STORMは、スタンフォード大で研究されている生成AIを用いた文書記述のアプローチであり、Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Askingの略とのことです。検索と複数観点での質問を通じたトピックアウトラインの合成とでも訳しましょうか。
こちらで実装されているので動かします。
Web Research (STORM)
STORMは、Shaoらによって設計された研究アシスタントで、より豊かな記事生成のために「アウトライン駆動型RAG」のアイデアを拡張しています。
STORMは、ユーザーが提供したトピックに関するウィキペディアスタイルの記事を生成するように設計されています。より組織的で包括的な記事を生成するために、2つの主な洞察を適用します:
- 類似トピックをクエリすることによるアウトラインの作成(計画)は、カバレッジの向上に役立ちます。
- 多面的で、検索に基づいた会話シミュレーションは、参照数と情報密度を増加させるのに役立ちます。
制御フローは、以下の図のようになります。
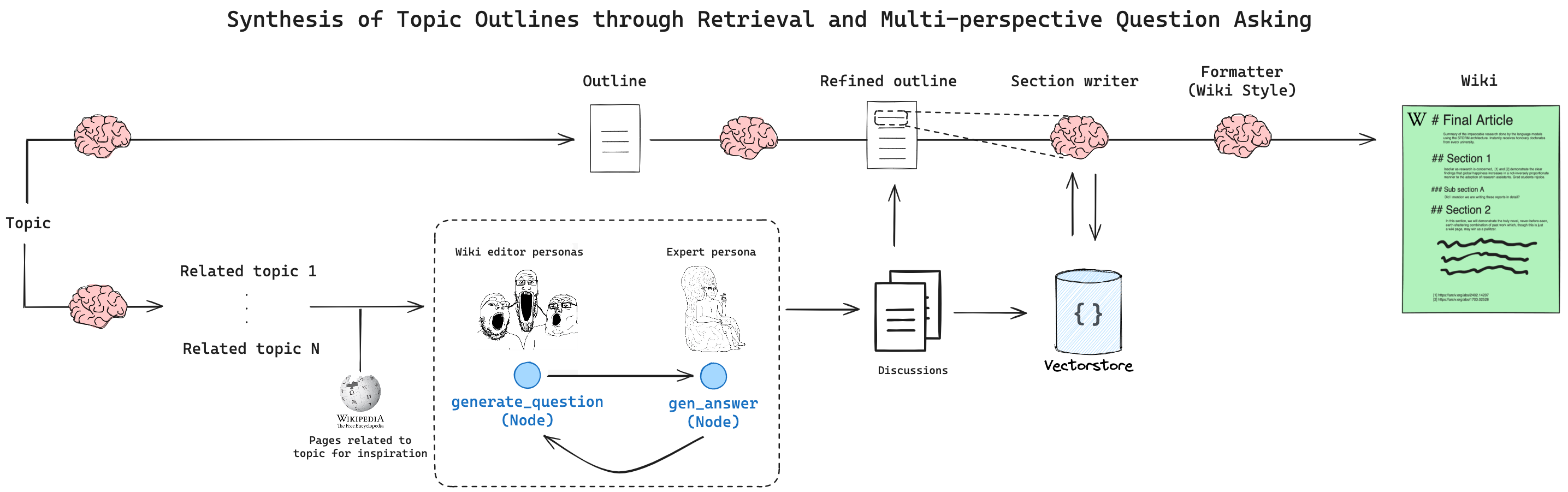
STORMにはいくつかの主要なステージがあります:
- 初期アウトラインの生成 + 関連トピックの調査
- 異なる視点の特定
- 「専門家へのインタビュー」(ロールプレイLLM)
- アウトラインの洗練(参照を使用)
- セクションを書き、記事を書く
専門家インタビューのステージは、ロールプレイ記事作成者と研究専門家の間で行われます。「専門家」は外部知識をクエリし、的を絞った質問に応じて回答することができ、引用されたソースをベクトルストアに保存することで、後の洗練ステージが完全な記事を合成できるようにします。
無限の研究の幅を制限するために設定できるいくつかのハイパーパラメータがあります:
- N: 調査する視点の数 / 使用する数(ステップ2->3)
- M: ステップ内の最大会話ターン数(ステップ3)
セットアップ
まず、必要なパッケージをインストールし、APIキーを設定しましょう。
%%capture --no-stderr
%pip install -U langchain_community langchain_openai langchain_fireworks langgraph wikipedia duckduckgo-search tavily-python mlflow
%restart_python
import os
os.environ["OPENAI_API_KEY"] = dbutils.secrets.get(scope="demo-token-takaaki.yayoi", key="openai_api_key")
os.environ["TAVILY_API_KEY"] = "TavilyのAPIキー"
MLflow Tracingを有効にします。
import mlflow
mlflow.langchain.autolog()
LLMの選択
私たちは、ほとんどの作業を行うために高速なLLMを使用しますが、会話を蒸留し、最終報告書を書くために遅い長文モデルを使用します。
from langchain_openai import ChatOpenAI
fast_llm = ChatOpenAI(model="gpt-4o-mini")
long_context_llm = ChatOpenAI(model="gpt-4o")
初期アウトラインの生成
多くのトピックについて、LLMは重要で関連するトピックの初期アイデアを持っているかもしれません。研究の後に洗練される初期アウトラインを生成できます。以下では、「高速」LLMを使用してアウトラインを生成します。
from typing import List, Optional
from langchain_core.prompts import ChatPromptTemplate
from pydantic import BaseModel, Field, field_validator
direct_gen_outline_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたはウィキペディアの作家です。ユーザーが提供したトピックについてのウィキペディアページのアウトラインを書いてください。包括的で具体的に。",
),
("user", "{topic}"),
]
)
class Subsection(BaseModel):
subsection_title: str = Field(..., title="小見出しのタイトル")
description: str = Field(..., title="小見出しの内容")
@property
def as_str(self) -> str:
return f"### {self.subsection_title}\n\n{self.description}".strip()
class Section(BaseModel):
section_title: str = Field(..., title="セクションのタイトル")
description: str = Field(..., title="セクションの内容")
subsections: Optional[List[Subsection]] = Field(
default=None,
title="ウィキペディアページの各小見出しのタイトルと内容。",
)
@property
def as_str(self) -> str:
subsections = "\n\n".join(
f"### {subsection.subsection_title}\n\n{subsection.description}"
for subsection in self.subsections or []
)
return f"## {self.section_title}\n\n{self.description}\n\n{subsections}".strip()
class Outline(BaseModel):
page_title: str = Field(..., title="ウィキペディアページのタイトル")
sections: List[Section] = Field(
default_factory=list,
title="ウィキペディアページの各セクションのタイトルと内容。",
)
@property
def as_str(self) -> str:
sections = "\n\n".join(section.as_str for section in self.sections)
return f"# {self.page_title}\n\n{sections}".strip()
generate_outline_direct = direct_gen_outline_prompt | fast_llm.with_structured_output(
Outline
)
example_topic = "ミリオンプラスのトークンコンテキストウィンドウ言語モデルがRAGに与える影響"
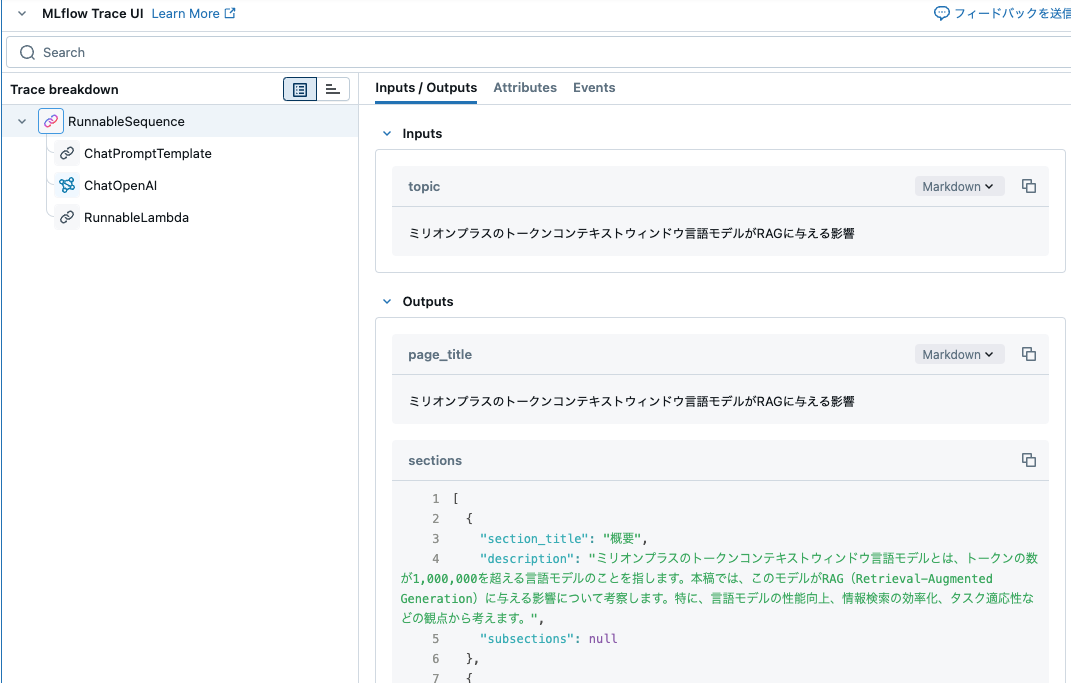
initial_outline = generate_outline_direct.invoke({"topic": example_topic})
print(initial_outline.as_str)

トピックの拡張
言語モデルはパラメータにウィキペディアのような知識を蓄積していますが、検索エンジンを使用して関連性の高い最新情報を取り入れることで、より良い結果が得られます。
ウィキペディアから得られた関連トピックのリストを生成することから検索を始めます。
gen_related_topics_prompt = ChatPromptTemplate.from_template(
"""私は以下に示すトピックのウィキペディアページを作成しています。関連する主題のウィキペディアページをいくつか特定し、推奨してください。このトピックに一般的に関連する興味深い側面を提供する例や、類似のトピックに関するウィキペディアページに含まれる典型的な内容と構造を理解するのに役立つ例を探しています。
できるだけ多くの主題とURLをリストしてください。
関心のあるトピック: {topic}
"""
)
class RelatedSubjects(BaseModel):
topics: List[str] = Field(
description="背景調査としての関連主題の包括的なリスト。",
)
