こちらのデモをウォークスルーします。
インストール
ノートブックを作成して、以下を実行します。
%pip install dbdemos
import dbdemos
dbdemos.install('lakehouse-iot-platform', catalog='takaakiyayoi_catalog', schema='dbdemos_iot_turbine')
インストールが実行されます。
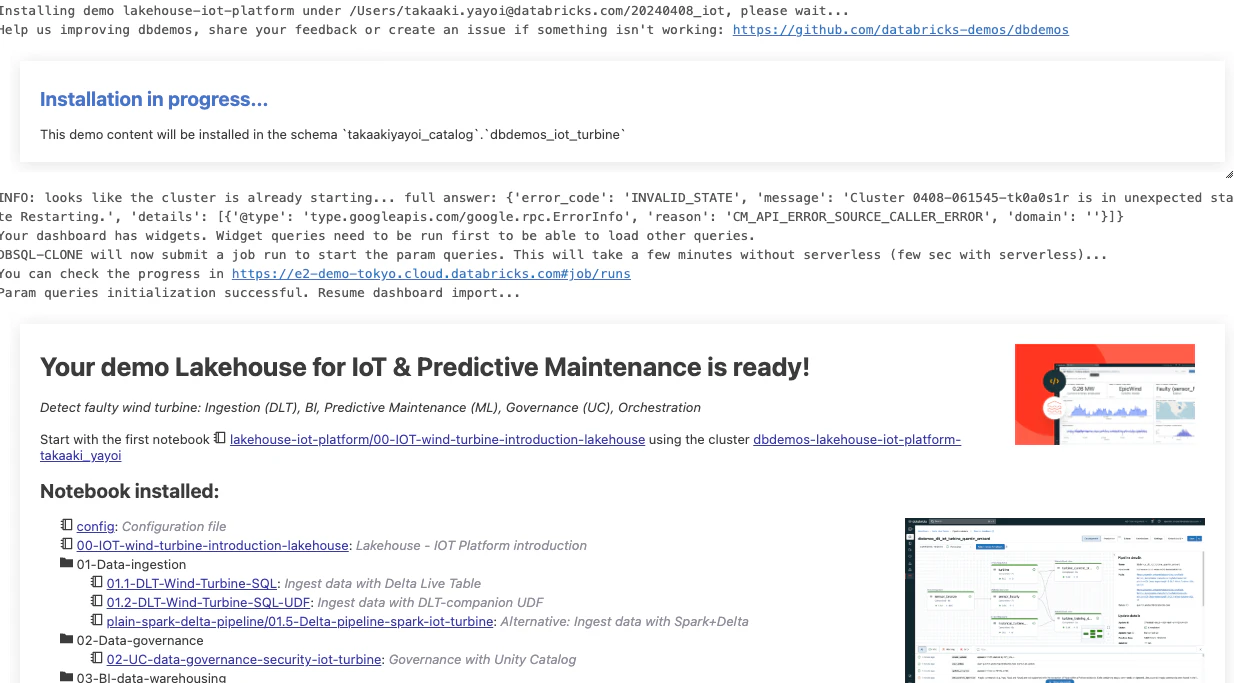
ノートブックやジョブなどが作成され、ジョブも実行されますので以下のメッセージに注意してください。ジョブが完了するまでお待ちください。


ジョブが完了するとテーブルなどが作成されます。
ノートブックのウォークスルー
上のインストールを行うと複数のノートブックが作成されますが、ここでは概要を説明している00-IOT-wind-turbine-introduction-lakehouseと、データパイプラインを実装している01.1-DLT-Wind-Turbine-SQL、予兆保全モデル構築を行っている04.1-automl-iot-turbine-predictive-maintenanceをウォークスルーします。
00-IOT-wind-turbine-introduction-lakehouse
このノートブックは全体像の説明のためのもので実行する必要はありませんが、ご一読をお勧めします。
DatabricksインテリジェンスデータプラットフォームによるIoTプラットフォーム - リアルタイム分析のための産業センサーデータの取り込み

IoT & 製造におけるDatabricksインテリジェンスデータプラットフォームとは?
皆様のすべてのソースからのすべてのデータの活用を可能にする唯一のエンタープライズデータプラットフォームであり、低コストでリアルタイムデータを用いて製造ラインを最適化するために様々なワークロードを実行することができます。
レイクハウスによって、IoTリアルタイムストリームから在庫情報や売り上げデータに至るすべてのデータを集中管理することができ、かつては不可能であった大規模でのオペレーションの高速化と効率を実現します。
シンプル
イノベーションを加速し、リスクを削減するための、データウェアハウスやAIに対する単一のプラットフォームとガバナンス/セキュリティレイヤーとなります。分散したガバナンスや高い複雑性を伴う複数のソリューションを組み合わせる必要はありません。
オープンオープンソース、オープン標準の上に構築されています。さまざまなサードパーティベンダーやサービスとの容易なインテグレーションを通じて、ご自身のデータを保持し、ベンダーロックインを回避します。また、オープンであることによって、お使いのソフトウェアスタックやベンダーに関係なく、いかなる外部組織とのデータ共有が可能となります。
マルチクラウド
クラウド横断で一貫したデータプラットフォームです。必要とする、あるいはデータが存在する場所で処理できます。
Databricksインテリジェンスデータプラットフォームによる風力タービンの予兆保全

エネルギー業界においては、装置情報をリアルタイムで収集、集中管理できることが重要となります。風力タービンがダウンした際には、電力を生成することができず、貧弱なカスタマーサービスや収益の損失につながることになります。エネルギーの最適化、異常検知、予兆保全のような重要な能力を解放するにはデータが鍵となります。
予兆保全の例には以下のようなものがあります:
- エネルギーパイプラインにおける機械故障の予測
- 生産ラインにおける異常な挙動の検知
- 部品のサプライチェーンの最適化、予定されたメンテナンスや補修の計画
デモの内容
このデモでは、エンドツーエンドのIoTプラットフォームを構築し、リアルタイムで複数のソースからデータを収集します。
この情報に基づき、エネルギーの生産効率を高めるために、データアナリストはどのようにして障害の前に風力タービンの以上をプロアクティブに検知し、補修を計画することができるのかを説明します。
さらに、タービンのメンテナンスチームがタービンを監視し、現時点でどのタービンが稼働していないのか、障害のリスクにあるのかを特定できるようにするためのダッシュボードをビジネスサイドが要求するものとします。これによって、ROIを追跡し、年間を通じての生産性のゴールを達成することができます。
ハイレベルにおいては、以下のフローを実装します:

