Next-Level Interactivity in AI/BI Dashboards | Databricks Blogの翻訳です。
本書は著者が手動で翻訳したものであり内容の正確性を保証するものではありません。正確な内容に関しては原文を参照ください。
今年のData + AIサミットで最近発表されたDatabricks AI/BIは、高度にビジュアル的でインタラクティブなローコードのAI/BIダッシュボードと、AI/BI Genieによって強化されたノーコードの会話型分析によって、皆様の企業におけるビジネスインテリジェンスと分析を民主化します。この記事で、AI/BIダッシュボードのパフォーマンスとインタラクティブ性を強化する数多くの新機能をご紹介できることを嬉しく思っています。
高度にインタラクティブ(あるいはクリッカブルな)ビジネスインテリジェンスダッシュボードは、近年では当たり前のものとなっています。これらは、ダッシュボードをユーザーのクリックごとにデータを動的に探索し、洞察をカスタマイズできるようにするので、重要なものとなっています。これによって、分析を通じた探索や問題解決を制限する静的なダッシュボードとは異なり、データに対するフォローアップの質問を行い、より情報に基づいたし決定をさらに迅速に行えるようになります。
この記事でカバーするキーとなる改善点には以下が含まれます:
- クロスフィルタリング: ダッシュボードをフィルタリングし、他のキーメトリクスやビジュアルへのインパクトを確認するために興味のあるデータポイントをクリックできるようになりました。これには、新たな洞察を明らかにする関係性や相関を理解するためにデータを探索する助けとなります。
- 静的なウィジェットパラメーター: あなたのデータの様々な側面をハイライトするフィルタリングされた複数のビジュアライゼーションを作成します。例えば、売上にフォーカスした二つのグラフを作成し、一つは今年、もう一つは昨年にします。静的なウィジェットパラメーターを用いることで、ビジュアライゼーションごとにカスタムのデータセットを作成する必要なしに、単一のパラメーター化されたデータセットから複数のビジュアライゼーションを作成することができます。