expand_chain = gen_related_topics_prompt | fast_llm.with_structured_output(
RelatedSubjects
)
関連するトピックが生成されます。
related_subjects = await expand_chain.ainvoke({"topic": example_topic})
related_subjects
RelatedSubjects(topics=['トークン数とパフォーマンス', '言語モデルの進化', 'RAG(Retrieval-Augmented Generation)', '自然言語処理におけるテキスト生成', '大規模言語モデルの利用例', 'トランスフォーマーアーキテクチャの応用', '機械学習におけるトークン効率性', 'ファインチューニングとプレトレーニングの技術', 'データセットの役割と選択', 'AIモデルのスケーラビリティに関する研究', '情報検索に基づく生成的アプローチ', '知識文書の取り込みと利用'])
視点の生成
これらの関連する主題から、異なるバックグラウンドと所属を持つ代表的なウィキペディア編集者を「専門家」として選択できます。これにより、検索プロセスを分散させ、よりバランスの取れた最終報告を促進します。
編集者の名前は日本語の場合があるのでpatternはコメントアウトしてます。
class Editor(BaseModel):
affiliation: str = Field(
description="編集者の主な所属。",
)
name: str = Field(
#description="編集者の名前。", pattern=r"^[a-zA-Z0-9_-]{1,64}$"
description="編集者の名前。"
)
role: str = Field(
description="トピックにおける編集者の役割。",
)
description: str = Field(
description="編集者の焦点、関心、動機の説明。",
)
@field_validator("name", mode="before")
def sanitize_name(cls, value: str) -> str:
return value.replace(" ", "").replace(".", "")
@property
def persona(self) -> str:
return f"名前: {self.name}\n役割: {self.role}\n所属: {self.affiliation}\n説明: {self.description}\n"
class Perspectives(BaseModel):
editors: List[Editor] = Field(
description="役割と所属を持つ編集者の包括的なリスト。",
# 最大M人の編集者に制限するpydanticのバリデーションを追加
)
gen_perspectives_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""多様で(かつ異なる)Wikipedia編集者のグループを選択し、トピックに関する包括的な記事を作成するために協力させる必要があります。各編集者は、このトピックに関連する異なる視点、役割、または所属を表しています。\
関連トピックの他のWikipediaページを参考にすることができます。各編集者について、彼らが焦点を当てる内容の説明を追加してください。
参考のための関連トピックのWikiページのアウトライン:
{examples}""",
),
("user", "関心のあるトピック: {topic}"),
]
)
gen_perspectives_chain = gen_perspectives_prompt | fast_llm.with_structured_output(
Perspectives, method="function_calling"
)
from langchain_community.retrievers import WikipediaRetriever
from langchain_core.runnables import RunnableLambda
from langchain_core.runnables import chain as as_runnable
wikipedia_retriever = WikipediaRetriever(load_all_available_meta=True, top_k_results=1)
def format_doc(doc, max_length=1000):
related = "- ".join(doc.metadata["categories"])
return f"### {doc.metadata['title']}\n\nSummary: {doc.page_content}\n\nRelated\n{related}"[
:max_length
]
def format_docs(docs):
return "\n\n".join(format_doc(doc) for doc in docs)
@as_runnable
async def survey_subjects(topic: str):
related_subjects = await expand_chain.ainvoke({"topic": topic})
retrieved_docs = await wikipedia_retriever.abatch(
related_subjects.topics, return_exceptions=True
)
all_docs = []
for docs in retrieved_docs:
if isinstance(docs, BaseException):
continue
all_docs.extend(docs)
formatted = format_docs(all_docs)
return await gen_perspectives_chain.ainvoke({"examples": formatted, "topic": topic})
perspectives = await survey_subjects.ainvoke(example_topic)
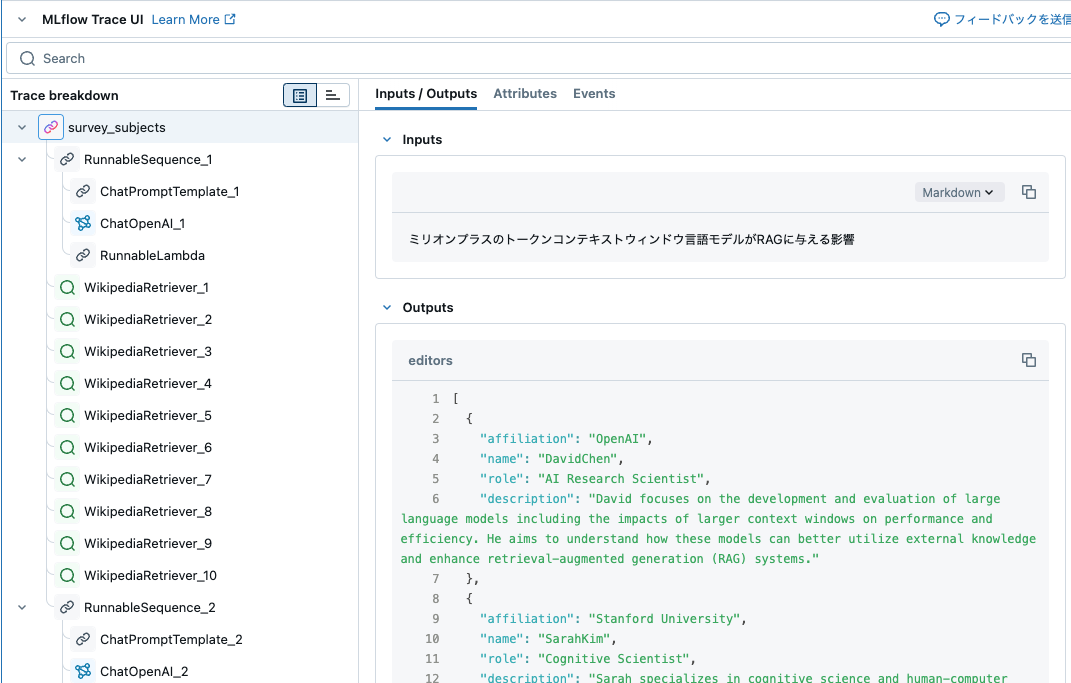
perspectives.model_dump()
{'editors': [{'affiliation': 'OpenAI',
'name': 'DavidChen',
'role': 'AI Research Scientist',
'description': 'David focuses on the development and evaluation of large language models including the impacts of larger context windows on performance and efficiency. He aims to understand how these models can better utilize external knowledge and enhance retrieval-augmented generation (RAG) systems.'},
{'affiliation': 'Stanford University',
'name': 'SarahKim',
'role': 'Cognitive Scientist',
'description': 'Sarah specializes in cognitive science and human-computer interaction. She is interested in how larger language models impact human language processing and interactions, particularly in applications that use retrieval-augmented generation.'},
{'affiliation': 'Microsoft Research',
'name': 'AlexWang',
'role': 'Applied AI Researcher',
