これまできちんと動かしていなかったので、以下のサンプルノートブックをウォークスルします。
翻訳したノートブックはこちらです。
Mosaic AI Gatewayとは
Mosaic AI ゲートウェイは、企業内の全てのモデルに対して一元管理されたガバナンスを通じて、データと生成 AI のデプロイメントを保護します。Azure OpenAI、Amazon Bedrock on AWS、Meta Llama 3 など、あらゆるモデルのエンドポイントをサポートする AI ゲートウェイは、単一の強力なクエリインターフェースを通じて、最先端のイノベーションにアクセスできます。AI ゲートウェイを使用すると、コードベースを変更することなく、容易に新しいモデルのテストや入れ替えができます。Unity Catalog で使用状況を追跡し、パーミッションを設定することで、機密データの漏洩を防ぎます。さらに、AI ゲートウェイはリアルタイムの支出分析機能による財務管理ができるため、業務の効率化を図ります。
Databricksでは生成AIへのアクセスをモデルサービングで一元管理しています。ここにアドオンされる形で動作するMosaic AI Gatewayは生成AIモデルへのアクセスだけではなく、ペイロードのロギング、ガードレイル、レート制限などを実現します。
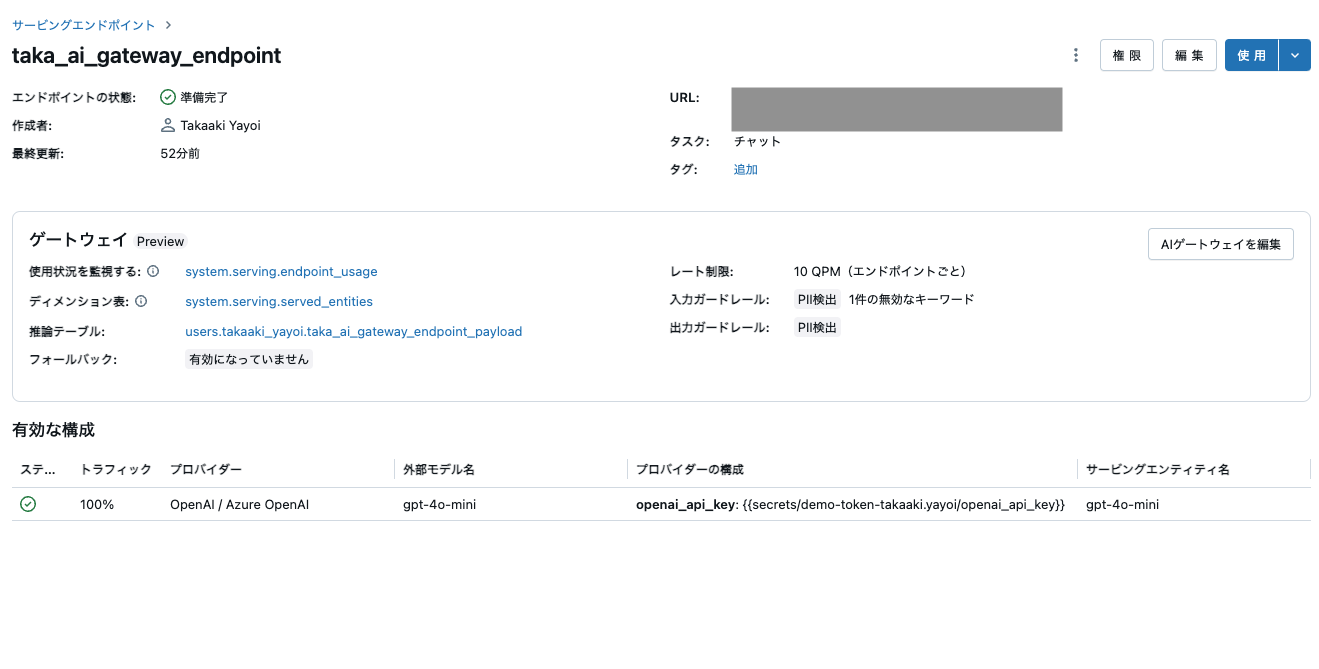
Databricks Mosaic AI Gateway 機能を有効にする
このノートブックでは、OpenAI や Anthropic などのプロバイダーからのモデルを管理およびガバナンスするために、Databricks Mosaic AI Gateway 機能を有効にして使用する方法を示します。
このノートブックでは、モデル サービングおよび AI Gateway API を使用して次のタスクを実行します。
- OpenAI GPT-4o-Mini のエンドポイントを作成および構成します。
- 使用状況の追跡、推論テーブル、ガードレール、レート制限などの AI Gateway 機能を有効にします。
- モデル リクエストおよびレスポンスの無効なキーワードおよび個人識別情報 (PII) 検出を設定します。
- モデル サービング エンドポイントのレート制限を実装します。
- A/B テスト用に複数のモデルを構成します。
- 失敗したリクエストのフォールバックを有効にします。
ローコード エクスペリエンスを好む場合は、外部モデル エンドポイントを作成し、サービング UI を使用して AI Gateway 機能を構成できます (AWS | Azure | GCP)。
%pip install --quiet openai
%restart_python
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
DATABRICKS_HOST = w.config.host
# モデルサービングエンドポイントの名前
ENDPOINT_NAME = "taka_ai_gateway_endpoint"
# 推論テーブルのカタログとスキーマ
CATALOG_NAME = "users"
SCHEMA_NAME = "takaaki_yayoi"
# Databricks Secretsに保存されたOpenAI APIキー
SECRETS_SCOPE = "demo-token-takaaki.yayoi"
SECRETS_KEY = "openai_api_key"
# OpenAI APIキーを追加する必要がある場合は、以下のようにします:
# w.secrets.put_secret(scope=SECRETS_SCOPE, key=SECRETS_KEY, string_value='<key_value>')
OpenAI GPT-4o-Mini のモデル サービング エンドポイントを作成する
次に、AI Gateway を有効にせずに GPT-4o Mini のモデル サービング エンドポイントを作成します。まず、エンドポイントを作成および更新するためのヘルパー関数を定義します:
import requests
import json
import time
from typing import Optional
def configure_endpoint(
name: str,
databricks_token: str,
config: dict,
host: str,
endpoint_path: Optional[str] = None,
):
base_url = f"{host}/api/2.0/serving-endpoints"
if endpoint_path:
# 更新操作
api_url = f"{base_url}/{name}/{endpoint_path}"
method = requests.put
operation = "Updating"
else:
# 作成操作
api_url = base_url
method = requests.post
operation = "Creating"
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
print(f"{operation} endpoint...")
