こちらの続きです。
こちらのノートブックをウォークスルーします。
このノートブックは、Unity Catalogで特徴量エンジニアリングを使用してNYCイエローキャブの運賃を予測するモデルを作成する方法を示しています。以下のステップが含まれます:
- Unity Catalogで直接時系列特徴量を計算して書き込む。
- これらの特徴量を使用して運賃を予測するモデルをトレーニングする。
- 既存の特徴量を使用して新しいデータバッチでそのモデルを評価する。
要件
- Databricks Runtime 13.3 LTS for Machine Learning以上
- Databricks Runtime for Machine Learningにアクセスできない場合は、このノートブックをDatabricks Runtime 13.3 LTS以上で実行できます。その場合、このノートブックの最初に
%pip install databricks-feature-engineeringを実行してください。
- Databricks Runtime for Machine Learningにアクセスできない場合は、このノートブックをDatabricks Runtime 13.3 LTS以上で実行できます。その場合、このノートブックの最初に
特徴量の計算
特徴量計算に使用する生データの読み込み
nyc-taxi-tinyデータセットを読み込みます。これは、NYC Taxi Dataの全データセットである/databricks-datasets/nyctaxiから以下の変換を適用して生成されます:
- 緯度と経度の座標をZIPコードに変換するためのUDFを適用し、DataFrameにZIPコード列を追加します。
- Sparkの
DataFrameAPIの.sample()メソッドを使用して、日付範囲クエリに基づいてデータセットをサブサンプリングします。 - 特定の列の名前を変更し、不要な列を削除します。
raw_data = spark.read.format("delta").load("/databricks-datasets/nyctaxi-with-zipcodes/subsampled")
display(raw_data)

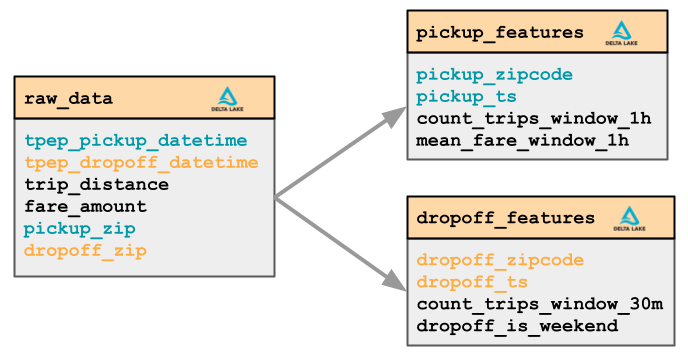
タクシー料金のトランザクションデータから、乗車および降車のZIPコードに基づいて2つの特徴量グループを計算します。
ピックアップ特徴量
- 移動回数(時間ウィンドウ = 1時間、スライディングウィンドウ = 15分)
- 平均運賃額(時間ウィンドウ = 1時間、スライディングウィンドウ = 15分)
ドロップオフ特徴量
- 移動回数(時間ウィンドウ = 30分)
- 移動が週末に終了するかどうか(Pythonコードを使用したカスタム特徴量)
ヘルパー関数
from pyspark.sql.functions import *
from pyspark.sql.types import FloatType, IntegerType, StringType
from pytz import timezone
@udf(returnType=IntegerType())
def is_weekend(dt):
tz = "America/New_York"
return int(dt.astimezone(timezone(tz)).weekday() >= 5) # 5 = Saturday, 6 = Sunday
def filter_df_by_ts(df, ts_column, start_date, end_date):
if ts_column and start_date:
df = df.filter(col(ts_column) >= start_date)
if ts_column and end_date:
df = df.filter(col(ts_column) < end_date)
return df
データサイエンティストによる特徴量計算のカスタムコード
def pickup_features_fn(df, ts_column, start_date, end_date):
"""
ピックアップ特徴量グループを計算します。
特徴量を時間範囲に制限するには、ts_column、start_date、および/またはend_dateをkwargsとして渡します。
"""
df = filter_df_by_ts(df, ts_column, start_date, end_date)
pickupzip_features = (
df.groupBy(
"pickup_zip", window("tpep_pickup_datetime", "1 hour", "15 minutes")
) # 1時間のウィンドウ、15分ごとにスライド
.agg(
mean("fare_amount").alias("mean_fare_window_1h_pickup_zip"),
count("*").alias("count_trips_window_1h_pickup_zip"),
)
.select(
col("pickup_zip").alias("zip"),
unix_timestamp(col("window.end")).cast("timestamp").alias("ts"),
col("mean_fare_window_1h_pickup_zip").cast(FloatType()),
col("count_trips_window_1h_pickup_zip").cast(IntegerType()),
)
)
return pickupzip_features
def dropoff_features_fn(df, ts_column, start_date, end_date):
"""
ドロップオフ特徴量グループを計算します。
特徴量を時間範囲に制限するには、ts_column、start_date、および/またはend_dateをkwargsとして渡します。
"""
df = filter_df_by_ts(df, ts_column, start_date, end_date)
dropoffzip_features = (
df.groupBy("dropoff_zip", window("tpep_dropoff_datetime", "30 minute"))
.agg(count("*").alias("count_trips_window_30m_dropoff_zip"))
.select(
col("dropoff_zip").alias("zip"),
unix_timestamp(col("window.end")).cast("timestamp").alias("ts"),
col("count_trips_window_30m_dropoff_zip").cast(IntegerType()),
is_weekend(col("window.end")).alias("dropoff_is_weekend"),
)
)
return dropoffzip_features
from datetime import datetime
pickup_features = pickup_features_fn(
df=raw_data,
ts_column="tpep_pickup_datetime",
start_date=datetime(2016, 1, 1),
end_date=datetime(2016, 1, 31),
)
dropoff_features = dropoff_features_fn(
df=raw_data,
ts_column="tpep_dropoff_datetime",
start_date=datetime(2016, 1, 1),
end_date=datetime(2016, 1, 31),
)
display(pickup_features)

