Claims Automation on Databricks Lakehouse | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
取り込み、分析、意思決定における請求処理の全ての側面を自動化することで、スマートクレームが効率性を改善
イントロダクション
グローバルコンサルタントのEYの最新のレポートによれば、保険の未来は徐々にデータドリブンかつ分析が活用されるようになるとのことです。クラウドに対する最近のフォーカスによって、高度な技術的なインフラストラクチャへのアクセスは改善されましたが、多くの組織ではそれらの能力を実装、活用するために依然として助けを必要としています。価値を実現するためのサービスの本格運用化に向けてフォーカスをシフトする時です。
現在の経済状況において、保険企業は増加し続ける様々な課題に直面しています。保険会社は、加速したペースにおいて、彼らの優勢を推し進め、革新をもたらすためにデータを活用することを強いられています。
個人向けP&C保険会社においては、これはパーソナライゼーションと顧客維持へのフォーカスを高めることを意味します。ブランドへのロイヤルティが常に低く、競合からの購入率が継続的に高い場合、解約のリスクが増加します。不正なクレームの増加は、収益のマージンを侵食します。保険会社はコストを削減し、よりリスクを管理できるようにするための新た方法を見つけ出す必要があります。
クレーム対応プロセスの自動化と最適化は、時間短縮と人間資本への依存の削減を通じて、コストを劇的に削減できる領域の一つです。さらに、データや高度な分析からの洞察を効果的に活用することで、リスクにさらされる可能性を劇的に削減することができます。
この'スマートクレーム'のソリューションアクセラレータのモチベーションはシンプルです - レイクハウスを用いて、迅速な決着、処理コストの削減、潜在的な不正クレームに関する洞察のクイックな提供を可能にすることでクレーム対応を改善することです。レイクハウスパラダイムを実装することで、現行のアーキテクチャのランドスケープをシンプルにし、組織におけるさらなる拡張に向けたシーンをセットします。添付のアセットはこちらにあります。
リファレンスアーキテクチャとワークフロー
