こちらのソリューションアクセラレータをウォークスルーします。
アクセラレータの翻訳版はこちらです。
イントロダクション
多くの物流シナリオにおける共通のニーズは、2点間以上での移動距離と移動時間を推定することです。Euclidean、Haversine、Manhattanなど類似の距離計算手法はあるシナリオにおいては適切な値を算出しますが、その他のケースではポイント間を移動するために通過すべき経路や道路を考慮しなくてはなりません。
Project OSRMのゴールは、OpenStreetMap Foundationによって提供される地図詳細を用いてルートの計算を行うためのソフトウェアを利用できるようにするというものです。OSRMバックエンドサーバーは、世界中のどこにおいても自動車や徒歩のルーティングに活用できる容易にデプロイできるソリューションを提供します。
OSRMバックエンドサーバーは、シンプルかつ高速なREST APIを表現するウェブサービスをデプロイします。多くの企業において、このサーバーはさまざまな内部アプリケーションにアクセスできるコンテナ化されたサービスとしてデプロイされます。大規模な履歴データ、シミュレートされたデータに対してルートを生成する分析チームにとっては、多くの場合専用のデプロイメントが必要となります。このようなニーズを持つ分析を支援するために、OSRMバックエンドサーバーがDatabricksクラスターにどのようにデプロイできるのか、さまざまなデータ処理の取り組みの一部としてアクセスできるのかを説明します。
デプロイメントの要件
どのようにOSRMソフトウェアがデプロイされるのかをより理解するには、Databricksクラスターがどのように動作するのかに関して知識を持つことが重要です。
Databricksクラスターは、共有データ処理のワークロードを実行するために動作するサーバーコンピューターから構成されます。Sparkデータフレームにロードされたデータはクラスターのワーカーノードとして知られる複数台のコンピュータのリソースに分散されます。別のコンピューターであるドライバーノードは、ワーカーノードに割り当てられたデータ処理をコーディネートします。すべてのノードはさまざまなデータセットや他のアセットを読み書きする共有ストレージロケーションにアクセスできます。これは非常に単純化したDatabricksクラスターの説明ですが、我々のアプローチの説明には十分です。

大規模なルーティング情報を生成するために、クラスターのワーカーノードのそれぞれにOSRMバックエンドサーバーをデプロイします。これは、ノードが配備されるとそれぞれのノードで実行されるクラスターinitスクリプトを通じて処理されます。このスクリプトを通じて、OSRMバックエンドサーバーのローカルインスタンスがそれぞれのワーカーにデプロイされます。これらのOSRMソフトウェアのインスタンスによって、Sparkデータフレームでデータを処理する際にローカルにルートを生成できるようになります:
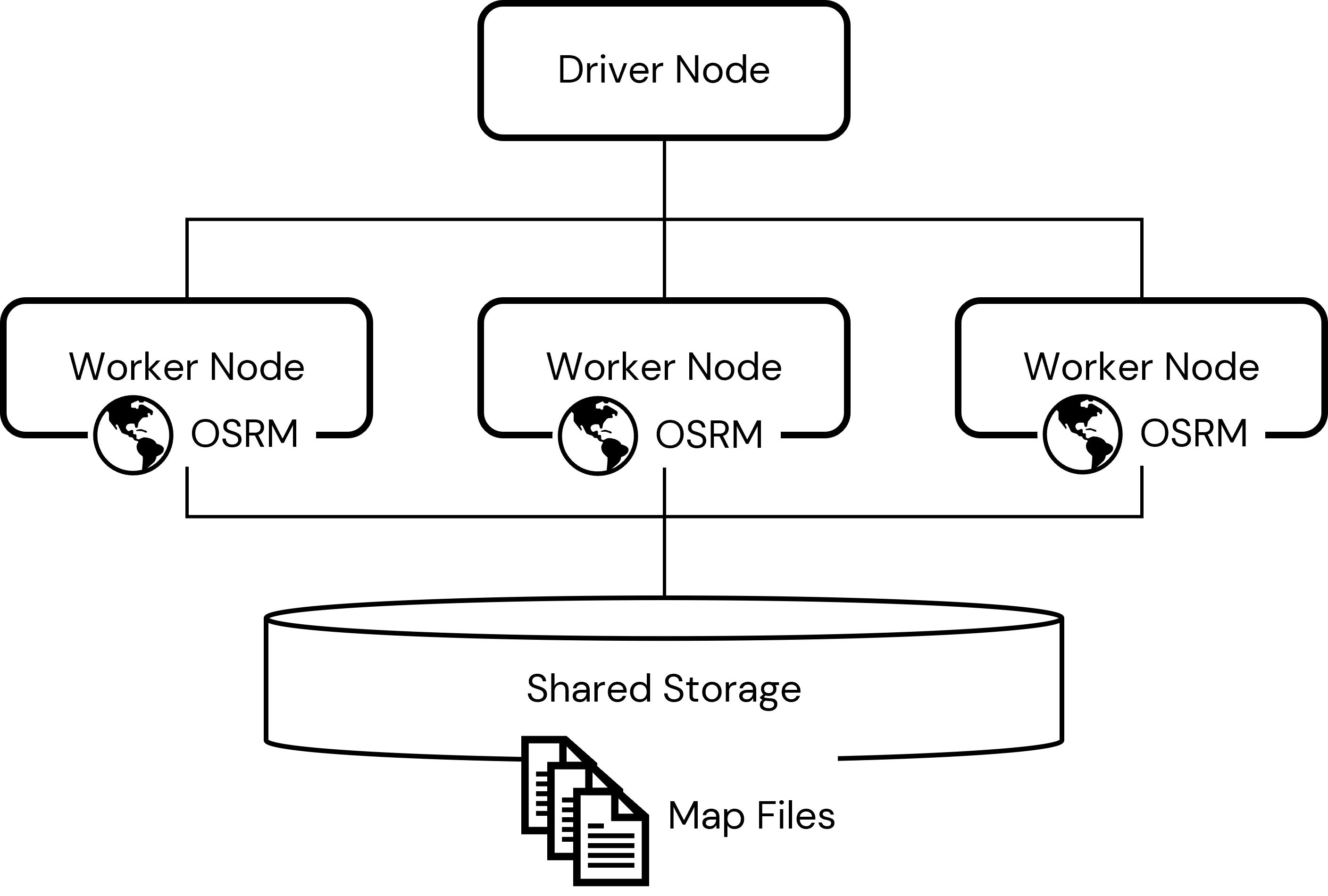
OSRMバックエンドサーバーのそれぞれのインスタンスは、地図データへのアクセスを必要とします。それぞれのワーカーノードが共有され一貫性のあるロケーションから容易にアクセスできるように、このデータは共有ストレージに保存されます。このデータはOSRMソフトウェアが使用する前にダウンロードされ前処理される必要があります。このデータを使用できるように準備する(そして、OSRMバックエンドサーバーソフトウェア自体をコンパイルする)ために、ワーカーノードを持たない軽量クラスター、すなわちシングルノードクラスターを使用します。Databricksワークスペースの任意のクラスターからアクセスできる共有ストレージロケーションに処理済み地図データ(とコンパイル済みのソフトウェア)を格納します。
クラスターデプロイメントのトポロジーを計画する際、OSRMソフトウェアがメモリーに幾分大きな地図ファイルをロードすることに留意することが重要です。これは、ルート解決を高速にしますが、OSRMソフトウェアインスタンスをホストするそれぞれのコンピューターにある一定量のRAMを持つ必要があります。十分なメモリーがない場合、OSRMソフトウェアは多くの場合、明確なメッセージを出さずにシャットダウンしてしまいます。 前処理のステップが成功した際に得られる地図ファイルによって必要なRAMの総量に注意してください。そして、必要に応じてルーティングのクラスターデプロイメントのワーカーノードのサイズを調整してください。
ソリューションアクセラレータのノートブック
このソリューションアクセラレータは3つのノートブックから構成されます。それぞれがOSRMがインテグレーションされたデプロイメントの固有の用途に取り組んでおり、順番に実行する必要があります。
- RT 00: Introduction - ソリューションアクセラレータのシナリオを紹介します
- RT 01: Setup OSRM Server - OSRMソフトウェアをコンパイルし、OpenStreetMapファイルを前処理します
- RT 02: Generate Routes - データ処理の一環としてルートを生成するためにOSRMソフトウェアを使用します
OSRMサーバーのセットアップ
イントロダクション
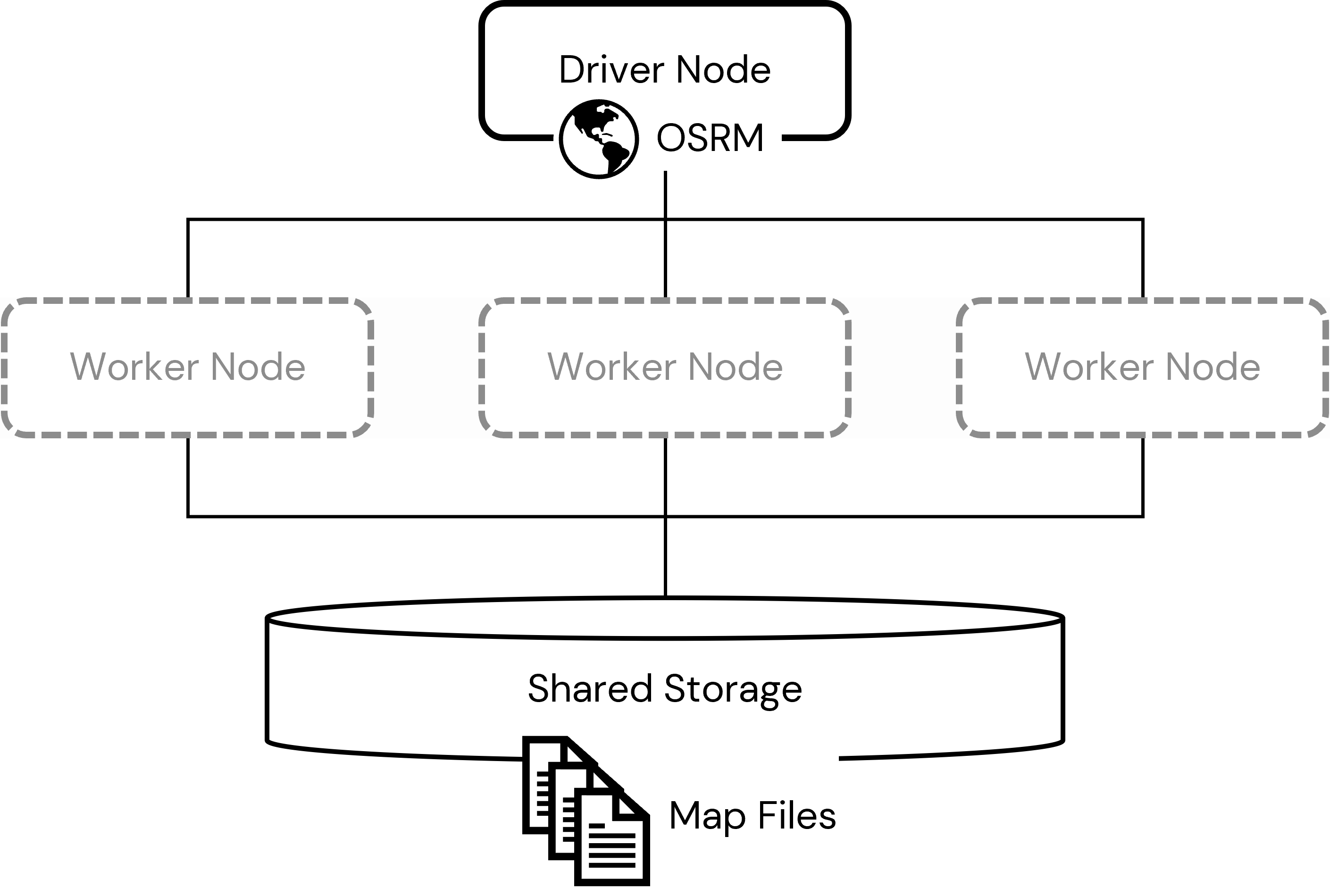
