2024/4/12に翔泳社よりApache Spark徹底入門を出版します!

書籍のサンプルノートブックをウォークスルーしていきます。Python/Chapter04/4-1 Example 4.1となります。
翻訳ノートブックのリポジトリはこちら。
ノートブックはこちら
from pyspark.sql.types import *
from pyspark.sql.functions import *
日付フォーマットを読めるフォーマットに変換するUDFを定義します。
注意
日付は文字列で年が含まれていないため、SQLのyear()関数を使うことが困難な場合があります。
def to_date_format_udf(d_str):
l = [char for char in d_str]
return "".join(l[0:2]) + "/" + "".join(l[2:4]) + " " + " " +"".join(l[4:6]) + ":" + "".join(l[6:])
to_date_format_udf("02190925")
'02/19 09:25'
ユーザー定義関数(UDF: User Defined Function)を登録します。
spark.udf.register("to_date_format_udf", to_date_format_udf, StringType())
<function __main__.to_date_format_udf(d_str)>
USを出発するフライトデータを読み込みます。
df = (spark.read.format("csv")
.schema("date STRING, delay INT, distance INT, origin STRING, destination STRING")
.option("header", "true")
.option("path", "/databricks-datasets/learning-spark-v2/flights/departuredelays.csv")
.load())

UDFをテストします。
df.selectExpr("to_date_format_udf(date) as data_format").show(10, truncate=False)
+------------+
|data_format |
+------------+
|01/01 12:45|
|01/02 06:00|
|01/02 12:45|
|01/02 06:05|
|01/03 12:45|
|01/03 06:05|
|01/04 12:43|
|01/04 06:05|
|01/05 12:45|
|01/05 06:05|
+------------+
only showing top 10 rows
SQLクエリーを実行する一次ビューを作成します。
df.createOrReplaceTempView("us_delay_flights_tbl")
クエリーに都合が良いようにテーブルをキャッシュします。
%sql
CACHE TABLE us_delay_flights_tbl
読みやすくなるようにすべてのdateをdate_fmに変換します。
注意
オンザフライで変換するためにUDFを使用しています。
spark.sql("SELECT *, date, to_date_format_udf(date) AS date_fm FROM us_delay_flights_tbl").show(10, truncate=False)
+--------+-----+--------+------+-----------+--------+------------+
|date |delay|distance|origin|destination|date |date_fm |
+--------+-----+--------+------+-----------+--------+------------+
|01011245|6 |602 |ABE |ATL |01011245|01/01 12:45|
|01020600|-8 |369 |ABE |DTW |01020600|01/02 06:00|
|01021245|-2 |602 |ABE |ATL |01021245|01/02 12:45|
|01020605|-4 |602 |ABE |ATL |01020605|01/02 06:05|
|01031245|-4 |602 |ABE |ATL |01031245|01/03 12:45|
|01030605|0 |602 |ABE |ATL |01030605|01/03 06:05|
|01041243|10 |602 |ABE |ATL |01041243|01/04 12:43|
|01040605|28 |602 |ABE |ATL |01040605|01/04 06:05|
|01051245|88 |602 |ABE |ATL |01051245|01/05 12:45|
|01050605|9 |602 |ABE |ATL |01050605|01/05 06:05|
+--------+-----+--------+------+-----------+--------+------------+
only showing top 10 rows
spark.sql("SELECT COUNT(*) FROM us_delay_flights_tbl").show()
+--------+
|count(1)|
+--------+
| 1391578|
+--------+
Query 1: 出発地と到着地との距離が1000より大きい全てのフライトを検索
spark.sql("SELECT distance, origin, destination FROM us_delay_flights_tbl WHERE distance > 1000 ORDER BY distance DESC").show(10, truncate=False)
+--------+------+-----------+
|distance|origin|destination|
+--------+------+-----------+
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
+--------+------+-----------+
only showing top 10 rows
Sparkデータフレームで行う同じクエリー
df.select("distance", "origin", "destination").where(col("distance") > 1000).orderBy(desc("distance")).show(10, truncate=False)
+--------+------+-----------+
|distance|origin|destination|
+--------+------+-----------+
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
|4330 |HNL |JFK |
+--------+------+-----------+
only showing top 10 rows
df.select("distance", "origin", "destination").where("distance > 1000").orderBy("distance", ascending=False).show(10)
+--------+------+-----------+
|distance|origin|destination|
+--------+------+-----------+
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
+--------+------+-----------+
only showing top 10 rows
df.select("distance", "origin", "destination").where("distance > 1000").orderBy(desc("distance")).show(10)
+--------+------+-----------+
|distance|origin|destination|
+--------+------+-----------+
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
| 4330| HNL| JFK|
+--------+------+-----------+
only showing top 10 rows
Query 2: サンフランシスコとシカゴの間で2時間より長い遅延のあったフライトを検索
spark.sql("""
SELECT date, delay, origin, destination
FROM us_delay_flights_tbl
WHERE delay > 120 AND ORIGIN = 'SFO' AND DESTINATION = 'ORD'
ORDER by delay DESC
""").show(10, truncate=False)
+--------+-----+------+-----------+
|date |delay|origin|destination|
+--------+-----+------+-----------+
|02190925|1638 |SFO |ORD |
|01031755|396 |SFO |ORD |
|01022330|326 |SFO |ORD |
|01051205|320 |SFO |ORD |
|01190925|297 |SFO |ORD |
|02171115|296 |SFO |ORD |
|01071040|279 |SFO |ORD |
|01051550|274 |SFO |ORD |
|03120730|266 |SFO |ORD |
|01261104|258 |SFO |ORD |
+--------+-----+------+-----------+
only showing top 10 rows
Query 3: より複雑なクエリー
SQLにおけるより複雑なクエリーとして、目的地に関係なく空港から出発する全てのUSフライトにラベル、high, medium, low, no delaysをつけましょう。
spark.sql("""SELECT delay, origin, destination,
CASE
WHEN delay > 360 THEN 'Very Long Delays'
WHEN delay > 120 AND delay < 360 THEN 'Long Delays '
WHEN delay > 60 AND delay < 120 THEN 'Short Delays'
WHEN delay > 0 and delay < 60 THEN 'Tolerable Delays'
WHEN delay = 0 THEN 'No Delays'
ELSE 'No Delays'
END AS Flight_Delays
FROM us_delay_flights_tbl
ORDER BY origin, delay DESC""").show(10, truncate=False)
+-----+------+-----------+-------------+
|delay|origin|destination|Flight_Delays|
+-----+------+-----------+-------------+
|333 |ABE |ATL |Long Delays |
|305 |ABE |ATL |Long Delays |
|275 |ABE |ATL |Long Delays |
|257 |ABE |ATL |Long Delays |
|247 |ABE |ATL |Long Delays |
|247 |ABE |DTW |Long Delays |
|219 |ABE |ORD |Long Delays |
|211 |ABE |ATL |Long Delays |
|197 |ABE |DTW |Long Delays |
|192 |ABE |ORD |Long Delays |
+-----+------+-----------+-------------+
only showing top 10 rows
df = spark.sql("""SELECT delay, origin, destination,
CASE
WHEN delay > 360 THEN 'Very Long Delays'
WHEN delay > 120 AND delay < 360 THEN 'Long Delays '
WHEN delay > 60 AND delay < 120 THEN 'Short Delays'
WHEN delay > 0 and delay < 60 THEN 'Tolerable Delays'
WHEN delay = 0 THEN 'No Delays'
ELSE 'No Delays'
END AS Flight_Delays
FROM us_delay_flights_tbl
ORDER BY origin, delay DESC""")
display(df)