response = method(api_url, headers=headers, json=config)
if response.status_code == 200:
return response.json()
else:
print(
f"Failed to {operation.lower()} endpoint. Status code: {response.status_code}"
)
return response.text
次に、エンドポイントを設定するための簡単な構成を書きます。API の詳細については、POST /api/2.0/serving-endpoints を参照してください。
create_endpoint_request_data = {
"name": ENDPOINT_NAME,
"config": {
"served_entities": [
{
"name": "gpt-4o-mini",
"external_model": {
"name": "gpt-4o-mini",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": f"{{{{secrets/{SECRETS_SCOPE}/{SECRETS_KEY}}}}}",
},
},
}
],
},
}
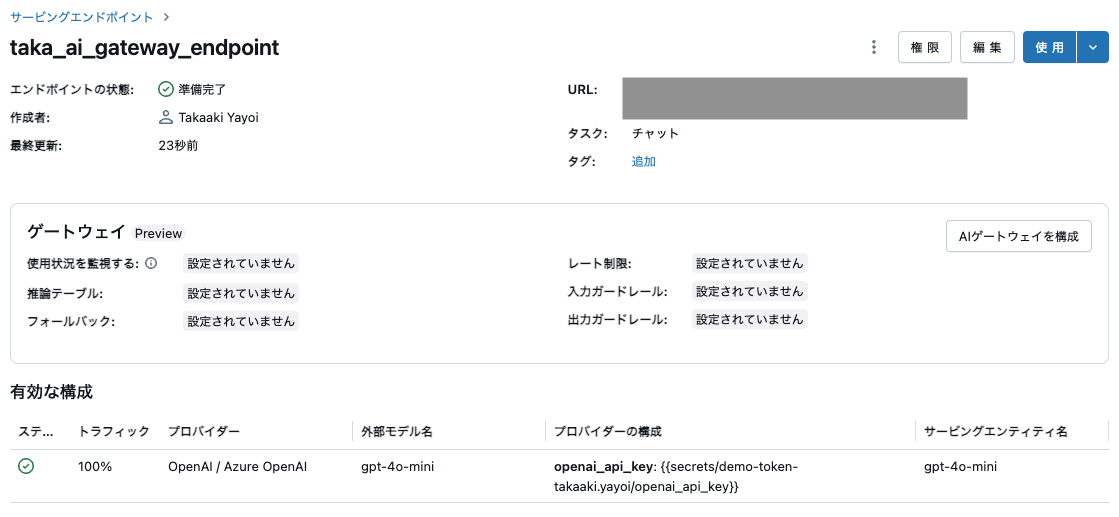
以下を実行することでモデルサービングエンドポイントが作成されます。以降の操作はGUIからも行えますが、ここではAPIを用いてプログラムから設定を行なっていきます。
import time
tmp_token = w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value
configure_endpoint(
ENDPOINT_NAME, tmp_token, create_endpoint_request_data, DATABRICKS_HOST
)
Creating endpoint...
{'name': 'taka_ai_gateway_endpoint',
'creator': 'takaaki.yayoi@databricks.com',
'creation_timestamp': 1742814914000,
'last_updated_timestamp': 1742814914000,
'state': {'ready': 'READY', 'config_update': 'NOT_UPDATING'},
'config': {'served_entities': [{'name': 'gpt-4o-mini',
'external_model': {'provider': 'openai',
'name': 'gpt-4o-mini',
'task': 'llm/v1/chat',
'openai_config': {'openai_api_key': '{{secrets/demo-token-takaaki.yayoi/openai_api_key}}'}},
'type': 'EXTERNAL_MODEL',
'state': {'deployment': 'DEPLOYMENT_READY',
'deployment_state_message': ''},
'creator': 'takaaki.yayoi@databricks.com',
'creation_timestamp': 1742814914000}],
'traffic_config': {'routes': [{'served_model_name': 'gpt-4o-mini',
'traffic_percentage': 100}]},
'config_version': 1},
'id': '1e71284ed4c0472d8dc0c2e6233c23a8',
'permission_level': 'CAN_MANAGE',
'task': 'llm/v1/chat',
'route_optimized': False,
'endpoint_type': 'EXTERNAL_MODEL',
'creator_display_name': 'Takaaki Yayoi',
'creator_kind': 'User',
'resource_credential_strategy': 'EMBEDDED_CREDENTIALS'}
Databricks を使用して OpenAI モデル(または他のプロバイダーのモデル)を使用することの即時の利点の一つは、次のいずれかの方法を使用してモデルにすぐにクエリを実行できることです:
- Databricks Python SDK
- OpenAI Python クライアント
- REST API 呼び出し
- MLflow Deployments SDK
- Databricks SQL
ai_query関数
基盤モデルおよび外部モデルのクエリに関する記事を参照してください (AWS | Azure | GCP)。
例えば、Databricks SQL を使用して ai_query を使用してモデルにクエリを実行できます。
%sql
SELECT
ai_query(
"taka_ai_gateway_endpoint",
"専門家の混合モデルとは何ですか?"
