こちらのソリューションアクセラレータがさらに進化してました。
Hugging faceのモデルの活用、SHAPによる推論結果の説明が追加されていました。
翻訳しながらウォークスルーします。
注意
05-torch-lightning-training-and-inferenceは割愛します。
はじめに必要なノートブックをインストールします。
%pip install dbdemos
%restart_python
import dbdemos
dbdemos.install('computer-vision-pcb')

config
使用するカタログやスキーマを指定します。
catalog = "takaakiyayoi_catalog"
dbName = db = "dbdemos_computer_vision_dl"
volume_name = "pcb_training_data"
00-introduction-deep-learning-vision
全体の流れを説明しているノートブックです。
コンピュータビジョン - PCBの品質検査

このデモでは、Databricksがどのようにしてプリント基板(PCB)の品質を検査するためのエンドツーエンドのコンピュータビジョンモデルを構築するのに役立つかを示します。
Visual Anomaly (VisA) 検出データセットを使用し、PCB画像の異常を検出するパイプラインを構築します。
コンピュータビジョンは、近年、大量のデータ、強力なGPU、事前学習済みのディープラーニングモデル、転移学習、および高レベルのフレームワークの利用可能性のおかげで急速に進歩している研究分野です。しかし、コンピュータビジョンモデルのトレーニングと提供は、さまざまな課題のために非常に困難です:
- スケールでのデータの取り込みと前処理
- トレーニングに複数のGPUを必要とするデータ量
- エンドツーエンドのモデルライフサイクルのためのガバナンスと生産準備が整ったMLOpsパイプライン
- ストリーミングまたはリアルタイム推論のための厳しいSLA
Databricks Lakehouseは、この全体のプロセスを簡単にするように設計されており、データサイエンティストがコアユースケースに集中できるようにします。
ディープラーニングパイプラインの実装
このモデルを構築し、これらの課題を簡単に解決するために、次のステップを実装します:
- Autoloader を使用して、画像を増分的にロードし、Delta Lake形式に処理する取り込みパイプライン。
- Spark Datasetを使用して、Hugging Face Transformers でMLモデルを構築。
- PandasUDFとDatabricks Model Serving を使用して、バッチまたはリアルタイムで推論を実行。
- 高度な内容:分散トレーニングのための Spark Torch Distributor を使用した完全なTorchバージョン。
データフロー

1/ 取り込みとETL

最初のステップは画像を取り込むことです。Databricks Autoloaderを活用して、画像とラベル(csvファイル)を取り込みます。
データはDelta Tableとして保存され、Databricks Unity Catalogで簡単にガバナンスできます。
また、画像サイズを縮小し、モデルトレーニングのためのデータセットを準備するための初期変換も適用します。
2/ huggingface transformerを使用したモデルの構築

データの準備が整ったので、huggingface transformerライブラリを活用し、既存の最先端モデルをファインチューニングできます。
これは、pytorchの詳細に踏み込むことなく、迅速に結果を出すための非常に効率的なアプローチです。
3/ バッチ推論の実行とリアルタイムサーバーレスモデルエンドポイントのデプロイ

モデルが作成され、MLFlowレジストリで利用可能になったので、これを使用できるようになります。
典型的なサービングユースケースには以下が含まれます:
- バッチおよびストリーミングユースケース(Delta Live Tableを含む)
- Databricksサーバーレスエンドポイントを使用したリアルタイムモデルサービング
4/ モデル予測の説明と損傷したPCBピクセルのハイライト

