LLM Inference Performance Engineering: Best Practices | Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
本記事では、人気のオープンソース大規模言語モデルをプロダクション用途でどのように活用するのかに関して、MosaicMLのエンジニアリングチームがベストプラクティスを共有します。また、ユーザーがモデルやデプロイするハードウェアを選択する際に助けとなるように、これらのモデルに対する推論サービスのデプロイに関するガイドラインも提供します。我々はプロダクション環境で複数のPyTorchベースのバックエンドを取り扱ってきています。これらのガイドラインは、FasterTransformersやまもなくリリースされるNVIDIAのTensorRT-LLMなどの経験から導き出されています。
LLMテキスト生成の理解
大規模言語モデル(LLM)は、2ステップのプロセスでテキストを生成します:入力プロンプトのトークンが並列で処理される「prefill」と、自己回帰的な方法で一度に一つのトークンが生成され、テキストが生成される「decoding」です。生成されるそれぞれのトークンは入力に追加され、モデルが次のトークンを生成できるようにフィードバックされます。LLMが特殊なストップトークンを出力するか、ユーザーが定義した条件(最大トークン数が生成された場合など)を満たした場合に生成が停止します。LLMがどのようにデコーダーブロックを使用するのかの背景を知りたいのであれば、こちらのブログ記事をご覧ください。
トークンは単語あるいは単語の一部となります。テキストをトークンに分割する実際のルールはモデルによって異なります。例えば、Llamaモデルのテキストのトークン化の方法とOpenAIモデルのトークン化の方法を比較することができます。LLM推論プロバイダーは多くの場合、トークンベースのメトリクス(秒あたりのトークン数など)でパフォーマンスを議論しますが、バリエーションのあるモデルにおいて、常にこれらの数値を比較できるわけではありません。具体的な例としては、AnyscaleのチームはLlama 2のトークン作成はChatGPTよりもさらに19%の時間を要することを発見しています(しかし、全体的なコストは以前としてはるかに低いものとなっています)。そして、HuggingGaceの研究者もまた、GPT-4と同じ量のテキストをトレーニングする際に、Llama 2は約20%のトークンをさらに必要とすることを発見しています。
LLMサービングにおける重要なメトリクス
だとしたら、実際には我々はどのように推論のスピードを考えるべきなのでしょうか?
我々のチームでは、LLMのサービングにおいて4つのキーメトリクスを使用しています:
- 最初のトークン出力までに要する時間 Time To First Token (TTFT): クエリー入力後にユーザーがどれだけクイックにモデルのアウトプットを参照し始めるのか。レスポンスの待ち時間が短いことはリアルタイムのやり取りで重要ですが、オフラインのワークロードではそれほど重要ではありません。このメトリックは、プロンプトの処理と最初の出力トークンの生成に必要とされる時間による影響を受けます。
-
出力トークンごとの時間 Time Per Output Token (TPOT): システムに対してクエリーを行うそれぞれのユーザーに対して出力トークンを制するのに要する時間です。このメトリックは、それぞれのユーザーがモデルの
スピードをどのように感じるのかに対応します。例えば、100ms/トークンのTPOTは、ユーザーあたり秒間10トークンとなり、分あたり約450単語であり、通常の人間が読むスピードよりも速いことになります。 - レーテンシー: モデルがユーザーに対して完全なレスポンスを生成するのに要する合計の時間です。全体的なレスポンスのレーテンシーは、上述の2つのメトリクスを用いて計算することができます: レーテンシー = (TTFT) + (TPOT) * (生成されるトークンの数)。
- スループット: すべてのユーザーとリクエストに対して推論サーバーが秒間生成できる出力トークンの数です。
我々のゴールは何でしょうか?最初のトークンを可能な限り高速に出力し、最高のスループットを達成し、出力トークンあたりの時間を最小にすることです。言い換えると、我々がサポートできる数多くのユーザーに対して、可能な限りモデルに高速にテキストを生成させたいということになります。
特筆すべきこととして、スループットと出力トークンあたりの時間にはトレードオフが存在します: 16ユーザーのクエリーを同時に処理する場合、クエリーを順次実行するよりも高いスループットを実現しますが、それぞれのユーザーに対して出力トークンを生成する時間は長くなります。