)

AI ゲートウェイ構成の追加
モデルサービングエンドポイントを設定した後、Databricks でアクセス可能なさまざまなクエリ方法を使用して OpenAI モデルにクエリを実行できます。
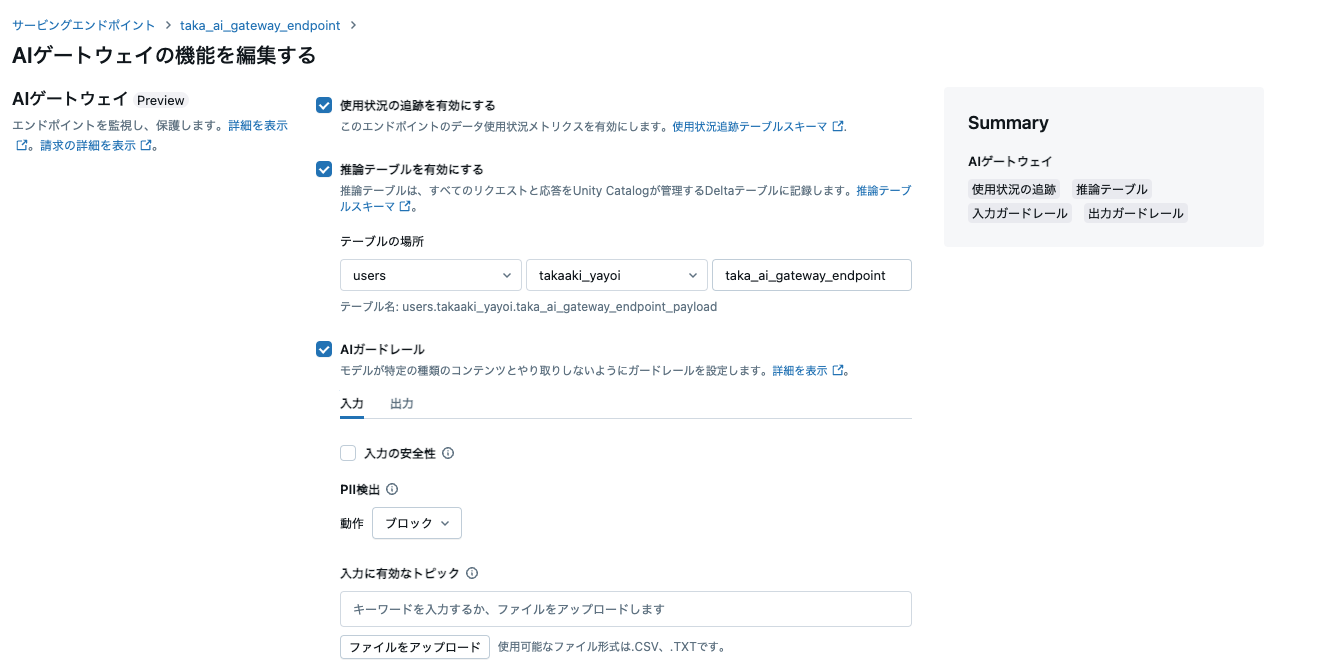
Databricks Mosaic AI ゲートウェイを有効にすることで、エンドポイントの監視と管理のためのさまざまな機能を提供し、モデルサービングエンドポイントをさらに充実させることができます。これらの機能には、推論テーブル、ガードレール、レート制限などが含まれます。
まず、エンドポイントの使用状況を監視するための推論テーブルを有効にする簡単な構成を以下に示します。エンドポイントがどのように、どのくらいの頻度で使用されているかを理解することで、使用制限やガードレールがどのように役立つかを判断するのに役立ちます。
gateway_request_data = {
"usage_tracking_config": {"enabled": True},
"inference_table_config": {
"enabled": True,
"catalog_name": CATALOG_NAME,
"schema_name": SCHEMA_NAME,
},
}
tmp_token = w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value
configure_endpoint(
ENDPOINT_NAME, tmp_token, gateway_request_data, DATABRICKS_HOST, "ai-gateway"
)
Updating endpoint...
{'usage_tracking_config': {'enabled': True},
'inference_table_config': {'catalog_name': 'users',
'schema_name': 'takaaki_yayoi',
'table_name_prefix': 'taka_ai_gateway_endpoint',
'enabled': True}}
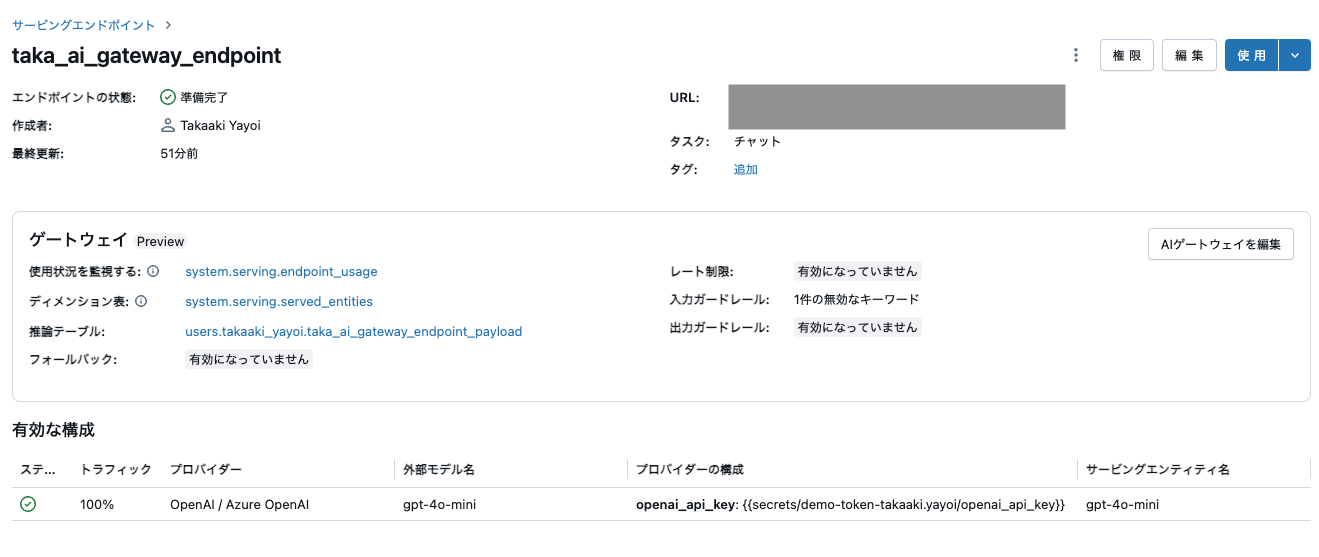
ゲートウェイ設定が更新されました。
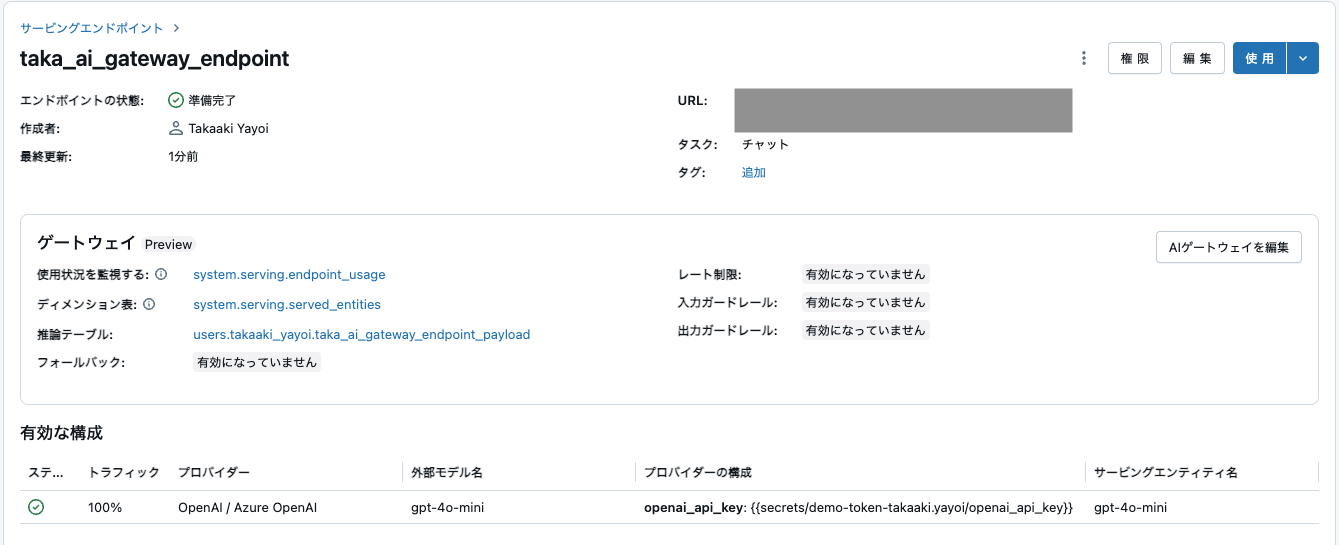
なお、推論テーブルにデータが流入するまでには制限に記載があるように1時間ほどお待ちください。それまでに、AI Playgroundでモデルサービングエンドポイントに問い合わせを行なってサンプルデータを収集しておきます。
推論テーブルのログ配信は現在ベストエフォートですが、リクエストから 1 時間以内にログが利用可能になることが期待できます。 詳細については、 Databricks アカウントチームにお問い合わせください。
しばらく待つとテーブルにエンドポイントのリクエストやレスポンスが記録されます。
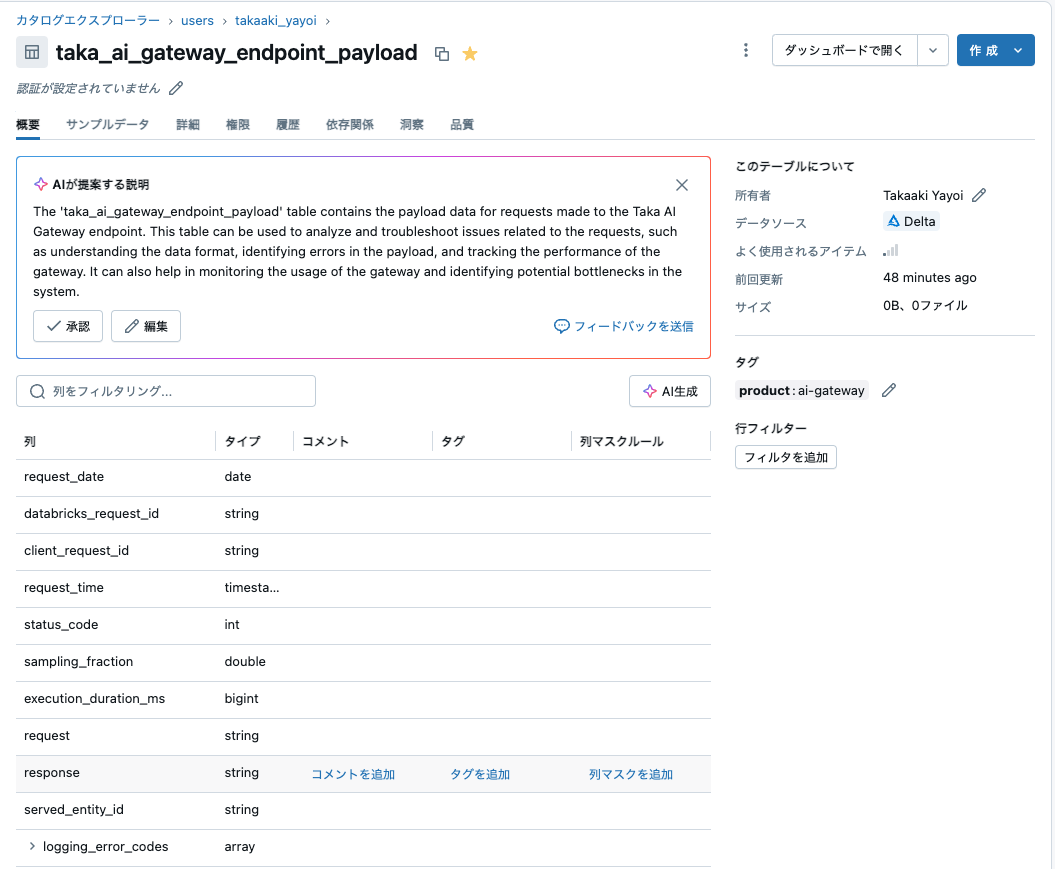
推論テーブルをクエリする
以下は、AI ゲートウェイで有効になった推論テーブルを表示しています。
注意: 推論テーブルに例を追加するために、上のコマンドで推論テーブルを設定した後でAI Playgroundでこのエンドポイントに対する問い合わせを何回か実行しています。
spark.sql(
f"""select request_time, status_code, request, response
from {CATALOG_NAME}.{SCHEMA_NAME}.`{ENDPOINT_NAME}_payload`
