こちらで紹介したルート生成のソリューションアクセラレータを日本の地図に対応させました。
ノートブックはこちらです。
バックグラウンドなどは上の記事を参照ください。こちらでは手順のみを説明します。
OSRMサーバーのセットアップ
シングルノードのクラスター(メモリーは256GB程度を推奨)を作成し、ノートブック01_ Setup OSRM Serverを実行していきます。
Step 1: サーバーソフトウェアの構築
こちらは従来の手順と変わりません。
依存関係のインストール
%sh -e
sudo apt -qq install -y build-essential git cmake pkg-config \
libbz2-dev libxml2-dev libzip-dev libboost-all-dev \
lua5.2 liblua5.2-dev libtbb-dev
OSRMバックエンドサーバーリポジトリのクローン
%sh -e
# make directory for repo clone
mkdir -p /srv/git
cd /srv/git
# clone the osrm backend server repo
rm -rf osrm-backend
git clone --depth 1 -b v5.26.0 https://github.com/Project-OSRM/osrm-backend
OSRMバックエンドサーバーの構築
%sh -e
cd /srv/git/osrm-backend
mkdir -p build
cd build
cmake ..
cmake --build .
sudo cmake --build . --target install
Step 2: 地図ファイルの準備
地図ファイルのダウンロード
アジアのファイル: Geofabrik Download Serverから日本のファイルをダウンロードしていきます。
%sh -e
# create clean folder to house downloaded map file
rm -rf /srv/git/osrm-backend/maps/japan
mkdir -p /srv/git/osrm-backend/maps/japan
# download map file to appropriate folder
cd /srv/git/osrm-backend/maps/japan
wget --quiet https://download.geofabrik.de/asia/japan-latest.osm.pbf
# list folder contents
ls -l .
地図ファイルのコンテンツの抽出
%sh -e
# setup location to house log files
mkdir -p /srv/git/osrm-backend/logs
# move to folder housing map file
cd /srv/git/osrm-backend/maps/japan
# extract map file contents
/srv/git/osrm-backend/build/osrm-extract japan-latest.osm.pbf -p /srv/git/osrm-backend/profiles/car.lua > /srv/git/osrm-backend/logs/extract_log.txt
# review output from extract command
#echo '----------------------------------------'
#tail /srv/git/osrm-backend/logs/extract_log.txt
%sh -e
tail /srv/git/osrm-backend/logs/extract_log.txt

地図ファイル抽出の検証
%sh -e ls -l /srv/git/osrm-backend/maps/japan

抽出地図ファイルのパーティション
%sh -e
cd /srv/git/osrm-backend/maps/japan
/srv/git/osrm-backend/build/osrm-partition japan-latest.osrm
抽出地図ファイルのカスタマイズ
%sh -e
cd /srv/git/osrm-backend/maps/japan
/srv/git/osrm-backend/build/osrm-customize japan-latest.osrm
Step 3: OSRMアセットの永続化
%sh -e
rm -rf /dbfs/FileStore/osrm-backend-japan
cp -L -R /srv/git/osrm-backend /dbfs/FileStore/osrm-backend-japan
Step 4: initスクリプトの作成
# make folder to house init script
dbutils.fs.mkdirs('dbfs:/databricks/scripts')
# write init script
dbutils.fs.put(
'/databricks/scripts/osrm-backend-japan.sh',
'''
#!/bin/bash
if [[ $DB_IS_DRIVER != "TRUE" ]]; then
echo "installing osrm backend server dependencies"
sudo apt -qq install -y build-essential git cmake pkg-config libbz2-dev libxml2-dev libzip-dev libboost-all-dev lua5.2 liblua5.2-dev libtbb-dev
echo "launching osrm backend server"
/dbfs/FileStore/osrm-backend-japan/build/osrm-routed --algorithm=MLD /dbfs/FileStore/osrm-backend-japan/maps/japan/japan-latest.osrm &
echo "wait until osrm backend server becomes responsive"
res=-1
i=1
# while no response
while [ $res -ne 0 ]
do
# test connectivity
curl --silent "http://127.0.0.1:5000/route/v1/driving/139.6503,35.6762;139.6380,35.4437"
res=$?