- デフォルト値によるフィルタリング: 初回ロード時に適用されるデフォルトのフィルター値を設定することで、参照者はダッシュボード内で特定のデータやコンテキストにフォーカスできます。
- パフォーマンスの改善: ダッシュボードを開いたり、興味のあるデータポイントをクリックするたびに固まったり、「お待ちください」と表示するダッシュボードを好む人はいないでしょう。このため、追加のSQLクエリーを実行することなしにユーザーが追加の質問を行えるように、高速でインタラクティブなダッシュボードを提供するために、いくつかのパフォーマンス強化を行いました。
- クエリーベースのパラメーター: ダッシュボードの作成者は、フィールドとパラメーターのフィルターの両方を用いて、表現にあふれた体験を作成できるようになっているべきです。単一のフィルターでパラメーターとフィールドの組み合わせを行えるようにすることで、クエリー結果に基づいて動的に生成されるパラメーターのドロップダウンのような新たな機能を実現しました。
クロスフィルタリング
ダッシュボードを探索する際、ビジュアライゼーションにさらに調査したいと考えるような、特出している特定のデータポイントが存在するかもしれません。いくつかのフィルターがすでに適用されているかもしれませんが、これらが全ての参照者のニーズに応えられているわけではありません。
クロスフィルタリングを用いることで、データをフィルタリングするために全てのチャート活用できるようになります。ダッシュボードをフィルタリングし、より深くデータを探索するには、ビジュアライゼーションをシンプルにクリックするだけす。クロスフィルタリングは同じデータセットを共有している全てのビジュアライゼーションで自動的に有効化されているので、ダッシュボードにある全ての関連するビジュアライゼーションでデータをフィルタリングするには、ビジュアライゼーションの一部(棒グラフの棒など)をクリックすればいいことを意味します。