- SQLを通じてデータを取り込み、IoTデータベースと容易にクエリーできるテーブルを作成
- データを保護し、データアナリスト、データサイエンスチームに対するアクセス権を付与
- 既存の障害を解析するためにBIクエリーを実行
- 風力タービンファームを監視し、予兆保全オペレーションを実行するためのMLモデルの構築
どのタービンに障害が生じる可能性があるのかを予測できるようになることは、風力タービンファームの効率性を向上させる最初の一歩に過ぎません。潜在的なメンテナンスを予測するモデルを構築できるようになることで、スペアパーツの在庫を動的に適応させることができ、メンテナンスチームに自動で適切な装置を割り当ててディスパッチできるようになります。
データセット
このデモをシンプルにするために、外部システムが定期的にデータをblobストレージ(S3/ADLS/GCS)に送信するものとします:
- タービンデータ (位置、モデル、IDなど)
- 毎秒の風力タービンのセンサーデータ (生成エネルギー、振動のストリーミング)
- 分析チームによってラベル付けされたタービンの状態の時系列変化 (モデルをトレーニングする際に使用する履歴データ)
技術的なレベルにおいては、さまざまなソースからデータが取り込まれることに注意してください。Databricksはいかなるシステムからもデータを取り込むことができます。(SalesForce, Fivetran, queuing message like kafka, blob storage, SQL & NoSQL databases...)。
センサーデータの分析や予兆保全の実行のために、レイクハウスでどのようにデータを活用できるのかを見ていきましょう。
1/ データの取り込みと準備 (データエンジニアリング)

最初のステップは、データアナリストチームが分析をスタートできるように、受信した生データを取り込んできれいにすることです。
Delta Lake
レイクハウスで作成するすべてのテーブルはDelta Lakeテーブルとして格納されます。Delta Lakeは信頼性とパフォーマンスのためのオープンストレージフレームワークです。
(ACIDトランザクション, DELETE/UPDATE/MERGE, Clone zero copy, Change data Capture...) のようなさまざまな機能を提供します。
Delta Lakeの詳細については、dbdemos.install('delta-lake')を実行してください。
Delta Live Tables (DLT)による取り込みの簡素化
DatabricksではSQLユーザーがバッチやストリーミングで高度なパイプラインを作成できるようにすることで、データの取り込みや変換処理をシンプルにします。また、皆様がビジネスニーズにフォーカスできるように、Databricksではパイプラインの開発、テスト、データ品質の追跡をシンプルにしており、オペレーションの複雑性を削減します。
3/ 障害の分析 (BI / データウェアハウス / SQL)


我々のデータセットは適切に取り込まれ、保護されており、高品質かつ企業内で容易に発見できるようになっています。
これによって、データアナリストは低レーテンシーかつ高スループットのBIインタラクティブクエリーを実行する準備が整ったことになります。新規の計算クラスターを作成するか、共有クラスターを活用するか、あるいはさらに高速なレスポンス時間のために、即座の停止と起動を実現するDatabricksサーバレスデータウェアハウスを活用することができます。
Databricksでどのようにデータウェハウスを活用できるのかを見てみましょう!Databricksはデータ取り込みから分析だけではなく、PowerBI、Tabelauなどの人気のBIツールとのインテグレーションをも提供する完全なデータプラットフォームなので、ビルトインのダッシュボードも提供しています!
予測結果に基づいてタービン障害を削減するためのアクションの自動化

これで、センサーデータを分析し、障害発生前に潜在的な障害を検知するエンドツーエンドのデータパイプラインを手に入れました。これによって、以下のような障害を削減するためのアクションを取ることが可能となります:
- チームの空き状態と障害の重要度に基づいたメンテナンス計画
- 手元の在庫を抑えつつも、予兆保全オペレーションに合わせた部品と補充の割り当て
- 回復性を改善するための過去の問題とコンポーネントの障害の分析
- モデルの効率とROIを計測することによる予兆保全モデルの効率性の追跡
注意: これらのアクションはこのデモのスコープ外であり、MLモデルの予兆保全の結果をシンプルに活用するのみとなっています。
5/ 完全なワークフローのデプロイとオーケストレーション

我々のデータパイプラインはほぼ完成しましたが、最後のステップが抜けています: プロダクションにおけるすべてのワークフローのオーケストレーションです。
Databricksレイクハウスを用いることで、ジョブを実行するための外部のオーケストレーターを活用する必要はありません。Databricksワークフローは、高度なアラート、監視、分岐のオプションなどによってすべてのジョブをシンプルにします。
まとめ
単一かつ統合されセキュアなプラットフォームであるレイクハウスを用いて、どのようにエンドツーエンドのパイプラインを実装するのかを説明しました。ここでは以下を見てきました:
- データ取り込み
- データ分析 / DW / BI
- データサイエンス / ML
- ワークフロー & オーケストレーション
結果として、ビジネス分析チームは障害をより理解するだけではなく、未来の障害を予測し、それに応じたアクションを取ることを可能にするシステムを構築できるようになりました。
これはDatabricksプラットフォームの紹介に過ぎません。詳細については、アカウントチームにコンタクトいただき、dbdemos.list()でより多くのデモを探索してみてください!
01.1-DLT-Wind-Turbine-SQL
こちらのノートブックはDelta Live Tablesで実行され、以下のようなパイプラインが構築・実行されます。

Databricksによるデータエンジニアリング - 製造業IOTプラットフォームの構築
IOTプラットフォームの構築では、複数のデータソースからの取り込みが必要となります。
リアルタイム監視などで使用されるリアルタイムの洞察をサポートするために、バッチロードとストリーミング取り込みの両方を必要とする複雑なプロセスです。
後段のユーザー(データアナリスト、データサイエンティスト)のためにのクリーンなSQLテーブルを作成するためのデータの取り込み、変換、クレンジングは複雑です。
 データエンジニアのJohnは膨大な時間を費やしています…。
データエンジニアのJohnは膨大な時間を費やしています…。
- データの取り込みと変換処理を手でコーディングしており、技術的課題に対応しています:
- ストリーミングとバッチのサポート、同時実行オペレーション、小さなファイル問題、GDPR要件、複雑なDAG依存関係への対応...*
- 品質とテストを強制するカスタムフレームワークの構築
- スケーラブルなインフラストラクチャ、観測可能性、モニタリングの構築とメンテナンス
- 異なるシステムの互換性のないガバナンスの管理
これは、オペレーションの複雑性、オーバーヘッドに繋がり、専門家を必要とし、最終的にはプロジェクトにデータを配置することがリスクとなります。
Delta Live Tablesでデータ取り込みと変換をシンプルに

