Introducing Mixtral 8x7B with Databricks Model Serving | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
注意
本書で説明されている機能は、翻訳時点では日本リージョンで利用できないものが含まれています。
本日、モデルサービングでのMixtral 8x7Bのサポートを発表できることを嬉しく思っています。Mixtral 8x7Bは、数多くの最先端のモデルと比類するあるいは上回る性能を示す疎結合のMixture of Experts (MoE)のオープン言語モデルです。最大32kのトークンからなる長いコンテキスト対応しており、そのMoEアーキテクチャは推論が高速であり、Retrieval-Augmented Generation (RAG)やその他のエンタープライズユースケースにおいて理想的なものとなります。
Databricksモデルサービングでは、プロダクションレベルかつ企業利用可能なプラットフォームでオンデマンド課金ですぐにMixtral 8x7Bを利用できるようになっています。我々は秒間数千のクエリーをサポートしており、ベクトルストアとのシームレスなインテグレーション、自動化された品質モニタリング、統合されたガバナンス、稼働時間に関するSLAを提供しています。このエンドツーエンドのインテグレーションによって、生成AIシステムをプロダクションに投入する高速なパスを提供します。
Mixture of Expertsモデルとは?
Mixtral 8x7Bでは、Llama2のようなモデルで使用されている密結合のGPTライクのアーキテクチャよりも非常に進んでいると考えられているMoEアーキテクチャを採用しています。GPTライクのモデルでは、それぞれのブロックはアテンションレイヤーとフィードフォワードレイヤーを構成しています。MoEモデルにおけるフィードフォワードレイヤーは、それぞれが「エキスパート」と知られている複数の並列サブレイヤーから構成され、その前にはどのエキスパートにトークンを送信するのかを決定する「ルーター」ネットワークが構成されています。特定のトークンに対してMoEモデルのすべてのパラメーターがアクティブになる訳では無いので、MoEモデルは「疎な」アーキテクチャと考えられます。以下の図では、switch transformersに関する実践的な論文で図的に説明されているものです。研究コミュニティにおいては、それぞれのエキスパートがデータの特定の観点や領域に特化するものと広く受け止められています[Shazeer et al.]。
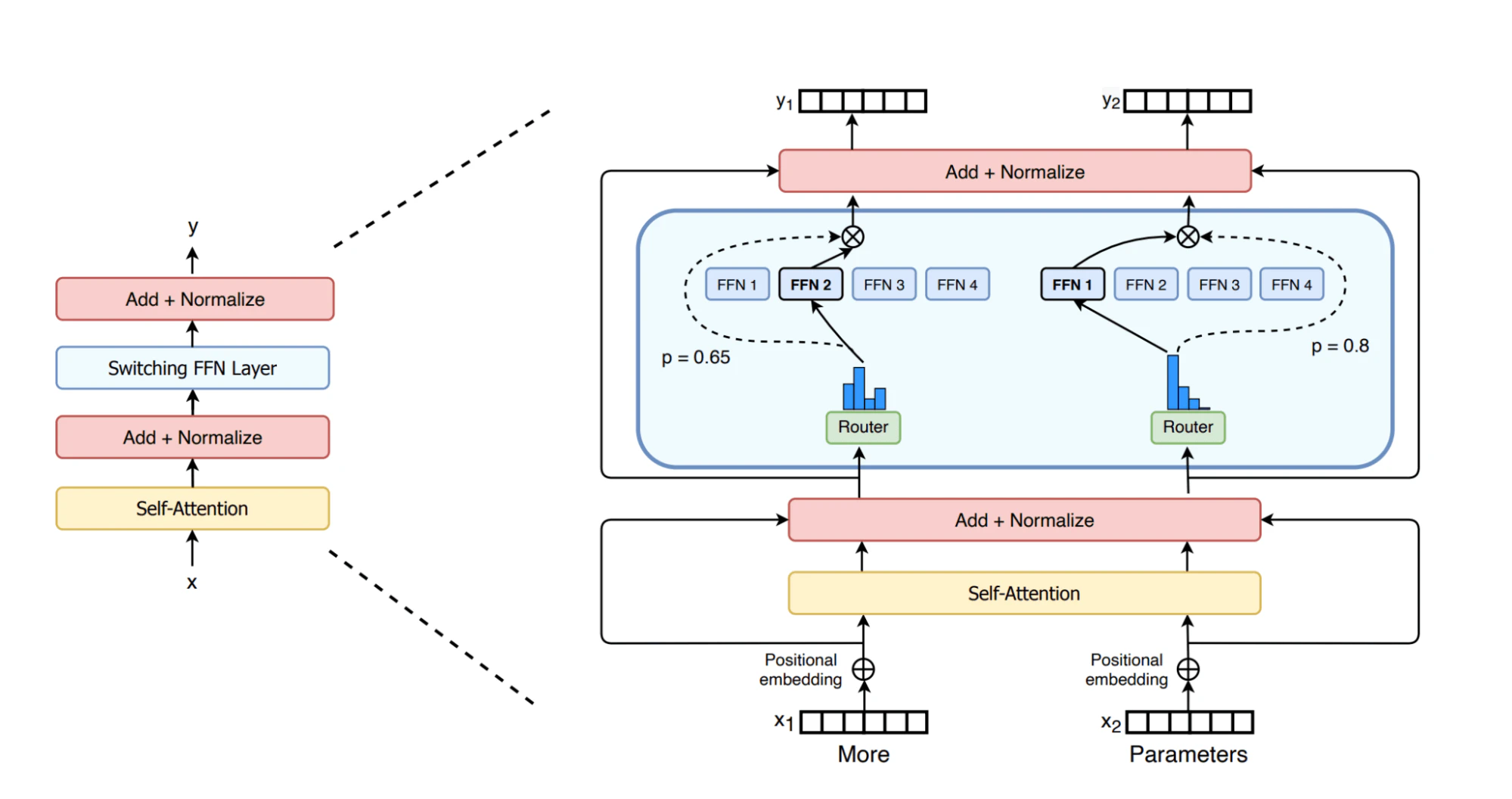
ソース: Fedus, Zoph, and Shazeer, JMLR 2022
MoEアーキテクチャの大きなメリットは、密なモデルで必要となる推論時の計算処理の線形的な増加なしに、モデルのサイズをスケールできるということです。MoEモデルにおいては、それぞれの入力トークンは、利用可能なエキスパートで選択されたサブセット(例: Mixtral 8x7Bではトークンごとに2つのエキスパート)でのみ処理されるので、トレーニングや推論の際にそれぞれのトークンに対して行われる計算処理の量を最小化することができます。