'description': 'Alex explores the integration of larger token context windows in real-world applications such as chatbots and personal assistants, focusing on how RAG can improve natural language understanding and generation in these systems.'},
{'affiliation': 'Tokyo Institute of Technology',
'name': 'MasakiTanaka',
'role': 'Machine Learning Engineer',
'description': 'Masaki works on optimizing machine learning algorithms for efficient processing of large language models and is particularly focused on the computational implications of scaling context windows in RAG architectures.'},
{'affiliation': 'MIT Media Lab',
'name': 'EmilySmith',
'role': 'AI Ethics Researcher',
'description': 'Emily investigates the ethical implications of AI developments, including the potential biases and societal impacts of larger language models and their use in RAG systems. She advocates for responsible AI research and application.'}]}
専門家対話
さあ、本当の楽しみが始まります。各ウィキペディアの執筆者は、上記の視点を用いてロールプレイする準備が整っています。彼らは、検索エンジンにアクセスできる第二の「ドメイン専門家」に一連の質問を行います。これにより、洗練されたアウトラインと更新された参考文書のインデックスを生成するコンテンツが作成されます。
インタビューの状態
会話は循環的であるため、それを独自のグラフ内で構築します。状態にはメッセージ、参照文書、およびエディター(独自の「ペルソナ」を持つ)を含め、これらの会話を並行して進めやすくします。
from typing import Annotated
from langchain_core.messages import AnyMessage
from typing_extensions import TypedDict
from langgraph.graph import END, StateGraph, START
def add_messages(left, right):
if not isinstance(left, list):
left = [left]
if not isinstance(right, list):
right = [right]
return left + right
def update_references(references, new_references):
if not references:
references = {}
references.update(new_references)
return references
def update_editor(editor, new_editor):
# 最初にのみ設定できます
if not editor:
return new_editor
return editor
class InterviewState(TypedDict):
messages: Annotated[List[AnyMessage], add_messages]
references: Annotated[Optional[dict], update_references]
editor: Annotated[Optional[Editor], update_editor]
対話の役割
グラフには2人の参加者がいます。ウィキペディアの編集者(generate_question)は、割り当てられた役割に基づいて質問を行い、ドメイン専門家(gen_answer_chain)は、検索エンジンを使用してできるだけ正確に質問に答えます。
from langchain_core.messages import AIMessage, HumanMessage, ToolMessage
from langchain_core.prompts import MessagesPlaceholder
gen_qn_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""あなたは経験豊富なウィキペディアのライターであり、特定のページを編集したいと考えています。 \
ウィキペディアのライターとしてのアイデンティティに加えて、あなたにはトピックを調査する際の特定の焦点があります。 \
今、あなたは専門家とチャットをして情報を得ようとしています。より有用な情報を得るために良い質問をしてください。
質問がもうない場合は、「ご協力いただきありがとうございます!」と言って会話を終了してください。\
一度に一つの質問だけをしてください。以前に尋ねたことを聞かないでください。\
あなたの質問は、あなたが書きたいトピックに関連している必要があります。
包括的で好奇心を持ち、専門家からできるだけ多くのユニークな洞察を得てください。\
あなたの特定の視点に忠実でいてください:
{persona}""",
),
MessagesPlaceholder(variable_name="messages", optional=True),
]
)
def tag_with_name(ai_message: AIMessage, name: str):
ai_message.name = name
return ai_message
def swap_roles(state: InterviewState, name: str):
converted = []
for message in state["messages"]:
if isinstance(message, AIMessage) and message.name != name:
message = HumanMessage(**message.model_dump(exclude={"type"}))
converted.append(message)
return {"messages": converted}
@as_runnable
async def generate_question(state: InterviewState):
editor = state["editor"]
gn_chain = (
RunnableLambda(swap_roles).bind(name=editor.name)
| gen_qn_prompt.partial(persona=editor.persona)
| fast_llm
| RunnableLambda(tag_with_name).bind(name=editor.name)
)
result = await gn_chain.ainvoke(state)
return {"messages": [result]}
messages = [
HumanMessage(f"あなたは{example_topic}に関する記事を書いていると言いましたか?")
]
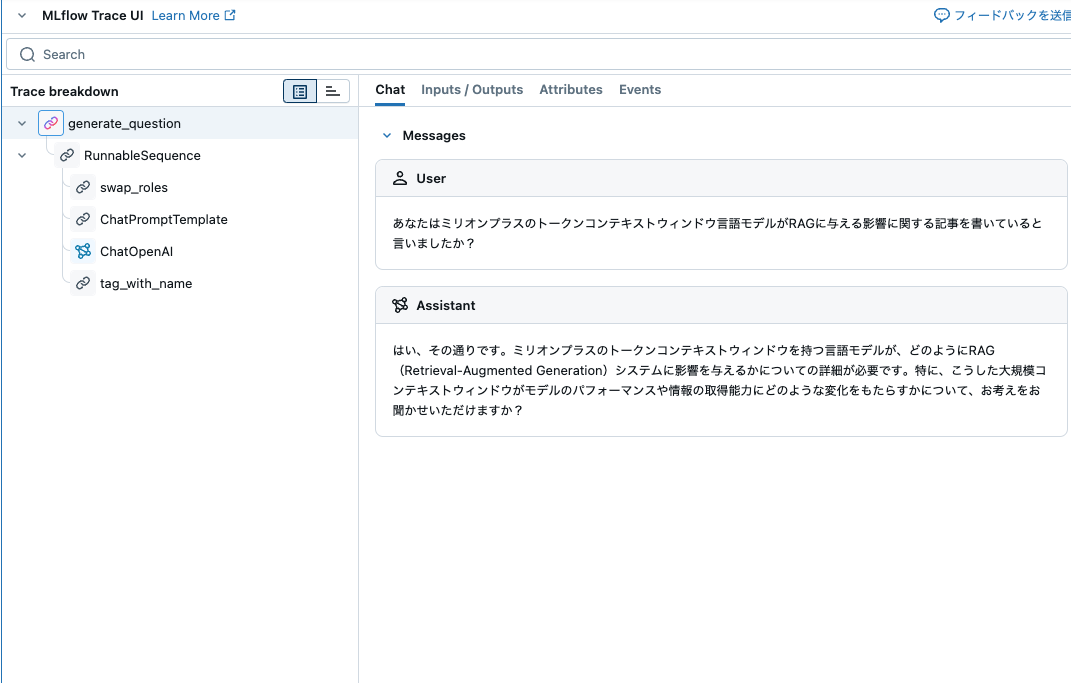
question = await generate_question.ainvoke(
{
"editor": perspectives.editors[0],
"messages": messages,
}
)
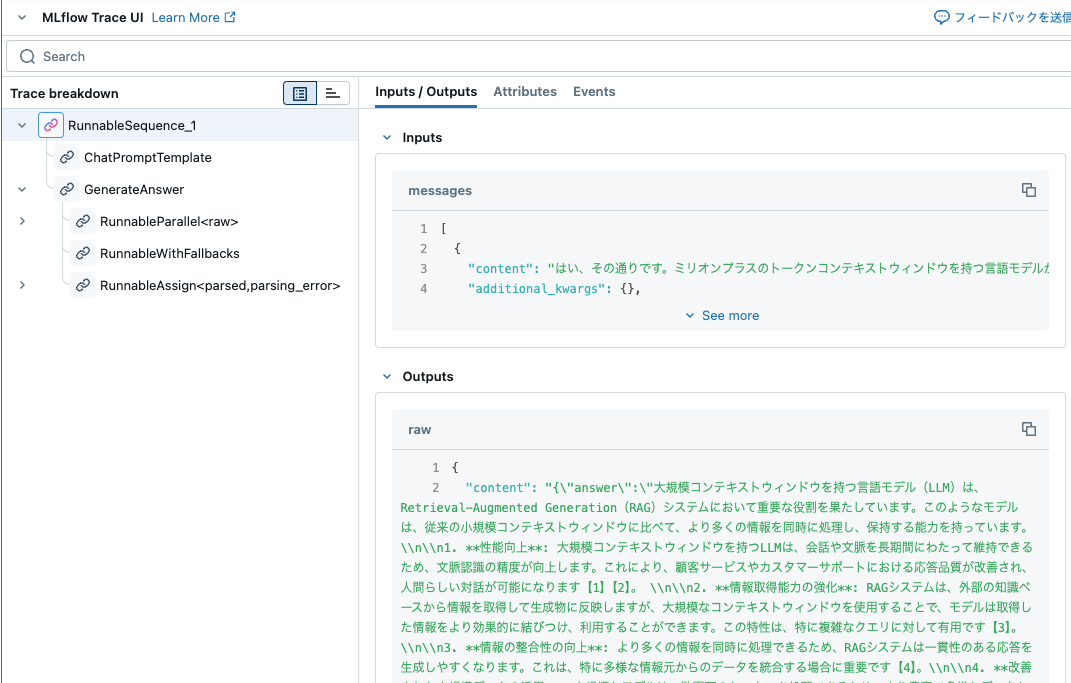
question["messages"][0].content
'はい、その通りです。ミリオンプラスのトークンコンテキストウィンドウを持つ言語モデルが、どのようにRAG(Retrieval-Augmented Generation)システムに影響を与えるかについての詳細が必要です。特に、こうした大規模コンテキストウィンドウがモデルのパフォーマンスや情報の取得能力にどのような変化をもたらすかについて、お考えをお聞かせいただけますか?'