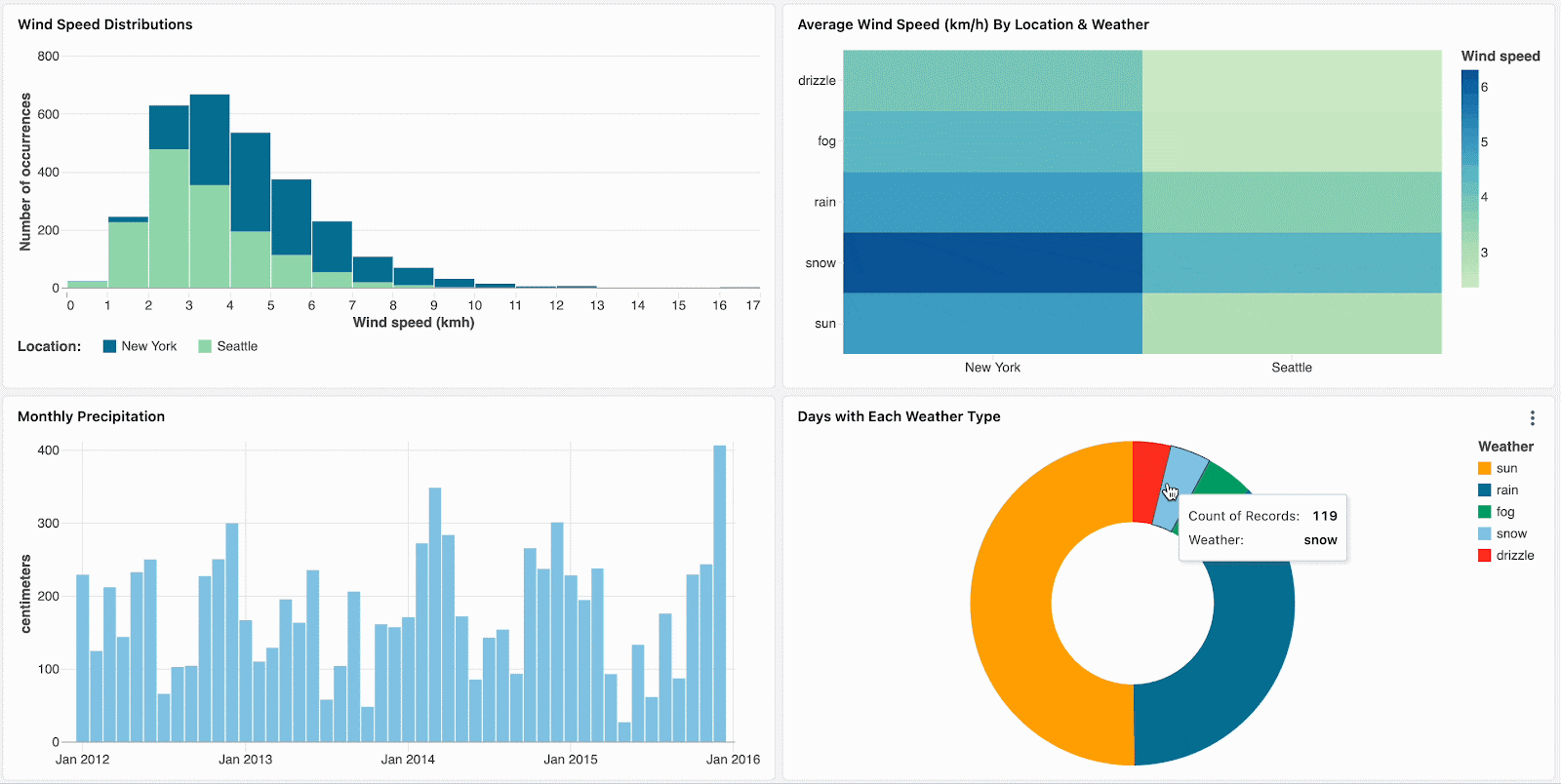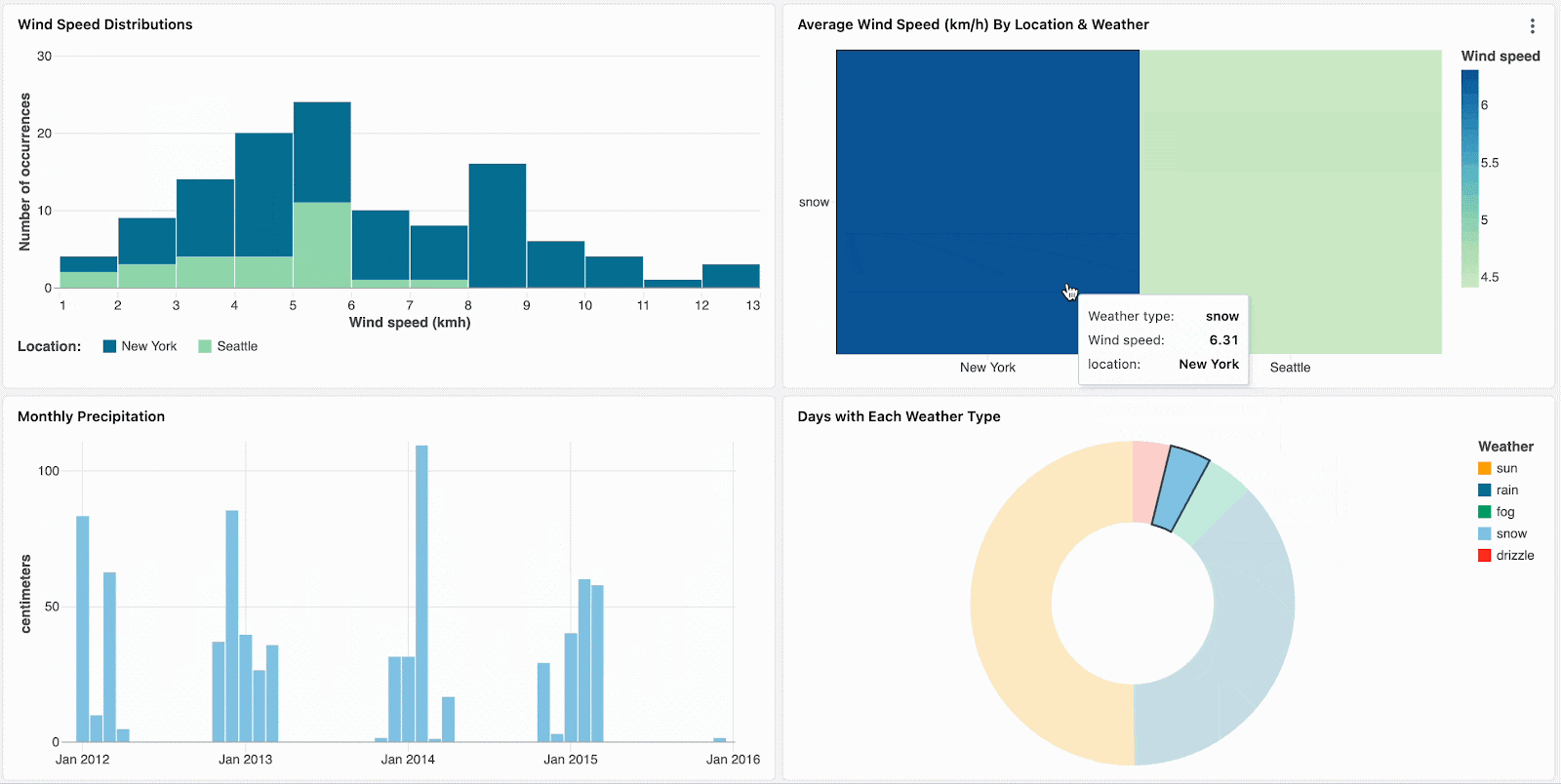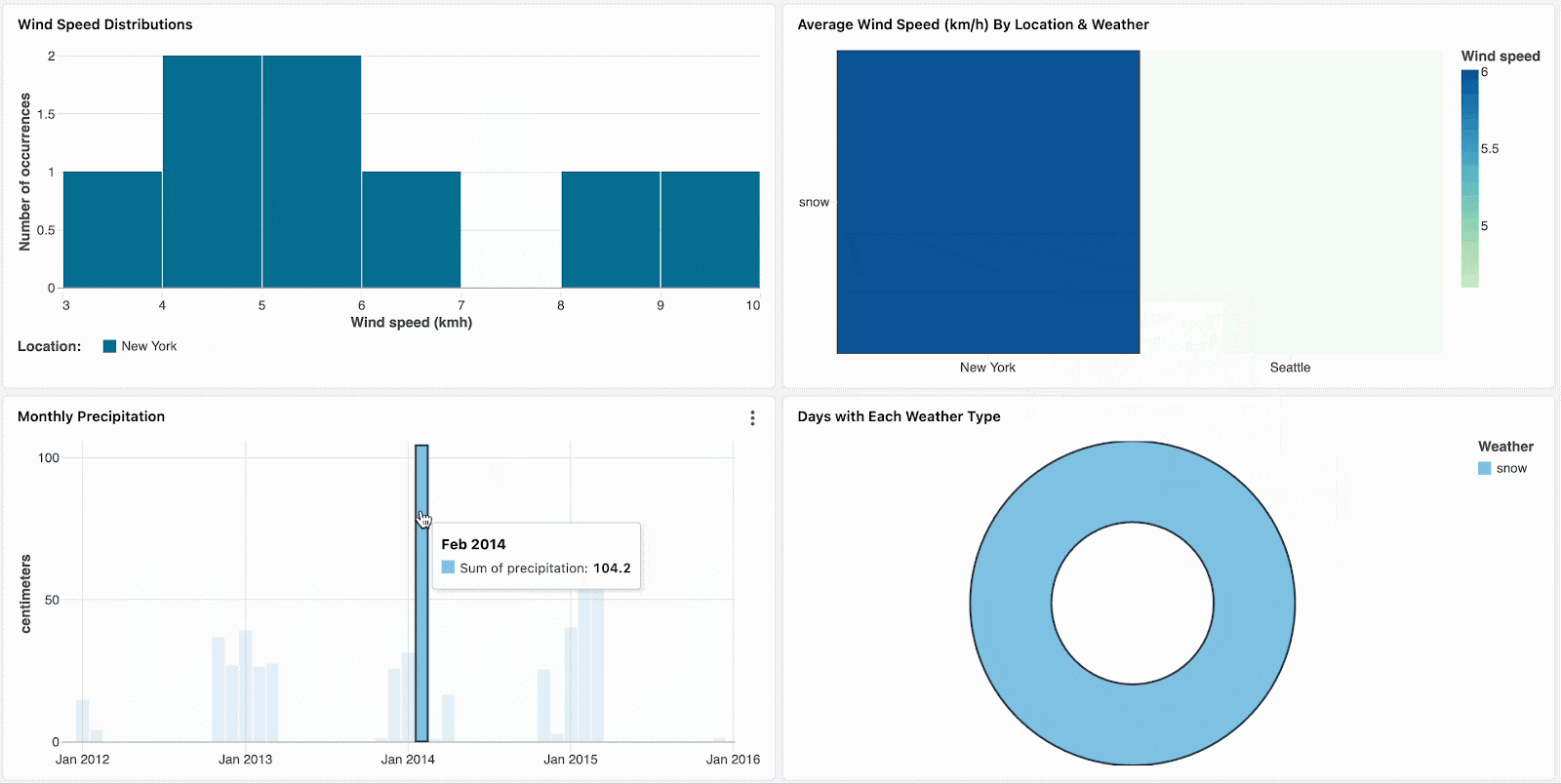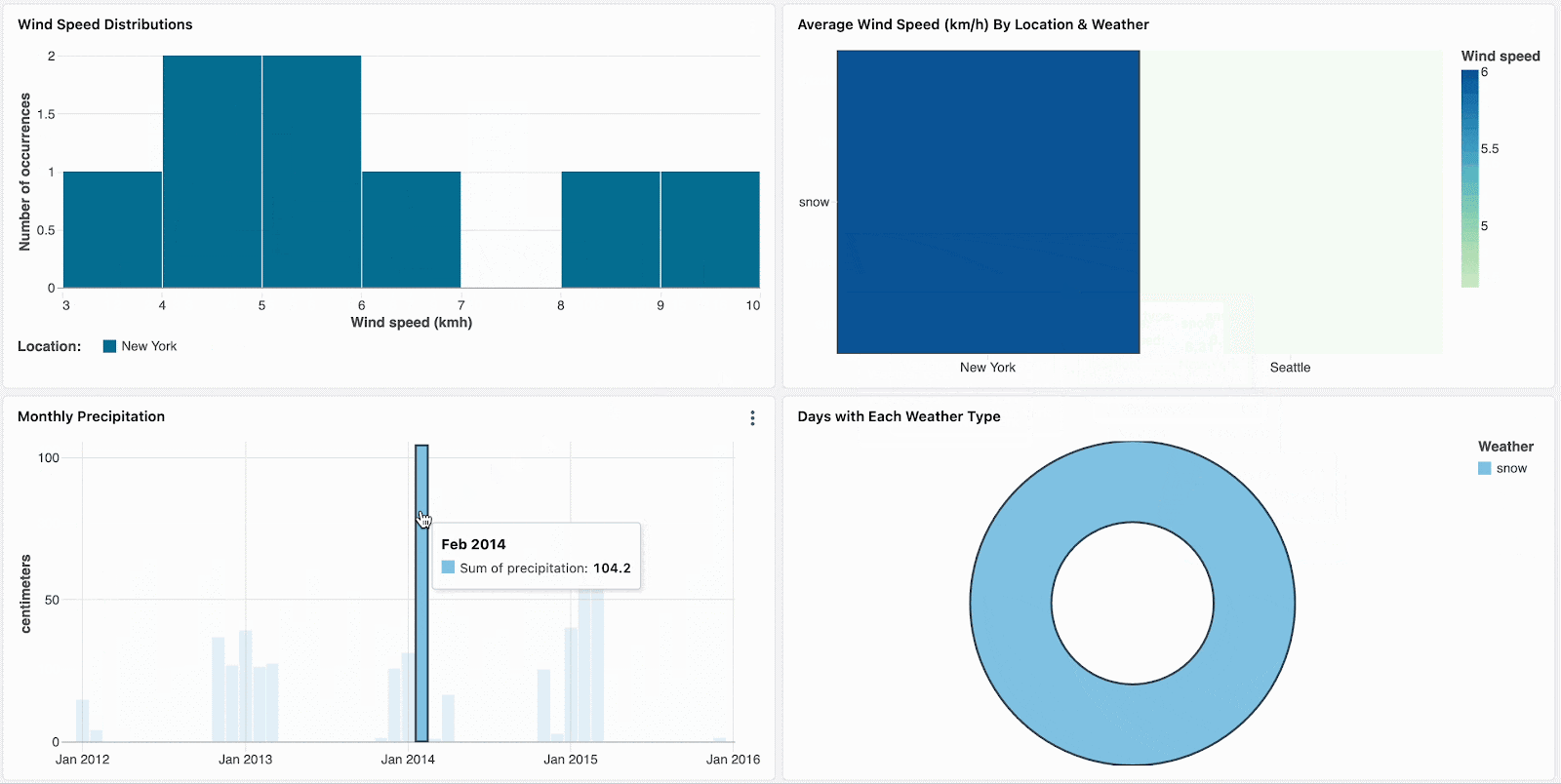
ヒートマップで目立つ箇所のような外れ値をクリックすることで、データをスライスし分析にフォーカスします。
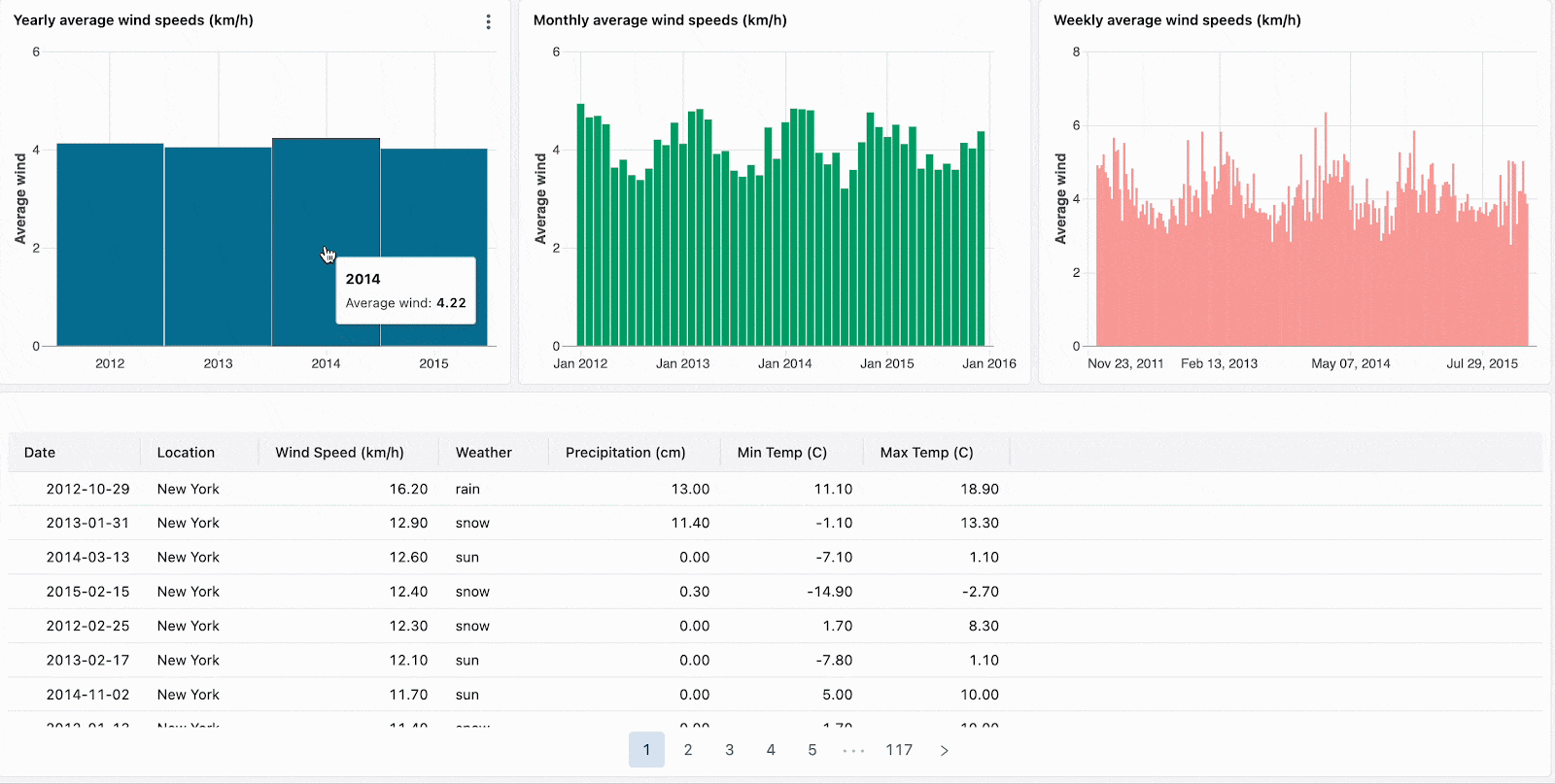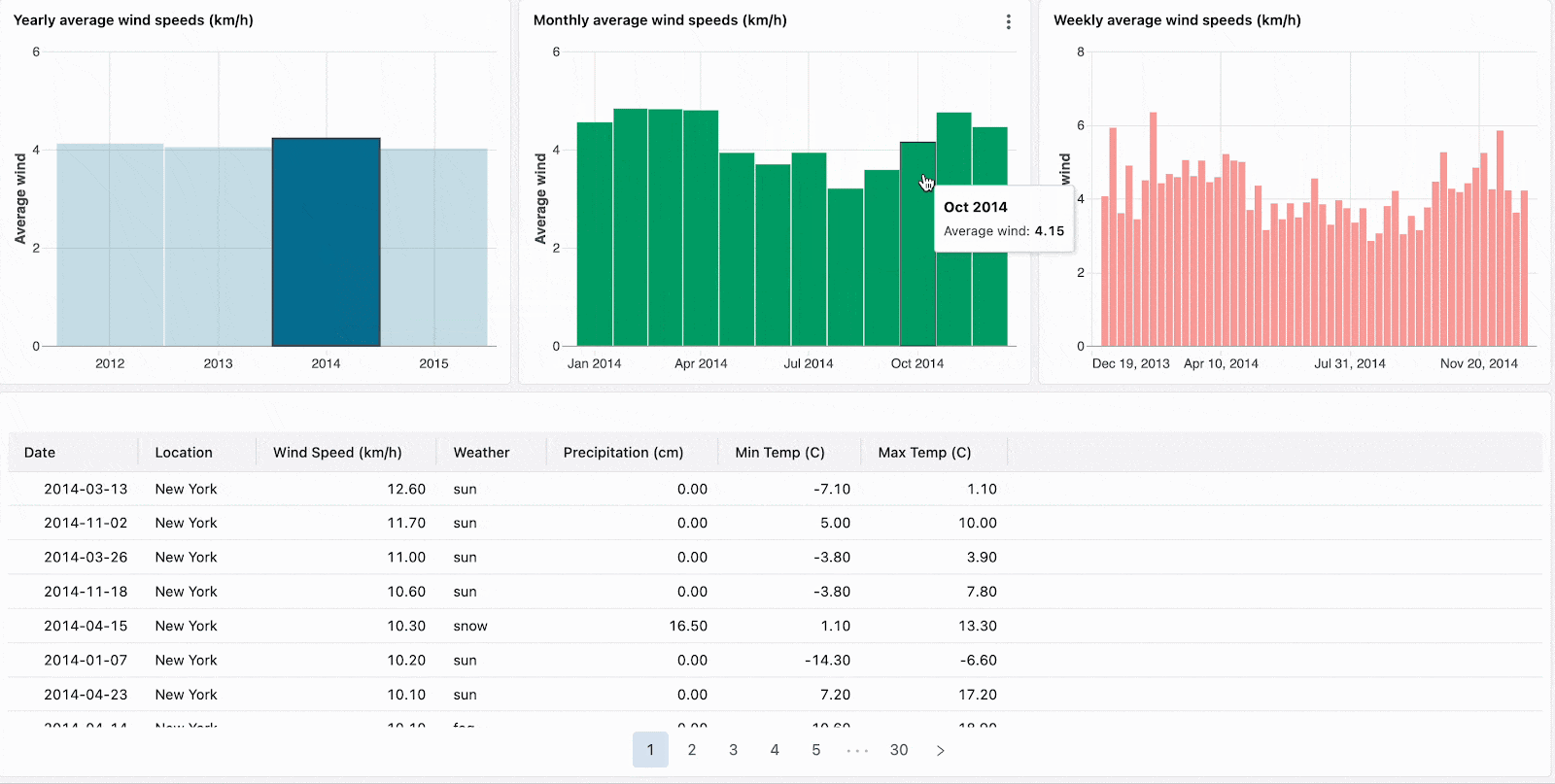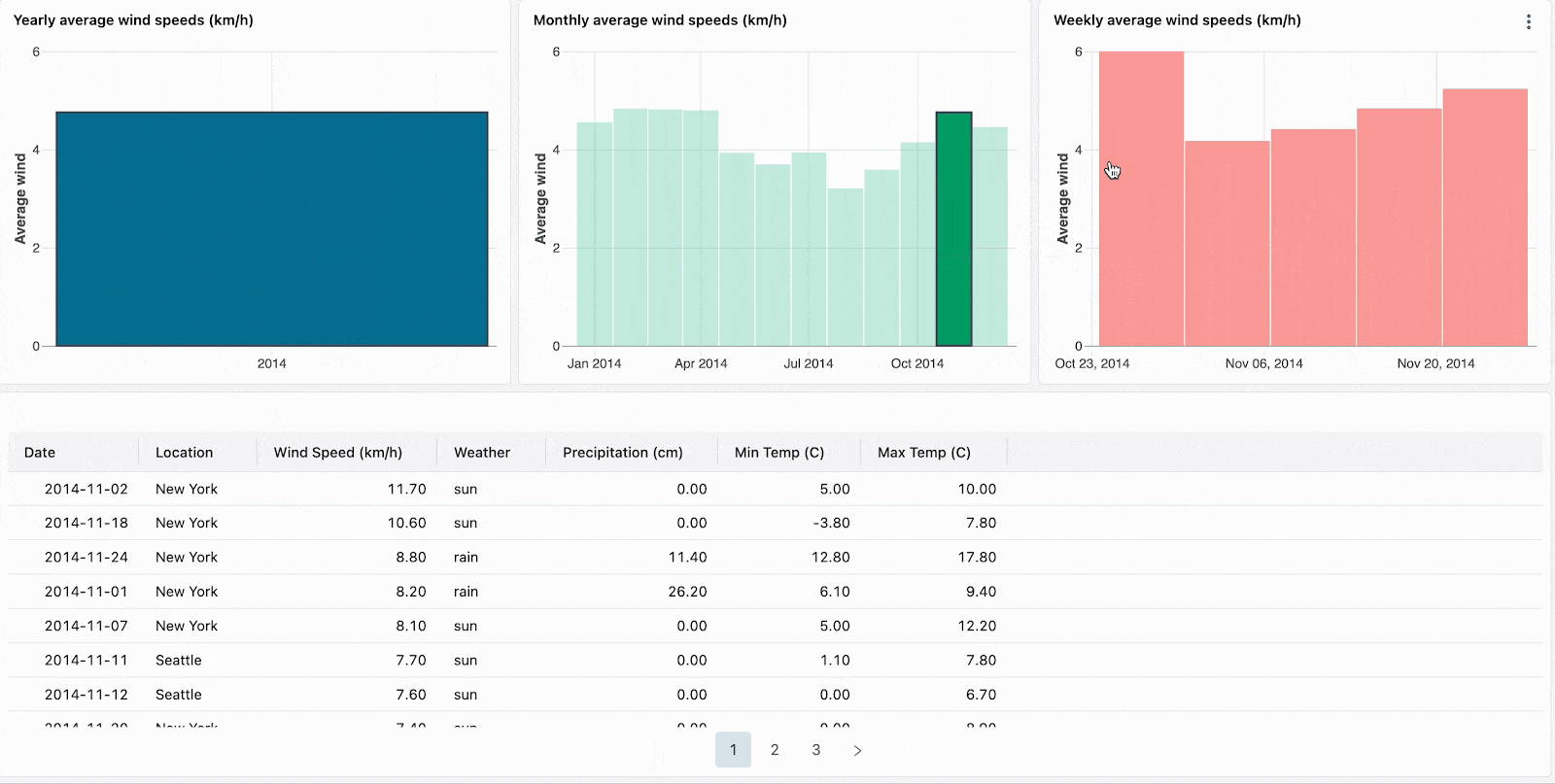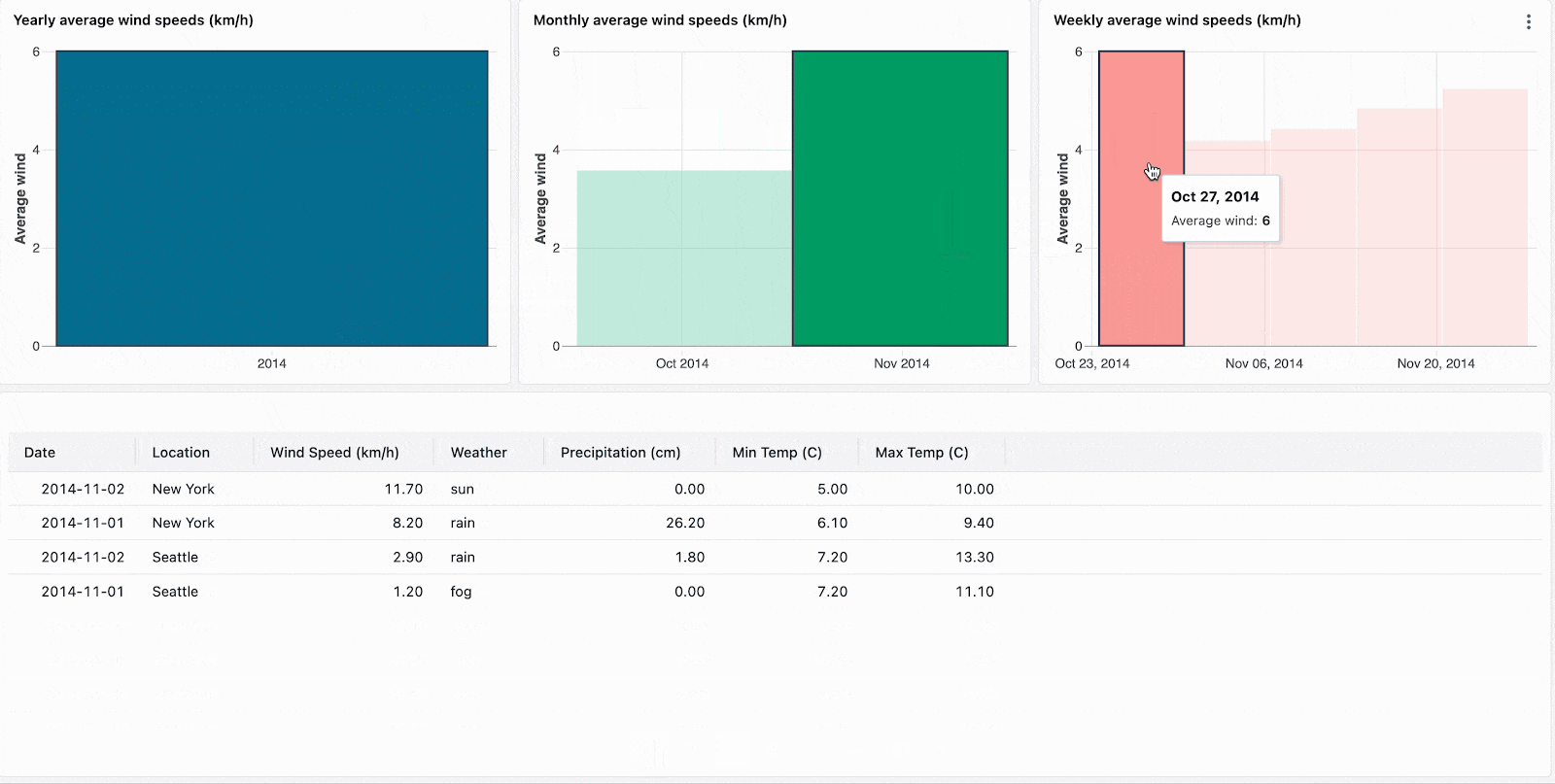
集計されたビジュアライゼーションをドリルダウンすることで、階層型のっデータをナビゲートします。例えば、当該年のデータに他のデータを制限するには、年次データをクリックします。ドリルダウンを継続するには、月レベル、週レベルのチャートのバーをクリックします。
現時点では、クロスフィルタリングは棒グラフ、ヒートマップ、円グラフ、散布図で利用でき、既存のフィールドやパラメーターのフィルターを保管するものとなります。ヒストグラム、折れ線グラフ、エリアチャート、コンボチャート、複数値の選択などのサポートは間も無く提供される予定です。
静的なウィジェットパラメーター
関連づけるデータセットが少ないほど、ダッシュボードの構築は簡単になります。特定のビジュアライゼーションのためのフィルターや集計処理を追加するためだけにデータセットをクローンすることは、混乱や摩擦を引き起こします。