このノートブックで行うステップは、DatabricksクラスターでOSRMバックエンドサーバーを実行するために必要なアセットをどのように準備するのかを説明します。これらのステップは頻繁には実行せず、OSRMを装備したDatabricksクラスターを起動する前に一度実行する場合が多いです。
この作業を行うためには、シングルノードクラスター、すなわち、ドライバーのみでワーカーノードを持たないクラスターを使用することをお勧めします。(シングルノードクラスターをデプロイするにはCreate ClusterページのCluster Modeドロップダウンからsingle nodeを選択します) ドライバーノードには、処理する地図ファイルのサイズよりも遥かに大きいRAMを割り当てる必要があります。ドライバーノードのサイジングに関するガイドラインとしては、GeoFabrik websiteからダウンロードした11.5GBの北米の .osm.pbf 地図ファイルの処理に128GBのRAMのドライバーノードが必要となりました。
Step 1: サーバーソフトウェアの構築
スタートするには、its GitHub repositoryから利用できる現在のソースコードからOSRMバックエンドサーバーを構築する必要があります。プロジェクトチームによって提供されているBuild from Source instructionsは、このための基本的なステップをカバーしています。以下のように我々の環境にパッケージの依存関係をインストールするところからスタートします。
依存関係のインストール
%sh -e
sudo apt -qq install -y build-essential git cmake pkg-config \
libbz2-dev libxml2-dev libzip-dev libboost-all-dev \
lua5.2 liblua5.2-dev libtbb-dev
次に、我々のローカルシステムにOSRMバックエンドサーバーリポジトリをクローンします。
%sh -e
# make directory for repo clone
mkdir -p /srv/git
cd /srv/git
# clone the osrm backend server repo
rm -rf osrm-backend
git clone --depth 1 -b v5.26.0 https://github.com/Project-OSRM/osrm-backend
そしてサーバーを構築します:
注意
このステップは、お使いのDatabrikcsクラスターのサイズに応じて完了するまでに20分以上かかることがあります。
OSRMバックエンドサーバーの構築
%sh -e
cd /srv/git/osrm-backend
mkdir -p build
cd build
cmake ..
cmake --build .
sudo cmake --build . --target install
Step 2: 地図ファイルの準備
OSRMバックエンドサーバーは地図データを使ってルートを生成します。特定リージョンの地図は .osm.pbf ファイルとしてGeoFabrik download siteから利用することができます。要件に応じて、特定の大陸、国、リージョンレベルの地図ファイルを活用しても構いません。
使用するファイルはOSRMソフトウェアが利用する前にダウンロードして前処理する必要があります。前処理の過程では、2つの前処理のパスから選択し、ルーティングが車によるものなのか、徒歩や他の移動手段によるものなのかを選択する必要があります。これらのオプションの詳細に関しては、こちらを参照ください。ここでは、前処理のパスとしては、車移動を選択する際にはOSRMドキュメントで好まれているMulti-Level Dijkstra (MLD)を選択しました。
注意
地図ファイルのサイズによっては、ダウンロードと前処理ステップが完了するまである程度の時間を要する場合があります。
最初のステップは使用する地図ファイルのダウンロードです:
注意
このステップは北米の地図ファイルの場合は15分程度必要とします。
地図ファイルのダウンロード
%sh -e
# create clean folder to house downloaded map file
rm -rf /srv/git/osrm-backend/maps/north-america
mkdir -p /srv/git/osrm-backend/maps/north-america
# download map file to appropriate folder
cd /srv/git/osrm-backend/maps/north-america
wget --quiet https://download.geofabrik.de/north-america-latest.osm.pbf
# list folder contents
ls -l .
次に、我々が選択した移動手段を示すプロファイルを指定する地図ファイルアセットを抽出します。osrm-extract コマンドの出力は非常に多いことに注意してください。セルの出力を溢れさせないために、ログファイルに標準出力をリダイレクトし、完了したことを検証するためにそのファイルの最後の数行を確認します:
注意
このステップは北米地図ファイルの場合1時間程度必要とします。
地図ファイルのコンテンツの抽出