# increment the loop counter
if [ $i -gt 40 ]
then
break
fi
i=$(( $i + 1 ))
# if no response, sleep
if [ $res -ne 0 ]
then
sleep 30
fi
done
fi
''',
True
)
# show script content
print(
dbutils.fs.head('dbfs:/databricks/scripts/osrm-backend-japan.sh')
)
ルート生成
ノートブック02_ Generate Routesを実行していきます。
クラスターのinitスクリプトとして、上で作成したdbfs:/databricks/scripts/osrm-backend-japan.shを指定します。

必要なライブラリのインストール
%pip install tabulate databricks-mosaic
必要なライブラリのインポート
import requests
import pandas as pd
import numpy as np
import json
import itertools
import subprocess
import pyspark.sql.functions as fn
from pyspark.sql.types import *
# mosaicのインポートと設定
import mosaic as mos
spark.conf.set('spark.databricks.labs.mosaic.geometry.api', 'ESRI')
spark.conf.set('spark.databricks.labs.mosaic.index.system', 'H3')
mos.enable_mosaic(spark, dbutils)
from tabulate import tabulate
Step 1: それぞれのワーカーで稼働するサーバーの検証
ワーカーノードのIPアドレスの取得
# それぞれのワーカーのエグゼキューターに分散させるRDDの生成
myRDD = sc.parallelize(range(sc.defaultParallelism))
# IPアドレスの一覧を取得
ip_addresses = set( # 出力の重複を排除するためにsetに変換
sc.runJob(
myRDD,
lambda _: [subprocess.run(['hostname','-I'], capture_output=True).stdout.decode('utf-8').strip()] # それぞれのエグゼキューターで hostname -I を実行
)
)
ip_addresses
ルーティングレスポンスに対するそれぞれのワーカーのテスト
各ノードがOSRMサーバになっています。ある意味変態的で私は好きです。
responses = []
# それぞれのワーカーのIPアドレスに対するループ
for ip in ip_addresses:
print(ip)
# OSRMバックエンドサーバーからレスポンスを取得
resp = requests.get(f'http://{ip}:5000/route/v1/driving/139.6503,35.6762;139.6380,35.4437').text
responses += [(ip, resp)]
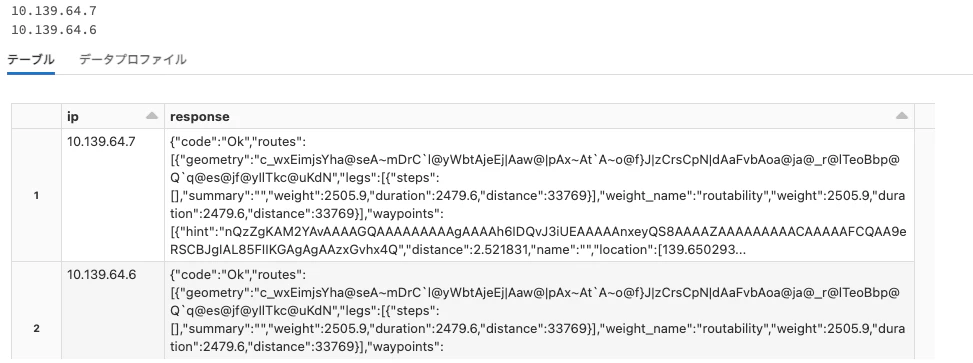
# それぞれのワーカーで生成されたレスポンスを表示
display(
