はじめに
本記事は、講義「生成AIによる情報システムへのインパクト」の事後課題です。
講義で体験した3つのツール(Genie、アシスタント、Apps)を使って、より実践的な課題に取り組みます。自分のペースで進めてください。
前提条件
- Databricksワークスペースにアクセスできること
- 事前課題・講義ハンズオンを完了していること
- Bakehouse Sales Starter Space が利用可能なこと
課題1:Genie によるビジネスシナリオ分析
前提条件
この実習は、Databricks Free Editionにデフォルトで用意されているGenieスペース 「Bakehouse Sales Starter Space」 を使用します。
データセット概要
グローバル展開するクッキーベーカリーチェーン「Bakehouse」のデータを使用します。
| テーブル | 説明 | 件数 |
|---|---|---|
| sales_transactions | 売上トランザクション | 3,333件 |
| sales_customers | 顧客マスタ | 300件 |
| sales_franchises | フランチャイズ店舗マスタ | 48件 |
| sales_suppliers | サプライヤーマスタ | 27件 |
| media_customer_reviews | 顧客レビュー | 204件 |
| media_gold_reviews_chunked | レビュー(チャンク化済) | 196件 |
商品ラインナップ: Outback Oatmeal, Austin Almond Biscotti, Orchard Oasis, Golden Gate Ginger, Tokyo Tidbits, Pearly Pies
展開国: Japan(20店舗), US(16店舗), Australia(6店舗), Canada, Netherlands, France, Germany, Italy, Sweden
実習0: Genieスペースの設定 (事前準備)
Genieを効果的に活用するには、適切なインストラクション(指示)の設定が重要です。この実習では、日本語での問い合わせに対応できるようGenieスペースを設定します。
0-1: 指示の設定手順
- Genieスペース右上の 「設定する」 をクリック
- 「指示」 タブを選択
- 「テキスト」 欄に以下を入力して保存
## 言語設定
- ユーザーからの質問には日本語で回答してください
- SQLのコメントも日本語で記述してください
## 国名の対応
ユーザーが以下の日本語で国名を指定した場合、対応する英語値(countryカラムの値)で検索してください:
- 日本 → Japan
- アメリカ、米国 → US
- オーストラリア、豪州 → Australia
- カナダ → Canada
- オランダ → Netherlands
- フランス → France
- ドイツ → Germany
- イタリア → Italy
- スウェーデン → Sweden
## 店舗サイズの対応
店舗サイズ(sizeカラム)は以下の5段階です:
- S: 小型店舗
- M: 中型店舗
- L: 大型店舗
- XL: 特大店舗
- XXL: 超大型店舗
## テーブル結合のヒント
- 店舗情報を含む売上分析: sales_transactions.franchiseID = sales_franchises.franchiseID
- 顧客情報を含む売上分析: sales_transactions.customerID = sales_customers.customerID
- サプライヤー情報を含む分析: sales_franchises.supplierID = sales_suppliers.supplierID
- レビューと店舗の紐付け: media_customer_reviews.franchiseID = sales_franchises.franchiseID
0-2: 設定の確認
設定を保存したら、以下の質問で動作を確認しましょう:
日本にある店舗数を教えてください
期待される結果: 20店舗
学習ポイント: Genieのインストラクションは、データとユーザーの間の「翻訳層」として機能します。データが英語で格納されていても、適切な設定により日本語での自然な問い合わせが可能になります。
シナリオ: 新任エリアマネージャーの業務分析
あなたは「Bakehouse」のアジア太平洋地域エリアマネージャーとして着任しました。2024年5月の売上データとレビューを分析し、経営会議での報告資料を作成する必要があります。
実習1: 基本的なデータ把握 (ウォームアップ)
まずはデータの全体像を把握しましょう。
問い合わせ 1-1: 単純な集計
全商品の売上総額を教えてください
問い合わせ 1-2: カウント
日本にある店舗は何店舗ありますか?
問い合わせ 1-3: 一覧取得
取り扱っている商品の一覧を見せてください
問い合わせ 1-4: 条件付き検索
東京にある店舗の情報を教えてください
実習2: 売上分析 (基礎)
問い合わせ 2-1: 商品別売上
商品別の売上金額を多い順に教えてください
問い合わせ 2-2: 国別売上
国別の売上金額と取引件数を比較したいです
問い合わせ 2-3: 支払方法分析
支払方法ごとの利用割合はどうなっていますか?
問い合わせ 2-4: 日別推移
日別の売上推移をグラフで見せてください
実習3: 店舗パフォーマンス分析 (中級)
問い合わせ 3-1: 店舗別売上ランキング
売上金額トップ10の店舗を店舗名と一緒に表示してください
問い合わせ 3-2: 店舗規模と売上の関係
店舗サイズ(S/M/L/XL/XXL)別の平均売上を比較したいです
問い合わせ 3-3: 地域特性の把握
日本の店舗で最も売れている商品は何ですか?
問い合わせ 3-4: 低パフォーマンス店舗の特定
売上が平均以下の店舗はどこですか?店舗名と売上金額を教えてください
実習4: 顧客分析 (中級)
問い合わせ 4-1: 顧客属性
顧客の男女比を教えてください
問い合わせ 4-2: 顧客単価
1回あたりの平均購入金額はいくらですか?
問い合わせ 4-3: リピーター分析
複数回購入している顧客は何人いますか?
問い合わせ 4-4: 優良顧客の特定
購入金額が最も多い顧客トップ5の名前と合計購入金額を教えてください
実習5: 複合分析 (上級)
問い合わせ 5-1: サプライヤーと売上の関係
サプライヤーごとに、そのサプライヤーと取引のある店舗の総売上を集計してください
問い合わせ 5-2: 時間帯別分析
時間帯別(午前/午後/夕方/夜)の売上傾向を教えてください
問い合わせ 5-3: クロス分析
店舗の国別・商品別の売上マトリクスを作成してください
問い合わせ 5-4: 曜日別パターン
曜日別の売上パターンに違いはありますか?
実習6: 自然言語での複雑な質問 (応用)
問い合わせ 6-1: ビジネス課題の特定
アジア太平洋地域(日本とオーストラリア)で、改善が必要な店舗を特定したいです。
売上が地域平均の80%未満の店舗をリストアップしてください。
問い合わせ 6-2: 商品戦略の検討
Tokyo Tidbitsは東京の店舗でどのくらい売れていますか?
他の地域と比較して特別な傾向はありますか?
問い合わせ 6-3: 経営指標の算出
店舗ごとの1日あたり平均売上と、全店舗平均との比較を見せてください
問い合わせ 6-4: アドホックな質問
XLサイズ以上の大型店舗で、Austin Almond Biscottiの売上が
全商品売上の20%以上を占めている店舗はありますか?