where status_code=200
limit 10"""
).display()

SQLを用いることで、リクエストのメッセージ、レスポンスのメッセージ、トークン数などの詳細情報を抽出することができます:
query = f"""SELECT
request_time,
from_json(
request,
'array<struct<messages:array<struct<role:string, content:string>>>>'
).messages [0].content AS request_messages,
from_json(
response,
'struct<choices:array<struct<message:struct<role:string, content:string>>>>'
).choices [0].message.content AS response_messages,
from_json(
response,
'struct<choices:array<struct<message:struct<role:string, content:string>>>, usage:struct<prompt_tokens:int, completion_tokens:int, total_tokens:int>>'
).usage.prompt_tokens AS prompt_tokens,
from_json(
response,
'struct<choices:array<struct<message:struct<role:string, content:string>>>, usage:struct<prompt_tokens:int, completion_tokens:int, total_tokens:int>>'
).usage.completion_tokens AS completion_tokens,
from_json(
response,
'struct<choices:array<struct<message:struct<role:string, content:string>>>, usage:struct<prompt_tokens:int, completion_tokens:int, total_tokens:int>>'
).usage.total_tokens AS total_tokens
FROM
{CATALOG_NAME}.{SCHEMA_NAME}.`{ENDPOINT_NAME}_payload`
WHERE
status_code = 200
LIMIT
10;"""
spark.sql(query).display()

AI ガードレールの設定
無効なキーワードの設定
推論テーブルを調査して、エンドポイントが不適切なトピックに使用されているかどうかを確認できます。推論テーブルから、ユーザーが SuperSecretProject について話しているようです!この例では、そのトピックはこのチャットエンドポイントの使用範囲に含まれていないと仮定できます。
spark.sql(
f"""SELECT
DATE_TRUNC('HOUR', request_time) AS hour,
CASE
WHEN INSTR(from_json(request, 'array<struct<messages:array<struct<role:string, content:string>>>>').messages[0].content[0], 'SuperSecretProject') > 0 THEN 'Mentioned'
ELSE 'Not Mentioned'
