Databricksのコアコンポーネントシリーズは一旦これで終了です。
Databricksにおける並列処理エンジンはApache Spark、ストレージフォーマットはDelta Lakeです。それではもう一つのコアコンポーネントであるMLflowは何に活用されるのでしょうか?本書ではMLflowとは何か、そのメリットは何かを説明します。
かつては、Jupyter notebookで機械学習モデルを構築し、モデルをExcelで管理していた身からすると、MLflowの無い生活には戻れません。
背景
過去数年を通じて機械学習モデルは様々なユースケースで活用されています。そして、大規模言語モデルの出現も起爆剤となっています。

しかし、機械学習の営みで重要なのは機械学習モデルだけではありません。
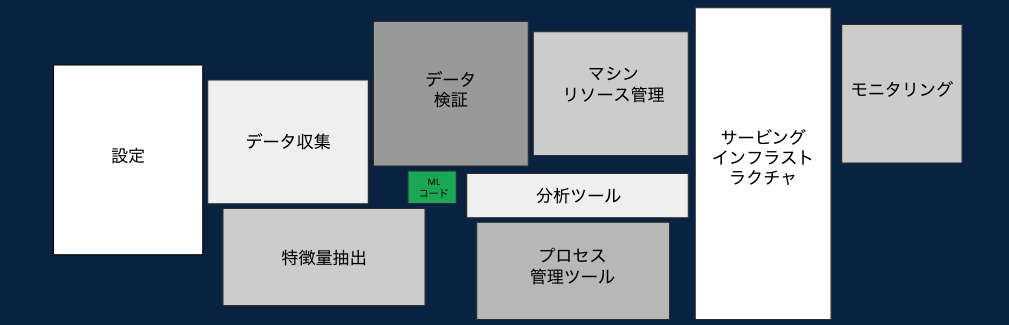
出典: https://papers.nips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
中央の緑の箱に示すように、MLコードは現実世界のMLシステムのほんの一部です。必要となる周辺のインフラストラクチャは広大で複雑です。
