こちらの続きです。
今更ながらにAzure OpenAIサービスを使い始めてみました。
最初にサインアップが必要です。手順はこちらにまとめられています。
エンドポイントの作成
利用できるようになるとエンドポイントを作成できるようになります。
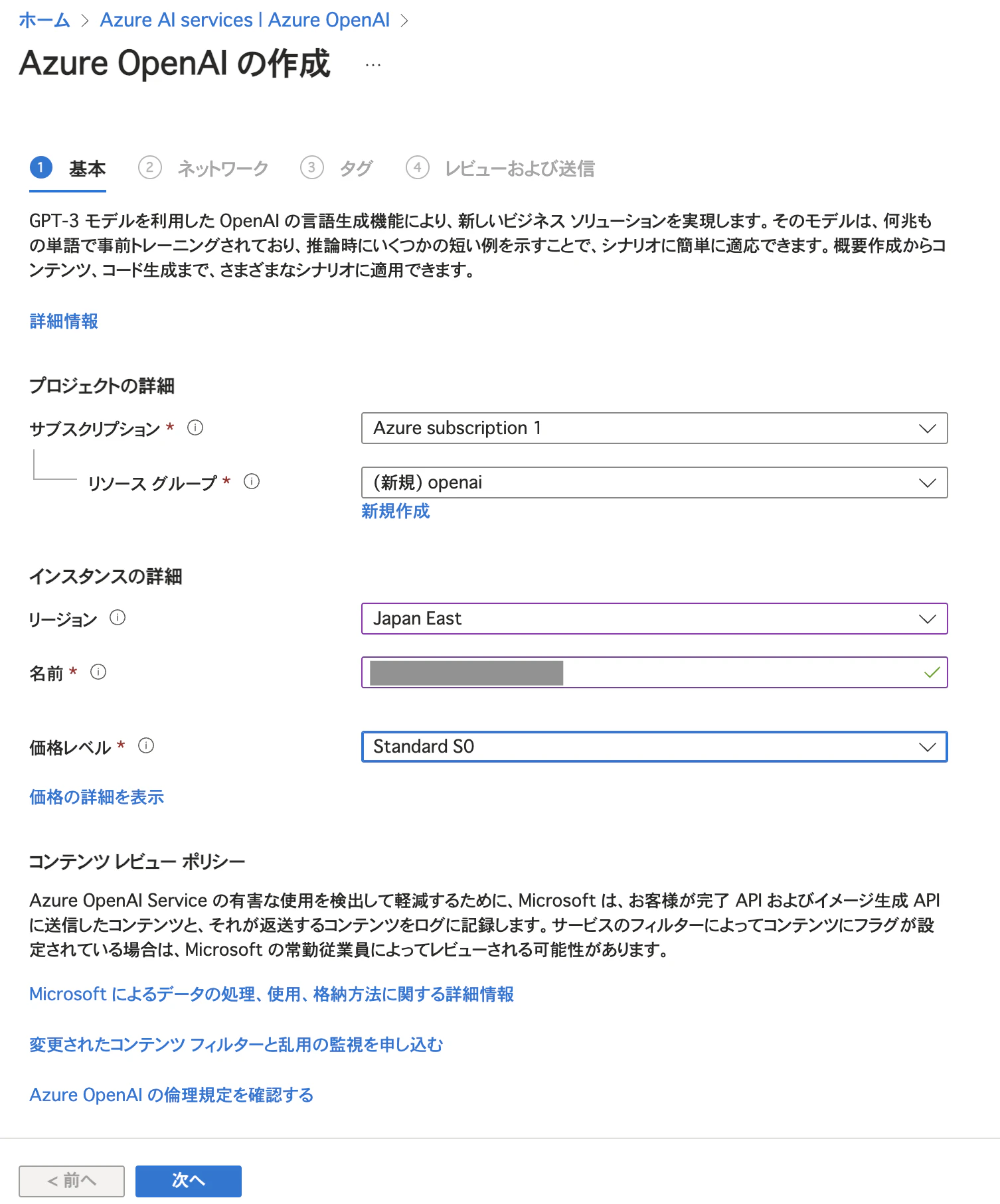
リソースグループやエンドポイント名を指定します。
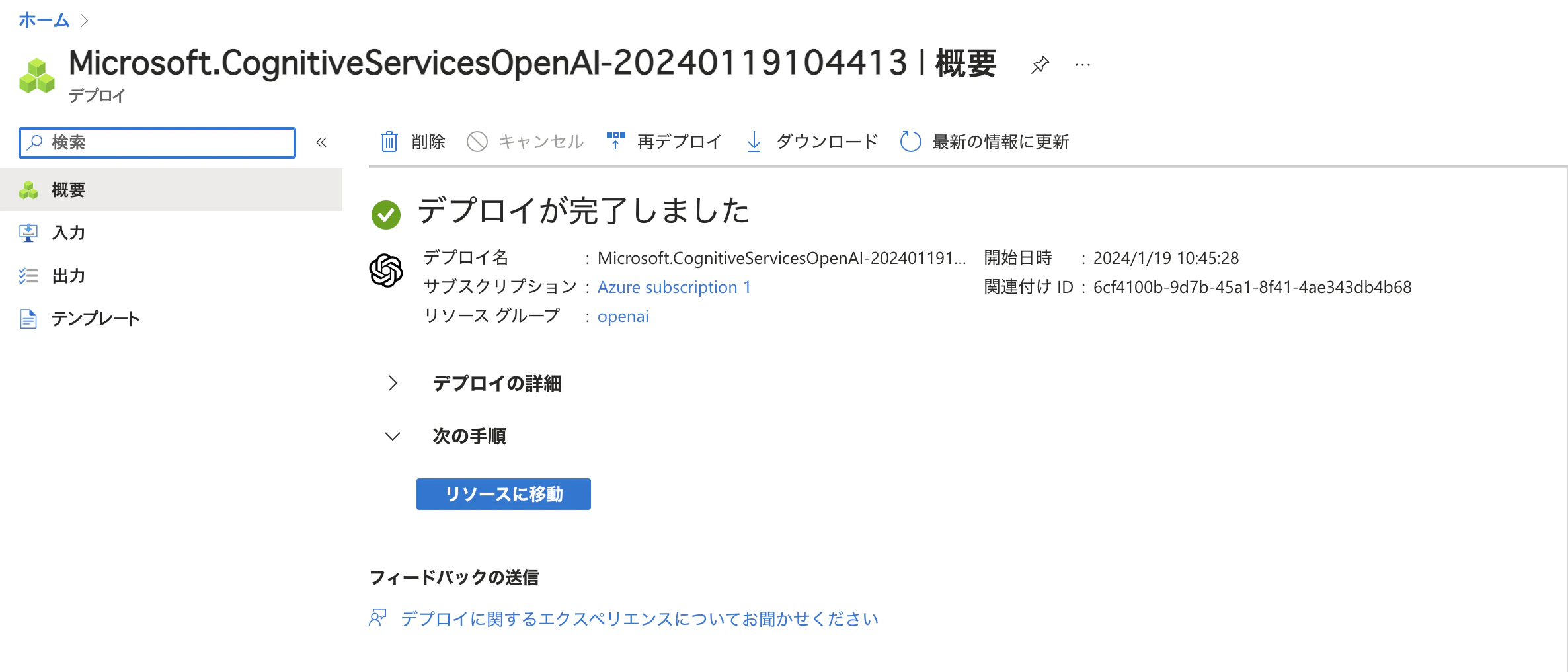
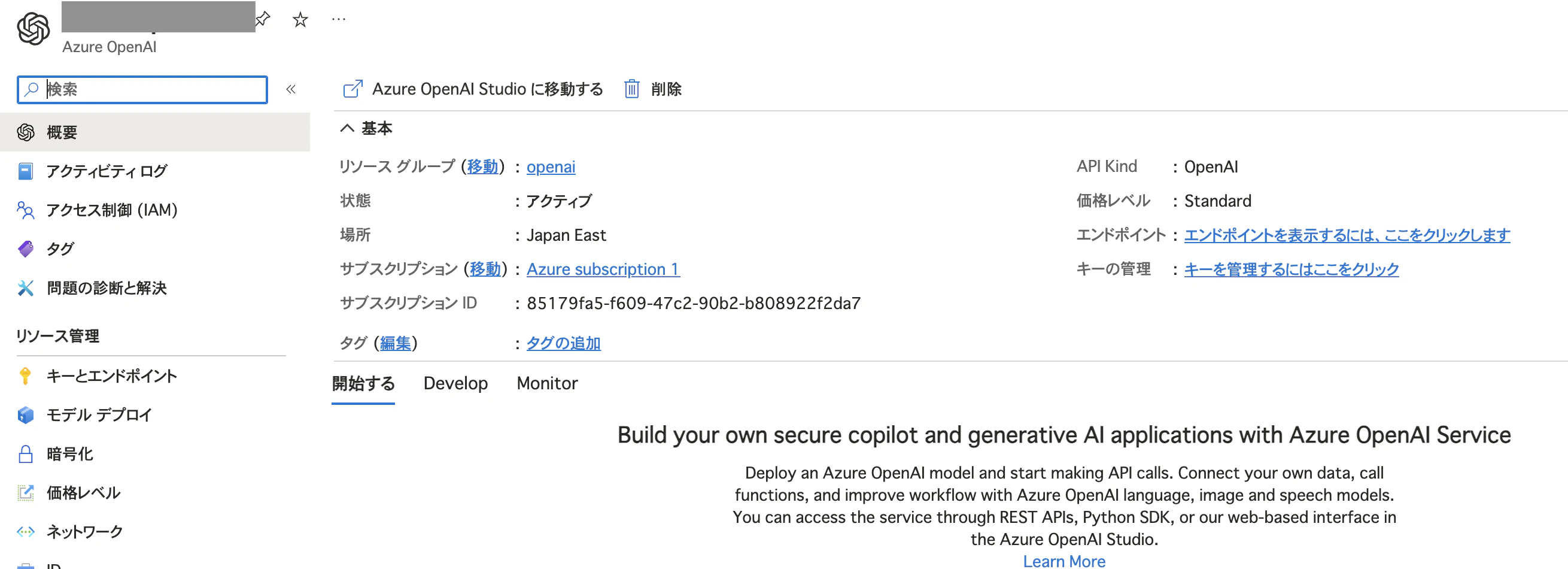
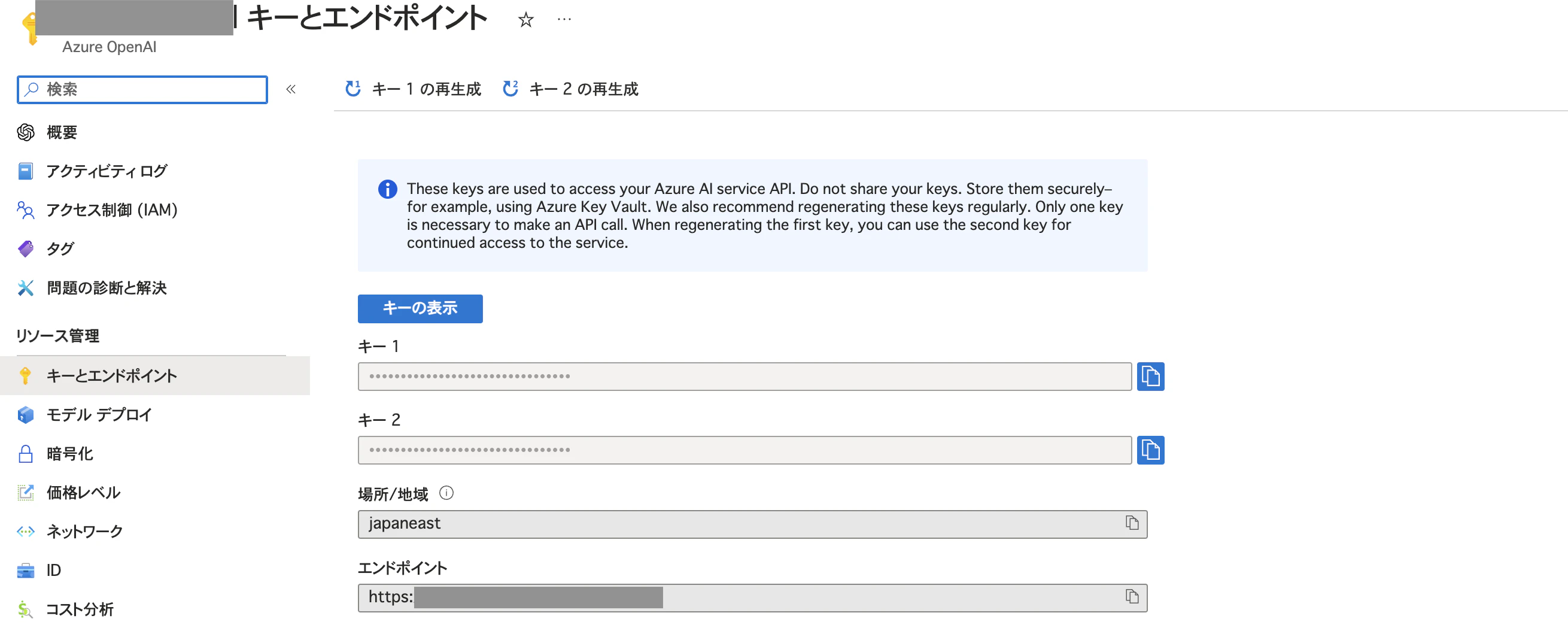
これでAPIキーとエンドポイントURLを入手できました。
ですが、これだけでは動かなくて、モデルをデプロイしてデプロイメントを作成する必要があります。
デプロイメントの作成
