A Technical Overview of Azure Databricks - The Databricks Blogの翻訳です。
本書は抄訳であり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
2017年の記事です。
これはDatabricks Chief TechnologistのMatei ZahariaとMicrosoftのDistinguished EngineerであるPeter Carlinの共著です。
本日のMicrosoft Connect();で、Apache Sparkの分析プラットフォームとAzureクラウドの長所を組み合わせたエキサイティングな新規サービスであるAzure Databricksを発表しました。Databricksとマイクロソフトの密接なパートナーシップによって、Azure Databricksは他のクラウドプラットフォームにはないユニークなメリットをもたらします。このブログ記事ではテクノロジーを紹介し、Azure上のDatabricksを用いることでデータサイエンティスト、データエンジニア、ビジネスの意思決定者が利用できる新機能を説明します。
Apache Spark + Databricks + エンタープライズクラウド = Azure Databricks
クラウドで大規模なデータを管理することで、予測分析、AI、リアルタイムアプリケーションの膨大な可能性の扉を開くことになります。過去5年間を通じて、これらのアプリケーションを構築する際のプラットフォームとして、Apache Sparkが選択され続けています。世界中の数千の企業による巨大なコミュニティによって、Sparkはビジネス洞察を生み出すために、大規模かつリアルタイムでパワフルな分析アルゴリズムの実行を実現しています。しかし、大規模なユーザーと強いセキュリティ要件をもつエンタープライズのユースケースにおいては特に、大規模なSparkの管理、デプロイが課題であり続けていました。
Databricksにようこそ。Sparkプロジェクトをスタートしたチームによって2013年に創立され、Databricksはクラウドに最適化されたエンドツーエンドかつマネージドなApache Sparkプラットフォームを提供します。ワンクリックによるデプロイメント、オートスケーリング、クラウドにおけるSparkジョブの性能を10倍から100倍改善する最適化されたDatabricksランタイムを特徴としており、Dataricksは大規模なSparkワークロードの実行をシンプルかつコスト効率の高いものにします。さらにDatabricksは、インタラクティブなノートブック環境、モニタリングツール、そして、数千のユーザーを抱えるエンタープライズでのSpark活用を簡単にするセキュリティコントロールを提供します。
Azure Databricksでは、さらにDatabricksとマイクロソフト間のコラボレーションを通じて、Azureサービスとの密なインテグレーションを行うことで、ベースとなるDatabricksプラットフォームの一歩先に踏み出しました。Azure Databricksでは、高速データアクセスのためにAzureストレージプラットフォーム(データレイクやBlobストレージなど)に最適化されたコネクター、Azureコンソールから直接ワンクリックで管理できることを特徴としています。徹底的にデータ分析プラットフォームを最適化するために、Apache Sparkの提供者とクラウド提供者が密にパートナーシップを結んだのは初めてのことです。
データエンジニア、データサイエンティストにとってのメリット
なぜ、Azure Databricksはデータサイエンティストやデータエンジニアにとって有用なのでしょうか?いくつかの観点で見ていきましょう。
最適化された環境
Azure Databricksでは、クラウドにおけるパフォーマンスとコスト効率が徹底的に最適化されています。DatabricksランタイムはApache Sparkのワークロードにキーとなるいくつかの機能を追加し、Azureで実行した際に最大10-100倍コストを削減することができます。
