SparkのデフォルトエンコーディングはUTF-8です。これ以外のエンコーディングのファイルをそのまま読み込むと文字化けします。
PySparkでCSVを読み込む際には、オプションencodingを指定します。
こちらでも、エンコーディングの指定に関する記事が書かれています。
自分でも試してみます。ボリュームにそれぞれのエンコーディングでファイルを保存します。
file_to_read = "/Volumes/users/takaaki_yayoi/encoding/utf8.csv"
# 検出された文字セットでファイルをSpark DataFrameに読み込む
df = spark.read.option("header", True).csv(file_to_read)
# DataFrameを表示
display(df)
UTF-8は問題なく読み込めます。
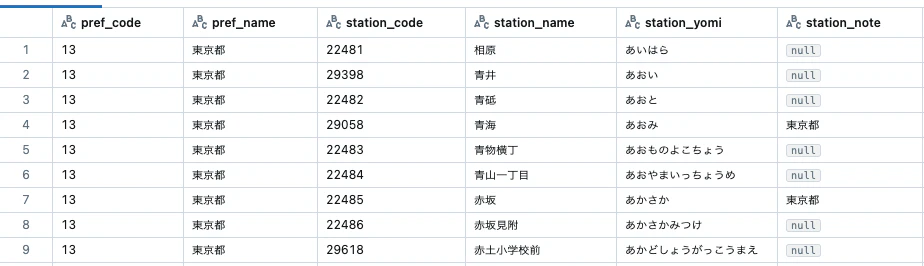
file_to_read = "/Volumes/users/takaaki_yayoi/encoding/euc.csv"
df = spark.read.option("header", True).csv(file_to_read)
# DataFrameを表示
display(df)
EUCは文字化けします。

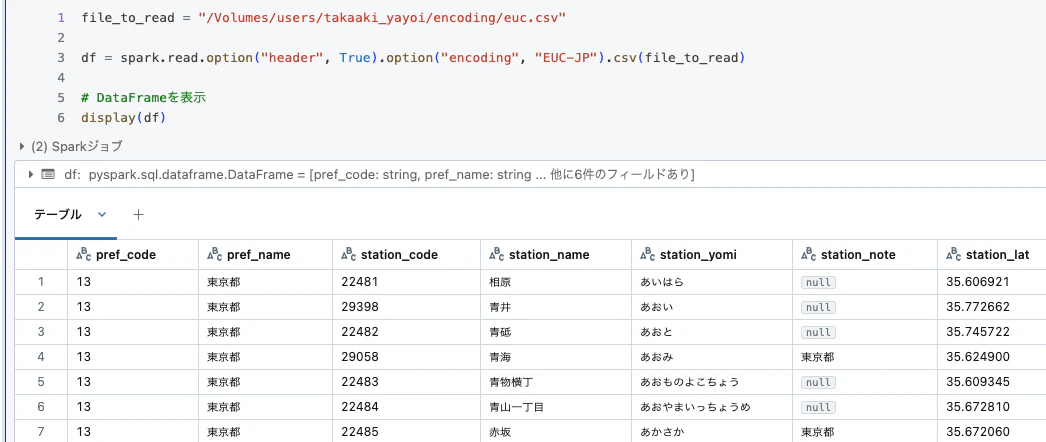
エンコーディングEUC-JPを指定します。
file_to_read = "/Volumes/users/takaaki_yayoi/encoding/euc.csv"
df = spark.read.option("header", True).option("encoding", "EUC-JP").csv(file_to_read)
# DataFrameを表示
display(df)
文字化けが解消されました。
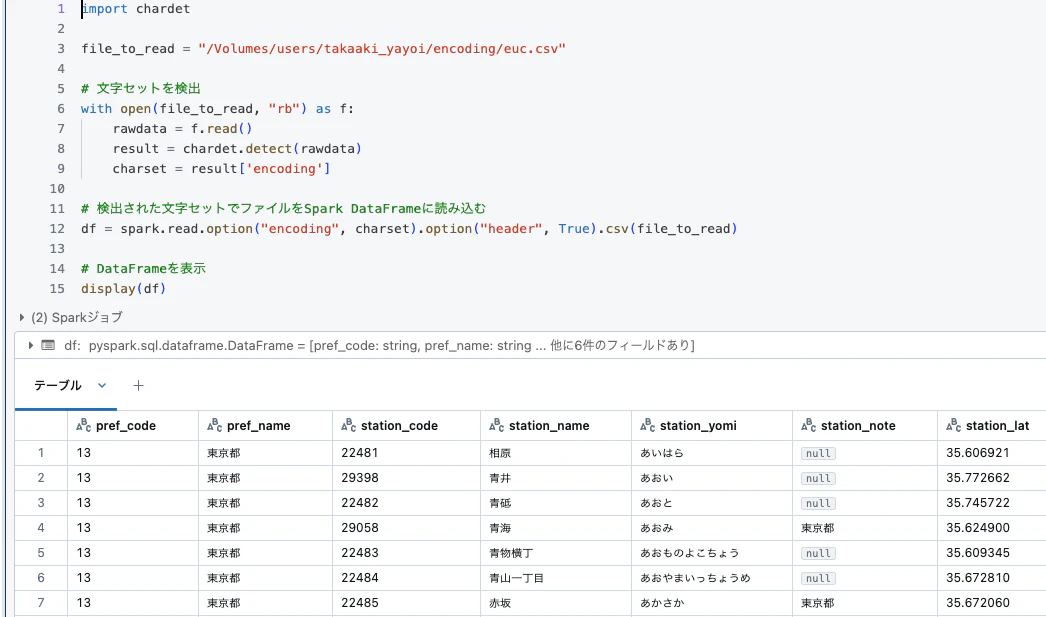
毎回指定するのも大変なので、chardetを使った検知の機構を組み込みます。
import chardet
file_to_read = "/Volumes/users/takaaki_yayoi/encoding/euc.csv"
# 文字セットを検出
with open(file_to_read, "rb") as f:
rawdata = f.read()
result = chardet.detect(rawdata)
charset = result['encoding']
# 検出された文字セットでファイルをSpark DataFrameに読み込む
df = spark.read.option("encoding", charset).option("header", True).csv(file_to_read)
# DataFrameを表示
display(df)
エンコーディングが検知され、それを用いてCSVファイルが読み込まれまるようになりました。