こちらのサンプルノートブックをウォークスルーします。
しばらく見ないうちに、Feature StoreのテーブルもUnity Catalogで管理できるようになってました。
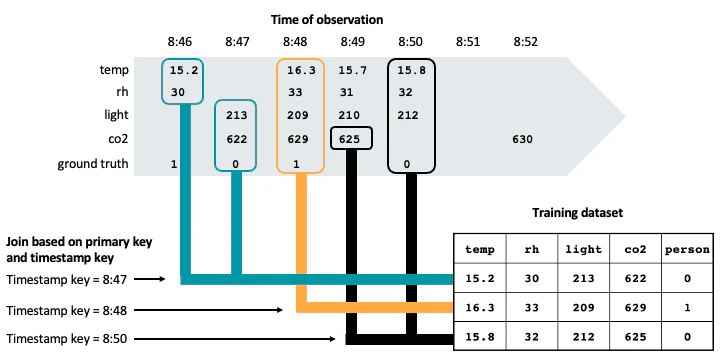
ポイントインタイムという概念自体、良くわかっていませんでしたがマニュアルにあるように、時系列データのjoinを行う際にある時点(AS OF)での最新のデータを用いるという考え方だそうで。確かに、センサーデータなどはどのタイミングで取得できるかを制御することは困難ですし、同じタイミングでjoinしてもjoinのしようがないことを考えると合理的なソリューションと言えます。
サンプルノートブックはUnity Catalog前提ではないので、特徴量テーブルがUnity Catalogで管理されるように適宜修正しています。
Feature Storeの時系列特徴量テーブル
このノートブックでは、シミュレーションされたInternet of Things (IoT)センサーデータから時系列特徴量テーブルを作成します。その後で以下を実施します:
- 時系列特徴量テーブルに対するpoint-in-timeルックアップを行うことでトレーニングセットを生成
- モデルのトレーニングにトレーニングセットを使用
- モデルの登録
- 新規センサーデータに対するバッチ推論の実行
要件
- Databricks機械学習ランタイム10.4 LTS以降
注意: Databricks Runtime 13.2 ML以降では、create_table APIに変更が加えられています。タイムスタンプキーのカラムは、引数primary_keysで指定される必要があります。このノートブックでDatabricks Runtime 13.1 ML以前を使用している場合には、Cmd 9でコメントアウトされているcreate_tableの呼び出しのコードを使ってください。
背景
このノートブックで使用するデータは次のようなシチュエーションを表現するためにシミュレーションされています: 倉庫の様々な部屋に設置された一連のIoTセンサーから読み取り値があるものとします。あなたは、人が部屋に入った際に検知するモデルをトレーニングするためにこのデータを活用したいと考えています。それぞれの部屋には、温度センサー、光センサー、CO2センサーがあり、それぞれは異なる周期でデータを記録します。
catalog_name = "takaakiyayoi_catalog"
database_name = "anomaly_detection"
model_name = "pit_demo_model"
print(f"Catalog name: {catalog_name}")
print(f"Database name: {database_name}")
print(f"Model name: {model_name}")
spark.sql(f"USE {catalog_name}.{database_name}")
シミュレートされたデータセットの生成
このステップでは、シミュレートされたデータセットを生成し、光センサー、温度センサー、CO2センサー、正解データを含む4つのSparkデータフレームを作成します。
# 必要なライブラリをインポート
from pyspark.sql.functions import *
# センサーの閾値を設定
wavelength_lo, wavelength_hi = 209.291, 213.111
ppm_lo, ppm_hi = 35, 623.99
temp_lo, temp_hi = 15.01, 25.99
humidity_lo, humidity_hi = 35.16, 43.07
# 部屋に人がいるかどうかを判断する関数
def is_person_in_the_room(wavelength, ppm, temp, humidity):
return (
(wavelength < (wavelength_lo + (wavelength_hi - wavelength_lo) * .45)) &
(ppm > (.9 * ppm_hi)) &
(temp > ((temp_hi + temp_lo) / 2)) &
(humidity > (humidity_hi * .6))
)
# データセットを生成する関数
def generate_dataset(start, end):
# センサーデータフレームを生成する内部関数
def generate_sensor_df(features):
return pd.DataFrame({
'room': np.random.choice(3, end-start),
'ts': start + np.random.choice(end-start, end-start, replace=False) + np.random.uniform(-0.99, 0.99, end-start),
**features
}).sort_values(by=['ts'])
# 各センサーのデータフレームを生成
wavelength_df = generate_sensor_df({
'wavelength': np.random.normal(np.mean([wavelength_lo, wavelength_hi]), 2, end-start),
})
temp_df = generate_sensor_df({
'temp': np.random.normal(np.mean([temp_lo, temp_hi]), 4, end-start),
'humidity': np.random.normal(np.mean([humidity_lo, humidity_hi]), 2, end-start),
})