質問に答える
gen_answer_chainは、編集者の質問に答えるために最初にクエリを生成(クエリ拡張)し、その後、引用を用いて応答します。
class Queries(BaseModel):
queries: List[str] = Field(
description="ユーザーの質問に答えるための検索エンジンクエリの包括的なリスト。",
)
gen_queries_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは役立つリサーチアシスタントです。ユーザーの質問に答えるために検索エンジンにクエリを送信してください。",
),
MessagesPlaceholder(variable_name="messages", optional=True),
]
)
gen_queries_chain = gen_queries_prompt | fast_llm.with_structured_output(
Queries, include_raw=True, method="function_calling"
)
queries = await gen_queries_chain.ainvoke(
{"messages": [HumanMessage(content=question["messages"][0].content)]}
)
queries["parsed"].queries
['ミリオンプラスのトークンコンテキストウィンドウ 言語モデル RAG システム 影響',
'大規模コンテキストウィンドウ モデルのパフォーマンス',
'RAGシステムにおける情報取得能力の向上',
'トークンコンテキストウィンドウと生成能力の関係']
class AnswerWithCitations(BaseModel):
answer: str = Field(
description="ユーザーの質問に対する包括的な回答と引用。",
)
cited_urls: List[str] = Field(
description="回答に引用されたURLのリスト。",
)
@property
def as_str(self) -> str:
return f"{self.answer}\n\n引用:\n\n" + "\n".join(
f"[{i+1}]: {url}" for i, url in enumerate(self.cited_urls)
)
gen_answer_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""あなたは情報を効果的に使用できる専門家です。あなたは、あなたが知っているトピックに関するウィキペディアのページを作成したいウィキペディアの作家とチャットしています。あなたは関連情報を集め、その情報を使用して応答を形成します。
応答をできるだけ情報豊富にし、各文が集めた情報によって裏付けられていることを確認してください。
各応答は、信頼できるソースからの引用によって裏付けられ、脚注としてフォーマットされ、応答の後にURLを再現します。""",
),
MessagesPlaceholder(variable_name="messages", optional=True),
]
)
gen_answer_chain = gen_answer_prompt | fast_llm.with_structured_output(
AnswerWithCitations, include_raw=True
).with_config(run_name="GenerateAnswer")
from langchain_community.utilities.duckduckgo_search import DuckDuckGoSearchAPIWrapper
from langchain_core.tools import tool
'''
# Tavily is typically a better search engine, but your free queries are limited
search_engine = TavilySearchResults(max_results=4)
@tool
async def search_engine(query: str):
"""Search engine to the internet."""
results = tavily_search.invoke(query)
return [{"content": r["content"], "url": r["url"]} for r in results]
'''
# DDG
search_engine = DuckDuckGoSearchAPIWrapper()
@tool
async def search_engine(query: str):
"""インターネット検索エンジン。"""
results = DuckDuckGoSearchAPIWrapper()._ddgs_text(query)
return [{"content": r["body"], "url": r["href"]} for r in results]
import json
from langchain_core.runnables import RunnableConfig
async def gen_answer(
state: InterviewState,
config: Optional[RunnableConfig] = None,
name: str = "Subject_Matter_Expert",
max_str_len: int = 15000,
):
swapped_state = swap_roles(state, name) # 他のAIメッセージを変換
queries = await gen_queries_chain.ainvoke(swapped_state)
query_results = await search_engine.abatch(
queries["parsed"].queries, config, return_exceptions=True
)
successful_results = [
res for res in query_results if not isinstance(res, Exception)
]
all_query_results = {
res["url"]: res["content"] for results in successful_results for res in results
}
# ここで最大トークン長の処理をより正確にすることも可能
dumped = json.dumps(all_query_results)[:max_str_len]
ai_message: AIMessage = queries["raw"]
tool_call = queries["raw"].tool_calls[0]
tool_id = tool_call["id"]
tool_message = ToolMessage(tool_call_id=tool_id, content=dumped)
swapped_state["messages"].extend([ai_message, tool_message])
# 中間メッセージで対話履歴を汚染しないように最終的な回答のみを共有状態に更新
generated = await gen_answer_chain.ainvoke(swapped_state)
cited_urls = set(generated["parsed"].cited_urls)
# 将来の参照のために取得した情報を共有状態に保存
cited_references = {k: v for k, v in all_query_results.items() if k in cited_urls}
formatted_message = AIMessage(name=name, content=generated["parsed"].as_str)
return {"messages": [formatted_message], "references": cited_references}
example_answer = await gen_answer(
{"messages": [HumanMessage(content=question["messages"][0].content)]}
)
example_answer["messages"][-1].content
引用を含む専門家の回答が生成されます。