そして、データサイエンティストとデータエンジニアの用いる技術は大きく異なり、データも技術もサイロ化されています。

さらに、機械学習のライフサイクルはマニュアルであり、一貫性がなく分断されています。

このような状況を打開するためにも標準化が必要です。
標準化の必要性
あなたがデータサイエンティストだと仮定し、モデルを構築する日々の業務をイメージしてみましょう。
何かしらの機械学習モデルを構築したものとします。

精度が変化したのを見て思いを巡らします。
特徴量エンジニアリングに変更があったのか?

それ以外にもいろいろなことに気を配らなくてはなりません。
ハイパーパラメータはどのように変更された?
このモデルをトレーニングしたデータが変更された?
トレーニング時の精度は?
他に見逃していることは?
メモ帳やExcelでこれら全てを追跡することは不可能と言っても過言ではありません。
ソフトウェアのリリースと機械学習モデルのデプロイの違い
従来からあるソフトウェアのリリースサイクルと、機械学習モデルをデプロイするサイクルも大きく異なります。
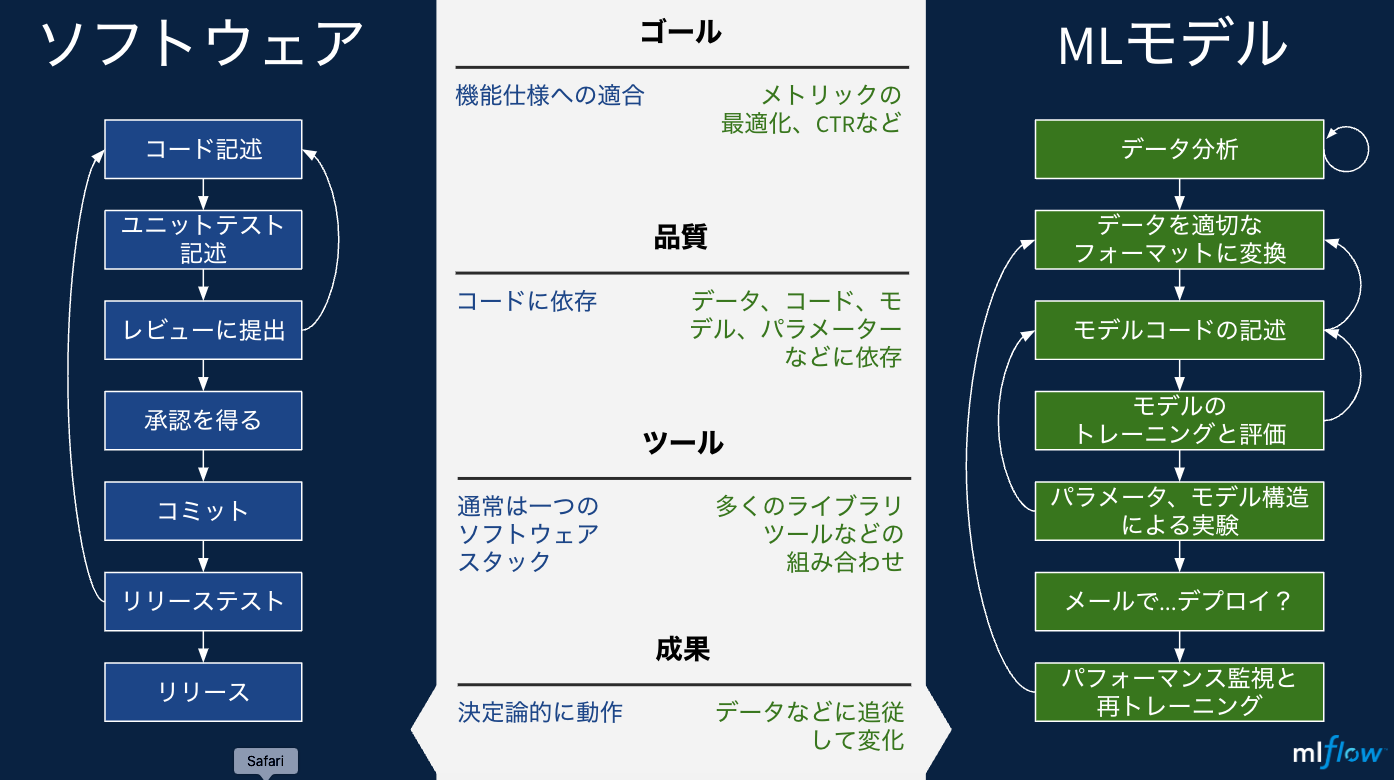