実習7: レビュー分析への橋渡し (発展)
問い合わせ 7-1: レビュー数の確認
店舗ごとのレビュー数を教えてください
問い合わせ 7-2: 売上とレビューの関係
レビュー数が多い店舗トップ5と、その店舗の売上金額を表示してください
問い合わせ 7-3: 特定店舗のレビュー
売上トップの店舗に寄せられたレビューの内容を見せてください
実習のポイント
Genieの特徴を活かす質問のコツ
- 曖昧な表現もOK: 「一番売れている」「最近の」など自然な言葉で質問
- 段階的に詳細化: 概要→詳細の順で質問を重ねる
- 比較を求める: 「〜と比較して」で相対的な分析が可能
- 可視化の依頼: 「グラフで」「チャートで」と明示すると可視化される
インストラクション設定のベストプラクティス
| 設定項目 | 目的 | 例 |
|---|---|---|
| 用語マッピング | データ値と自然言語の対応付け | 日本 → Japan |
| 結合ヒント | テーブル間のリレーション明示 | franchiseIDで結合 |
| ビジネスルール | 業務固有の計算ロジック | 「大型店舗」= XL以上 |
| 出力形式 | 回答の言語や形式の指定 | 日本語で回答 |
よくあるつまずきと対処法
| 問題 | 対処法 |
|---|---|
| 意図と異なる結果 | 質問を言い換えて再試行 |
| テーブル間の結合ミス | インストラクションに結合条件を追加 |
| 集計単位の誤解 | 「〜ごとに」「〜別に」を明確に |
| データ値の不一致 | インストラクションにマッピングを追加 |
発展課題
課題A: インストラクションの拡張
以下の要件に対応するインストラクションを追加してみましょう:
- 「売れ筋商品」と言われたら売上トップ3を返す
- 「最近」と言われたら直近7日間のデータを対象とする
- 「優良顧客」の定義を設定する(例: 購入回数5回以上)