静的なウィジェットパラメーターは、個別にフィルタリングしたデータセットを作成することなしに、それぞれのビジュアライゼーションに対するフィルターをカスタマイズできるので、このプロセスをシンプルにします。この機能は、ビジュアライゼーションごとの集計やビンの数を定義する既存の能力を補完します。
例えば、単一のデータセットを用いて異なる場所の気温のメトリクスをハイライトするために、以下のような条件で拡張することができます:
/*
This filter allows for the display of grand totals when the viewer selects 'All'.
- If a specific location is selected, the filter matches records for that location.
- If 'All' is selected, the filter condition always returns true, including all locations in the results.
Read more details about this pattern here
*/
WHERE location = :location OR :location = 'All'
次に、それぞれの新たなビジュアライゼーションに対して、異なる静的なパラメーターの値を設定するだけです。以下の例では、3つのチャートを確認できます: 一つは全ての場所、一つはシアトル、もう一つはニューヨークです。それぞれのチャートでは同じデータセットを使用していますが、それぞれデータをフィルタリングするために、異なる静的な値が適用されています。
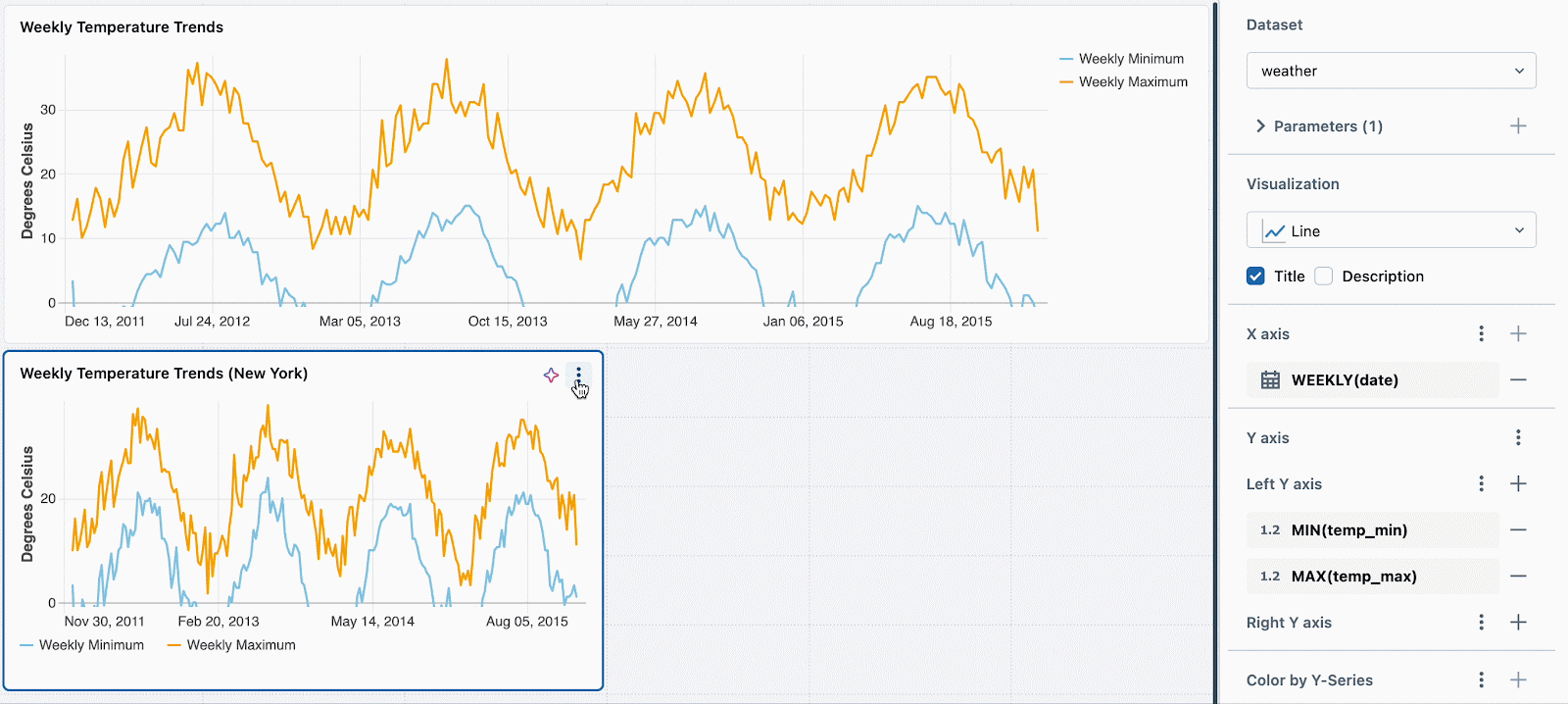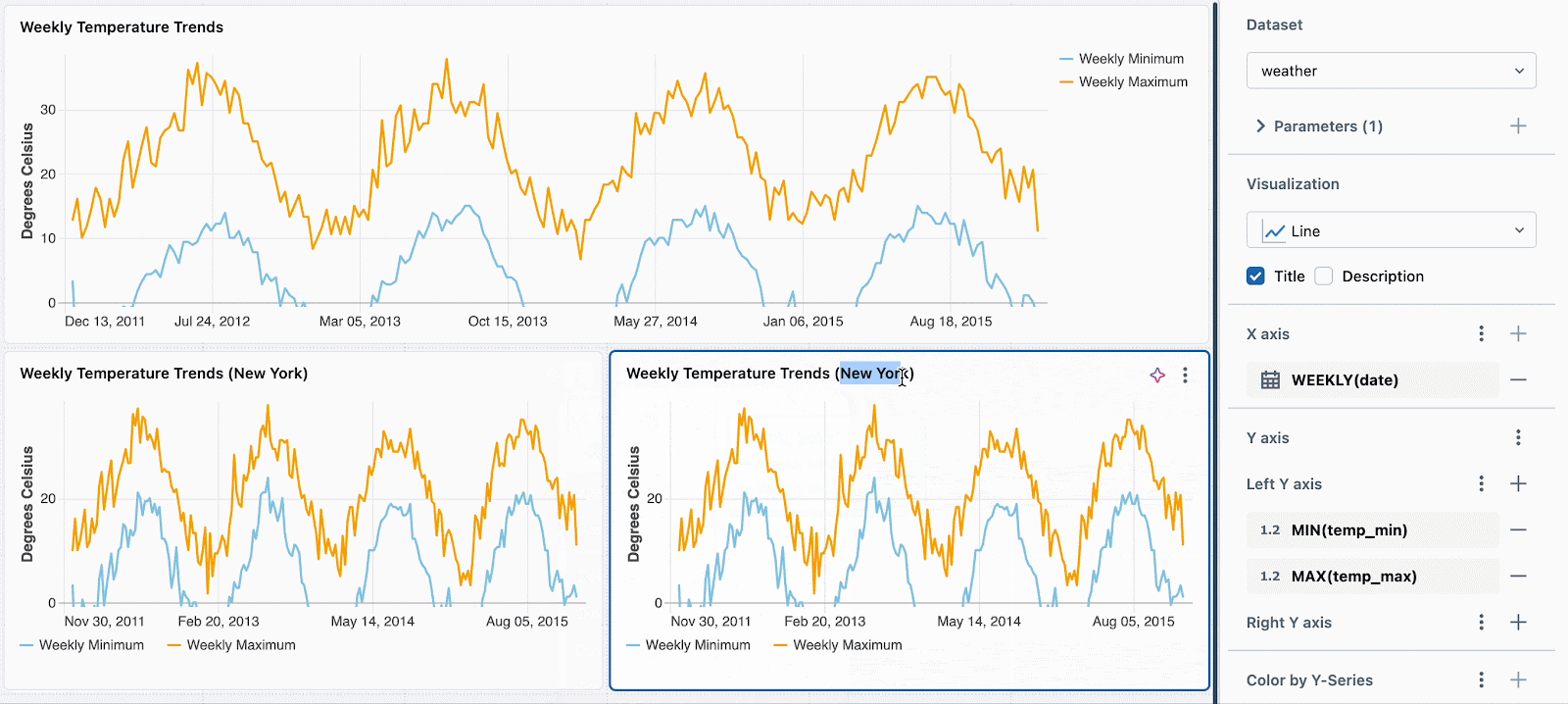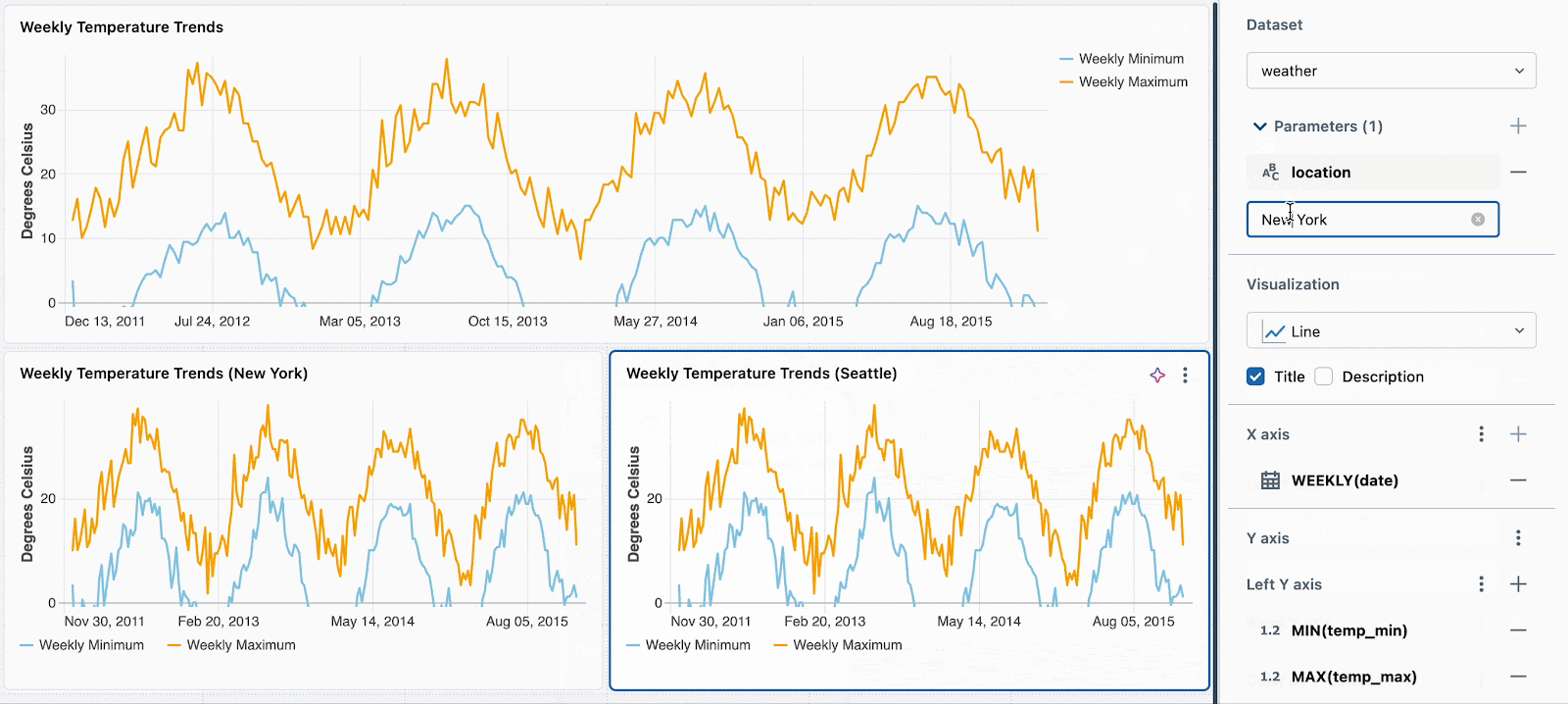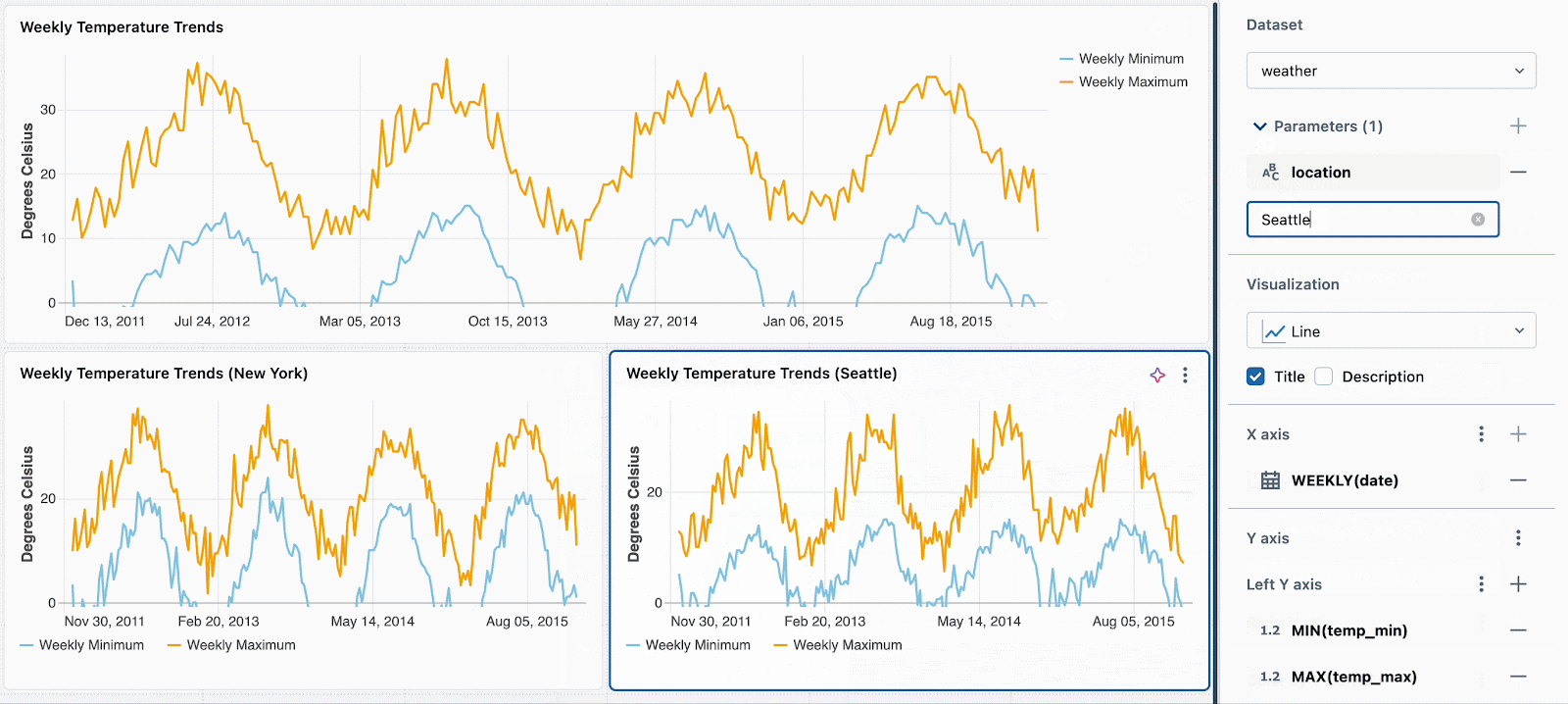