display(dropoff_features)

Unity Catalogで新しい時系列特徴量テーブルを作成する
まず、新しいカタログを作成するか、既存のカタログを再利用し、特徴量テーブルを格納するスキーマを作成します。
- 新しいカタログを作成するには、メタストアに対する
CREATE CATALOG権限が必要です。 - 既存のカタログを使用するには、カタログに対する
USE CATALOG権限が必要です。 - カタログ内に新しいスキーマを作成するには、カタログに対する
CREATE SCHEMA権限が必要です。
%sql
-- 新しいカタログを作成:
-- CREATE CATALOG IF NOT EXISTS ml;
-- USE CATALOG ml;
-- 既存のカタログを再利用:
USE CATALOG takaakiyayoi_catalog;
-- 新しいスキーマを作成
CREATE SCHEMA IF NOT EXISTS taxi_example;
USE SCHEMA taxi_example;
次に、主キー制約を使用してUnity Catalogに時系列特徴量テーブルを作成します。
CREATE TABLE SQL構文を使用して、Unity Catalogに直接テーブルを作成できます。主キー制約を使用して主キー列を指定します。時系列テーブルの場合、TIMESERIESを使用して時系列列を注釈します(AWS|Azure|GCP)。
時系列の列はTimestampTypeまたはDateTypeでなければなりません。
%sql
CREATE TABLE IF NOT EXISTS takaakiyayoi_catalog.taxi_example.trip_pickup_time_series_features(
zip INT NOT NULL,
ts TIMESTAMP NOT NULL,
mean_fare_window_1h_pickup_zip FLOAT,
count_trips_window_1h_pickup_zip INT,
CONSTRAINT trip_pickup_time_series_features_pk PRIMARY KEY (zip, ts TIMESERIES)
)
COMMENT "タクシー料金。ピックアップ時系列特徴量";
%sql
CREATE TABLE IF NOT EXISTS takaakiyayoi_catalog.taxi_example.trip_dropoff_time_series_features(
zip INT NOT NULL,
ts TIMESTAMP NOT NULL,
count_trips_window_30m_dropoff_zip INT,
dropoff_is_weekend INT,
CONSTRAINT trip_dropoff_time_series_features_pk PRIMARY KEY (zip, ts TIMESERIES)
)
COMMENT "タクシー料金。ドロップオフ時系列特徴量";
初期特徴量をUnity Catalogの特徴量テーブルに書き込む
特徴量エンジニアリングクライアントのインスタンスを作成します。
from databricks.feature_engineering import FeatureEngineeringClient
fe = FeatureEngineeringClient()
Unity Catalogの特徴テーブルに特徴量を書き込むためにwrite_table APIを使用します。
時系列特徴量テーブルに書き込むためには、DataFrameに時系列の列として指定する列が含まれている必要があります。
spark.conf.set("spark.sql.shuffle.partitions", "5")
fe.write_table(
name="takaakiyayoi_catalog.taxi_example.trip_pickup_time_series_features",
df=pickup_features
)
fe.write_table(
name="takaakiyayoi_catalog.taxi_example.trip_dropoff_time_series_features",
df=dropoff_features
)
特徴量テーブルが作成され、データが登録されます。