このノートブックでは、IOTプラットフォームを構築するためにデータエンジニアとして作業します。
BI & MLワークロードに必要なテーブルを準備するために生のデータソースを取り込んでクレンジングします。
Databricksは、誰でもデータエンジニアリングにアクセスできるようにすることで、Delta Live Table (DLT)によってこのタスクをシンプルにします。
DLTによって、データアナリストは簡素なSQLを用いて高度なパイプラインを作成できるようになります。
Delta Live Table: 新鮮で高品質なデータのためのデータパイプラインを構築、管理するためのシンプルな方法!

ETL開発の加速
シンプルなパイプライン開発とメンテナンスによってアナリストとデータエンジニアが迅速なイノベーションを可能に

オペレーションの複雑性の排除
複雑な管理タスクを自動化し、広範な可視性をパイプラインオペレーションに提供

データへの信頼
正確で有用なBI、データサイエンス、MLを確実にするための、ビルトインの品質コントロールと品質モニタリング

バッチとストリーミングの簡素化
バッチやストリーミング処理のための自己最適化、オートスケーリングのデータパイプライン
Delta Lake
レイクハウスで作成するすべてのテーブルはDelta Lakeテーブルとして格納されます。Delta Lakeは信頼性とパフォーマンスのためのオープンストレージフレームワークです。
(ACIDトランザクション, DELETE/UPDATE/MERGE, Clone zero copy, Change data Capture...) のようなさまざまな機能を提供します。
Delta Lakeの詳細については dbdemos.install('delta-lake') を実行してください。
IOTセンサーデータを取り込み、故障している装置を検知するためのDelta Live Tableパイプラインの構築
このサンプルでは、風力タービンのセンサーデータを処理するエンドツーエンドのDLTパイプラインを実装します。ここではメダリオンアーキテクチャを採用しますが、スタースキーマ、データボルト、その他のモデル手法を活用することもできます。
オートローダーを用いて新規データをインクリメンタルにロードし、この情報を補強し、予兆保全分析を行うためにMLflowからモデルをロードします。
そして、この情報は、潜在的なダウンタイムを削減するために、風力タービンファームの状態、故障した装置のインパクト、推奨事項を追跡するためのDBSQLダッシュボードを構築するために活用されます。
データセット:
- タービンのメタデータ: タービンID, 位置 (タービンごとに1行)
- タービンのセンサーストリーム: 風力タービンセンサーからのリアルタイムストリーミングフロー (振動、生成エネルギー、スピードなど)
- タービンのステータス: どのパーツが故障したのかを分析することで得られたタービンステータスの履歴 (MLモデルのラベルとして使用)
以下のフローを実装しましょう:
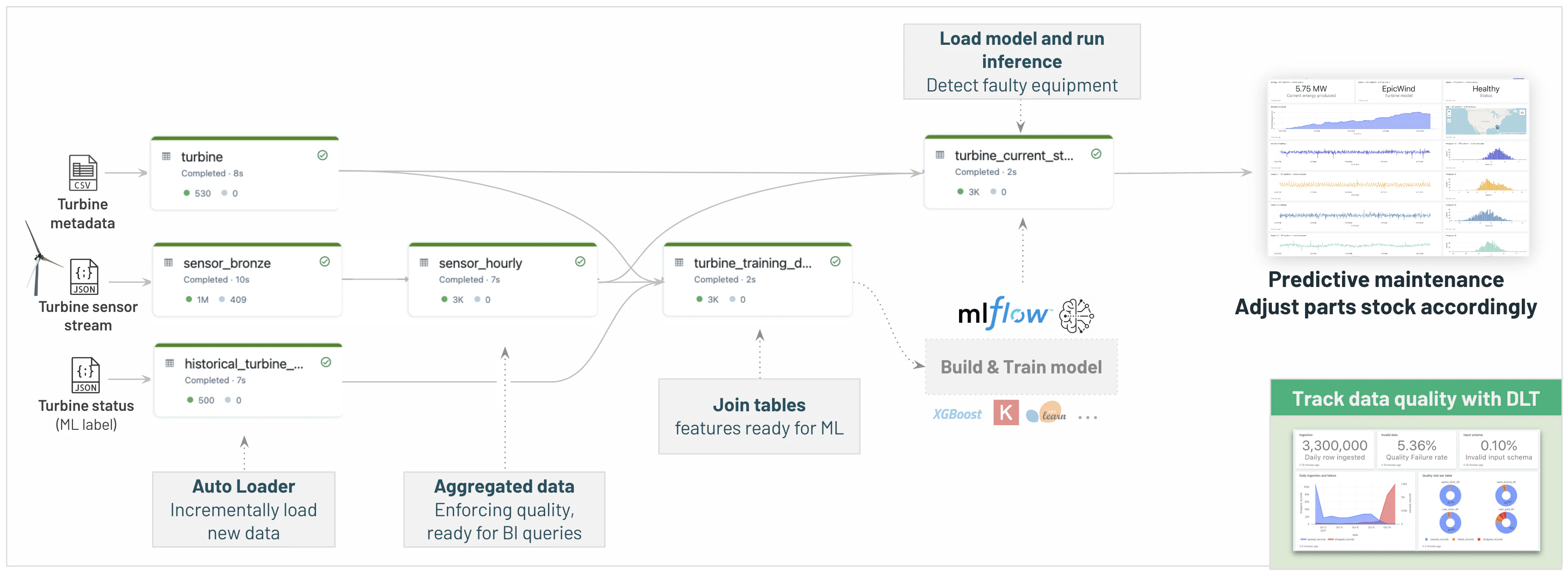
障害を予測するために、データサイエンティストが04-Data-Science-ML/04.1-automl-predictive-maintenance-turbineで構築したMLモデルを含めていることに注意してください。これは次のセクションでカバーします。
あなたのためにDLTパイプラインがインストールされ起動しています!動作している様子を確認するには、IOT Wind Turbine Delta Live Table pipelineをオープンしてください。
(注意: このパイプラインはdbdemosによって初期化ジョブが完了すると自動でスタートし、これには数分を要します。詳細はインストールログを確認してください)
風力タービンのメタデータ
%python
display(spark.read.json('/Volumes/takaakiyayoi_catalog/dbdemos_iot_turbine/turbine_raw_landing/turbine'))
display(spark.read.json('/Volumes/takaakiyayoi_catalog/dbdemos_iot_turbine/turbine_raw_landing/historical_turbine_status')) #Historical turbine status analyzed
風力タービンのセンサーデータ
%python
display(spark.read.parquet('/Volumes/takaakiyayoi_catalog/dbdemos_iot_turbine/turbine_raw_landing/incoming_data'))
1/ データの取り込み: Auto Loader (cloudFiles)によるデータの取り込み