# CO2濃度のデータを生成
ppm_bern = np.random.binomial(1, 0.3, end-start)
ppm_normal_1 = np.random.normal(ppm_lo, 8, end-start)
ppm_normal_2 = np.random.normal(ppm_hi, 3, end-start)
ppm_df = generate_sensor_df({
'ppm': ppm_bern*ppm_normal_1+(1-ppm_bern)*ppm_normal_2
})
# 統合データフレームを生成
df = pd.DataFrame({
'room': np.random.choice(3, end-start),
'ts': np.random.uniform(start, end, end-start)
}).sort_values(by=['ts'])
for right_df in [wavelength_df, ppm_df, temp_df]:
df = pd.merge_asof(
df,
right_df,
on='ts',
by='room'
)
df['person'] = is_person_in_the_room(df['wavelength'], df['ppm'], df['temp'], df['humidity'])
# センサーデータにノイズを追加
wavelength_df['wavelength'] += np.random.uniform(-1, 1, end-start) * 0.2
ppm_df['ppm'] += np.random.uniform(-1, 1, end-start) * 2
temp_df['temp'] += np.random.uniform(-1, 1, end-start)
temp_df['humidity'] += np.random.uniform(-1, 1, end-start)
# Sparkデータフレームに変換
light_sensors = spark.createDataFrame(wavelength_df) \
.withColumn("ts", col("ts").cast('timestamp')) \
.select(col("room").alias("r"), col("ts").alias("light_ts"), col("wavelength"))
temp_sensors = spark.createDataFrame(temp_df) \
.withColumn("ts", col("ts").cast('timestamp')) \
.select("room", "ts", "temp", "humidity")
co2_sensors = spark.createDataFrame(ppm_df) \
.withColumn("ts", col("ts").cast('timestamp')) \
.select(col("room").alias("r"), col("ts").alias("co2_ts"), col("ppm"))
ground_truth = spark.createDataFrame(df[['room', 'ts', 'person']]) \
.withColumn("ts", col("ts").cast('timestamp'))
return temp_sensors, light_sensors, co2_sensors, ground_truth
# データセットを生成
temp_sensors, light_sensors, co2_sensors, ground_truth = generate_dataset(1458031648, 1458089824)
# 温度データに微調整を加える
fixed_temps = temp_sensors.select("room", "ts", "temp").sample(False, 0.01).withColumn("temp", temp_sensors.temp + 0.25)
# 生成したデータフレームの確認
# 部屋ごとの温度/湿度センサーの読み取り値
display(temp_sensors.limit(3))
# それぞれの部屋の光センサーの読み取り値
display(light_sensors.limit(3))
# それぞれの部屋のCO2センサーの読み取り値
display(co2_sensors.limit(3))
# 部屋に人がいた際の正解データ
display(ground_truth.limit(3))

時系列特徴量テーブルの作成
このステップでは、時系列特徴量テーブルを作成します。それぞれのテーブルでは、部屋を主キーとして使用します。
from databricks.feature_store.client import FeatureStoreClient
from databricks.feature_store.entities.feature_lookup import FeatureLookup
fs = FeatureStoreClient()
# roomを主キーとし、timeをタイムスタンプキーとして用いることで、温度センサーデータの時系列特徴量テーブルを作成します。
# Databricks Runtime 13.2 for Machine Learning以降:
fs.create_table(
f"{database_name}.temp_sensors",
primary_keys=["room", "ts"],
timestamp_keys=["ts"],
df=temp_sensors,
description="温度、湿度センサーの読み取り値",
)