特徴量の更新
write_table関数を使用して特徴テーブルの値を更新します。
display(raw_data)

以下を実行して、2月分のデータをマージします。
# 新しいバッチのpickup_features特徴量グループを計算します。
new_pickup_features = pickup_features_fn(
df=raw_data,
ts_column="tpep_pickup_datetime",
start_date=datetime(2016, 2, 1),
end_date=datetime(2016, 2, 29),
)
# 新しいpickup features DataFrameを特徴量テーブルに書き込みます
fe.write_table(
name="takaakiyayoi_catalog.taxi_example.trip_pickup_time_series_features",
df=new_pickup_features,
mode="merge",
)
# 新しいバッチのdropoff_features特徴量グループを計算します。
new_dropoff_features = dropoff_features_fn(
df=raw_data,
ts_column="tpep_dropoff_datetime",
start_date=datetime(2016, 2, 1),
end_date=datetime(2016, 2, 29),
)
# 新しいdropoff features DataFrameを特徴量テーブルに書き込みます
fe.write_table(
name="takaakiyayoi_catalog.taxi_example.trip_dropoff_time_series_features",
df=new_dropoff_features,
mode="merge",
)
書き込み時には、mergeモードがサポートされています。
fe.write_table(
name="ml.taxi_example.trip_pickup_time_series_features",
df=new_pickup_features,
mode="merge",
)
データは、df.isStreamingがTrueに設定されているデータフレームを渡すことで、特徴量テーブルにストリーミングすることもできます:
fe.write_table(
name="ml.taxi_example.trip_pickup_time_series_features",
df=streaming_pickup_features,
mode="merge",
)
Databricks Jobsを使用してノートブックを定期的に更新するようにスケジュールすることができます (AWS|Azure|GCP)。
アナリストは、例えば次のようにSQLを使用してUnity Catalogの特徴量テーブルと対話できます:
%sql
SELECT
SUM(count_trips_window_30m_dropoff_zip) AS num_rides,
dropoff_is_weekend
FROM
takaakiyayoi_catalog.taxi_example.trip_dropoff_time_series_features
WHERE
dropoff_is_weekend IS NOT NULL
GROUP BY
dropoff_is_weekend;

特徴量の検索と発見
Unity CatalogのFeatures UIで特徴量テーブルを発見できます。"takaakiyayoi_catalog.taxi_example.trip_pickup_time_series_features"または"takaakiyayoi_catalog.taxi_example.trip_dropoff_time_series_features"で検索し、テーブル名をクリックすると、カタログエクスプローラーUIでテーブルスキーマ、メタデータ、リネージなどの詳細を確認できます。また、特徴量テーブルの説明を編集することもできます。特徴量の発見とリネージの追跡についての詳細は、(AWS|Azure|GCP)をご覧ください。
カタログエクスプローラーUIで特徴量テーブルの権限を設定することもできます。詳細は、(AWS|Azure|GCP)をご覧ください。

