7 Reasons to Migrate from your Cloud-based Hadoop to Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
過去数年間を通じて、多くの企業が自分たちのレガシーでオンプレミスなHadoopワークロードを、EMR、HDInsight、DataProcのようなクラウドベースのマネージドサービスに移行しています。しかし、お客様はオンプレミスのHadoop環境で直面したのと同じ課題(信頼性やスケーラビリティなど)を既存のクラウドベースのHadoop環境に継承してしまっていることに気づき始めています。彼らは、クラスターの配備、起動に時間を要しており、ピーク時間にオートスケールする際にもさらに時間を要していることを観測しています。このため、ワークロードの需要に対応するために長時間稼働し、過度に配備したクラスターを維持しています。多くの時間がエンドツーエンドのパイプラインを維持管理するために、トラブルシュート、インフラストラクチャ、リソース管理のオーバーヘッド、異なるマネージドサービスを繋ぎ合わせることに費やされています。
最後になりますが、これはリソースの無駄となり、セキュリティやガバナンスを複雑にし、不要なコストを増加させます。このため、お客様はデータチームが継承されたHadoopプラットフォームの問題のトラブルシュートではなく、ビジネス課題の解決にフォーカスできるようになってほしいと思っています。
この記事では、クラウドベースのHadoopプラットフォームをDatabricksレイクハウスプラットフォームに移行することの価値やメリットを議論します。
以下に、これらクラウドベースHadoopサービスをDatabricksに移行することを検討するに値する特筆すべき価値と理由を示します。
- レイクハウスプラットフォームでご自身のアーキテクチャをシンプルに
- 集中管理されるデータガバナンスとセキュリティ
- すべてのデータワークロードにおける最高のパフォーマンス
- 生産性の改善とビジネス価値の向上
- データとAIによるイノベーションの促進
- クラウドに依存しないプラットフォーム
- Databricksパートナーエコシステムのメリット
これら7つの理由の詳細を議論して学んでいきましょう。
1) レイクハウスプラットフォームでご自身のアーキテクチャをシンプルに
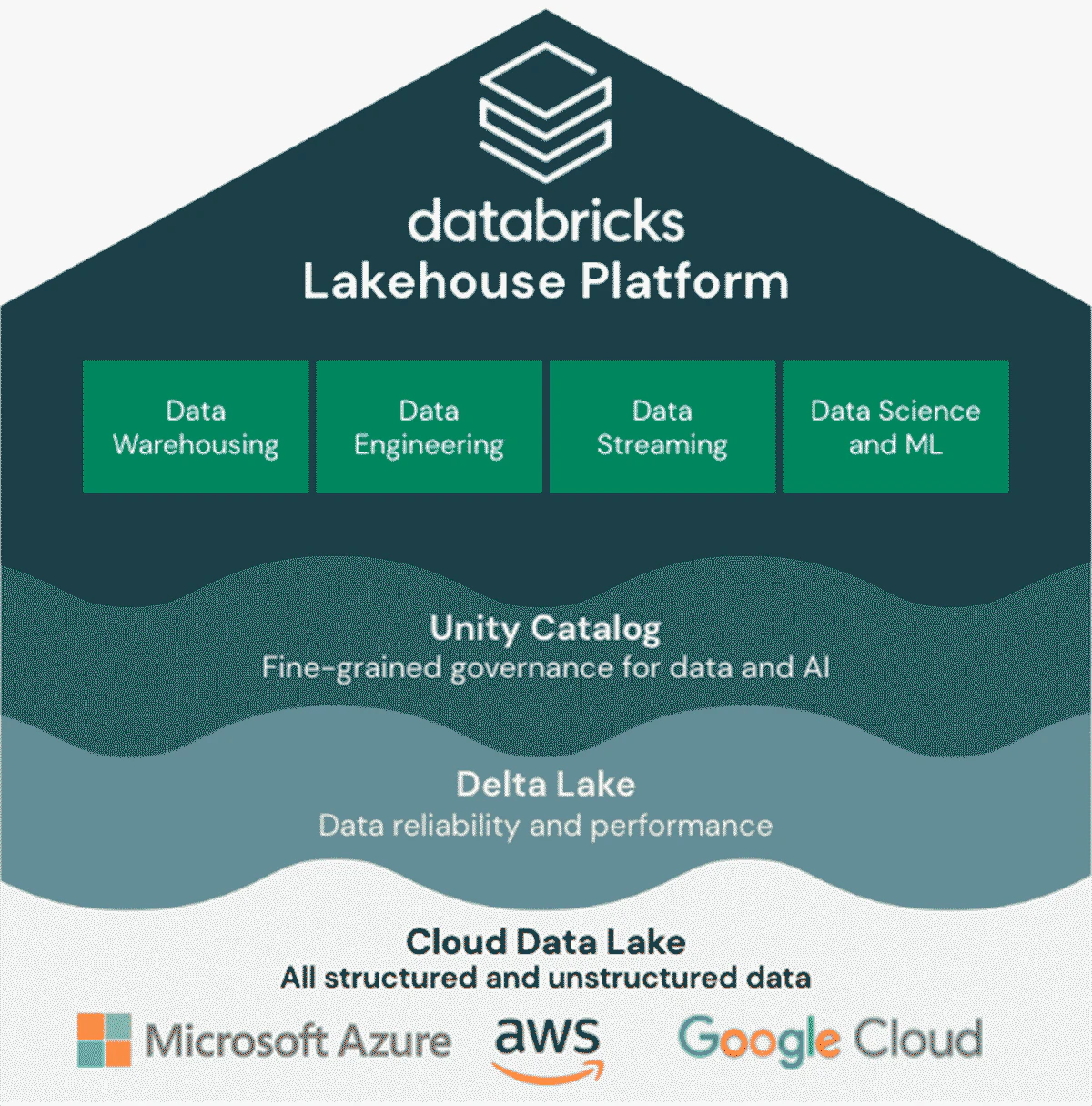
Databricksレイクハウスプラットフォームは、データウェアハウスの信頼性、ガバナンス、パフォーマンスと、データレイクのオープン性、柔軟性、機械学習サポートを提供するために、データレイクとデータウェアハウスのベストな部分を組み合わせています。
多くの場合、クラウドベースのHadoopプラットフォームはデータエンジニアリングのような固有のユースケースで使用されており、ストリーミング、BI、データサイエンスユースケースでは他のサービスや製品で拡張する必要があります。これは、データサイロや分断されたチームを引き起こす複雑なアーキテクチャにつながり、セキュリティやガバナンスの課題を引き起こします。