pd.DataFrame(responses, columns=['ip','response'])
)
以下の様に各ノードのOSRMサーバからレスポンスが返ってきます。
Step 2: ルート生成データの取得
日本のルート生成をデモンストレーションするために、駅の緯度経度を使用します。
東京都の駅-路線の最新リストデータ 鉄道 | オープンポータル
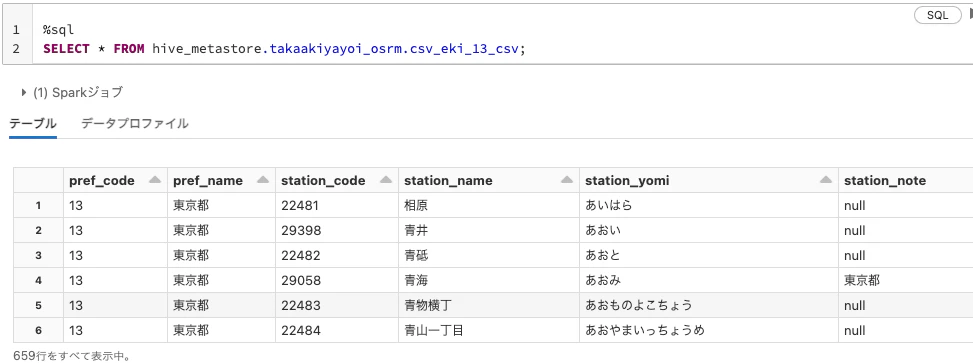
GUIからCSVをアップロードしてcsv_eki_13_csvというテーブルを作成します。CSVは以下の場所に置いてあります。
データベースを作成します。名前は適宜変更してください。
%sql
CREATE DATABASE IF NOT EXISTS takaakiyayoi_osrm;
UIを使うなどしてテーブルを作成します。

%sql
SELECT * FROM hive_metastore.takaakiyayoi_osrm.csv_eki_13_csv;
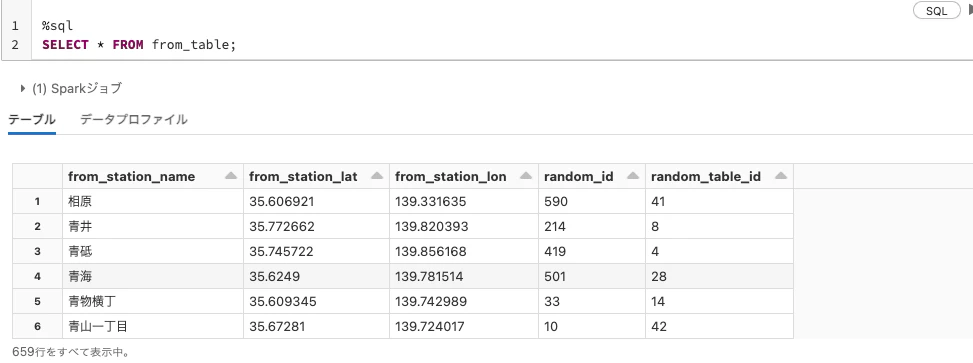
出発地点と行き先をランダムに組み合わせます。
%sql
DROP TABLE IF EXISTS hive_metastore.takaakiyayoi_osrm.eki_movement;
%sql CREATE TEMPORARY VIEW from_table AS (
SELECT
station_name AS from_station_name,
station_lat AS from_station_lat,
station_lon AS from_station_lon,
floor(RAND() * 700) AS random_id,
floor(RAND() * 50) AS random_table_id -- あとでドライビングテーブルを作成する際に使用します
FROM
hive_metastore.takaakiyayoi_osrm.csv_eki_13_csv
)
%sql
SELECT * FROM from_table;
%sql
CREATE TABLE hive_metastore.takaakiyayoi_osrm.eki_movement AS
SELECT
from_station_name,
from_station_lat,
from_station_lon,
to_station_name,
to_station_lat,
to_station_lon,
random_table_id
FROM
from_table A
INNER JOIN (
SELECT
station_name AS to_station_name,
station_lat AS to_station_lat,
station_lon AS to_station_lon,
floor(RAND() * 700) AS random_id
FROM
hive_metastore.takaakiyayoi_osrm.csv_eki_13_csv
ORDER BY
RAND()
) B ON A.random_id = B.random_id
eki_movement_df = spark.read.table("hive_metastore.takaakiyayoi_osrm.eki_movement")
display(eki_movement_df)
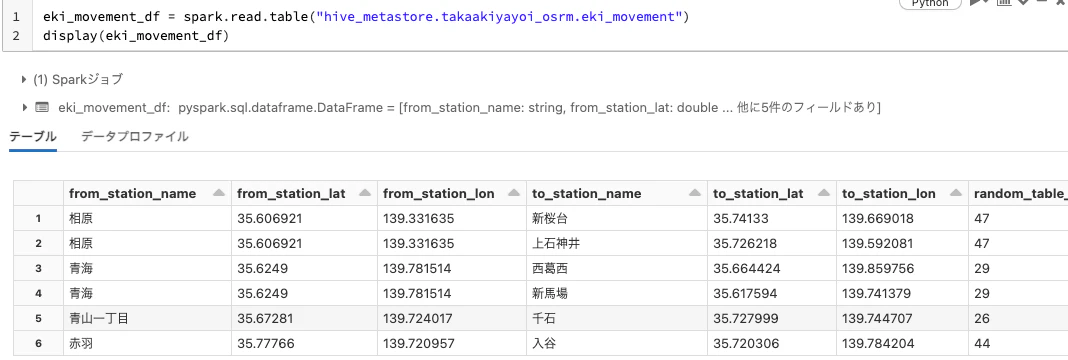