全体的な推論レーテンシーのターゲットがある場合には、モデル評価に対して有用なヒューリスティックがあります:
- 全体的なレスポンスのレーテンシーにおいては出力の長さが支配的です: 平均レーテンシーを計算するには、出力トークン長の期待値/最大値と、モデルの出力トークンあたりの全体的な平均時間とで掛け算します。
- 入力の長さはパフォーマンスにおいて重要ではありませんが、ハードウェア要件では重要となります: MPTモデルにおいては、512の入力トークンの追加によるレーテンシーの増加は8の追加出力トークンの積よりも小さくなります。しかし、長いインプットをサポートする場合、モデルのサービングが困難となります。例えば、単体のA100-40GBは、最大のコンテキスト長が2048トークンであるMPT-7Bのサービングには十分なGPUメモリーを提供しません。
- 全体的なレーテンシーはモデルサイズと劣線形にスケールします: 同じハードウェアにおいては、大規模なモデルは遅くなりますが、スピードの比率は必ずしもパラメーター数の比率とは一致しません。MPT-30BのレーテンシーはMPT-7Bのレーテンシーの約2.5倍です。Llama2-70Bのレーテンシーは、Llama2-13Bの約2倍です。
多くのケースで我々は見込みのお客様から平均の推論レーテンシーを尋ねられます。特定のレーテンシーターゲット(トークンあたり20ms以下にしたい、など)にフォーカスする前に、期待する入出力長の特徴を把握することに一定の時間を費やすことをお勧めします。
LLM推論の課題
以下のような一般的なテクニックを用いることで、LLM推論の最適化の助けとなります:
- オペレータの融合: 隣接する異なるオペレータを結合することで、多くの場合レーテンシーを改善できます。
- 量子化: より少ないビットを使用するようにアクティベーションと重みを圧縮します。
- 圧縮: スパーシティあるいはディスティレーション。
- 並列化: 複数デバイスに対するテンソル並列化、大規模モデルに対するパイプライン並列化。
これらの手法の他に、トランスフォーマー固有の数多くの重要な最適化があります。この主要な例はKV(キーバリュー)キャッシングです。デコーダーのみのトランスフォーマーベースのモデルにおけるアテンションのメカニズムは計算処理的に非効率です。それぞれのトークンは以前に出現したすべてのトークンを処理するため、新たなトークンが生成される都度、数多くの同じ値を再計算します。例えば、N番目のトークンを生成する際には、(N-1)番目のトークンは(N-2)番目、(N-3)番目…最初のトークンを処理します。同様に、(N+1)番目のトークンを生成する際には、N番目のトークンに対するアテンションは、 (N-1)番目、(N-2)番目、(N-3)番目…最初のトークンを再度参照する必要があります。KVキャッシング、すなわち、アテンションレイヤーに対する中間的なキー/バリューの保存は、繰り返しの計算を避け、あとで再利用できるようにこれらの結果を保持するために活用されます。
メモリー帯域が鍵となります
LLMの計算処理の大部分は、行列・行列の掛け算のオペレーションとなります。次元の小さい行列に対するこれらのオペレーションは通常、多くのハードウェアにおいてメモリー帯域の制限を受けることになります。自己回帰的にトークンを生成する際、(バッチサイズとシーケンスのトークン数によって定義される)アクティベーション行列次元の一つは小規模なバッチサイズにおいて小さなものとなります。このため、このスピードはロードされたデータをどれだけクイックに計算できるのかではなく、モデルのパラメーターをGPUメモリーからローカルのキャッシュ/レジスタにどれだけクイックにロードできるのかに依存します。推論ハードウェアにおいて利用可能なメモリー帯域は、ピークの計算パフォーマンスよりもトークン生成のスピード予測において優れた指標となります。
推論ハードウェアの使用率は、サービングコストの観点で非常に重要です。GPUは高価で、可能な限りそれらを最大限活用する必要があります。共有推論サービスは、多数のユーザーのワークロードをまとめることで低コストを保証し、それぞれのギャップを埋め、重複するリクエストをバッチにまとめます。Llama2-70Bのような大規模なモデルに対しては、大規模なバッチサイズにおいてのみ優れたコストパフォーマンスを達成しています。大規模なバッチサイズに対応できる推論サービングもシステムを持つことは、コスト効率性において重要となります。しかし、大規模なバッチは、大規模なKVキャッシュサイズを意味し、モデルサービングに必要なGPUの数が増加することとなります。このために争奪戦が起きており、共有サービスのオペレータはコストのトレードオフを判断し、システムの最適化を実装する必要に迫られています。
モデル帯域使用量(MBU)
LLM推論サーバーはどのように最適化できるのでしょうか?