レイクハウスプラットフォームは、これらの複雑性を排除することでデータスタックをシンプルにする統合的なアプローチを提供します。
2) 集中管理されるデータガバナンスとセキュリティ
Databricksでは、Unity Catalogを用いてレイクハウスのデータに対するきめ細かいガバナンスとセキュリティを提供します。Unity Catalogによって、企業では標準的なANSI SQLやシンプルなUIを用いてきめ細かいデータアクセス権を管理することができ、安全にレイクハウスを利用できるようになります。
Unity Catalogは、テーブルを管理するだけでなく、機械学習モデルやファイルのような他のデータ資産の管理までも対応します。これによって、企業は自分たちのデータ&AI資産の統治方法をシンプルにすることができます。これは、企業において重要なアーキテクチャ上の教義であり、お客様がクラウドベースのHadoopではなくDatabricksに移行する主要な理由となっています。
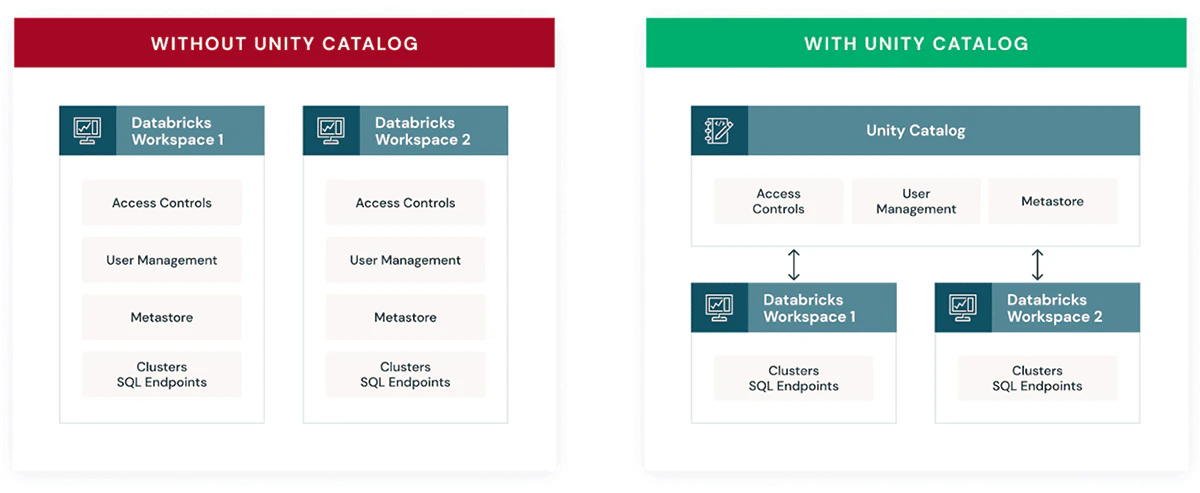
ハイレベルでは、Unity Catalogは以下の主要な機能を提供しています:
- 集中管理されたメタデータとユーザー管理
- 集中管理されたデータアクセスコントロール
- データリネージ
- データアクセス監査
- データ検索と発見
- Delta Sharingによるセキュアなデータ共有
Unity Catalogとは別に、ご自身のデータガバナンス要件を満たすことが可能なテーブルアクセスコントロール(TACL)やIAMロールクレディンシャルパススルーのような機能を提供しています。
さらに、Delta Lakeを用いることで、すぐに自動でスキーマ強制やスキーマ進化のようなメリットを享受することができます。
Delta Sharingを用いることで、データが存在しているプラットフォームと独立して、リアルタイムに企業間でセキュアにデータを共有することができます。ネイティブにDatabricksレイクハウスプラットフォームにインテグレーションされているので、一つのプラットフォームですべての共有データの発見、管理、統治を集中管理することができます。
3) すべてのデータワークロードにおける最高のパフォーマンス
レイクハウスでの、すべてのタイプのワークロードにおいて低コストの高スピードクエリー性能を提供するDatabricksのPhotonエンジンに移行することで、お客様は最高クラスのパフォーマンスを手に入れることができます。
- Photonによって、データをデータウェアハウスに移動することなしに大部分の分析ワークロードがデータウェアハウス相当、あるいはそれ以上の性能を発揮します。
- PhotonはApache Spark™ APIやSQLとの互換性があるため、使い始めるのはスイッチをオンするくらい簡単です。