END AS SuperSecretProject_Mention,
COUNT(*) AS count
FROM
{CATALOG_NAME}.{SCHEMA_NAME}.`{ENDPOINT_NAME}_payload`
WHERE
request_time >= current_timestamp() - INTERVAL 1 DAYS
GROUP BY
hour, SuperSecretProject_Mention
ORDER BY
hour ASC"""
).display()
| hour | SuperSecretProject_Mention | count |
|---|---|---|
| 2025-03-24T11:00:00.000+00:00 | Not Mentioned | 5 |
次のコードは、SuperSecretProject を無効なキーワードのリストに追加して、使用範囲を確保します。
gateway_request_data.update(
{
"guardrails": {
"input": {
"invalid_keywords": ["SuperSecretProject"],
},
}
}
)
tmp_token = w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value
configure_endpoint(
ENDPOINT_NAME, tmp_token, gateway_request_data, DATABRICKS_HOST, "ai-gateway"
)
Updating endpoint...
{'usage_tracking_config': {'enabled': True},
'inference_table_config': {'catalog_name': 'users',
'schema_name': 'takaaki_yayoi',
'table_name_prefix': 'taka_ai_gateway_endpoint',
'enabled': True},
'guardrails': {'input': {'safety': False,
'pii_detection': False,
'pii': {'behavior': 'NONE'},
'invalid_keywords': ['SuperSecretProject']}}}
入力ガードレールの設定が更新されます。
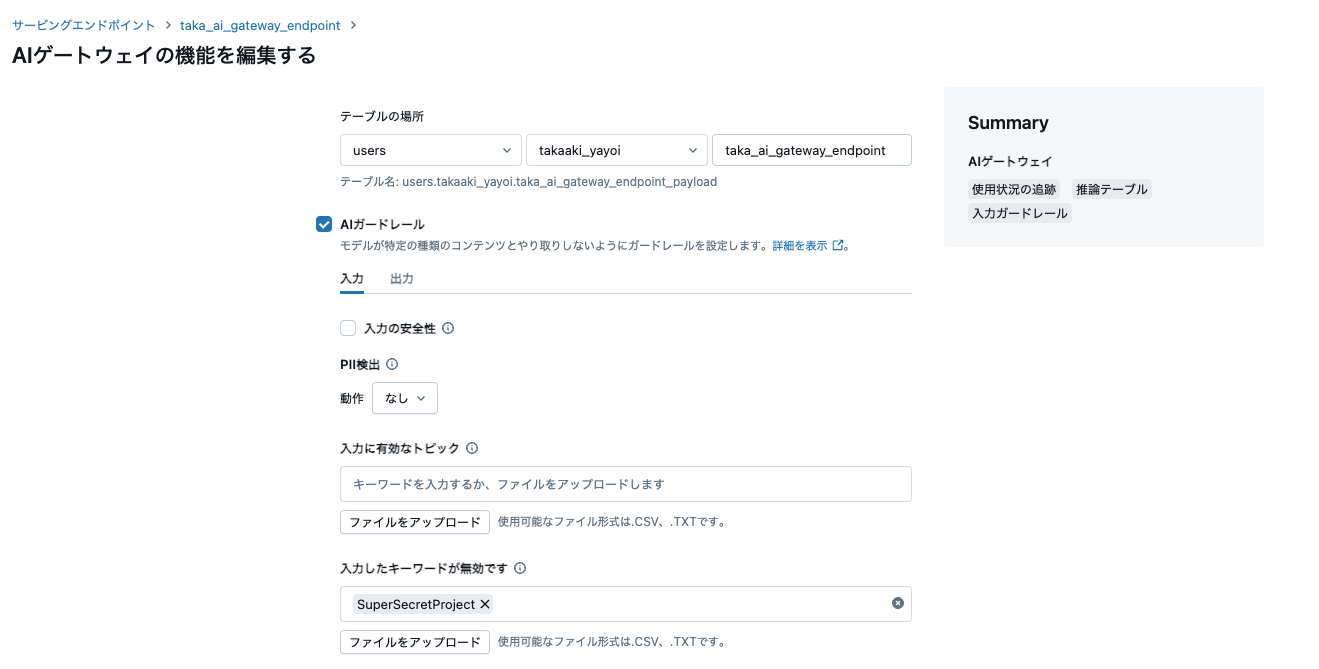
これで、SuperSecretProject に言及するクエリは実行されず、代わりにエラーメッセージ "エラー: プロンプトに無効なキーワードが検出されました。入力を修正してください。" が返されます。
from openai import OpenAI
import time
client = OpenAI(
api_key=w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value,
base_url=f"{w.config.host}/serving-endpoints",
)
prompt = "量子暗号プロジェクト、 SuperSecretProject について助けが必要です。"
try:
response = client.chat.completions.create(
model=ENDPOINT_NAME,
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです。"},
{"role": "user", "content": prompt},
],
max_tokens=256,
)