%sh -e
# setup location to house log files
mkdir -p /srv/git/osrm-backend/logs
# move to folder housing map file
cd /srv/git/osrm-backend/maps/north-america
# extract map file contents
/srv/git/osrm-backend/build/osrm-extract north-america-latest.osm.pbf -p /srv/git/osrm-backend/profiles/car.lua > /srv/git/osrm-backend/logs/extract_log.txt
# review output from extract command
#echo '----------------------------------------'
#tail /srv/git/osrm-backend/logs/extract_log.txt
続ける前に、osrm-extractコマンドの出力の最後の数行をチェックするようにしてください。[info] RAM: peak bytes usedで終わるメッセージを受け取らなかった場合、クラスターのドライバーノードに十分なメモリーがなかったことから抽出プロセスがクラッシュしている可能性が高いです。クラッシュした場合には、コマンド出力でエラーが確認できない場合があります。
RAM使用に関するメッセージを受け取ったとしても、 .osm.pbf ファイルが保存されているフォルダーに大量のファイルが存在していることを確認することで、抽出が成功したことを検証することは良いアイデアです。
MLD前処理パスの次のステップは抽出ファイルからコンテンツをパーティショニングすることとなります。
注意
このステップは北米地図ファイルの場合、1時間程度要します。
抽出地図ファイルのパーティション
%sh -e
cd /srv/git/osrm-backend/maps/north-america
/srv/git/osrm-backend/build/osrm-partition north-america-latest.osrm
そして、最後にこの前処理パスに関連づけられた指示に従ってコンテンツをカスタマイズします:
注意
5分程度かかります。
抽出地図ファイルのカスタマイズ
%sh -e
cd /srv/git/osrm-backend/maps/north-america
/srv/git/osrm-backend/build/osrm-customize north-america-latest.osrm
Step 3: OSRMアセットの永続化
OSRMバックエンドサーバーと関連する地図アセットは、クラスターのドライバーノードの /srv/git フォルダーに作成されました。このフォルダーは一時的なものであり、ドライバーノードからしかアクセスすることができません。これは、クラスターが停止されると、これらすべてのアセットは失われることを意味します。クラスターが再起動しても再利用できる様に、これらのアセットを永続化するには、これらを永続化ロケーションにコピーする必要があります。Databricksでは、クラウドストレージのマウントを利用することができます。また、シンプルにビルトインのFileStoreストレージロケーションを使用することもできます。
注意
15分程度かかります。
OSRMアセットを永続化ロケーションにコピー
%sh -e
rm -rf /dbfs/FileStore/osrm-backend
cp -L -R /srv/git/osrm-backend /dbfs/FileStore/osrm-backend
Step 4: initスクリプトの作成
この時点で、OSRMバックエンドサーバーを実行するために必要なすべての要素が揃いました。ここでは、Databricksクラスターのそれぞれのワーカーノードにサーバーがデプロイされる様に、クラスターinitスクリプトを定義する必要があります。
このスクリプトのロジックは非常にわかりやすいものとなっています。パッケージの依存関係をインストール(すでに大部分は行いました)し、ルーティングサーバーを起動します。
ルーティングサーバーがルーティングのリクエストに反応するまでには少々の時間を要します。我々はサーバーをテストし、完全に起動するまで待つロジックを追加しました。このスクリプトを用いるクラスターにおいては、ジョブを完全に実行できるようになるまで数分の遅れが生じることになりますが、ワークフロー(ジョブ)の一部として実行されるロジックの様に、クラスターの起動後即座にロジックが実行され、成功することを保証することができる様になります。
initスクリプトはDBFSファイルシステムの中のアクセス可能なロケーションに書き込む様にしてください。この様なロケーションは、クラスターのスタートアップの過程でスクリプトにアクセスするために必要となります。
注意
initスクリプトを設定したクラスターの起動には10分程度要します。
initスクリプトの作成
# make folder to house init script
dbutils.fs.mkdirs('dbfs:/databricks/scripts')
# write init script
dbutils.fs.put(