- 最初からC++で記述されており、Photonはより高速な性能を出すモダンなハードウェアを活用することができ、他のクラウドデータウェアハウスよりも優れたコストパフォーマンスを発揮します。詳細は、Databricksが正式にデータウェアハウスのパフォーマンス世界記録を達成をご覧ください。
これとは別に、Databricksの強化オートスケーリングは、あなたのパイプラインのデータ処理レーテンシーへのインパクトを最小にしつつも、ワークロードのボリュームに基づいてクラスターリソースを自動で割り当てることで、クラスターの使用率を最適化します。クラスターのスケーリングは、クラウドベースのHadoopプラットフォームの重大な問題となっており、場合によってはオートスケールに30分要することがあります。
クラウドベースのHadoopプラットフォームと比較して優れているDatabricksのパフォーマンスによって、全体的なTCOが劇的に削減します。お客様は、インフラストラクチャ費用を削減し、それと同時に優れたコストパフォーマンスを達成しています。
4) 生産性の改善とビジネス価値の向上
お客様は、Databricksに移行することで、より迅速に行動し、よりコラボレーションし、より効率的に業務を行えるようになります。
- Databricksはアナリスト、データサイエンティスト、データエンジニア間のコラボレーションを制限する技術的障壁を取り除き、データチムがより効率的に作業を進められるようにします。お客様は、手作業のオーバヘッドを取り除くことで、データサイエンティスト、データエンジニア、SQLアナリストにおいて高い生産性を目撃することになります。
- Databricksのお客様は、データエンジニアリング、データサイエンス、BIチームがエンドツーエンドのパイプラインを構築することで、価値創出に至る時間を劇的に加速し、収益を増加させることになります。一方、必要とされるデータ製品を提供するためには、複数サービスを繋ぎ合わせる必要があるクラウドベースのHadoopプラットフォームを用いて同じことを達成することは不可能であったことを理解します。
生産性が向上することで、Databricksは新たなビジネスユースケースの解放やビジネス志向のユースケースからの価値実現の加速や拡大に役立ちます。
最近のForresterの研究、The Total Economic Impact™ (TEI) of the Databricks Unified Data Analytics PlatformではDatabricksをデプロイした企業は3年間で合計約2,900万ドルの経済的利益を実現し、417%のROIを実現していることを明らかにしています。また、彼らはDatabricksプラットフォーム導入の費用は6ヶ月以内に相殺されると結論づけています。
5) データとAIによるイノベーションの促進