各画像の推論とスコアを得ることは素晴らしいことですが、手動での確認や修正のために、オペレーターはどの部分が損傷と見なされているかを知る必要があります。
モデル予測に最も影響を与えるピクセルをハイライトするために、SHAPをエクスプレイナーとして使用します。
結論
レイクハウスがどのようにしてあなたのMLおよびディープラーニングの課題を解決するのに適しているかを説明しました:
- データの取り込みと変換をスケールで加速
- モデルのトレーニングとガバナンスを簡素化
- バッチからリアルタイム推論まで、すべてのユースケースに対応するワンクリックモデルデプロイメント
01-ingestion-and-ETL: PCB - データパイプラインの取り込み
データを取り込んでテーブルに永続化します。
使用したクラスター: MLランタイムが稼働しているシングルノードクラスター
これは私たちが構築するパイプラインです。2つのデータセットを取り込みます。具体的には:
- PCBを含む生の画像(jpg)
- CSVファイルとして保存された異常の種類のラベル
まず、このデータを段階的にロードし、最終的なゴールドテーブルを作成するデータパイプラインの構築に焦点を当てます。
このテーブルは、リアルタイムで画像の異常を検出するML分類モデルをトレーニングするために使用されます!
%pip install databricks-sdk==0.39.0 mlflow==2.20.2
dbutils.library.restartPython()
%run ./_resources/00-init $reset_all_data=false
print(f"Training data has been installed in the volume {volume_folder}")
Training data has been installed in the volume /Volumes/takaakiyayoi_catalog/dbdemos_computer_vision_dl/pcb_training_data
ボリュームに画像が保存されます。
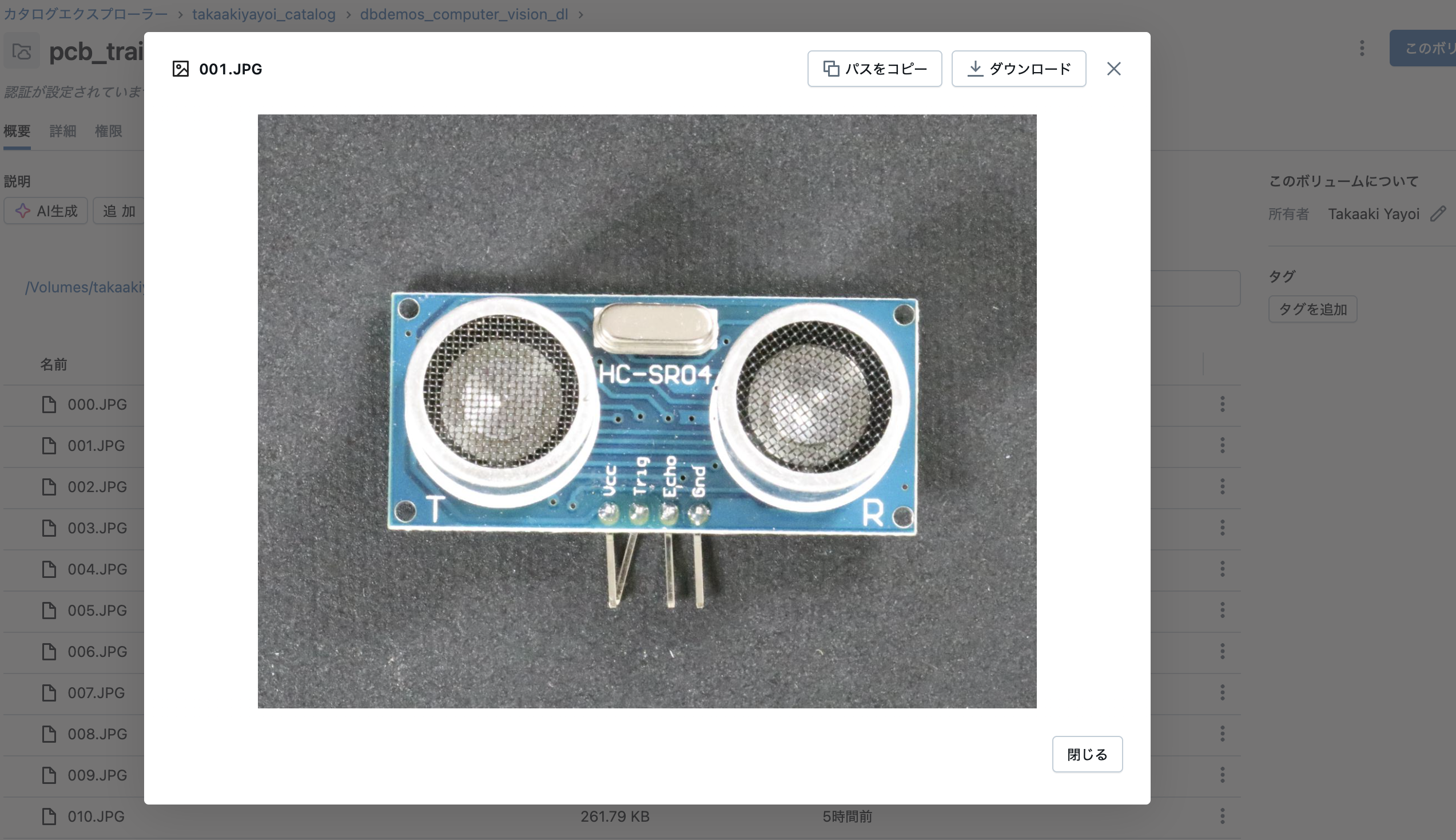
データセットのレビュー
データセットは自動的にダウンロードされ、クラウドのdbfsストレージフォルダに保存されています。データを探索してみましょう:
display(dbutils.fs.ls(f"{volume_folder}/images/Normal/"))
display(dbutils.fs.ls(f"{volume_folder}/labels/"))
display(dbutils.fs.head(f"{volume_folder}/labels/image_anno.csv"))
PCB画像の検査
matplotlibを使用して、ネイティブなPythonの方法で画像を表示できます。
正常な画像と異常のある画像を調査してみましょう。
from PIL import Image
import matplotlib.pyplot as plt
def display_image(path, dpi=300):
img = Image.open(path)
width, height = img.size
plt.figure(figsize=(width / dpi, height / dpi))
plt.imshow(img, interpolation="nearest", aspect="auto")
display_image(f"{volume_folder}/images/Normal/0000.JPG")
display_image(f"{volume_folder}/images/Anomaly/000.JPG")

Databricks Autoloaderを使用した生画像の取り込み

最初のステップは、個々のJPG画像をロードすることです。これは、特に増分ロード(新しいものだけを消費する)では、スケールで非常に困難です。
Databricks Autoloaderは、すべての形式のデータを簡単に処理し、新しいデータセットの取り込みを非常に簡単にします。
Autoloaderは、数百万の個々の画像をスケーリングしながら、新しいファイルのみが処理されることを保証します。
Auto Loaderを使用したバイナリファイルのロード
Autoloaderを使用して画像をロードし、Spark関数を使用してラベル列を作成できます。Autoloaderは自動的にテーブルを作成し、バイナリの圧縮を無効にするなど、適切に調整します。
また、画像とラベルの内容をテーブルとして非常に簡単に表示することもできます。
(spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "binaryFile")
.option("pathGlobFilter", "*.JPG")
.option("recursiveFileLookup", "true")
.option("cloudFiles.schemaLocation", f"{volume_folder}/stream/pcb_schema")
.option("cloudFiles.maxFilesPerTrigger", 200)
.load(f"{volume_folder}/images/")
.withColumn("filename", F.substring_index(col("path"), "/", -1))
.writeStream.trigger(availableNow=True)
.option("checkpointLocation", f"{volume_folder}/stream/pcb_checkpoint")
.toTable("pcb_images").awaitTermination())
spark.sql("ALTER TABLE pcb_images OWNER TO `account users`")
display(spark.table("pcb_images"))

Auto Loaderを使用したCSVラベルファイルのロード
CSVファイルは、スキーマ推論と進化を含め、DatabricksのAuto Loaderを使用して簡単にロードできます。
(spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "csv")
.option("header", True)
.option("cloudFiles.schemaLocation", f"{volume_folder}/stream/labels_schema")
.load(f"{volume_folder}/labels/")
.withColumn("filename", F.substring_index(col("image"), "/", -1))
.select("filename", "label")
.withColumnRenamed("label", "labelDetail")
.writeStream.trigger(availableNow=True)
.option("checkpointLocation", f"{volume_folder}/stream/labels_checkpoint")
.toTable("pcb_labels").awaitTermination())
spark.sql("ALTER TABLE pcb_labels SET OWNER TO `account users`")
display(spark.table("pcb_labels"))