ここまでで簡単に説明したように、小規模なバッチサイズなLLMの推論、特にでコード時間においては、デバイスのメモリーから計算ユニットにどれだけ高速にモデルのパラメーターをロードできるのかがボトルネックとなります。メモリーの帯域がどれだけクイックにデータを移動できるのかを示します。背後のハードウェアの使用量を計測するために、Model Bandwidth Utilization (MBU)という新たなメトリックを導入します。MBUは(達成されるメモリー帯域) / (ピークのメモリー帯域)で計算され、達成されるメモリー帯域は((合計のモデルパラメーターサイズ + KVキャッシュサイズ) / TPOT)となります。
例えば、16ビット精度の7BパラメーターのモデルのTPOTが14msの場合、14msで14GBのパラメーターを移動するということは、1TB/秒の帯域使用となります。マシンのピークの帯域が2TB/秒ならば、50%のMBUで処理を行っています。シンプルにするために、この例では小規模なバッチサイズかつ短いシーケンス長において小さいKVキャッシュサイズを無視しています。MBUが100%に近づくことは、推論システムが利用可能なメモリー帯域を高価的に活用していることを意味します。また、MBUは正規化された方法で異なる推論システム(ハードウェア + ソフトウェア)を比較する際にも有用です。MBUは計算処理に制約を受ける環境で重要なメトリックであるModel Flops Utilization (MFU: PaLMの論文で導入)を補完するものとなります。
図1では、roofline plotと同様のプロットで、MBUを図示しています。オレンジの領域の斜線は、メモリー帯域が完全に100%で飽和する際の最大予想スループットとなります。しかし、小さなバッチなサイズにおいては、観測されるパフォーマンスは最大よりも小さなものとなります - どれだけ低いのかがMBUの指標となります。大規模なバッチサイズ(黄色の領域)においては、計算能力による制限を受け、ピークの予測スループットの割合としての達成スループットはModel Flops Utilization (MFU)として計測されます。
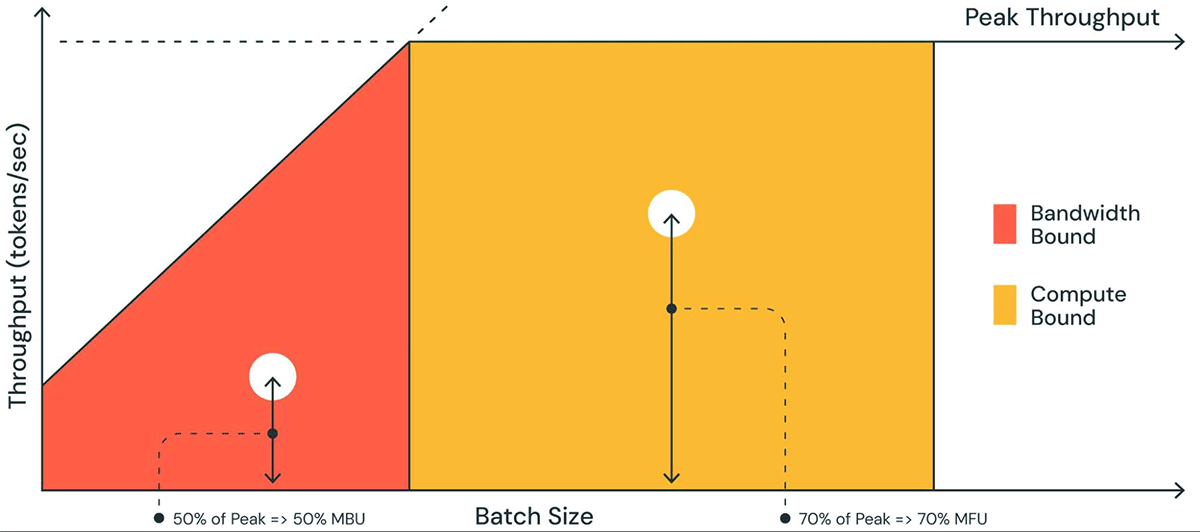
図1. MBU (Model Bandwidth Utilization)とMFU (Model Flops Utilization)の図。MBUとMFUはそれぞれ、メモリーの限界と計算能力の限界に対する割合となります。
MBUとMFUは、特定のハードウェア環境でどれだけ推論スピードを改善できるのかの余地を決定します。図2では我々のTensorRT-LLMベースの推論サーバーにおいて異なるテンソル並列度に対するMBUを計測しています。隣接する大規模なメモリーのチャンクを転送する際に、ピークのメモリー帯域使用量となっています。MPT-7Bのように小規模なモデルが複数のGPUに分散された際、それぞれのGPUで小規模なメモリーのチャンクを移動するため低いMBUを観測しています。

図2: A100-40GのGPUのTensorRT-LLMにおける様々なテンソル並列度のMBUの実験結果。バッチサイズ1で512の入力トークンのシーケンスを使用。