ストリームソースからのデータ取り込みは困難です。このサンプルでは、クラウドストレージからファイルをインクリメンタルにロードし、新規のものだけを(ニアリアルタイムあるいは数時間周期で)取得します。
ここではクラウドストレージにストリーミングデータが追加されますが、kafkaから直接データを容易に取り込めることに注意してください: .format(kafka)
Auto-loaderは以下を提供します:
- スキーマ推定と進化
- 数百万ファイルに対応できるスケーラビリティ
- シンプルさ: 取り込みフォルダーを指定するだけで、Databricksが残りの面倒を見ます!
AutoLoaderの詳細については、dbdemos.install('auto-loader')を実行して下さい。
パイプラインで活用して、blobストレージ/demos/manufacturing/iot_turbine/...に配信される生のJSON & CSVのデータを取り込みましょう。
タービンのメタデータ
CREATE STREAMING TABLE turbine (
CONSTRAINT correct_schema EXPECT (_rescued_data IS NULL)
)
COMMENT "Turbine details, with location, wind turbine model type etc"
AS SELECT * FROM cloud_files("/Volumes/takaakiyayoi_catalog/dbdemos_iot_turbine/turbine_raw_landing/turbine", "json", map("cloudFiles.inferColumnTypes" , "true"))
風力タービンセンサー
CREATE STREAMING TABLE sensor_bronze (
CONSTRAINT correct_schema EXPECT (_rescued_data IS NULL),
CONSTRAINT correct_energy EXPECT (energy IS NOT NULL and energy > 0) ON VIOLATION DROP ROW
)
COMMENT "Raw sensor data coming from json files ingested in incremental with Auto Loader: vibration, energy produced etc. 1 point every X sec per sensor."
AS SELECT * FROM cloud_files("/Volumes/takaakiyayoi_catalog/dbdemos_iot_turbine/turbine_raw_landing/incoming_data", "parquet", map("cloudFiles.inferColumnTypes" , "true"))
ステータスの履歴
CREATE STREAMING TABLE parts
COMMENT "Turbine parts from our manufacturing system"
AS SELECT * FROM cloud_files("/Volumes/takaakiyayoi_catalog/dbdemos_iot_turbine/turbine_raw_landing/parts", "json", map("cloudFiles.inferColumnTypes" , "true"))
2/ 集計処理: 時間レベルにセンサーデータをマージ
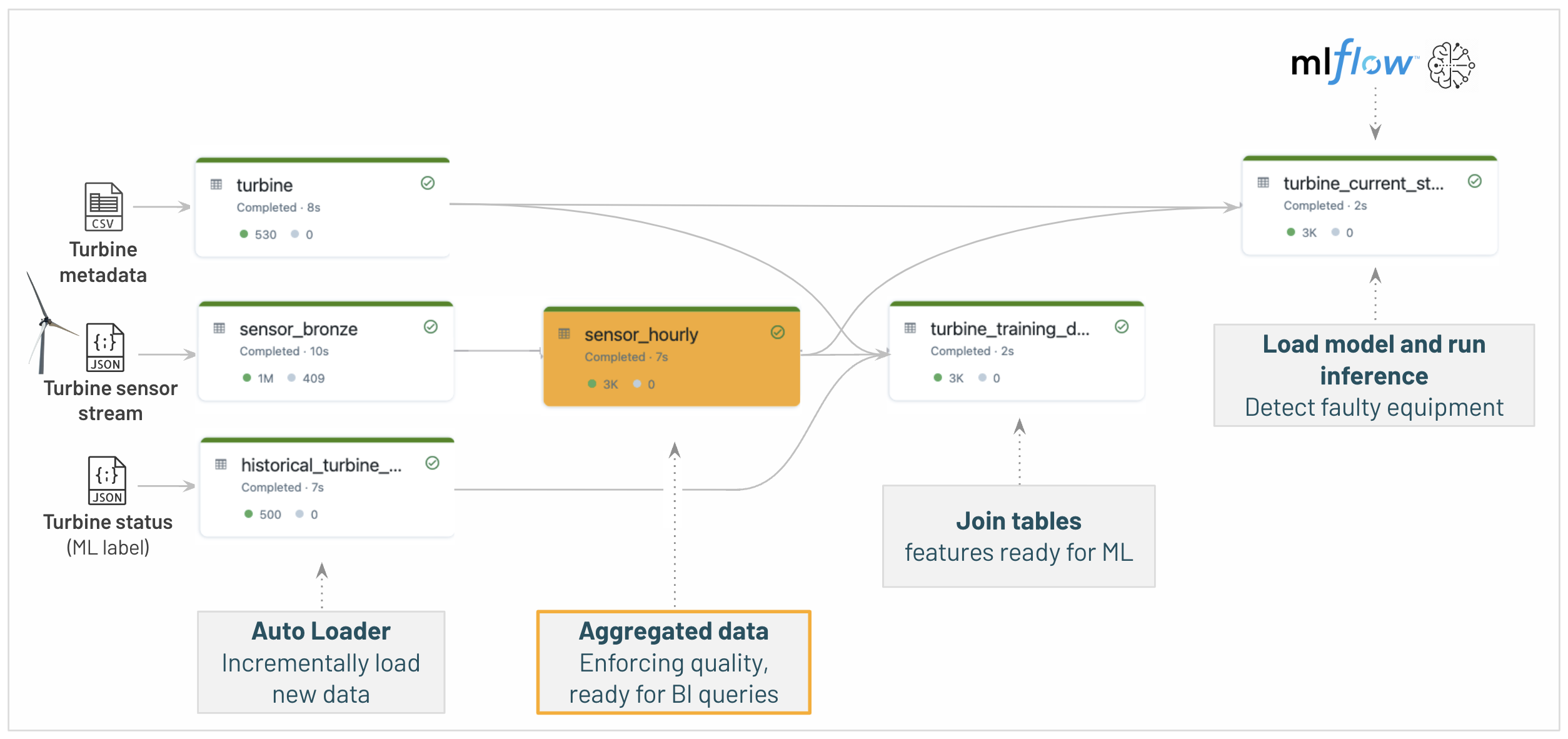
データを分析できるようにするために、標準偏差や四分位数のような統計メトリクスを時間単位で計算します。
この例をシンプルにするためにすべてのテーブルを再計算していることに注意してください。ステートフルな集計処理を用いて、現在時刻のUPSERTを行うことも可能です
CREATE LIVE TABLE sensor_hourly (
CONSTRAINT turbine_id_valid EXPECT (turbine_id IS not NULL) ON VIOLATION DROP ROW,
CONSTRAINT timestamp_valid EXPECT (hourly_timestamp IS not NULL) ON VIOLATION DROP ROW
)
COMMENT "Hourly sensor stats, used to describe signal and detect anomalies"
AS
SELECT turbine_id,
date_trunc('hour', from_unixtime(timestamp)) AS hourly_timestamp,
avg(energy) as avg_energy,
stddev_pop(sensor_A) as std_sensor_A,
stddev_pop(sensor_B) as std_sensor_B,
stddev_pop(sensor_C) as std_sensor_C,
stddev_pop(sensor_D) as std_sensor_D,
stddev_pop(sensor_E) as std_sensor_E,
stddev_pop(sensor_F) as std_sensor_F,
percentile_approx(sensor_A, array(0.1, 0.3, 0.6, 0.8, 0.95)) as percentiles_sensor_A,
percentile_approx(sensor_B, array(0.1, 0.3, 0.6, 0.8, 0.95)) as percentiles_sensor_B,
percentile_approx(sensor_C, array(0.1, 0.3, 0.6, 0.8, 0.95)) as percentiles_sensor_C,
percentile_approx(sensor_D, array(0.1, 0.3, 0.6, 0.8, 0.95)) as percentiles_sensor_D,
percentile_approx(sensor_E, array(0.1, 0.3, 0.6, 0.8, 0.95)) as percentiles_sensor_E,
percentile_approx(sensor_F, array(0.1, 0.3, 0.6, 0.8, 0.95)) as percentiles_sensor_F
FROM LIVE.sensor_bronze GROUP BY hourly_timestamp, turbine_id
3/ MLエンジニアが活用するテーブルの構築: センサーの集計値をタービンのメタデータとステータス履歴とjoin