典型的なクレームワークフローには、ガイドワイヤーのようなオペレーショナルシステムとDatabricksのような分析システム間のいくつかのレベルのオーケストレーションが関与します。以下の図では、自動車保険会社のそのようなワークフローの例を示しています。
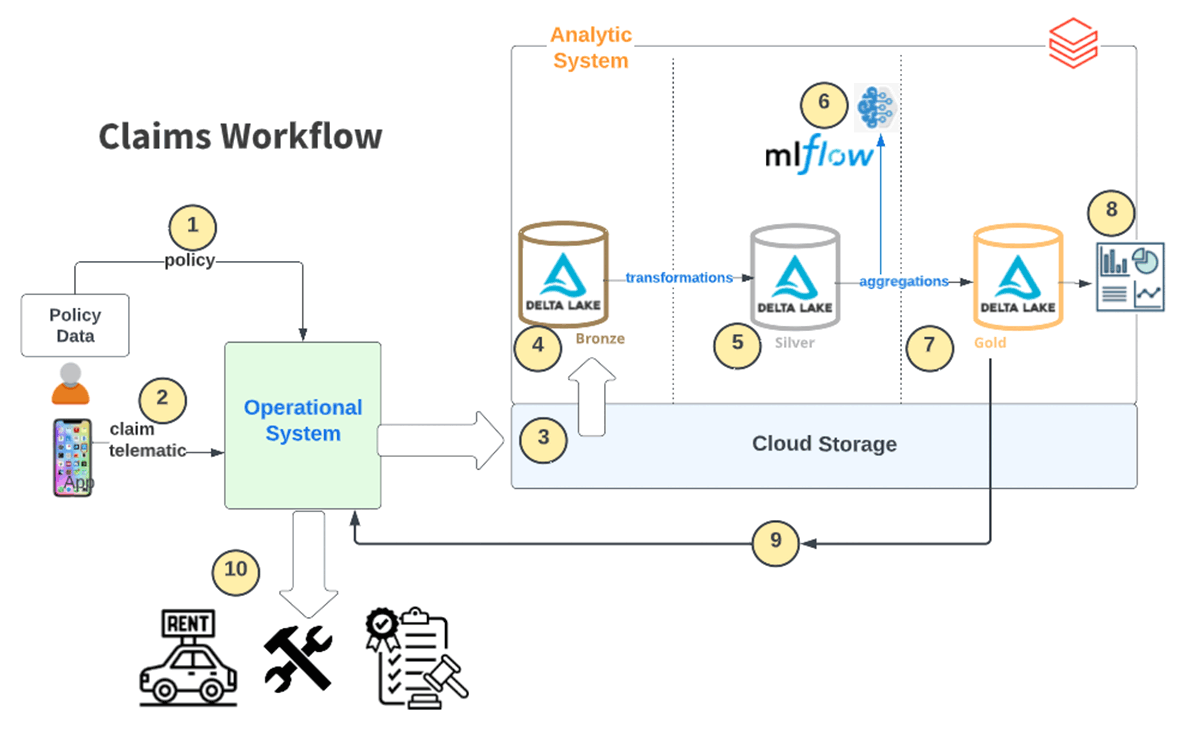
図1. スマートクレームのリファレンスアーキテクチャとワークフロー
クレーム対応プロセスの自動化と最適化には、オペレーショナルシステムと顧客のインタラクションと、分析で利用できる様々な情報ソースに対する深い理解が必要となります。
この例では、モバイルアプリを通じた顧客の主要なやり取りを想定し、そこから彼らはクレームを送信し、既存ケースのステータスを監視します。このタッチポイントは、顧客の挙動の重要な情報を提供します。別の重要な情報ソースは顧客の自動車にインストールされているIoTデバイスです。テレマティクスデータは、オペレーショナルシステム、分析システムにストリーミングすることができ、顧客の運転挙動やパターンに対する重要な洞察を提供します。その他の外部データソースには、自動車の特性(メーカー、モデル、年度)、運転手の特性やエクスポージャー/カバレッジ(制限、自己負担学)のような従来のデータカテゴリを補完する気象や道路のコンディションデータが含まれることがあります。
追加のデータソースへのアクセスは、クレジット会社のような従来のソースからのデータが存在しない場合には特に重要になってきています。クレジット会社からのクレジットのスコアは通常、リスクモデリングの基礎を形成し、最終的には保険料にインパクトを与える運転手のエクスポージャーを評価します。一方で、モバイルアプリやIoTデバイスからのデータは、特定のグループに関連づけられるリスクの正確なインジケーターを作成するために活用できる、顧客の挙動に対するよりパーソナライズされたビューを提供します。このリスクのモデリングとプライシングにおいて代替となる挙動ベースのアプローチは、特にパーソナライズされた顧客体験を提供する際には重要になります。
Databricksによるレイクハウスは、将来にわたって保障されるクレーム対応プロセスをサポートするために必要なすべての機能やサービスを組み合わせる唯一のプラットフォームです。ストリーミングから機械学習、レポートに至るまで、Databricksでは未来の保険業界におけるエンドツーエンドのソリューションを構築するためのベストなプラットフォームを提供します。