課題B: 自然言語クエリの設計
以下の分析を行うための自然言語クエリを考えてみましょう:
- 週末(土日)と平日で売上傾向に違いはあるか?
- 新規顧客獲得に成功している店舗を特定するには?
- 商品ごとの平均購入数量に地域差はあるか?
✅ 完了チェック
- 売上トレンドを把握できた
- 異常値とその原因を特定できた
- 好調/不調な店舗・商品を分析できた
- 経営層に報告できるレベルのサマリーを作成できた
💡 ヒント
- 一度に完璧な質問をしなくてOK。会話しながら絞り込む
- 「なぜ?」「もう少し詳しく」と深掘りする
- 結果が期待と違ったら、条件を変えて再質問
課題2:Genie Codeによる分析ワークフロー構築
🎯 ゴール
Genie CodeのAgent Modeを使って、データ取得から可視化・解釈までの一連のワークフローを構築する。
シナリオ
Irisデータセット(アヤメの花の計測データ)を使って、
機械学習の基本的な分析フローを体験します。
- データの読み込みと概要把握
- 探索的データ分析(EDA)
- 簡単な機械学習モデルの構築
- 結果のレポート化
手順
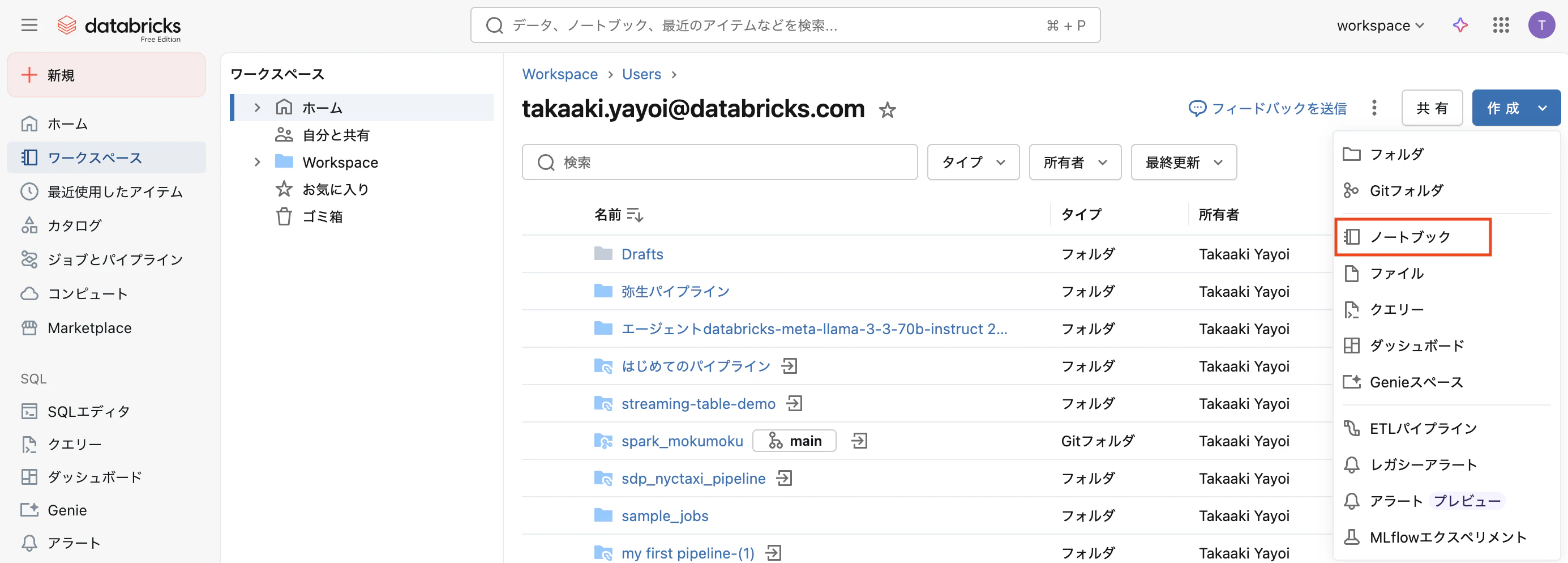
Step 1:ノートブックを作成する
- ワークスペースで「作成」→「ノートブック」を選択
- 名前を「iris_analysis_handson」などに設定
- クラスターを接続
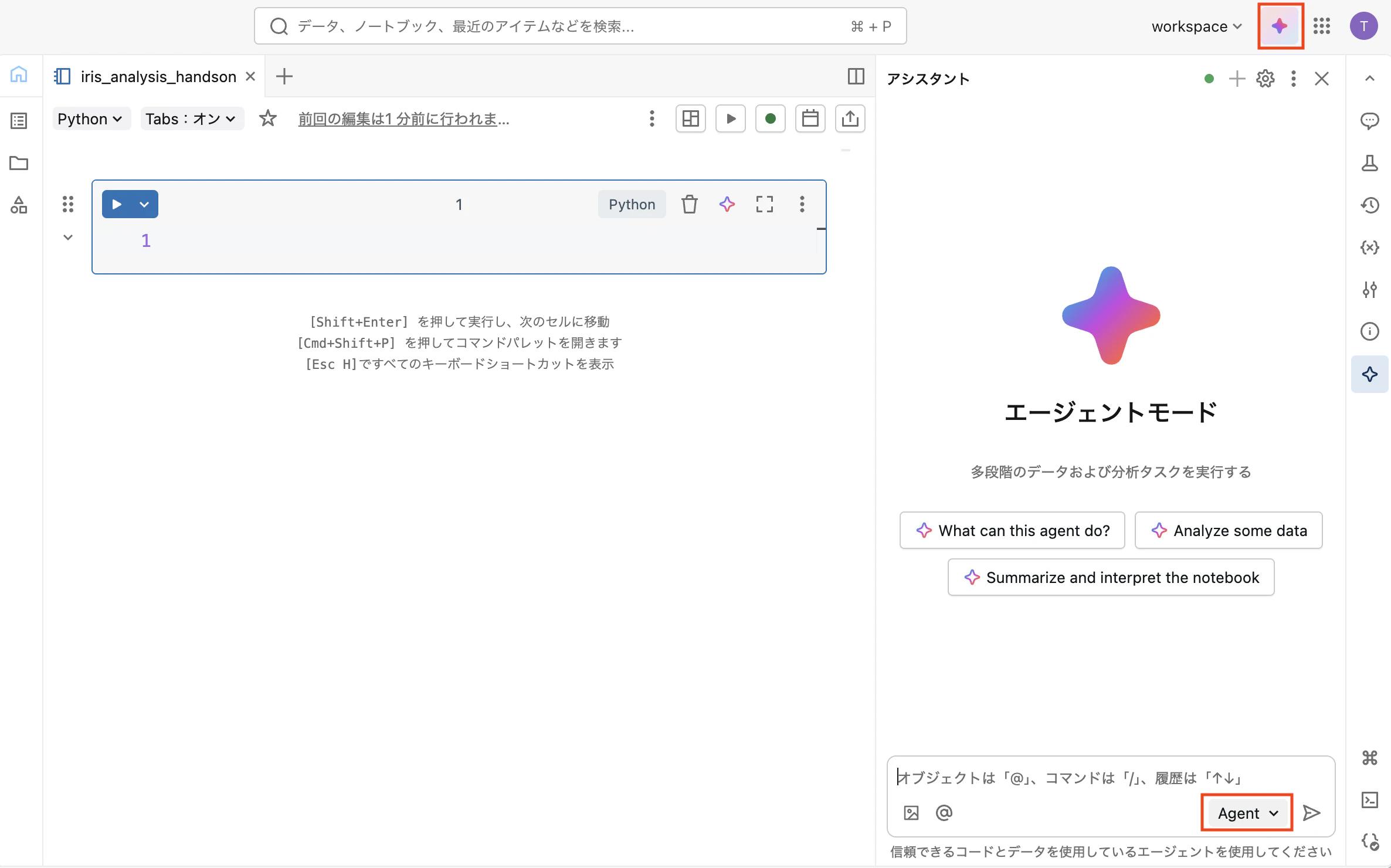
Step 2:エージェントモードを有効にする
- 画面右側のGenie Codeパネルを開く
- パネル右下で「Agent」を選択
Step 3:インストラクションの設定
アシスタントの挙動を制御するために、ここでもインストラクション(指示)を設定できます。

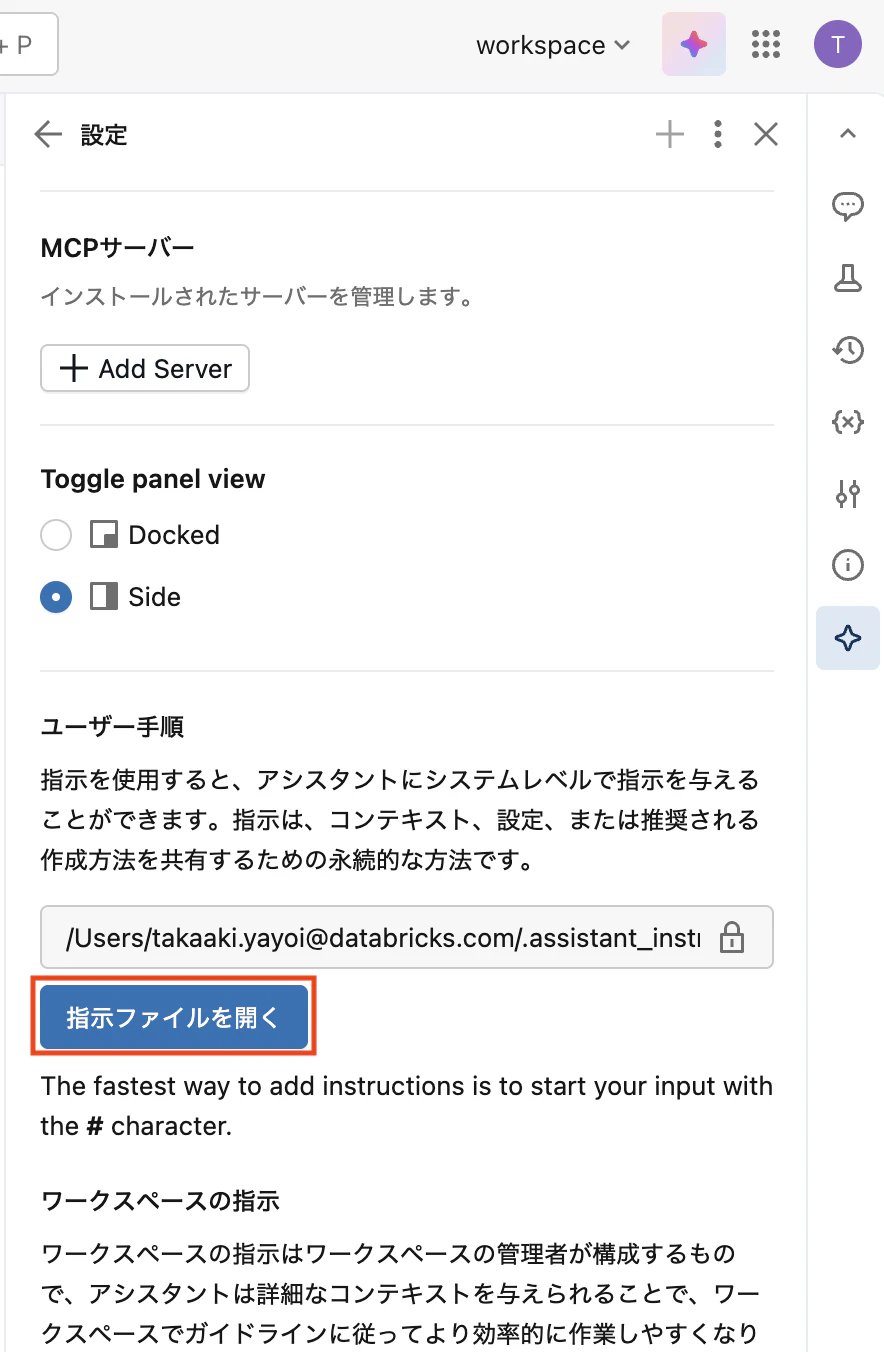