Azure OpenAI Studioにアクセスして、以下のモデルをデプロイします。これらは後でLlamaIndexから利用します。
- LLM: gpt-35-turbo
- エンベディングモデル: text-embedding-ada-002
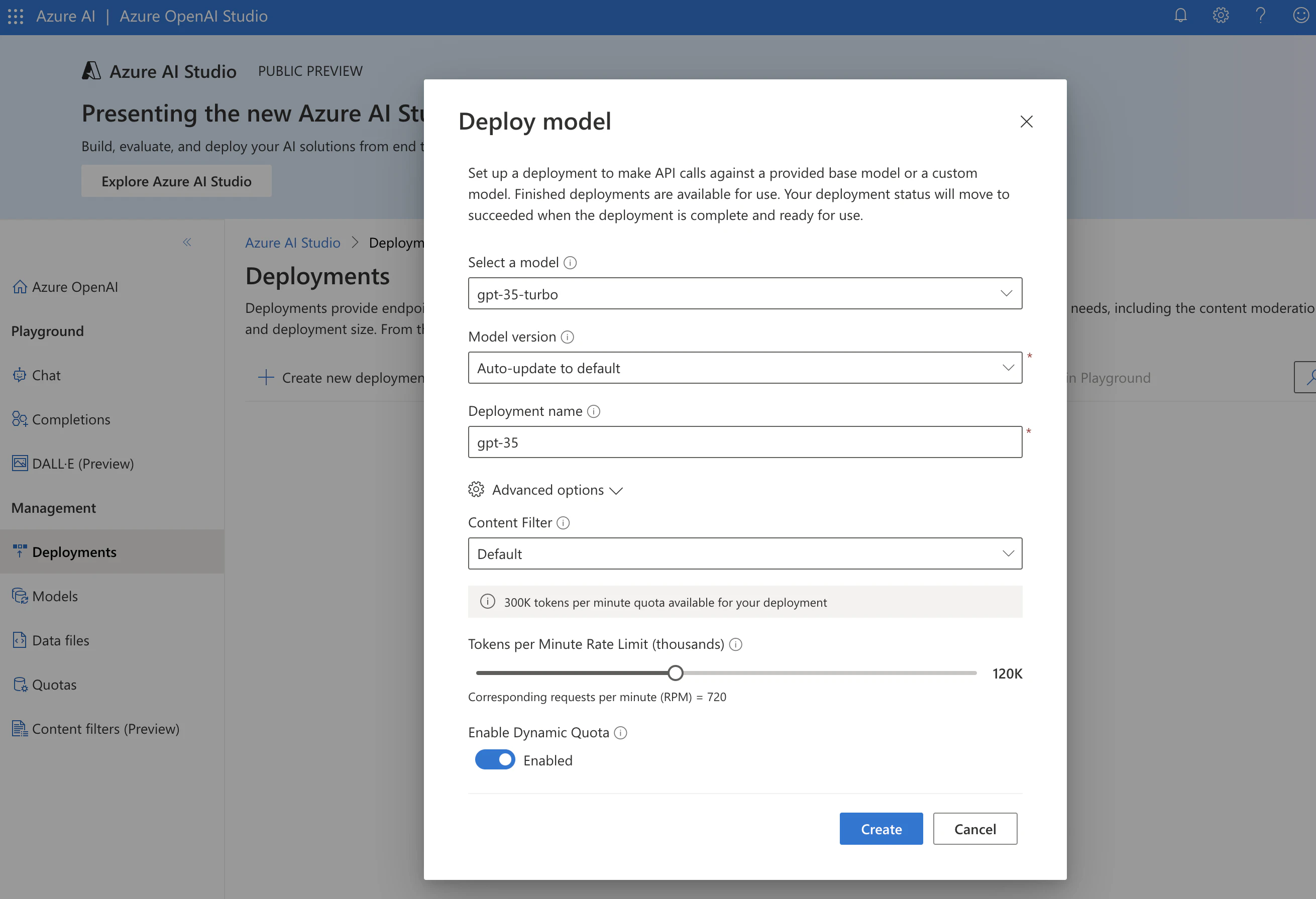
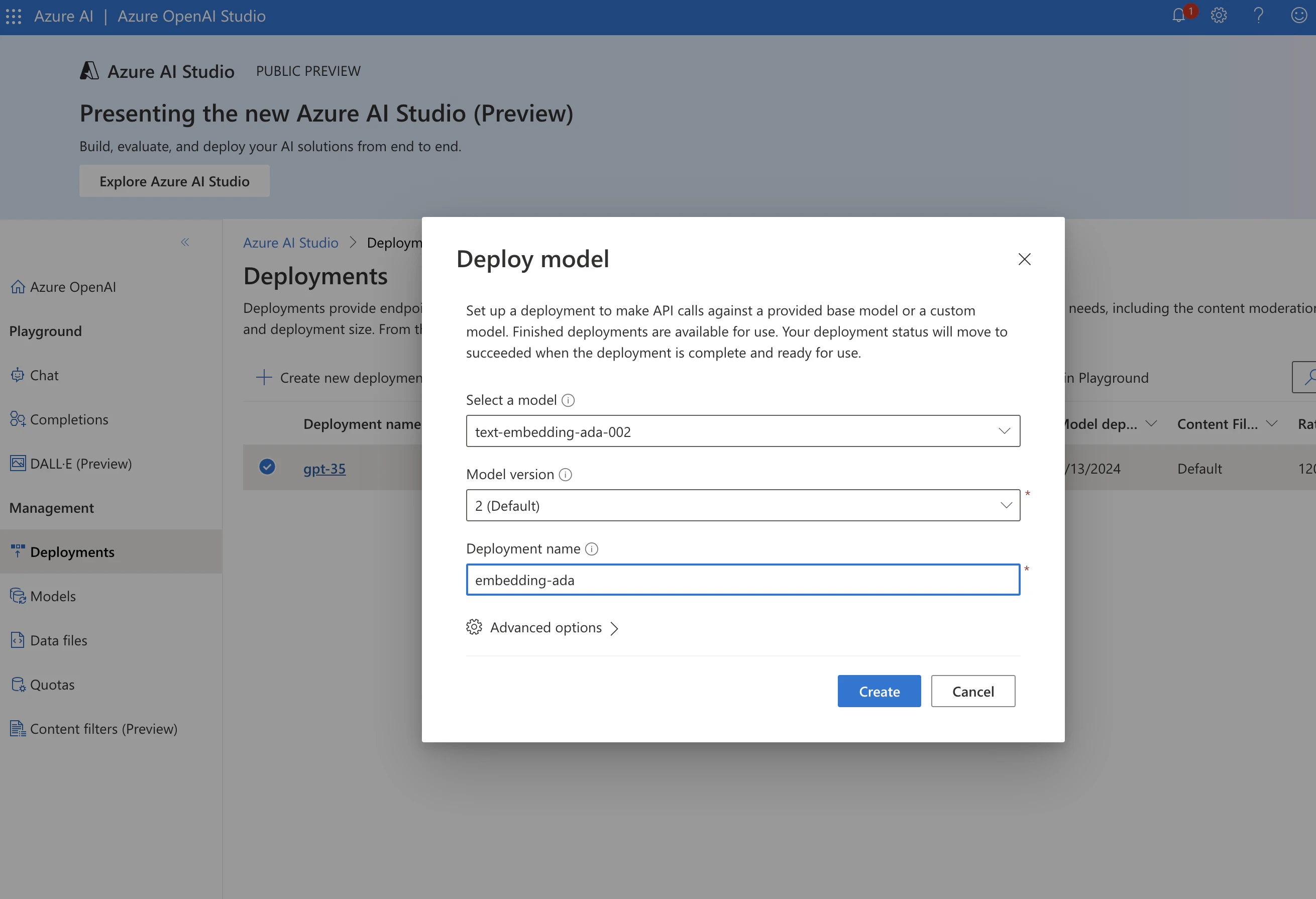
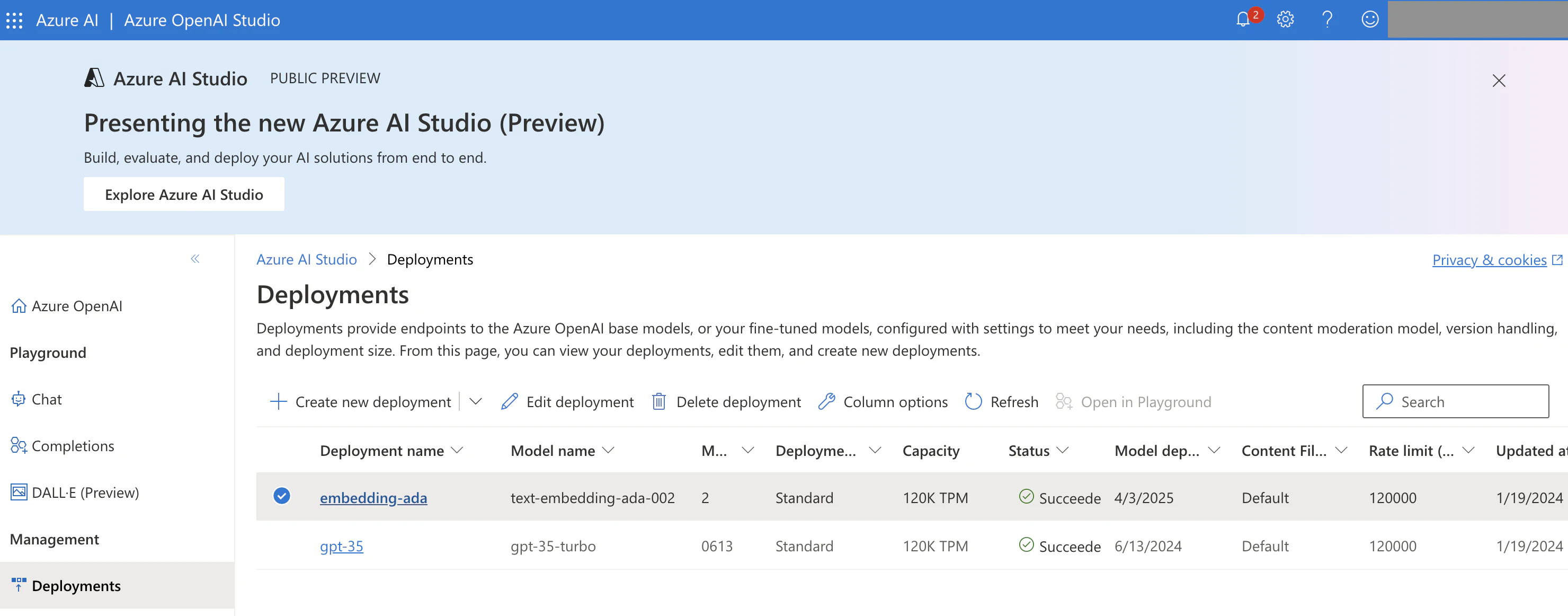
このような形でデプロイメントできました。Deployment nameをメモしておきます。
LlamaIndexからAzure OpenAIを利用する
LlamaIndexはデフォルトではOpenAIを呼び出すので、そのままではAzure OpenAIを利用できません。