}/serving-endpoints/{model_serving_endpoint_name}/invocations",
)
re = requests.post(endpoint_url, headers=headers, json=my_json)
else:
new_model_version = (my_json["config"])["served_models"][0]["model_version"]
print(
"This endpoint existed previously! We are updating it to a new config with new model version: ",
new_model_version,
)
# 設定の更新
url = f"{endpoint_url}/{model_serving_endpoint_name}/config"
re = requests.put(url, headers=headers, json=my_json["config"])
# 新たな設定ファイルが配置されるまで待ちます
import time, json
# エンドポイントのステータスを取得
url = f"https://{instance}/api/2.0/serving-endpoints/{model_serving_endpoint_name}"
retry = True
total_wait = 0
while retry:
r = requests.get(url, headers=headers)
assert (
r.status_code == 200
), f"Expected an HTTP 200 response when accessing endpoint info, received {r.status_code}"
endpoint = json.loads(r.text)
if "pending_config" in endpoint.keys():
seconds = 10
print("New config still pending")
if total_wait < 6000:
# 待ち時間合計が10分以内なら待ち続けます
print(f"Wait for {seconds} seconds")
print(f"Total waiting time so far: {total_wait} seconds")
time.sleep(10)
total_wait += seconds
else:
print(f"Stopping, waited for {total_wait} seconds")
retry = False
else:
print("New config in place now!")
retry = False
assert (
re.status_code == 200
), f"Expected an HTTP 200 response, received {re.status_code}. {re}"
def func_delete_model_serving_endpoint(model_serving_endpoint_name):
endpoint_url = f"https://{instance}/api/2.0/serving-endpoints"
url = f"{endpoint_url}/{model_serving_endpoint_name}"
response = requests.delete(url, headers=headers)
if response.status_code != 200:
raise Exception(
f"Request failed with status {response.status_code}, {response.text}"
)
else:
print(model_serving_endpoint_name, "endpoint is deleted!")
return response.json()
func_create_endpoint(model_serving_endpoint_name)
エンドポイントの準備が整うまで待つ
以下のコマンドで定義されているwait_for_endpoint()関数はサービングエンドポイントのステータスを取得して返却します。
import time, mlflow
def wait_for_endpoint():
endpoint_url = f"https://{instance}/api/2.0/serving-endpoints"
while True:
url = f"{endpoint_url}/{model_serving_endpoint_name}"
response = requests.get(url, headers=headers)
assert (
response.status_code == 200
), f"Expected an HTTP 200 response, received {response.status_code}\n{response.text}"
status = response.json().get("state", {}).get("ready", {})
# print("status",status)
if status == "READY":
print(status)
print("-" * 80)
return
else:
print(f"Endpoint not ready ({status}), waiting 300 seconds")
time.sleep(300) # 300秒待つ
api_url = mlflow.utils.databricks_utils.get_webapp_url()
wait_for_endpoint()
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
Endpoint not ready (NOT_READY), waiting 300 seconds
READY
--------------------------------------------------------------------------------
モデルサービングエンドポイントが立ち上がりました。

# ['bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr']
prompt = pd.DataFrame(
{"prompt": ["A photo of an orange bcnchr chair"], "num_inference_steps": 25}
)
t = generate_image(prompt)
plt.imshow(t["predictions"])
plt.axis("off")
plt.show()

# ['bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr']
prompt = pd.DataFrame(
{"prompt": ["A photo of an blue hsmnchr chair"], "num_inference_steps": 25}
)
t = generate_image(prompt)
plt.imshow(t["predictions"])
plt.axis("off")
plt.show()

# ['bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr']
prompt = pd.DataFrame(
{"prompt": ["A photo of an white rckchr chair"], "num_inference_steps": 25}
)
t = generate_image(prompt)
plt.imshow(t["predictions"])
plt.axis("off")
plt.show()
モデルのスコアリング
以下のコマンドでは、score_model()を定義し、payload_json変数のリクエストに対してサンプルのスコアリングリクエストを行います。
import os
import requests
import pandas as pd
import json
import matplotlib.pyplot as plt
token = (
dbutils.notebook.entry_point.getDbutils()
.notebook()
.getContext()
.apiToken()
.getOrElse(None)
)
java_tags = dbutils.notebook.entry_point.getDbutils().notebook().getContext().tags()
tags = sc._jvm.scala.collection.JavaConversions.mapAsJavaMap(java_tags)
instance = tags["browserHostName"]
# モデルサービングエンドポイントのページから取得できるエンドポイント呼び出しのURLで置き換えます
endpoint_url = (
f"https://{instance}/serving-endpoints/{model_serving_endpoint_name}/invocations"
)
token = (
dbutils.notebook.entry_point.getDbutils().notebook().getContext().apiToken().get()
)
def generate_image(dataset, url=endpoint_url, databricks_token=token):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
ds_dict = {"dataframe_split": dataset.to_dict(orient="split")}
data_json = json.dumps(ds_dict, allow_nan=True)
response = requests.request(method="POST", headers=headers, url=url, data=data_json)
if response.status_code != 200:
raise Exception(
f"Request failed with status {response.status_code}, {response.text}"
)
return response.json()
オレンジのbcnchrチェア。
# ['bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr']
prompt = pd.DataFrame(
{"prompt": ["A photo of an orange bcnchr chair"], "num_inference_steps": 25}
)
t = generate_image(prompt)
plt.imshow(t["predictions"])
plt.axis("off")
plt.show()

ブルーのhsmnchrチェア。
# ['bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr']
prompt = pd.DataFrame(
{"prompt": ["A photo of an blue hsmnchr chair"], "num_inference_steps": 25}
)
t = generate_image(prompt)
plt.imshow(t["predictions"])
plt.axis("off")
plt.show()

レッドのrckchrチェア。
# ['bcnchr', 'emslng', 'hsmnchr', 'rckchr', 'wdnchr']
prompt = pd.DataFrame(
{"prompt": ["A photo of an red rckchr chair"], "num_inference_steps": 25}
)
t = generate_image(prompt)
plt.imshow(t["predictions"])
plt.axis("off")
plt.show()

すごいですね。
フロントエンドも作成しました。