表示される.assistant_instructions.mdに以下の内容を記述します。
- あなたはデータ分析の専門家です
- 日本語で会話します
- 可視化にはplotlyを使います
Step 4:データ読み込みと概要把握
Genie Codeに以下のように依頼します。
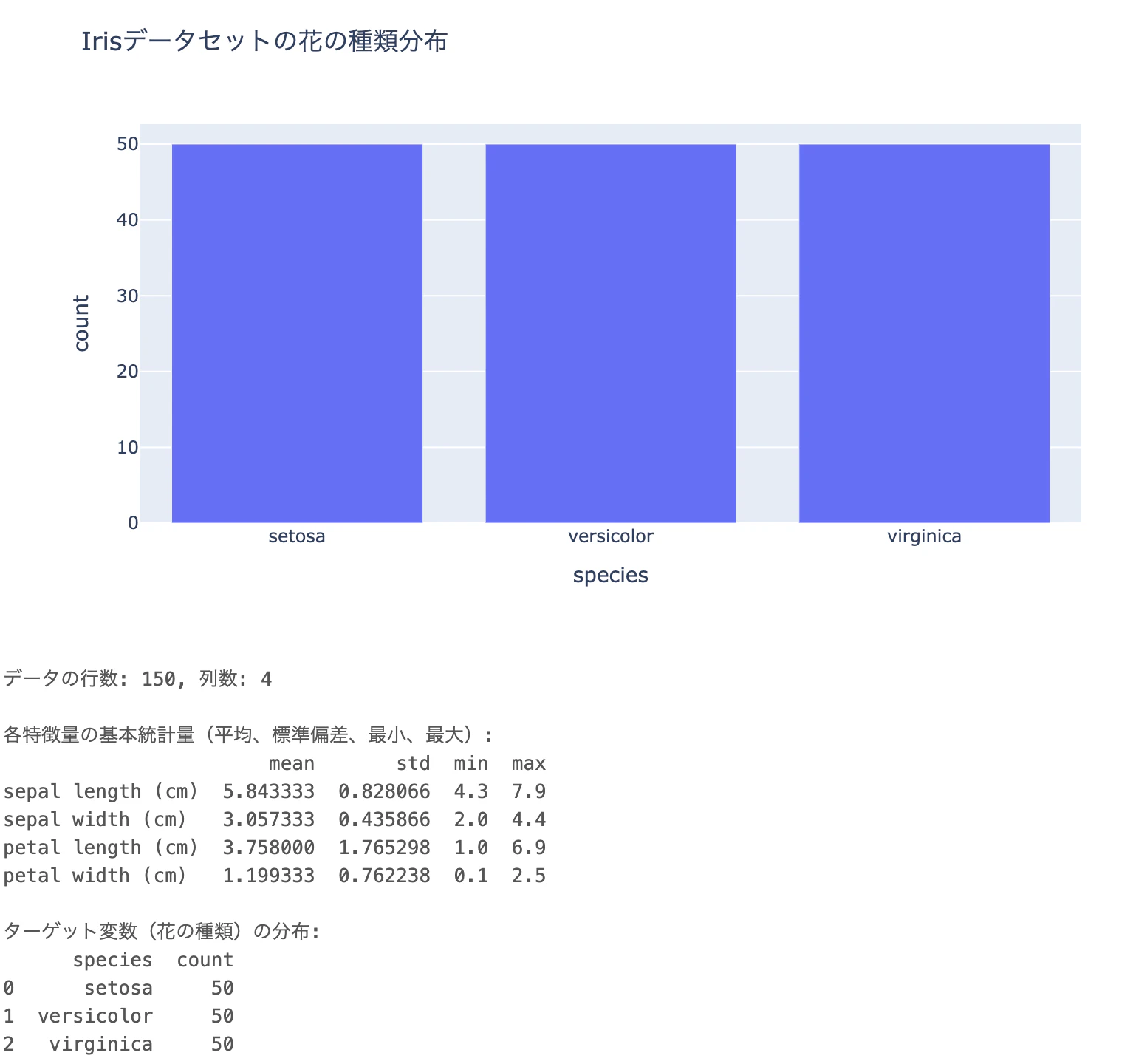
scikit-learnのirisデータセットを読み込んで、以下を教えてください:
・データの行数・列数
・各特徴量の基本統計量(平均、標準偏差、最小、最大)
・ターゲット変数(花の種類)の分布
Genie Codeがコードを生成し、自動で実行します。結果を確認しましょう。
Step 5:探索的データ分析(EDA)
続けて、可視化を依頼します。
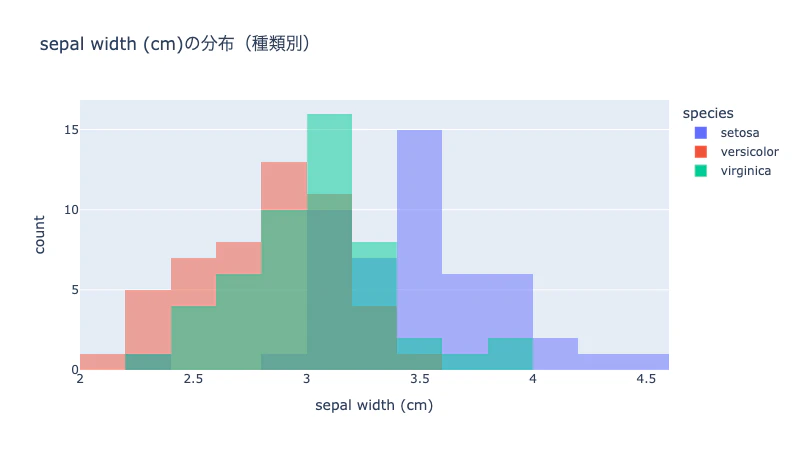
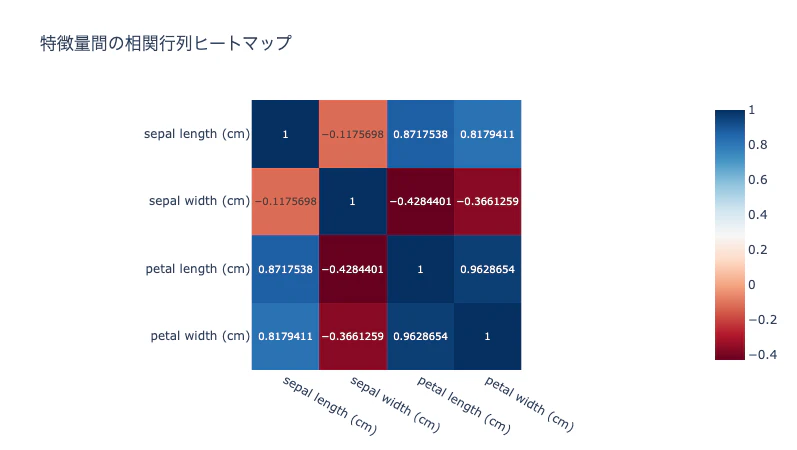
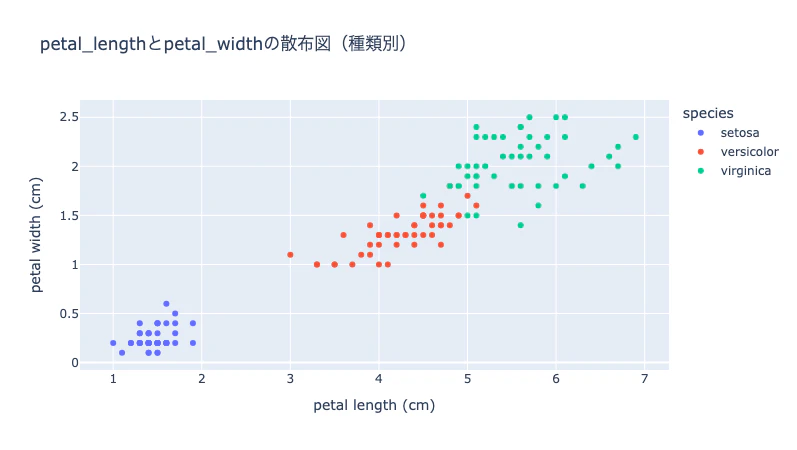
以下の可視化を作成してください:
1. 各特徴量の分布を種類別にヒストグラムで表示
2. 特徴量間の相関行列をヒートマップで表示
3. petal_lengthとpetal_widthの散布図を種類別に色分けして表示
生成されたグラフを確認し、気づいたことがあれば深掘りします。
この散布図を見ると、setosaは他の2種類と明確に分離できそうですね。
sepal_lengthとsepal_widthでも同じことが言えるか確認してください。
Step 6:機械学習モデルの構築
簡単な分類モデルを作成します。
以下の手順で分類モデルを構築してください:
1. データを訓練用(80%)とテスト用(20%)に分割
2. ランダムフォレスト分類器でモデルを訓練
3. テストデータで精度を評価
4. 混同行列を可視化