'/databricks/scripts/osrm-backend.sh',
'''
#!/bin/bash
if [[ $DB_IS_DRIVER != "TRUE" ]]; then
echo "installing osrm backend server dependencies"
sudo apt -qq install -y build-essential git cmake pkg-config libbz2-dev libxml2-dev libzip-dev libboost-all-dev lua5.2 liblua5.2-dev libtbb-dev
echo "launching osrm backend server"
/dbfs/FileStore/osrm-backend/build/osrm-routed --algorithm=MLD /dbfs/FileStore/osrm-backend/maps/north-america/north-america-latest.osrm &
echo "wait until osrm backend server becomes responsive"
res=-1
i=1
# while no response
while [ $res -ne 0 ]
do
# test connectivity
curl --silent "http://127.0.0.1:5000/route/v1/driving/-74.005310,40.708750;-73.978691,40.744850"
res=$?
# increment the loop counter
if [ $i -gt 40 ]
then
break
fi
i=$(( $i + 1 ))
# if no response, sleep
if [ $res -ne 0 ]
then
sleep 30
fi
done
fi
''',
True
)
# show script content
print(
dbutils.fs.head('dbfs:/databricks/scripts/osrm-backend.sh')
)
initスクリプトを定義すると、OSRMバックエンドサーバーが実行されるクラスターを設定することができます。このクラスターのワーカーノードのサイジングに関しては、ノートブック RT 00 のガイダンスを参照してください。
このアクセラレータのジョブとクラスターを作成するために、このフォルダーにあるRUNMEファイルを使用している場合、initスクリプトのセットアップステップが自動化されることに注意してください。手動でクラスターの設定を定義する場合は、上のセルで書き込まれるinitスクリプトのパスを指定してください。クラスターが起動すると、クラスターのそれぞれのノードは設定を反映するためにこのスクリプトを実行します。

ルート生成
イントロダクション
ソフトウェアと地図ファイルを準備することで、それぞれのワーカーにOSRMバックエンドサーバーのインスタンスがデプロイされた(複数のワーカーノードを持つ)クラスターを起動することができました。
デフォルトでワーカーノードに分散されるSparkデータフレームにあるポイントデータを用いることで、スケーラブルな方法でルーティングデータを生成するために、これらのサーバーインスタンスに対してローカルの呼び出しを行う一連の関数を定義することができます。
必要なライブラリのインストール
%pip install tabulate databricks-mosaic
必要なライブラリのインポート
import requests
import pandas as pd
import numpy as np
import json
import itertools
import subprocess
import pyspark.sql.functions as fn
from pyspark.sql.types import *
# mosaic import and configuration
import mosaic as mos
spark.conf.set('spark.databricks.labs.mosaic.geometry.api', 'ESRI')
spark.conf.set('spark.databricks.labs.mosaic.index.system', 'H3')
mos.enable_mosaic(spark, dbutils)
from tabulate import tabulate
Step 1: それぞれのワーカーで稼働するサーバーの検証
最初のステップは、それぞれのワーカーノードで実行されるOSRMバックエンドサーバーが期待通りに動作していることを確認することになります。このためには、クラスターのワーカーに対して小規模なデータセットの分散を強制するいにしえのSpark RDDを用いて、クラスターのそれぞれのIPアドレスを明らかにする必要があります。
さらにこれを理解するためには、それぞれのワーカーノードにおいて利用できるメモリーとプロセッサーのリソースが、Java Virtual Machines (JVM)でどのように分割されるのかを知ることが助けとなります。これらのJVMは Executors として参照され、Spark RDDやSparkデータフレームのデータのサブセットを保持します。多くの場合、エグゼキューターとワーカーノードには1対1の関係がありますが、常にそうと言う訳ではありません。