その他のクエリー
df1 = spark.sql("SELECT date, delay, origin, destination FROM us_delay_flights_tbl WHERE origin = 'SFO'")
df1.createOrReplaceGlobalTempView("us_origin_airport_SFO_tmp_view")
%sql
SELECT * FROM global_temp.us_origin_airport_SFO_tmp_view

%sql
DROP VIEW IF EXISTS global_temp.us_origin_airport_JFK_tmp_view
df2 = spark.sql("SELECT date, delay, origin, destination from us_delay_flights_tbl WHERE origin = 'JFK'")
df2.createOrReplaceTempView("us_origin_airport_JFK_tmp_view")
%sql
SELECT * FROM us_origin_airport_JFK_tmp_view
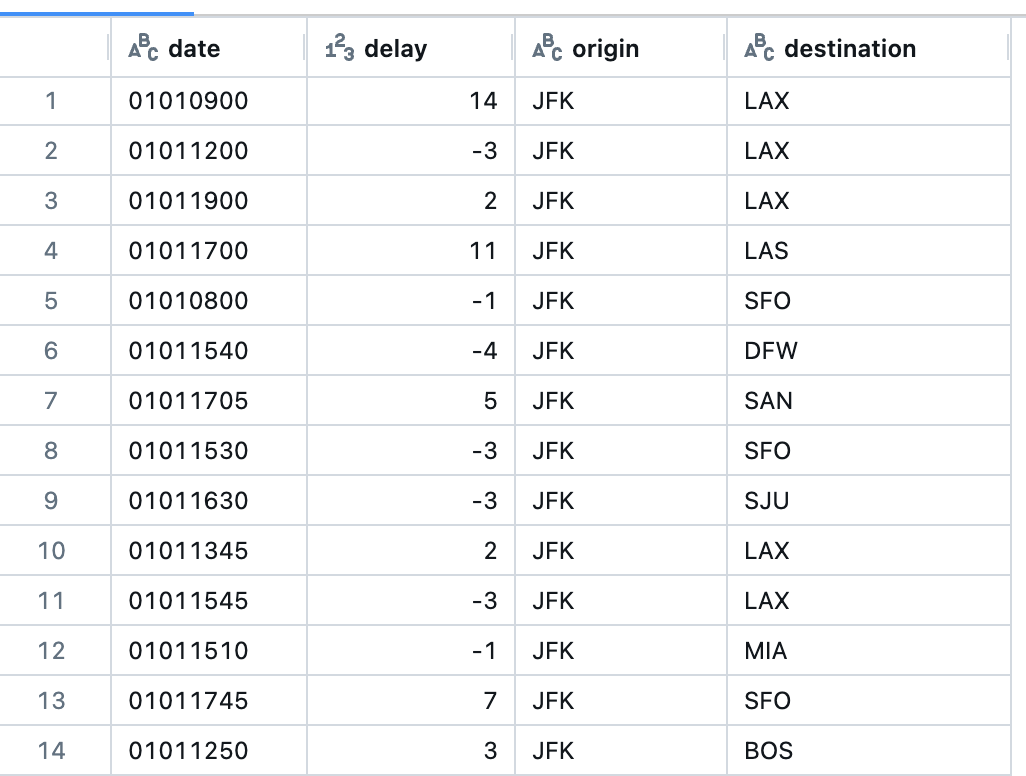
%sql
DROP VIEW IF EXISTS us_origin_airport_JFK_tmp_view
spark.catalog.listTables(dbName="global_temp")
[Table(name='us_origin_airport_sfo_tmp_view', catalog=None, namespace=['global_temp'], description=None, tableType='TEMPORARY', isTemporary=True),
Table(name='us_delay_flights_tbl', catalog=None, namespace=[], description=None, tableType='TEMPORARY', isTemporary=True)]