# For Databricks Runtime 13.1 for Machine Learning or below:
# fs.create_table(
# f"{database_name}.temp_sensors",
# primary_keys=["room"],
# timestamp_keys=["ts"],
# df=temp_sensors,
# description="Readings from temperature and humidity sensors",
# )
# roomを主キーとし、timeをタイムスタンプキーとして用いることで、光センサーデータの時系列特徴量テーブルを作成します。
# Databricks Runtime 13.2 for Machine Learning以降:
fs.create_table(
f"{database_name}.light_sensors",
primary_keys=["r", "light_ts"],
timestamp_keys=["light_ts"],
df=light_sensors,
description="光センサーの読み取り値",
)
# For Databricks Runtime 13.1 for Machine Learning or below:
# fs.create_table(
# f"{database_name}.light_sensors",
# primary_keys=["r"],
# timestamp_keys=["light_ts"],
# df=light_sensors,
# description="Readings from light sensors",
# )
# roomを主キーとし、timeをタイムスタンプキーとして用いることで、CO2センサーデータの時系列特徴量テーブルを作成します。
# Databricks Runtime 13.2 for Machine Learning以降:
fs.create_table(
f"{database_name}.co2_sensors",
primary_keys=["r", "co2_ts"],
timestamp_keys=["co2_ts"],
df=co2_sensors,
description="Readings from CO2 sensors",
)
# For Databricks Runtime 13.1 for Machine Learning or below:
# fs.create_table(
# f"{database_name}.co2_sensors",
# primary_keys=["r"],
# timestamp_keys=["co2_ts"],
# df=co2_sensors,
# description="Readings from CO2 sensors",
# )
これで、時系列特徴量テーブルがFeature Store UIに表示されるようになります。これらの特徴量テーブルでは、Timestamp Keysフィールドが埋められています。
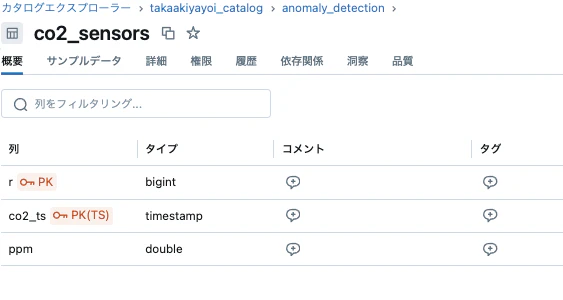
時系列特徴量テーブルの更新
特徴量テーブルを作成した後に更新された値を受信したものとします。例えば、いくつかの温度センサーの読み取り値が不適切に処理され、温度時系列特徴量テーブルの更新が必要になった場合などです。
display(fixed_temps.limit(3))
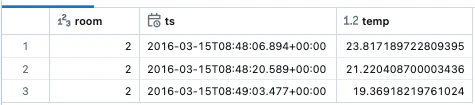
時系列特徴量テーブルにデータフレームを書き込む際、データフレームでは特徴量テーブルのすべての特徴量を指定する必要があります。時系列特徴量テーブルの単一の特徴量を更新するには、はじめに主キーとタイムスタンプキーを指定して、テーブルの他の特徴量と更新された特徴量のカラムをjoinする必要があります。すると、特徴量を更新できるようになります。
temp_ft = fs.read_table(f"{database_name}.temp_sensors").drop('temp')
temp_update_df = fixed_temps.join(temp_ft, ["room", "ts"])
fs.write_table(f"{database_name}.temp_sensors", temp_update_df, mode="merge")
時系列特徴量テーブルに対するpoint-in-timeルックアップを用いたトレーニングセットの作成
このステップでは、時系列特徴量テーブルのセンサーデータに対するpoint-in-timeルックアップを実行することで、正解データを用いたトレーニングセットを作成します。
point-in-timeルックアップでは、正解データで指定されている部屋の正解データで示されているタイムスタンプ時点での最新のセンサーの値を取得します。
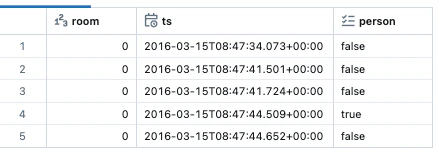
training_labels, test_labels = ground_truth.randomSplit([0.75, 0.25])
display(training_labels.limit(5))
# トレーニングセットの特徴量を定義するpoint-in-timeルックアップを作成します。それぞれのpoint-in-timeルックアップには、 `lookup_key` と `timestamp_lookup_key` を含める必要があります。
feature_lookups = [
FeatureLookup(
table_name=f"{database_name}.temp_sensors",
feature_names=["temp", "humidity"],
rename_outputs={
"temp": "room_temperature",
