こちらの続きです。ノートブック02-llm-evaluationをウォークスルーします。
ファインチューンLLMの評価
前のノートブックでは、DatabricksがどのようにLLMのファインチューニングをシンプルにするのかを見てきました。
ファインチューニングはシンプルなAPI呼び出しですが、あなたの新たなLLMがどの様に動作するのかを評価しなくてはなりません。これは、ファインチューニングが適切な方法で役に立っているのかどうかを評価するためには重要なものであり、あなたのファインチューニングデータセットをどの様に改善できるのかを理解し、潜在的なギャップを検知する鍵となります。
DatabricksではMLflowと新たなLLMの機能を活用します。ここでは、プレーン/ベースの基盤モデルとファインチューニングしたモデルを様々なメトリクスで比較します。
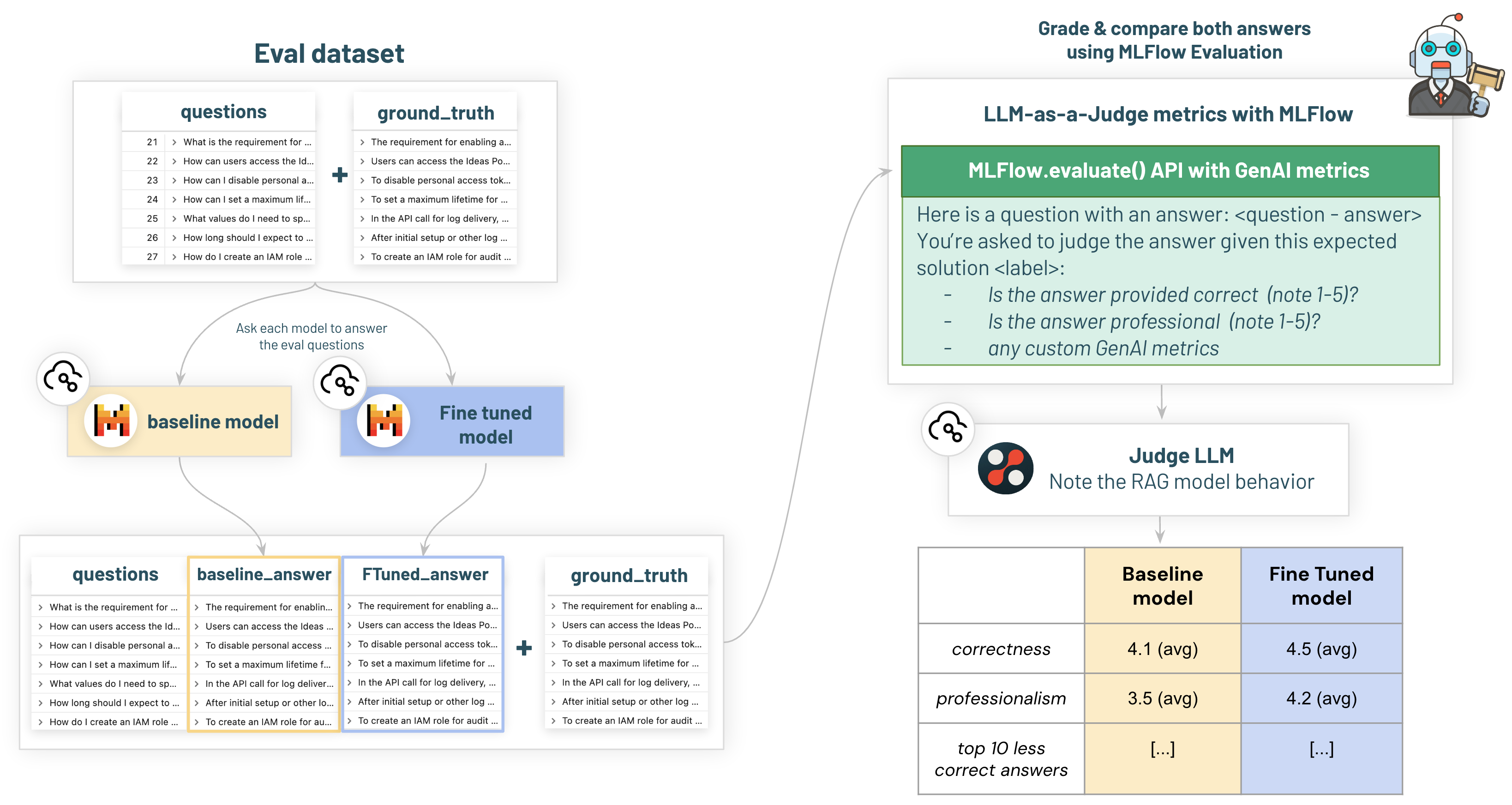
このためには、評価データセットを作成し、ベンチマークしたい2つのモデルを呼び出すRAGアプリケーションが必要となります: ベースライン vs ファインチューニングモデルです。これによって、ファインチューニングが我々のモデルのパフォーマンスをどれだけ改善したのかを確認することができます!