次に、センサーの集計値とタービン情報をjoinして最終テーブルを構築します。
このテーブルには、潜在的なタービンの呼称を推定するのに必要なすべてのデータが含まれています。
CREATE LIVE TABLE turbine_training_dataset
COMMENT "Hourly sensor stats, used to describe signal and detect anomalies"
AS
SELECT * except(t._rescued_data, s._rescued_data, m.turbine_id) FROM LIVE.sensor_hourly m
INNER JOIN LIVE.turbine t USING (turbine_id)
INNER JOIN LIVE.historical_turbine_status s ON m.turbine_id = s.turbine_id AND from_unixtime(s.start_time) < m.hourly_timestamp AND from_unixtime(s.end_time) > m.hourly_timestamp
4/ モデルレジストリからモデルを取得し、故障タービンにフラグ付け

データサイエンティストチームは上述のテーブルからデータを読み込み、AutoMlを用いて予兆保全モデルを構築し、Databricksのモデルレジストリにモデルを保存できるようになっています(次のセクションでどのように行うのかを説明します)。
レイクハウスの価値の一つは、タービン故障を予測するこのモデルを容易かつ直接パイプラインにロードできるということです。
モデルのフレームワーク(sklearnなど)を心配する必要がなく、MLflowがそれらを抽象化してくれることに注意してください。
しなくてはならないのは、モデルをロードしてSQL(あるいはPython)関数として呼び出すことだけです。
モデルをロードしてSQL関数として保存
%python
import mlflow
mlflow.set_registry_uri('databricks-uc')
# Stage/version
# Model name |
# | |
predict_maintenance_udf = mlflow.pyfunc.spark_udf(spark, "models:/takaakiyayoi_catalog.dbdemos_iot_turbine.dbdemos_turbine_maintenance@prod", "string") #, env_manager='virtualenv'
spark.udf.register("predict_maintenance", predict_maintenance_udf)
#Note that this cell is just as example (dlt will ignore it), python needs to be on a separate notebook and the real udf is declared in the companion UDF notebook
CREATE LIVE TABLE turbine_current_status
COMMENT "Wind turbine last status based on model prediction"
AS
WITH latest_metrics AS (
SELECT *, ROW_NUMBER() OVER(PARTITION BY turbine_id, hourly_timestamp ORDER BY hourly_timestamp DESC) AS row_number FROM LIVE.sensor_hourly
)
SELECT * EXCEPT(m.row_number),
predict_maintenance(hourly_timestamp, avg_energy, std_sensor_A, std_sensor_B, std_sensor_C, std_sensor_D, std_sensor_E, std_sensor_F, percentiles_sensor_A, percentiles_sensor_B, percentiles_sensor_C, percentiles_sensor_D, percentiles_sensor_E, percentiles_sensor_F, location, model, state) as prediction
FROM latest_metrics m
INNER JOIN LIVE.turbine t USING (turbine_id)
WHERE m.row_number=1
まとめ
我々のDLT Data Pipelineは純粋なSQLを用いて利用できるようになりました。エンドツーエンドのサイクルを手に入れ、データエンジニアリングチームによってMLモデルをシームレスに連携されました。
モデルトレーニングの詳細については、モデルトレーニングノートブック04-Data-Science-ML/04.1-automl-iot-turbine-predictive-maintenanceをオープンしてください。
最終的なデータセットには、予兆保全ユースケースのためのML予測結果が含まれています。
これで、全体的な風力タービンファームの主要なKPIやステータスを追跡するためのDBSQL Dashboardと、Predictive maintenance DBSQL Dashboardを構築する準備が整いました。
04.1-automl-iot-turbine-predictive-maintenance
このノートブックでは機械学習モデルの構築に必要な特徴量を準備し、AutoMLでのモデル構築を説明しています。
Databricksによるデータサイエンス
MLは風力タービンファームの最適化の鍵となります
現在の市場環境は、これまで以上にエネルギーを戦略的なものにしています。風力タービンの状態を取り込んで分析できるようにすることが第一歩でしたが、非常に競争の激しい市場で成功するには十分ではありません。
エネルギー生産をさらに最適化し、メンテナンスコストとダウンタイムを削減する必要があります。モダンなデータカンパニーはAIによってこれを達成しています。