また、MoEモデルはエキスパートとしてフィードフォワードレイヤーのみを取り扱いながらも、残りのパラメーターを共有するので、Mistral 8x7Bは名前のように56Bのパラメータではなく47Bのパラメータモデルとなっています。しかし、それぞれのトークンは、ライブパラメータとして知られる約13Bパラメータを用いてのみ計算処理を行います。同等の47Bの密なモデルはフォワードの経路で94B(2 * パラメーター数)のFLOPを必要としますが、Mixtralモデルはフォワード経路では26B(2 * ライブパラメーター数)のオペレーションしか必要としません。これは、Mixtralの推論は13Bモデルと同じくらいに高速であり、47Bやさらに大規模な密なモデルと同等の品質を提供することを意味します。
MoEモデルは一般的にトークンあたりの計算量は少なくて済みますが、それらの推論時のパフォーマンスに関するニュアンスはさらに複雑なものとなります。同等のサイズの密モデルに対するMoEモデルの効率性のゲインは、処理されるデータバッチのサイズによって変動します。例えば、Mixtralの推論が大規模なバッチサイズに対して計算処理に制限がある場合、密モデルよりも3.6倍ほどのスピードアップを期待することができます。一方で、小規模なバッチサイズで帯域に制限がある場合には、この最大の増加率よりもスピードアップのゲインは少なくなります。以前のブログ記事ではこれらのコンセプトにより詳細に踏み込んでおり、小規模なバッチサイズでは帯域の制約を受けやすく、大規模なバッチサイズでは計算資源に制限を受けやすくなるのかを説明しています。
シンプルかつプロダクションレベルのMixtral 8x7B向けのAPI
Foundation Model APIによるMixtral 8x7Bへの即座のアクセス
Databricksモデルサービングでは、Foundation Model API経由でMixtral 8x7Bにすぐにアクセスできるようになっています。Foundation Model APIはトークン数あたりの課金で利用することができ、コストを劇的に削減しつつも柔軟性を増加させることができます。Foundation Model APIはDatabricksのインフラストラクチャで提供されているので、あなたのデータがサードパーティサービスを経由することはありません。
また、Foundation Model APIは、一貫性のあるパフォーマンス保証を提供し、ファインチューニングされたモデルや高いQPSトラフィックをサポートするためにMixtral 8x7Bにフィーチャーされたスループットを提供しています。
他のモデルとMixtral 8x7Bを容易に比較、管理
他の基盤モデルと同様に統合されたAPIやSDKを用いてMixtral 8x7Bにアクセスすることができます。この統合されたインタフェースによって、いかなるクラウド、プロバイダーが提供している基盤モデルを実験、カスタマイズ、プロダクション化することが可能となります。
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
inputs = {
"messages": [
{
"role": "user",
"content": "List 3 reasons why you should train an AI model on domain specific data sets? No explanations required."