# ここでは順番が重要です。MLflowを最後にインストールします。
%pip install textstat==0.7.3 databricks-genai==1.0.2 openai==1.30.1 langchain==0.2.0 langchain-community==0.2.0 langchain_text_splitters==0.2.0 markdown==3.6
%pip install databricks-sdk==0.27.1
%pip install "transformers==4.37.1" "mlflow==2.12.2"
dbutils.library.restartPython()
%run ./_resources/00-setup
MLFlowによるモデルの評価
このサンプルでは、カスタムシステムプロンプトとMLflow Ecaluate、LangChainを組み合わせてどの様に活用するのかを説明します。
1) ベースラインの確立
まず、標準的なLLMを用いてベースラインのパフォーマンスを確立します。ファインチューニングしたもモデルが基盤モデルとして利用できる場合、Databricksで提供されるAPIを用いて直接利用することができます。
ここでは、mistralかllama2-7Bをファインチューンしているので、このモデルを用いてサービングエンドポイントをデプロイし、コストを削減するためにゼロへのスケールを行う様にします。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, AutoCaptureConfigInput
serving_endpoint_baseline_name = "taka_dbdemos_llm_not_fine_tuned"
w = WorkspaceClient()
endpoint_config = EndpointCoreConfigInput(
name=serving_endpoint_baseline_name,
served_entities=[
ServedEntityInput(
entity_name="system.ai.mistral_7b_instruct_v0_2", # 適切な評価にするために、ファインチューニングに用いたのと同じモデルを使う様にしてください!
entity_version=1,
min_provisioned_throughput=0, # エンドポイントがスケールダウンする最小秒間トークン数
max_provisioned_throughput=100, # エンドポイントがスケールアップする最大秒間トークン数
scale_to_zero_enabled=True
)
]
)
existing_endpoint = next(
(e for e in w.serving_endpoints.list() if e.name == serving_endpoint_baseline_name), None
)
if existing_endpoint == None:
print(f"Creating the endpoint {serving_endpoint_baseline_name}, this will take a few minutes to package and deploy the LLM...")
w.serving_endpoints.create_and_wait(name=serving_endpoint_baseline_name, config=endpoint_config)
else:
print(f"endpoint {serving_endpoint_baseline_name} already exist")
2つのエンドポイントの違いを確認するためにシンプルで手動のクエリーを試します
import mlflow
from mlflow import deployments
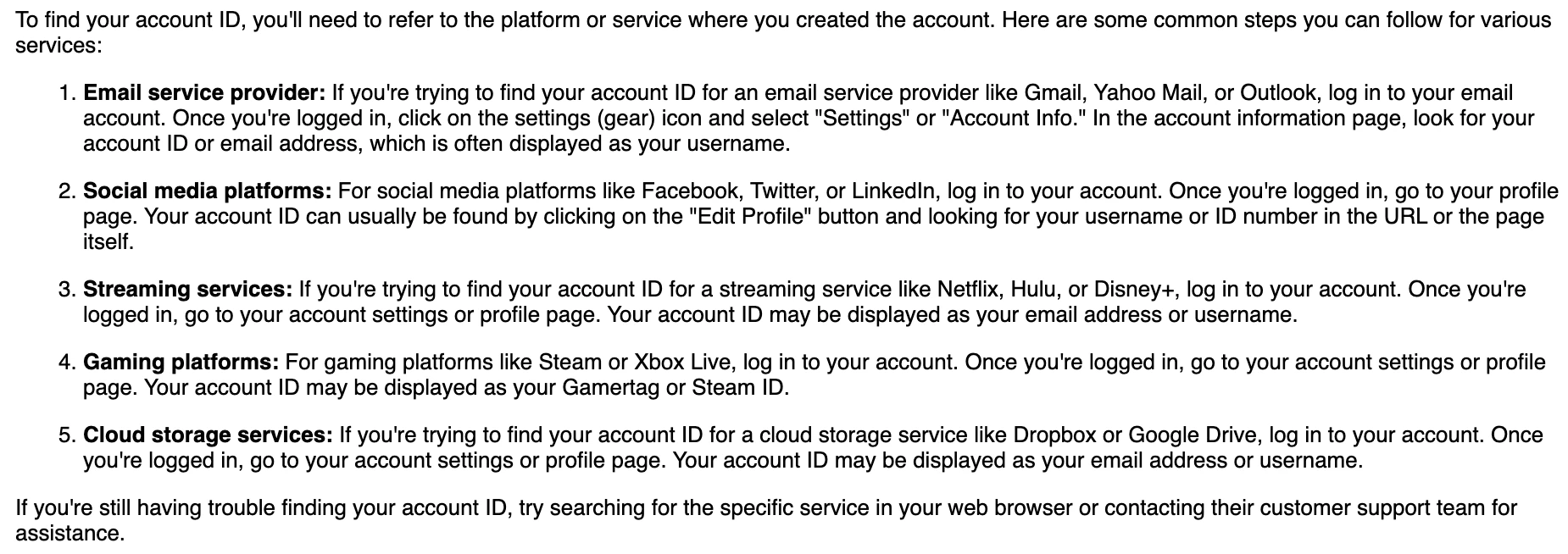
question = "How can I find my account ID?"
