2024/4/12に翔泳社よりApache Spark徹底入門を出版します!

書籍のサンプルノートブックをウォークスルーしていきます。Python/Chapter10/10-6 Decision Treesとなります。
翻訳ノートブックのリポジトリはこちら。
ノートブックはこちら
以前のノートブックではパラメトリックモデルである線形回帰を取り扱いました。線形回帰モデルさらにハイパーパラメーターチューニングを行うこともできますが、ツリーベースの手法をトライし、パフォーマンスの改善を見ていきます。
filePath = "/databricks-datasets/learning-spark-v2/sf-airbnb/sf-airbnb-clean.parquet"
airbnbDF = spark.read.parquet(filePath)
trainDF, testDF = airbnbDF.randomSplit([.8, .2], seed=42)
カテゴリ型の特徴量をどのように取り扱うべきか?
以前のノートブックでStringIndexer/OneHotEncoderEstimator/VectorAssemblerやRFormulaを活用できることを見てきました。
しかし、決定木、特にランダムフォレストでは、変数をOHEすべきではありません。
なぜでしょうか?それは、スプリットの作成方法が違い(ツリーを可視化するとわかります)、特徴量の重要度スコアが正しくありません。
(すぐに説明する)ランダムフォレストでは、結果は劇的に変化します。このため、RFormulaを使うのではなく、シンプルにStringIndexer/VectorAssemblerを使います。
from pyspark.ml.feature import StringIndexer
categoricalCols = [field for (field, dataType) in trainDF.dtypes if dataType == "string"]
indexOutputCols = [x + "Index" for x in categoricalCols]
stringIndexer = StringIndexer(inputCols=categoricalCols, outputCols=indexOutputCols, handleInvalid="skip")
VectorAssembler
すべてのカテゴリ型と数値型の入力のすべてを組み合わせるためにVectorAssemblerを使いましょう Python/Scala。
from pyspark.ml.feature import VectorAssembler
# 数値列のみにフィルタリング(そして、ラベルのpriceを除外)
numericCols = [field for (field, dataType) in trainDF.dtypes
if ((dataType == "double") & (field != "price"))]
# 上で定義したStringIndexerの出力と数値列を結合
assemblerInputs = indexOutputCols + numericCols
vecAssembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
決定木
デフォルトのハイパーパラメータでDecisionTreeRegressorを構築しましょう Python/Scala。
from pyspark.ml.regression import DecisionTreeRegressor
dt = DecisionTreeRegressor(labelCol="price")
パイプラインのフィッティング
from pyspark.ml import Pipeline
# ステージをパイプラインに結合
stages = [stringIndexer, vecAssembler, dt]
pipeline = Pipeline(stages=stages)
# フィッティング
pipelineModel = pipeline.fit(trainDF)
IllegalArgumentException: requirement failed: DecisionTree requires maxBins (= 32) to be at least as large as the number of values in each categorical feature, but categorical feature 3 has 36 values. Consider removing this and other categorical features with a large number of values, or add more training examples.
File <command-3966529444466685>, line 8
5 pipeline = Pipeline(stages=stages)
7 # フィッティングを行うにはコメントを解除
----> 8 pipelineModel = pipeline.fit(trainDF)
File /databricks/spark/python/pyspark/errors/exceptions/captured.py:230, in capture_sql_exception.<locals>.deco(*a, **kw)
226 converted = convert_exception(e.java_exception)
227 if not isinstance(converted, UnknownException):
228 # Hide where the exception came from that shows a non-Pythonic
229 # JVM exception message.