機械学習はデータ + 変換処理です。
ビジネスラインに価値を提供することはモデルを構築することだけではないので、MLは難しいものとなっています。
MLライフサイクルは複数のデータパイプラインから構成されます: データの前処理、特徴量エンジニアリング、トレーニング、推論、モニタリングや再トレーニング...
一歩引くとすべてのパイプラインはデータ + コードとなります。

 データサイエンティストのMarcはすべてのML & DSステップを加速するデータ + MLのプラットフォームを必要としています:
データサイエンティストのMarcはすべてのML & DSステップを加速するデータ + MLのプラットフォームを必要としています:
- (DLTによる)リアルタイムをサポートするデータパイプラインの構築
- データ探索
- 特徴量の作成
- モデルの構築 & トレーニング
- モデルのデプロイ (バッチやサーバレスリアルタイム)
- モニタリング
Marcはレイクハウスを必要としています。レイクハウスでどのようにして予兆保全モデルをプロダクションにデプロイできるのかを見ていきましょう。
予兆保全 - AutoMLによるシングルクリックでのデプロイメント
予兆保全モデルを構築するためにどのようにセンサーデータを活用できるのかを見てみましょう。
データサイエンティストとしての第一歩は、モデルのトレーニングに使用する特徴量を分析して構築するということです。
タービンデータで拡張されたセンサーテーブルはDelta Live Tableパイプラインに保存されます。やらなくてはいけないことは、この情報を読み込んで分析し、AutoMLのランを実行するということです。

%pip install databricks-sdk==0.17.0
dbutils.library.restartPython()
%run ../_resources/00-setup $reset_all_data=false
データ探索と分析
データセットを確認し、故障を予測するための分析をスタートしましょう。
Pandas on Sparkを用いたクイックなデータ探索: 2つの風力タービンのセンサー
def plot(sensor_report):
turbine_id = spark.table('turbine_training_dataset_ml').where(f"abnormal_sensor = '{sensor_report}' ").limit(1).collect()[0]['turbine_id']
#Let's explore a bit our datasets with pandas on spark.
df = spark.table('sensor_bronze_ml').where(f"turbine_id == '{turbine_id}' ").orderBy('timestamp').pandas_api()
df.plot(x="timestamp", y=["sensor_B"], kind="line", title=f'Sensor report: {sensor_report}').show()
plot('ok')
plot('sensor_B')

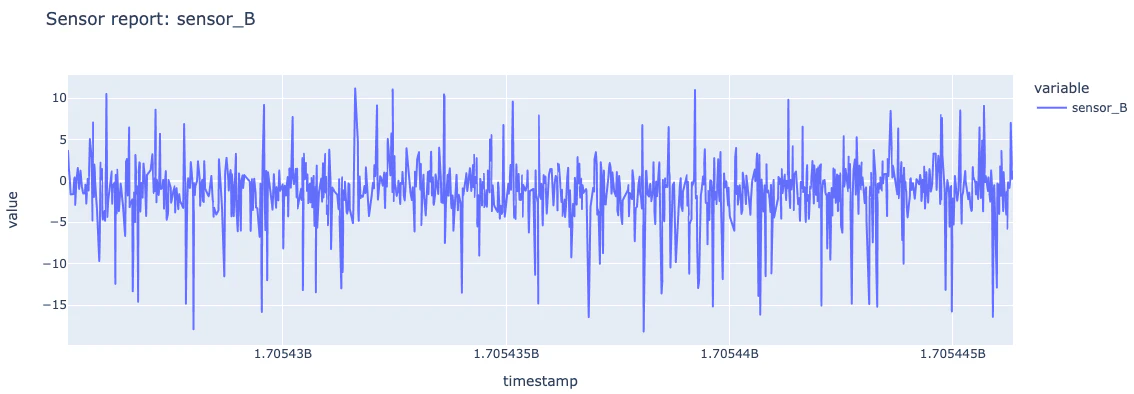
これらのグラフから分かるように、センサーの読み取り値からいくつかの異常を明確に確認できます。探索を継続し、我々の主要な特徴量テーブルでstdを活用しましょう。
# Read our churn_features table
turbine_dataset = spark.table('turbine_training_dataset_ml').withColumn('damaged', col('abnormal_sensor') != 'ok')
display(turbine_dataset)
ダメージのあるセンサーでは明確に異なる分布となっています
import seaborn as sns
g = sns.PairGrid(turbine_dataset.sample(0.01).toPandas()[['std_sensor_A', 'std_sensor_E', 'damaged','avg_energy']], diag_sharey=False, hue="damaged")
g.map_lower(sns.kdeplot).map_diag(sns.kdeplot, lw=3).map_upper(sns.regplot).add_legend()

pandas APIを用いた追加のデータ分析とデータ準備
データサイエンティストチームはPandasに慣れ親しんでいるので、pandasコードをスケールさせるためにpandas on sparkを活用しています。Pandasの命令は内部ではSparkエンジンで変換され、大規模に分散されます。
通常、データサイエンスプロジェクトには、より高度なデータ準備が含まれ、より複雑な特徴量の準備を含む追加のデータ準備ステップが必要となる場合があります。このデモではシンプルにしています。
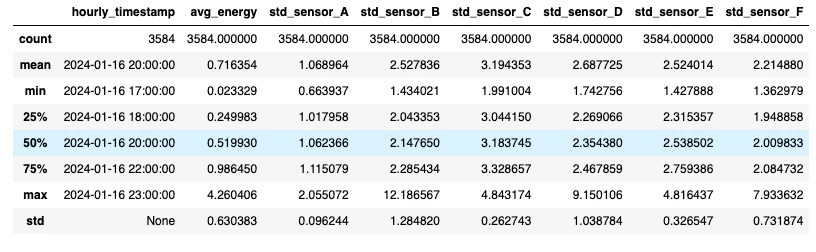
すべてのデータセットに対するカスタムのpandas変換処理
# Convert to pandas (koalas)
dataset = turbine_dataset.pandas_api()
# Drop columns we don't want to use in our model
dataset = dataset.drop(columns=['end_time', 'start_time', '_rescued_data', 'country', 'lat', 'long', 'damaged'])
# Drop missing values
dataset = dataset.dropna()
dataset.describe()
Feature Storeへの書き込み (オプション)