(特にウォーターフォール型の)ソフトウェア開発は仕様や要件に即したソフトウェアをリリースすれば一旦サイクルは終了します。一方で、機械学習モデルのウォーターフォール開発はイメージできません。基本的にはデータやアルゴリズムに対する試行錯誤を繰り返すことになります。さらに、一旦モデルをデプロイ(配備)したとしてもデータの傾向変化などによって精度が劣化(ドリフト)することが起こりえます。
要は MLモデルのデプロイは大変! ということなのです。
MLflow
このような大変さを解決するために開発されたのがMLflowという訳です。
MLflowは2018年6月に公開されました。MLflowは完全な機械学習ライフサイクルを管理するために設計された唯一のオープンソースフレームワークです。
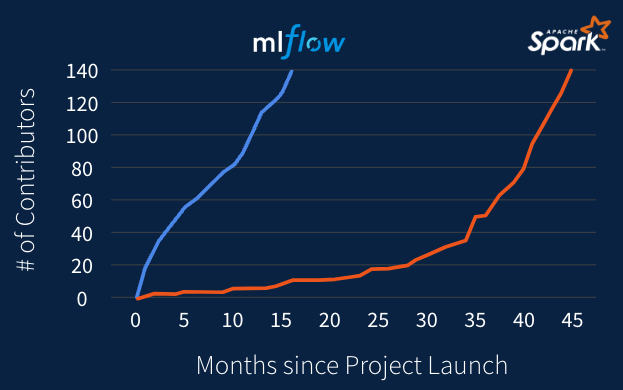
なお、プロジェクト開始以降、Sparkよりもすごい勢いでコントリビューターが増加しています。すごいですね。
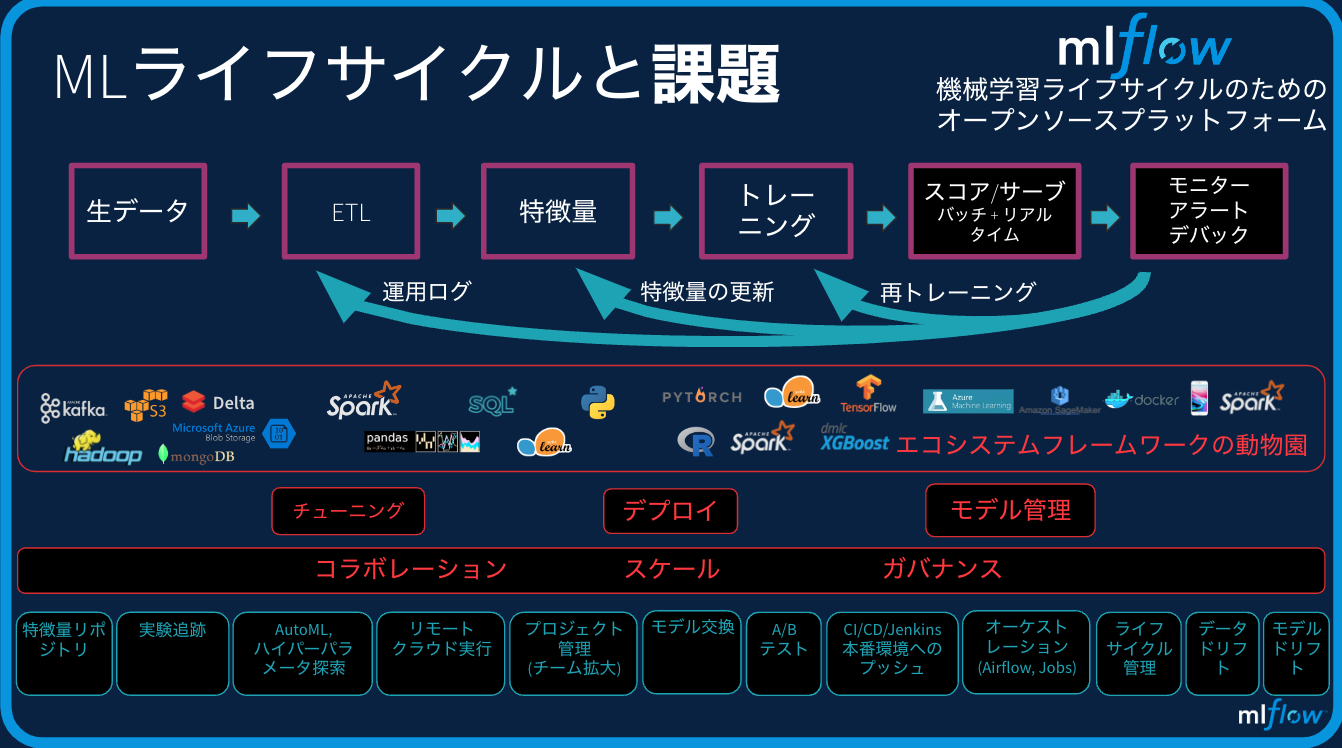
MLflowのコンポーネント
(最近いくつかのコンポーネントが追加されていますが)MLflowには主に4つのコンポーネントから構成されています。

- MLflow Tracking: 上述したモデルの追跡を一手に引き受けてくれます。