--> 230 raise converted from None
231 else:
232 raise
maxBins
パラメーターのmaxBinsは何でしょうか?(Sparkが使う)分散決定技のPLANET実装を見て、Matei ZahariaらによるYggdrasilという論文と比較してみましょう。これは、maxBinsパラメータを説明する助けとなります。

Sparkでは、データは行ごとにパーティションが作成されます。このため、スプリットを行う必要がある際には、それぞれのワーカーでそれぞれの分割ポイントのすべての特徴量のサマリー統計情報を計算する必要があります。そして、これらのサマリー統計情報は作成されるそれぞれのスプリットに対して(ツリーのreduceを通じて)集約される必要があります。
考えてみましょう: ワーカー1では値32があり、他のワーカーではその値ではない場合どうなるでしょうか。あるスプリットがどのくらい良いものであるのかをどのように伝えるのでしょうか?このため、Sparkでは連続的な変数をバケットに離散化するためのmaxBinsパラメーターがありますが、バケットの数はカテゴリ型変数の数と同じくらい大きなものである必要があります。
先に進めて、maxBinsを40に増やします。
dt.setMaxBins(40)
DecisionTreeRegressor_0755491ad393
テイク2です。
pipelineModel = pipeline.fit(trainDF)
決定木の可視化
dtModel = pipelineModel.stages[-1]
print(dtModel.toDebugString)
DecisionTreeRegressionModel: uid=DecisionTreeRegressor_0755491ad393, depth=5, numNodes=47, numFeatures=33
If (feature 12 <= 2.5)
If (feature 12 <= 1.5)
If (feature 5 in {1.0,2.0})
If (feature 4 in {0.0,1.0,3.0,5.0,9.0,10.0,11.0,13.0,14.0,16.0,18.0,24.0})
If (feature 3 in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,20.0,21.0,23.0,24.0,25.0,26.0,27.0,28.0,29.0,30.0,31.0,32.0,33.0,34.0})
Predict: 104.23992784125075
Else (feature 3 not in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,20.0,21.0,23.0,24.0,25.0,26.0,27.0,28.0,29.0,30.0,31.0,32.0,33.0,34.0})
Predict: 250.7111111111111
Else (feature 4 not in {0.0,1.0,3.0,5.0,9.0,10.0,11.0,13.0,14.0,16.0,18.0,24.0})
If (feature 3 in {0.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,20.0,21.0,22.0,23.0,27.0,33.0,35.0})
Predict: 151.94179894179894
Else (feature 3 not in {0.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,20.0,21.0,22.0,23.0,27.0,33.0,35.0})
Predict: 245.8507462686567
Else (feature 5 not in {1.0,2.0})
If (feature 3 in {1.0,5.0,6.0,7.0,8.0,9.0,11.0,13.0,15.0,16.0,17.0,19.0,22.0,23.0,24.0,25.0,26.0,28.0,29.0,30.0,33.0})
If (feature 3 in {5.0,8.0,13.0,15.0,16.0,19.0,22.0,23.0,24.0,25.0,28.0,30.0,33.0})
Predict: 131.96658097686375
Else (feature 3 not in {5.0,8.0,13.0,15.0,16.0,19.0,22.0,23.0,24.0,25.0,28.0,30.0,33.0})
Predict: 164.19959266802445
Else (feature 3 not in {1.0,5.0,6.0,7.0,8.0,9.0,11.0,13.0,15.0,16.0,17.0,19.0,22.0,23.0,24.0,25.0,26.0,28.0,29.0,30.0,33.0})
If (feature 10 <= 6.5)
Predict: 205.5814889336016
Else (feature 10 > 6.5)
Predict: 841.6666666666666
Else (feature 12 > 1.5)
If (feature 13 <= 4.5)
If (feature 3 in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,15.0,16.0,17.0,18.0,19.0,22.0,23.0,24.0,25.0,26.0,27.0,28.0,29.0,30.0,31.0,33.0,34.0})
If (feature 14 <= 26.5)
Predict: 290.8357933579336
Else (feature 14 > 26.5)
Predict: 214.04819277108433
Else (feature 3 not in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,9.0,10.0,11.0,12.0,13.0,15.0,16.0,17.0,18.0,19.0,22.0,23.0,24.0,25.0,26.0,27.0,28.0,29.0,30.0,31.0,33.0,34.0})