フィールドを用いたウィジェットごとのフィルタリングをサポートするように、この機能を拡張しようとしています。例えば、背後のデータセットをパラメーター化することなしに、場所のフィールドでそれぞれのチャートをフィルタリングできるようになります。
デフォルト値
ダッシュボードの作成者として、特定の日付レンジや場所のような特定のデータスライスに参照者をガイドしたいと思うかもしれません。
デフォルト値を用いることで、初回のダッシュボードのロードや選択がリセットされた際に適用される特定のフィルターの値を設定することができます。これによって、参照者は最初からキーとなるデータポイントにフォーカスさせることができます。デフォルト値は、現在のビューのURLを共有することで、ダッシュボードのフィルターの選択状態を保持する既存の機能を補完します。
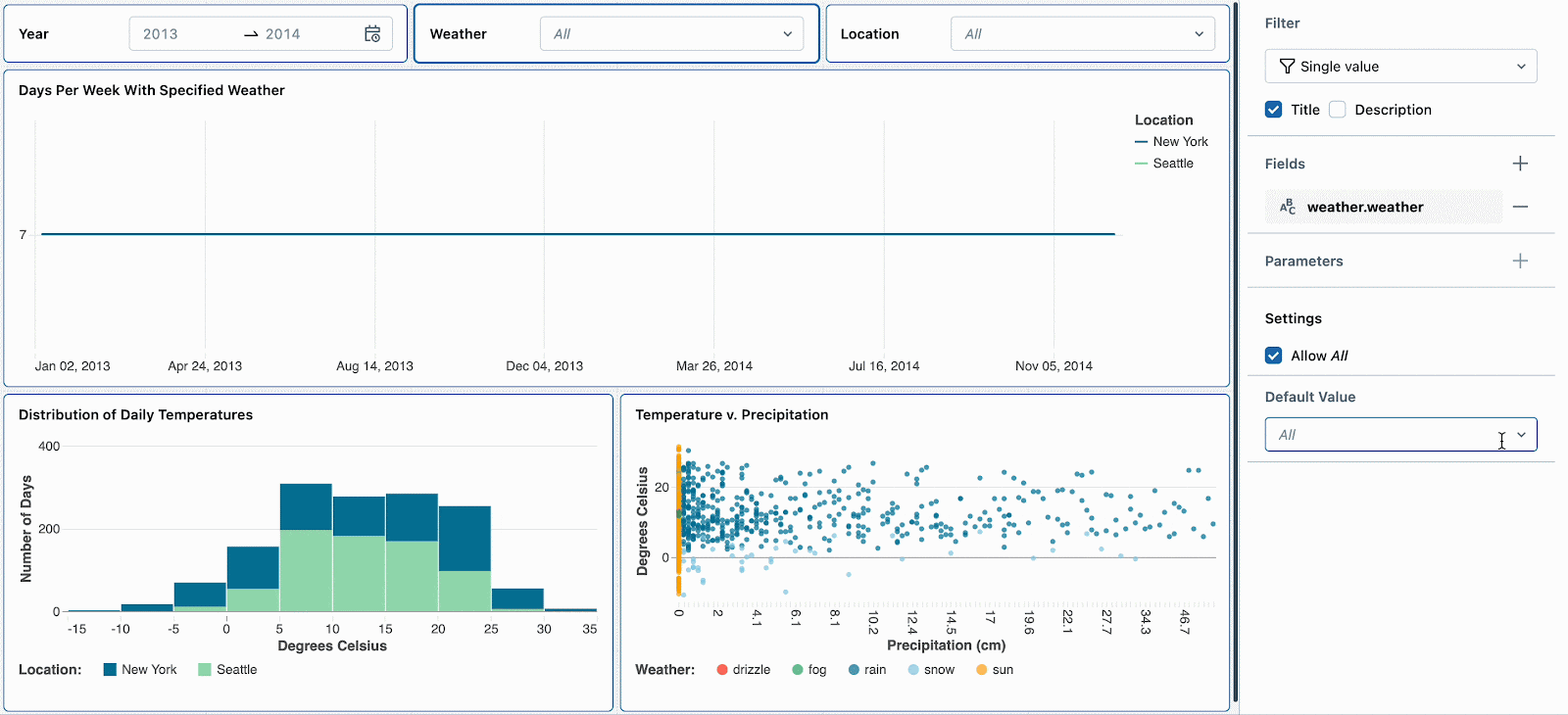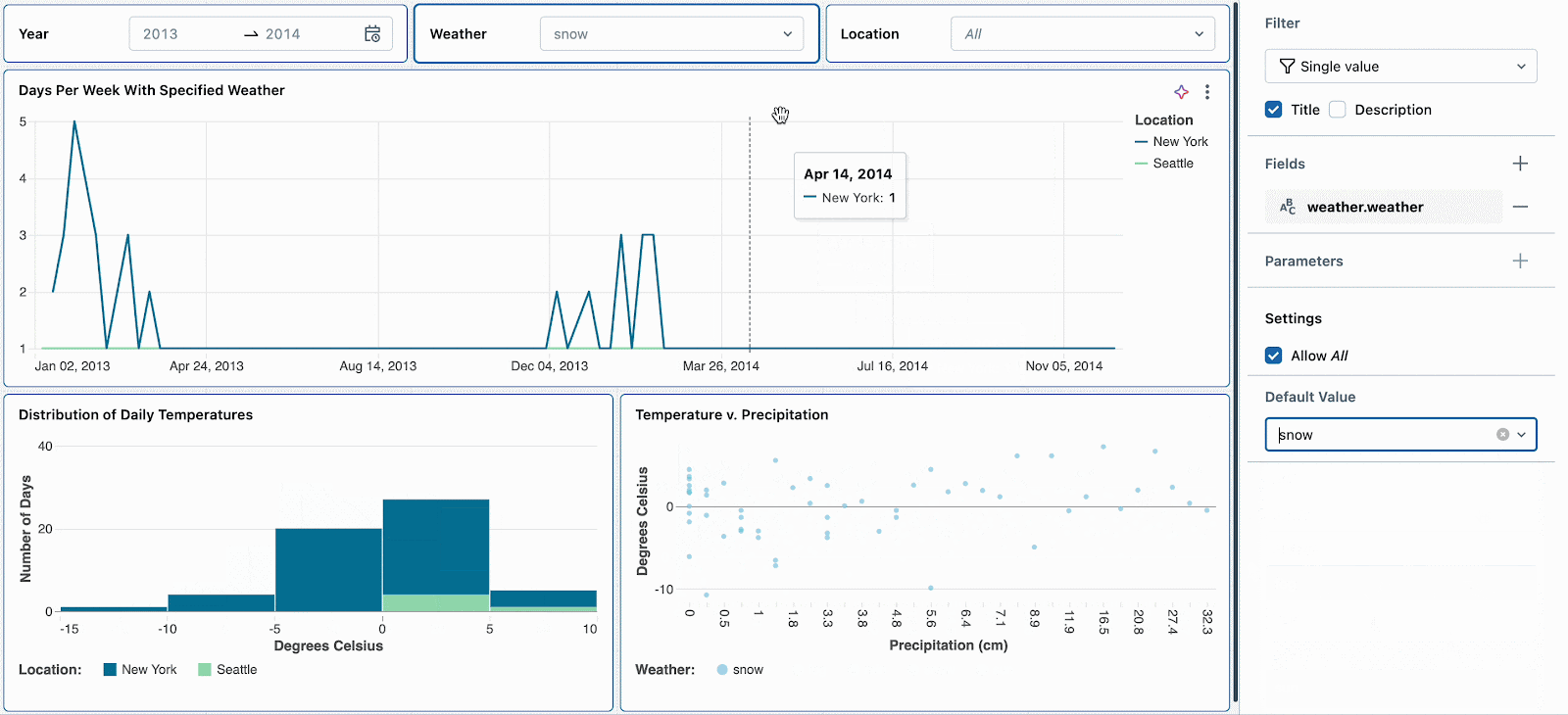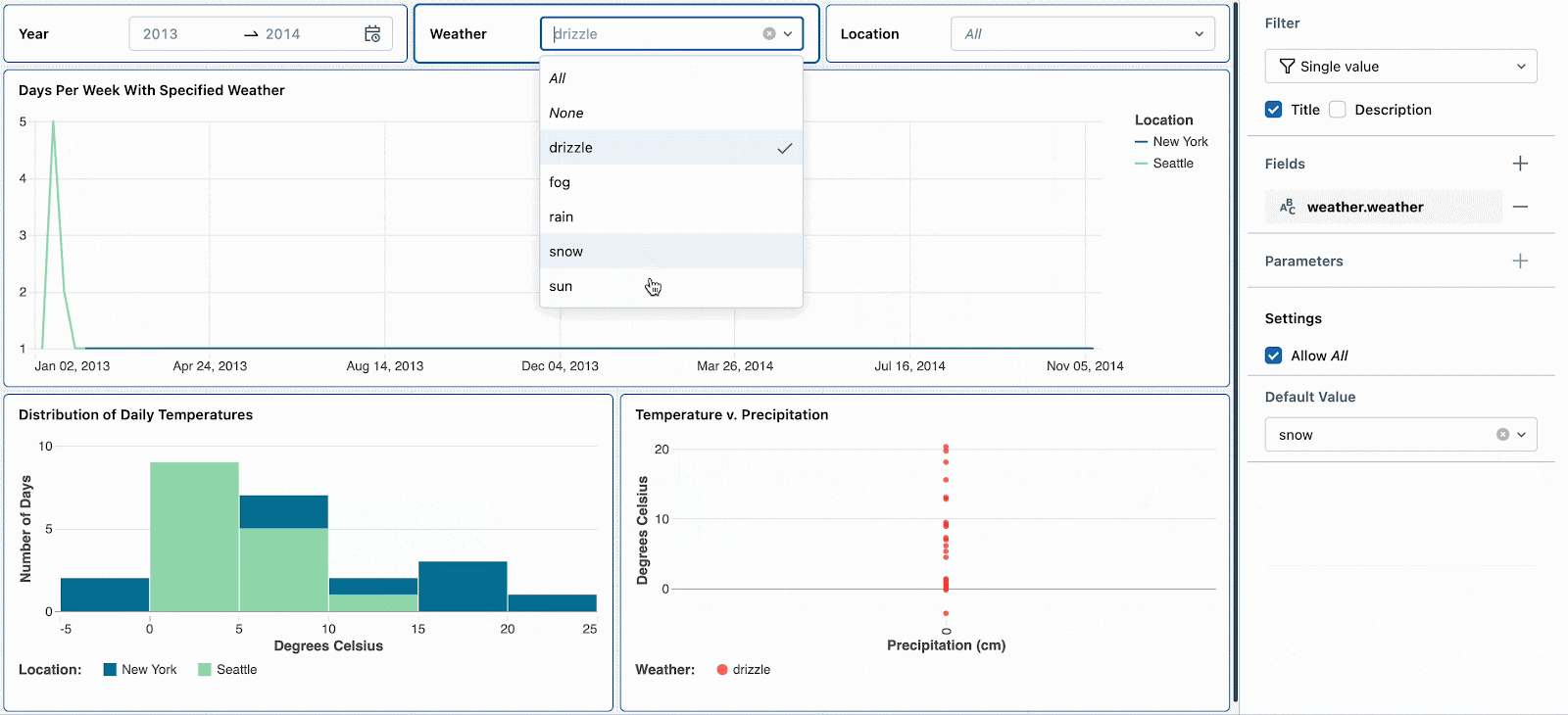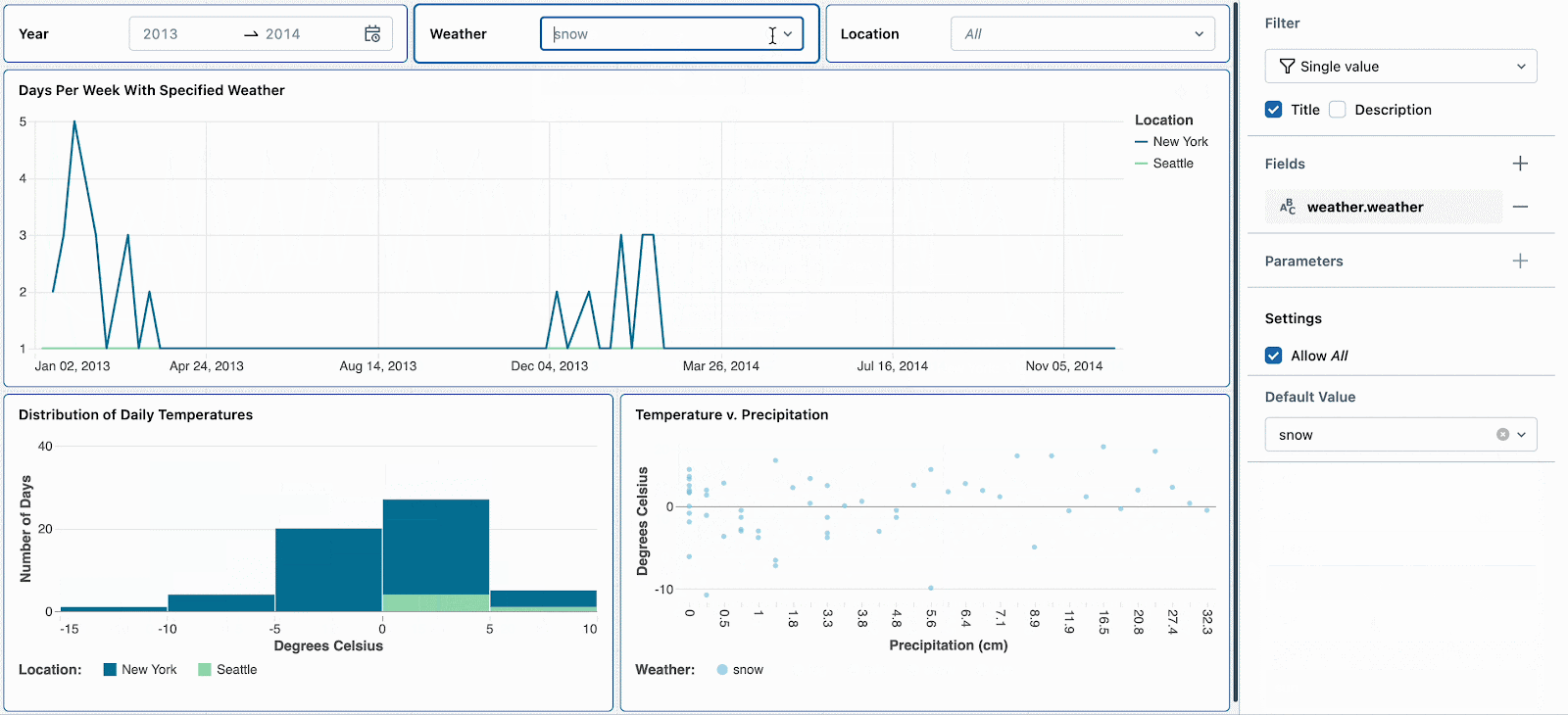
例えば、雪の日は極端な気温と高い降水確率となるため興味があるものとします。デフォルトの気候フィルターを「snow」に設定することで、新たな参照者がこの気候タイプを探索するように促すことになります。他の気候のトレンドを確認した後で、雪の日へのディープダイブを続けるためにフィルターをリセットすることができます。
パフォーマンスの改善
インタラクティブなダッシュボードが本当に楽しいものとなるには、高速であるべきです。フィルターを適用するたびにクエリーの実行を待つことは、分析フローの妨げとなります。