以下のステップでは、全体的なフローをカバーしています:
- ポリシーデータの取り込み
- IoTセンサーから継続的にテレマティクスデータを取り込み。モバイルアプリを通じてクレームデータを送信。
- すべてのオペレーショナルデータがクラウドストレージに取り込まれる。
- これは、Deltaのブロンズテーブルに'生データ'としてインクリメンタルにロードされる。
- 様々なデータ変換処理を通じて、データは操作、洗練される。
- トレーニングしたモデルを用いてデータはスコアリングされる。
- ゴールドテーブルに予測結果がロードされる。
- 可視化のためのクレームダッシュボードがリフレッシュされる。
- 結果として得られる洞察がオペレーショナルシステムにフィードバックされる。これによって、どのクレームを優先度づけすべきかを知るために、リアルタイムでガイドワイヤーからデータを取得し、ガイドワイヤーに'ネクストベストアクション'を引き渡すフィードバックループを形成する。
- クレーム決定ワークフローでは、ケースを適切にルーティングするために、これら生成された洞察を活用する。(例: 修理費用の承認、レンタルの払い戻し、関係者へのアラートなど)
レイクハウスのパラダイムがどのようにスマートクレームを支援するのか
Databricksレイクハウスアーキテクチャによって、すべてのデータペルソナ(データエンジニア、データサイエンティスト、分析エンジニア、BIアナリスト)が単一のプラットフォームでコラボレーションできるようになります。単一かつコラボレーティブなプラットフォームで、すべてのビッグデータワークロードやパラダイムをサポートすることで、全体的なアーキテクチャを劇的にシンプルにし、安定性を改善し、コストを劇的に削減します。
DatabricksのDelta Live Tables(DLT)パイプラインは、ワークロードをクイックに開発、実装するためのシンプルで宣言型のフレームワークを提供します。また、アウトプットの一貫性をh賞するためのきめ細かい制約を持つデータ品質管理のネイティブサポートを提供します。
再現可能性と監査可能性のために、MLflowを用いることで、MLやAIのワークロードをように作成、管理することができます。MLflowは、実験からモデルのデプロイメント、サービング、アーカイブを通じて、モデルライフサイクル全体をシンプルにします。テキスト以外の非構造化データ(画像、音声、動画など)を含むいかなるタイプのデータでMLを実行することができます。このソリューションでは、自動車のダメージを評価するためにコンピュータービジョンの機能を活用します。