- マイクロソフトチームと共に開発したAzure Blob StoreやAzure Data LakeのようなAzureストレージサービスに対する高速なコネクター。
- コストを最小化するSparkクラスターのオートスケーリング、自動停止。
- 従来のクラウド、オンプレミス環境におけるApache Spark環境と比較して10-100倍高いパフォーマンス改善を実現するキャッシュ、インデックス、高度なクエリー最適化を含むパフォーマンスの最適化。
シームレスなコラボレーション
ドキュメントが真に同時編集可能になった際の生産性の改善を覚えていますか?なぜ我々はこれをデータエンジニアリングやデータサイエンスで活用できないのでしょうか?Azure Databricksはまさにそれそのものを提供します。Databricksのノートブックはライブで共有でき、リアルタイムのコラボレーションを実現し、皆様の組織の全員があなたのデータで作業することができます。ダッシュボードによって、ビジネスユーザーは新たなパラメーターで既存のジョブを呼び出すことができます。そして、Databricksはインタラクティブなビジアライゼーションのために、PowerBIと密にインテグレーションしています。これら全ては、Azure Databricksが高い同時接続性、高速な性能、地理的なれプレリケーションを実現するAzure Databaseや他のテクノロジーによって支えられているため可能となっています。
使いやすさ
Azure Databricksは一般的なデータソースに接続し、機械学習アルゴリズムを実行し、クイックにスタートするためにApache Sparkの基本を学ぶことができるインタラクティブなノートブックと共にパッケージされて提供されます。また、インタラクティブノートブックからSparkジョブの進捗を分析することができるデバッグ環境と過去のジョブを分析するためのパワフルなツールがインテグレーションされています。最後に、PythonやRのデータサイエンススタックのような他の一般的な分析ライブラリはインストール済みなので、洞察を導き出すためにSparkでそれらを活用することができます。我々はビッグデータは10倍使いやすくなるものと信じており、Apache Sparkで始まった統合され、かつ、エンドツーエンドのプラットフォームを提供するという哲学は変わっていません。
Azure Databricksのアーキテクチャ
それでは、Azure Databricksはどのように構成されているのでしょうか?ハイレベルでは、それぞれのお客さまのサブスクリプションでサービスが起動し、ワーカーノードを管理するので、お客様は自身のアカウントの既存の管理ツールを活用することができます。
特に、お客さまがDatabricks経由でクラスターを起動すると、お客さまのサブスクリプションに「Databricksアプライアンス」がデプロイされます。お客さまはVMのタイプと数を指定しますが、Databricksが他の全てを管理します。このアプライアンスに加えて、我々がVNet、セキュリティグループ、ストレージアカウントをデプロイするマネージドリソースグループがお客さまのサブスクリプションに作成されます。これらはAzureユーザーにとっては馴染みのあるコンセプトです。これらのサービスがレディになると、ユーザーはAzure Databricks UIやオートスケーリングのような機能を通じてDatabricksクラスターを管理することができます。全てのメタデータ(例えばスケジュールされたジョブ)は、耐障害性のために地理的に複製されるAzure Databaseに格納されます。
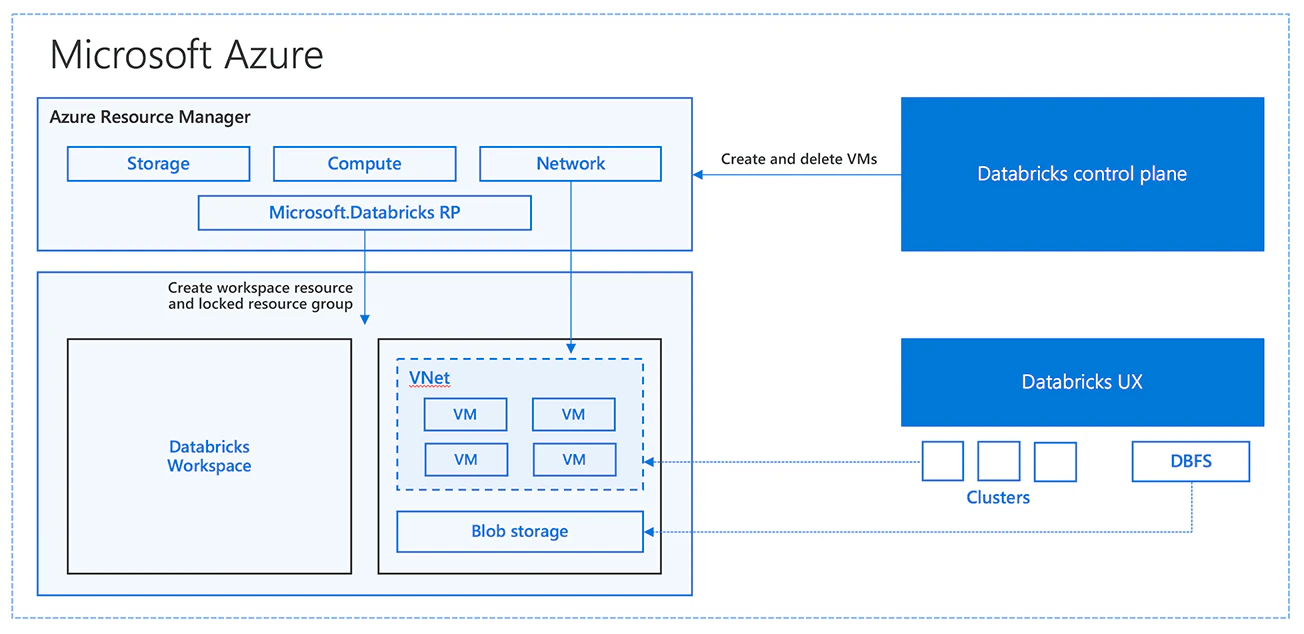
ユーザーに対してこの図は2つのことを意味します。1つ目は、自身のアカウントにある既存のBlob StoreやData Lakeのような任意のストレージアカウントとAzure Databricksを容易に接続できるということです。2つ目はDatabricksはAzureコトンロールセンターから集中管理され、追加のセットアップが不要ということです。