'大規模コンテキストウィンドウを持つ言語モデル(LLM)は、Retrieval-Augmented Generation(RAG)システムにおいて重要な役割を果たしています。このようなモデルは、従来の小規模コンテキストウィンドウに比べて、より多くの情報を同時に処理し、保持する能力を持っています。\n\n1. **性能向上**: 大規模コンテキストウィンドウを持つLLMは、会話や文脈を長期間にわたって維持できるため、文脈認識の精度が向上します。これにより、顧客サービスやカスタマーサポートにおける応答品質が改善され、人間らしい対話が可能になります【1】【2】。 \n\n2. **情報取得能力の強化**: RAGシステムは、外部の知識ベースから情報を取得して生成物に反映しますが、大規模なコンテキストウィンドウを使用することで、モデルは取得した情報をより効果的に結びつけ、利用することができます。この特性は、特に複雑なクエリに対して有用です【3】。\n\n3. **情報の整合性の向上**: より多くの情報を同時に処理できるため、RAGシステムは一貫性のある応答を生成しやすくなります。これは、特に多様な情報元からのデータを統合する場合に重要です【4】。\n\n4. **改善された大規模データの活用**: 大規模なモデルは、数百万のトークンを処理できるため、より豊富で多様なデータセットを活用することができ、それによって生成されるコンテンツの質も向上します。これにより、専門的な知識を必要とするタスクにおいても優れたパフォーマンスを発揮します【5】【6】。 \n\n5. **リアルタイム処理の可能性**: 大規模なコンテキストウィンドウを持つモデルは、リアルタイムでの情報取得と応答生成が可能であり、迅速な問題解決や情報提供が実現します。これにより、ユーザビリティが向上し、システム全体の効率性も高まります【7】。\n\n引用:\n\n[1]: https://reinforz.co.jp/bizmedia/79408/\n[2]: https://zenn.dev/chameleonmeme/articles/989ccef3027419\n[3]: https://www.genspark.ai/spark/ai%E3%81%AE%E3%82%B3%E3%83%B3%E3%83%86%E3%82%AF%E3%82%B9%E3%83%88%E3%82%A6%E3%82%A3%E3%83%B3%E3%83%89%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6/8a6dc236-3b02-4bb4-b818-dd053c8fc66a\n[4]: https://www.sbbit.jp/article/cont1/142381\n[5]: https://myscale.com/blog/ja/rag-vs-large-context-llms/'
インタビューグラフの構築
編集者とドメイン専門家を定義したので、グラフに組み込むことができます。
max_num_turns = 5
from langgraph.pregel import RetryPolicy
def route_messages(state: InterviewState, name: str = "Subject_Matter_Expert"):
messages = state["messages"]
num_responses = len(
[m for m in messages if isinstance(m, AIMessage) and m.name == name]
)
if num_responses >= max_num_turns:
return END
last_question = messages[-2]
if last_question.content.endswith("ご協力いただきありがとうございます!"):
return END
return "ask_question"
builder = StateGraph(InterviewState)
builder.add_node("ask_question", generate_question, retry=RetryPolicy(max_attempts=5))
builder.add_node("answer_question", gen_answer, retry=RetryPolicy(max_attempts=5))
builder.add_conditional_edges("answer_question", route_messages)
builder.add_edge("ask_question", "answer_question")
builder.add_edge(START, "ask_question")
interview_graph = builder.compile(checkpointer=False).with_config(
run_name="Conduct Interviews"
)
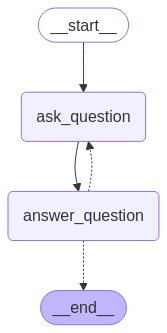
グラフを可視化します。
from IPython.display import Image, display
try:
display(Image(interview_graph.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
説明の通り、質疑応答が循環しています。
final_step = None
initial_state = {
"editor": perspectives.editors[0],
"messages": [
AIMessage(
content=f"あなたは{example_topic}に関する記事を書いていると言いましたね?",
name="Subject_Matter_Expert",
)
],
}
async for step in interview_graph.astream(initial_state):
name = next(iter(step))
print(name)
print("-- ", str(step[name]["messages"])[:300])
final_step = step
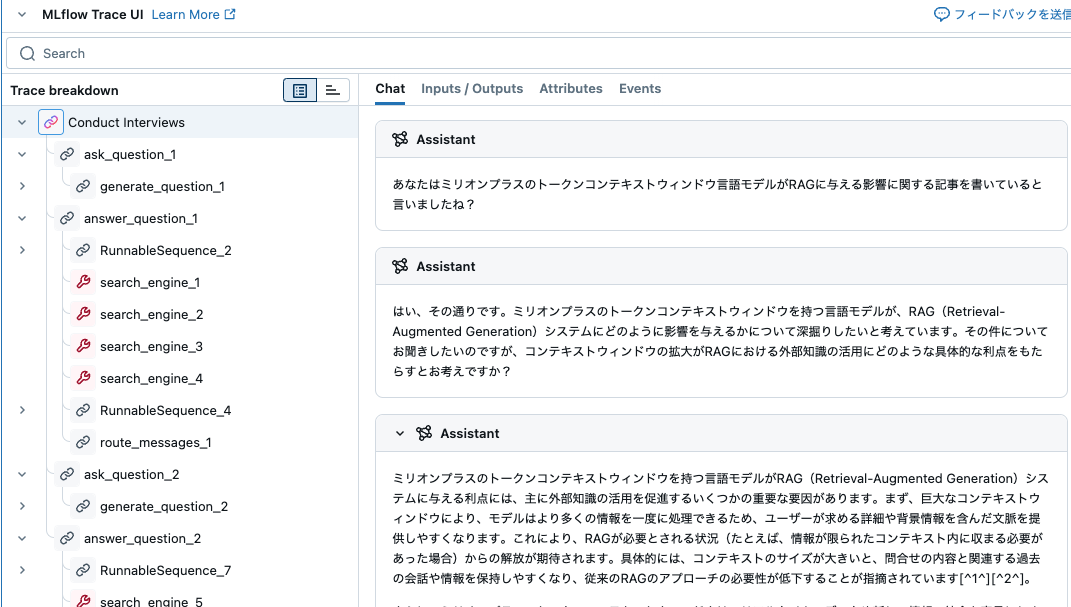
エージェント同士で質疑応答している...。
ask_question
-- [AIMessage(content='はい、その通りです。ミリオンプラスのトークンコンテキストウィンドウを持つ言語モデルが、RAG(Retrieval-Augmented Generation)システムにどのように影響を与えるかについて深掘りしたいと考えています。その件についてお聞きしたいのですが、コンテキストウィンドウの拡大がRAGにおける外部知識の活用にどのような具体的な利点をもたらすとお考えですか?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens':
answer_question
-- [AIMessage(content='ミリオンプラスのトークンコンテキストウィンドウを持つ言語モデルがRAG(Retrieval-Augmented Generation)システムに与える利点には、主に外部知識の活用を促進するいくつかの重要な要因があります。まず、巨大なコンテキストウィンドウにより、モデルはより多くの情報を一度に処理できるため、ユーザーが求める詳細や背景情報を含んだ文脈を提供しやすくなります。これにより、RAGが必要とされる状況(たとえば、情報が限られたコンテキスト内に収まる必要があった場合)からの解放が期待されます。具体的には、コンテキストのサイズが大きいと、問合せの内容と
ask_question
-- [AIMessage(content='ご協力いただきありがとうございます!', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 8, 'prompt_tokens': 1227, 'total_tokens': 1235, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_pre
answer_question
-- [AIMessage(content='ミリオンプラスのトークンコンテキストウィンドウを持つ言語モデルがRAG(Retrieval-Augmented Generation)システムに与える影響について考えると、以下のような具体的な利点が考えられます。まず、これにより、モデルが一度に扱える情報量が大幅に増加するため、ユーザーが質問する際に関連する文脈をより効果的に保持し、活用することが可能になります。特に、長い文脈を必要とする複雑な問い合わせに対して、より豊かな背景情報を含んだ回答を生成しやすくなる点が挙げられます[^1^][^2^]。 \n\nまた、RAGのメカニズムによって外部知識を効果的
final_state = next(iter(final_step.values()))
アウトラインの洗練
STORMのこの段階では、さまざまな視点から多くの研究を行いました。これらの調査に基づいて、元のアウトラインを洗練させる時です。以下に、元のアウトラインを更新するために長いコンテキストウィンドウを持つLLMを使用してチェーンを作成してください。