図3では、NVIDIAのH100 GPUにおけるいくつかのテンソル並列度とバッチサイズにおけるMBUを計測しています。バッチサイズが増加するとMBUは減少します。しかし、GPUをスケールさせると、MBUの相対的な減少はさらに小さなものとなります。より大きなメモリー帯域を持つハードウェアを選択することで、少ないGPUでのパフォーマンスをブーストできることを特記しておきます。バッチサイズ1では、2つのH100-80GBで60%のMBUという、4つのA100-40GB GPUの55%よりも高い値を達成できています。

図3. H100-80GBのGPUびおけるバッチサイズやテンソル並列度に対するMBUの実験結果。リクエスト: 512入力トークンのシーケンス。
ベンチマーク結果
レーテンシー
MPT-7BとLlama2-70Bモデルで様々なテンソル並列度を指定して、最初のトークン出力までに要する時間(TTFT)と出力トークンごとの時間(TPOT)を計測しました。入力プロンプトが長くなると、最初のトークンの生成に要する時間が全体的なレーテンシーの大半を占めるようになりました。複数のGPUに対するテンソル並列化はこのレーテンシーの削減に寄与しました。
モデルのトレーニングとは異なり、より多くのGPUにスケールしても劇的に推論のレーテンシーを削減するわけではありません。例えば、Llama2-70BでGPUを4から8にしても、小規模バッチサイズにおいてはレーテンシーは0.7倍にしかなりません。この利用の一つは、(上述の通り)並列度を高めてもMBUが低くなるということがあります。他の理由は、テンソル並列化によってGPUノード間の通信オーバーヘッドが生じるというものです。

表1. バッチサイズ1で入力リクエストが512トークンの場合に最初のトークンに要する時間。Llama2 70Bのような大規模なモデルをメモリーに載せるには最低でも4台のA100-40GBのGPUが必要。
大規模なバッチサイズにおいては、テンソルの並列度を高くするとトークンのレーテーシーは相対的に大きく削減されます。図4ではMPT-7Bにおいて出力トークンごとの時間がどのように変化するのかを示しています。バッチサイズ1では2から4に変えてもトークンのレーテンシーは12%程度しか削減されません。バッチサイズ16では、2から4にすることで33%削減されます。これは、バッチサイズ1と比べてバッチサイズ16におけるテンソルの並列度を高くした場合にMBUの相対的な減少値が小さくなるという以前の観測結果と適合しています。
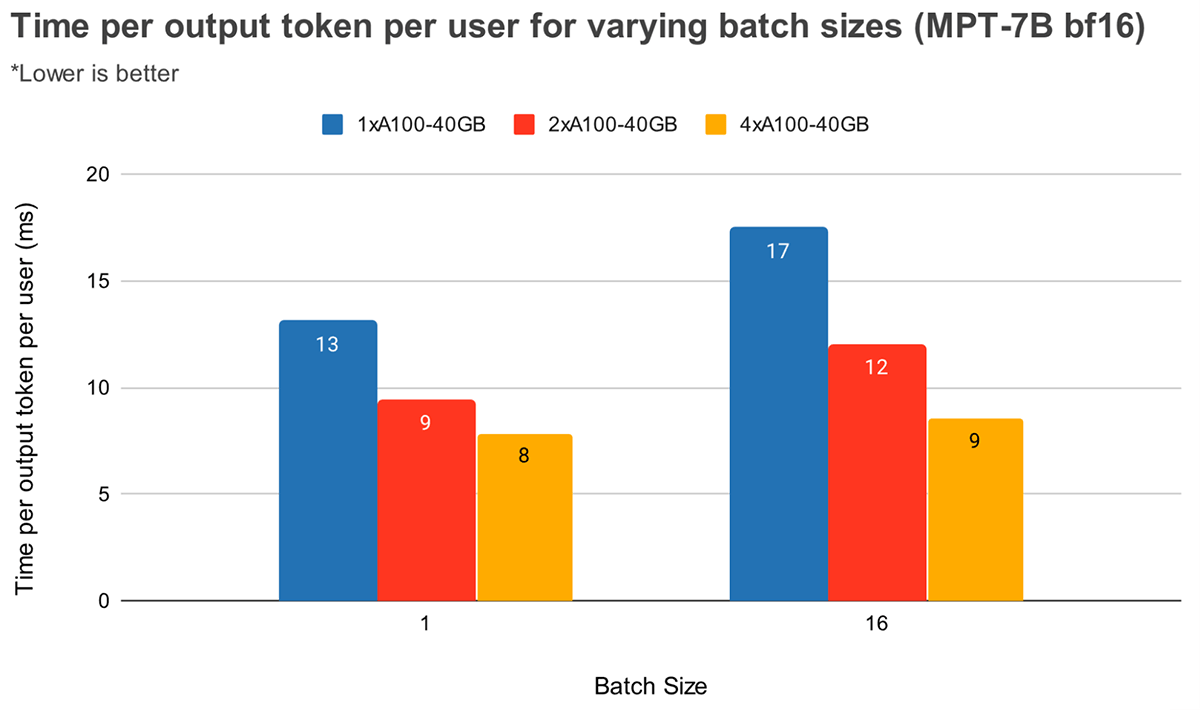
図4. A100-40GBのGPUにおいてMPT-7Bをスケールした際のユーザーごと出力トークンごとの時間。GPUの数を増やしてもレーテンシーは線形にスケールしません。リクエスト:128の入力トークン、64の出力トークンのシーケンス。