"humidity": "room_humidity"
},
lookup_key="room",
timestamp_lookup_key="ts"
),
FeatureLookup(
table_name=f"{database_name}.light_sensors",
feature_names=["wavelength"],
rename_outputs={"wavelength": "room_light"},
lookup_key="room",
timestamp_lookup_key="ts",
),
FeatureLookup(
table_name=f"{database_name}.co2_sensors",
feature_names=["ppm"],
rename_outputs={"ppm": "room_co2"},
lookup_key="room",
timestamp_lookup_key="ts",
),
]
training_set = fs.create_training_set(
training_labels,
feature_lookups=feature_lookups,
exclude_columns=["room", "ts"],
label="person",
)
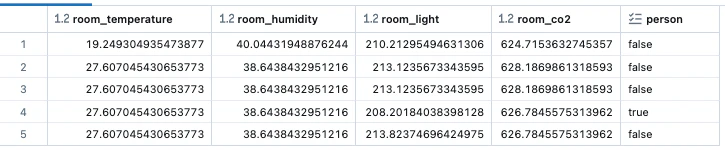
training_df = training_set.load_df()
display(training_df.limit(5))
モデルのトレーニング
features_and_label = training_df.columns
training_data = training_df.toPandas()[features_and_label]
X_train = training_data.drop(["person"], axis=1)
y_train = training_data.person.astype(int)
import lightgbm as lgb
import mlflow.lightgbm
from mlflow.models.signature import infer_signature
mlflow.lightgbm.autolog()
model = lgb.train(
{"num_leaves": 32, "objective": "binary"},
lgb.Dataset(X_train, label=y_train.values),
5
)
# モデルレジストリにモデルを登録
# `log_model`を使用すると、機能メタデータがパッケージ化され、推論時にFeature Storeから特徴量を自動的に取得します
fs.log_model(
model,
artifact_path="model_packaged",
flavor=mlflow.lightgbm,
training_set=training_set,
registered_model_name=model_name
)
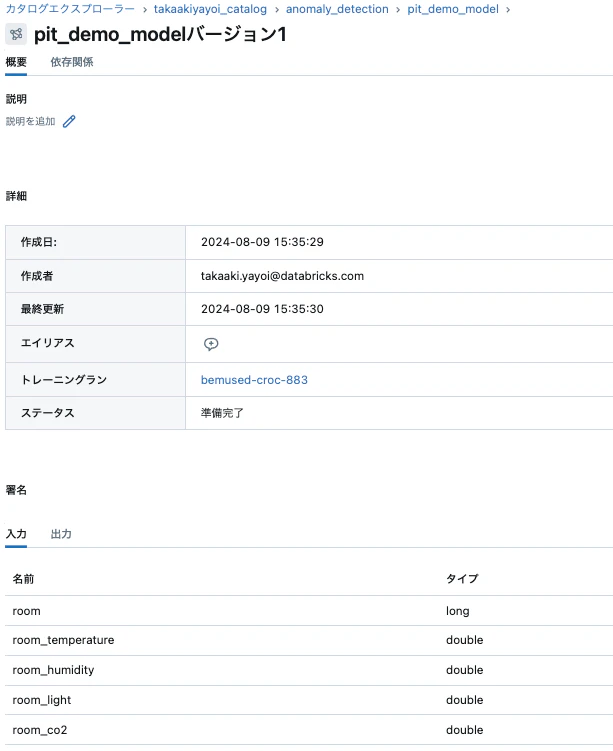
Unity Catalog配下にモデルが登録されます。
時系列特徴量テーブルに対するpoint-in-timeルックアップによるデータのスコアリング
スコアリング時に同じルックアップを行うように、トレーニングセットの作成時に指定されたpoint-in-timeルックアップのメタデータはモデルにパッケージされます。
from mlflow.tracking import MlflowClient
def get_latest_model_version(model_name):
latest_version = 1
mlflow_client = MlflowClient()
for mv in mlflow_client.search_model_versions(f"name='{model_name}'"):
version_int = int(mv.version)
if version_int > latest_version:
latest_version = version_int
return latest_version
latest_version = get_latest_model_version(f"{catalog_name}.{database_name}.{model_name}")
scored = fs.score_batch(
f"models:/{catalog_name}.{database_name}.{model_name}/{latest_version}",
test_labels,
result_type="float",
)
from pyspark.sql.types import BooleanType
classify_udf = udf(lambda pred: pred > 0.5, BooleanType())
class_scored = scored.withColumn("person_prediction", classify_udf(scored.prediction))
display(class_scored.limit(5))

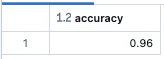
精度を確認します。
from pyspark.sql.functions import avg, round
display(class_scored.select(round(avg((class_scored.person_prediction == class_scored.person).cast("int")), 3).alias("accuracy")))
結構な精度で検知できています。