refine_outline_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""あなたはウィキペディアのライターです。専門家や検索エンジンから情報を集めました。今、ウィキペディアページのアウトラインを洗練させています。 \
アウトラインが包括的で具体的であることを確認する必要があります。 \
あなたが書いているトピック: {topic}
古いアウトライン:
{old_outline}""",
),
(
"user",
"専門家との会話に基づいてアウトラインを洗練させてください:\n\n会話:\n\n{conversations}\n\n洗練されたウィキペディアのアウトラインを書いてください:",
),
]
)
# コンテキストがかなり長くなる可能性があるため、ターボプレビューを使用
refine_outline_chain = refine_outline_prompt | long_context_llm.with_structured_output(
Outline
)
refined_outline = refine_outline_chain.invoke(
{
"topic": example_topic,
"old_outline": initial_outline.as_str,
"conversations": "\n\n".join(
f"### {m.name}\n\n{m.content}" for m in final_state["messages"]
),
}
)
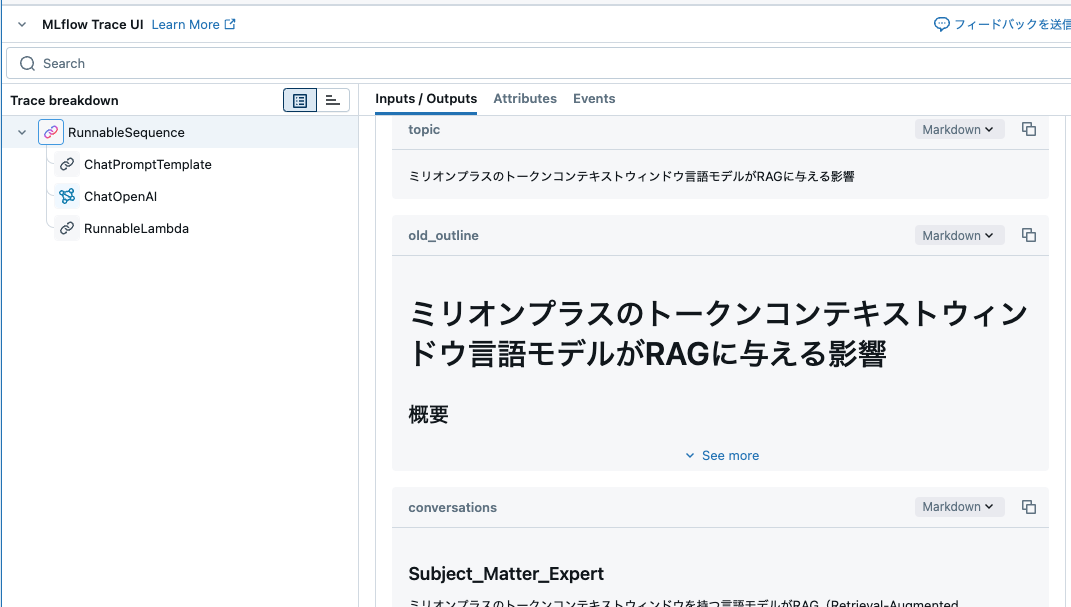
print(refined_outline.as_str)
# ミリオンプラスのトークンコンテキストウィンドウ言語モデルがRAGに与える影響
## 概要
ミリオンプラスのトークンコンテキストウィンドウ言語モデルとは、1,000,000を超えるトークンサイズを持つ言語モデルのことです。このモデルはRAG(Retrieval-Augmented Generation)のパフォーマンスに重要な影響を与え、特に情報処理能力と生成精度を向上させる可能性があります。本稿では、言語モデルの利点、RAGとの相互作用、及び両者が相互に補完する方法について考察します。
## 言語モデルの基礎
言語モデルは自然言語処理における重要な技術で、言語生成と理解に使用されます。このセクションでは、言語モデルの基本概念とトークン及びコンテキストウィンドウの役割について説明します。
### トークンの定義
トークンはテキストの最小単位であり、言語の理解と生成の過程で重要な役割を果たします。単語、句、文字がどのようにトークン化されるかを示します。
### コンテキストウィンドウとは
コンテキストウィンドウは言語モデルが処理するテキストの範囲を決定します。特に、トークン数の増加が文脈理解や情報の一貫性に与える影響を考察します。
## RAGの基礎
RAG(Retrieval-Augmented Generation)は、情報検索と生成を統合する手法です。このセクションでは、RAGの基本構造と重要な特徴について説明します。
### 情報検索のプロセス
RAGにおける情報検索は、外部知識を効果的に利用してタスクを遂行するプロセスです。このプロセスがどのように実行されるかを詳説します。
### 生成プロセス
検索された情報に基づいて文を生成する過程を解説し、そこにおける言語モデルの役割と影響について議論します。
## ミリオンプラスモデルの利点と応用
ミリオンプラスのトークンを持つ言語モデルがRAGに対してどのような利点を提供するかを確認し、RAGの実用的応用を探ります。
### 情報の向上
大規模トークンコンテキストが如何に情報の多様性と範囲を拡大し、文脈を保持するかを説明します。
### 複雑な問い合わせへの対処
長い文脈を必要とする複雑な問いに対して、より詳しく、背景情報を含む応答が可能になる例を示します。
### 動的知識統合
RAGが外部知識をリアルタイムで統合できることがもたらす利点を、具体的なユースケースと共に解説します。
## 課題と展望
ミリオンプラスモデルとRAGの統合における課題と、その克服方法についての議論、及び将来的な研究の方向性を示します。
### 計算リソースの消費
大規模言語モデルに必要な計算リソースの課題について述べ、効率的にリソースを使用するための方法を模索します。
### モデルの最適化手法
ミリオンプラスモデルの最適化のための新しいアプローチや手法について探り、性能向上を図る方法を議論します。
## 結論
ミリオンプラスのトークンコンテキストウィンドウを持つ言語モデルがRAGに与える影響を総括し、その重要性と今後の研究の必要性について考察します。
記事生成
さあ、完全な記事を生成する時間です。まずは分割して、それぞれのセクションを個別のLLMで処理します。その後、長文LLMに完成した記事を洗練させるように促します(各セクションは一貫性のない声を使用する可能性があるため)。
リトリーバーの作成
研究プロセスでは、最終的な記事執筆プロセス中にクエリを実行したい多くの参考文書が明らかになります。
まず、リトリーバーを作成します:
from langchain_community.vectorstores import InMemoryVectorStore
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
reference_docs = [
Document(page_content=v, metadata={"source": k})
for k, v in final_state["references"].items()
]
# このデータサイズではベクトルストアである必要はありません。
# numpy行列にすることもできますし、リクエスト間でドキュメントを保存することもできます。
vectorstore = InMemoryVectorStore.from_documents(
reference_docs,
embedding=embeddings,
)
retriever = vectorstore.as_retriever(k=3)
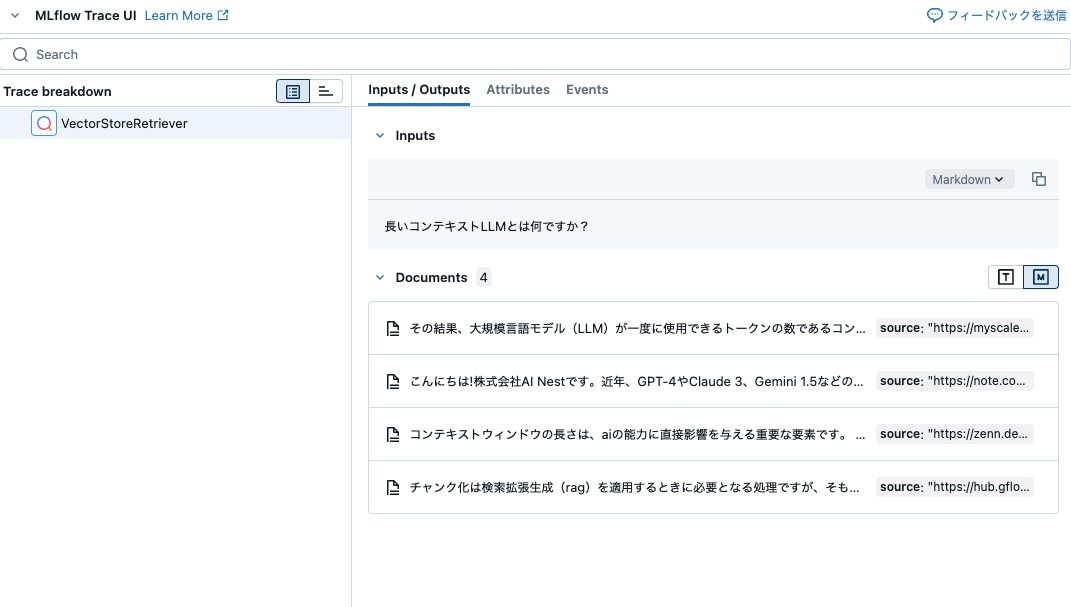
retriever.invoke("長いコンテキストLLMとは何ですか?")
[Document(id='7d4fe5df-4908-424d-a5ad-568e1432a203', metadata={'source': 'https://myscale.com/blog/ja/rag-vs-large-context-llms/'}, page_content='その結果、大規模言語モデル(LLM)が一度に使用できるトークンの数であるコンテキストウィンドウも急速に拡大しています。 2024年2月にリリースされたGoogle Gemini 1.5 Proは、最長のコンテキストウィンドウの記録を樹立しました。'),
Document(id='897b489f-04d5-4a3b-b84a-c9673ad0bf04', metadata={'source': 'https://note.com/ainest/n/ndb353ef19032'}, page_content='こんにちは!株式会社AI Nestです。近年、GPT-4やClaude 3、Gemini 1.5などの大規模言語モデル(LLM)は、より長い文章を一度に処理できるようになってきています。しかし、この「長いコンテキスト」は本当に実用的なのでしょうか?特に、外部知識を活用するRAG(Retrieval Augmented Generation)システムに ...'),
Document(id='f0b36ffa-36af-426e-829e-addafbaf4537', metadata={'source': 'https://zenn.dev/chameleonmeme/articles/989ccef3027419'}, page_content='コンテキストウィンドウの長さは、aiの能力に直接影響を与える重要な要素です。 長文の理解と処理 コンテキストウィンドウが長いほど、AIは長文のドキュメントや記事、書籍などをより深く理解し、要約したり、質問に答えたりすることができます。'),
Document(id='aa91f951-e990-44c8-9565-16f7ddeda486', metadata={'source': 'https://hub.gflops-ai.com/rag/321/'}, page_content='チャンク化は検索拡張生成(rag)を適用するときに必要となる処理ですが、そもそもチャンク化が必要な理由は、大規模言語モデル(llm)のコンテキストウィンドウに制限があるからです。 ... コンテキストサイズ: 131,072トークン(約128k ...')]