図5では、4つと8つの違いの相対的な違いが少ないことを除いて同様のLlama2-70Bの結果を示しています。また、我々は2つの異なるハードウェアでのGPUのスケーリングを比較しました。H100-80GBはA100-40GBと比較して、2.15倍のメモリー帯域を持っているので、バッチサイズ1でのレーテンシーは36%低く、4つのシステムでのバッチサイズ16では52%低くなっています。

図5. 複数のGPUにLlama-v2-70Bをスケールさせた際のユーザーごと出力トークンごとの時間(入力リクエスト: 512トークン長)。Llama-v2-70B(float16)は1x40GB GPU、2x40GB、1x80GB GPUにフィットしないので、これらの値がないことに注意してください。
スループット
リクエストをバッチにまとめることで、スループットとトークンあたりの時間をトレードオフすることができます。GPU評価の際にクエリーをグルーピングすることで、シーケンシャルにクエリーを処理するよりもスループットを改善することができますが、(キューの効果を無視して)それぞれのクエリーの完了に要する時間は長くなります。
推論リクエストのバッチにはいくつかの共通的なテクニックがあります:
- 静的バッチ: クライアントで複数のプロンプトをリクエストにパッケージし、バッチにあるすべてのシーケンスが完了したあとにレスポンスが返却されます。我々の推論サーバーはこれをサポートしていますがこれを必要とはしません。
- 動的バッチ: サーバー内でオンザフライでプロンプトがバッチ化されます。通常、この手法は静的バッチよりも性能が悪いですが、レスポンスが短い場合あるいは固定長の場合には最適に近いものとなります。リクエストのパラメーターが異なる際にはうまく動作しません。
- 連続バッチ: リクエストが到着するたびにリクエストのバッチ化を行うというアイデアは、この素晴らしい論文で導入され、現在のSOTA手法となっています。バッチを完了するためにすべてのシーケンスを待つのではなく、イテレーションレベルでシーケンスをグルーピングします。動的バッチよりも10倍から20倍優れたスループットを達成することができます。
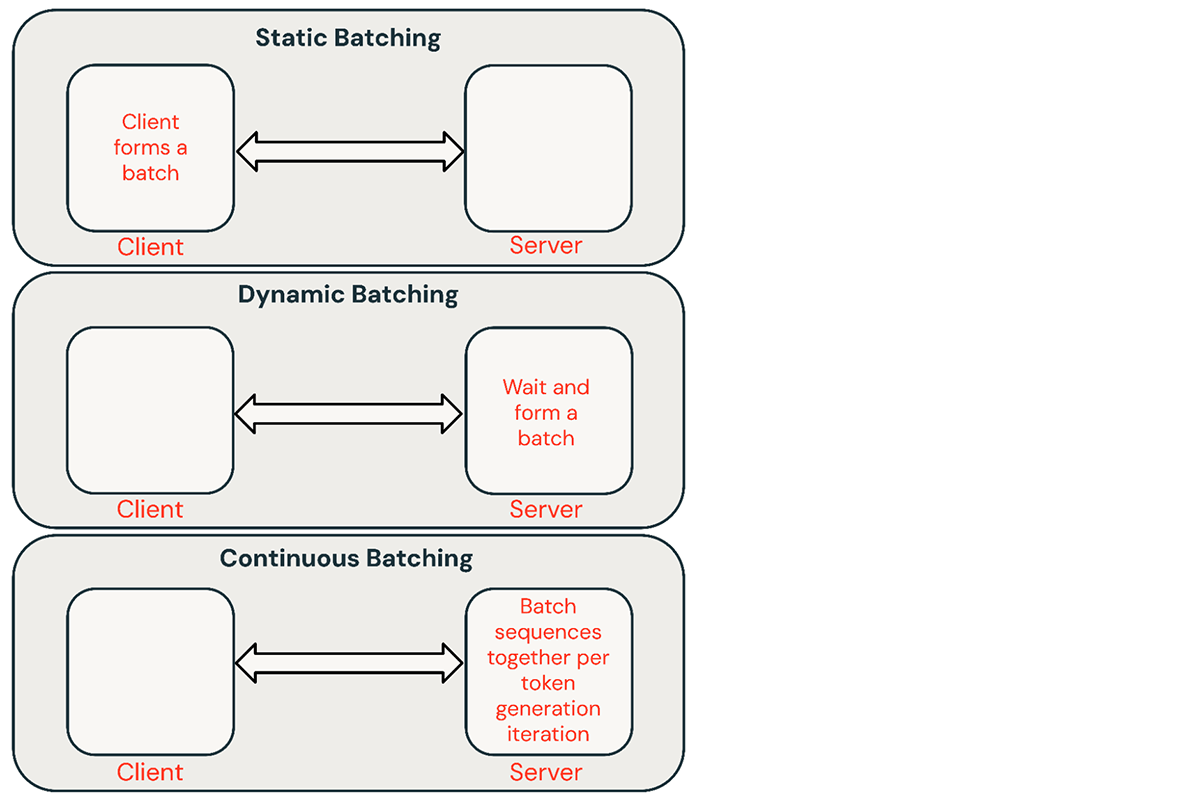
図6. LLMサービングにおける様々なバッチ手法。バッチ化は推論効率の改善に有効です。
通常、共有サービスにおいて連続バッチが最適なアプローチですが、他の二つが適しているシチュエーションがあります。低QPSの環境では、動的バッチの方が連続バッチよりも性能が出ることがあります。よりシンプルなバッチフレームワークで低レベルのGPU最適化を実装することの方が簡単な場合があります。オフラインのバッチ推論ワークロードでは、静的バッチでは大きなオーバーヘッドを回避し、優れたスループットを達成することができます。
バッチサイズ
どれだけうまくバッチ化を行えるのかは、リクエストのストリームに依存します。しかし、同じリクエストを用いて静的バッチをベンチマークすることでパフォーマンスの上限を取得することができます。
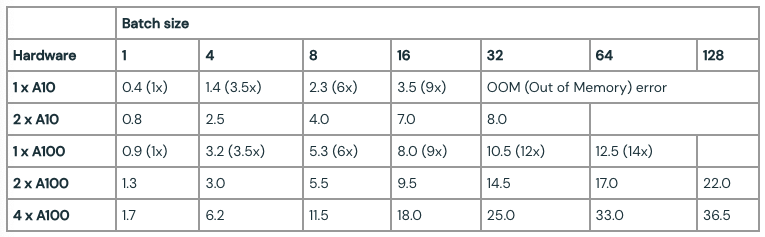
