こちらのLangChain PySparkデータフレームローダーを動かしてみます。単一のメソッドでPySparkデータフレームをロードすることができます。以下でこちらのノートブックを動かしますが、LangchainではRetrievalQAがdeprecaedになっており、LCELへの移行が推奨されていますので、そちらに合わせてコードを変更しています。
LangchainのPySparkデータフレームローダーとMLFlow連携
このノートブックは、以下を含むPySparkとLangchainの統合を紹介します:
- PySpark DataframeからLangchainドキュメントローダーを作成する方法
- そのドキュメントローダーを使用してLangchain RetrievalQAインスタンスを作成する方法
- Mlflowを使用してRetrievalQAの例を保存する方法
要件
- Databricks Runtime 13.3 ML以上
- MLflow 2.5以上
インポート
%pip install --upgrade langchain faiss-cpu mlflow
dbutils.library.restartPython()
PySparkベースのドキュメントローディングを使用したRAGチェーンの作成
/databricks-datasets/内のWikipediaデータセットを使用しましょう。次のセルで、OpenAI APIキーを追加してください。
import os
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get(scope="demo-token-takaaki.yayoi", key="openai_api_key")
number_of_articles = 20
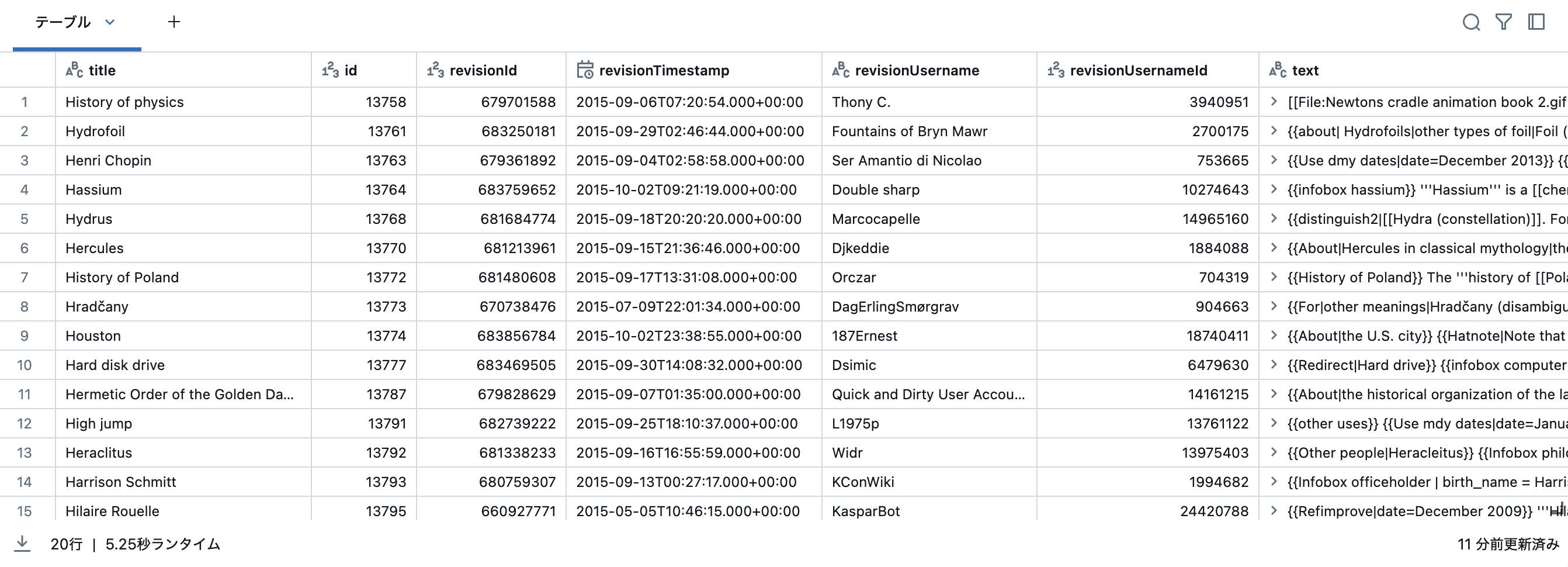