Databricksは、データエンジニア、データサイエンティスト、MLエンジニア、SQL & BIアナリストのように、データからビジネス価値を導き出す際に重要なすべてのペルソナに仕立てられた包括的、統合プラットフォームです。皆様のデータチームのすべてのメンバーが、Databricks内でデータ取り込みからスタートし、キュレーション、特徴量エンジニアリング、モデルトレーニング、検証からデプロイメントを含む、エンドツーエンドのパイプラインをクイックに構築することができます。さらに、レイクハウスアーキテクチャを活用することで、データ処理はバッチやストリームの両方で交換可能な形で実装できます。
クラウドベースのHadoopプラットフォームと異なり、Databricksではユーザーにモダンなデータプラットフォーム体験を提供すべくイノベーションを継続しています。以下で、Databricksを使っている人であれば誰でも利用できる特筆すべきプラットフォームの機能をいくつかご紹介します。
任意のクラウドストレージでDeltaを用いたレイクハウスの相互運用性
Delta Lakeはお使いのデータレイクにストリーミングとバッチオペレーションの両方において、信頼性、セキュリティ、パフォーマンスを提供するオープンフォーマットのストレージレイヤーです。データサイロを構造化データ、半構造化データ、非構造化データの単一のホームで置き換えることで、Delta Lakeはコスト効率が高く、高度にスケーラブルなレイクハウスの基盤となります。IcebergやHudiのような他のオープンフォーマットストレージレイヤーと比べて、Delta Lakeは最もパフォーマンスが高く、レイクハウスアーキテクチャで広く利用されているフォーマットです。
Delta Live TablesによるETL開発
Delta Live Tables (DLT)は、データアナリストやデータエンジニアがツールの操作に費やす時間を削減し、データから価値を得ることにフォーカスできるように、大規模かつ信頼できるデータパイプラインを構築するためにシンプルな宣言型アプローチを採用した史上初のETLフレームワークであり、皆様のインフラストラクチャを自動で管理します。DLTを用いることで、エンジニアは自分たちのデータをコードとして取り扱い、大規模に高信頼のパイプラインをデプロイするために、テスト、エラーハンドリング、監視やドキュメントのようなソフトウェアエンジニアリングのベストプラクティスを適用することができます。
Auto Loaderによる簡単かつ自動的なデータ取り込み
最も共通した課題の一つが、クラウドストレージからレイクハウスにデータを定常的かつ自動的に取り込み、処理することです。DatabricksのAuto Loaderは、クラウドストレージからストリーミングモードあるいはバッチモードで、自動データロードをスケーリングすることでデータ取り込みプロセスをシンプルにします。
Databricks SQLを用いてウェアハウスをデータレイクに持ち込む
Databricks SQL (DB SQL)によって、お客様はデータレイクでマルチクラウドのレイクハウスを操作することができ、従来のクラウドデータウェアハウスよりも12倍のコストパフォーマンス、オープンソースのビッグデータフレームワーク、分散クエリーエンジンを提供します。