ラベルと画像テーブルをマージしましょう

インジェストを簡単にするために、デルタテーブルを使用しています。
個々の小さな画像について心配する必要はもうありません。
結合操作はPythonまたはSQLで行うことができます。
%sql
CREATE OR REPLACE TABLE training_dataset AS
(SELECT
*,
CASE WHEN labelDetail = 'normal' THEN 'normal' ELSE 'damaged' END as label
FROM
pcb_images
INNER JOIN pcb_labels USING (filename)
);
ALTER TABLE training_dataset SET OWNER TO `account users`;
SELECT * FROM training_dataset LIMIT 10;
最終ステップ: DLファインチューニングのための画像データセットの準備と拡張

テーブルを使用して作業していることに注意してください。これらの変換はPythonまたはSQLで行うことができます。
画像の変換には高コストなものもあります。Sparkを活用して、まずいくつかの画像前処理を分散させることができます。
この例では、以下のことを行います:
- 画像を中央でクロップして正方形にする(ファインチューニングに使用するモデルは正方形の画像を使用します)
- 画像を小さな解像度(256x256)にリサイズする(モデルは高解像度の画像を使用しません)
また、データセットを拡張して「損傷した」アイテムを増やします。ここではかなり不均衡な状態(10個中1個しか異常がない)です。
システムは上下逆さまのPCB画像を好みなく撮影しているようですので、推論もそのようになります。損傷したすべての画像を水平に反転させ、それらをデータセットに追加しましょう。
画像のクロップとリサイズ
from PIL import Image
import io
from pyspark.sql.functions import pandas_udf
IMAGE_RESIZE = 256
# 画像サイズ変更のUDF関数
@pandas_udf("binary")
def resize_image_udf(content_series):
def resize_image(content):
"""画像のサイズを変更し、jpegとしてシリアライズ"""
# PIL画像を読み込む
image = Image.open(io.BytesIO(content))
width, height = image.size # サイズを取得
new_size = min(width, height)
# 画像の中心をクロップ
image = image.crop(((width - new_size)/2, (height - new_size)/2, (width + new_size)/2, (height + new_size)/2))
# 新しい解像度にリサイズ
image = image.resize((IMAGE_RESIZE, IMAGE_RESIZE), Image.NEAREST)
# jpegとして保存
output = io.BytesIO()
image.save(output, format='JPEG')
return output.getvalue()
return content_series.apply(resize_image)
# 画像プレビューを有効にするためのメタデータを追加
image_meta = {"spark.contentAnnotation" : '{"mimeType": "image/jpeg"}'}
(spark.table("training_dataset")
.withColumn("sort", F.rand()).orderBy("sort").drop('sort') # データフレームをシャッフル
.withColumn("content", resize_image_udf(col("content")).alias("content", metadata=image_meta))
.write.mode('overwrite').saveAsTable("training_dataset_augmented"))
spark.sql("ALTER TABLE training_dataset_augmented OWNER TO `account users`")
反転や破損している画像の追加
import PIL
@pandas_udf("binary")
def flip_image_horizontal_udf(content_series):
def flip_image(content):
"""画像をリサイズし、jpegとしてシリアライズ"""
# PIL画像を読み込む
image = Image.open(io.BytesIO(content))
# 画像を反転
image = image.transpose(PIL.Image.FLIP_TOP_BOTTOM)
# jpegとして保存
output = io.BytesIO()
image.save(output, format='JPEG')
return output.getvalue()
return content_series.apply(flip_image)
(spark.table("training_dataset_augmented")
.filter("label == 'damaged'")
.withColumn("content", flip_image_horizontal_udf(col("content")).alias("content", metadata=image_meta))
.write.mode('append').saveAsTable("training_dataset_augmented"))
最終的なデータセットには20%のダメージ画像があります
%sql
SELECT
label,
count(*)
FROM
training_dataset_augmented
GROUP BY
label
| label | count(1) |
|---|---|
| normal | 1004 |
| damaged | 200 |
データサイエンスチームのためのデータセットが準備できました
これで完了です!本番環境に対応したインジェストパイプラインをデプロイしました。
画像は増分的にインジェストされ、ラベルデータセットと結合されます。
このデータを使用してデータサイエンティストがどのようにコンピュータビジョンモデルを構築するかを見てみましょう。
ここまでで作成されたテーブルのリネージは以下のようになっています。