- MLflow Projects: モデルの実行環境の可搬性を実現します。トレーニングしたモデルの依存関係などをパッケージングして、様々な環境での実行を実現します。
- MLflow Models: 様々なモデルをフレーバーとして表現し、様々な環境で活用できるようにモデルを標準化します。
- MLflow Model Registry: 機械学習モデル版GitHubです。モデルのバージョン管理、ステータス管理、コラボレーションを可能にします。
MLflow Tracking
MLflowトラッキングサーバーが、いかなる環境であってもトレーニングされたモデルを必要な情報と共に記録します。これによって、データサイエンティストの方は優れたモデルの構築にフォーカスできるようになります。トレーニングしたモデルはMLflowが面倒を見るので、あとでUIなどからモデルに簡単にアクセスできます。
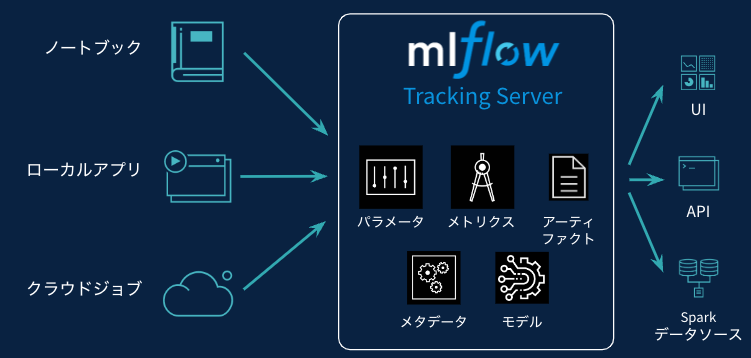
トラッキングされるものは以下の通りです。
- パラメータ: コードに対するキーバリューの入力値(決定木の深さ、データのバージョンなど)
- メトリクス: (時間と共にアップデートされる)精度指標。
- モデル: 機械学習モデル本体。
- アーティファクト: 任意のファイル。グラフなども含めることが可能。
- ソース: モデルをトレーニングしたソースコード。