MLflowで完全な機械学習ライフサイクルを管理
Databricksによって開発されたオープンソースプラットフォームであるMLflowは、エンタープライズの信頼性、セキュリティ、規模での完全なる機械学習ライフサイクルの管理に役立ちます。ある人は、実験トラッキング、モデル管理、モデルデプロイを簡単にできるようになることのメリットを即座に理解します。
AutoMLによる機械学習ライフサイクルの自動化
Databricks AutoMLによって、クイックにベースラインの機械学習モデルとノートブックを生成することができます。MLエキスパートは、自身のドメイン知識を用いたカスタマイゼーションへのフォーカスや通常のトライアンドエラーを通じて前に進めることで、自身のワークフローを加速することができ、シチズンデータサイエンティストはローコードアプローチによって、利用可能な結果をクイックに達成することができます。
レイクハウスで特徴量ストアを構築
DatabricksではDatabricks Feature Storeを用いて、データチームに新規の特徴量を作成し、既存の特徴量の探索、再利用、低レーテンシーのオンライストアへの特徴料の公開、トレーニングデータセットの構築、バッチ推論における特徴料取得の手段を提供します。これは特徴量の集中管理されたリポジトリです。これによって、企業内での特徴量共有と発見を可能にし、モデルトレーニングと推論で同じ特徴量計算sコードが使用されることを保証します。
ワークフローによる高信頼のオーケストレーション
Databricksワークフローは皆様のデータ、分析、AIのニーズに応える完全マネージドのオーケストレーションサービスです。いかなるクラウドでも信頼できるプロダクションワークロードを作成、実行することができ、エンドユーザーにとってのシンプルさを通じたディープかつ集中管理されたモニタリングを実現します。ワークフローによって、ユーザーはデータ取り込み、リネージ、Delta Libe Tablesを活用する自動管理されるETLパイプラインを構築することができます。また、ノートブック、SQL、Spark、MLモデル、dbt、他システムの呼び出しを含むジョブのワークフローを任意の組み合わせでオーケストレーションすることができます。
6) クラウドに依存しないプラットフォーム
マルチクラウド戦略は、データ取り込みからBI、AIに対して統合データ分析を行うためのオープンプラットフォームを必要とする企業において重要なものとなっています。
- 複数クラウドにデータを置くことで、自分たちのクラウドストレージに格納されているデータに依存することになるので、企業は一つのクラウドのネイティブサービスに制限されなくなります。
- 企業は使用しているクラウドに関係なく、自分たちのチームに一貫性のある形で可視性、コントロール、セキュリティ、ガバナンスを提供するマルチクラウドプラットフォームを必要としています。