5. 特徴量の重要度をグラフで表示
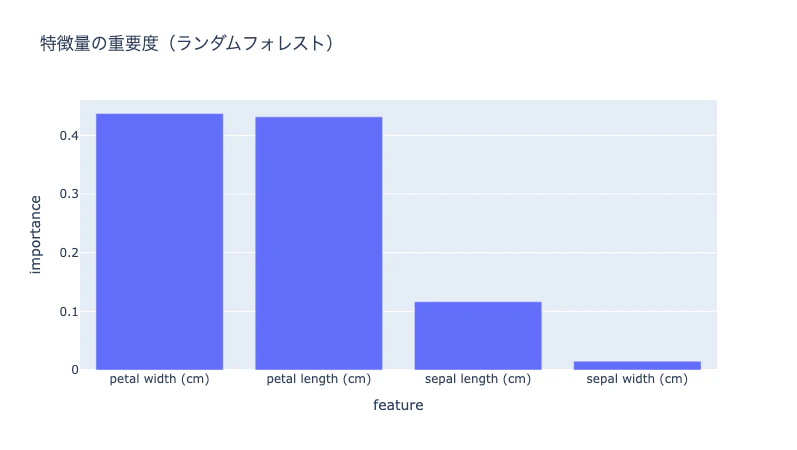
Step 7:結果のレポート化
分析結果をまとめてもらいます。
ここまでの分析結果を、以下の構成でMarkdown形式のレポートにまとめてください:
1. データ概要
2. 探索的分析の主な発見
3. モデルの性能
4. 結論と考察
Step 7:(発展)モデルの改善
余裕があれば、モデルの改善にも挑戦してみましょう。
精度をさらに上げるために、以下を試してください:
・特徴量のスケーリング(StandardScaler)
・他のアルゴリズム(SVM、勾配ブースティング)との比較
・クロスバリデーションによる評価
✅ 完了チェック
- データの読み込みと概要把握ができた
- 複数の可視化を作成できた
- 機械学習モデルを構築し、精度を評価できた
- 分析結果をレポートにまとめられた
💡 ヒント
- Agent Modeでは、ゴールを具体的に伝えると良い結果が得られる
- エラーが出たら「修正して」と伝えるだけでOK
- グラフの見た目を調整したいときは「色を変えて」「サイズを大きくして」など追加指示
課題3:Databricks Apps によるダッシュボード作成
🎯 ゴール
アシスタントを活用しながら、Streamlitでインタラクティブなダッシュボードアプリを作成し、Databricks Appsとしてデプロイする。
シナリオ
課題2で行ったIrisデータセットの分析結果を、
誰でも触れるダッシュボードアプリとして公開します。
- データの概要表示
- インタラクティブな可視化
- 簡単な予測機能
手順
Step 1:Appsを作成する
Free Editionの場合、作成できるアプリの最大数は1です。前に作成したものがある場合には削除してください。
- 左メニューから「コンピュート」→「アプリ」を選択