inputs = {"messages": [{"role": "user", "content": question}], "max_tokens": 400}
client = mlflow.deployments.get_deploy_client("databricks")
not_fine_tuned_answer = client.predict(endpoint=serving_endpoint_baseline_name, inputs=inputs)
display_answer(not_fine_tuned_answer)

serving_endpoint_ft_name = "taka_dbdemos_llm_fine_tuned"
fine_tuned_answer = client.predict(endpoint=serving_endpoint_ft_name, inputs={"messages": [{"role": "user", "content": question}]})
display_answer(fine_tuned_answer)
2) オフラインのモデル評価
モデルがどの様な性能であるのかを確認するために、審判として外部のLLMとmlflow.evaluateを活用します。
考え方は、LLMに我々の質問 + コンテキストを送信し、(通常はより強力な)外部モデルを活用して得られる期待される回答と、モデルの回答を比較するというものです。我々のケースでは、正解データと比較したMistral LLMを判定するためにビルトインのサーバレスDBRXモデルエンドポイントを活用します。
評価データセットの構築
eval_dataset = spark.table("chat_completion_evaluation_dataset").withColumnRenamed("content", "context").toPandas()
display(eval_dataset)

from langchain_community.chat_models.databricks import ChatDatabricks
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts.chat import ChatPromptTemplate
import pandas as pd
base_model_name = "mistralai/Mistral-7B-Instruct-v0.2"
# ----------------------------------------------------------------------------------------------------------------------------------------- #
# -- デモのための基本的なチェーン。本来はあなたの完全なRAGチェーンであるべきです (ご自身の最終的なチェーンでLLMを評価したいと思うことでしょう) --------------------------- #
# ----------------------------------------------------------------------------------------------------------------------------------------- #
system_prompt = """You are a highly knowledgeable and professional Databricks Support Agent. Your goal is to assist users with their questions and issues related to Databricks. Answer questions as precisely and accurately as possible, providing clear and concise information. If you do not know the answer, respond with "I don't know." Be polite and professional in your responses. Provide accurate and detailed information related to Databricks. If the question is unclear, ask for clarification.\n"""
user_input = "Here is a documentation page that could be relevant: {context}. Based on this, answer the following question: {question}"