AI/BIダッシュボードでは、クエリーのキャッシュや深いプラットフォーム連携のようなテクニックを通じて、大規模データであっても、高いパフォーマンスに最適化されています。クエリーのキャッシュは、自動でクエリーの結果を24時間保持するので、以前に実行されたクエリーを活用することで、高速なパフォーマンスを確実にします。また、スケジュール処理を通じてプロアクティブにキャッシュを作成することもできます。
高速な初回ロードの提供に加えて、AI/BIダッシュボードでは、変更のたびにクエリーを再実行するのではなく、ブラウザでフィルターを評価することで、小規模なデータセットに対する即座のインタラクティブ性を提供します。
最近我々は、クライアント側のフィルター評価の制限を100K行まで増加させました。これは、この制限に収まるデータセットにおいては、データセット全体が一度クエリーされると、以降の全てのフィルタリングはクライアント側で行われ、追加のサーバー側のクエリーが不要になることを意味します。大規模なテーブルであっても、マテリアライズドビューのような事前集計処理のようなテクニックで、より小規模でフィルタリングが高速になるデータセットを作成することができます。
通常我々は、常にサーバー側のクエリーを必要とするパラメーターではなく、フィールドに対するフィルタリングを推奨します。サブクエリーでのフィルタリングや複雑な集計処理をもつデータセットの定義のように、フィールドに対するフィルタリングではうまく対応できない場合に、パラメーターは最も適しています。
クライアント側のフィルター制限のさらなる増加のような最適化の探索を継続しています。ビジュアライゼーションレベルの計算処理のように間もなく提供される機能は、フィールドに対するフィルタリングを通じて達成することができるユースケースの数を増やすことになります。
クエリーベースのパラメーター