02-huggingface-model-training: Hugging faceを使用したコンピュータビジョンモデルの構築

次のステップとして、データサイエンティストは画像セグメンテーションを実行するためのMLモデルを実装します。
前のデータパイプラインで構築したゴールドテーブルをトレーニングデータセットとして再利用します。
このようなモデルの構築は、huggingface transformerライブラリを使用することで大幅に簡素化されます。
MLOpsのステップ
画像セグメンテーションモデルの構築は簡単に行えますが、そのようなモデルを本番環境にデプロイするのははるかに難しいです。
Databricksはこのプロセスを簡素化し、MLFlowの助けを借りてデータサイエンスの旅を加速させます。
- 自動実験とトラッキング
- 最適なモデルを得るためのhyperoptを使用したシンプルで分散型のハイパーパラメータチューニング
- MLFlowでのモデルパッケージング、MLフレームワークの抽象化
- ガバナンスのためのモデルレジストリ
- バッチまたはリアルタイムのサービング(ワンクリックデプロイ)
使ったクラスター: サーバレス(CPU)
注意
- 私が動作確認した際、GPUクラスターではセル14で
ProcessGroupGloo::allgather: invalid tensor size at index 0 (expected (1, 2), got (2))というエラーに遭遇しました。
%pip install databricks-sdk==0.39.0 datasets==2.20.0 transformers==4.49.0 tf-keras==2.17.0 accelerate==1.4.0 mlflow==2.20.2 torchvision==0.20.1 deepspeed==0.14.4 evaluate==0.4.3
dbutils.library.restartPython()
デモの初期化
%run ./_resources/00-init $reset_all_data=false
トレーニングデータセットの確認
# トレーニング実験のセットアップ
DBDemos.init_experiment_for_batch("computer-vision-dl", "pcb")
df = spark.read.table("training_dataset_augmented")
display(df.limit(10))
Deltaテーブルからデータセットを作成
Hugging Faceはこのステップを非常に簡単にします。Dataset.from_spark関数を呼び出すだけです。
新しいDelta Loaderの詳細については、ブログ投稿を参照してください。
Sparkデータフレーム(Deltaテーブル)からtransformerデータセットの作成
from datasets import Dataset
# 注意: from_sparkのサポートはサーバーレスコンピュートで提供予定 - この小さなデモではfrom_pandasを使用します
# dataset = Dataset.from_spark(df), cache_dir="/tmp/hf_cache/train").rename_column("content", "image")
dataset = Dataset.from_pandas(df.toPandas()).rename_column("content", "image")
splits = dataset.train_test_split(test_size=0.2, seed = 42)
train_ds = splits['train']
val_ds = splits['test']
Hugging faceを使用した転移学習
転移学習は、他のタスクのために何千もの画像でトレーニングされた既存のモデルを使用し、その知識を私たちのドメインに転移するプロセスです。Hugging Faceは、転移学習を非常に簡単に実装するためのヘルパークラスを提供しています。
一般的なプロセスは、カスタムデータセットを使用してモデルまたはモデルの一部(通常は最後の層)を再トレーニングすることです。
これにより、トレーニングコストと効率の間で最適なトレードオフが得られます。特にトレーニングデータセットが限られている場合に有効です。
ベースモデルの定義
import torch
from transformers import AutoFeatureExtractor, AutoImageProcessor
# ファインチューニングするための事前学習済みモデル
# 詳細および他のモデルについてはhugging faceのリポジトリを参照: https://huggingface.co/google/vit-base-patch16-224
model_checkpoint = "google/vit-base-patch16-224"
# GPUの利用可能性を確認
if not torch.cuda.is_available(): # GPUが利用可能か
# CPUデモ用に小さなモデルを使用
model_checkpoint = "WinKawaks/vit-tiny-patch16-224"
print("モデルのトレーニングにはGPUクラスタを使用してください。CPUインスタンスでは遅すぎます。サーバーレス環境では、環境タブを開いてGPUを選択してください(プレビューが必要な場合があります)。")
トレーニング & 検証のための画像変換処理の定義
from PIL import Image
import io
from torchvision.transforms import CenterCrop, Compose, Normalize, RandomResizedCrop, Resize, ToTensor, Lambda
# モデルの特徴を抽出(データを変換するために必要な前処理ステップの情報を含む、リサイズや正規化など)
# モデルのパラメータを使用することで、入力サイズが異なっても変更なしで別のモデルに切り替えることが容易になります。
model_def = AutoFeatureExtractor.from_pretrained(model_checkpoint)
normalize = Normalize(mean=model_def.image_mean, std=model_def.image_std)
byte_to_pil = Lambda(lambda b: Image.open(io.BytesIO(b)).convert("RGB"))
# トレーニングデータセットに対する変換。ここでクロップを追加します
train_transforms = Compose([byte_to_pil,
RandomResizedCrop((model_def.size['height'], model_def.size['width'])),
ToTensor(), # PIL画像をテンソルに変換
normalize
])
# 検証用変換、画像を期待されるサイズにリサイズするだけです
val_transforms = Compose([byte_to_pil,
Resize((model_def.size['height'], model_def.size['width'])),
ToTensor(), # PIL画像をテンソルに変換
normalize
])
# トレーニングデータセットにランダムなリサイズと変換を追加
def preprocess_train(batch):
"""バッチ全体にtrain_transformsを適用します。"""
batch["image"] = [train_transforms(image) for image in batch["image"]]
return batch
# 検証データセット
def preprocess_val(batch):
"""バッチ全体にval_transformsを適用します。"""
batch["image"] = [val_transforms(image) for image in batch["image"]]
return batch
# トレーニング/検証変換を設定
train_ds.set_transform(preprocess_train)
val_ds.set_transform(preprocess_val)
事前学習済みモデルからモデルを構築
from transformers import AutoModelForImageClassification, TrainingArguments, Trainer
# クラスラベルと値のマッピング(推論時に適切なラベルを出力するためにhuggingfaceが使用)
label2id, id2label = dict(), dict()
for i, label in enumerate(set(dataset['label'])):
label2id[label] = i
id2label[i] = label
model = AutoModelForImageClassification.from_pretrained(
model_checkpoint,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes = True # すでにファインチューニングされたチェックポイントをさらにファインチューニングする場合にこれを提供
)
モデルのファインチューニング
データセットとモデルの準備が整いました。これで、モデルをファインチューニングするためのトレーニングステップを開始できます。
本番環境向けのユースケースでは、通常ここでハイパーパラメータの調整を行います。この最初の例では、設定を固定してシンプルに実行します。
パラメーターのトレーニング
model_name = model_checkpoint.split("/")[-1]
batch_size = 32 # トレーニングと評価のためのバッチサイズ
args = TrainingArguments(
f"/tmp/huggingface/pcb/{model_name}-finetuned-leaf",
remove_unused_columns=False,
evaluation_strategy="epoch", # 各エポックごとに評価を行う
save_strategy="epoch", # 各エポックごとにモデルを保存する
learning_rate=5e-5, # 学習率
per_device_train_batch_size=batch_size, # デバイスごとのトレーニングバッチサイズ
gradient_accumulation_steps=1, # 勾配の蓄積ステップ数
per_device_eval_batch_size=batch_size, # デバイスごとの評価バッチサイズ
no_cuda=not torch.cuda.is_available(), # ResNetをCPUで実行するための設定
num_train_epochs=20, # トレーニングエポック数
warmup_ratio=0.1, # ウォームアップ比率
logging_steps=10, # ログを記録するステップ数
load_best_model_at_end=True, # 最後に最良のモデルを読み込む
metric_for_best_model="f1", # 最良モデルの評価指標
push_to_hub=False # モデルをHubにプッシュしない
)
評価メトリックの定義
import numpy as np
import evaluate
# compute_metrics関数はNamed Tupleを入力として受け取ります:
# predictionsはNumpy配列としてのモデルのロジット、
# label_idsはNumpy配列としての真のラベルです。
# モデルをF1スコアで評価します。このデモではバイナリとして保持します(デフォルトタイプで分類しません)
accuracy = evaluate.load("f1")
def compute_metrics(eval_pred):
"""バッチの予測に対する精度を計算します"""
predictions = np.argmax(eval_pred.predictions, axis=1)
return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
トレーニングの開始、MLflowへのモデルの記録
import mlflow
from mlflow.models.signature import infer_signature
import torch
from PIL import Image
from torchvision.transforms import ToPILImage
from transformers import pipeline, DefaultDataCollator, EarlyStoppingCallback
def collate_fn(examples):
pixel_values = torch.stack([e["image"] for e in examples])
labels = torch.tensor([label2id[e["label"]] for e in examples])
return {"pixel_values": pixel_values, "labels": labels}
# モデルがGPUでトレーニングされていることを確認
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
with mlflow.start_run(run_name="hugging_face") as run:
early_stop = EarlyStoppingCallback(early_stopping_patience=10)
trainer = Trainer(
model,
args,
train_dataset=train_ds,
eval_dataset=val_ds,
tokenizer=model_def,
compute_metrics=compute_metrics,
data_collator=collate_fn,
callbacks = [early_stop])
train_results = trainer.train()
# 最終的なHugging Faceパイプラインを構築
classifier = pipeline(
"image-classification",
model=trainer.state.best_model_checkpoint,
tokenizer = model_def,
device_map='auto')
# モデルをMLFlowにログ
# pip_requirementsはオプションで、カスタム依存関係のセットを指定するために使用
reqs = mlflow.transformers.get_default_pip_requirements(model)
# signatureは入力と出力のスキーマを指定するために使用。出力スキーマを取得するために単一の予測を行う
transform = ToPILImage()
img = transform(val_ds[0]['image'])
prediction = classifier(img)
signature = infer_signature(
model_input=np.array(img),
model_output=pd.DataFrame(prediction))
# モデルをログし、タグを設定し、メトリクスをログ
mlflow.transformers.log_model(
artifact_path="model",
transformers_model=classifier,
pip_requirements=reqs,
signature=signature)
mlflow.set_tag("dbdemos", "pcb_classification")
mlflow.log_metrics(train_results.metrics)
# 入力データセットをログして、テーブルからモデルへの系統追跡を行う
src_dataset = mlflow.data.load_delta(
table_name=f'{catalog}.{db}.training_dataset_augmented')
mlflow.log_input(src_dataset, context="Training-Input")