表2. 静的バッチとFasterTransformersベースのバックエンドによるMPT-7Bのピークのスループット(リクエスト/秒)。リクエスト: 512の入力トークン、64の出力トークン。大規模な入力においては、小規模バッチサイズではOOMの制限が生じます。
レーテンシーのトレードオフ
リクエストのレーテンシーはバッチサイズによって増加します。例えば、1台のNVIDIA A100 GPUで、バッチサイズ64でスループットを最大化する場合、スループットは14倍に増加しますがレーテンシーは4倍に増加します。通常、共有推論サービスではバランスの取れたバッチサイズを選択します。自身のモデルをホスティングしているユーザは、自身のアプリケーションに適したレーテンシー/スループットのトレードオフを決断する必要があります。チャットbotのようにいくつかのアプリケーションにおいては、高速なレスポンスのための低レーテンシーが最大の優先事項となります。非構造化のPDFのバッチ処理のような他のアプリケーションにおいては、すべてを並列に高速に処理するために、個々のドキュメントの処理におけるレーテンシーを犠牲にするかもしれません。
図7では、7Bモデルのスループット対レーテンシーの曲線を示しています。この曲線のそれぞれの線は、バッチサイズを1から256に増加させることで取得しています。これは、様々なレーテンシーの制約においてどれだけバッチサイズを大きくできるのかを特定する際に有用です。上述のroofline譜rっとを思い返すと、我々が期待することとこれらの計測結果に一貫性があることがわかります。特定のバッチサイズを超えた場合、すなわち、計算処理の限界を超えた場合、バッチサイズを倍にしてもスループットを増加させることなしに、単にレーテンシーが増加するだけとなります。

図7. MPT-7Bモデルのスループットとレーテンシーの曲線。これによって、ユーザーはレーテンシーの制約の下でスループット要件を満たすハードウェア設定を選択することができます。
並列化を活用する際、低レベルのハードウェアの詳細を理解することが重要です。例えば、クラウドが異なる場合、8台のA100インスタンスが同じというわけではありません。いくつかのサーバーはすべてのGPUにおいて高い帯域接続を行いますが、他のペアのGPUではペア間の帯域が狭い場合があります。これによってボトルネックが生じ、上述の曲線から大きく乖離した実際のパフォーマンスをもたらすことになります。
最適化ケーススタディ:量子化
量子化は、LLM推論のハードウェア要件の削減で使用される一般的な手法です。推論時にモデルの重みとアクティベーションの精度を削減することで、ハードウェアの要件を劇的に削減することができます。例えば、16ビットの重みを8ビットの重みにスイッチすることで、メモリー制約のある環境で必要ツァれるGPUの数を半分にすることができます(例: A100におけるLlama2-70B)。重みを4ビットにすることで、コンシューマーのハードウェアで推論を実行することも可能です(例: MacbookでLlama2-70Bを実行)。
我々の経験では、量子化は注意して実装する必要があります。不用意な量子化技術のテクニックは、モデルの品質に大きなダメージを与えることがあります。また、量以下のインパクトはモデルのアーキテクチャ(MPT vs Llama)やサイズによって変化します。今後のブログ記事でこの詳細を探索します。