トータルのAzureインテグレーション
ユーザーに対してプラットフォームの最高の部分を提供するために、Azureプラットフォームの全ての機能とAzure Databricksを密にインテグレーションしています。これまでに行ったことを以下に示します。
- VMタイプの多様性: お客さまは全ての既存のVMを使用できます。機械学習シナリオにはFシリーズ、大量のメモリーを要するシナリオではMシリーズ、汎用のケースではDシリーズなど。
- セキュリティとプライバシー: Azureでは、データのオーナーシップとコントロールはお客様にあります。我々はAzure Databricksもこれらの標準に準拠するように構築しました。Azureの他の部分が準拠している全てのコンプライアンス認証をAzure Databricksでも満たそうとしています。
- ネットワークトポロジーにおける柔軟性: お客さまは様々なネットワークインフラストラクチャの要件を持っています。Azure Databricksでは、どのソースとシンクにアクセスできるのか、どのようにアクセスできるのかを制御できるお客さまのVNetetへのデプロイメントをサポートしています。
- Azure StorageとAzure Data Lakeとのインテグレーション: これらのストレージサービスは、既存データのキャッシュや最適化された分析を提供するために、DBFS経由でDatabricksユーザーに対して提供されます。
- Azure Power BI: ユーザーは馴染みのあるツールを用いて、大量データにインタラクティブなクエリーを行えるように、Power BIをJDBC経由で直接Databricksクラスターに接続することができます。
- Azure Active Directoryはリソースに対するアクセスコントロールを提供し、すでに多くの企業で使用されています。お客さまのサブスクリプションにAzure Databricksをデプロイするので、ソース、結果、ジョブに対するアクセスコントロールにAADを使えるのは自然なことです。
- Azure SQL Data Warehouse、Azure SQL DB、Azure CosmosDB: Azure Databricksはさらなる分析、リアルタイムのサービングのために簡単かつ効率的に結果をこれらのサービスにアップロードすることができ、Azureにおけるエンドツーエンドのデータアーキテクチャの構築をシンプルにします。
これまでにあなたが見た全てのインテグレーションに加え、我々はこれ以外のインテグレーションにも力を注ぎました。
- 内部的には、コンテナー経由でAzure Databricksのコントロールプレーンとデータプレーンを実行するためにAzureコンテナーサービスを使用しています。
- 高速化されたネットワークはクラウドにおいて催促の仮想化ネットワークインフラストラクチャを提供します。Sparkのパフォーマンスを改善するためにAzure Databricksはこれを活用しています。
- IOにおける100usのレーテンシーを実現できるNvMe SSDを持つ最新世代のAzureハードウェア(Dv3 VM)。これによって、さらにDatabricksのI/O性能が改善します。
これはまだ表層をなぞったに過ぎません!サービスがGAになりさらに進化することで、今後現れる他のAzureサービスとのインテグレーションを追加していくことになるでしょう。
結論
Azure Databricksを提供するためのこのパートナーシップに非常に興奮しています。クラウド提供者のリーダーと分析システム提供者のリーダーが、AzureのストレージやネットワークインフラストラクチャからApache SparkのDatabricksランタイムに至るまで、徹底的に最適化されたクラウド分析プラットフォームを構築するために初めてパートナーシップを結びました。Azure Databricksがエンタープライズレベルのプロダクションデータアプリケーションの構築をシンプルにすることを信じており、サービスがロールアウトしたら皆様からのフィードバックを心待ちにしています。