トラッキングは簡単です。以下のようなトレーニングのコードがあるとします。
# ElasticNetによる線形回帰のScikit学習
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
# 予測
predicted_qualities = lr.predict(test_x)
# メトリクスの評価
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
コードをmlflow.start_run()ブロックに含めて、mlflowのメソッドで記録するだけです。なお、明示的にメソッドを呼び出すこともできますが、Auto Loggingを活用して、自動で必要な情報を記録させることも可能です。
with mlflow.start_run() as run:
# ElasticNetによる線形回帰のScikit学習
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
# 予測
predicted_qualities = lr.predict(test_x)
# メトリクスの評価
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
# 記録
mlflow.log_param("alpha", alpha)
...
MLflow Projects
MLflowプロジェクトを用いることで、モデルの実行に必要な情報をパッケージングできるので様々な環境での再利用が可能となります。
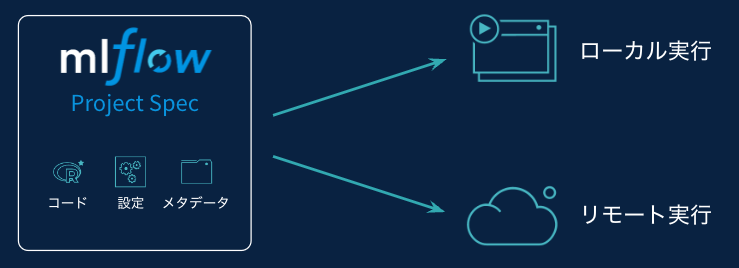
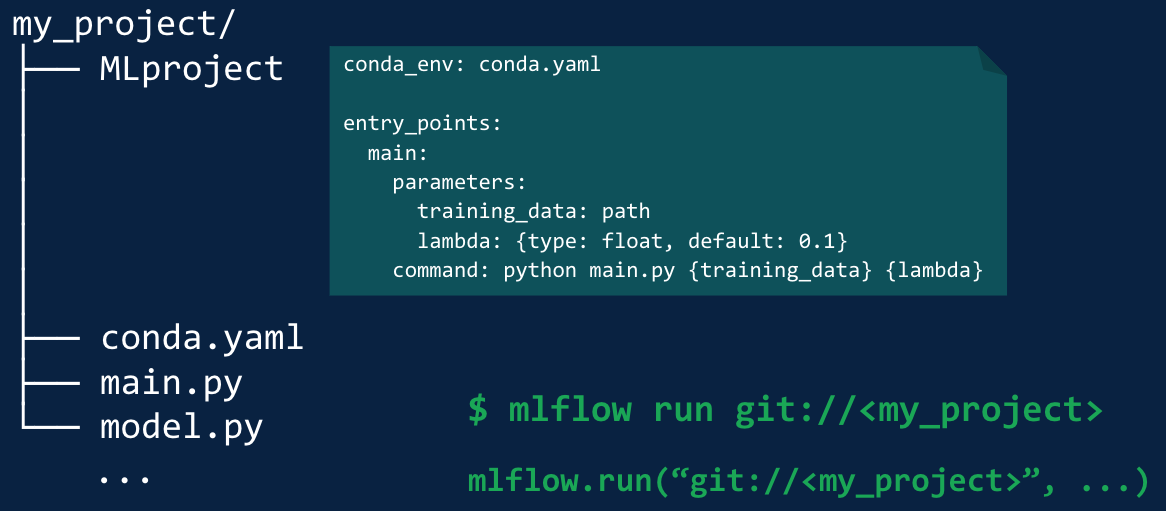
ディレクトリ配下に、必要なコードやconda.yamlファイルを格納することで再実行を容易にします。
MLflow Models
様々なライブラリのモデルをフレーバーとして表現することで、様々な環境にモデルを持ち込むことが可能となります。
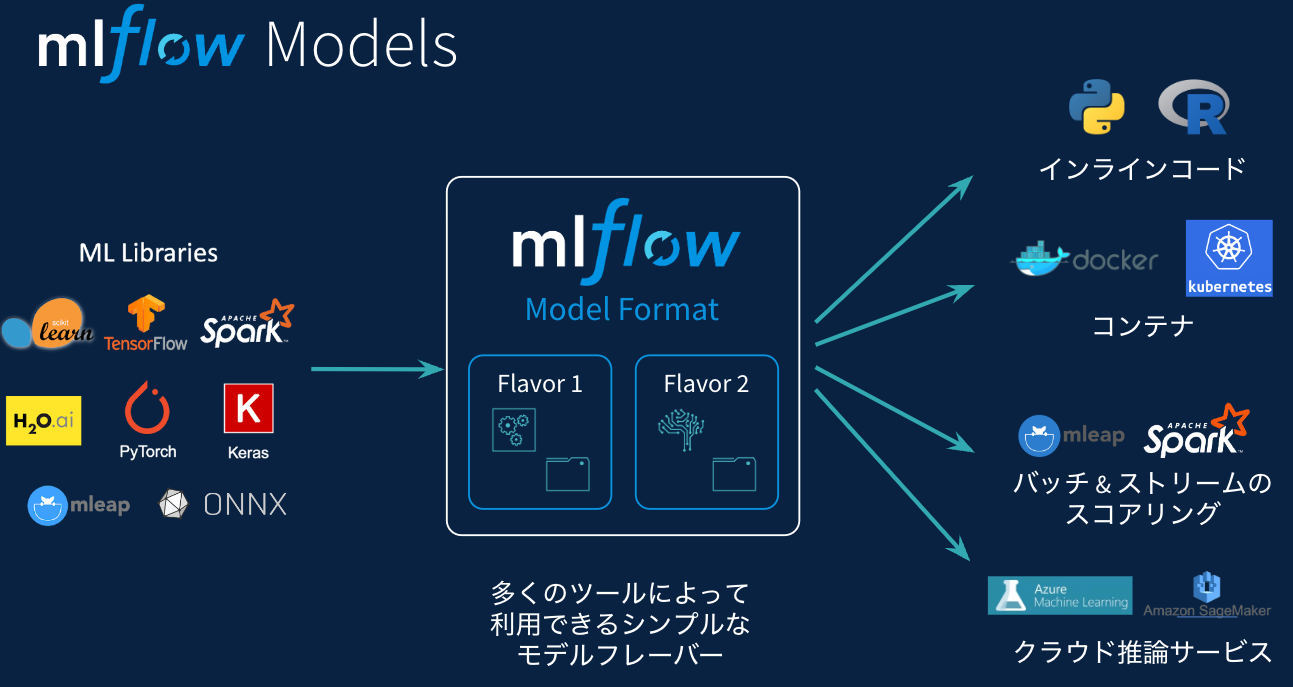
こちらにあるように、様々なフレーバーが提供されています。
- Python関数
- R関数
- Keras
- PyTorch
- Scikit-learn
- Spark MLlib
- XGBoost
- LightGBM
- Prophet
- Pmdarima
- OpenAI