量子化のようなテクニックを実験する際、個別にモデルの品質を評価するのではなく、推論システムの品質を評価するためにMosaic Eval GauntletのようなLLM品質ベンチマークを活用することをお勧めします。さらに、より深いシステムの最適化を探索することが重要です。特に、量子化はKVキャッシュをより効率的なものとします。
上述したように、自己再帰のトークン生成では、すべてのステップで再計算するのではなく、アテンションレイヤーの過去のキー/バリューをキャッシュします。KVキャッシュのサイズは、これらのシーケンスの長さと一度に処理されるシーケンスの数に応じて変化します。さらに、次のトークン生成のそれぞれのイテレーションにおいて、既存のキャッシュに新たなKVアイテムが追加されると、新規トークンが追加されるごとに肥大化していきます。このため、優れた推論パフォーマンスのためには、これらの新規の値を追加する際の効果的なKVキャッシュメモリー管理が重要となります。Llama2モデルでは、Grouped Query Attention (GQA)と呼ばれるアテンションのバリエーションを使用しています。KVのヘッドの数が1の場合、GQAはMulti-Query-Attention (MQA)と同じになることに注意してください。GQAはキー/バリューを共有することで、KVキャッシュのサイズを低く抑える助けとなります。KVキャッシュサイズの計算式は、batch_size * seqlen * (d_model/n_heads) * n_layers * 2 (K と V) * 2 (Float16ごとのバイト数) * n_kv_headsとなります。
表3では、シーケンス長が1024トークンで様々なバッチサイズで計算されたGQAのKVキャッシュサイズを示しています。Llama2モデルのパラメーターサイズは、70Bモデルでは140GB(Float16)となります。KVキャッシュの量子化は、KVキャッシュのサイズを削減するための(GQA/MQAに加えて)更なるテクニックであり、我々は積極的に生成品質に対するこのインパクトを評価しています。
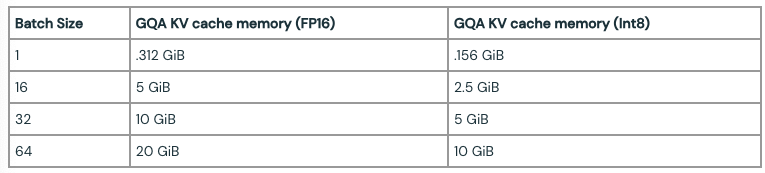
表3. シーケンス長1024のLlama-2-70BのKVキャッシュサイズ
上述したように、少ないバッチサイズでのLLMによるトークン生成は、GPUのメモリー帯域に制限を受ける問題となり、生成スピードはモデルパラメーターをどれだけ早くGPUメモリーからチップのキャッシュに移動できるのかに依存します。モデルの重みをFP16(2バイト)からINT8 (1バイト)やINT4(0.5バイト)に変換することで、データする移動が少なくなるので、トークン生成がスピードアップします。しかし、量子化はモデルの生成品質にネガティブなインパクトをもたらすことがああります。我々は現在Model Gauntletを用いてモデル品質へのインパクトを評価しており、今後はフォローアップのブログ記事を公開する予定です。
結論及び重要な結果