Step 3: 移動ルートの取得
ルートを取得すための関数の定義
@fn.pandas_udf(StringType())
def get_osrm_route(
start_longitudes: pd.Series,
start_latitudes:pd.Series,
end_longitudes: pd.Series,
end_latitudes: pd.Series
) -> pd.Series:
# データフレームを構成するために入力を組み合わせます
df = pd.concat([start_longitudes, start_latitudes, end_longitudes, end_latitudes], axis=1)
df.columns = ['start_lon','start_lat','end_lon','end_lat']
# 特定の行に対するルートを取得するための内部関数
def _route(row):
r = requests.get(
f'http://127.0.0.1:5000/route/v1/driving/{row.start_lon},{row.start_lat};{row.end_lon},{row.end_lat}?alternatives=true&steps=false&geometries=geojson&overview=simplified&annotations=false'
)
return r.text
# 行ごとにルーティング関数を適用
return df.apply(_route, axis=1)
ルートの取得
display(
eki_movement_df
.withColumn(
'osrm_route',
get_osrm_route('from_station_lon','from_station_lat','to_station_lon','to_station_lat')
)
.selectExpr(
'from_station_lon',
'from_station_lat',
'to_station_lon',
'to_station_lat',
'osrm_route',
'from_station_name',
'to_station_name'
)
)

ルートのJSONを複雑なデータ型表現に変換
# JSONドキュメントのスキーマ
response_schema = '''
STRUCT<
code: STRING,
routes:
ARRAY<
STRUCT<
distance: DOUBLE,
duration: DOUBLE,
geometry: STRUCT<
coordinates: ARRAY<ARRAY<DOUBLE>>,
type: STRING
>,
legs: ARRAY<
STRUCT<
distance: DOUBLE,
duration: DOUBLE,
steps: ARRAY<STRING>,
summary: STRING,
weight: DOUBLE
>
>,
weight: DOUBLE,
weight_name: STRING
>
>,
waypoints: ARRAY<
STRUCT<
distance: DOUBLE,
hint: STRING,
location: ARRAY<DOUBLE>,
name: STRING
>
>
>
'''
# ルートの取得、JSONをstructに変換
eki_routes = (
eki_movement_df
.withColumn(
'osrm_route',