これらのフレーバーを活用してモデルを記録することで、いろいろな環境でこれらの機械学習モデルを呼び出して実行することができます。
MLflow Model Registry
上述したようにMLflowモデルレジストリは機械学習モデル版のGitHubです。
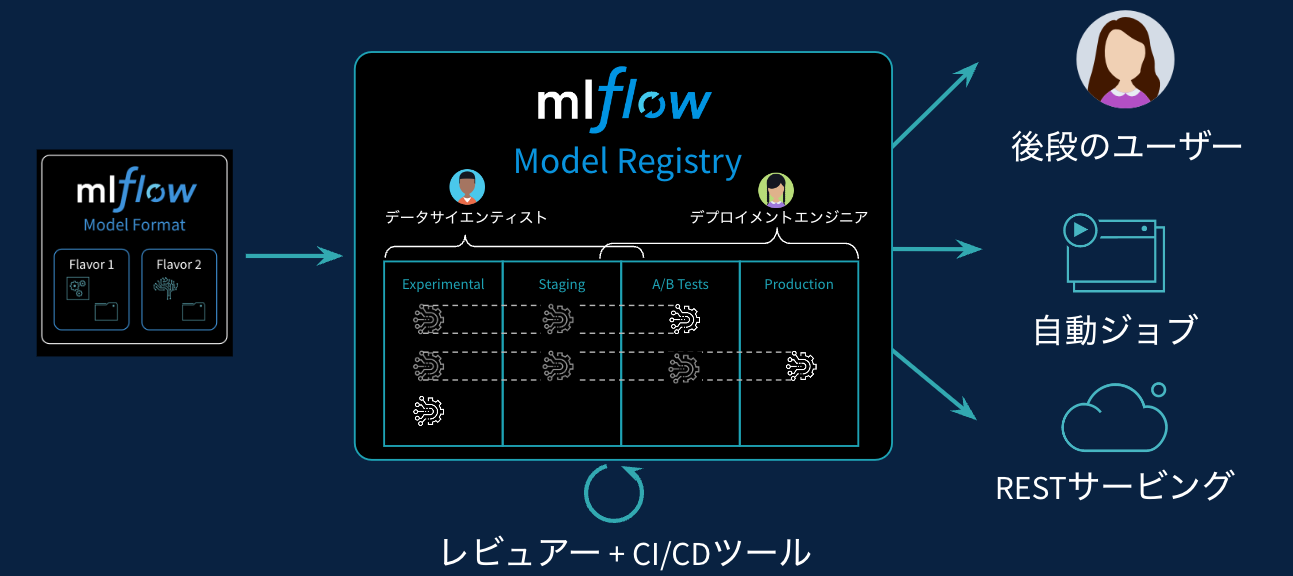
企業においては、多くのデータサイエンティストの方がテーマに合わせて様々なモデルを構築すると思いますが、そのようなモデルの一元管理やコラボレーションを可能にします。ここでいうコラボレーションには以下のようなものがあります。
- あるデータサイエンティストが実験を通じて構築した機械学習モデルを先輩のサイエンティストがレビューして、本番環境へのデプロイを承認する。承認されたモデルは本番環境に自動でデプロイされる。
- ある機械学習モデルに対してコメントする。
- モデルのステータス変更に関する通知を受け取る。
- モデルの説明ページにアクセスして用途やモデルを生成したコードを確認する。
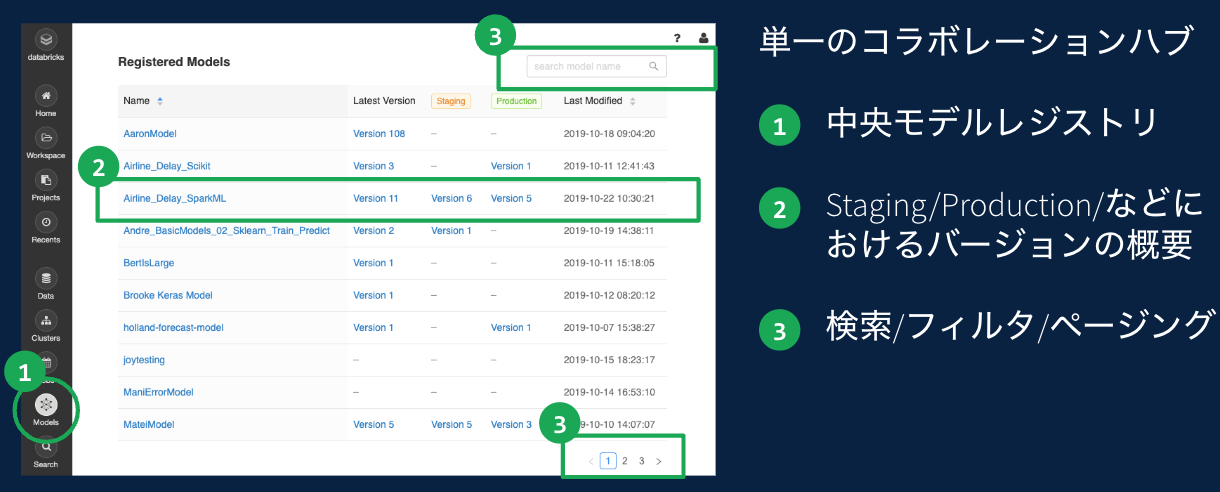
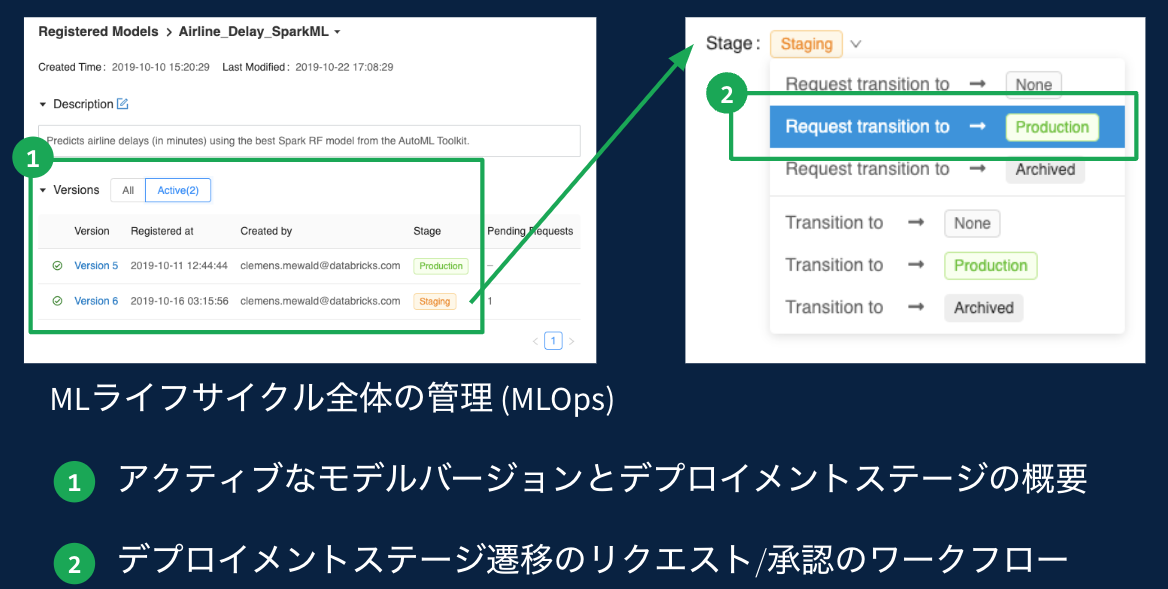
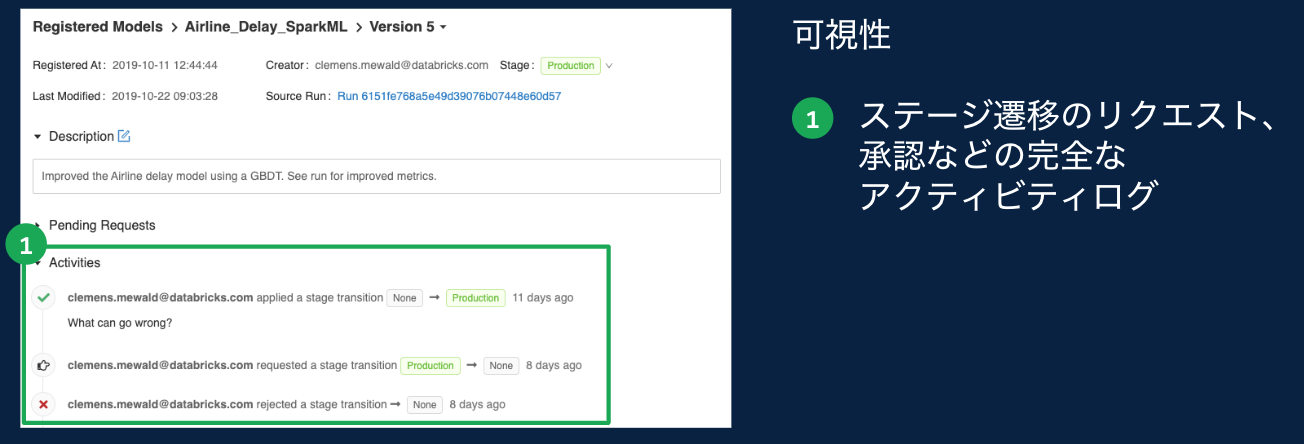