エクスペリメントからは学習の過程を確認できます。

期待通りにモデルが動作することを確認しましょう
import json
import io
from PIL import Image
def test_image(test, index):
img = Image.open(io.BytesIO(test.iloc[index]['content']))
print("ファイル名: " + test.iloc[index]['filename'])
print("真のラベル: " + test.iloc[index]['label'])
print(f"予測: {json.dumps(classifier(img), indent=4)}")
display(img)
# トレーニングデータセットから「normal」とラベル付けされた画像と「damaged」とラベル付けされた画像をサンプリング
normal_samples = spark.read.table("training_dataset_augmented").filter("label == 'normal'").select("content", "filename", "label").limit(10).toPandas()
damaged_samples = spark.read.table("training_dataset_augmented").filter("label == 'damaged'").select("content", "filename", "label").limit(10).toPandas()
# 各グループの最初の画像を使用してモデルをテスト
test_image(normal_samples, 0)
print('\n\n=======================')
test_image(damaged_samples, 0)
ファイル名: 0377.JPG
真のラベル: normal
予測: [
{
"label": "normal",
"score": 0.9993046522140503
},
{
"label": "damaged",
"score": 0.0006952926050871611
}
]

=======================
ファイル名: 036.JPG
真のラベル: damaged
予測: [
{
"label": "damaged",
"score": 0.9998854398727417
},
{
"label": "normal",
"score": 0.0001145034548244439
}
]

モデルのデプロイ
モデルのトレーニングが完了しました。あとは、モデルレジストリに保存し、プロダクション準備が整った状態に移行するだけです。
このデモでは最新のランを使用しますが、mlflow.search_runsを使用して(トレーニング中に定義したメトリックに基づいて)最適なランを検索することもできます。
モデルをレジストリに保存 & Productionとしてマーク
# Unity Catalogにモデルを登録
mlflow.set_registry_uri("databricks-uc")
MODEL_NAME = f"{catalog}.{db}.dbdemos_pcb_classification"
model_registered = mlflow.register_model("runs:/"+run.info.run_id+"/model", MODEL_NAME)
print("モデルバージョン " + model_registered.version + " をプロダクションモデルとして登録中")
## モデルバージョンにProductionエイリアスを設定
client = mlflow.tracking.MlflowClient()
client.set_registered_model_alias(
name = MODEL_NAME,
version = model_registered.version,
alias = "Production")
Created version '1' of model 'takaakiyayoi_catalog.dbdemos_computer_vision_dl.dbdemos_pcb_classification'.
モデルバージョン 1 をプロダクションモデルとして登録中
UCにモデルが登録されます。

テーブルとモデルのリネージも追跡されます。

モデルレジストリ
Unity Catalogモデルレジストリでモデルを確認しましょう。
-
左のナビゲーションメニューからカタログエクスプローラーを開きます

-
検索ボックスまたはカタログブラウザを使用して、カタログとスキーマ内の
dbdemos_pcb_classificationモデルを見つけます。

-
エイリアス
@productionのバージョンを開きます。

-
依存関係タブを選択します。
training_dataset_augmentedテーブルがモデルへの上流接続として識別されていることに注意してください。

-
リネージグラフを見るをクリックします。

-
拡張アイコンと列名を使用して、ボリュームから取り込まれた生のトレーニングデータまでモデルのリネージを探索します。

Unity Catalog Lineageは、生データの取り込みからモデルのトレーニングまで、データがどのように流れ、組織内で消費されるかをエンドツーエンドで可視化します。系譜データはシステムテーブルおよびUIを通じて利用できます。
次: バッチおよびリアルタイムでの推論
モデルはトレーニングされ、MLflowモデルレジストリに登録されました。Databricksはモデルをトレーニングするための多くの補助コードの必要性を軽減し、モデルのパフォーマンス向上に集中できるようにします。
次のステップは、このモデルをバッチまたはRESTエンドポイントの背後でリアルタイムで推論に使用することです。
次の03-running-cv-inferencesノートブックを開いて、Databricksのサービング機能を活用する方法を確認してください。
03-running-cv-inferences: 大規模かつリアルタイムでの推論実行