wikipedia_dataframe = spark.read.parquet("databricks-datasets/wikipedia-datasets/data-001/en_wikipedia/articles-only-parquet/*").limit(number_of_articles)
display(wikipedia_dataframe)
次の行は、PySparkデータフレームからLangchainにデータをロードするために必要なすべてです。
from langchain.document_loaders import PySparkDataFrameLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = PySparkDataFrameLoader(spark, wikipedia_dataframe, page_content_column="text")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=3000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
print(f"Number of documents: {len(texts)}")
Number of documents: 421
HuggingfaceEmbeddingsを使用してFAISSベクトルストアを作成する
このFAISSベクトルストアは、MLflowでモデルをログに記録できるようにするための中間ステップです。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
MLflow Traceが動きます。
RAGチェーンを作成する
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai.chat_models import ChatOpenAI
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# See full prompt at https://smith.langchain.com/hub/rlm/rag-prompt
prompt = hub.pull("rlm/rag-prompt")
llm=ChatOpenAI(model_name="gpt-4o-mini")
qa_chain = (
{
"context": db.as_retriever() | format_docs,
"question": RunnablePassthrough(),
}
| prompt
| llm
| StrOutputParser()
)
RAGチェーンにクエリを実行する
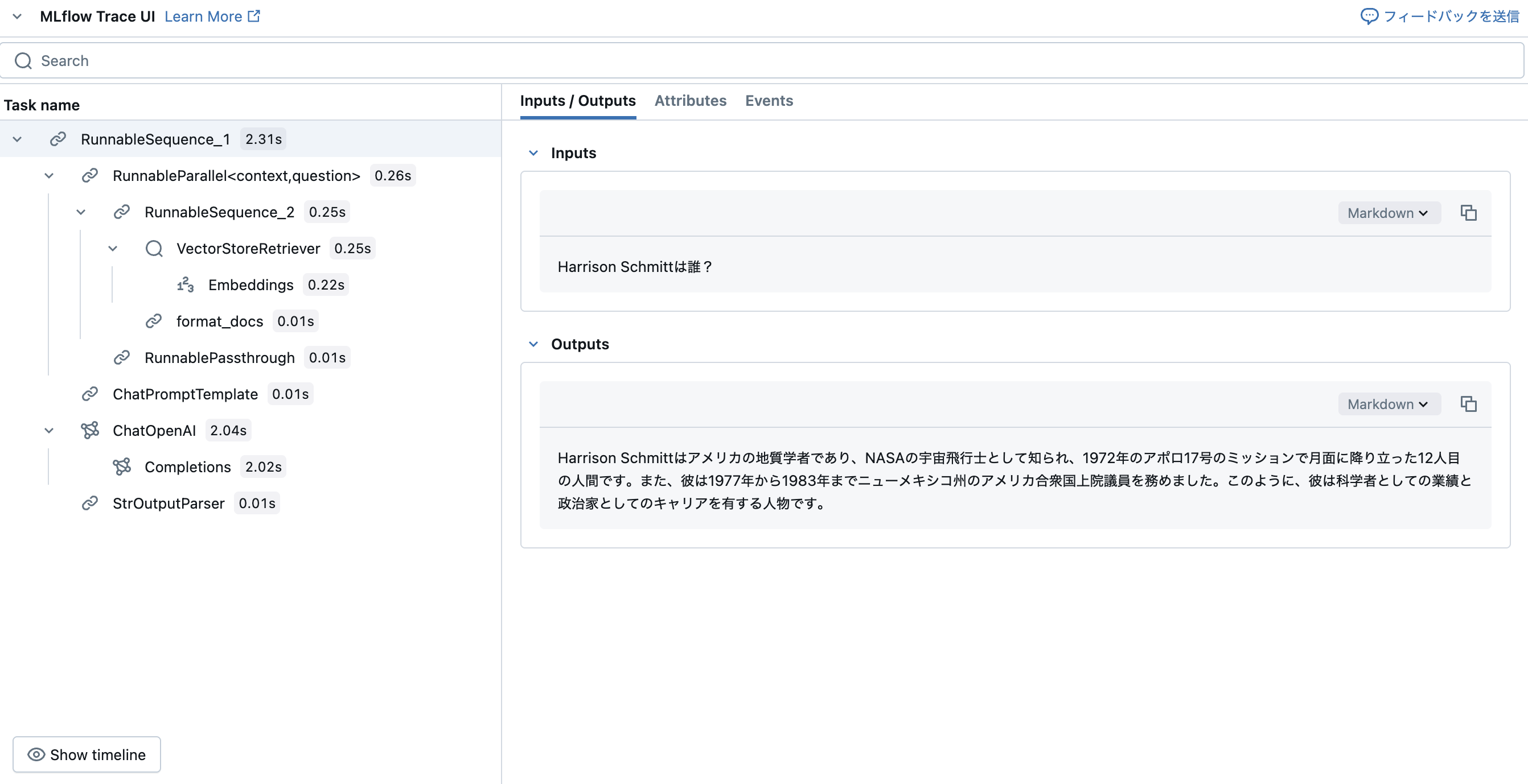
qa_chain.invoke("Harrison Schmittは誰?")
'Harrison Schmittはアメリカの地質学者であり、NASAの宇宙飛行士として知られ、1972年のアポロ17号のミッションで月面に降り立った12人目の人間です。また、彼は1977年から1983年までニューメキシコ州のアメリカ合衆国上院議員を務めました。このように、彼は科学者としての業績と政治家としてのキャリアを有する人物です。'
ここでもMLflow Traceでチェーンの動作を確認できます。
Mlflowでチェーンをログする
ここでは、以下のエラーに遭遇したので、こちらの記事を参考に、allow_dangerous_deserialization=Trueを追加しています。