最後に、Databricks SQLは、キュレーションされ集約されたデータに対してクエリーするための高速かつ効率的なエンジンを提供します。これらの洞察は、数分でインタラクティブダッシュボードにパッケージ、提供されます。
Unity Catalogは、ファイル、テーブル、機械学習モデル、ダッシュボードに対するビルトインの検索、ディスカバリー、自動化されたワークロードリネージを用いたデータやAI全てに対する、マルチクラウド、集中管理されたガバナンスソリューションを提供します。
以下の図では、典型的な保険のユースケースの文脈における、レイクハウスのリファレンスアーキテクチャを示しています:

図2: 保険リファレンスアーキテクチャ
DLTとマルチタスクワークフローを用いたデータの取り込み
クレーム対応プロセスの自動化は、取り込みとデータエンジニアリングワークフローの最適化からスタートします。以下の図では、構造化、半構造化、非構造化データを含む典型的なデータソースのサマリーを示しています。いくつかのソースは、ゆっくりと移動しますが、他のものはより高速に更新されます。さらに、いくつかのソースは追加的である場合があり、その場合には追加処理が必要となりますが、他のものはインクリメンタルな更新処理であり、その場合にはslow changing dimensionsとして取り扱わなくてはなりません。

図3: クレーム処理で使用するサンプルデータセット
DLTは、データ処理パイプラインをシンプルにし、本格運用します。このフレームワークでは、ストリーミングソースからの取り込みを促進するAuto Loader、データボリュームの突然の変化に対応するオートスケーリング、タスク失敗時の再起動による回復性をサポートしています。
Databricksワークフローは、複数のタスクやワークロード(ノートブック、DLT、ML、SQLなど)を保持します。ワークフローでは、リペア&ランやタスク間での計算資源の共有をサポートしており、堅牢、スケーラブル、コスト効率性の高いワークロードを実現します。さらに、ワークフローは、スケジュールやREST APIを通じたプログラムによって容易に自動化することができます。