私たちは今、モデルをレジストリにデプロイしました。レジストリはガバナンスとACLを提供し、すべての下流パイプライン開発を簡素化し加速します。
他のチームはモデル自体を気にする必要はなく、Opsタスクとモデルサービングに集中でき、データサイエンティストは準備が整ったときに新しいモデルをリリースできます。
モデルは通常、2つの方法で使用されます:
- スケールで、クラスター(バッチまたはストリーミング、Delta Live Tables内を含む)
- リアルタイム、低遅延のユースケース、REST APIの背後で提供される。
Databricksは両方のオプションを提供し、簡素化します。
使ったクラスター: シングルノードGPU
バッチ&ストリーミングモデルスコアリング
バッチ/ストリーミング推論から始めましょう。スケールで推論を実行するために、Sparkの分散機能を使用します。
そのためには、MLFlowレジストリからモデルをロードし、複数のインスタンス(通常はGPU上)で推論を分散させるためのPandas UDFを構築する必要があります。
最初のステップは、モデルの依存関係をインストールして、同じライブラリバージョンを使用してモデルをロードすることを確認することです。
%pip install databricks-sdk==0.39.0 mlflow==2.20.2
dbutils.library.restartPython()
デモの初期化
%run ./_resources/00-init $reset_all_data=false
モデルレジストリからpip requirementsをロード
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
import os
# Unity Catalogモデルレジストリを使用
mlflow.set_registry_uri("databricks-uc")
MODEL_NAME = f"{catalog}.{db}.dbdemos_pcb_classification"
MODEL_URI = f"models:/{MODEL_NAME}@Production"
# リモートレジストリからモデルの要件をダウンロード
requirements_path = ModelsArtifactRepository(MODEL_URI).download_artifacts(artifact_path="requirements.txt")
if not os.path.exists(requirements_path):
dbutils.fs.put("file:" + requirements_path, "", True)
requirementsのインストール
%pip install -r $requirements_path
レジストリからモデルをロード
import torch
# GPUが利用可能な場合はGPUを活用する
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
pipeline = mlflow.transformers.load_model(MODEL_URI, device=device.index)
ローカルでモデル推論を実行する(分散処理なし)
まず、標準のpandasデータフレームでローカルに予測を実行してみましょう:
import io
from PIL import Image
from torchvision.transforms.functional import to_tensor, to_pil_image
# パイプラインを呼び出し、主なクラスとその確率を返す
def predict_byte_series(content_as_byte_series, pipeline):
# Huggingfaceパイプライン用にPIL画像のリストに変換
image_list = content_as_byte_series.apply(lambda b: Image.open(io.BytesIO(b))).to_list()
# パイプラインはすべてのクラスの確率を返す
predictions = pipeline.predict(image_list)
# フィルタリングして、スコアが最も高いクラスのみを返す [{'score': 0.999038815498352, 'label': 'normal'}, ...]
return pd.DataFrame([max(r, key=lambda x: x['score']) for r in predictions])
df = spark.read.table("training_dataset_augmented").limit(50)
# モデルを推論モードに切り替える
pipeline.model.eval()
with torch.set_grad_enabled(False):
predictions = predict_byte_series(df.limit(10).toPandas()['content'], pipeline)
display(predictions)
| label | score |
|---|---|
| normal | 0.9993047714233398 |
| normal | 0.9994534850120544 |
| normal | 0.9995086193084717 |
| normal | 0.9998779296875 |
| normal | 0.994005560874939 |
| normal | 0.9994969367980957 |
| normal | 0.9996615648269653 |
| normal | 0.9975491166114807 |
| normal | 0.9989368319511414 |
| damaged | 0.9998854398727417 |
SparkとPandas UDFを使用して推論を分散させる(バッチ/ストリーミング推論)
pandas UDFを使用して関数をラップすることで、推論を並列化しましょう:
import numpy as np
import torch
from typing import Iterator
# 推論を行うUDFでバッチサイズを1000に設定、画像はメモリを多く消費する可能性があるため
try:
spark.conf.set("spark.sql.execution.arrow.maxRecordsPerBatch", 1000)
except:
pass
@pandas_udf("struct<score: float, label: string>")
def detect_damaged_pcb(images_iter: Iterator[pd.Series]) -> Iterator[pd.DataFrame]:
# パイプラインを評価モードに切り替える
pipeline.model.eval()
with torch.set_grad_enabled(False):
for images in images_iter:
yield predict_byte_series(images, pipeline)
display(df.limit(3).select('filename', 'content').withColumn("prediction", detect_damaged_pcb("content")))