print(response)
except Exception as e:
if 'invalid_keywords":true' in str(e):
print(
"エラー: プロンプトに無効なキーワードが検出されました。入力を修正してください。"
)
else:
print(f"エラーが発生しました: {e}")
エラー: プロンプトに無効なキーワードが検出されました。入力を修正してください。
PII 検出の設定
現在、エンドポイントは SuperSecretProject に言及するメッセージをブロックしています。また、エンドポイントが PII を含むリクエストやメッセージを受け付けないようにすることもできます。
次のコードは、pii のガードレール設定を更新します:
gateway_request_data.update(
{
"guardrails": {
"input": {
"pii": {"behavior": "BLOCK"},
"invalid_keywords": ["SuperSecretProject"],
},
"output": {
"pii": {"behavior": "BLOCK"},
},
}
}
)
tmp_token = w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value
configure_endpoint(
ENDPOINT_NAME, tmp_token, gateway_request_data, DATABRICKS_HOST, "ai-gateway"
)
Updating endpoint...
{'usage_tracking_config': {'enabled': True},
'inference_table_config': {'catalog_name': 'users',
'schema_name': 'takaaki_yayoi',
'table_name_prefix': 'taka_ai_gateway_endpoint',
'enabled': True},
'guardrails': {'input': {'safety': False,
'pii_detection': True,
'pii': {'behavior': 'BLOCK'},
'invalid_keywords': ['SuperSecretProject']},
'output': {'safety': False,
'pii_detection': True,
'pii': {'behavior': 'BLOCK'}}}}
入力ガードレールと出力ガードレールにPII検出が追加されます。
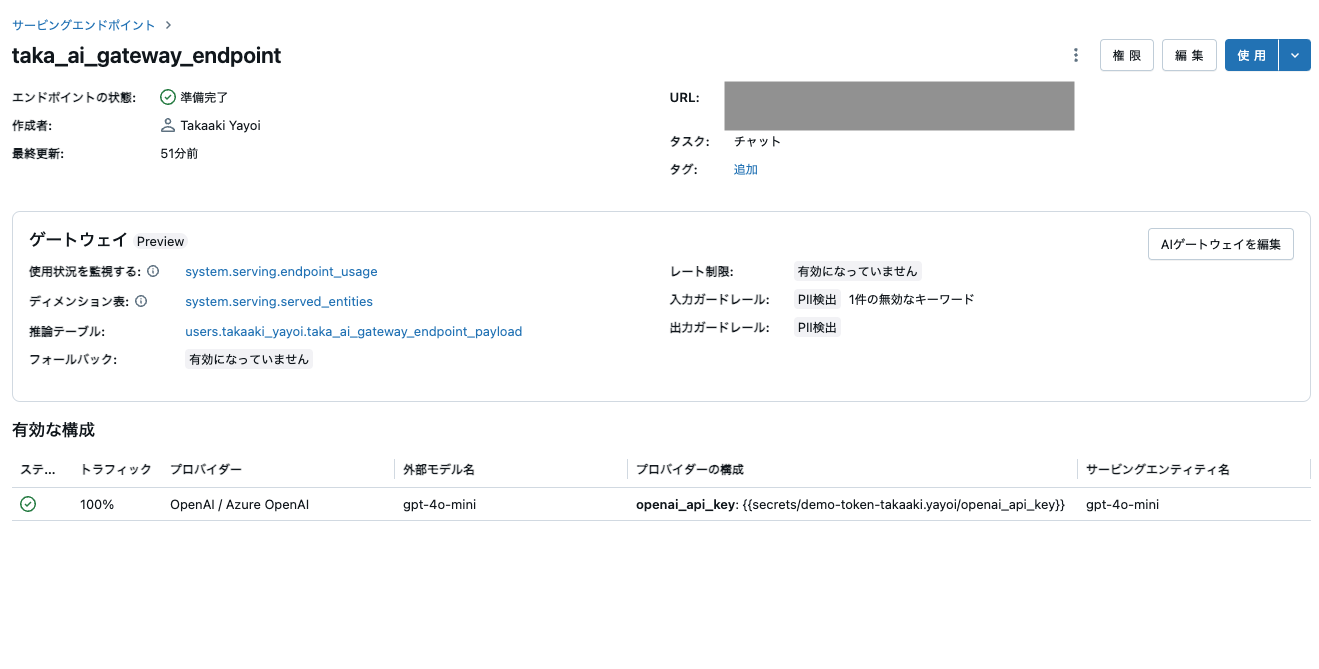
次のコードは、モデルに PII を扱うように促しますが、メッセージ "エラー: PII (個人を特定できる情報) が検出されました。再試行してください。" が返されます。
fictional_data = """
サマンサ・リー, slee@fictional-corp.com, (555) 123-4567, シニアマーケティングマネージャー
ラージ・パテル, rpatel@imaginary-tech.net, (555) 987-6543, ソフトウェアエンジニアII
エレナ・ロドリゲス, erodriguez@pretend-company.org, (555) 246-8135, オペレーションディレクター
"""
prompt = f"""
あなたは会社の人事部門のAIアシスタントです。以下に提供された従業員データを使用して、次の質問に答えてください:
ラージ・パテルの電話番号とメールアドレスは何ですか?