def build_chain(llm):
# mistralはsystemロールをサポートしていません
if "mistral" in base_model_name:
messages = [("user", f"{system_prompt} \n{user_input}")]
else:
messages = [("system", system_prompt),
("user", user_input)]
return ChatPromptTemplate.from_messages(messages) | llm | StrOutputParser()
# --------------------------------------------------------------------------------------------------- #
def eval_llm(llm_endoint_name, eval_dataset, llm_judge = "databricks-dbrx-instruct", run_name="dbdemos_fine_tuning_rag"):
# チェーンの構築。これはあなたのインデックスに問い合わせを行う実際のRAGチェーンであるべきです。
llm = ChatDatabricks(endpoint=llm_endoint_name, temperature=0.1)
chain = build_chain(llm)
# エントリーごとにエンドポイントを呼び出し
eval_dataset["prediction"] = chain.with_retry(stop_after_attempt=2) \
.batch(eval_dataset[["context", "question"]].to_dict(orient="records"), config={"max_concurrency": 4})
# モデルを評価するためにMLflowランをスタート
with mlflow.start_run(run_name="eval_"+llm_endoint_name) as run:
eval_df = eval_dataset.reset_index(drop=True).rename(columns={"question": "inputs"})
results = mlflow.evaluate(
data=eval_df,
targets="answer",
predictions="prediction",
extra_metrics=[
mlflow.metrics.genai.answer_similarity(model=f"endpoints:/{llm_judge}"),
mlflow.metrics.genai.answer_correctness(model=f"endpoints:/{llm_judge}")
],
evaluators="default",
)
return results
# ベースの基盤モデルの評価
baseline_results = eval_llm(serving_endpoint_baseline_name, eval_dataset, llm_judge = "databricks-dbrx-instruct", run_name="dbdemos_fine_tuning_rag")
# ファインチューニングしたモデルの評価
fine_tuned_results = eval_llm(serving_endpoint_ft_name, eval_dataset, llm_judge = "databricks-dbrx-instruct", run_name="dbdemos_fine_tuning_rag")
3/ ランを分析するためにMLflowエクスペリメントUIを活用
MLflowが自動で統計情報を収集してくれます。
2つのランのエクスペリメントを開き、比較することができます:
- ベースラインモデルの
eval_dbdemos_llm_not_fine_tuned - ファインチューニングモデルの
eval_dbdemos_llm_fine_tuned
こちらはサンプルです。見てわかる様に、ファインチューニングモデルではメトリクスが改善されています!
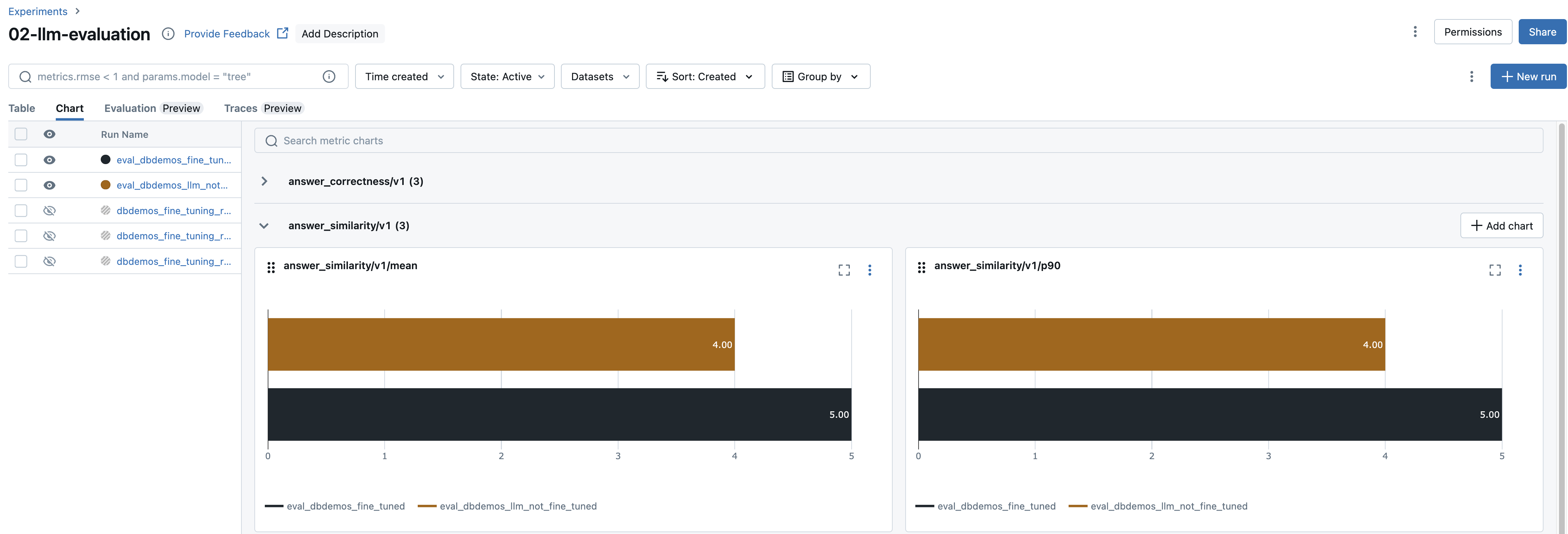
個々のクエリーを解析し、非常に間違っている回答をしている質問をフィルタリングすることもでき、それに応じてトレーニングデータセットを改善することができます。
大規模なデータセットをお持ちの場合、不適切な回答を持つ行をプログラムでフィルタリングすることができ、大規模なトレーニングデータセットに対する洞察を得るために、何が上手くいっていないのかを要約することをDBRXのような外部のモデルに依頼することができます!