get_osrm_route('from_station_lon','from_station_lat','to_station_lon','to_station_lat')
)
.withColumn(
'osrm_route',
fn.from_json('osrm_route',response_schema)
)
.selectExpr(
'osrm_route',
'from_station_name',
'to_station_name'
)
)
display(
eki_routes
)

ルートから距離と時間を取得
display(
eki_routes
.withColumn('route', fn.explode('osrm_route.routes'))
.withColumn('route_meters', fn.col('route.distance'))
.withColumn('route_seconds', fn.col('route.duration'))
.selectExpr(
'from_station_name',
'to_station_name',
'route_meters',
'route_seconds'
)
)
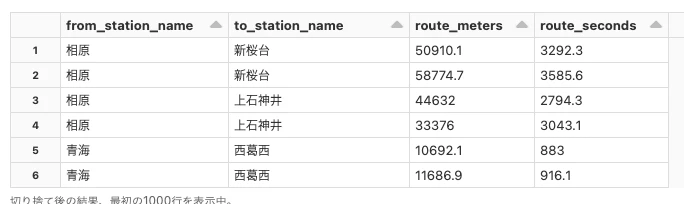
ルートジオメトリの取得
eki_geometry = (
eki_routes
.withColumn('route', fn.explode('osrm_route.routes')) # ルートの配列をexplode
.withColumn('geojson', fn.to_json(fn.col('route.geometry')))
.withColumn('geom', mos.st_aswkb(mos.st_geomfromgeojson('geojson')))
.drop('osrm_route')
)
display(eki_geometry)
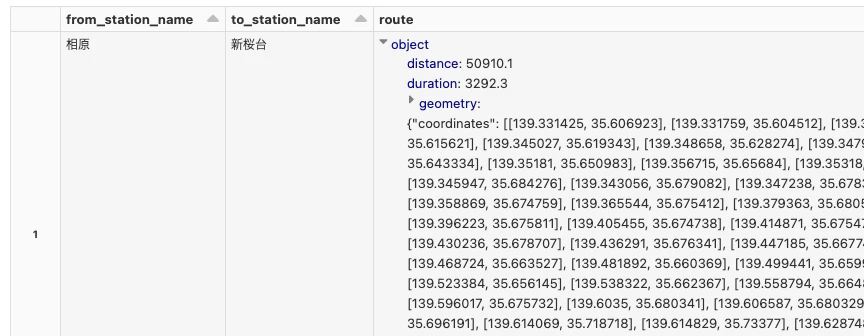
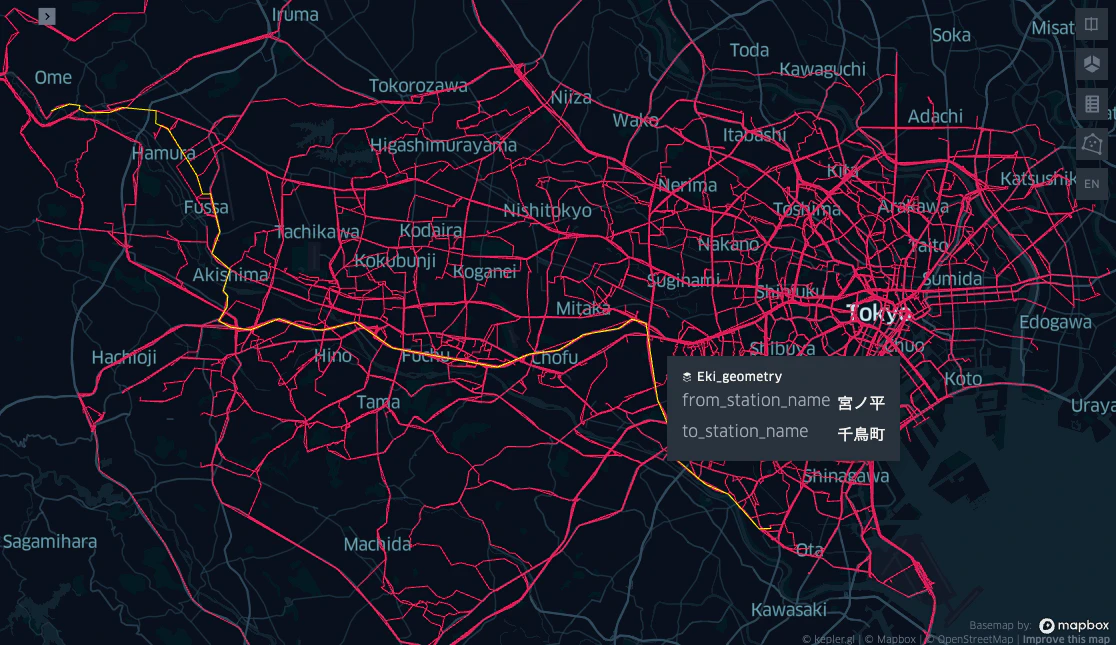
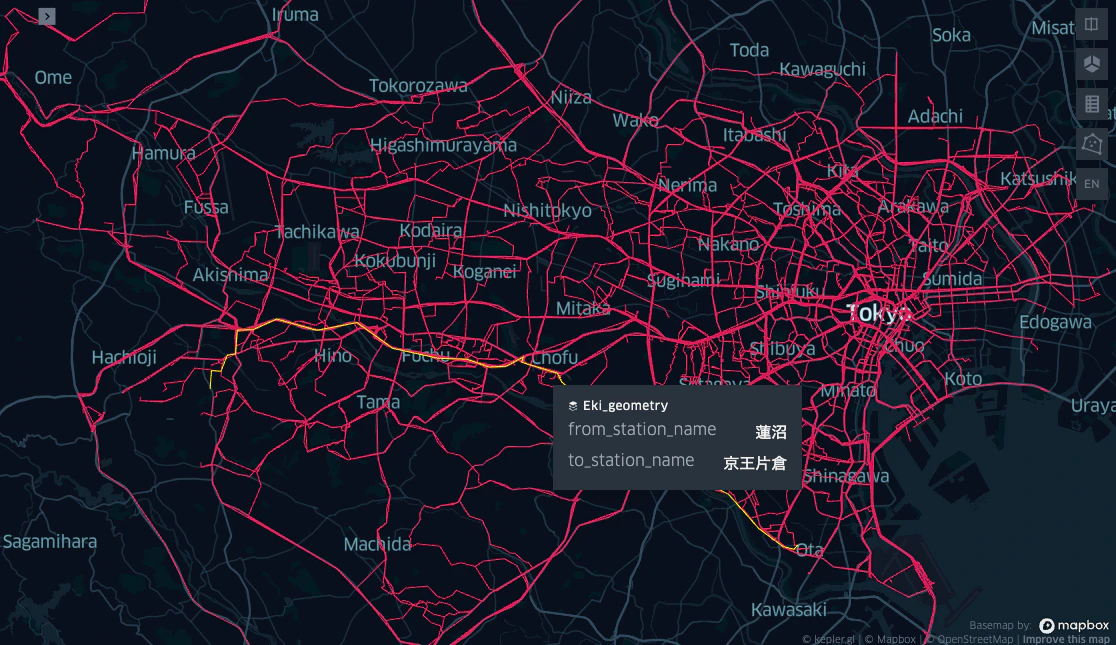
ルートの可視化
日本の地図で見ると実感が湧きますね。
%%mosaic_kepler
eki_geometry geom "geometry" 1000
ドライブ時間テーブルの取得
もちろんですが、我々はOSRMバックエンドサーバーからルーティングデータを取得することに限定されません。我々のゴールがポイント間の移動の最適化であるのならば、移動時間のテーブルを作成する必要があるかもしれません。このためには、OSRMバックエンドサーバーのtable methodを呼び出す関数を記述することができます。
@fn.pandas_udf(StringType())
def get_driving_table(
points_arrays: pd.Series
) -> pd.Series:
# 配列に含まれるポイントのテーブルを取得する内部関数
def _table(points_array):
points = ';'.join(points_array)
r = requests.get(
f'http://127.0.0.1:5000/table/v1/driving/{points}'
)
return r.text
# テーブル関数を行ごとに適用
return points_arrays.apply(_table)