従業員データ:
{fictional_data}
"""
client = OpenAI(
api_key=w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value,
base_url=f"{w.config.host}/serving-endpoints",
)
try:
response = client.chat.completions.create(
model=ENDPOINT_NAME,
messages=[
{"role": "system", "content": "あなたは役に立つアシスタントです。"},
{"role": "user", "content": prompt},
],
max_tokens=256,
)
print(response)
except Exception as e:
if 'pii_detection":true' in str(e):
print(
"エラー: PII(個人を特定できる情報)が検出されました。もう一度お試しください。"
)
else:
print(f"エラーが発生しました: {e}")
エラー: PII(個人を特定できる情報)が検出されました。もう一度お試しください。
レート制限の追加
推論テーブルをさらに調査していると、使用量の急激なスパイクが見られ、予想以上のクエリ量を示唆していることがあります。非常に高い使用量は、監視および制限されない場合、コストがかかる可能性があります。
query = f"""SELECT
DATE_TRUNC('minute', request_time) AS minute,
COUNT(DISTINCT databricks_request_id) AS queries_per_minute
FROM
{CATALOG_NAME}.{SCHEMA_NAME}.`{ENDPOINT_NAME}_payload`
WHERE
request_time >= CURRENT_TIMESTAMP - INTERVAL 20 HOURS
GROUP BY
DATE_TRUNC('minute', request_time)
ORDER BY
minute DESC;
"""
spark.sql(query).display()
| minute | queries_per_minute |
|---|---|
| 2025-03-24T11:18:00.000+00:00 | 1 |
| 2025-03-24T11:17:00.000+00:00 | 2 |
過剰なクエリを防ぐためにレート制限を設定できます。この場合、エンドポイントに制限を設定できますが、ユーザーごとに制限を設定することも可能です。
gateway_request_data.update(
{
"rate_limits": [{"calls": 10, "key": "endpoint", "renewal_period": "minute"}],
}
)
tmp_token = w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value
configure_endpoint(
ENDPOINT_NAME, tmp_token, gateway_request_data, DATABRICKS_HOST, "ai-gateway"
)
Updating endpoint...
{'usage_tracking_config': {'enabled': True},
'inference_table_config': {'catalog_name': 'users',
'schema_name': 'takaaki_yayoi',
'table_name_prefix': 'taka_ai_gateway_endpoint',
'enabled': True},
'rate_limits': [{'calls': 10, 'key': 'endpoint', 'renewal_period': 'minute'}],
'guardrails': {'input': {'safety': False,
'pii_detection': True,
'pii': {'behavior': 'BLOCK'},
'invalid_keywords': ['SuperSecretProject']},
'output': {'safety': False,
'pii_detection': True,
'pii': {'behavior': 'BLOCK'}}}}
レート制限が設定されます。
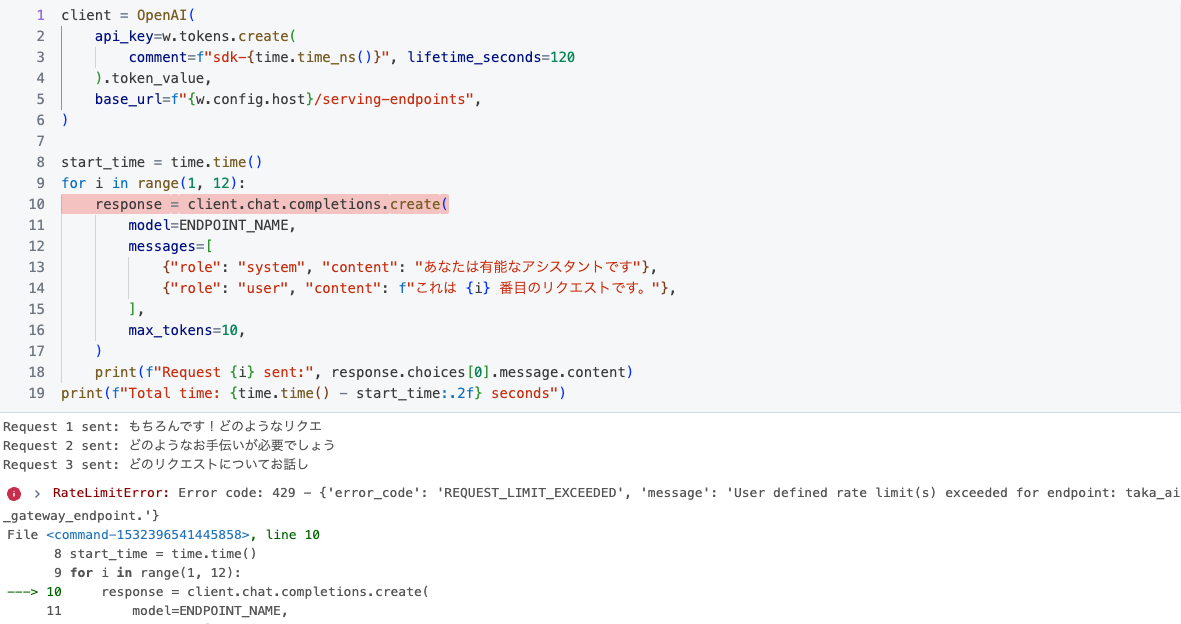
以下は、レート制限を超えたときの出力エラーの例を示しています。
client = OpenAI(
api_key=w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value,
base_url=f"{w.config.host}/serving-endpoints",
)
start_time = time.time()
for i in range(1, 12):
response = client.chat.completions.create(
model=ENDPOINT_NAME,
messages=[
{"role": "system", "content": "あなたは有能なアシスタントです"},
{"role": "user", "content": f"これは {i} 番目のリクエストです。"},
],
max_tokens=10,
)
print(f"Request {i} sent:", response.choices[0].message.content)
print(f"Total time: {time.time() - start_time:.2f} seconds")
別のモデルを追加する
ある時点で、異なるプロバイダーのモデルをA/Bテストしたくなるかもしれません。次の例のように、別のOpenAIモデルを構成に追加できます。
new_config = {
"served_entities": [
{
"name": "gpt-4o-mini",
"external_model": {
"name": "gpt-4o-mini",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": f"{{{{secrets/{SECRETS_SCOPE}/{SECRETS_KEY}}}}}",
},
},
},
{
"name": "gpt-4o",
"external_model": {
"name": "gpt-4o",
"provider": "openai",
"task": "llm/v1/chat",
"openai_config": {
"openai_api_key": f"{{{{secrets/{SECRETS_SCOPE}/{SECRETS_KEY}}}}}",
},
},
},
],
"traffic_config": {
"routes": [
{"served_model_name": "gpt-4o-mini", "traffic_percentage": 50},
{"served_model_name": "gpt-4o", "traffic_percentage": 50},
]
},
}
tmp_token = w.tokens.create(
comment=f"sdk-{time.time_ns()}", lifetime_seconds=120
).token_value
configure_endpoint(ENDPOINT_NAME, tmp_token, new_config, DATABRICKS_HOST, "config")
Updating endpoint...