特徴量の準備が整ったのでDatabricks Feature Storeに格納します。内部では、Feature Storeの背後にはDelta Lakeテーブルがあります。
これによって、企業における特徴量の発見可能性や再利用可能性を実現し、チームの効率性を改善します。
Feature Storeは我々のデプロイメントにおけるトレーサビリティやガバナンスを提供し、どのモデルが特徴量セットに依存しているのかを知ることができます。また、リアルタイムサービングをシンプルにします。
from databricks.feature_store import FeatureStoreClient
fs = FeatureStoreClient()
try:
#drop table if exists
fs.drop_table(f'{catalog}.{db}.turbine_hourly_features')
except:
pass
#Note: You might need to delete the FS table using the UI
churn_feature_table = fs.create_table(
name=f'{catalog}.{db}.turbine_hourly_features',
primary_keys=['turbine_id','hourly_timestamp'],
schema=dataset.spark.schema(),
description='These features are derived from the turbine_training_dataset table in the lakehouse. We made some basic transformations and removed NA value.'
)
fs.write_table(df=dataset.to_spark(), name=f'{catalog}.{db}.turbine_hourly_features', mode='overwrite')
features = fs.read_table(f'{catalog}.{db}.turbine_hourly_features')
display(features)
MLFlowとDatabricks AutoMLを用いた予兆保全モデル作成の加速
MLflowはモデルのトラッキング、パッケージング、デプロイメントを可能にするオープンソースプロジェクトです。データサイエンティストチームがモデルを操作する際には、Databricksが常に使用されたすべてのパラメータ、データをトラッキングし保存します。これによって、MLのトレーサビリティや再現可能性を確実なものにし、どのモデルがどのパラメータ/データを用いて構築されたのかを容易に知ることができるようになります。
データチームがコントロールを失うことないように支援するガラスボックスソリューション
DatabricksではMlflowによってモデルのデプロイメントとガバナンス(MLOps)をシンプルにしますが、新規のMLプロジェクトを軌道に乗せることは依然として長い時間を要し、非効率的なものとなっています。
それぞれの新規プロジェクトで定型コードを記述することなしに、Databricks Auto-MLは自動で分類、回帰、予測のための最先端のモデルを自動で生成することができます。