パラメーターは、データセットのSQLのどこでも導入することができるパワフルなツールであり、フィルターを定義する際に最大の柔軟性を提供します。パラメーターはSQLにおけるリテラルに対するプレースホルダーですが、それらは他のすべてのフィールドのように動作すべきであり、作成者が値を設定するためにドロップダウンや他に使用するフィルターに組み込めるようにすべきです。
パラメーターとフィールドの組み合わせを可能にすることで、他のデータセットの値を用いたパラメーターフィルターを作成する能力を追加しました。このクエリーベースのパラメーター値へのアプローチは、動的に変動する日付の粒度のような高度な分析能力を解放します。
例えば、集計で用いられるDATE_TRUNC関数をパラメーター化することで、異なる日付粒度を通じたドリルダウンが可能になります。結果として得られるデータセットとメトリクスは集計されるので、気候フィルターの追加もまたクエリーのパラメーター化を必要とすることを意味します。
SELECT
DATE_TRUNC(:date_granularity, date) as date,
avg(wind) as average_wind_speed,
sum(precipitation) as total_precipitation
FROM
weather
WHERE
:weather = 'All' or weather = :weather
GROUP BY ALL
ダッシュボードの参照者のフィルターのドロップダウンで、簡単に適切な値を選択できるようになっているべきです。例えば、日付のトランケーションにおいて適切なリテラルが"YEAR"であるか"YEARLY"であるのかを推測すべきではありません。適切にドロップダウンを作成するには、以下の二つのデータセットを作成します。
--Dataset 1: Generate a static list of valid date granularities
SELECT * FROM VALUES ('day'), ('week'), ('month'), ('year') AS t(date_granularity)