}
],
"max_tokens": 64,
"temperature": 0
}
response = client.predict(endpoint="databricks-mixtral-8x7b-instruct", inputs=inputs)
print(response["choices"][0]['message']['content'])
また、ai_query SQL関数を用いてSQLから直接モデルの推論を行うことができます。詳細はai_queryのドキュメントをご覧ください。
SELECT ai_query(
'databricks-mixtral-8x7b-instruct',
'Describe Databricks SQL in 30 words.'
) AS chat
Databricks内でホスティングされていようが、外でホスティングされていようが、お使いのすべてのモデルは一箇所にあるので、すべてのタイプのモデルの権限の管理、利用料制限の追跡、品質の監視を集中化することができます。これによって、新たなモデルがリリースされたとしても、適切なガードレイルを設置しつつも、追加のセットアップのコストや継続的なアップデートで負荷が生じることなしに、新規モデルのメリットを容易に生み出すことが可能となります。
“DatabricksのFoundation Model APIによってボタンひとつ押すだけで最先端のオープンなモデルに問い合わせを行うことができるので、計算資源をこねくり回すのではなく我々のお客様にフォーカスできるようになりました。プラットフォームでは複数のモデルを活用していますが、これまでに体験した安定性や信頼性、チケットをあげた際のサポートに感銘を受けています。” - Sidd Seethepalli, CTO & Founder, Vellum
最新のモデルを最適なパフォーマンスで提供するというDatabricksのコミットで常に最先端に
Databricksでは、最適化された推論処理を用いてベストかつ最新のオープンのモデルにアクセスできるようにすることに力を注いでいます。このアプローチは、それぞれのタスクに最も適したモデルを選択する柔軟性を提供し、さまざまな方向性で拡張を続けるモデルにおいて新たに生じる開発の最先端を走り続けられることを保証します。皆様が最短のレーテンシーやTotal Cost of Ownership (TCO)の削減を教示し続けられるように、さらなる最適化に積極的に取り組んでいます。来年(2024年)前半に行われるこれらの機能改善に関するアップデートを楽しみにしていてください。
"Databricksモデルサービングによって、Databricks内外でホスティングされている複数のSaaSやオープンモデルへのセキュアなアクセスや管理が容易になることで、我々のAIドリブンのプロジェクトを加速しています。この集中管理のアプローチは、セキュリティやコストの管理をシンプルにし、我々のデータチームは管理のオーバーヘッドではなく、イノベーションによりっフォーカスできるようになりました。" - Greg Rokita, AVP, Technology at Edmunds.com
DatabricksモデルサービングでMixtral 8x7Bを使い始める
Databricks AI Playgroundにアクセスし、お使いのワークスペースから直接生成AIモデルを試しましょう。詳細は:
- Foundation Model APIのドキュメントを学ぶ。
- Databricks Marketplaceで基盤モデルを探す。
- Databricks Model ServingのWebページにアクセスする。
ライセンス
Mixtral 8x7BはApache-2.0でライセンスされています。