sc.defaultParallelismプロパティは、クラスターのワーカーノードで利用できるプロセッサーの数をトラックし、この数に等しい値のレンジの並列度を用いてSpark RDDを用いることで、それぞれの仮想コアに1つの整数値を関連づけます。そして、sc.runJobメソッドが、RDDのそれぞれの値が存在するマシンのパブリックIPアドレスを収集する hostname -I コマンドのローカルインスタンスを実行するPythonのsubprocess.runメソッドを強制します。出力はコマンドによって識別されるユニークなIPの値を返却するために、Pythonのsetに変換されるlistとして返却されます。
このようなシンプルなタスクに対して多くの説明があるように聞こえますが、このノートブックの後半で別の関数呼び出しを行う際に同じパターンを用いることに注意してください。
ワーカーノードのIPアドレスの取得
# generate RDD to span each executor on each worker
myRDD = sc.parallelize(range(sc.defaultParallelism))
# get set of ip addresses
ip_addresses = set( # conversion to set deduplicates output
sc.runJob(
myRDD,
lambda _: [subprocess.run(['hostname','-I'], capture_output=True).stdout.decode('utf-8').strip()] # run hostname -I on each executor
)
)
ip_addresses

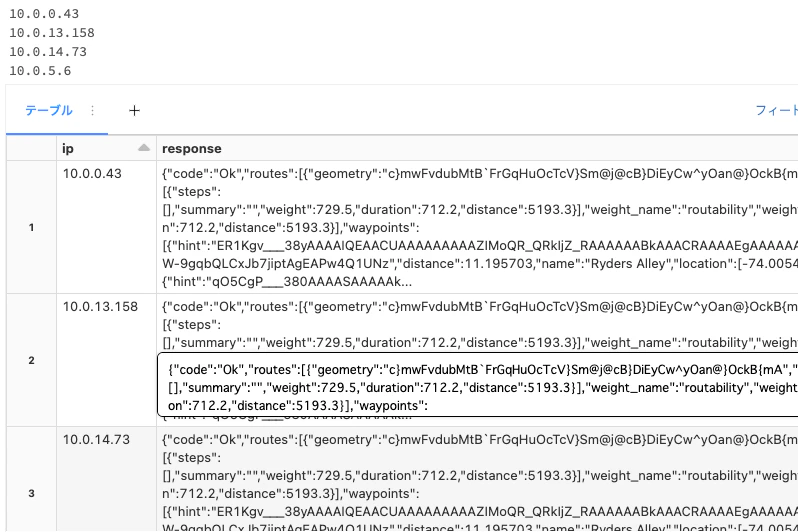
ワーカーノードのIPアドレスがわかったので、それぞれからルーティングのレスポンスをリクエストすることで、デフォルトポート5000でリッスンしているそれぞれのOSRMバックエンドサーバーのレスポンスをクイックにテストすることができます。
ルーティングレスポンスに対するそれぞれのワーカーのテスト
responses = []
# for each worker ip address
for ip in ip_addresses:
print(ip)
# get a response from the osrm backend server
resp = requests.get(f'http://{ip}:5000/route/v1/driving/-74.005310,40.708750;-73.978691,40.744850').text
responses += [(ip, resp)]
# display responses generated by each worker
display(
pd.DataFrame(responses, columns=['ip','response'])
)
Step 2: ルート生成データの取得
どのようにクラスターでルーティング能力を活用できるのかをデモンストレーションするためには、ルートを生成するためのデータを取得する必要があります。それぞれのDatabricksワークスペースには、この様なデータへの容易なアクセスを提供するNYC Taxi datasetがあります。
NYC Taxi (yellow cab)データセットは現時点で1.6億レコードから構成されています。この作業を管理できるようにするために、狭い範囲の期間のタクシーの乗車にフォーカスします。
NYC Taxiデータへのアクセス
nyc_taxi = (
spark.read
.format('delta')
.load('dbfs:/databricks-datasets/nyctaxi/tables/nyctaxi_yellow/')
.filter(fn.expr("pickup_datetime < '2016-01-01 00:00:00' AND dropoff_datetime > '2016-01-01 00:00:00'")) # stuck in cab at midnight on new years day
.filter(fn.expr('pickup_latitude is not null and dropoff_latitude is not null')) # valid coordinates
.withColumn('trip_meters', fn.expr('trip_distance * 1609.34'))
.withColumn('trip_seconds', fn.expr('datediff(second, pickup_datetime, dropoff_datetime)'))
)
display(nyc_taxi)
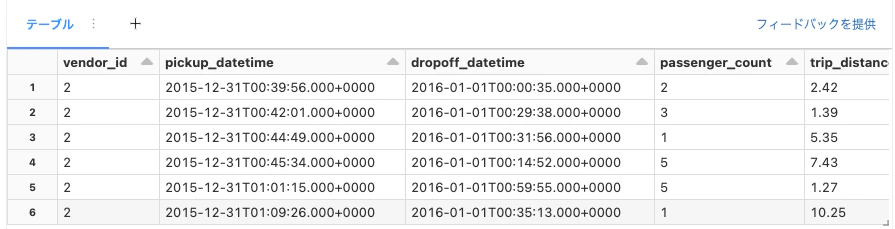
データプロバイダーによって提供されるデータ辞書情報によると、このデータセットのフィールドは以下を表現しています。
-
vendor_id - レコードを提供したTPEPプロバイダーのコード:
- 1= Creative Mobile Technologies, LLC.
- 2= VeriFone Inc.