- Databricksレイクハウスプラットフォームは、オープンスタンダードを使用する統合データプラットフォームを通じて複数のクラウドを活用するお客様を支援します。
クラウド非依存のプラットフォームとして、それぞれのクラウドストレージにある既存データレイクを活用しつつも、任意のクラウドプラットフォームで同じようにDatabricksのワークロードは実行されます。ユーザーとして、Databricksにワークロードを移行すると、任意のクラウドにおいて同じオープンソースコードを交換可能な形で活用することができます。これによって、クラウドネイティブのHadoopプラットフォームにロックインされるリスクを軽減します。
7) Databricksパートナーエコシステムのメリット
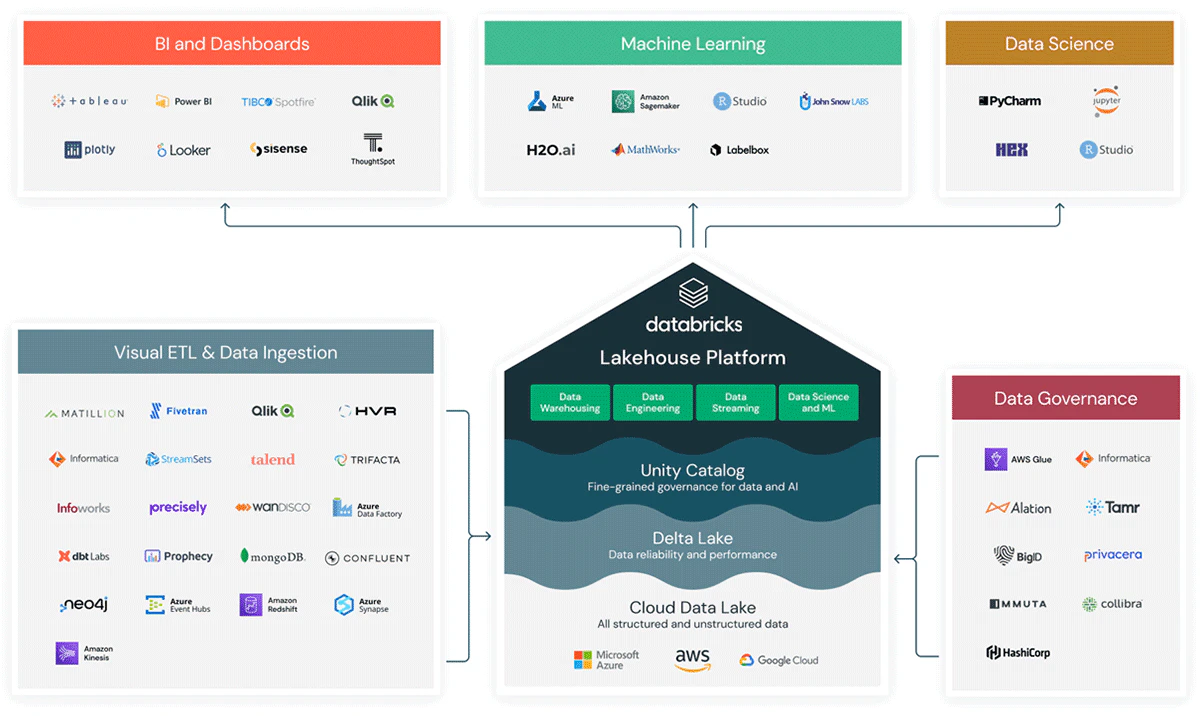
Databricksはモダンデータスタックにおける重要なパーツとなっており、より情報提供された意思決定を迅速に行うために、データ資産を実用に供する企業やデジタルネイティブを実現しています。データ取り込み、データパイプラインの構築、データガバナンス、データサイエンスや機械学習からBI/ダッシュボードに至るデータジャーニーの様々なフェーズにおいてシームレスにこれを実現するリッチなパートナーエコシステム(グローバルで450以上のパートナー)が存在しています。
Databricks内にあるPartner Connectによって、dbt、Fivetran、Tableau、Labelboxのような人気のデータプラットフォームとお使いのレイクハウスをインテグレーションすることができ、構築済みのインテグレーションによって数クリックでセットアップできます。
クラウドベースのHadoopプラットフォームと異なり、Databricksでは数クリックでエンドツーエンドのパイプラインを構築し、レイクハウスの能力を急速に拡張することができます。Databricksのテクノロジーパートナーの詳細については、https://www.databricks.com/jp/company/partners/technology をご覧ください。
次のステップ
あるプラットフォームから別のプラットフォームへの移行を決断することは簡単ではありません。現行のアーキテクチャの評価、課題やペインポイントのレビュー、新たなプラットフォームの適合性や持続可能性を検証する必要があります。しかし、企業は常に自分たちのデータでより多くのことを行い、インフラストラクチャの維持や管理工数を削減しつつも、革新的な技術でより多くの分析やAIを可能にするようにデータチームを支援したいと考えています。これらを短期的、長期的ゴールで達成するには、お客様はレガシーなオンプレミス、あるいはクラウドベースのHadoopソリューションの先をいくソリューションを必要としています。この記事の7つの理由を探索し、これらが皆様のビジネスにどのように価値をもたらすのかをご覧ください。
ebookのダウンロード