MLおよびダイナミックルールエンジンを用いた洞察の生成
これまでに明らかになっていなかったパターンの発見、新たな洞察のハイライト、疑いのある活動の特定においては、MLの活用が重要となります。しかし、MLと従来のルールベースのアプローチを組み合わせることで、さらにパワフルなものとなります。
クレーム対応プロセスにおいては、いくつかのユースケースでMLを活用することができます。一つの例は、自動車保険のクレームで送信された画像の評価とスコアリングにおけるコンピュータービジョンの活用と言えます。ダメージの妥当性と深刻度にフォーカスするようにモデルをトレーニングすることができます。ここでは、エンドツーエンドのMLOps機能を提供することで、モデルトレーニングとモデルサービングのプロセスをシンプルにするMLflowが重要となります。MLflowでは、REST APIを通じたサーバレスモデルサービングを提供します。トレーニングしたモデルは、数クリックで本格運用に投入することができます。
一方、ルールエンジンは、人間のインタラクションを必要とすることなしに自動化、適用できる既知のオペレーション上の特性や統計的なチェックを定義するための柔軟な手段を提供します。データが事前に定義された期待値に合致しない場合には、フラグが立てられ人間のレビューや調査に転送されます。このようなアプローチとMLベースのワークフローを組み合わせることで、さらなる洞察を導き出し、フラグが立てられたケースを分析、レビューするのにクレーム調査官が必要とする時間を劇的に削減します。
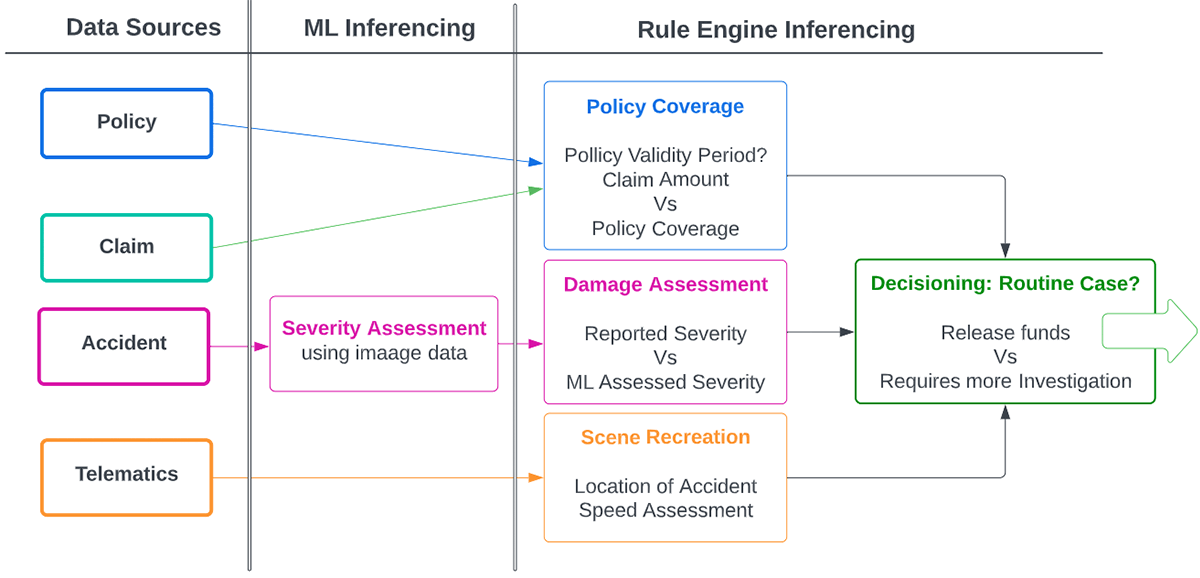
図4: MLとルールエンジンの推論
ダッシュボードを用いた洞察の可視化
この例では、重要なビジネス洞察を捕捉するために2つのダッシュボードを作成しました。ダッシュボードには以下が含まれます:
- 全体的なビジネスオペレーションに対するハイレベルなビューのためのLoss Summaryダッシュボード。
- 特定のケースの詳細を理解するためのクレームの詳細に対する高精細なビューを持つClaims Investigationダッシュボード。
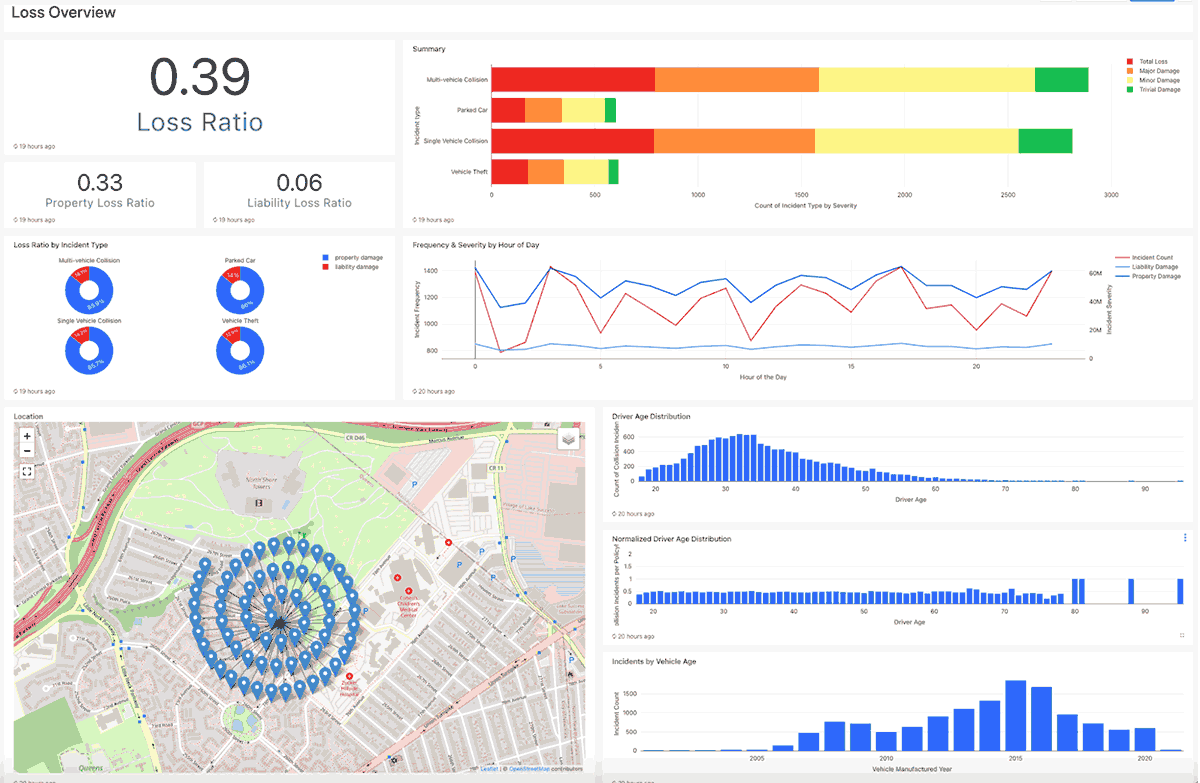
図5: Loss Summaryダッシュボード