直接モデルをデプロイしたり、ベストプラクティスを用いて生成されたノートブックでプロジェクトを推進することで、数週間の工数を削減します。
センサーデータにおけるDatabricks AutoMLの活用
スタートするために必要なのは、新規のAutoMLのエクスペリメントを作成し、これまでに作成した特徴量テーブル(turbine_hourly_features)を選択することだけです。
予測ターゲットはabnormal_sensorカラムとなります。
Startをクリックすると、Databricksが残りを実行します。
これはUIで行われていますが、python APIを活用することもできます。
こちらはすでに起動されているので探索することができます
from databricks import automl
xp_path = "/Shared/dbdemos/experiments/lakehouse-iot-platform"
xp_name = f"automl_iot_{datetime.now().strftime('%Y-%m-%d_%H:%M:%S')}"
automl_run = automl.classify(
experiment_name = xp_name,
experiment_dir = xp_path,
dataset = fs.read_table(f'{catalog}.{db}.turbine_hourly_features').drop('turbine_id'),
target_col = "abnormal_sensor",
timeout_minutes = 7
)
#Make sure all users can access dbdemos shared experiment
DBDemos.set_experiment_permission(f"{xp_path}/{xp_name}")
AutoMLはMLflowレジストリにベストなモデルを保存しています。アーティファクトや使用されたパラメーター、モデル作成に使用されたノートブックを含むトレーサビリティなどを探索するためにdbdemos_turbine_maintenanceをオープンします。
準備ができたら、クリックやAPIでProductionステージにモデルを投入します。
AutoMLで生成されたモデルは、潜在的なメンテナンスを必要とする風力タービンを検知するためにDLTパイプラインで使用することができます
これで、データエンジニアは容易にAutoMLによるモデルdbdemos_turbine_maintenanceを容易に取得し、Delta Live Tableパイプラインで異常を検知することができます。
どのように実施されるのかを知るためにDLTパイプラインを再度開いてみてください。
予兆保全の予測結果をベースとしてスペアの在庫を調整します
装置の障害確率を計測するだけではなく、メンテナンスを計画し、適切にスペアパーツの在庫を調整するためにダッシュボードでこれらの予測結果を再利用することができます。
レイクハウスで作成されたパイプラインは、強力なROIを提供します: このパイプラインのエンドツーエンドのセットアップには数時間のみを要しており、月間数百万ドルの潜在的メリットが得られています!
より高度なモデルデプロイメント (バッチやサーバレスリアルタイム)
また、モデルdbdemos_turbine_maintenanceを活用し、スタンドアローンのバッチやリアルタイム推論で予測処理を実行することができます!
ダッシュボードの探索
/dbdemos_dashboards/lakehouse-iot-platform配下にはdbdemosによってインストールされたダッシュボードが配備されています。最初のdbdemos.install('lakehouse-iot-platform'...)で起動したジョブが完了したら、IOT Platform - Turbine analysisやIOT Platform - Wind Turbine predictive maintenanceを確認します。
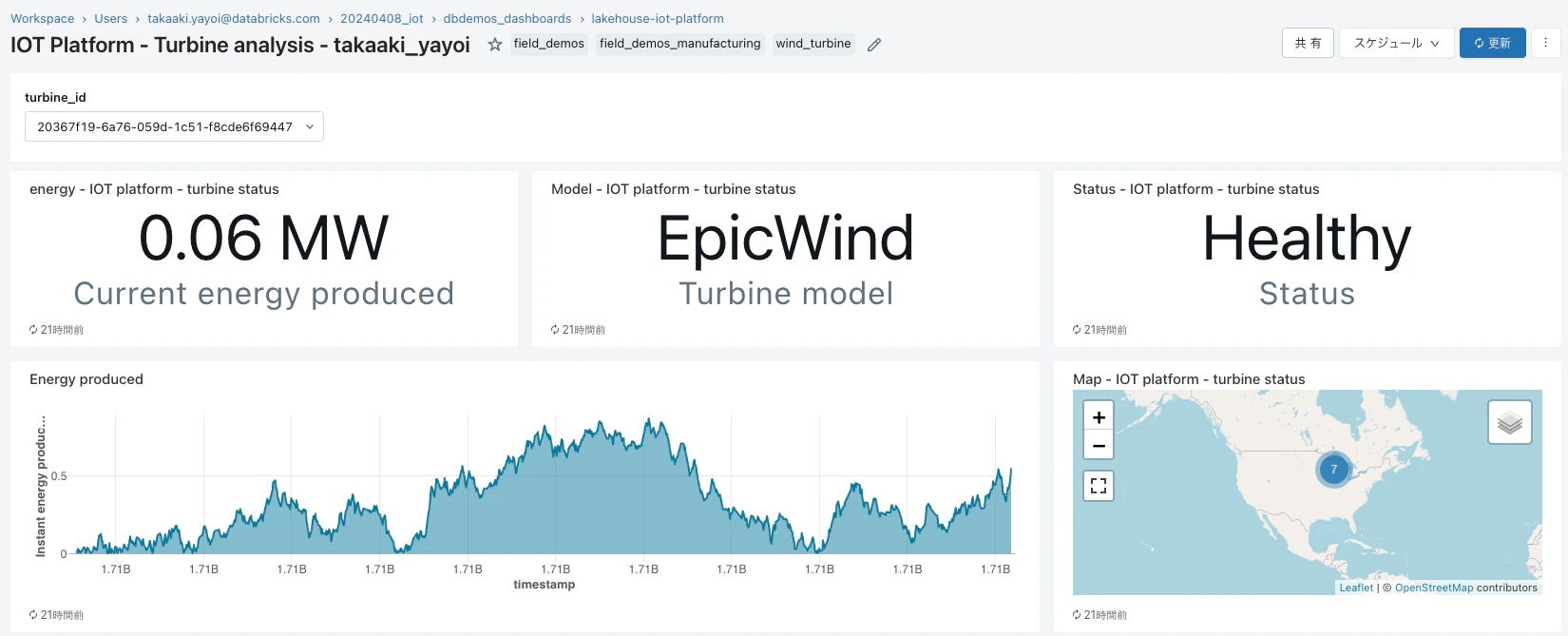
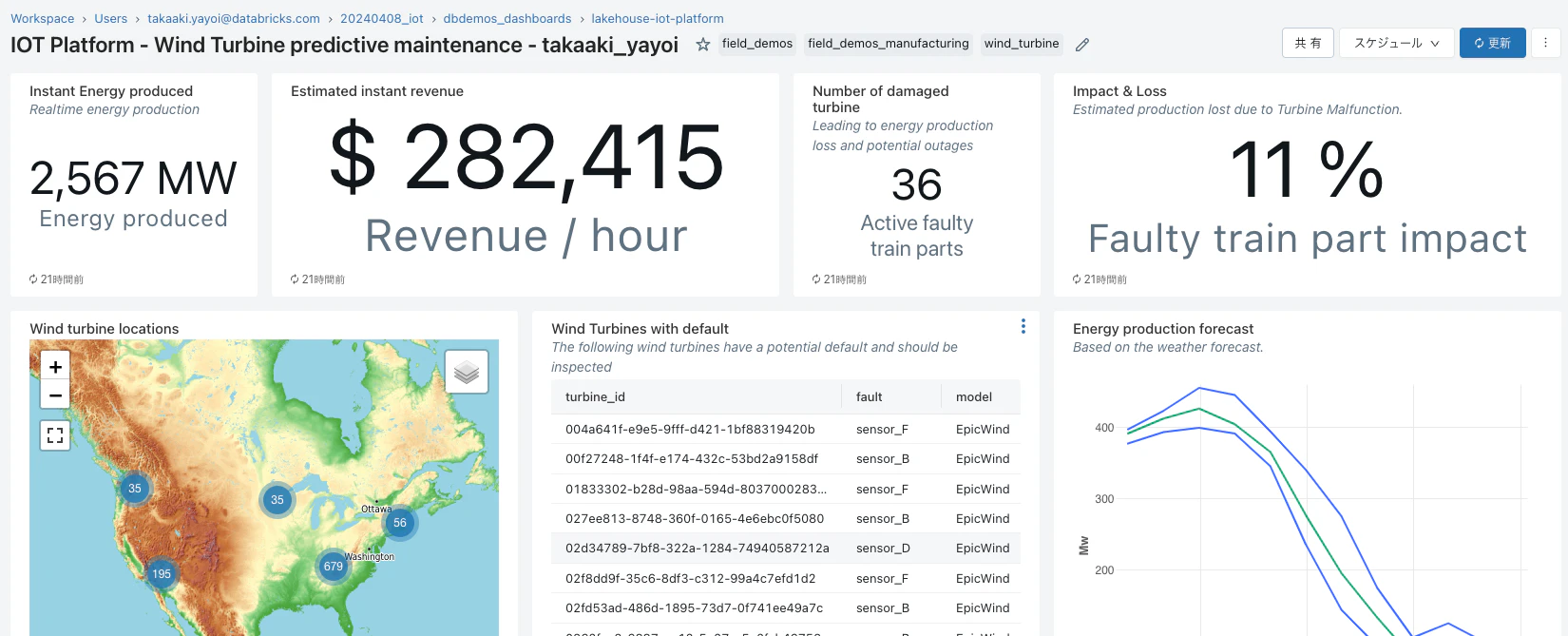
こちらの記事を参考にデモを動かしてみてください!