こちらで説明されているように、ServiceContextの設定が必要です。ServiceContextはLlamaIndexのパイプライン、アプリケーションでインデックスを作成したり、クエリーを行う際に使用される共通リソースのバンドルです。ServiceContextで上記のLLMとエンベディングモデルを指定します。
以下がコードサンプルです。
%pip install -U llama-index
dbutils.library.restartPython()
環境変数の設定
実際に利用される際にはAPIキーなどはシークレットに格納してください。
import os
os.environ["OPENAI_API_KEY"] = "<APIキー>"
os.environ[
"AZURE_OPENAI_ENDPOINT"
] = "<エンドポイントURL>"
os.environ["OPENAI_API_VERSION"] = "2023-07-01-preview"
ライブラリのインポート
ドキュメントのパスTEXT_DIRは適宜変更してください。
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.llms import AzureOpenAI
from llama_index.embeddings import AzureOpenAIEmbedding
TEXT_DIR = "/Volumes/takaakiyayoi_catalog/llama_index/data/corpus"
デプロイメントの参照
# Azure AI Studioのデプロイメントを指定
llm = AzureOpenAI(
deployment_name="gpt-35", temperature=0.0
)
embed_model = AzureOpenAIEmbedding(
deployment_name="embedding-ada"
)
LLMの動作確認をしておきます。
response = llm.complete("The sky is a beautiful blue and")
print(response)
the sun is shining brightly. Fluffy white clouds float lazily across the sky, creating a picturesque scene. The vibrant blue color of the sky brings a sense of calm and tranquility. It is a perfect day to be outside, enjoying the warmth of the sun and the gentle breeze. The sky seems to stretch endlessly, reminding us of the vastness and beauty of the world around us. It is a reminder to appreciate the simple pleasures in life and to take a moment to admire the natural wonders that surround us.
コンテキストの設定
上のLLMとエンベディングモデルをコンテキストから参照するようにします。
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model
)
ドキュメントのロード、インデックスの作成
documents = SimpleDirectoryReader("/Volumes/takaakiyayoi_catalog/llama_index/data/corpus").load_data()
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
インデックスへのクエリー
# インデックスに対するクエリー
query_engine = index.as_query_engine()
response = query_engine.query("幼少期、著者は何をしましたか?")
print(response)
幼少期、著者は短編小説を書いたり、プログラミングを試みたりしました。彼はIBM 1401というコンピューターでプログラムを書いた経験もあります。また、彼は友人と一緒にヒースキットのキットでマイクロコンピューターを組み立てたりもしました。
動きました!