- pickup_datetime - メーターが倒された日時です。
- dropoff_datetime - メーターが解除された日時です。
- passenger_count 乗客数。ドライバーによる入力値です。
- trip_distance - タクシーメーターで報告された移動距離(マイル)です。
- pickup_longitude, pickup_latitude - タクシーメーターが倒されたTLC Taxiのゾーンです。
-
rate_code_id - 移動後に入力された最終的なレートコード:
- 1 = Standard rate
- 2 = JFK
- 3 = Newark
- 4 = Nassau or Westchester
- 5 = Negotiated fare
- 6 = Group ride
- 1 = Standard rate
-
store_and_fwd_flag - このフラグはベンダーに送信する前に移動記録が車両のメモリーに登録されたかどうかを示します。自動車にサーバーに接続する能力がない場合にはメモリーに格納されます。「格納して転送」を意味します:
- Y= store and forward trip
- N= not a store and forward trip.
- Y= store and forward trip
- dropoff_longitude, dropoff_latitude - タクシーメーターが解除されたTLC Taxiゾーンです。
-
payment_type 乗客が移動に対してどの様に支払いを示したのかを示す数値のコードです:
- 1= Credit card
- 2= Cash
- 3= No charge
- 4= Dispute
- 5= Unknown
- 6= Voided trip
- 1= Credit card
- fare_amount - メーターによって計算された、時間と距離の料金です。
-
extra - 追加料金とサーチャージです。現在、これにラッシュアワーと深夜料金の
$0.50と$1のみが含まれます。 -
mta_tax - 使用中のメーターレートに応じて
$0.50のMTA税が自動で適用されます。 - tip_amount – クレジットカードのチップがある場合に自動でこのフィールドが埋められます。現金のキャッシュは含まれません。
- tolls_amount - 移動で支払われた通行料の総額です。Total amount of all tolls paid in trip.
- total_amount - 乗客にチャージされた総額です。現金のチップは含まれません。
これらのフィールドに加えて、OSRMバックエンドサーバーから受け取る内容と一貫性がある形で、距離と時間の情報を提供するために2つのフィールドtrip_metersとtrip_secondsを計算しました。
Step 3: 移動ルートの取得
NYC Taxiデータセットにはそれぞれの移動の開始地点と終了地点が記録されています。我々は正確なルートを知らないので、本日移動する際にベストなルートを特定するために、OSRMバックエンドサーバーのroute メソッドを使用することができます。これを有効化するために、それぞれの移動のピックアップ地点、降車地点の緯度経度を引き渡す関数を記述します。この関数は、OSRMバックエンドサーバーからのルートをリクエストし、結果のJSONドキュメントを返却するためにこのデータを使用します。
ルートを取得すための関数の定義
@fn.pandas_udf(StringType())
def get_osrm_route(
start_longitudes: pd.Series,
start_latitudes:pd.Series,
end_longitudes: pd.Series,
end_latitudes: pd.Series
) -> pd.Series:
# combine inputs to form dataframe
df = pd.concat([start_longitudes, start_latitudes, end_longitudes, end_latitudes], axis=1)
df.columns = ['start_lon','start_lat','end_lon','end_lat']
# internal function to get route for a given row
def _route(row):
r = requests.get(
f'http://127.0.0.1:5000/route/v1/driving/{row.start_lon},{row.start_lat};{row.end_lon},{row.end_lat}?alternatives=true&steps=false&geometries=geojson&overview=simplified&annotations=false'
)
return r.text
# apply routing function row by row
return df.apply(_route, axis=1)
この関数を理解するためには、データフレームのデータがクラスターのワーカーノードの仮想コアに割り当てられたエグゼキューターに対して分散されるサブセット(パーティション)に分割されることに注意してください。(エグゼキューターの概念に関しては、IPアドレスを取得しているセクションの説明をご覧ください) この関数をSparkデータフレームに適用すると、データフレーム自身の並列性に基づき、それぞれのパーティションに並列で適用されます。
この関数に指定される引数を通じて、それぞれのパーティションから値を受け取ります。それぞれの引数はカラムにマッピングされ、それぞれのカラムから、値に対応する複数の行がそれぞれの引数のpandasのSeriesとして受け取ります。Seriesによって受け取られる値の数は、パーティションのサイズと設定 spark.databricks.execution.pandasUDF.maxBatchesToPrefetch に依存します。
それぞれのseriesの値は同じ順番でソートされます。これらのseriesを結合すると、パーティションにあるデータの行を際作成することができます。結果のpandasデータフレームのそれぞれの行に対して、OSRMバックエンドサーバーのローカルインスタンスにリクエストを行う内部で定義した関数を適用します。バックエンドサーバーはJSON文字列としてルーティング情報を返却します。このJSON文字列は、pandasデータフレームのそれぞれに対して返却され、返却された値の結果の文字列は、Sparkデータフレームに組み込むために外部関数からSparkエンジンに送信されます。