- 「アプリを作成」をクリック
- 「Streamlit Hello World」を選択
- アプリ名を「iris-dashboard」に設定
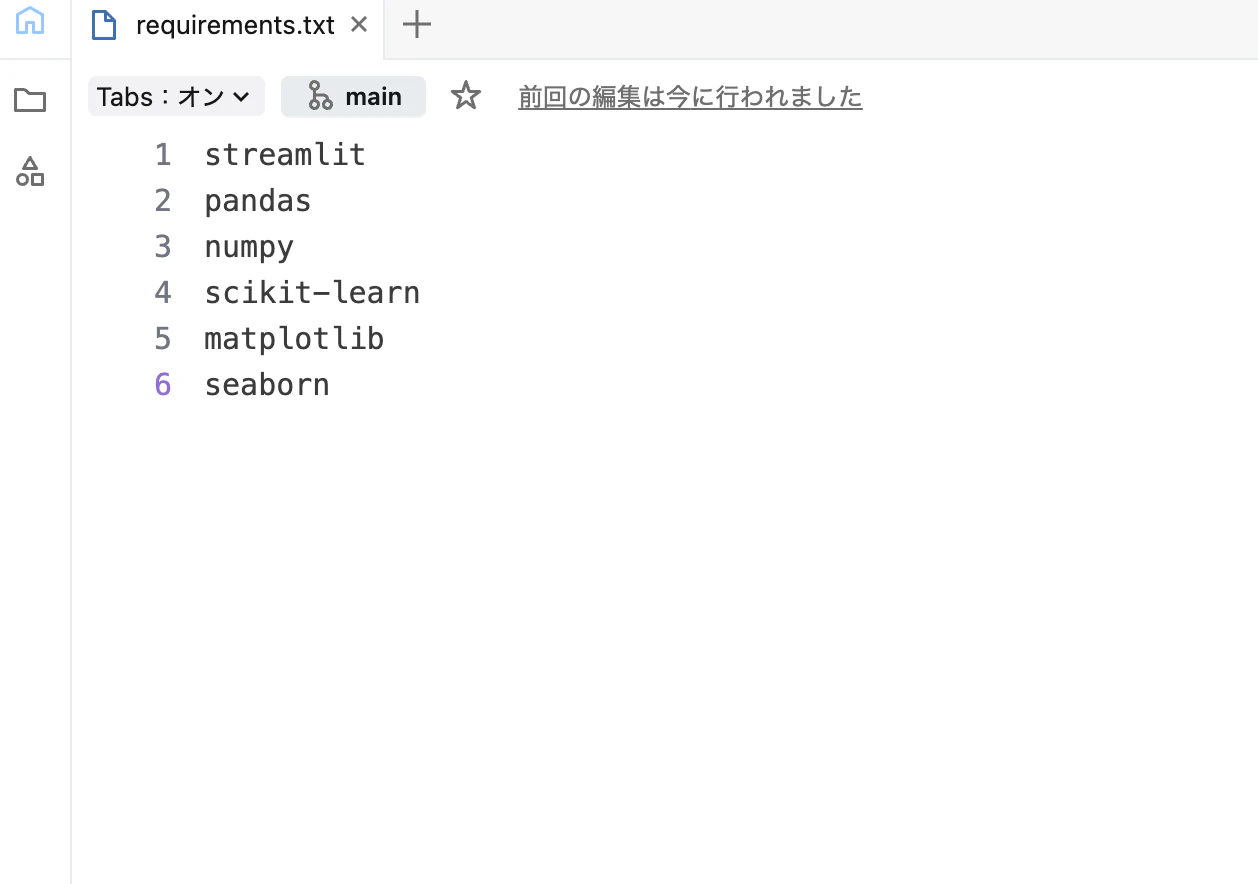
Step 2:requirements.txt を設定する
Appsでscikit-learnを使うには、requirements.txtに依存ライブラリを追加する必要があります。
-
アプリの画面でデプロイメントソースのリンクをクリック
-
ファイル一覧から
requirements.txtを開く -
以下の内容に更新する
streamlit
pandas
numpy
scikit-learn
matplotlib
seaborn
Step 3:アシスタントでコードを生成する
- エディタ左側のフォルダアイコンをクリックしてファイル一覧を表示
- タブに同期ボタンを押して、同じ場所にあるファイル一覧を表示
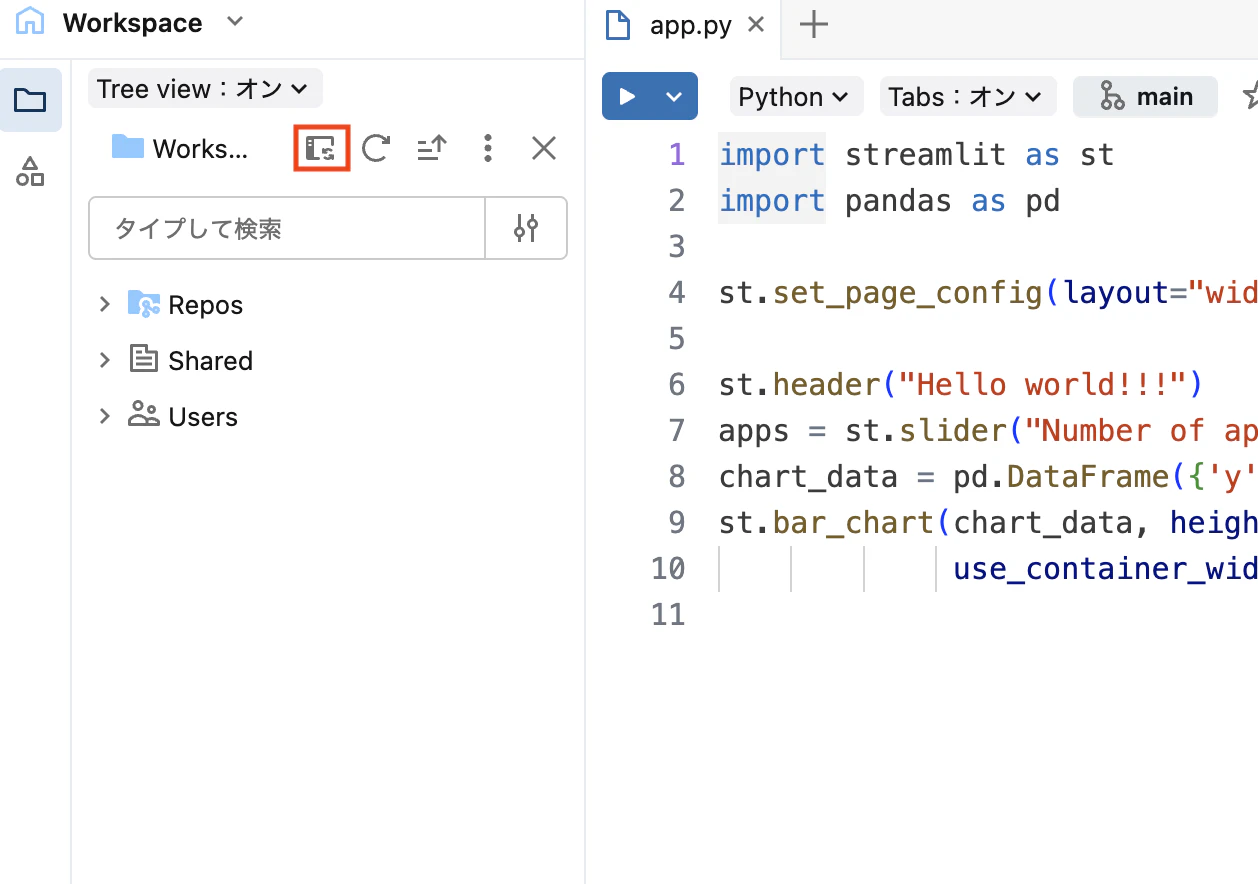

-
app.pyを選択 - アプリのエディタ画面が開いたら、右上の編集をクリックしてアシスタントを表示

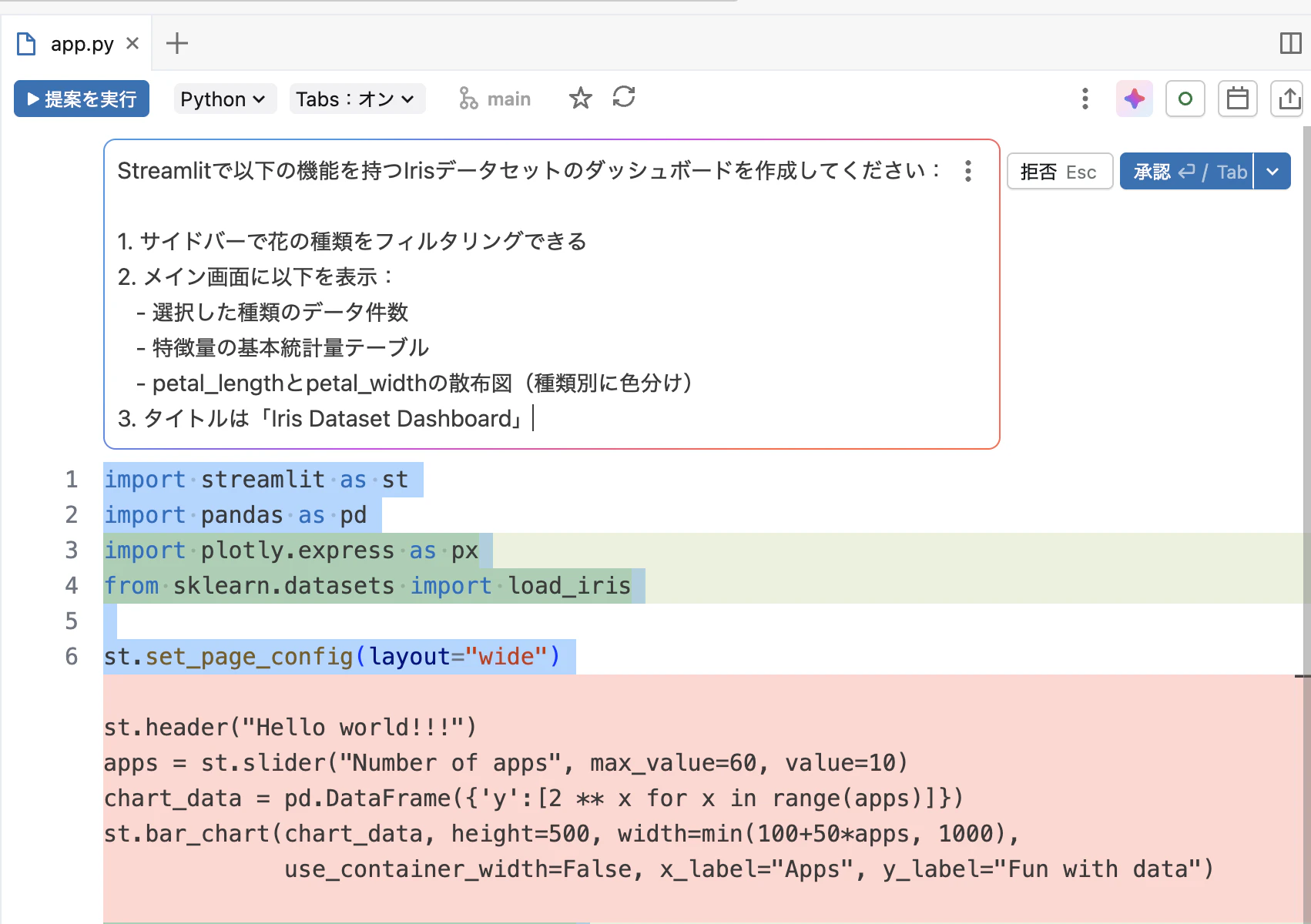
- アシスタントに以下を依頼します。
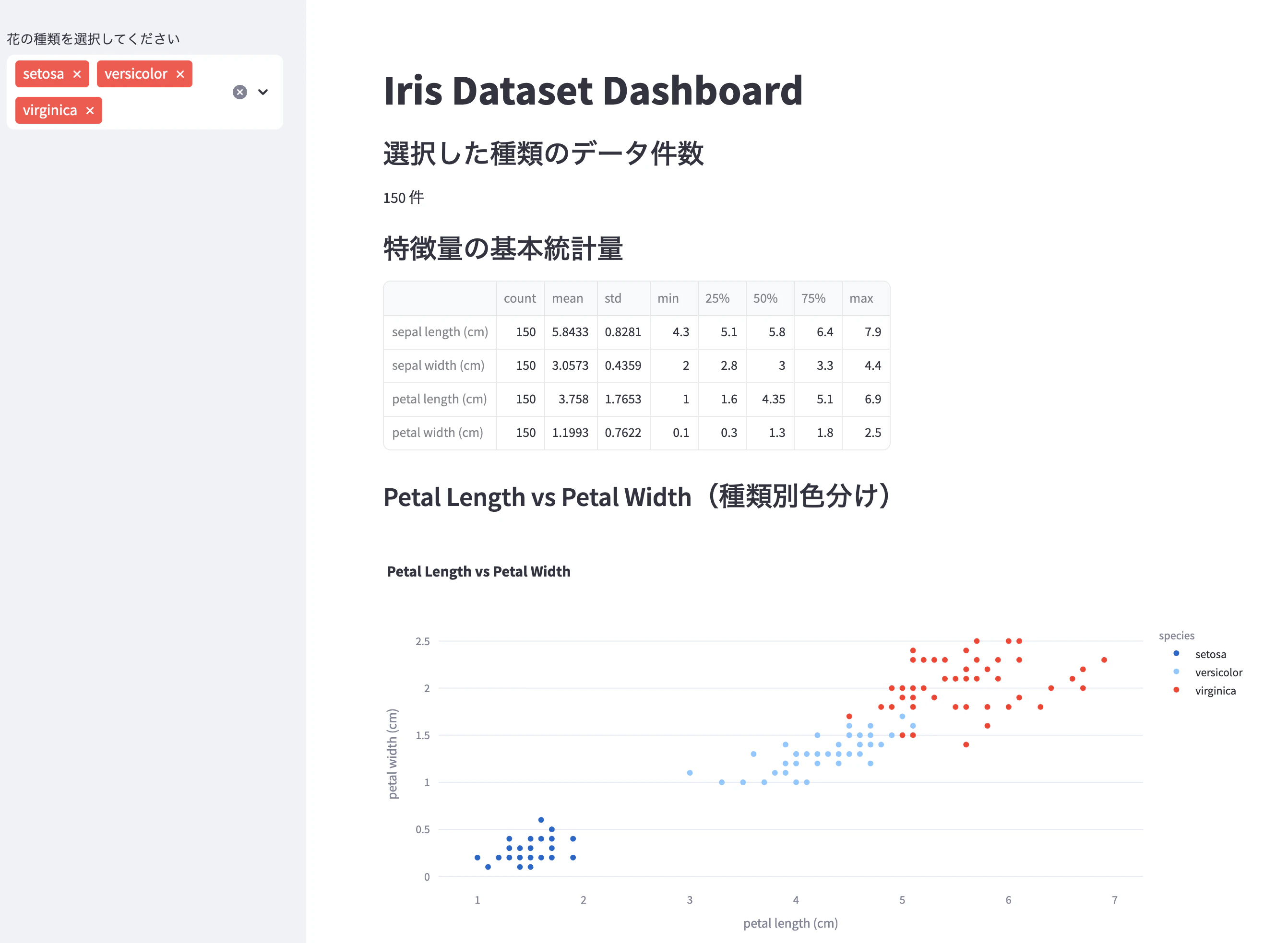
Streamlitで以下の機能を持つIrisデータセットのダッシュボードを作成してください:
1. サイドバーで花の種類をフィルタリングできる
2. メイン画面に以下を表示:
- 選択した種類のデータ件数
- 特徴量の基本統計量テーブル
- petal_lengthとpetal_widthの散布図(種類別に色分け)
3. タイトルは「Iris Dataset Dashboard」
承認を押して確定します。
Step 4:アプリをプレビューする