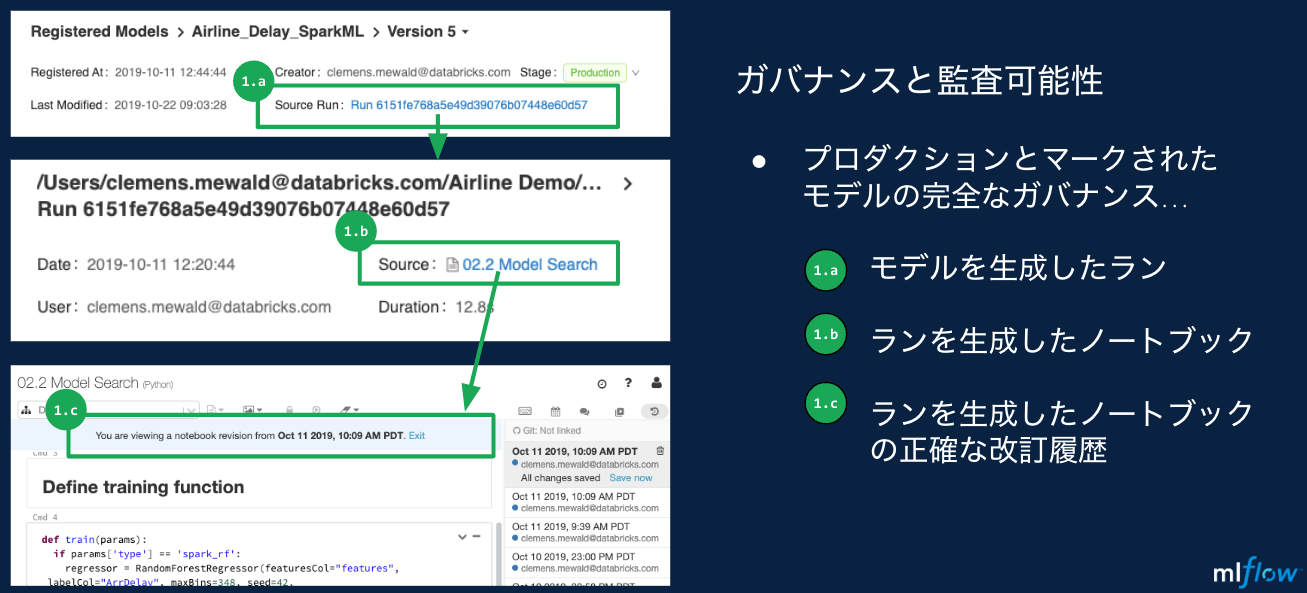
まとめ
MLflowを活用することで、原理原則に基づいたデータサイエンスとMLを実現することができます。すなわち、MLOpsです!
- ある機械学習モデルを本番環境に移行する前に、このモデルを構築する際に用いたデータ、パラメーター、環境が何であったのかに悩むことがなくなります。なぜならば、すべてがMLflowによって記録されているからです!
- 野放図な機械学習モデルの運用とはおさらばし、ガバナンスが効いた環境下で適切な承認フローを経て機械学習モデルが運用されるようになります!
- 属人的な機械学習モデルの運用ともおさらばし、モデルレジストリで機械学習モデルを集中管理することで各人のノートパソコンにモデルが閉じ込められることが無くなり、チーム間でのノウハウ(どのようなデータを用いて、どのようなライブラリ、ロジックを用いてモデルを構築することで良い精度が出るのか等)の共有が促進されます!
なお、MLflowはオープンソースですが、Databricksの環境では最初からインテグレーションされていますので、サインアップいただければすぐに活用いただけます(宣伝)。
凄まじいスピードで大規模言語モデルのサポートも進んでいるMLflow、ぜひご活用ください!