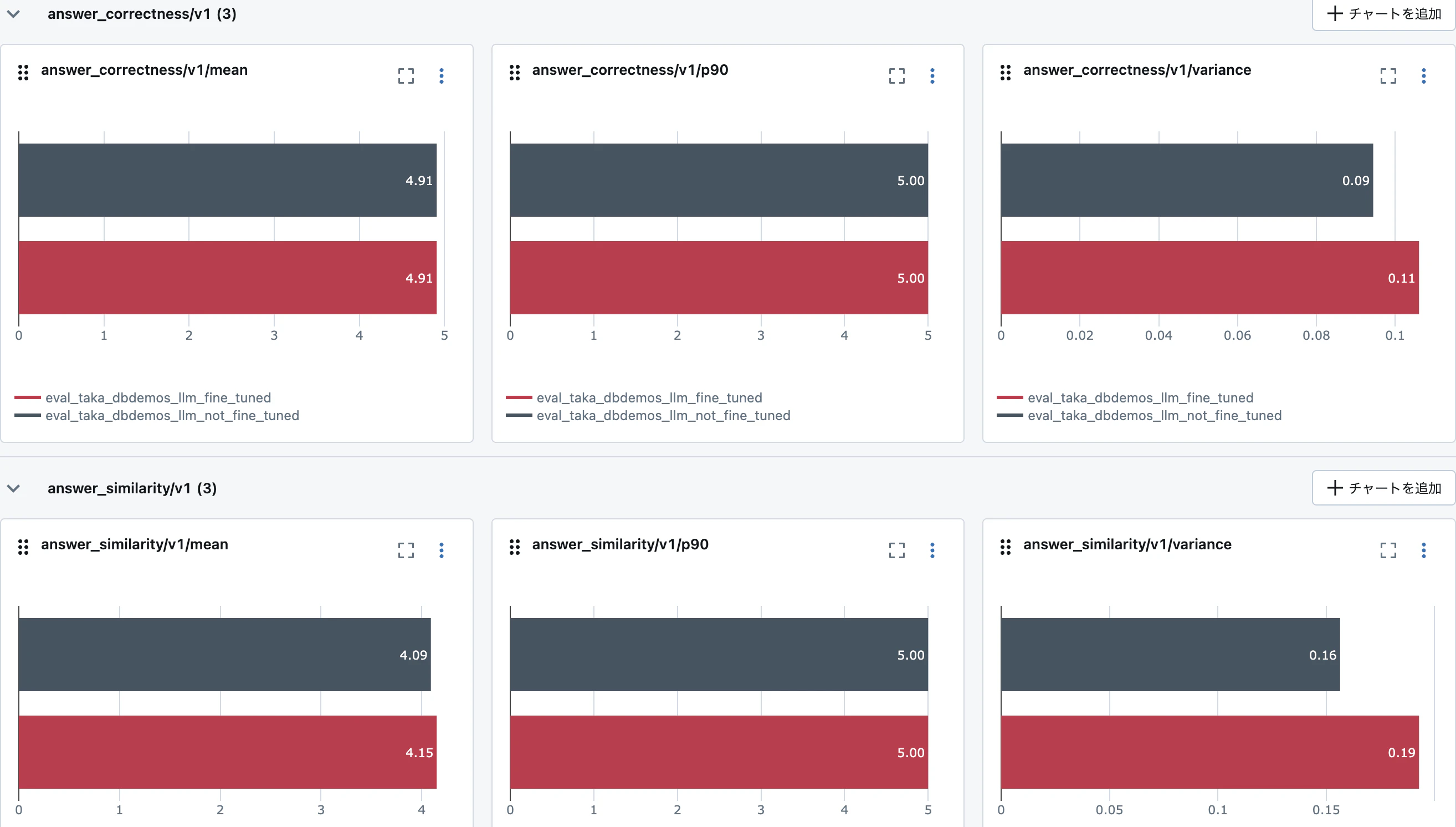
fine_tuned_results.metrics
{'answer_similarity/v1/mean': 4.14922480620155,
'answer_similarity/v1/variance': 0.19284823628387718,
'answer_similarity/v1/p90': 5.0,
'answer_correctness/v1/mean': 4.908914728682171,
'answer_correctness/v1/variance': 0.10604455862027522,
'answer_correctness/v1/p90': 5.0}
なお、これらのモデルはAI Playgroundでも比較することができます。
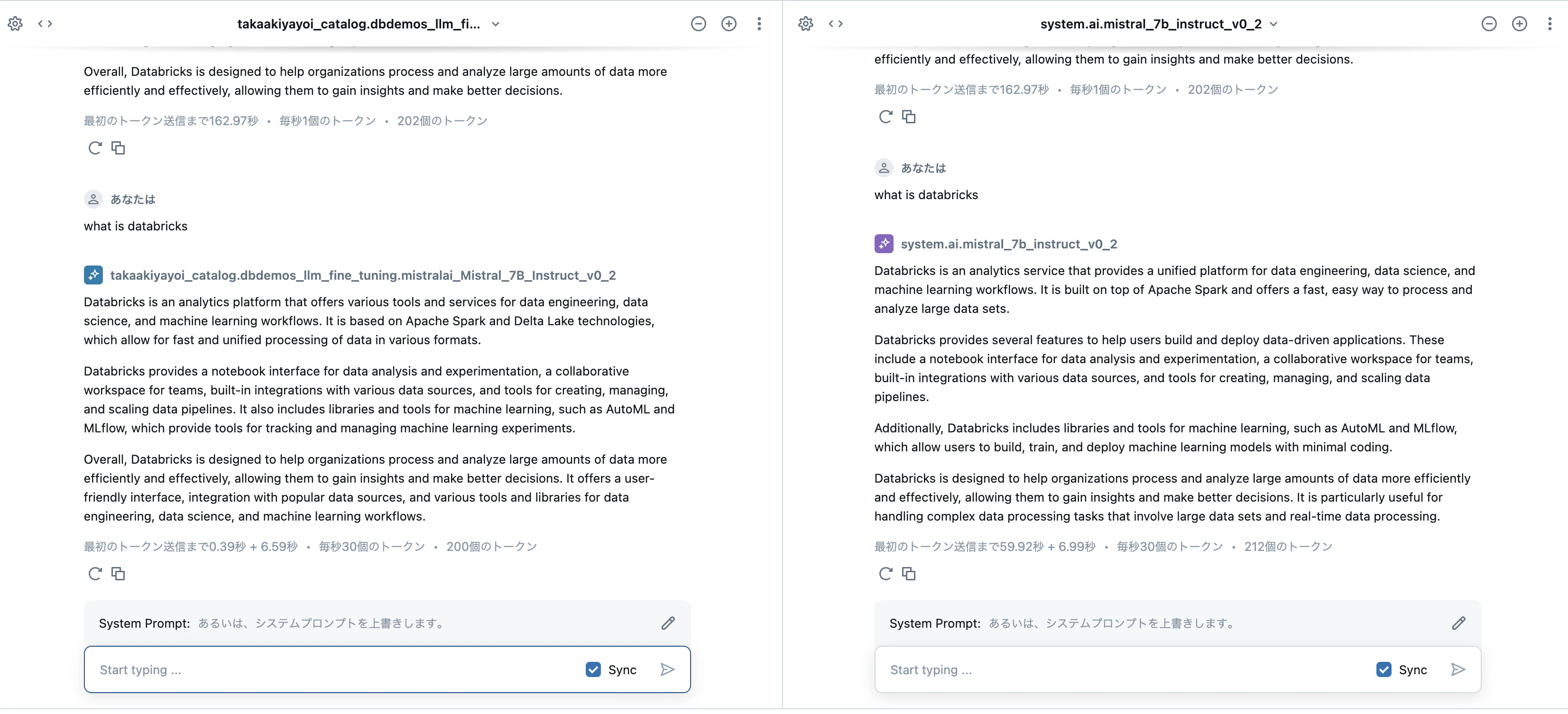
まとめ
DatabricksにおけるLLMのファインチューニングはシンプルであり、データサイエンティストの専門家を必要としません。
Mosaic MLファインチューニングを用いることで、新たなユースケースを解放し、ご自身の言語や期待する挙動をさせるようにOSSのLLMをファインチューニングすることができます。ご自身のデータをベースとしていかなるテキスト関連タスクを容易に構築することができます: エンティティ抽出、会話スタイルなどです!
次のステップ: 他のファインチューニングユースケースにディープダイブして探索したいですか?
ノートブックinstruction-fine-tuning/01-llm-instruction-drug-extraction-fine-tuningを用いて、あなたのモデルをNER (Named Entity Recognition)に特化させる様に指示ファインチューニングする方法を見ていきましょう。