最近のトレンドを分析することで、以下のような類似ケースのレビューに役立ちます:
- 保険のクレームの支払い+調整費用を合計取得保険料で割ることでLoss Ratioが計算されます。例えば、個人自動車の典型的な平均Loss Ratio(身体の怪我、物理ダメージの全てをカバー)はおおよそ65%であるべきです。
- サマリーのビジュアライゼーションは、ダメージの深刻度ごとの自己タイプの数をキャプチャします。
- 様々な特徴量/次元に対するトレンドライン
- ポリシーの地理的分布
Claims Investigationダッシュボードは、クレームに関するすべての適切な情報を提供することで、迅速な調査を促進し、人間の調査官はダメージを受けた自動車の画像、クレーム、ポリシー、運転手の詳細のような情報を確認するために、特定のクレームをドリルダウンし、テレマティックデータは自動車の経路を描画し、レポートされたデータは評価されたデータ洞察と対比されます。
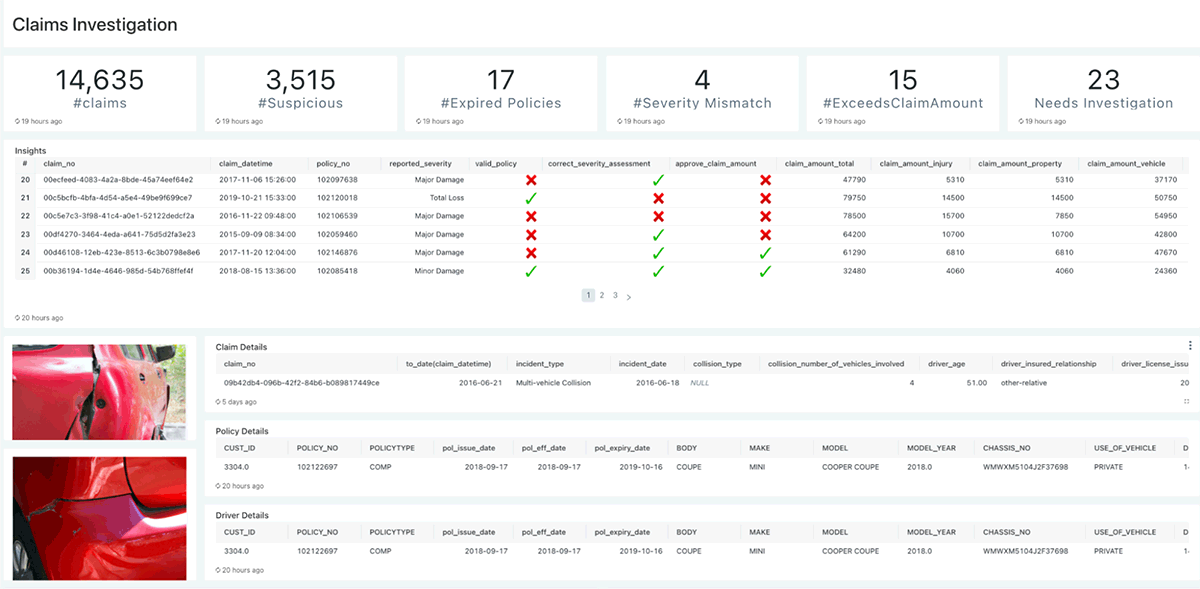
図6: Claims Investigationダッシュボード
ML推論とルールエンジンを用いたパイプラインで自動でスコアリングされた最近のクレームを表示します。
- 緑のチェックマークは、自動評価結果とクレームの記述が一致していることを示しています。
- 赤いバツは、さらなる手動での調査を必要とするミスマッチがあることを示しています。
まとめ
保険会社が競合に対する差別化要因を得るためには、イノベーションとパーソナライゼーションが重要となっています。このDatabricksレイクハウスは、保険会社がイノベーションを実現し、加速するために、サードパーティのツールやサービスと容易に連携できるオープン、セキュアかつ拡張可能なアーキテクチャを持つプラットフォーム提供します。このソリューションアクセラレータでは、このパラダイムをどのようにクレーム対応に適用できるのかをデモンストレーションしました。さらに、Databricksのエコシステムは、データチームやビジネスステークホルダーがコラボレーションし、ビジネスの意思決定をサポートし、ボトムライに対して具体的な価値をドライブする洞察を生成、共有できるようにする幅広い機能を提供します。
このサンプルで使用されるパイプライン設定、モデル、サンプルデータを含む記述的なアセットは、こちら、あるいは直接Gitからアクセスできます。