ValueError: The de-serialization relies loading a pickle file. Pickle files can be modified to deliver a malicious payload that results in execution of arbitrary code on your machine.You will need to set
allow_dangerous_deserializationtoTrueto enable deserialization. If you do this, make sure that you trust the source of the data. For example, if you are loading a file that you created, and know that no one else has modified the file,
また、ValueError: Must specify a chain Type in configのエラーにも遭遇したので、model_config={"chain_type": "stuff"}を追加しています。
import mlflow
persist_directory = "langchain/faiss_index"
db.save_local(persist_directory)
def load_retriever(persist_directory):
embeddings = OpenAIEmbeddings()
db = FAISS.load_local(persist_directory, embeddings, allow_dangerous_deserialization=True)
return db.as_retriever()
# RetrievalQAチェーンをログに記録
with mlflow.start_run() as mlflow_run:
logged_model = mlflow.langchain.log_model(
qa_chain,
"retrieval_qa_chain",
loader_fn=load_retriever,
persist_dir=persist_directory,
model_config={"chain_type": "stuff"}
)
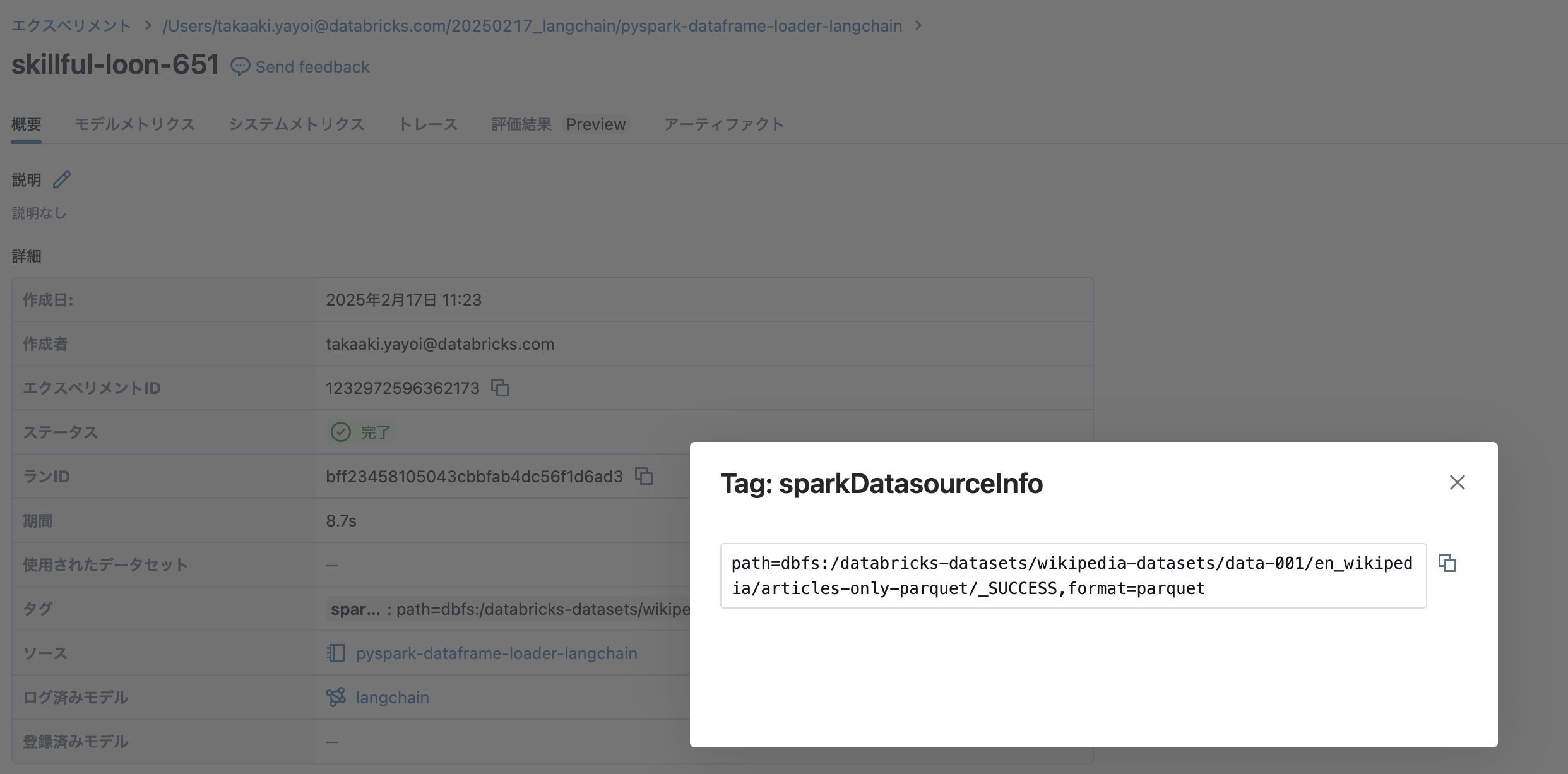
モデルが記録されます。PySparkデータフレームローダーのおかげか、sparkDatasourceInfoとしてデータソースのパスも記録されています。
MLflowでチェーンを読み込む
model_uri = f"runs:/{ mlflow_run.info.run_id }/retrieval_qa_chain"
loaded_pyfunc_model = mlflow.pyfunc.load_model(model_uri)
langchain_input = {"query": "Harrison Schmittは誰?"}
loaded_pyfunc_model.predict([langchain_input])
モデルがロードされ、チェーンを呼び出すことができました。
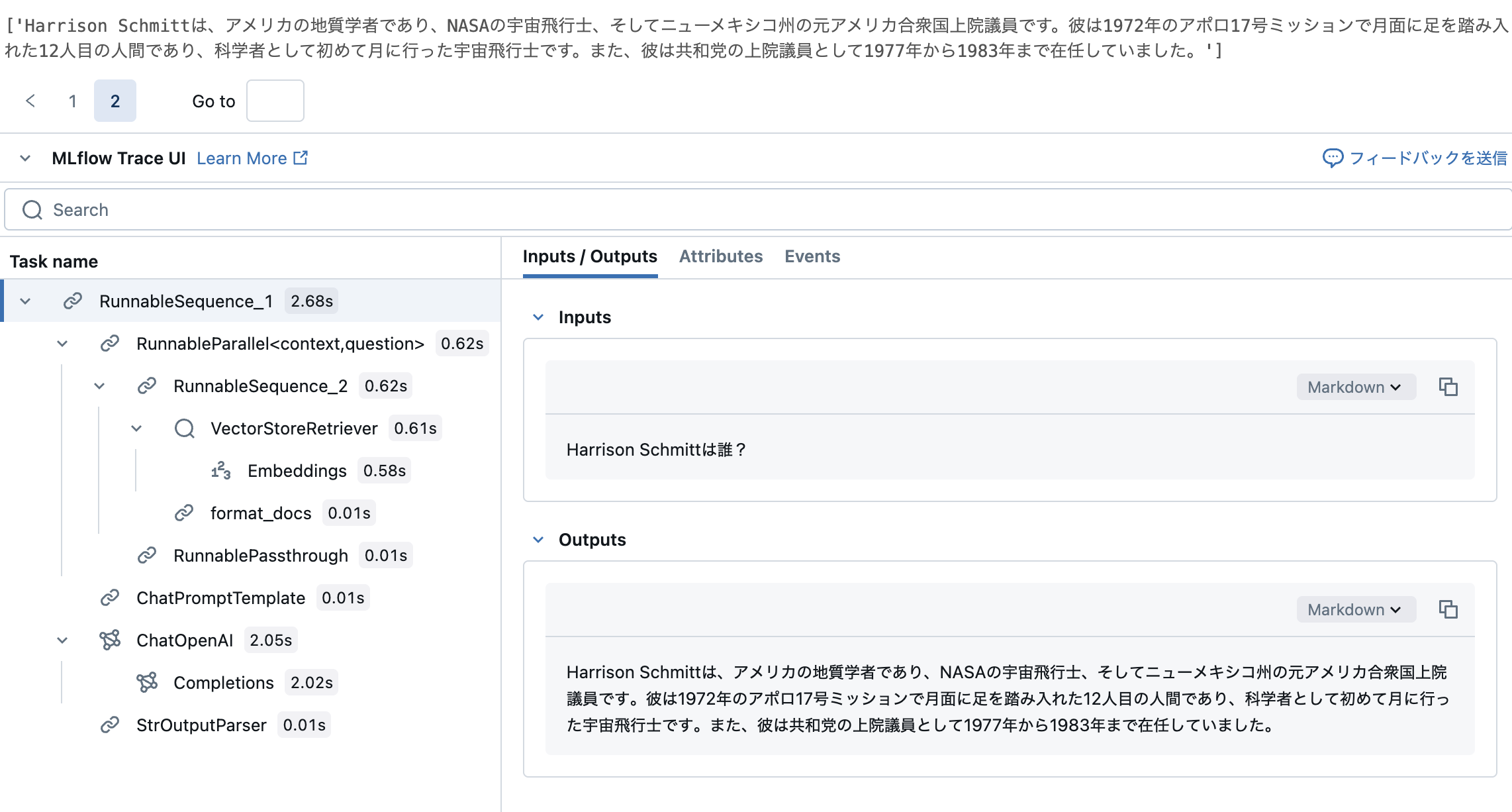
['Harrison Schmittは、アメリカの地質学者であり、NASAの宇宙飛行士、そしてニューメキシコ州の元アメリカ合衆国上院議員です。彼は1972年のアポロ17号ミッションで月面に足を踏み入れた12人目の人間であり、科学者として初めて月に行った宇宙飛行士です。また、彼は共和党の上院議員として1977年から1983年まで在任していました。']
ここでもMLflow Traceで挙動を確認できます。