{'name': 'taka_ai_gateway_endpoint',
'creator': 'takaaki.yayoi@databricks.com',
'creation_timestamp': 1742814914000,
'last_updated_timestamp': 1742818429000,
'state': {'ready': 'READY', 'config_update': 'NOT_UPDATING'},
'config': {'served_entities': [{'name': 'gpt-4o-mini',
'external_model': {'provider': 'openai',
'name': 'gpt-4o-mini',
'task': 'llm/v1/chat',
'openai_config': {'openai_api_key': '{{secrets/demo-token-takaaki.yayoi/openai_api_key}}'}},
'type': 'EXTERNAL_MODEL',
'state': {'deployment': 'DEPLOYMENT_READY',
'deployment_state_message': ''},
'creator': 'takaaki.yayoi@databricks.com',
'creation_timestamp': 1742818429000},
{'name': 'gpt-4o',
'external_model': {'provider': 'openai',
'name': 'gpt-4o',
'task': 'llm/v1/chat',
'openai_config': {'openai_api_key': '{{secrets/demo-token-takaaki.yayoi/openai_api_key}}'}},
'type': 'EXTERNAL_MODEL',
'state': {'deployment': 'DEPLOYMENT_READY',
'deployment_state_message': ''},
'creator': 'takaaki.yayoi@databricks.com',
'creation_timestamp': 1742818429000}],
'traffic_config': {'routes': [{'served_model_name': 'gpt-4o-mini',
'traffic_percentage': 50},
{'served_model_name': 'gpt-4o', 'traffic_percentage': 50}]},
'config_version': 1},
'id': '1e71284ed4c0472d8dc0c2e6233c23a8',
'permission_level': 'CAN_MANAGE',
'task': 'llm/v1/chat',
'route_optimized': False,
'endpoint_type': 'EXTERNAL_MODEL',
'ai_gateway': {'usage_tracking_config': {'enabled': True},
'inference_table_config': {'catalog_name': 'users',
'schema_name': 'takaaki_yayoi',
'table_name_prefix': 'taka_ai_gateway_endpoint',
'enabled': True},
'rate_limits': [{'calls': 10,
'key': 'endpoint',
'renewal_period': 'minute'}],
'guardrails': {'input': {'safety': False,
'pii_detection': True,
'pii': {'behavior': 'BLOCK'},
'invalid_keywords': ['SuperSecretProject']},
'output': {'safety': False,
'pii_detection': True,
'pii': {'behavior': 'BLOCK'}}}},
'creator_display_name': 'Takaaki Yayoi',
'creator_kind': 'User',
'resource_credential_strategy': 'EMBEDDED_CREDENTIALS'}
これで、トラフィックはこれら2つのモデル間で分割されます(各モデルに送られるトラフィックの割合を設定できます)。これにより、推論テーブルを使用して各モデルの品質を評価し、あるモデルから別のモデルに切り替えるかどうかを判断することができます。
これが今回の最終的な設定となります。2つのモデルに対して半分づつのトラフィックが送信されます。

リクエストのフォールバックモデルを有効にする
外部モデルへのリクエストに対してフォールバックを構成できます。
フォールバックを有効にすると、リクエストが429または5XXエラーで失敗した場合に、リストされた順序で次のエンティティに自動的にフェイルオーバーし、必要に応じて最初に戻ります。最大2つのフォールバックが許可されます。0%のトラフィックが割り当てられた外部モデルは、専らフォールバックモデルとして機能します。最初に成功したリクエストまたは最後に失敗したリクエストの試行は、使用状況追跡システムテーブルと推論テーブルの両方に記録されます。
次の例では:
-
traffic_configフィールドは、トラフィックの50%がexternal_model_1に、残りの50%がexternal_model_2に送られることを指定しています。 -
ai_gatewayセクションのfallback_configフィールドは、フォールバックが有効であることを指定しています。 - リクエストが
external_model_1に送信されたときに失敗した場合、そのリクエストはトラフィック構成で次にリストされているモデル、つまりこの場合はexternal_model_2にリダイレクトされます。
以下は例であり実行はしません。
endpoint_config = {
"name": endpoint_name,
"config": {
# 外部モデルをエンティティとして定義
"served_entities": [
external_model_1,
external_model_2
],
"traffic_config": {
"routes": [
{
# 50%のトラフィックが最初の外部モデルに行く
"served_model_name": "external_model_1",
"traffic_percentage": 50
},
{
# 50%のトラフィックが2番目の外部モデルに行く(フォールバックのみ)
"served_model_name": "external_model_2",
"traffic_percentage": 50
}
]
}
},
# フォールバックを有効にする(提供されるエンティティの順序で発生)
"ai_gateway": {
"fallback_config": {"enabled": True}
}
}