アプリの画面に戻ります。
- 右上の「デプロイ」ボタンをクリック
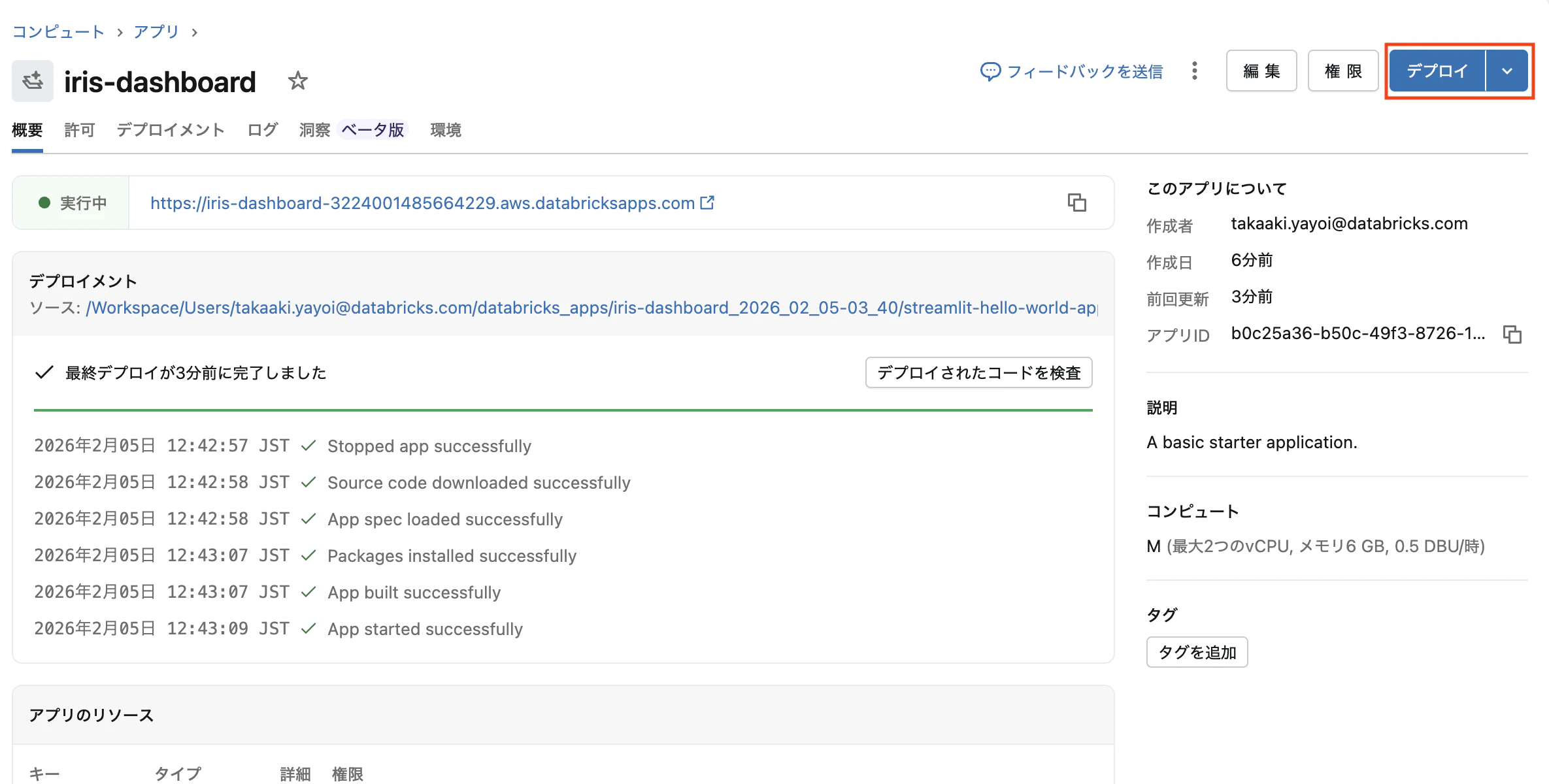
- 実行中の右のリンクをクリックしてアプリの動作を確認
- サイドバーのフィルタが機能するか確認
Step 5:機能を追加する
アシスタントに追加機能を依頼します。
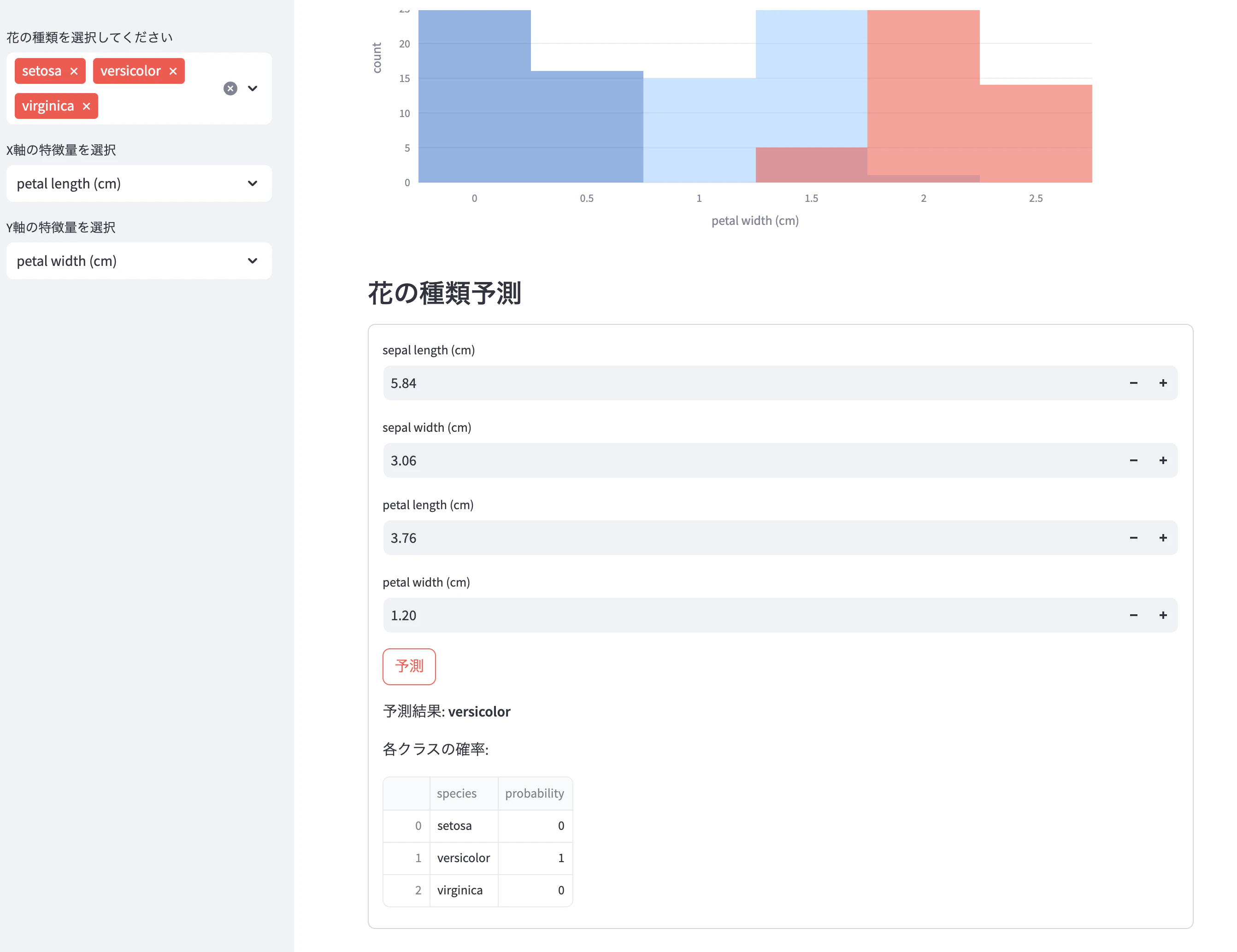
以下の機能を追加してください:
1. 特徴量を選択できるドロップダウン(X軸とY軸を選べる)
2. 選択した特徴量で散布図を更新
3. 各特徴量のヒストグラムも表示
生成されたコードでapp.pyを更新し、再度プレビューで確認します。
Step 6:予測機能を追加する
さらに発展させて、予測機能を追加します。
以下の予測機能を追加してください:
1. ユーザーが4つの特徴量を数値入力できるフォーム
2. 「予測」ボタンを押すと、入力値に基づいて花の種類を予測
3. 予測結果と確率を表示
4. モデルはランダムフォレストを使用
Step 7:見た目を整える
最後に、見た目を調整します。
以下の改善をしてください:
1. ページ全体のレイアウトを「wide」モードに
2. 各セクションに見出しと説明文を追加
3. 散布図のサイズを大きく
4. 予測結果を目立つように装飾(成功時は緑、など)
Step 8:(発展)機能拡張
余裕があれば、さらに機能を追加してみましょう。
以下の機能を追加してください:
1. データをCSVでダウンロードできるボタン
2. 複数のモデル(SVM、決定木)を選択して比較できる機能
3. モデルの精度をリアルタイムで表示
✅ 完了チェック
- Streamlitアプリを作成できた
- インタラクティブなフィルタリングが動作する
- 予測機能が動作する
- Databricks Appsとしてデプロイできた
💡 ヒント