セクション生成
インデックスされた文書を使用して、セクションを生成できます。
class SubSection(BaseModel):
subsection_title: str = Field(..., title="小見出しのタイトル")
content: str = Field(
...,
title="小見出しの完全な内容。関連する引用元には[#]の引用を含めてください。",
)
@property
def as_str(self) -> str:
return f"### {self.subsection_title}\n\n{self.content}".strip()
class WikiSection(BaseModel):
section_title: str = Field(..., title="セクションのタイトル")
content: str = Field(..., title="セクションの完全な内容")
subsections: Optional[List[Subsection]] = Field(
default=None,
title="Wikipediaページの各小見出しのタイトルと説明。",
)
citations: List[str] = Field(default_factory=list)
@property
def as_str(self) -> str:
subsections = "\n\n".join(
subsection.as_str for subsection in self.subsections or []
)
citations = "\n".join([f" [{i}] {cit}" for i, cit in enumerate(self.citations)])
return (
f"## {self.section_title}\n\n{self.content}\n\n{subsections}".strip()
+ f"\n\n{citations}".strip()
)
section_writer_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは専門のWikipediaライターです。以下のアウトラインから割り当てられたWikiSectionを完成させてください:\n\n"
"{outline}\n\n引用元を示してください。以下の参考文献を使用してください:\n\n<Documents>\n{docs}\n<Documents>",
),
("user", "セクション{section}の完全なWikiSectionを書いてください。"),
]
)
async def retrieve(inputs: dict):
docs = await retriever.ainvoke(inputs["topic"] + ": " + inputs["section"])
formatted = "\n".join(
[
f'<Document href="{doc.metadata["source"]}"/>\n{doc.page_content}\n</Document>'
for doc in docs
]
)
return {"docs": formatted, **inputs}
section_writer = (
retrieve
| section_writer_prompt
| long_context_llm.with_structured_output(WikiSection)
)
section = await section_writer.ainvoke(
{
"outline": refined_outline.as_str,
"section": refined_outline.sections[1].section_title,
"topic": example_topic,
}
)
print(section.as_str)
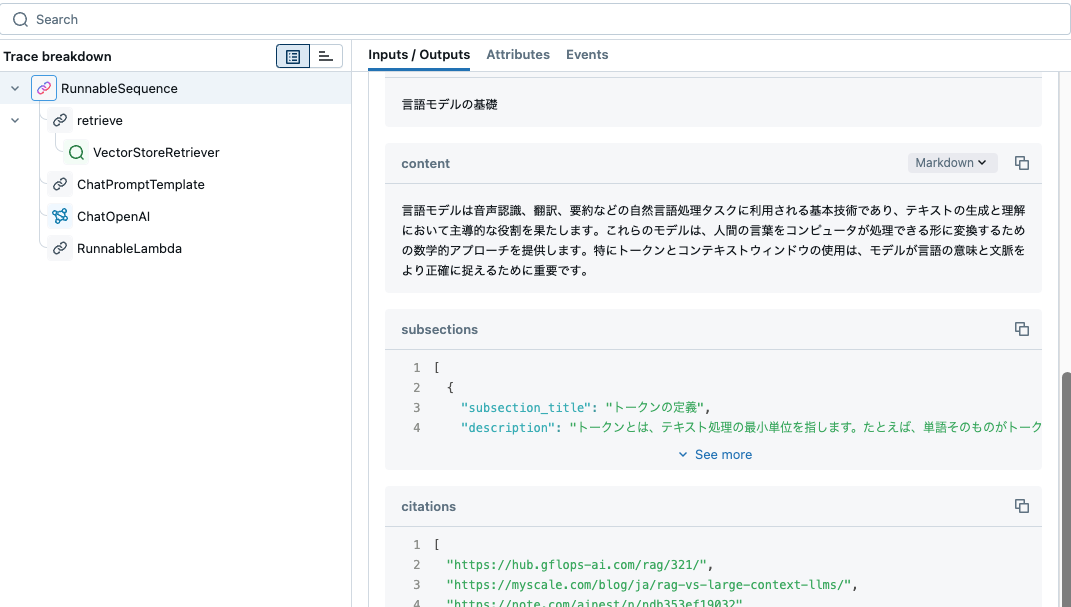
## 言語モデルの基礎
言語モデルは音声認識、翻訳、要約などの自然言語処理タスクに利用される基本技術であり、テキストの生成と理解において主導的な役割を果たします。これらのモデルは、人間の言葉をコンピュータが処理できる形に変換するための数学的アプローチを提供します。特にトークンとコンテキストウィンドウの使用は、モデルが言語の意味と文脈をより正確に捉えるために重要です。
### トークンの定義
トークンとは、テキスト処理の最小単位を指します。たとえば、単語そのものがトークンとして扱われる場合もあれば、句や文字単位でトークン化されることもあります。言語モデルはテキストを読み込む際にこのトークン単位に分解し、それぞれのトークンを数値ベクトルに変換することで処理します。このプロセスを通じて、モデルはテキストの意味を計算的に評価します。
### コンテキストウィンドウとは
コンテキストウィンドウとは、言語モデルが一度に処理可能なトークンの範囲を指します。このウィンドウの大きさは、モデルがどれだけの情報を一度に参照できるかを決定し、文脈理解の深さに直接影響します。トークン数の増加により、モデルはより長い文脈や複雑な情報を統合して理解でき、より一貫性のある自然な生成を可能にします。この拡大により、モデルはより複雑で詳細な質問に対しても的確な応答が可能となります。[0] https://hub.gflops-ai.com/rag/321/
[1] https://myscale.com/blog/ja/rag-vs-large-context-llms/
[2] https://note.com/ainest/n/ndb353ef19032
最終記事の生成
ドラフトを再構成し、すべての引用を適切にグループ化し、一貫した声を維持します。
from langchain_core.output_parsers import StrOutputParser
writer_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"あなたは専門のWikipedia著者です。以下のセクション草案を使用して、{topic}に関する完全なウィキ記事を書いてください:\n\n"
"{draft}\n\nWikipediaのフォーマットガイドラインに厳密に従ってください。",
),
(
"user",
'マークダウン形式で完全なウィキ記事を書いてください。フットノートの形式で引用を整理し、'
'フッターでの重複を避けてください。フッターにはURLを含めてください。',
),
]
)
writer = writer_prompt | long_context_llm | StrOutputParser()
for tok in writer.stream({"topic": example_topic, "draft": section.as_str}):
print(tok, end="")
脚注も含まれています。
# ミリオンプラスのトークンコンテキストウィンドウとRAGへの影響
## 言語モデルの基礎
### はじめに
言語モデルは、音声認識や機械翻訳、要約など多岐にわたる自然言語処理タスクにおいて重要な技術です。これらのモデルは、テキストの生成と理解に主導的な役割を果たし、人間の言葉をコンピュータが処理可能な形式に変換するための数学的アプローチを提供します。その際、特にトークンとコンテキストウィンドウの使用がモデルの能力に多大な影響を与えます。
### トークンの定義
トークンとはテキスト処理の最小単位であり、言語モデルがテキストを理解するために必要な要素です。トークンは単語、句、または文字単位で分解されることがあり、言語モデルはテキストをそれぞれのトークンに分解して処理します。これにより、モデルはテキストの意味を数値ベクトルとして計算し、評価することが可能となります。
### コンテキストウィンドウとは
コンテキストウィンドウは、言語モデルが一度に処理できるトークンの範囲を意味します。このウィンドウの大きさは、モデルがどれだけの情報を参照できるかを決定し、文脈理解の深さに直接影響します。トークン数の増加に伴い、モデルは長い文脈や複雑な情報を統合して理解する能力が向上し、より一貫性のある自然な生成が可能になります。この拡大により、より複雑で詳細な質問にも適切に応答できるようになります。
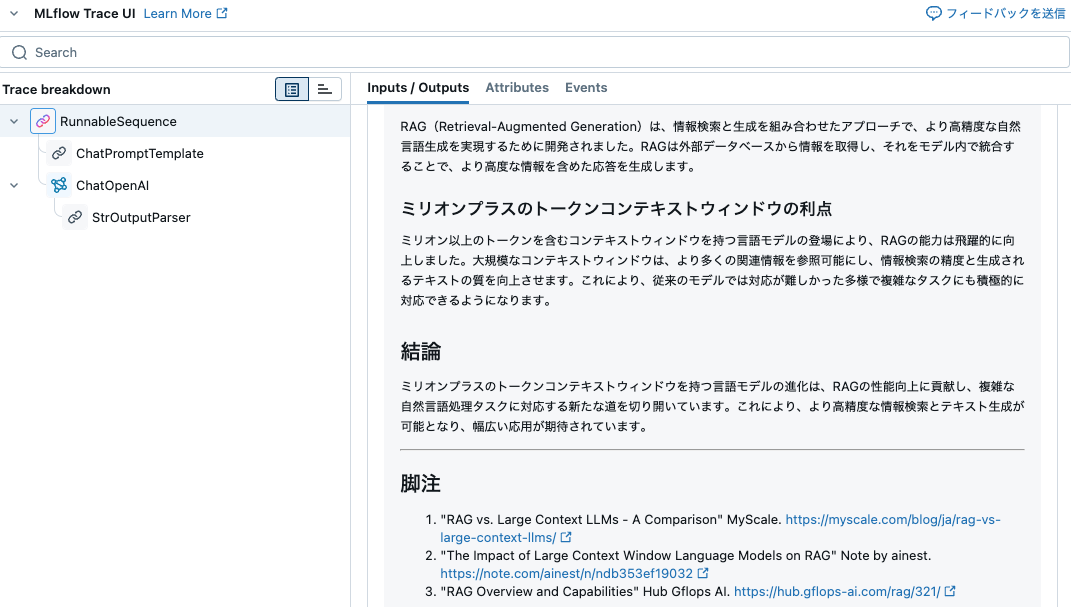
## RAGへの影響
### RAGとは
RAG(Retrieval-Augmented Generation)は、情報検索と生成を組み合わせたアプローチで、より高精度な自然言語生成を実現するために開発されました。RAGは外部データベースから情報を取得し、それをモデル内で統合することで、より高度な情報を含めた応答を生成します。
### ミリオンプラスのトークンコンテキストウィンドウの利点
ミリオン以上のトークンを含むコンテキストウィンドウを持つ言語モデルの登場により、RAGの能力は飛躍的に向上しました。大規模なコンテキストウィンドウは、より多くの関連情報を参照可能にし、情報検索の精度と生成されるテキストの質を向上させます。これにより、従来のモデルでは対応が難しかった多様で複雑なタスクにも積極的に対応できるようになります。
## 結論
ミリオンプラスのトークンコンテキストウィンドウを持つ言語モデルの進化は、RAGの性能向上に貢献し、複雑な自然言語処理タスクに対応する新たな道を切り開いています。これにより、より高精度な情報検索とテキスト生成が可能となり、幅広い応用が期待されています。
---
## 脚注
1. "RAG vs. Large Context LLMs - A Comparison" MyScale. [https://myscale.com/blog/ja/rag-vs-large-context-llms/](https://myscale.com/blog/ja/rag-vs-large-context-llms/)
2. "The Impact of Large Context Window Language Models on RAG" Note by ainest. [https://note.com/ainest/n/ndb353ef19032](https://note.com/ainest/n/ndb353ef19032)
3. "RAG Overview and Capabilities" Hub Gflops AI. [https://hub.gflops-ai.com/rag/321/](https://hub.gflops-ai.com/rag/321/)
最終フロー
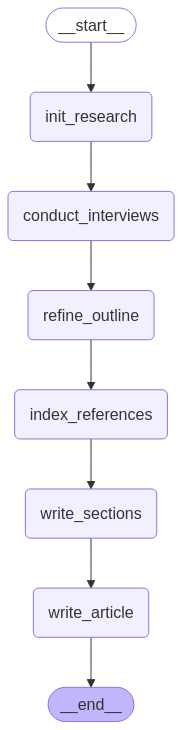
すべてをまとめる時が来ました。6つの主要なステージを順番に進めます:
- 初期のアウトラインと視点を生成
- 各視点とバッチで会話し、記事の内容を拡充
- 会話に基づいてアウトラインを洗練
- 会話からの参考文書をインデックス化
- 記事の各セクションを書く
- 最終的なウィキを書く
状態は各ステージの出力を追跡します。
class ResearchState(TypedDict):
topic: str
outline: Outline
editors: List[Editor]
interview_results: List[InterviewState]
# 最終セクションの出力
sections: List[WikiSection]
article: str
import asyncio
async def initialize_research(state: ResearchState):
topic = state["topic"]
coros = (
generate_outline_direct.ainvoke({"topic": topic}),
survey_subjects.ainvoke(topic),
)