--Dataset 2: Choose the distinct weather categories from the underlying table
SELECT DISTINCT weather FROM weather UNION ALL SELECT DISTINCT 'All' AS Weather
ドロップダウンを構成するフィールドを参照するために日付の粒度と気候のパラメーターを変更し、日付のドリルダウンを開始します。
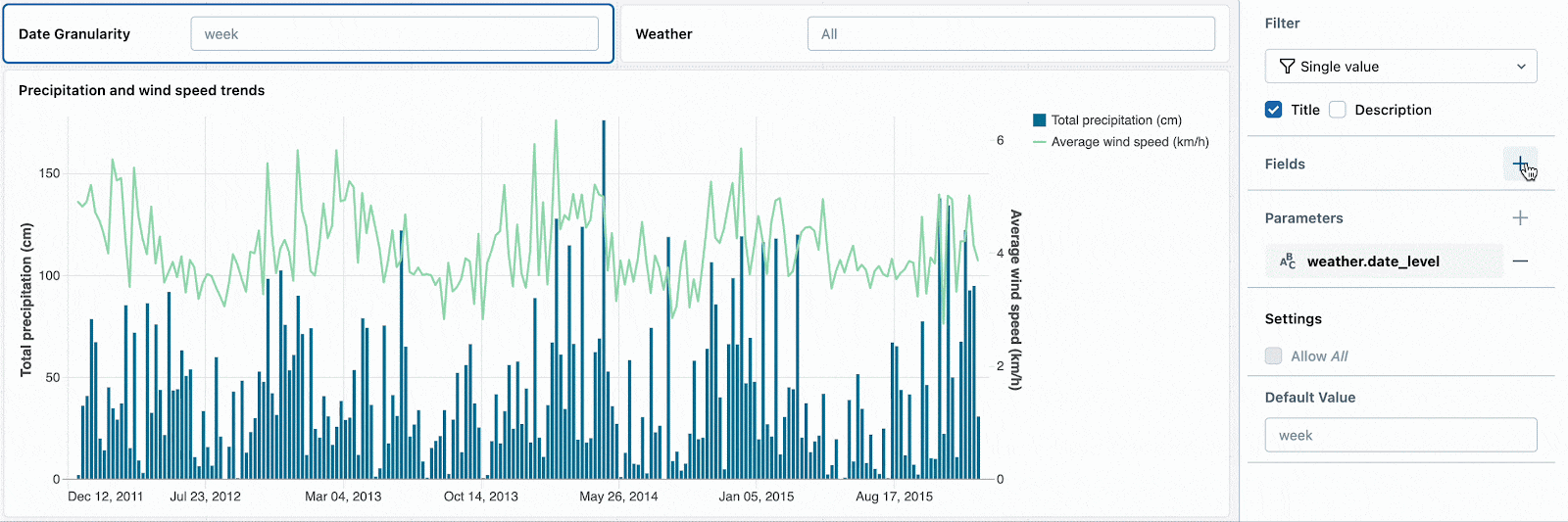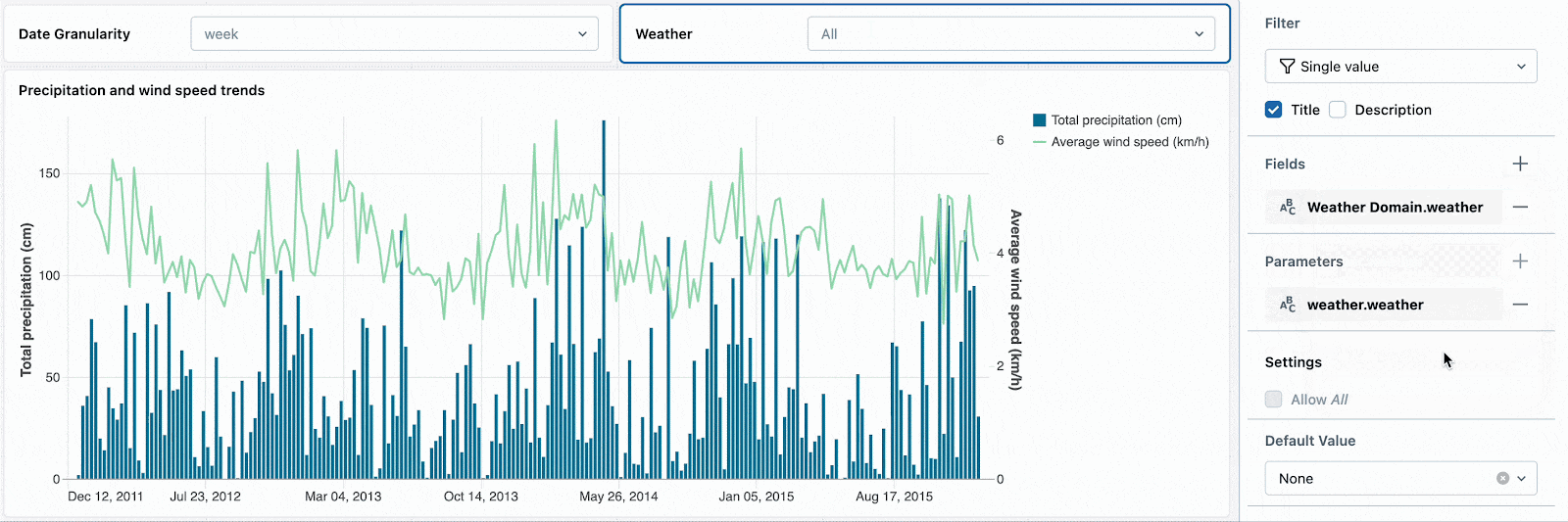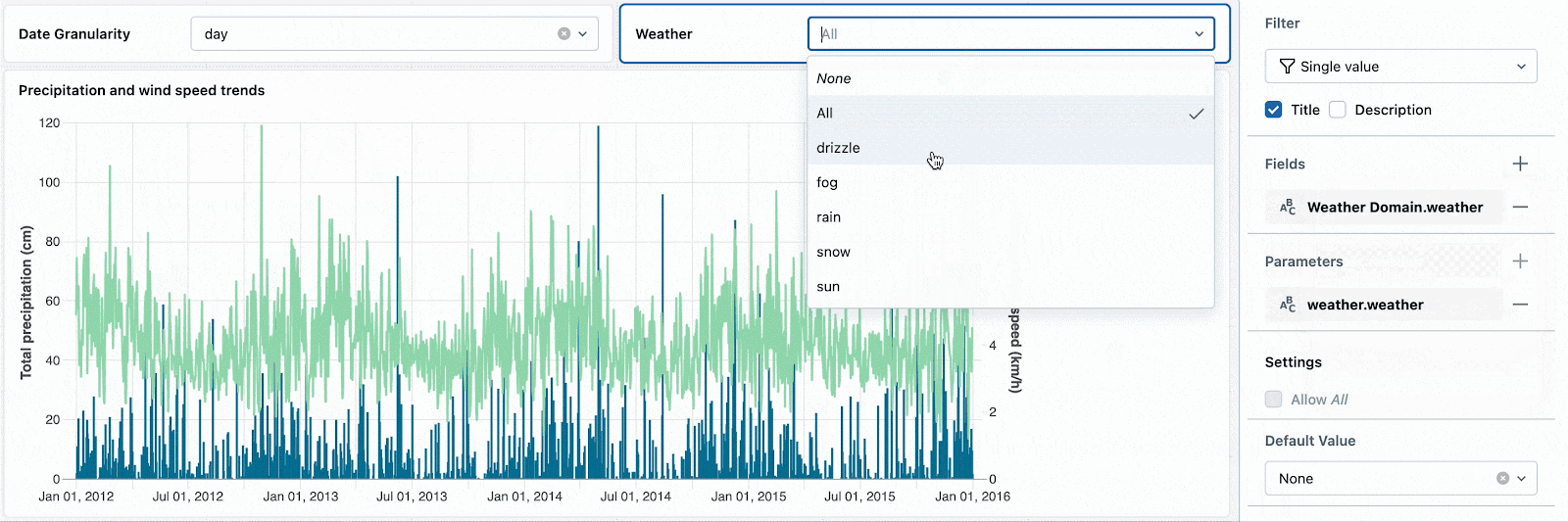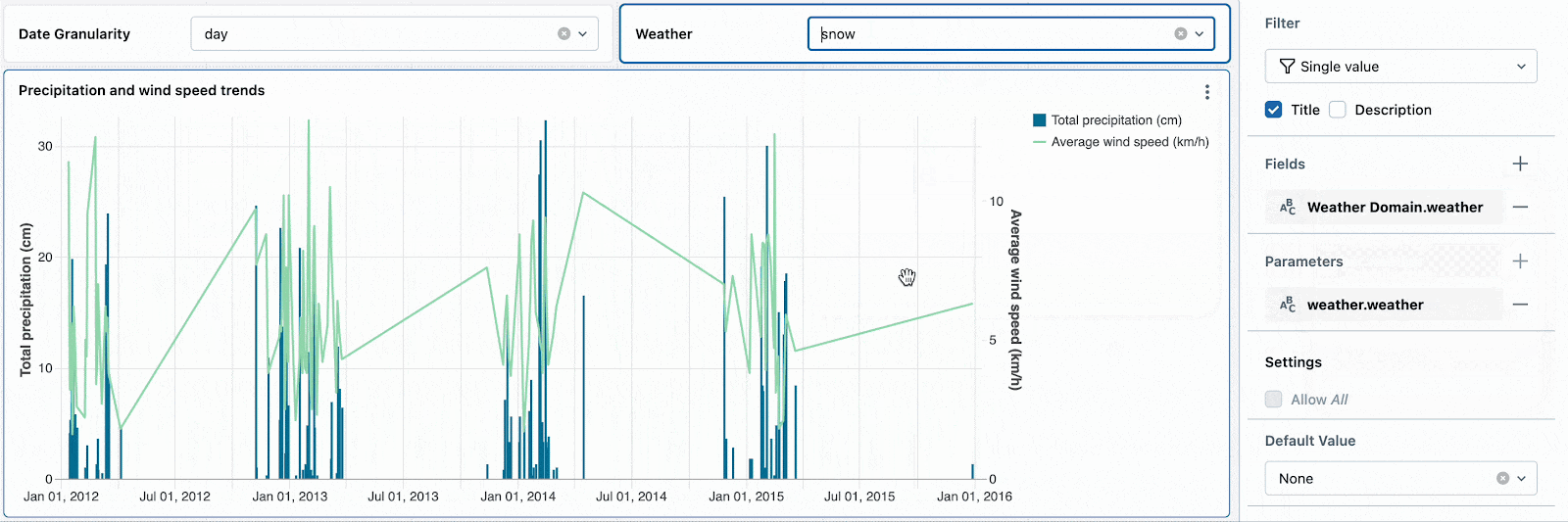
単一のウィジェットでフィールドとパラメーターを組み合わせることでも、データセットがパラメーターを使うのかフィールドフィルターを使うのかに関係なく、複数のデータセットをコントロールするための一つのフィルターを使うことができます。
我々は、日付範囲パラメーターや複数値パラメーターのような間もなく提供される機能で、フィールドとパラメーターのフィルタリングにおける柔軟性をさらに提供しようとしています。
AI/BIダッシュボードの詳細を知るには
ここで説明したように、キーとなるフォーカスとなるインタラクティブ性となるAI/BIダッシュボードは、Databricksにおける重要な投資領域となっています。皆様がこれらの新機能を探索し、どのように自信のダッシュボードを改善するのかを見るのを楽しみにしています。パラメーターやフィルターにおけるディープダイブを含むAI/BIダッシュボードのドキュメントをチェックしてください。
AI/BIダッシュボードの改善、拡張を継続するには皆様のフィードバックが重要です。皆様の考えや提案を聞くことを楽しみにしています!