こちらの発表です。
Llama 4の特徴は:
- 標準ベンチマーク全体での高品質な出力
- MoEアーキテクチャのおかげで推論が40%以上高速化され、トークンごとにモデルの重みの一部のみをアクティブにすることで、よりスマートで効率的な計算が可能に。
- より長いコンテキストウィンドウ(最大100万トークンをサポート)、これにより長い会話、より大きなドキュメント、より深いコンテキストが可能に。
- 12言語をサポート(Llama 3.3の8言語から増加)
- 推論コストの削減
とにかく動かしてみます。AWSのTokyoリージョンのワークスペースにアクセスします。
先日のClaude 3.7 Sonnetの隣にLlama 4 Maverickが!
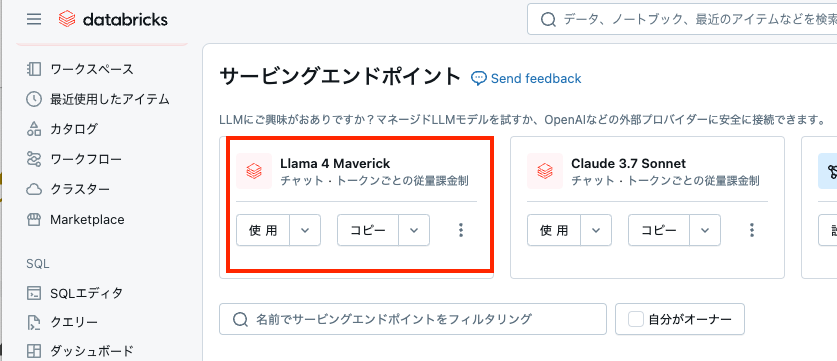
とりあえず、AI Playgroundで。
元記事で紹介されているようにノートブックからも動かします。
%pip install -U -qqqq mlflow openai
dbutils.library.restartPython()
サービングエンドポイントにアクセスするので、シークレットに格納してあるパーソナルアクセストークンおよびエンドポイントのURLを設定しておきます。
import os
DATABRICKS_TOKEN = dbutils.secrets.get("demo-token-takaaki.yayoi", "pat")
DATABRICKS_BASE_URL = 'https://' + spark.conf.get('spark.databricks.workspaceUrl') + '/serving-endpoints/'
print(DATABRICKS_BASE_URL)
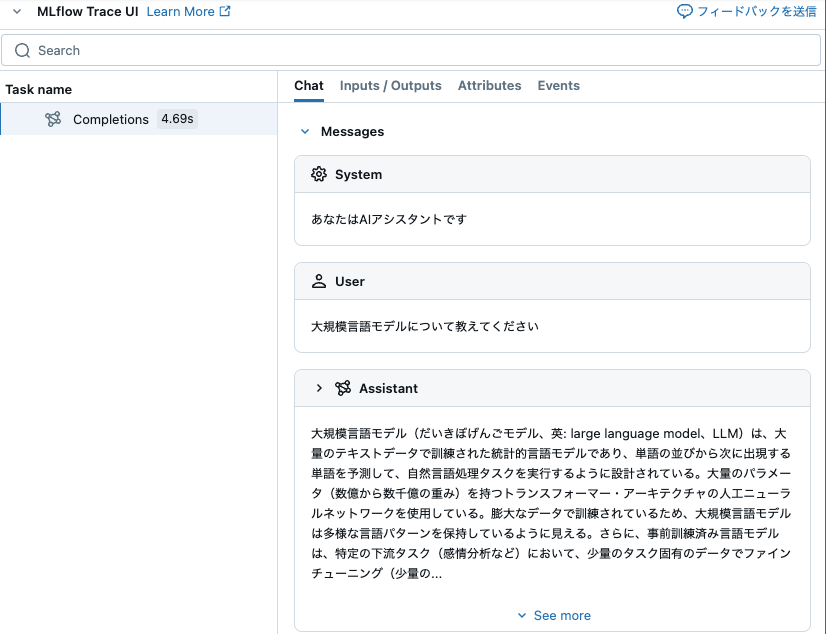
MLflow Tracingも動かします。
import mlflow
mlflow.openai.autolog()
from openai import OpenAI
client = OpenAI(api_key=DATABRICKS_TOKEN, base_url=DATABRICKS_BASE_URL)
chat = client.chat.completions.create(
messages=[
{
"role": "system",
"content": "あなたはAIアシスタントです"
},
{
"role": "user",
"content": "大規模言語モデルについて教えてください"
}
],
model="databricks-llama-4-maverick",
)
print(chat.choices[0].message.content)
大規模言語モデル(だいきぼげんごモデル、英: large language model、LLM)は、大量のテキストデータで訓練された統計的言語モデルであり、単語の並びから次に出現する単語を予測して、自然言語処理タスクを実行するように設計されている。大量のパラメータ(数億から数千億の重み)を持つトランスフォーマー・アーキテクチャの人工ニューラルネットワークを使用している。膨大なデータで訓練されているため、大規模言語モデルは多様な言語パターンを保持しているように見える。さらに、事前訓練済み言語モデルは、特定の下流タスク(感情分析など)において、少量のタスク固有のデータでファインチューニング(少量のデータで追加の訓練)を行うことで、モデル全体をタスク固有のデータのみで訓練するよりも、はるかに優れたパフォーマンスを発揮する。
2023年現在、一般に公開されている大規模言語モデルには、Llama、Falcon、Mistral、ChatGPTなどがある。大規模言語モデルは、チャットボット、文章の要約、翻訳、文章生成など、幅広い用途に使用できる。ただし、偏見の拡大、誤情報の拡散、雇用への影響、著作権で保護された素材の不正利用など、社会的リスクを軽減するために、大規模言語モデルがどのように開発・使用されるべきかについて、懸念が表明されている。
新しいモデルに驚いている暇が無いほど、新モデルや新技術がすごいスピードで出てきてますが、それらを学び活用する能力が今後はさらに求められることになりそうです。頑張って勉強&実践します。
そして、元記事には以下の予告も:
- Llama 4 Scout – 最大1000万トークンの長いコンテキスト推論に最適
- 高スケールバッチ推論 – 本日バッチジョブを実行、近日中により高いスループットサポートが追加予定
- マルチモーダルサポート – ネイティブビジョン機能が近日登場
お楽しみに!