results = await asyncio.gather(*coros)
return {
**state,
"outline": results[0],
"editors": results[1].editors,
}
async def conduct_interviews(state: ResearchState):
topic = state["topic"]
initial_states = [
{
"editor": editor,
"messages": [
AIMessage(
content=f"あなたは{topic}に関する記事を書いていると言いましたね?",
name="Subject_Matter_Expert",
)
],
}
for editor in state["editors"]
]
# ここでサブグラフを呼び出してインタビューを並列化します
interview_results = await interview_graph.abatch(initial_states)
return {
**state,
"interview_results": interview_results,
}
def format_conversation(interview_state):
messages = interview_state["messages"]
convo = "\n".join(f"{m.name}: {m.content}" for m in messages)
return f'{interview_state["editor"].name}との会話\n\n' + convo
async def refine_outline(state: ResearchState):
convos = "\n\n".join(
[
format_conversation(interview_state)
for interview_state in state["interview_results"]
]
)
updated_outline = await refine_outline_chain.ainvoke(
{
"topic": state["topic"],
"old_outline": state["outline"].as_str,
"conversations": convos,
}
)
return {**state, "outline": updated_outline}
async def index_references(state: ResearchState):
all_docs = []
for interview_state in state["interview_results"]:
reference_docs = [
Document(page_content=v, metadata={"source": k})
for k, v in interview_state["references"].items()
]
all_docs.extend(reference_docs)
await vectorstore.aadd_documents(all_docs)
return state
async def write_sections(state: ResearchState):
outline = state["outline"]
sections = await section_writer.abatch(
[
{
"outline": refined_outline.as_str,
"section": section.section_title,
"topic": state["topic"],
}
for section in outline.sections
]
)
return {
**state,
"sections": sections,
}
async def write_article(state: ResearchState):
topic = state["topic"]
sections = state["sections"]
draft = "\n\n".join([section.as_str for section in sections])
article = await writer.ainvoke({"topic": topic, "draft": draft})
return {
**state,
"article": article,
}
グラフを作成する
from langgraph.checkpoint.memory import MemorySaver
builder_of_storm = StateGraph(ResearchState)
nodes = [
("init_research", initialize_research),
("conduct_interviews", conduct_interviews),
("refine_outline", refine_outline),
("index_references", index_references),
("write_sections", write_sections),
("write_article", write_article),
]
for i in range(len(nodes)):
name, node = nodes[i]
builder_of_storm.add_node(name, node, retry=RetryPolicy(max_attempts=3))
if i > 0:
builder_of_storm.add_edge(nodes[i - 1][0], name)
builder_of_storm.add_edge(START, nodes[0][0])
builder_of_storm.add_edge(nodes[-1][0], END)
storm = builder_of_storm.compile(checkpointer=MemorySaver())
from IPython.display import Image, display
try:
display(Image(storm.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
最終的なグラフ構造は以下のようになります。しかし、これって人間が執筆する時にやっていることですよね。
config = {"configurable": {"thread_id": "my-thread"}}
async for step in storm.astream(
{
"topic": "Groq、NVIDIA、Llamma.cppとLLM推論の未来",
},
config,
):
name = next(iter(step))
print(name)
print("-- ", str(step[name])[:300])
init_research
-- {'topic': 'Groq、NVIDIA、Llamma.cppとLLM推論の未来', 'outline': Outline(page_title='Groq、NVIDIA、Llamma.cppとLLM推論の未来', sections=[Section(section_title='はじめに', description='このセクションでは、LLM(大規模言語モデル)の推論に関連する技術の進展と、Groq、NVIDIA、Llamma.cppの役割について概観します。特に、各技術の基本的な機能とその重要性について説明します。', subsections=None), Section(secti
conduct_interviews
-- {'topic': 'Groq、NVIDIA、Llamma.cppとLLM推論の未来', 'outline': Outline(page_title='Groq、NVIDIA、Llamma.cppとLLM推論の未来', sections=[Section(section_title='はじめに', description='このセクションでは、LLM(大規模言語モデル)の推論に関連する技術の進展と、Groq、NVIDIA、Llamma.cppの役割について概観します。特に、各技術の基本的な機能とその重要性について説明します。', subsections=None), Section(secti
refine_outline
-- {'topic': 'Groq、NVIDIA、Llamma.cppとLLM推論の未来', 'outline': Outline(page_title='Groq、NVIDIA、Llamma.cppとLLM推論の未来', sections=[Section(section_title='はじめに', description='このセクションでは、LLM(大規模言語モデル)の推論における技術の進展と、Groq、NVIDIA、Llamma.cppの役割について概観します。それぞれの技術の基本的な機能と重要性について説明します。', subsections=[Subsection(subsection
index_references
-- {'topic': 'Groq、NVIDIA、Llamma.cppとLLM推論の未来', 'outline': Outline(page_title='Groq、NVIDIA、Llamma.cppとLLM推論の未来', sections=[Section(section_title='はじめに', description='このセクションでは、LLM(大規模言語モデル)の推論における技術の進展と、Groq、NVIDIA、Llamma.cppの役割について概観します。それぞれの技術の基本的な機能と重要性について説明します。', subsections=[Subsection(subsection
write_sections
-- {'topic': 'Groq、NVIDIA、Llamma.cppとLLM推論の未来', 'outline': Outline(page_title='Groq、NVIDIA、Llamma.cppとLLM推論の未来', sections=[Section(section_title='はじめに', description='このセクションでは、LLM(大規模言語モデル)の推論における技術の進展と、Groq、NVIDIA、Llamma.cppの役割について概観します。それぞれの技術の基本的な機能と重要性について説明します。', subsections=[Subsection(subsection
write_article
-- {'topic': 'Groq、NVIDIA、Llamma.cppとLLM推論の未来', 'outline': Outline(page_title='Groq、NVIDIA、Llamma.cppとLLM推論の未来', sections=[Section(section_title='はじめに', description='このセクションでは、LLM(大規模言語モデル)の推論における技術の進展と、Groq、NVIDIA、Llamma.cppの役割について概観します。それぞれの技術の基本的な機能と重要性について説明します。', subsections=[Subsection(subsection
トレースも凄いことになってますね。
checkpoint = storm.get_state(config)
article = checkpoint.values["article"]
ウィキをレンダリングする
これで最終的なウィキページをレンダリングできます!
from IPython.display import Markdown
# セクションの見出しを小さくして、このノートブックの混乱を減らします
Markdown(article.replace("\n#", "\n##"))



エージェント界隈、どんどん凄いことになってますね。