ユーザー定義関数(UDF)で定義されたそれぞれの引数に対するpandasのSeriesとして値のセットを受け取り、pandasのシリーズとして対応する結果セットを返却する、この全体的なパターンによって、この関数をpandasのSeries-to-Seriesユーザー定義関数にします。このタイプのpandas UDFに関してはこちらを参照ください。
我々のデータにpandas UDFを適用するには、以下の様にシンプルにwithColumnメソッド呼び出しのコンテキストでUDFを使用するだけです。
ルートの取得
display(
nyc_taxi
.withColumn(
'osrm_route',
get_osrm_route('pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude')
)
.selectExpr(
'pickup_datetime',
'dropoff_datetime',
'pickup_longitude',
'pickup_latitude',
'dropoff_longitude',
'dropoff_latitude',
'osrm_route',
'fare_amount',
'trip_meters',
'trip_seconds'
)
)
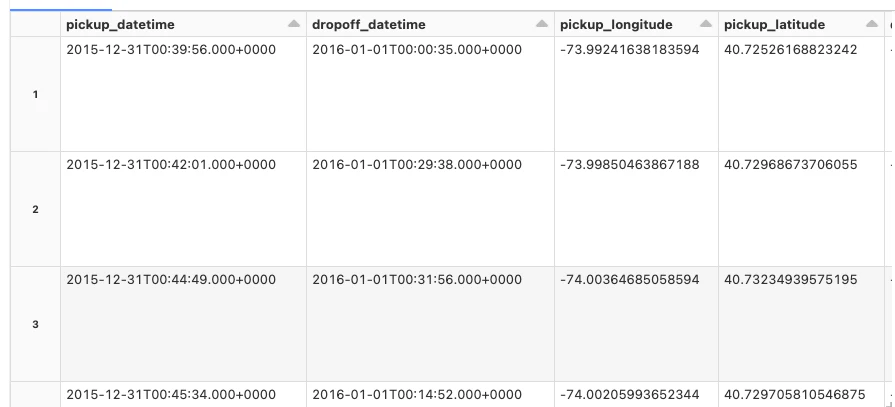
関数呼び出しの結果はJSON文字列となります。pandas UDFはpandas UDFとSparkエンジンの間ですべての複雑な型をまとめる能力を持たないので、複雑なデータ型ではなく文字列を返却する様にしました。このため、文字列を複雑なデータ表現に変換する必要がある場合には、関数がこの処理を終えた後に行う必要があります。
例えば、戻り値を希望の複雑な型に変換するために、文字列ベースのJSONスキーマの表現を指定し、このスキーマを引数としてfrom_jsonを適用します。
注意
従来のPySparkデータ型表現を用いてスキーマを定義したいのであれば、同様に動作する様子をこのノートブックの後半で説明しています。
ルートのJSONを複雑なデータ型表現に変換
# schema for the json document
response_schema = '''
STRUCT<
code: STRING,
routes:
ARRAY<
STRUCT<
distance: DOUBLE,
duration: DOUBLE,
geometry: STRUCT<
coordinates: ARRAY<ARRAY<DOUBLE>>,
type: STRING
>,
legs: ARRAY<
STRUCT<
distance: DOUBLE,
duration: DOUBLE,
steps: ARRAY<STRING>,
summary: STRING,
weight: DOUBLE
>
>,
weight: DOUBLE,
weight_name: STRING
>
>,
waypoints: ARRAY<
STRUCT<
distance: DOUBLE,
hint: STRING,
location: ARRAY<DOUBLE>,
name: STRING
>
>
>
'''
# retrieve routes and convert json to struct
nyc_taxi_routes = (
nyc_taxi
.withColumn(
'osrm_route',
get_osrm_route('pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude')
)
.withColumn(
'osrm_route',
fn.from_json('osrm_route',response_schema)
)
.selectExpr(
'pickup_datetime',
'dropoff_datetime',
'osrm_route',
'trip_meters',
'trip_seconds'
)
)
display(
nyc_taxi_routes
)
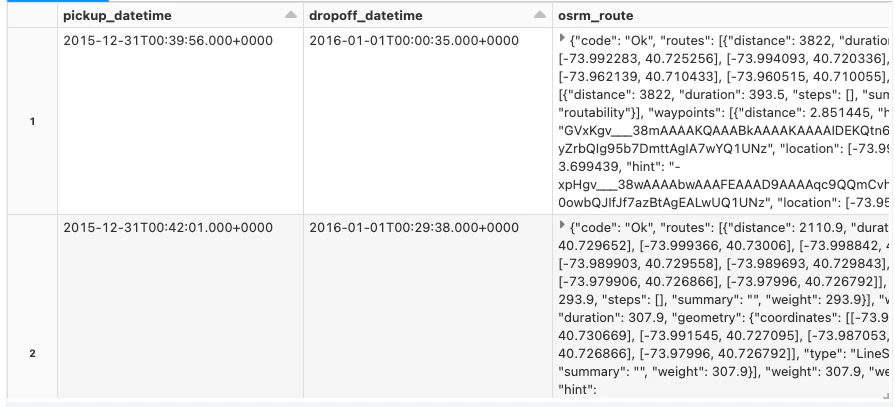
JSONドキュメントの構造はOSRMバックエンドサーバーによって定義されます。これらの要素はシンプルなドット表記参照で抽出することができます。
注意
JSONドキュメント内では、ドキュメントあたり一つのルートのみ存在したとしても、ルートは配列として表現されます。explode関数は配列を展開し、配列のそれぞれの要素のフィールドの重複を発生させます。ルートの配列に1つのルートしかないので、この関数呼び出しはデータセットのサイズは増加しません。
ルートから距離と時間を取得
display(
nyc_taxi_routes
.withColumn('route', fn.explode('osrm_route.routes'))
.withColumn('route_meters', fn.col('route.distance'))
.withColumn('route_seconds', fn.col('route.duration'))
.selectExpr(
'pickup_datetime',
'dropoff_datetime',
'trip_meters',
'route_meters',
'trip_seconds',
'route_seconds'
)
)
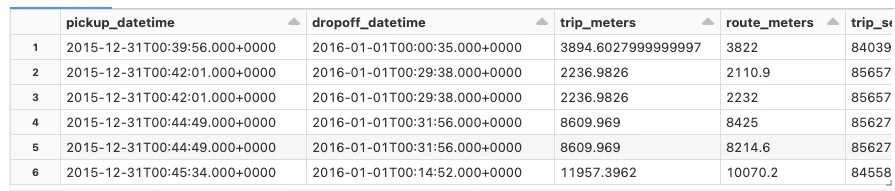
距離や時間のような属性に加え、OSRMバックエンドサーバーによって返却されるルート情報にはGeoJSON formatに準拠したgeometry要素が含まれています。Databricks Mosaicライブラリのst_geomfromgeojson とst_aswkbメソッドを用いることで、この要素を標準的な表現に変換します。
ルートジオメトリの取得
nyc_taxi_geometry = (
nyc_taxi_routes
.withColumn('route', fn.explode('osrm_route.routes')) # explode routes array
.withColumn('geojson', fn.to_json(fn.col('route.geometry')))
.withColumn('geom', mos.st_aswkb(mos.st_geomfromgeojson('geojson')))
.drop('osrm_route')
)
display(nyc_taxi_geometry)

そして、我々のルートデータの情報の検証に役立てるために、Kepler visualizationを用いてこの標準ジオメトリを可視化することができます。
注意