- エラーが出たら、エラーメッセージをそのままアシスタントに伝える
- 「動かない」より「○○のエラーが出る」と具体的に伝える
- 一度に全部作ろうとせず、少しずつ機能を追加していく
発展課題(オプション)
時間に余裕がある方は、以下の発展課題にも挑戦してみてください。
発展1:Genieの高度な活用
- Research Agent(有効な場合)を使って「なぜ売上が変動したか」を深掘り分析
- 複数のGenieスペースを組み合わせた横断分析
発展2:Genie Codeでのパイプライン構築
- Delta Lakeへのデータ保存
- 定期実行ジョブの設定
- MLflowでのモデル管理
発展3:Appsの本格開発
- 認証機能の追加
- 複数ページ構成
- 外部APIとの連携
トラブルシューティング
Genieが期待した結果を返さない
- 質問を具体的にしてみる(期間、対象を明示)
- 別の言い回しで試す
- 一度に多くを聞かず、段階的に質問
Genie Codeのコードがエラーになる
- 「このエラーを修正して」と伝える
- 必要なライブラリがインストールされているか確認
- クラスターが起動しているか確認
Appsがデプロイできない
-
requirements.txtに必要なライブラリが記載されているか確認 - コードにシンタックスエラーがないか確認
- クラスターのリソースが十分か確認
おわりに
お疲れさまでした!
この課題を通じて、以下のスキルが身についたはずです:
- Genie:自然言語でのデータ分析、ビジネスインサイトの抽出
- Genie Code:Agent Modeを活用した複合タスクの自動化
- Apps:AIを活用したアプリケーション開発とデプロイ
これらのスキルは、日々の業務でもすぐに活用できます。
「これ、Genieに聞けるかも」「Genie Codeに任せられるかも」
そんな視点で、ぜひ自分の業務を見直してみてください。