モデルのトレーニング
このセクションでは、時系列のピックアップおよびドロップオフ特徴量テーブルを使用してポイントインタイムルックアップを行い、トレーニングセットを作成してモデルをトレーニングする方法を説明します。タクシー料金を予測するためにLightGBMモデルをトレーニングします。
ヘルパー関数
import mlflow.pyfunc
def get_latest_model_version(model_name):
latest_version = 1
mlflow_client = MlflowClient()
for mv in mlflow_client.search_model_versions(f"name='{model_name}'"):
version_int = int(mv.version)
if version_int > latest_version:
latest_version = version_int
return latest_version
トレーニングデータセットの作成方法の理解
モデルをトレーニングするためには、モデルのトレーニングに使用されるトレーニングデータセットを作成する必要があります。トレーニングデータセットは以下の要素で構成されています:
- 生の入力データ
- Unity Catalog内の特徴量テーブルからの特徴量
生の入力データは以下の理由で必要です:
- プライマリキーと時系列カラムは、特徴量との結合に使用され、ポイントインタイムの正確性を持たせます (AWS|Azure|GCP).
- 特徴量テーブルに存在しない
trip_distanceのような生の特徴量です。 - モデルのトレーニングに必要な
fareのような予測対象です。
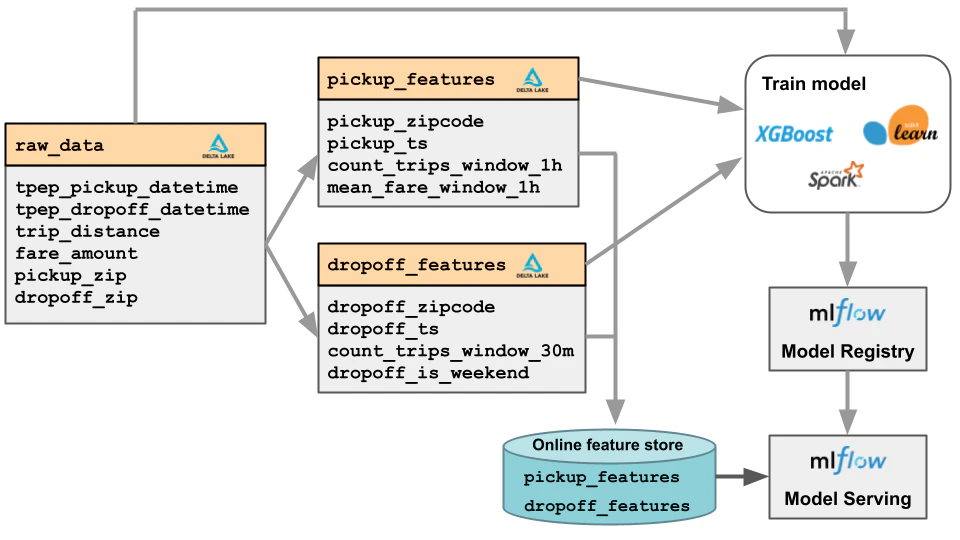
以下の図は、生の入力データがUnity Catalogの特徴量と組み合わさってトレーニングデータセットを生成する様子を示しています:

これらの概念は、トレーニングデータセットの作成に関するドキュメントで詳しく説明されています (AWS|Azure|GCP).
次のセルでは、モデルのトレーニングにUnity Catalogから特徴量をロードするために、必要な特徴量ごとにFeatureLookupを作成しています。
時系列特徴量テーブルから特徴量の値をポイントインタイムでルックアップするには、フィーチャーのFeatureLookupでtimestamp_lookup_keyを指定する必要があります。これは、タイムスタンプを含むDataFrameの列の名前を示し、DataFrameの各行に対して、指定されたタイムスタンプの前の最新の特徴量の値が取得されます。取得される特徴量の値は、DataFrameのlookup_key列の値と一致するプライマリキーを持つものであり、該当する特徴量の値が存在しない場合はnullとなります。
from databricks.feature_engineering import FeatureLookup
import mlflow
pickup_features_table = "takaakiyayoi_catalog.taxi_example.trip_pickup_time_series_features"
dropoff_features_table = "takaakiyayoi_catalog.taxi_example.trip_dropoff_time_series_features"
pickup_feature_lookups = [
FeatureLookup(
table_name=pickup_features_table,
feature_names=[
"mean_fare_window_1h_pickup_zip",
"count_trips_window_1h_pickup_zip",
],
lookup_key=["pickup_zip"],
timestamp_lookup_key="tpep_pickup_datetime",
),
]
dropoff_feature_lookups = [
FeatureLookup(
table_name=dropoff_features_table,
feature_names=["count_trips_window_30m_dropoff_zip", "dropoff_is_weekend"],
lookup_key=["dropoff_zip"],
timestamp_lookup_key="tpep_dropoff_datetime",
),
]
Unity CatalogのモデルにアクセスするためのMLflowクライアントの設定
import mlflow
mlflow.set_registry_uri("databricks-uc")
fe.create_training_set(..)が呼び出されると、以下のステップが実行されます:
-
TrainingSetオブジェクトが作成され、モデルのトレーニングに使用する特定の特徴量が特徴量テーブルから選択されます。各特徴量は、以前に作成されたFeatureLookupによって指定されます。 -
特徴量は各
FeatureLookupのlookup_keyに従って生の入力データと結合されます。 -
データリークの問題を避けるために、ポイントインタイムルックアップが適用されます。
timestamp_lookup_keyに基づいて、最新の特徴量の値のみが結合されます。
その後、TrainingSetはトレーニング用のDataFrameに変換されます。このDataFrameには、taxi_dataの列と、FeatureLookupsで指定された特徴量が含まれます。
# 既存のランを終了します(このノートブックが2回目以降に実行されている場合)
mlflow.end_run()
# モデルをログに記録するためにmlflowランを開始します
mlflow.start_run()
# タイムスタンプ列は追加の特徴量エンジニアリングが行われない限り、モデルがデータに過剰適合する可能性が高いため、
# それらを除外してトレーニングを避けます。
exclude_columns = ["tpep_pickup_datetime", "tpep_dropoff_datetime"]
# 生データと両方の特徴量テーブルからの対応する特徴量をマージしたトレーニングセットを作成します
training_set = fe.create_training_set(
df=raw_data,
feature_lookups=pickup_feature_lookups + dropoff_feature_lookups,
label="fare_amount",
exclude_columns=exclude_columns,
)
# sklearnでモデルをトレーニングするために渡すことができるデータフレームにTrainingSetをロードします
training_df = training_set.load_df()
# トレーニングデータフレームを表示します。生データと特徴量テーブルからの特徴量(例えば `dropoff_is_weekend`)の両方が含まれていることに注意してください
display(training_df)

TrainingSet.to_df によって返されるデータで LightGBM モデルをトレーニングし、FeatureEngineeringClient.log_model でモデルをログに記録します。モデルは特徴量メタデータと共にパッケージ化されます。
from sklearn.model_selection import train_test_split
from mlflow.tracking import MlflowClient
import lightgbm as lgb
import mlflow.lightgbm
from mlflow.models.signature import infer_signature
features_and_label = training_df.columns
# トレーニングのためにデータをPandas配列に収集します
data = training_df.toPandas()[features_and_label]
train, test = train_test_split(data, random_state=123)
X_train = train.drop(["fare_amount"], axis=1)
X_test = test.drop(["fare_amount"], axis=1)
y_train = train.fare_amount
y_test = test.fare_amount
mlflow.lightgbm.autolog()
train_lgb_dataset = lgb.Dataset(X_train, label=y_train.values)
test_lgb_dataset = lgb.Dataset(X_test, label=y_test.values)
param = {"num_leaves": 32, "objective": "regression", "metric": "rmse"}
num_rounds = 100
# lightGBMモデルをトレーニングします
model = lgb.train(param, train_lgb_dataset, num_rounds)
# トレーニング済みモデルをMLflowでログし、特徴量ルックアップ情報と共にパッケージ化します。
fe.log_model(
model=model,
artifact_path="model_packaged",
flavor=mlflow.lightgbm,
training_set=training_set,
registered_model_name="takaakiyayoi_catalog.taxi_example.taxi_example_fare_time_series_packaged",
)
カタログエクスプローラーでモデルのリネージを確認
カタログエクスプローラーのテーブル詳細ページにアクセスします。「リネージ」タブに移動し、「リネージグラフを表示」をクリックします。特徴量テーブルに下流のモデルリネージが表示されます。