mosaic_kepler magic commandの構文は、dataset column_name feature_type [row_limit]です。表示結果の右上のトグルを用いて、可視化の調整を行うことができます。
ルートの可視化
%%mosaic_kepler
nyc_taxi_geometry geom geometry 5000
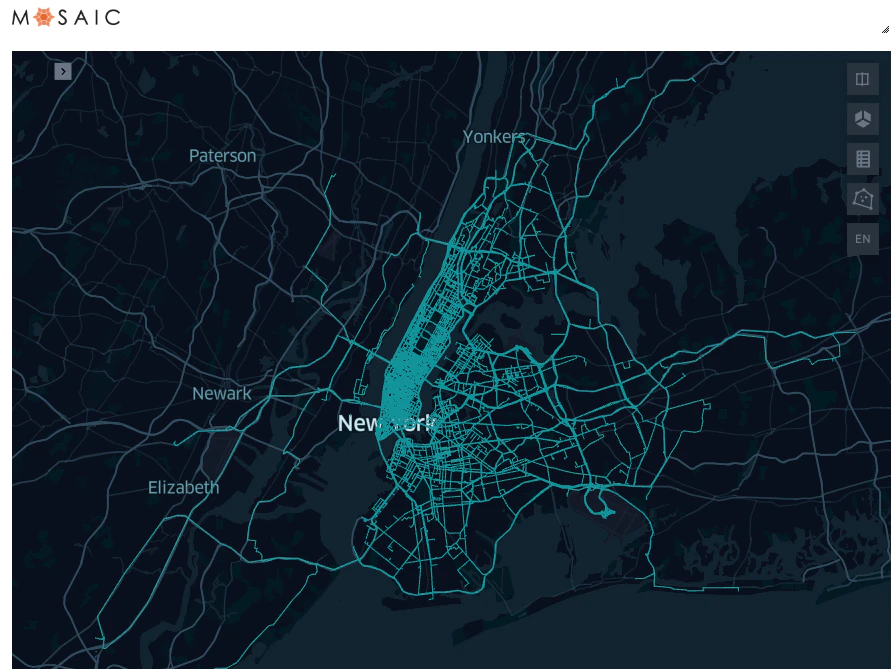
しかし、もちろんですが、我々はOSRMバックエンドサーバーからルーティングデータを取得することに限定されません。我々のゴールがポイント間の移動の最適化であるのならば、移動時間のテーブルを作成する必要があるかもしれません。このためには、OSRMバックエンドサーバーのtable methodを呼び出す関数を記述することができます。
ドライブ時間テーブルの取得
@fn.pandas_udf(StringType())
def get_driving_table(
points_arrays: pd.Series
) -> pd.Series:
# internal function to get table for points in an array
def _table(points_array):
points = ';'.join(points_array)
r = requests.get(
f'http://127.0.0.1:5000/table/v1/driving/{points}'
)
return r.text
# apply table function row by row
return points_arrays.apply(_table)
この関数を呼び出すためにはポイントのコレクションを提供する必要があります。NYCタクシーデータはこれに適した良い方法を提供していませんので、勝手に1秒周期ですべてのポイントに取り込む必要があることにしましょう。
注意
この例の集計は、上で定義したget_driving_table関数にどの様に値を渡すのかをデモンストレーションするための、ある意味不自然なものとなっています。
# schema for driving table
response_schema = StructType([
StructField('code',StringType()),
StructField('destinations',ArrayType(
StructType([
StructField('hint',StringType()),
StructField('distance',FloatType()),
StructField('name',StringType()),
StructField('location',ArrayType(FloatType()))
])
)
),
StructField('durations',ArrayType(ArrayType(FloatType()))),
StructField('sources',ArrayType(
StructType([
StructField('hint',StringType()),
StructField('distance',FloatType()),
StructField('name',StringType()),
StructField('location',ArrayType(FloatType()))
])
))
])
# retrieve driving table and extract matrix
driving_tables = (
nyc_taxi
.withColumn('pickup_point', fn.expr("concat(pickup_longitude,',',pickup_latitude)"))
.withColumn('pickup_window', fn.expr("window(pickup_datetime, '1 SECONDS')"))
.groupBy('pickup_window')
.agg(fn.collect_set('pickup_point').alias('pickup_points'))
.filter(fn.expr('size(pickup_points) > 1')) # more than one point required for table
.withColumn('driving_table', get_driving_table('pickup_points'))
.withColumn('driving_table', fn.from_json('driving_table', response_schema))
.withColumn('driving_table_durations', fn.col('driving_table.durations'))
)
display(driving_tables)
ドライビングテーブルから抽出したマトリクスを検証する際には、ルーティングが異なる場合があるため、方向が異なる際は推定されたドライビング時間に対称性がないことに注意することが重要です。データセットから取得したマトリクスの一つを以下に示します。
単一のドライビングテーブルの表示
# generate a single table
driving_table = driving_tables.limit(1).collect()[0]['driving_table_durations']
# print driving table
print(
tabulate(
np.array(driving_table),
tablefmt='grid'
)
)

OSRMバックエンドサーバーのroute と tableメソッドはサーバーのREST API経由で利用できるメソッドの2つです。利用できるメソッドの完全なリストを以下に示します。
- route - 指定された順序の座標間で最も早いルートを見つけ出します
- nearest - 座標をストリートネットワークにスナップし、近傍のnマッチを返却します
- table - 指定された座標のすべてのペア間で最速のルートの時間を計算します
- match - 指定されたGPS地点を最も納得いく方法で道路のネットワークにスナップします
- trip - 貪欲なヒューリスティック(farthest-insertion algorithm)を用いてセールスマン巡回問題を解きます
- tile - ベクタータイルの能力を持つslippy-mapビューアーで参照可能なMapbox Vector Tileを生成します
Sparkデータフレームの処理過程でこれらにアクセスできる様にするには、上述した様にシンプルにHTTP REST API呼び出しを行うpandas UDFを構築し、文字列として結果のJSONを返却し、上の例で示した様に結果に対して適切なスキーマを適用するだけです。