If (feature 14 <= 3.5)
Predict: 741.64
Else (feature 14 > 3.5)
Predict: 309.03921568627453
Else (feature 13 > 4.5)
If (feature 15 <= 0.5)
If (feature 2 in {1.0})
Predict: 300.0
Else (feature 2 not in {1.0})
Predict: 10000.0
Else (feature 15 > 0.5)
If (feature 3 in {1.0,4.0,5.0,7.0,8.0,19.0})
Predict: 222.91666666666666
Else (feature 3 not in {1.0,4.0,5.0,7.0,8.0,19.0})
Predict: 398.0
Else (feature 12 > 2.5)
If (feature 1 in {0.0,1.0,2.0,3.0,4.0})
If (feature 12 <= 5.5)
If (feature 3 in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,10.0,11.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,21.0,22.0,23.0,24.0,25.0,26.0,28.0,29.0,30.0,33.0})
If (feature 14 <= 7.5)
Predict: 493.3795620437956
Else (feature 14 > 7.5)
Predict: 296.76666666666665
Else (feature 3 not in {0.0,1.0,2.0,3.0,4.0,5.0,6.0,7.0,8.0,10.0,11.0,13.0,14.0,15.0,16.0,17.0,18.0,19.0,21.0,22.0,23.0,24.0,25.0,26.0,28.0,29.0,30.0,33.0})
If (feature 9 <= -122.411075)
Predict: 722.96875
Else (feature 9 > -122.411075)
Predict: 2399.4
Else (feature 12 > 5.5)
If (feature 4 in {0.0,1.0,5.0,7.0})
If (feature 3 in {0.0,3.0,6.0,25.0})
Predict: 609.5
Else (feature 3 not in {0.0,3.0,6.0,25.0})
Predict: 1715.0
Else (feature 4 not in {0.0,1.0,5.0,7.0})
Predict: 8000.0
Else (feature 1 not in {0.0,1.0,2.0,3.0,4.0})
Predict: 8000.0
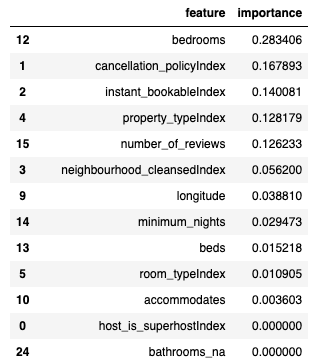
特徴量の重要度
先に進めて、フィッティングした決定木モデルを取得し、特徴量の重要度スコアを見てみましょう。
dtModel = pipelineModel.stages[-1]
dtModel.featureImportances
SparseVector(33, {1: 0.1679, 2: 0.1401, 3: 0.0562, 4: 0.1282, 5: 0.0109, 9: 0.0388, 10: 0.0036, 12: 0.2834, 13: 0.0152, 14: 0.0295, 15: 0.1262})
特徴量重要度の解釈
うーん、特徴量4や11が何であるのかを理解するのは困難です。特徴量重要度のスコアが「小さなデータ」であれば、オリジナルのカラム名に復旧するためにPandasを使いましょう。
import pandas as pd
dtModel = pipelineModel.stages[-1]
featureImp = pd.DataFrame(
list(zip(vecAssembler.getInputCols(), dtModel.featureImportances)),
columns=["feature", "importance"])
featureImp.sort_values(by="importance", ascending=False)
テストセットにモデルを適用
predDF = pipelineModel.transform(testDF)
display(predDF.select("features", "price", "prediction").orderBy("price", ascending=False))

落とし穴
規模の大きいAirbnb賃貸情報の場合はどうしましょうか?例えば20のベッドルームと20のバスルームです。決定木はどのように予測を行うのでしょうか?
決定木はトレーニングしたものより大きな値を予測できないことがわかります。ここでのトレーニングセットの最大値は$10,000なので、それよりも大きな値を予測することはできません。
from pyspark.ml.evaluation import RegressionEvaluator
regressionEvaluator = RegressionEvaluator(predictionCol="prediction",
labelCol="price",
metricName="rmse")
rmse = regressionEvaluator.evaluate(predDF)
r2 = regressionEvaluator.setMetricName("r2").evaluate(predDF)
print(f"RMSE is {rmse}")
print(f"R2 is {r2}")
RMSE is 385.8704264527981
R2 is -1.5696388432265533
なんてこった!
このモデルは線形回帰モデルよりも精度が悪いです。
次のいくつかのノートブックでは、単体の決定木のパフォーマンスよりも改善するために、ハイパーパラメーターチューニングやアンサンブルモデルを見ていきましょう。