REST APIを使用したリアルタイム推論
多くのユースケースではリアルタイム機能が必要です。例えば、PCB製造システムでのリアルタイム分析を考えてみましょう。写真が撮影され、潜在的な欠陥を即座にチェックする必要があります。
これを実現するためには、推論をREST APIの背後で提供する必要があります。システムは画像を送信し、エンドポイントが予測結果を返答します。
そのためには、画像バイトをbase64としてエンコードし、REST APIを介して送信する必要があります。
これにより、モデルはbase64をPIL画像としてデコードする必要があります。これを簡単にするために、トランスフォーマーパイプラインとbase64を変換する簡単なメソッドを持つカスタムモデルラッパーを作成できます。
これは通常通り、mlflow.pyfunc.PythonModelクラスを拡張して行います:
base64画像デコーディングのためのモデルラッパー
from io import BytesIO
import base64
# モデルラッパー
class RealtimeCVModelWrapper(mlflow.pyfunc.PythonModel):
def __init__(self, pipeline):
self.pipeline = pipeline
# 評価モードでモデルをインスタンス化
self.pipeline.model.eval()
# imagesはb64でエンコードされた画像のシリーズを含む
def predict(self, context, images):
with torch.set_grad_enabled(False):
# base64をPIL画像に変換
images = images['data'].apply(lambda b: Image.open(BytesIO(base64.b64decode(b)))).to_list()
# 予測を行う
predictions = self.pipeline(images)
# 最も高いスコアの予測を返す
return pd.DataFrame([max(r, key=lambda x: x['score']) for r in predictions])
画像ベースのモデルをロードし、base64ベースとしてラップしてテスト
def to_base64(b):
return base64.b64encode(b).decode("ascii")
# レジストリからモデルをロードして最終的なHugging Faceパイプラインを構築
pipeline_cpu = mlflow.transformers.load_model(MODEL_URI, return_type="pipeline", device=torch.device("cpu"))
# モデルをPyFuncModelとしてラップし、リアルタイムサービングエンドポイントとして使用できるようにする
rt_model = RealtimeCVModelWrapper(pipeline_cpu)
# エンドポイントをデプロイする前に、ローカルで動作確認を行う:
# 入力をbase64を含むpandasデータフレームに変換。これはサーバーレスモデルエンドポイントが受け取る形式。
pdf = df.toPandas()
df_input = pd.DataFrame(pdf["content"].apply(to_base64).to_list(), columns=["data"])
predictions = rt_model.predict(None, df_input)
display(predictions)
| label | score |
|---|---|
| normal | 0.9993046522140503 |
| normal | 0.9994534850120544 |
| normal | 0.9995086193084717 |
| normal | 0.9998779296875 |
| normal | 0.994005560874939 |
| normal | 0.9994969367980957 |
ラッパーが準備できたので、新しいモデルとしてレジストリにデプロイしましょう。
リアルタイムサービングが主な使用目的である場合、通常はモデルを登録する際にトレーニングステップでそれを行います。このデモでは、バッチ用のモデルと、リアルタイム推論用のbase64ラッパーを持つモデルの2つを作成します。
base64を受け取るRTモデルをレジストリに保存
from mlflow.models.signature import infer_signature
DBDemos.init_experiment_for_batch("computer-vision-dl", "pcb")
with mlflow.start_run(run_name="hugging_face_rt") as run:
signature = infer_signature(df_input, predictions)
# モデルをMLFlowにログ
reqs = mlflow.pyfunc.log_model(
artifact_path="model",
python_model=rt_model,
pip_requirements=requirements_path,
input_example=df_input,
signature = signature)
mlflow.set_tag("dbdemos", "pcb_classification")
mlflow.set_tag("rt", "true")
# モデルをレジストリに保存
model_registered = mlflow.register_model(
model_uri="runs:/"+run.info.run_id+"/model",
name="dbdemos_pcb_classification")
モデルをサービングエンドポイントにデプロイ
新しいモデルラッパーがレジストリで利用可能です。この新しいバージョンをモデルエンドポイントとしてデプロイし、リアルタイムモデルサービングを開始できます。
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ServedEntityInput, EndpointCoreConfigInput, AutoCaptureConfigInput
serving_endpoint_name = "taka_dbdemos_pcb_classification_endpoint"
# モデルサービングエンドポイントの設定を指定
endpoint_config = EndpointCoreConfigInput(
name=serving_endpoint_name,
served_entities=[
ServedEntityInput(
entity_name=MODEL_NAME,
entity_version=model_registered.version,
workload_size="Small",
workload_type="CPU",
scale_to_zero_enabled=True
)
],
auto_capture_config = AutoCaptureConfigInput(
catalog_name=catalog,
schema_name=db,
enabled=True)
)
# 新しいバージョンをリリースするにはこれをTrueに設定(デモはデフォルトでエンドポイントを新しいモデルバージョンに更新しません)
force_update = False
# 既存のエンドポイントを確認して、このエンドポイントが既に存在するかどうかを確認
w = WorkspaceClient()
existing_endpoint = next(
(e for e in w.serving_endpoints.list() if e.name == serving_endpoint_name), None
)
if existing_endpoint == None:
print(f"エンドポイント {serving_endpoint_name} を作成しています。エンドポイントのパッケージ化とデプロイには数分かかります...")
from datetime import timedelta
w.serving_endpoints.create_and_wait(
name=serving_endpoint_name,
config=endpoint_config,
timeout=timedelta(minutes=60))
else:
print(f"エンドポイント {serving_endpoint_name} は既に存在します...")
if force_update:
print(f"エンドポイント {serving_endpoint_name} の {endpoint_config.served_entities[0].entity_name} をバージョン {endpoint_config.served_entities[0].entity_version} に更新しています...")
from datetime import timedelta
w.serving_endpoints.update_config_and_wait(
served_entities=endpoint_config.served_entities,
name=serving_endpoint_name,
timeout=timedelta(minutes=60))
少し待つと、モデルサービングエンドポイントが稼働します(以下のスクリーンショットは一時停止状態です)。