カスタム PyFunc モデルの構築とログ
バッチ推論で前処理や後処理のコードをモデルに追加し、処理された予測を生成するには、これらのメソッドをカプセル化するカスタム PyFunc MLflow モデルを構築できます。次のセルは、モデルからの数値予測に基づいて文字列出力を返す例を示しています。
class fareClassifier(mlflow.pyfunc.PythonModel):
def __init__(self, trained_model):
self.model = trained_model
def preprocess_result(self, model_input):
return model_input
def postprocess_result(self, results):
"""後処理された結果を返します。
運賃範囲のセットを作成し、
予測された範囲を返します。"""
return [
"$0 - $9.99" if result < 10 else "$10 - $19.99" if result < 20 else " > $20"
for result in results
]
def predict(self, context, model_input):
processed_df = self.preprocess_result(model_input.copy())
results = self.model.predict(processed_df)
return self.postprocess_result(results)
pyfunc_model = fareClassifier(model)
# 現在のMLflowランを終了し、新しいpyfuncモデルをログするために新しいランを開始します
mlflow.end_run()
with mlflow.start_run() as run:
fe.log_model(
model=pyfunc_model,
artifact_path="pyfunc_packaged_model",
flavor=mlflow.pyfunc,
training_set=training_set,
registered_model_name="takaakiyayoi_catalog.taxi_example.pyfunc_taxi_fare_time_series_packaged",
)
スコアリング: バッチ推論
別のデータサイエンティストがこのモデルを別のデータバッチに適用したいとします。
推論に使用するデータを表示し、予測対象である fare_amount 列を強調するように並べ替えます。

score_batch APIを使用して、Unityカタログ内のFeature Engineeringから必要な特徴量を取得し、データのバッチ上でモデルを評価します。
時系列特徴テーブルからの特徴量を使用してトレーニングされたモデルをスコアリングする場合、適切な特徴量はトレーニング中にモデルとパッケージ化されたメタデータを使用してポイントインタイムのルックアップが行われます。FeatureEngineeringClient.score_batchに提供するDataFrameには、FeatureEngineeringClient.create_training_setに提供されるFeatureLookupのtimestamp_lookup_keyと同じ名前とDataTypeのタイムスタンプ列が含まれている必要があります。
# モデルURIを取得します
latest_model_version = get_latest_model_version(
"takaakiyayoi_catalog.taxi_example.taxi_example_fare_time_series_packaged"
)
model_uri = f"models:/takaakiyayoi_catalog.taxi_example.taxi_example_fare_time_series_packaged/{latest_model_version}"
# score_batchを呼び出してモデルから予測を取得します
with_predictions = fe.score_batch(model_uri=model_uri, df=new_taxi_data)
display(with_predictions)

ログに記録されたPyFuncモデルを使用してスコアリングするには:
latest_pyfunc_version = get_latest_model_version(
"takaakiyayoi_catalog.taxi_example.pyfunc_taxi_fare_time_series_packaged"
)
pyfunc_model_uri = (
f"models:/takaakiyayoi_catalog.taxi_example.pyfunc_taxi_fare_time_series_packaged/{latest_pyfunc_version}"
)
pyfunc_predictions = fe.score_batch(
model_uri=pyfunc_model_uri, df=new_taxi_data, result_type="string"
)
display(pyfunc_predictions)
predictionに後処理が施されていることがわかります。


タクシー料金予測の表示
このコードは、タクシー料金予測を最初の列に表示するように列を並べ替えます。 predicted_fare_amount は実際の fare_amount と大まかに一致しますが、モデルの精度を向上させるには、より多くのデータと特徴エンジニアリングが必要です。
import pyspark.sql.functions as func
cols = [
"prediction",
"fare_amount",
"trip_distance",
"pickup_zip",
"dropoff_zip",
"tpep_pickup_datetime",
"tpep_dropoff_datetime",
"mean_fare_window_1h_pickup_zip",
"count_trips_window_1h_pickup_zip",
"count_trips_window_30m_dropoff_zip",
"dropoff_is_weekend",
]
with_predictions_reordered = (
with_predictions.select(
cols,
)
.withColumnRenamed(
"prediction",
"predicted_fare_amount",
)
.withColumn(
"predicted_fare_amount",
func.round("predicted_fare_amount", 2),
)
)
display(with_predictions_reordered)

PyFunc予測の表示
display(pyfunc_predictions.select("fare_amount", "prediction"))

次のステップ
- この例で作成された特徴量テーブルを特徴量UIで探索する。
- 特徴量テーブルをオンラインストアに公開する (AWS|Azure)。
- Unity CatalogでモデルをデプロイしてModel Servingを行う (AWS|Azure).
- このノートブックを自分のデータに適用し、独自の特徴量テーブルを作成する。