ドライビング時間テーブルの取得
# ドライビングテーブルのスキーマ
response_schema = StructType([
StructField('code',StringType()),
StructField('destinations',ArrayType(
StructType([
StructField('hint',StringType()),
StructField('distance',FloatType()),
StructField('name',StringType()),
StructField('location',ArrayType(FloatType()))
])
)
),
StructField('durations',ArrayType(ArrayType(FloatType()))),
StructField('sources',ArrayType(
StructType([
StructField('hint',StringType()),
StructField('distance',FloatType()),
StructField('name',StringType()),
StructField('location',ArrayType(FloatType()))
])
))
])
上の関数を呼び出すためにはポイントのコレクションを提供する必要があります。使っているデータはこれに適した良い方法を提供していませんので、上で準備したrandom_table_idでグルーピングされる地点を移動することにします。
# ドライビングテーブルを取得しマトリクスを抽出
driving_tables = (
eki_movement_df
.withColumn('start_point', fn.expr("concat(from_station_lon,',',from_station_lat)"))
.groupBy('random_table_id')
.agg(fn.collect_set('start_point').alias('start_points'))
.filter(fn.expr('size(start_points) > 1')) # テーブルには1つ以上のポイントが必要です
.withColumn('driving_table', get_driving_table('start_points'))
.withColumn('driving_table', fn.from_json('driving_table', response_schema))
.withColumn('driving_table_durations', fn.col('driving_table.durations'))
)
display(driving_tables)
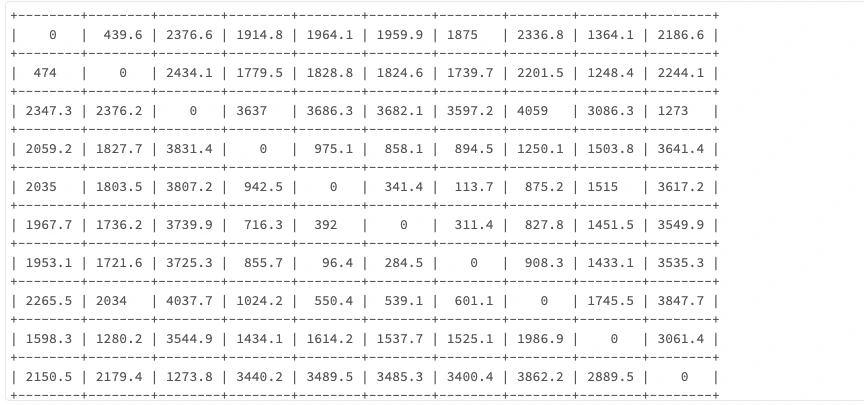
単一のドライビングテーブルの表示
# 単一のテーブルの生成
driving_table = driving_tables.limit(1).collect()[0]['driving_table_durations']
# ドライビングテーブルの表示
print(
tabulate(
np.array(driving_table),
tablefmt='grid'
)
)
こちらの例では東京都の駅のみを使用しましたが、データを差し替えれば任意の地点間でのルートを自在に生成することができます。しかも、OSRMサーバは容易に並列化できるので、大量のルート生成も高速に行うことができます。