上で説明した要因のそれぞれは、モデルの構築、デプロイの方法に影響を与えます。ハードウェアのタイプ、ソフトウェアスタック、モデルアーキテクチャ、典型的な使用パターンを検討する際にデータドリブンの意思決定を行えるように、我々はこれらの結果を活用しています。我々の経験から導き出されるいくつかの推奨事項を示します。
あなたの最適化ターゲットを特定しましょう: インタラクティブなパフォーマンスを気にしていますか?スループットの最大化ですか?コストの最小化?予測可能なトレードオフが存在します。
レーテンシーのコンポーネントに注意を払いましょう: インタラクティブなアプリケーションでは、最初のトークン生成に要する時間はあなたのサービスがどれだけレスポンシブかを決定し、出力トークンごとの時間はそれがどれだけ速いのかを決定します。
メモリーの帯域が鍵となります: 最初のトークンの生成は通常計算能力による制限を受けますが、以降のデコーディングのオペレーションはメモリーによる制約を受けるものとなります。LLM推論は多くの場合、メモリーの制約を受ける環境で動作するので、MBUは最適化すべき有用なメトリックであり、推論システムの効率性を比較する際に活用することができます。
バッチ作成が重要です: 同時に複数のリクエストのを処理することは、高いスループットを達成し、効果なGPUを効果的に活用するためには重要なこととなります。共有オンラインサービスにおいては、連続バッチが不可欠となり、オフラインバッチ推論ワークロードでは、よりシンプルなバッチ技術で高いスループットを達成することができます。
深い最適化: 標準的な推論最適化技術(オペレーターの融合、重みの量子化など)はLLMにおいて重要ですが、システムの最適化を深く探索すること、特にメモリーの使用率を改善するものを探索することが重要となります。その一例がKVキャッシュの量子化です。
ハードウェア設定: デプロイメントのハードウェアを決定するためには、モデルのタイプと予測されるワークロードを活用すべきです。例えば、複数のGPUにスケーリングする際、MPT-5のような小規模なモデルでは、Llama2-70Bのような大規模モデルと比較して、MBUは急速に低下します。また、テンソル並列度に対してパフォーマンスは劣線形でスケールする傾向があります。すなわち、トラフィックが多い、あるいはユーザーがさらなる低レーテンシーを望んでいる場合には、テンソル並列度を高くすることには依然として合理性があると言えます。
データに基づく意思決定: 理論を理解することは重要ですが、常にエンドツーエンドのパフォーマンスを計測することをお勧めします。推論のデプロイメントが予測したよりも性能が出ないことには多数の理由が存在します。ソフトウェアの非効率性によって、予期せずMBUが低くなることがあります。あるいは、クラウドプロバイダー間のハードウェアの違いによって、驚きをもたらすことがあります(2つのクラウドプロバイダーの8つのA100サーバーで2倍のレーテンシーの違いを観測したことがあります)。
LLM推論をスタートするには、Databricksモデルサービングを使い始めましょう。詳細はドキュメントをチェックしてください。