エンドポイントの準備ができました
モデルサービングUIまたはAPIを使用して、エンドポイントにアクセスして構成できます。モデルエンドポイントはサーバーレスであり、ほぼ瞬時に停止および開始します。私たちの場合、使用されていないときにゼロにスケールダウンすることを選択しました(テスト/開発環境に理想的です)。
Databricks Model Servingは複数のモデルバージョンをホストできるため、A/Bテストや新しいモデルのデプロイが簡単になります。
import timeit
import mlflow
from mlflow import deployments
client = mlflow.deployments.get_deploy_client("databricks")
for i in range(3):
input_slice = df_input[2*i:2*i+2]
starting_time = timeit.default_timer()
inferences = client.predict(
endpoint=serving_endpoint_name,
inputs={
"dataframe_records": input_slice.to_dict(orient='records')
})
print(f"Inference time, end 2 end :{round((timeit.default_timer() - starting_time)*1000)}ms")
print(" "+str(inferences))
Inference time, end 2 end :425ms
{'predictions': [{'label': 'normal', 'score': 0.9993046522140503}, {'label': 'normal', 'score': 0.9994534850120544}]}
Inference time, end 2 end :324ms
{'predictions': [{'label': 'normal', 'score': 0.9995086193084717}, {'label': 'normal', 'score': 0.9998779296875}]}
Inference time, end 2 end :189ms
{'predictions': [{'label': 'normal', 'score': 0.994005560874939}, {'label': 'normal', 'score': 0.9994969367980957}]}
結論
Databricksがどのようにしてディープラーニングモデルをスケールでデプロイするのを簡単にするか、特にDatabricks Serverless Model Servingを使用してRESTエンドポイントの背後にデプロイする方法について説明しました。
次のステップ: モデルの説明可能性
次のステップとして、モデルが損傷と見なすピクセルをどのように説明し、強調するかを見てみましょう。
04-explaining-inferenceノートブックを開いて、SHAPを使用して予測を分析する方法を発見してください。
04-explaining-inference: PCBの欠陥を強調するための推論の説明
モデルによってPCBが「損傷」としてフラグ付けされたことを知ることは、素晴らしい第一歩です。
画像のどの部分が損傷と見なされているかを強調できることは、オペレーターに追加の情報を提供するのに役立ちます。
これはモデルの説明可能性の領域に該当します。説明のための最も人気のあるパッケージはSHAPまたはLIMEです。
このノートブックでは、SHAPを使用して、huggingfaceパイプラインの予測をどのように説明できるかを探ります。
%pip install databricks-sdk==0.39.0 mlflow==2.20.2 shap==0.42.1 opencv-python==4.11.0.86
dbutils.library.restartPython()
デモの初期化
%run ./_resources/00-init $reset_all_data=false
モデルレジストリからpip requirementsのロード
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
import os
# Unity Catalogモデルレジストリを使用
mlflow.set_registry_uri("databricks-uc")
MODEL_NAME = f"{catalog}.{db}.dbdemos_pcb_classification"
MODEL_URI = f"models:/{MODEL_NAME}@Production"
# リモートレジストリからモデルの要件をダウンロード
requirements_path = ModelsArtifactRepository(MODEL_URI).download_artifacts(artifact_path="requirements.txt")
if not os.path.exists(requirements_path):
dbutils.fs.put("file:" + requirements_path, "", True)
requirementsのインストール
%pip install -r $requirements_path
レジストリからモデルをロード
import torch
# GPUが利用可能な場合はGPUを使用する
device = torch.device("cuda:0") if torch.cuda.is_available() else torch.device("cpu")
pipeline = mlflow.transformers.load_model(MODEL_URI, device=device.index)
print(f"Model loaded from {MODEL_URI} to device {device}")
df = spark.read.table("training_dataset_augmented").limit(10).toPandas()
def nhwc_to_nchw(x: torch.Tensor) -> torch.Tensor:
return x if x.shape[1] == 3 else x.permute(0, 3, 1, 2)
def nchw_to_nhwc(x: torch.Tensor) -> torch.Tensor:
return x if x.shape[3] == 3 else x.permute(0, 2, 3, 1)
import io
from PIL import Image
import shap
import torchvision.transforms as tf
from torchvision.transforms.functional import to_tensor
mlflow.autolog(disable=True)
mean=[0.485, 0.456, 0.406]
std=[0.229, 0.224, 0.225]
transform = tf.Compose([
tf.Lambda(lambda b: to_tensor(Image.open(io.BytesIO(b)))[None, :]),
tf.Lambda(nhwc_to_nchw),
tf.Resize((pipeline.image_processor.size['height'], pipeline.image_processor.size['width'])),
tf.Normalize(mean=pipeline.image_processor.image_mean, std=pipeline.image_processor.image_std),
tf.Lambda(nchw_to_nhwc),
])
inv_transform= tf.Compose([
tf.Lambda(nhwc_to_nchw),
tf.Normalize(mean = (-1 * np.array(pipeline.image_processor.image_mean) / np.array(pipeline.image_processor.image_std)).tolist(),
std = (1 / np.array(pipeline.image_processor.image_std)).tolist()),
tf.Lambda(nchw_to_nhwc),
])
def hf_model_wrapper(img_vector):
img_vector = torch.from_numpy(img_vector)
revert_img_back = img_vector.permute(0, 3, 1, 2).to(device)
output = pipeline.model(revert_img_back)
return output.logits
class_names = ['damaged', 'normal']
mask_size = transform(df.iloc[0]['content'])[0].size()
masker_blur = shap.maskers.Image("blur(128,128)", mask_size)
# モデルと画像マスカーを使用して説明者を作成
explainer = shap.Explainer(hf_model_wrapper, masker_blur, output_names=class_names)
def explain_image(image_to_explain, explainer, class_names):
topk = 4
batch_size = 50
n_evals = 10000
# 1つの画像のみをフィード
# ここでは、基礎モデルのSHAP値を推定するために100回の評価を使用して2つの画像を説明します
shap_values = explainer(image_to_explain, max_evals=n_evals, batch_size=batch_size,
outputs=shap.Explanation.argsort.flip[:topk])
shap_values.data = inv_transform(shap_values.data).cpu().numpy()
shap_values.values = [val for val in np.moveaxis(shap_values.values,-1, 0)]
shap.image_plot(shap_values=shap_values.values, pixel_values=shap_values.data, labels=class_names)
損傷したPCBの評価
赤で損傷部分が表示されています(画像で明確に識別可能)
PCB ナンバー 010はダメージありです
# 赤い部分で異常がある部分が明確にわかり、青い部分はその反対(「正常」に寄与していない)です。
test = spark.read.table("training_dataset_augmented").where("filename = '010.JPG'").toPandas()
image_bytes = test.iloc[0]['content']
predictions = pipeline(Image.open(io.BytesIO(image_bytes)))
print(f"Prediction for image 010.JPG: {predictions}")
explain_image(transform(image_bytes), explainer, class_names)
Prediction for image 010.JPG: [{'label': 'damaged', 'score': 0.9998244643211365}, {'label': 'normal', 'score': 0.00017554960504639894}]
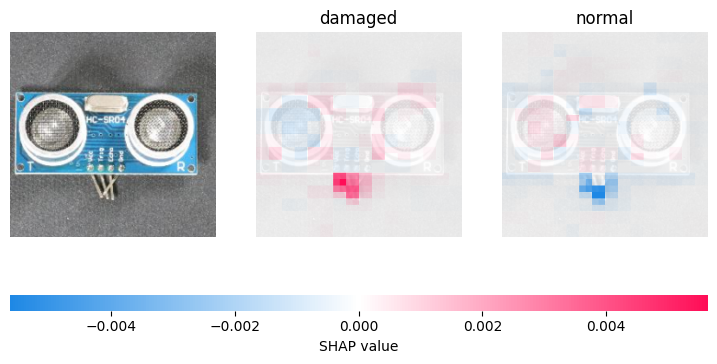
結論
損傷部分を予測できるだけでなく、損傷箇所を理解し、欠陥の解決に役立てることができます!